EvoBrain: Continual Learning of EEG Foundation Models Across Heterogeneous BCI Tasks
Pith reviewed 2026-06-28 14:31 UTC · model grok-4.3
The pith
EvoBrain treats EEG model adaptation as continual learning so one foundation model can handle new BCI tasks without losing accuracy on earlier ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
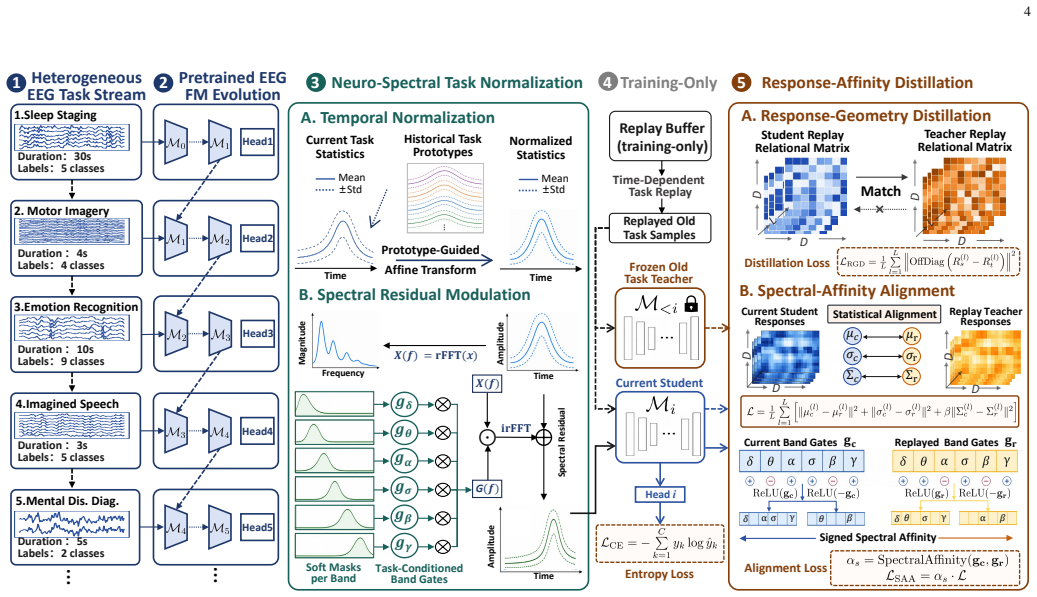
EvoBrain is a dynamic, task-aware continual learning framework for unified EEG decoding. It uses Neuro-Spectral Task Normalization to align incoming tasks with historical statistics and recalibrate spectral responses for distributional and neuro-spectral shifts, together with Response-Affinity Distillation and time-dependent replay to preserve old-task response geometry and enable selective knowledge transfer between spectrally compatible tasks, thereby mitigating forgetting while balancing plasticity and stability.
What carries the argument
Neuro-Spectral Task Normalization combined with Response-Affinity Distillation and time-dependent replay, which align spectral statistics and transfer response geometry selectively across tasks.
If this is right
- Storage and compute costs no longer scale linearly with the number of BCI tasks.
- A single foundation model can improve on new tasks while retaining performance on prior ones.
- Knowledge transfers selectively only between tasks whose spectral properties are compatible.
- The plasticity-stability trade-off is managed without task-specific architectural changes.
- Cross-task continual learning becomes feasible for EEG foundation models.
Where Pith is reading between the lines
- The same alignment and distillation steps might apply to other time-series biosignals if their spectral structure permits similar normalization.
- Clinical BCI systems could move from per-task retraining to incremental model updates in deployed settings.
- Testing the method on tasks with deliberately mismatched spectra would reveal the boundary of selective transfer.
- Real-time adaptation in variable user states could become practical if the replay buffer stays small.
Load-bearing premise
New tasks will show distributional and neuro-spectral shifts that can be aligned to historical data via normalization and that response affinity will allow useful transfer only between compatible tasks without interference.
