Encoded but Not Routed: Explaining the Table-Chart Gap in Scientific Claim Verification
Pith reviewed 2026-06-28 15:10 UTC · model grok-4.3
The pith
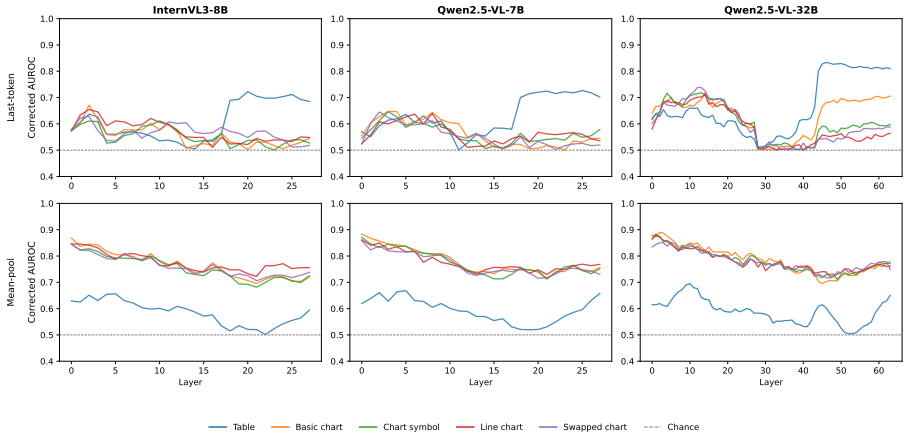
Chart information is encoded in vision-language models but does not reach the prediction token, unlike table information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
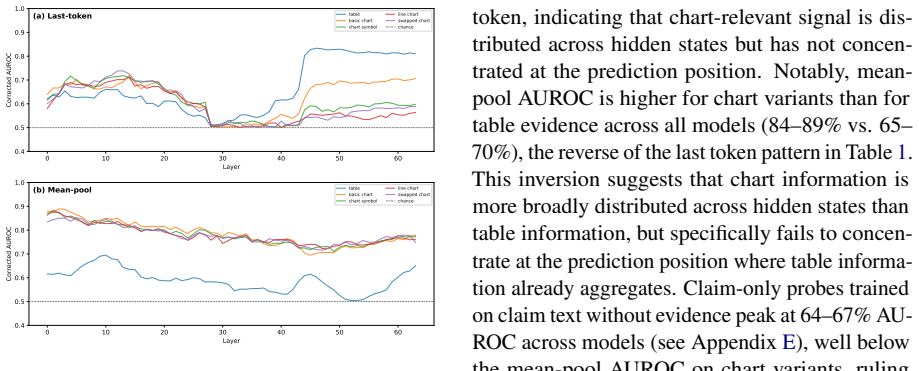
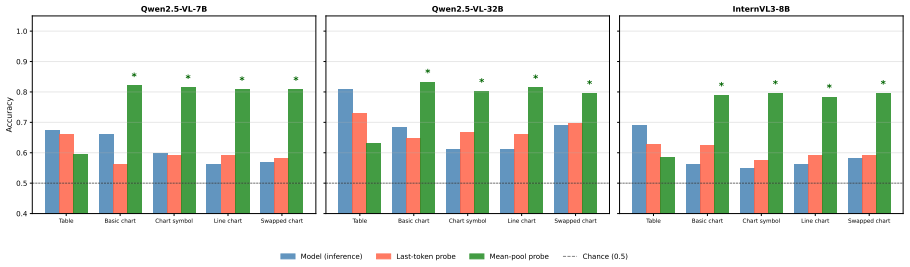
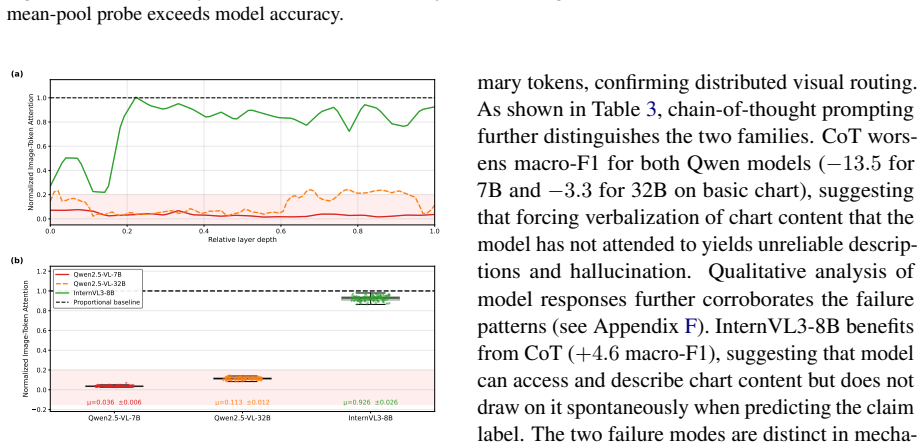
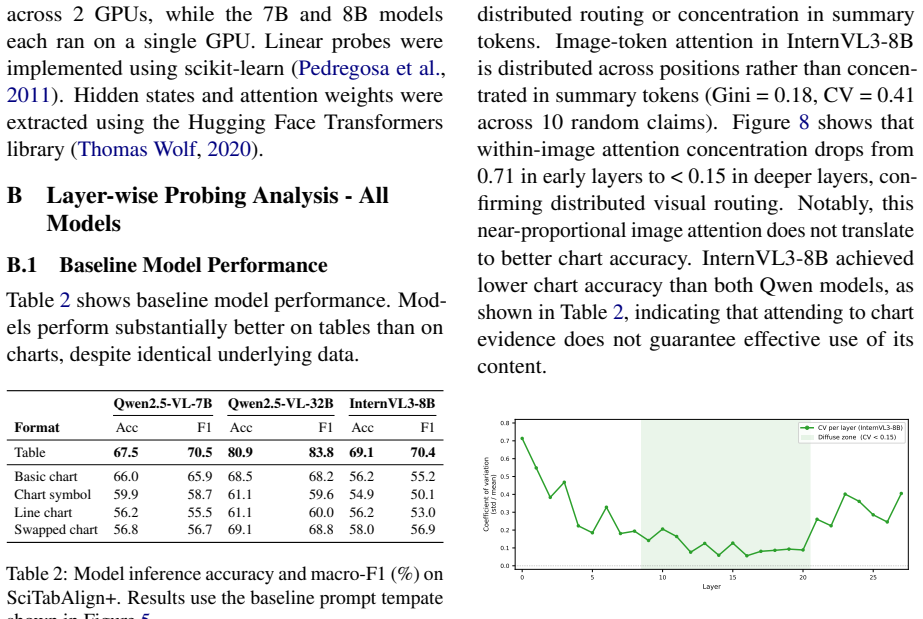
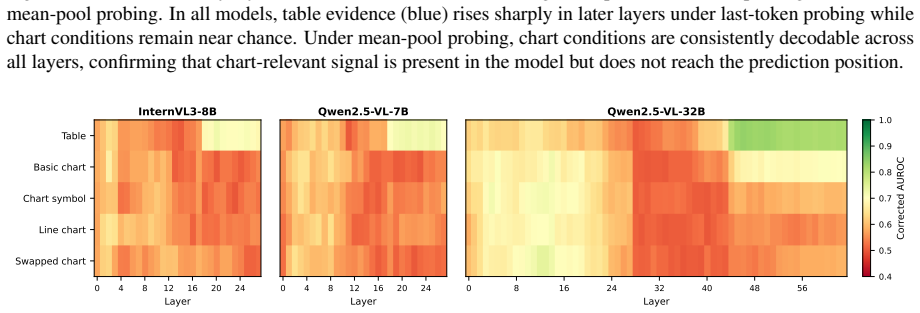
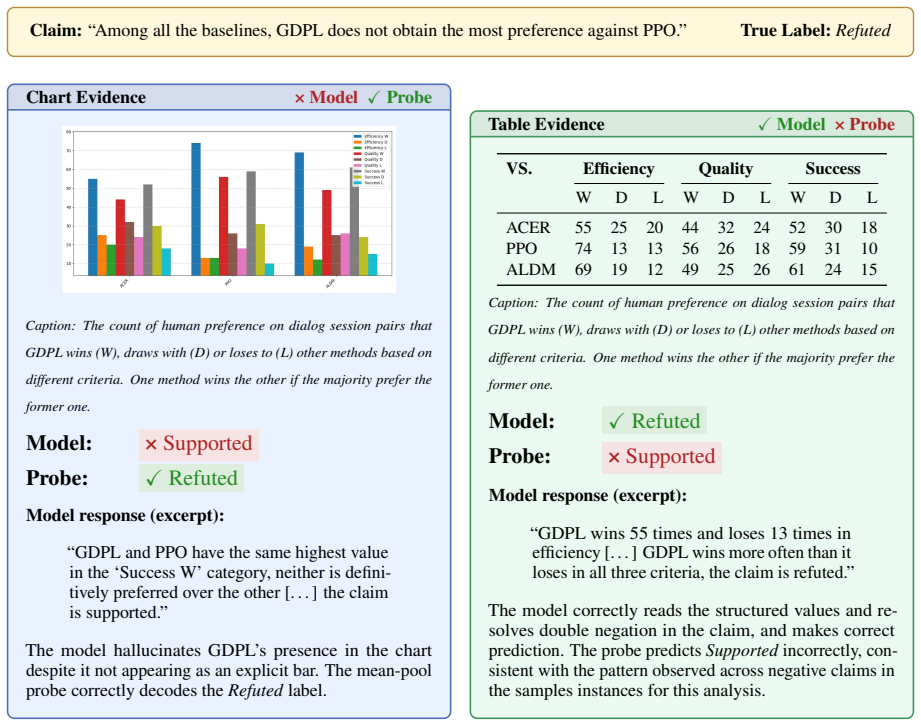
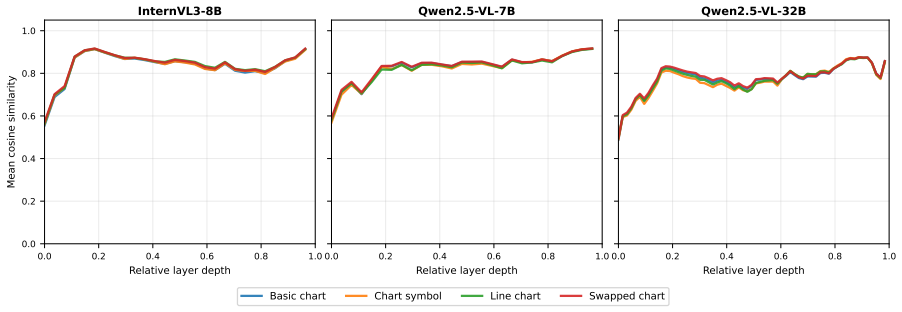
The central claim is that chart information is encoded in the models' intermediate representations but does not reach the prediction position, a gap absent for tables that holds across all conditions. Attention analysis reveals this disconnect takes two architecturally distinct forms across model families. This reframes the table-chart gap as a failure of routing encoded visual information at prediction time rather than a failure of encoding itself.
What carries the argument
Layer-wise linear probing of intermediate representations combined with attention analysis to track whether encoded information reaches the prediction token.
If this is right
- The performance advantage of tables over charts stems from successful routing of encoded data to the prediction step.
