RCEM: Robust Conversational Search EMbedder in Distributional Shift
Pith reviewed 2026-06-28 15:08 UTC · model grok-4.3
The pith
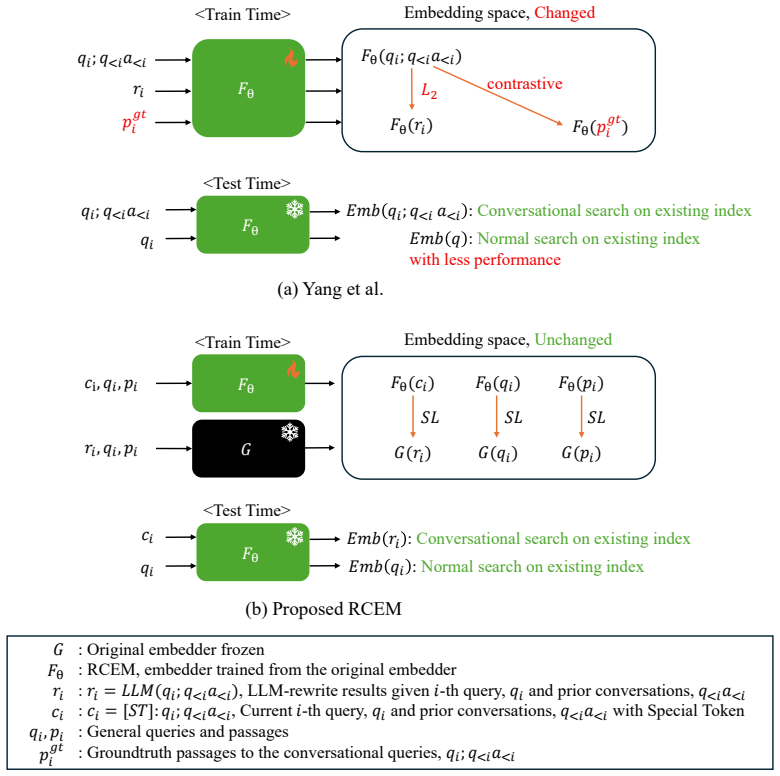
RCEM aligns conversations prepended with a special token to LLM-rewritten queries while preserving the original embedding space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
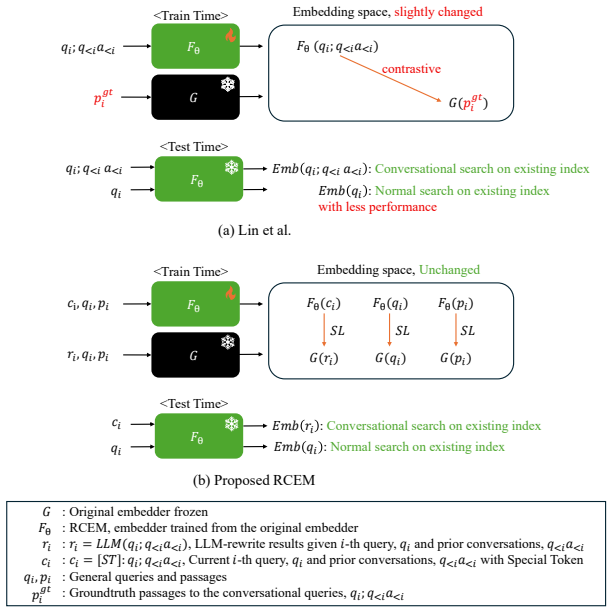
RCEM equips a conversational search embedder with LLM query reformulation capability by aligning conversations prepended by a special token to LLM-rewritten queries while preserving the original embedding space. The unchanged space automatically maps the rewritten queries to the relevant passages, which reduces overfitting by simplifying alignment from long passages to shorter queries, eliminates the need for conversation-to-passage relevance labels, and maintains compatibility with indexes built by the original embedder.
What carries the argument
Alignment of special-token-prepended conversations to LLM-rewritten queries that leaves the base embedding space unchanged so rewritten queries inherit the original passage mappings.
If this is right
- RCEM reduces overfitting by simplifying the alignment task from long passages to shorter rewritten queries.
- RCEM eliminates the need for conversation-to-passage relevance labels during training.
- RCEM maintains the original embedding space, allowing conversational queries against indexes built by the original embedder without rebuilding them.