What would settle it
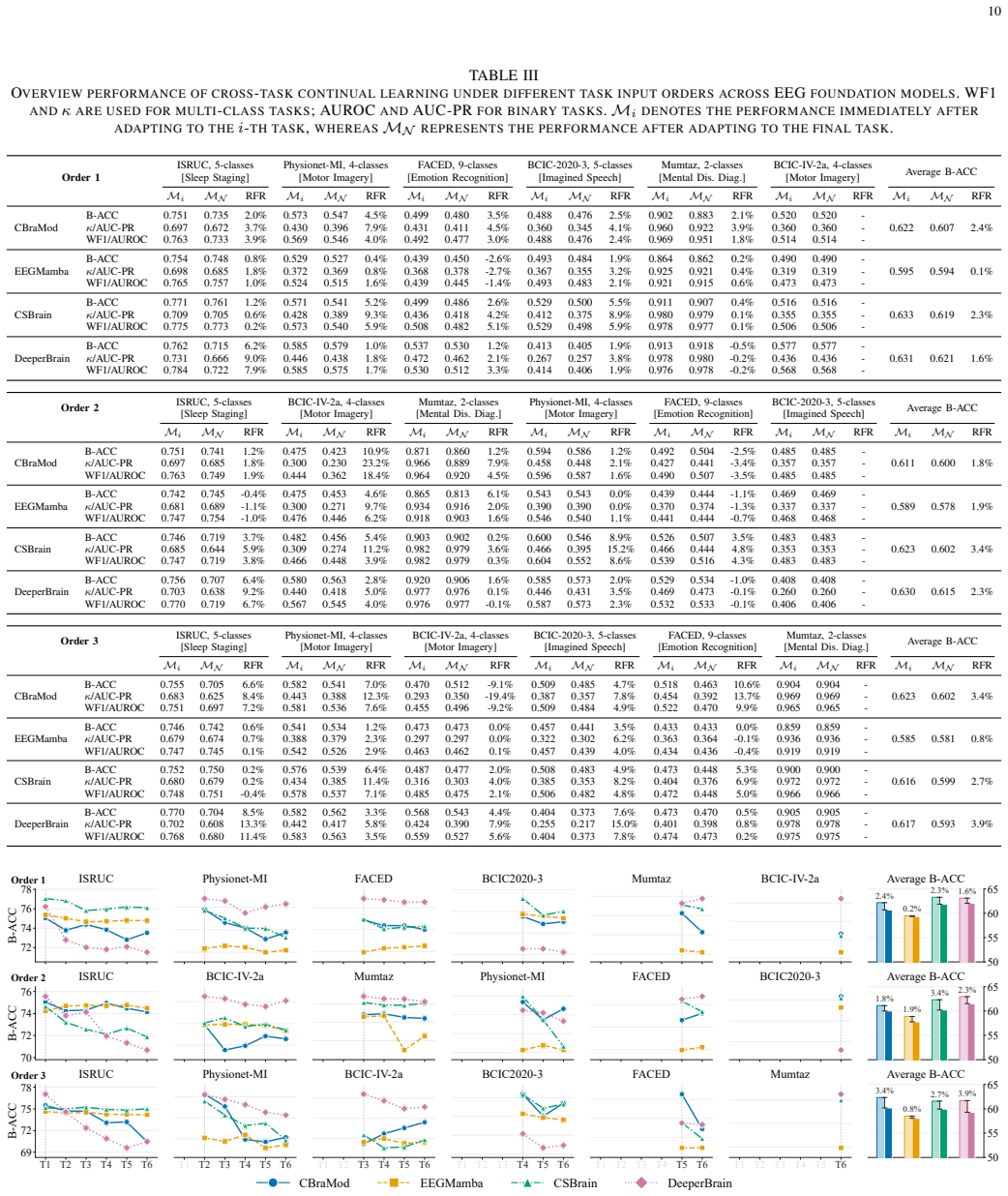
Run EvoBrain on a sequence of six BCI tasks and measure whether accuracy on the first task falls below the level achieved by isolated fine-tuning of the same backbone.