- Different vision-language model architectures exhibit distinct mechanisms for the routing failure with charts.
- Addressing the table-chart gap requires methods that ensure visual information influences the prediction position.
Where Pith is reading between the lines
- Modifying attention mechanisms or adding explicit routing layers could close the gap in chart-based verification.
- The same encoding-without-routing pattern may appear in other multimodal tasks beyond scientific claim verification.
- Probing methods like those used here could diagnose similar issues in new model releases.
Load-bearing premise
Linear probing at intermediate layers measures information available for downstream use, and attention patterns indicate whether information reaches the prediction token.
What would settle it
A model variant where chart representations are forced to attend to the prediction token would close the performance gap with tables if the routing account is correct.
Figures



read the original abstract
Multimodal LLMs are increasingly used to assist scientific peer review, where a core requirement is verifying whether claims in a paper are supported by its evidence. Prior work has shown that models perform substantially better at this task when the evidence is a table than when it is a chart of the same underlying data. This raises the question of whether models fail to extract information from charts, or do they extract it but fail to use it when forming their prediction? We study this question through layer-wise linear probing and attention analysis on three open-weight VLMs over table and chart evidence, representing the same underlying data. We find consistent evidence for the latter. Chart information is encoded in the models' intermediate representations but does not reach the prediction position, a gap that is absent for tables and holds across all conditions tested. Attention analysis further reveals that this disconnect takes two architecturally distinct forms across model families. These findings reframe the table-chart gap as a failure of how encoded visual information is routed at prediction time, rather than a failure of encoding itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the table-chart performance gap in multimodal LLMs for scientific claim verification. Using layer-wise linear probing and attention analysis across three open-weight VLMs, it reports that chart data is encoded in intermediate-layer representations (high probe accuracy) but fails to reach the final prediction position, a disconnect absent for tables; attention patterns indicate two architecturally distinct routing failures. The central claim reframes the gap as a routing rather than encoding problem.