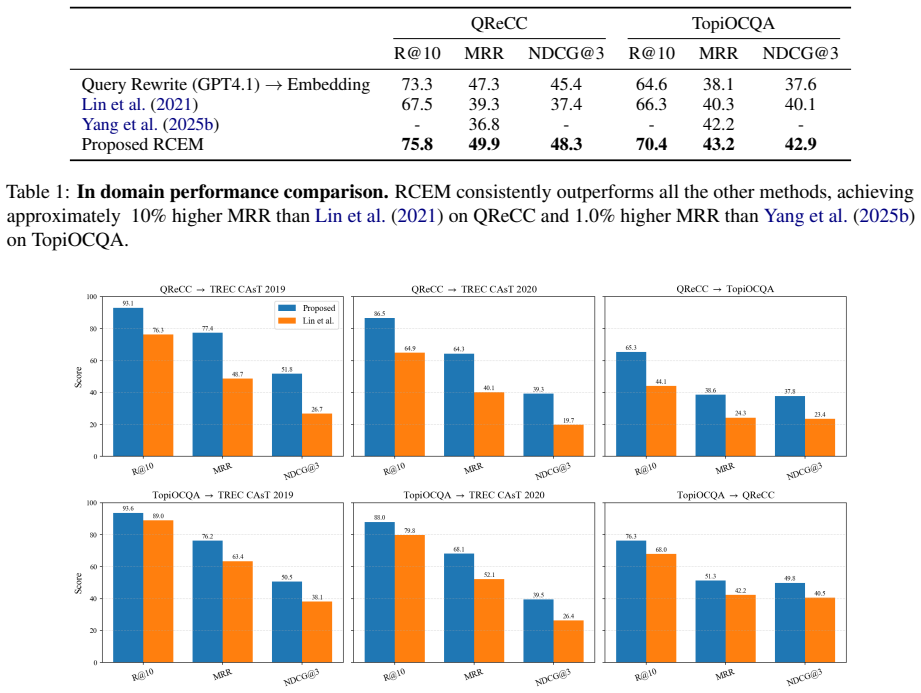
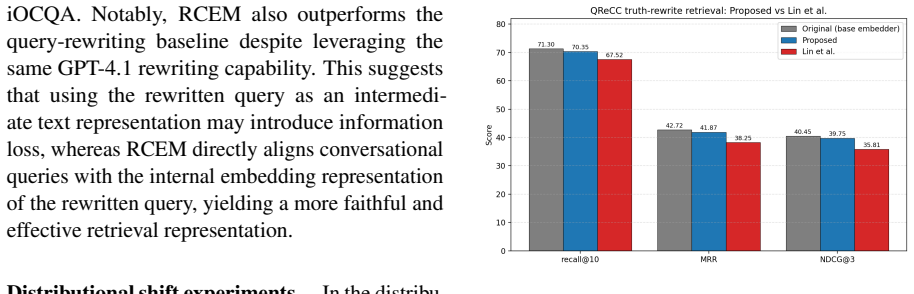
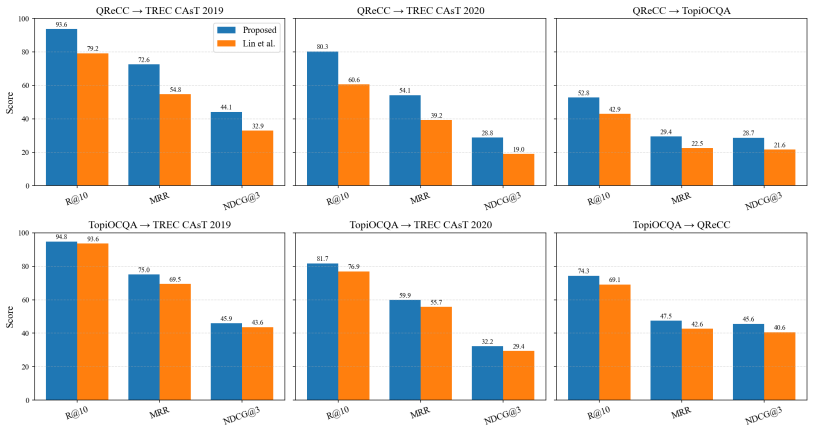
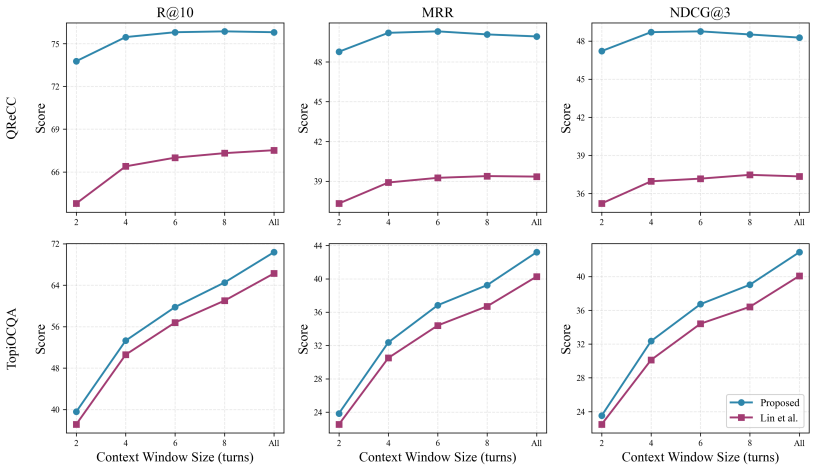
- RCEM delivers up to 30 percent improvement over prior approaches under distributional shift.