Figures

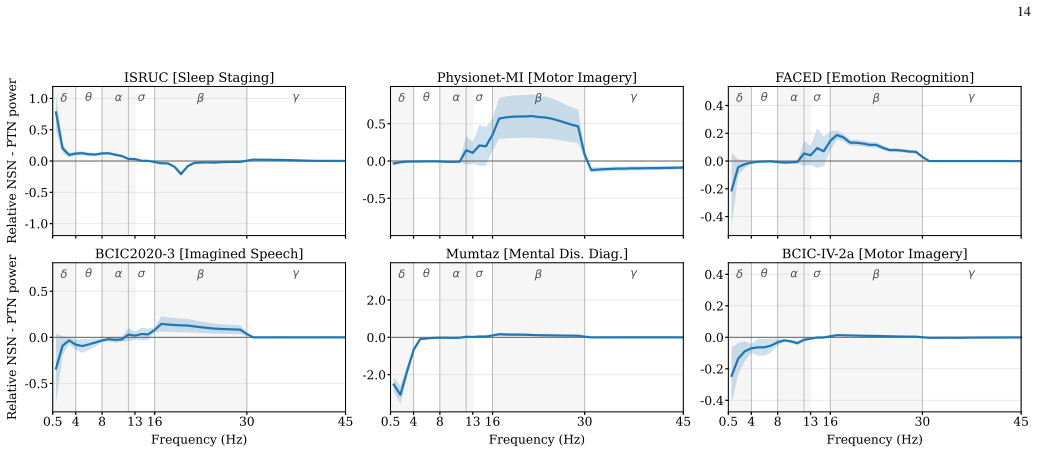
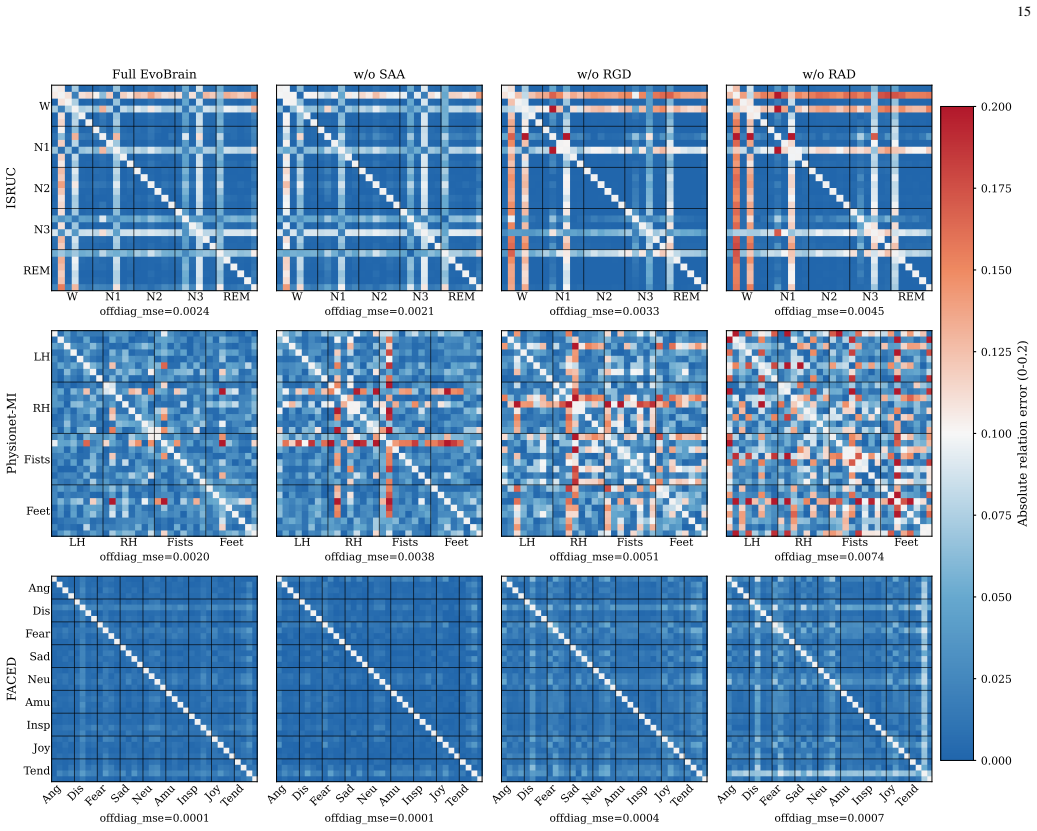
read the original abstract
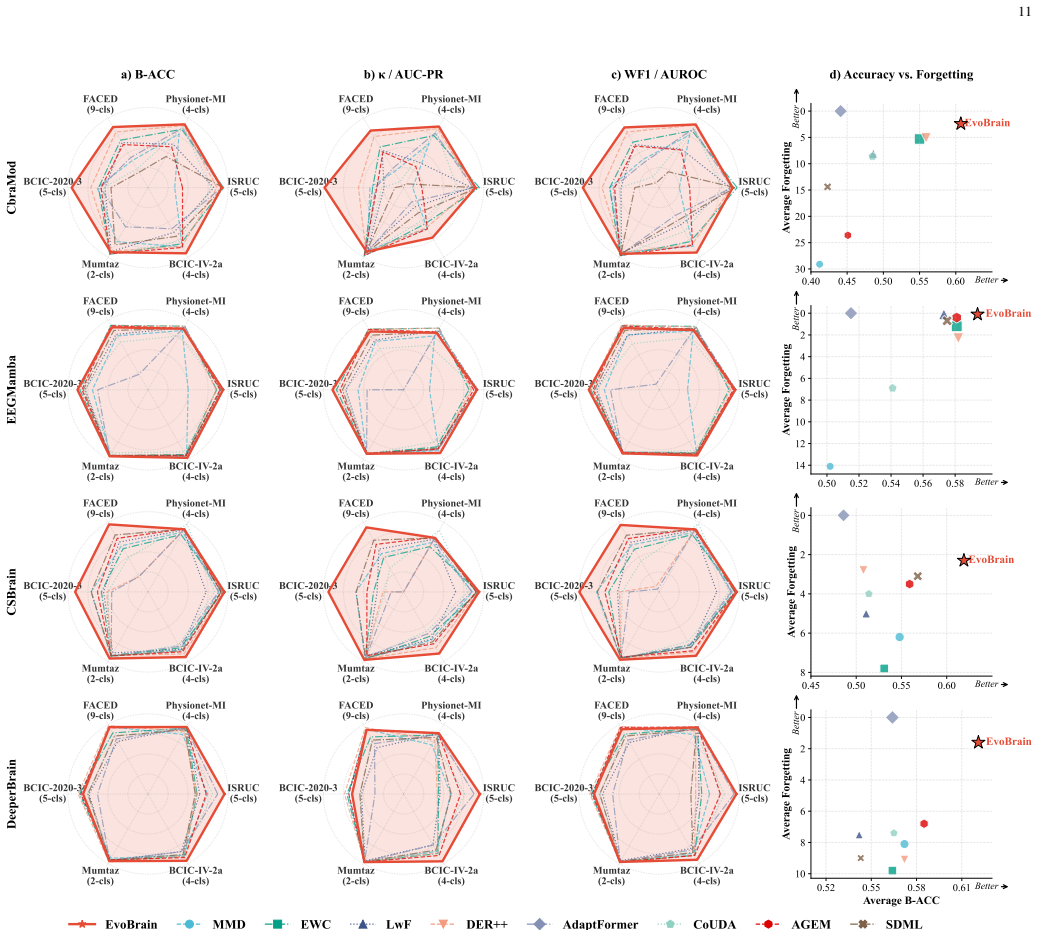
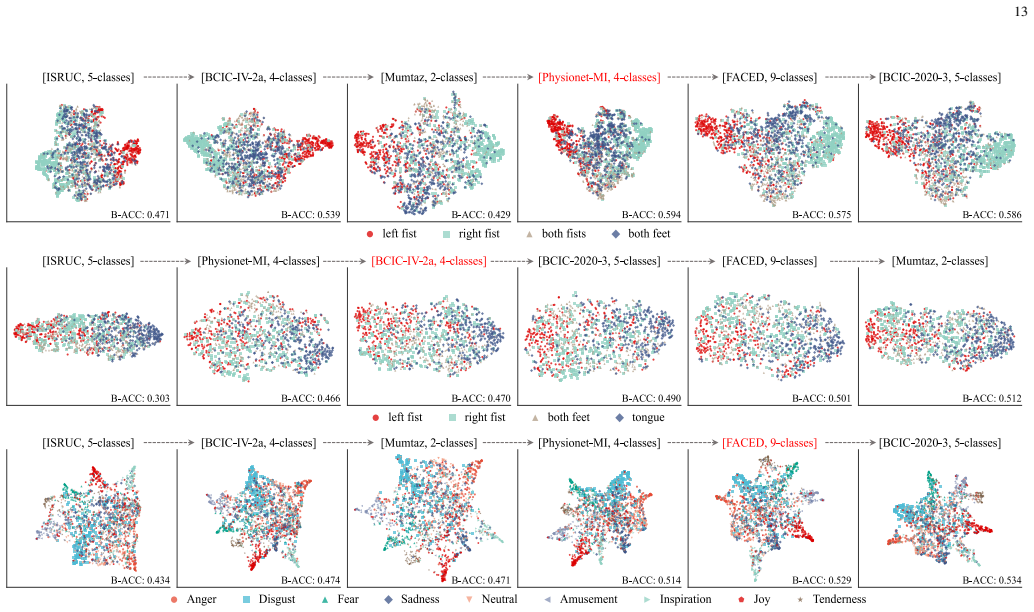
Electroencephalography (EEG) is the cornerstone of non-invasive brain-computer interfaces (BCIs), yet conventional decoding relies on fragmented, task-specific architectures that severely limit cross-task scalability. While EEG foundation models pre-trained on massive corpora promise universal brain decoding, current post-training depends on task-isolated fine-tuning. This static paradigm restricts knowledge transfer across heterogeneous tasks, hinders model scalability, and incurs computational and storage overheads that scale linearly with task count. To overcome these bottlenecks, we formulate downstream adaptation as a cross-task continual learning problem and propose EvoBrain, a dynamic, task-aware continual learning framework for unified EEG decoding. EvoBrain addresses the plasticity-stability trade-off via two complementary components: (1) Neuro-Spectral Task Normalization (NSN) aligns incoming tasks with historical statistics while recalibrating spectral responses to handle distributional and neuro-spectral shifts; and (2) Response-Affinity Distillation (RAD), combined with time-dependent replay, preserves old-task response geometry and