Significance. If the empirical patterns hold under causal scrutiny, the work supplies a mechanistic account of a documented multimodal failure mode and identifies a concrete target (routing at prediction time) for architectural or training interventions. The consistency of results across models and conditions is a strength; the absence of parameter fitting or self-referential definitions keeps the analysis non-circular.
major comments (2)
- [§4] §4 (Probing Results): The reframing from 'encoding failure' to 'routing failure' rests on the inference that high intermediate-layer probe accuracy demonstrates information available for downstream use while low accuracy at the prediction token demonstrates a routing failure. Linear probes recover linearly separable information that the model's non-linear pathways may never employ; without representation editing, attention ablation, or path-specific knockouts, the observed gap is compatible with both interpretations. This assumption is load-bearing for the central claim.
- [Attention Analysis] Attention Analysis subsection: The claim that attention patterns reveal 'architecturally distinct forms' of the disconnect across model families requires explicit quantification of how attention weights track residual-stream flow to the prediction token; current attention analysis does not exhaustively rule out alternative flow paths.
minor comments (2)
- [Methods] Clarify the exact layer indices used for 'intermediate' vs. 'prediction position' probes and report the number of data points per condition to allow replication.
- [Figure 3] Figure 3 caption should state whether error bars reflect standard deviation across seeds or across data splits.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below, indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [§4] §4 (Probing Results): The reframing from 'encoding failure' to 'routing failure' rests on the inference that high intermediate-layer probe accuracy demonstrates information available for downstream use while low accuracy at the prediction token demonstrates a routing failure. Linear probes recover linearly separable information that the model's non-linear pathways may never employ; without representation editing, attention ablation, or path-specific knockouts, the observed gap is compatible with both interpretations. This assumption is load-bearing for the central claim.
Authors: We agree that linear probes demonstrate the presence of linearly extractable information but do not prove that the model employs this information via its non-linear pathways. Our central claim is grounded in the consistent contrast between tables (where probe accuracy remains high at the prediction token) and charts (where it drops), observed across three models and multiple conditions. This differential pattern under identical methods supports interpreting the gap as routing-related rather than a general artifact of probing. We will revise §4 to explicitly acknowledge the correlational nature of the evidence, add caveats on interpretation, and note that causal interventions (e.g., representation editing) would provide stronger confirmation. revision: yes
-
Referee: [Attention Analysis] Attention Analysis subsection: The claim that attention patterns reveal 'architecturally distinct forms' of the disconnect across model families requires explicit quantification of how attention weights track residual-stream flow to the prediction token; current attention analysis does not exhaustively rule out alternative flow paths.
Authors: We will expand the Attention Analysis subsection with explicit quantitative metrics linking attention weights to residual-stream contributions at the prediction token. Additional analyses will be included to evaluate and address potential alternative flow paths (e.g., via other tokens or cross-layer mechanisms), thereby better supporting the distinction across model families. revision: yes
Circularity Check
No circularity: empirical probing results are independent of inputs
full rationale
The paper conducts an empirical interpretability study on VLMs using layer-wise linear probing and attention analysis to compare table vs. chart evidence. The central claim (information encoded in intermediate layers but not reaching the prediction position for charts) is derived directly from measured probe accuracies and attention weights across models and conditions. No equations, fitted parameters, or self-citations are used to define the result in terms of itself; the observations stand as external measurements rather than tautological redefinitions. This is a standard non-circular empirical analysis.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Linear probing at intermediate layers reveals information that is encoded and potentially usable by later layers
- domain assumption Attention weights indicate whether encoded information is routed to the final prediction position
Reference graph
Works this paper leans on
-
[1]
On the Perception Bottleneck of VLM s for Chart Understanding
Liu, Junteng and Zeng, Weihao and Zhang, Xiwen and Wang, Yijun and Shan, Zifei and He, Junxian. On the Perception Bottleneck of VLM s for Chart Understanding. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.573
-
[2]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Format Matters: The Robustness of Multimodal LLMs in Reviewing Evidence from Tables and Charts , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i37.40361 , number=
-
[3]
Table-Text Alignment: Explaining Claim Verification Against Tables in Scientific Papers
Ho, Xanh and Kumar, Sunisth and Wu, Yun-Ang and Boudin, Florian and Takasu, Atsuhiro and Aizawa, Akiko. Table-Text Alignment: Explaining Claim Verification Against Tables in Scientific Papers. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.135
-
[4]
Probing the Probing Paradigm: Does Probing Accuracy Entail Task Relevance?