Where Pith is reading between the lines
- The same alignment trick could be tested on non-conversational retrieval where query rewriting is known to help.
- Performance may vary with the quality or style of the LLM chosen to generate the rewritten queries.
- Extending the approach to longer multi-turn histories would require checking whether the single special token still suffices.
Load-bearing premise
Training the embedder to map conversations with a special token to LLM-rewritten queries will cause the preserved embedding space to map those queries to the correct passages without losing the base model's generalization.
What would settle it
An experiment that measures retrieval accuracy under distributional shift and finds RCEM no better than baselines that directly match conversations to passages, or that finds the special-token mapping alters passage rankings for the rewritten queries.
Figures

read the original abstract
We propose RCEM, a Robust Conversational search EMbedder that is additionally equipped with LLM's query reformulation capability without losing base model's generalization. Unlike prior conversational dense retrieval approaches that learn direct conversation-to-passage matching, RCEM aligns conversations, prepended by special token, to LLM-rewritten queries, while preserving the original embedding space. The unchanged embedding space automatically maps the rewritten-query to the relevant passages. As a result, RCEM (1) reduces overfitting by simplifying the alignment task from long passages to shorter rewritten queries, (2) eliminates the need for conversation-to-passage relevance labels for training, and (3) maintains its original embedding space that allows conversational queries against indexes built by original embedder without rebuilding them. Extensive experiments show that RCEM consistently outperforms prior approaches, achieving up to 30% improvement under distributional shift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RCEM, a conversational dense retriever that prepends a special token to conversations and aligns their embeddings to those of LLM-rewritten queries rather than directly to passages. It claims this alignment, performed while preserving the original embedding space, allows the unchanged space to automatically map rewritten queries to relevant passages. The method is presented as reducing overfitting, removing the need for conversation-to-passage labels, and enabling use with indexes built by the base embedder. Experiments are said to demonstrate consistent gains, including up to 30% improvement under distributional shift.
Significance. If the embedding-space preservation holds and the reported gains prove robust across datasets and shifts, the approach could simplify training for conversational retrieval and improve generalization without requiring new relevance labels or index rebuilds. The three listed benefits address practical pain points in the field, but their value depends on whether the core assumption about unchanged rewritten-query representations survives training.
major comments (2)
- [Abstract] Abstract: The central claim that the embedding space remains 'preserved' and 'unchanged' so that LLM-rewritten queries continue to map to their original passages is load-bearing, yet the abstract provides no mechanism (freezing of parameters, regularization term, partial updates, or loss design) to enforce this during alignment training. Without such a mechanism, gradient updates on the conversation-to-rewritten-query objective can alter E(rewritten_query) representations, directly undermining the automatic mapping to passages under distributional shift.
- [Abstract] Abstract: The reported 'up to 30% improvement under distributional shift' is presented without reference to specific datasets, baselines, controls for post-hoc hyperparameter choices, or error analysis; this absence prevents verification that the gains arise from the claimed alignment rather than from the LLM rewriting step or other unstated factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract point by point below. Both concerns are valid regarding clarity, and we will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the embedding space remains 'preserved' and 'unchanged' so that LLM-rewritten queries continue to map to their original passages is load-bearing, yet the abstract provides no mechanism (freezing of parameters, regularization term, partial updates, or loss design) to enforce this during alignment training. Without such a mechanism, gradient updates on the conversation-to-rewritten-query objective can alter E(rewritten_query) representations, directly undermining the automatic mapping to passages under distributional shift.
Authors: We agree the abstract should indicate the mechanism. The full manuscript (Section 3) specifies that preservation is achieved via a contrastive alignment loss applied only to conversation embeddings (with the special token) while LLM-rewritten query embeddings are computed from the frozen base embedder without gradient flow through them. We will add a concise clause to the abstract referencing this design to make the preservation claim self-contained. revision: yes
-
Referee: [Abstract] Abstract: The reported 'up to 30% improvement under distributional shift' is presented without reference to specific datasets, baselines, controls for post-hoc hyperparameter choices, or error analysis; this absence prevents verification that the gains arise from the claimed alignment rather than from the LLM rewriting step or other unstated factors.