promotes selective knowledge transfer between spectrally compatible tasks, effectively mitigating forgetting. Extensive evaluations across six distinct BCI tasks demonstrate that EvoBrain consistently surpasses state-of-the-art methods across diverse foundation backbones, optimally balancing plasticity and stability. To our knowledge, this work pioneers cross-task continual learning in the EEG domain, advancing the realization of a unified, one-for-all brain decoding system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates downstream adaptation of EEG foundation models as a cross-task continual learning problem and introduces EvoBrain, which uses Neuro-Spectral Task Normalization (NSN) to align incoming tasks with historical statistics and recalibrate spectral responses, plus Response-Affinity Distillation (RAD) combined with time-dependent replay to preserve old-task response geometry and enable selective transfer between compatible tasks. It claims that extensive evaluations on six distinct BCI tasks show EvoBrain consistently outperforming SOTA methods across diverse foundation backbones while balancing plasticity and stability, positioning the work as the first to pioneer cross-task continual learning in the EEG domain.
Significance. If the empirical claims hold with rigorous controls, the work would be significant for enabling scalable, unified EEG decoding systems that avoid linear growth in compute and storage with task count. The domain-specific mechanisms (NSN and RAD) tailored to neuro-spectral shifts represent a targeted contribution to continual learning in BCI, with potential to reduce reliance on task-isolated fine-tuning.
major comments (2)
- [Abstract] Abstract: the central empirical claim that EvoBrain 'consistently surpasses state-of-the-art methods across diverse foundation backbones' is stated without any quantitative metrics, error bars, task-specific performance tables, or ablation results, which is load-bearing for assessing whether the plasticity-stability balance is actually achieved.
- [Methods (implied from abstract description of NSN and RAD)] The assumption that NSN and RAD together optimally balance plasticity and stability relies on the unverified premise that spectrally compatible tasks allow effective selective transfer; without explicit equations or pseudocode for RAD's affinity computation and replay scheduling in the methods section, it is unclear whether the approach avoids circularity in hyperparameter selection for the stability-plasticity trade-off.
minor comments (2)
- [Abstract] The abstract would benefit from a brief parenthetical note on the six tasks (e.g., motor imagery, P300, SSVEP) to allow readers to gauge heterogeneity.