Ravichander, Abhilasha and Belinkov, Yonatan and Hovy, Eduard. Probing the Probing Paradigm: Does Probing Accuracy Entail Task Relevance?. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.295
-
[5]
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations , url =
Orgad, Hadas and Toker, Michael and Gekhman, Zorik and Reichart, Roi and Szpektor, Idan and Kotek, Hadas and Belinkov, Yonatan , booktitle =. LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations , url =
-
[6]
Inside-Out: Hidden Factual Knowledge in
Zorik Gekhman and Eyal Ben-David and Hadas Orgad and Eran Ofek and Yonatan Belinkov and Idan Szpektor and Jonathan Herzig and Roi Reichart , booktitle=. Inside-Out: Hidden Factual Knowledge in. 2025 , url=
2025
-
[7]
2026 , eprint=
Responses Fall Short of Understanding: Revealing the Gap between Internal Representations and Responses in Visual Document Understanding , author=. 2026 , eprint=
2026
-
[8]
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pp
Wadden, David and Lin, Shanchuan and Lo, Kyle and Wang, Lucy Lu and van Zuylen, Madeleine and Cohan, Arman and Hajishirzi, Hannaneh. Fact or Fiction: Verifying Scientific Claims. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.609
-
[9]
Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026) , month =
SciClaimEval: Cross-modal Claim Verification in Scientific Papers , author =. Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026) , month =. 2026 , pages =
2026
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Zhang, Zhi and Yadav, Srishti and Han, Fengze and Shutova, Ekaterina , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[11]
Proceedings of the 42nd International Conference on Machine Learning , articleno =
Skean, Oscar and Arefin, Md Rifat and Zhao, Dan and Patel, Niket and Naghiyev, Jalal and LeCun, Yann and Shwartz-Ziv, Ravid , title =. Proceedings of the 42nd International Conference on Machine Learning , articleno =. 2025 , publisher =
2025
-
[12]
Belinkov, Yonatan. Probing Classifiers: Promises, Shortcomings, and Advances. Computational Linguistics. 2022. doi:10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[13]
FEVER: a large-scale dataset for Fact Extraction and VERification
Thorne, James and Vlachos, Andreas and Christodoulopoulos, Christos and Mittal, Arpit. FEVER : a Large-scale Dataset for Fact Extraction and VER ification. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1074
work page internal anchor Pith review doi:10.18653/v1/n18-1074 2018
-
[14]
Lu, Xinyuan and Pan, Liangming and Liu, Qian and Nakov, Preslav and Kan, Min-Yen. SCITAB : A Challenging Benchmark for Compositional Reasoning and Claim Verification on Scientific Tables. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.483
-
[15]
M u S ci C laims: Multimodal Scientific Claim Verification
Lal, Yash Kumar and Bandham, Manikanta and Hasan, Mohammad Saqib and Kashi, Apoorva and Koupaee, Mahnaz and Balasubramanian, Niranjan. M u S ci C laims: Multimodal Scientific Claim Verification. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Co...
-
[16]
S ci V er: Evaluating Foundation Models for Multimodal Scientific Claim Verification
Wang, Chengye and Shen, Yifei and Kuang, Zexi and Cohan, Arman and Zhao, Yilun. S ci V er: Evaluating Foundation Models for Multimodal Scientific Claim Verification. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.420
-
[17]
C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Masry, Ahmed and Long, Do Xuan and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul. C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.177
-
[18]
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs , url =
Wang, Zirui and Xia, Mengzhou and He, Luxi and Chen, Howard and Liu, Yitao and Zhu, Richard and Liang, Kaiqu and Wu, Xindi and Liu, Haotian and Malladi, Sadhika and Chevalier, Alexis and Arora, Sanjeev and Chen, Danqi , booktitle =. CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs , url =. doi:10.52202/079017-3609 , editor =
-
[19]
Probing the Visualization Literacy of Vision Language Models: The Good, the Bad, and the Ugly , year=
Dong, Lianghan and Crisan, Anamaria , journal=. Probing the Visualization Literacy of Vision Language Models: The Good, the Bad, and the Ugly , year=
-
[20]
2025 , eprint=
Seeing but Not Believing: Probing the Disconnect Between Visual Attention and Answer Correctness in VLMs , author=. 2025 , eprint=
2025
-
[21]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , month =
Esmaeilkhani, Parsa and Latecki, Longin Jan , title =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , month =. 2026 , pages =
2026
-
[22]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models , author=. 2025 , eprint=
2025
-
[24]
Note on the sampling error of the difference between correlated proportions or percentages , author =. Psychometrika , volume =. 1947 , publisher =. doi:10.1007/BF02295996 , url =
-
[25]
and Varoquaux, G
Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E. , journal=. Scikit-learn: Machine Learning in
-
[26]
Transformers: State-of-the-Art Natural Language Processing
Thomas Wolf, et al. Transformers: State-of-the-Art Natural Language Processing. Proceedings of the 2020 Conference on EMNLP: System Demonstrations. 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.