Authors: The 30% figure summarizes results from Section 4 experiments across multiple datasets and distributional shifts, with explicit baselines, hyperparameter controls, and comparisons isolating the alignment contribution versus LLM rewriting alone. The abstract's brevity precludes full details, but we will revise it to name the primary shift setting and note that full controls appear in the experiments. revision: yes
Circularity Check
No circularity: derivation relies on external LLM rewriting and empirical preservation claim without self-referential reduction
full rationale
The paper's core procedure (aligning [special-token + conversation] embeddings to LLM-rewritten query embeddings while claiming the original space is preserved) is presented as a training objective whose success is evaluated externally via retrieval metrics under distributional shift. No equations, fitted parameters, or self-citations are shown that define the claimed improvement or the 'automatic mapping' property in terms of the method's own inputs. The preservation of the embedding space is an explicit modeling assumption rather than a derived result that reduces to the alignment loss by construction. No load-bearing uniqueness theorems or ansatzes imported from prior self-work appear in the provided text. This is the common case of a self-contained empirical method whose validity rests on external benchmarks rather than definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Proceedings of TREC , year=
Cast 2019: The conversational assistance track overview , author=. In Proceedings of TREC , year=
2019
-
[2]
In Proceedings of TREC , year=
Cast 2020: The conversational assistance track overview , author=. In Proceedings of TREC , year=
2020
-
[3]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[4]
Advances in neural information processing systems , volume=
Self-normalizing neural networks , author=. Advances in neural information processing systems , volume=
-
[5]
The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval , pages=
Pytrec\_eval: An extremely fast python interface to trec\_eval , author=. The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval , pages=
-
[6]
2023 , publisher=
Neural approaches to conversational information retrieval , author=. 2023 , publisher=
2023
-
[7]
2024 , howpublished =
Unsloth: Fast and Memory-Efficient Fine-Tuning for Large Language Models , author =. 2024 , howpublished =
2024
-
[8]
Lai, Yilong and Wu, Jialong and Wang, Zhenglin and Zhou, Deyu. A da R ewriter: Unleashing the Power of Prompting-based Conversational Query Reformulation via Test-Time Adaptation. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.193
-
[9]
T opi OCQA : Open-domain Conversational Question Answering with Topic Switching
Adlakha, Vaibhav and Dhuliawala, Shehzaad and Suleman, Kaheer and de Vries, Harm and Reddy, Siva. T opi OCQA : Open-domain Conversational Question Answering with Topic Switching. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00471
-
[10]
Open-Domain Question Answering Goes Conversational via Question Rewriting
Anantha, Raviteja and Vakulenko, Svitlana and Tu, Zhucheng and Longpre, Shayne and Pulman, Stephen and Chappidi, Srinivas. Open-Domain Question Answering Goes Conversational via Question Rewriting. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18...
-
[11]
Learning Contextual Retrieval for Robust Conversational Search
Yang, Seunghan and Lee, Juntae and Bang, Jihwan and Shim, Kyuhong and Kim, Minsoo and Chang, Simyung. Learning Contextual Retrieval for Robust Conversational Search. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.602
-
[12]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , year =
Contextualized Query Embeddings for Conversational Search , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , year =
2021
-
[13]
Findings of the Association for Computational Linguistics: ACL 2024 , year =
History-Aware Conversational Dense Retrieval , author =. Findings of the Association for Computational Linguistics: ACL 2024 , year =
2024
-
[14]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
ChatRetriever: Adapting Large Language Models for Generalized and Robust Conversational Dense Retrieval , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
2024
-
[15]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Interpreting Conversational Dense Retrieval by Rewriting-Enhanced Inversion of Session Embedding , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[16]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
Large Language Models Know Your Contextual Search Intent: A Prompting Framework for Conversational Search , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
2023
-
[17]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
Enhancing Conversational Search: Large Language Model-Aided Informative Query Rewriting , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
2023
-
[18]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
CHIQ: Contextual History Enhancement for Improving Query Rewriting in Conversational Search , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
2024
-
[19]
Proceedings of the 31st International Conference on Computational Linguistics , year =
AdaCQR: Enhancing Query Reformulation for Conversational Search via Sparse and Dense Retrieval Alignment , author =. Proceedings of the 31st International Conference on Computational Linguistics , year =
-
[20]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
ConvGQR: Generative Query Reformulation for Conversational Search , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[21]
Findings of the Association for Computational Linguistics: ACL 2023 , year =
Search-Oriented Conversational Query Editing , author =. Findings of the Association for Computational Linguistics: ACL 2023 , year =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.