- [Abstract] Clarify whether NSN is strictly parameter-free or introduces any learned components, as this affects the claim of reduced overhead.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive overall assessment. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that EvoBrain 'consistently surpasses state-of-the-art methods across diverse foundation backbones' is stated without any quantitative metrics, error bars, task-specific performance tables, or ablation results, which is load-bearing for assessing whether the plasticity-stability balance is actually achieved.
Authors: We agree that the abstract presents the empirical claim in qualitative terms. The full manuscript provides extensive quantitative support, including performance tables with means and standard deviations, error bars in figures, task-specific results, and ablation studies in the Experiments section. To strengthen the abstract, we will revise it to include representative quantitative highlights (e.g., average accuracy gains across the six tasks) while remaining within length constraints. revision: yes
-
Referee: [Methods (implied from abstract description of NSN and RAD)] The assumption that NSN and RAD together optimally balance plasticity and stability relies on the unverified premise that spectrally compatible tasks allow effective selective transfer; without explicit equations or pseudocode for RAD's affinity computation and replay scheduling in the methods section, it is unclear whether the approach avoids circularity in hyperparameter selection for the stability-plasticity trade-off.
Authors: The Methods section of the manuscript defines NSN via explicit spectral normalization equations that align task statistics and recalibrate responses. For RAD, affinity is computed as normalized cosine similarity between response vectors of old and new tasks to enable selective transfer, with the distillation loss weighted accordingly; time-dependent replay uses an exponential decay schedule based on task arrival order. These details are present, though we acknowledge that pseudocode would improve accessibility. We will add pseudocode for the affinity computation and replay scheduler in the revision to clarify the hyperparameter choices and avoid any perception of circularity. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper frames downstream adaptation as a cross-task continual learning problem and introduces two new mechanisms (NSN for alignment of distributional/neuro-spectral shifts and RAD plus replay for selective transfer). These are presented as algorithmic contributions whose effectiveness is assessed via empirical evaluation across six BCI tasks. No equations, derivations, or first-principles results are exhibited in the provided text that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claims rest on experimental outperformance rather than tautological mappings, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous BCI tasks exhibit distributional and neuro-spectral shifts that can be handled by normalization and selective distillation
invented entities (2)
-
Neuro-Spectral Task Normalization (NSN)
no independent evidence
-
Response-Affinity Distillation (RAD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cyborg intelligence: recent progress and future directions,
Z. Wu, Y . Zhou, Z. Shi, C. Zhang, G. Li, X. Zheng, N. Zheng, and G. Pan, “Cyborg intelligence: recent progress and future directions,” IEEE Intelligent Systems, vol. 31, no. 6, pp. 44–50, 2016
2016
-
[2]
Bci2000: a general-purpose brain-computer interface (bci) system,
G. Schalk, D. J. McFarland, T. Hinterberger, N. Birbaumer, and J. R. Wolpaw, “Bci2000: a general-purpose brain-computer interface (bci) system,”IEEE Transactions on biomedical engineering, vol. 51, no. 6, pp. 1034–1043, 2004
2004
-
[3]
Emotion recognition in human-computer interaction,
R. Cowie, E. Douglas-Cowie, N. Tsapatsoulis, G. V otsis, S. Kollias, W. Fellenz, and J. G. Taylor, “Emotion recognition in human-computer interaction,”IEEE Signal processing magazine, vol. 18, no. 1, pp. 32–80, 2001
2001
-
[4]
Eeg dynamics in patients with alzheimer’s disease,
J. Jeong, “Eeg dynamics in patients with alzheimer’s disease,”Clinical neurophysiology, vol. 115, no. 7, pp. 1490–1505, 2004
2004
-
[5]
Feature extraction and selection for emotion recognition from eeg,
R. Jenke, A. Peer, and M. Buss, “Feature extraction and selection for emotion recognition from eeg,”IEEE Transactions on Affective computing, vol. 5, no. 3, pp. 327–339, 2014
2014
-
[6]
A review of classification algorithms for eeg-based brain–computer interfaces,
F. Lotte, M. Congedo, A. L ´ecuyer, F. Lamarche, and B. Arnaldi, “A review of classification algorithms for eeg-based brain–computer interfaces,”Journal of neural engineering, vol. 4, no. 2, p. R1, 2007
2007
-
[7]
Personalized sleep staging leveraging source-free unsupervised domain adaptation,
Y . Zhou, S. Zhao, J. Wang, H. Jiang, S. Li, B. Luo, T. Li, and G. Pan, “Personalized sleep staging leveraging source-free unsupervised domain adaptation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 13, 2025, pp. 14 529–14 537
2025
-
[8]
Tsception: Capturing temporal dynamics and spatial asymmetry from eeg for emo- tion recognition,
Y . Ding, N. Robinson, S. Zhang, Q. Zeng, and C. Guan, “Tsception: Capturing temporal dynamics and spatial asymmetry from eeg for emo- tion recognition,”IEEE Transactions on Affective Computing, vol. 14, no. 3, pp. 2238–2250, 2022
2022
-
[9]
Deep learning techniques for classification of electroencephalogram (eeg) motor imagery (mi) signals: A review,
H. Altaheri, G. Muhammad, M. Alsulaiman, S. U. Amin, G. A. Altuwai- jri, W. Abdul, M. A. Bencherif, and M. Faisal, “Deep learning techniques for classification of electroencephalogram (eeg) motor imagery (mi) signals: A review,”Neural Computing and Applications, vol. 35, no. 20, pp. 14 681–14 722, 2023
2023
-
[10]
Bendr: Using transform- ers and a contrastive self-supervised learning task to learn from massive amounts of eeg data,
D. Kostas, S. Aroca-Ouellette, and F. Rudzicz, “Bendr: Using transform- ers and a contrastive self-supervised learning task to learn from massive amounts of eeg data,”Frontiers in Human Neuroscience, vol. 15, p. 653659, 2021
2021
-
[11]
Biot: Biosignal transformer for cross-data learning in the wild,
C. Yang, M. Westover, and J. Sun, “Biot: Biosignal transformer for cross-data learning in the wild,”Advances in Neural Information Pro- cessing Systems, vol. 36, pp. 78 240–78 260, 2023
2023
-
[12]
Brant: Foundation model for intracranial neural signal,
D. Zhang, Z. Yuan, Y . Yang, J. Chen, J. Wang, and Y . Li, “Brant: Foundation model for intracranial neural signal,”Advances in Neural Information Processing Systems, vol. 36, pp. 26 304–26 321, 2023
2023
-
[13]
W.-B. Jiang, L.-M. Zhao, and B.-L. Lu, “Large brain model for learning generic representations with tremendous eeg data in bci,”arXiv preprint arXiv:2405.18765, 2024
-
[14]
Eegpt: Pretrained transformer for universal and reliable representation of eeg signals,
G. Wang, W. Liu, Y . He, C. Xu, L. Ma, and H. Li, “Eegpt: Pretrained transformer for universal and reliable representation of eeg signals,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 39 249– 39 280, 2024
2024
-
[15]
Fome: A foundation model for eeg using adaptive temporal-lateral attention scaling,
E. Shi, K. Zhao, Q. Yuan, J. Wang, H. Hu, S. Yu, and S. Zhang, “Fome: A foundation model for eeg using adaptive temporal-lateral attention scaling,”arXiv preprint arXiv:2409.12454, 2024
-
[16]
W.-B. Jiang, Y . Wang, B.-L. Lu, and D. Li, “Neurolm: A universal multi- task foundation model for bridging the gap between language and eeg signals,”arXiv preprint arXiv:2409.00101, 2024
-
[17]
Cbramod: A criss-cross brain foundation model for eeg decoding.arXiv preprint arXiv:2412.07236, 2024
J. Wang, S. Zhao, Z. Luo, Y . Zhou, H. Jiang, S. Li, T. Li, and G. Pan, “Cbramod: A criss-cross brain foundation model for eeg decoding,” arXiv preprint arXiv:2412.07236, 2024
-
[18]
Eegmamba: An eeg foundation model with mamba,
J. Wang, S. Zhao, Z. Luo, Y . Zhou, S. Li, and G. Pan, “Eegmamba: An eeg foundation model with mamba,”Neural Networks, p. 107816, 2025
2025
-
[19]
Csbrain: A cross-scale spatiotemporal brain foundation model for eeg decoding,
Y . Zhou, J. Wu, Z. Ren, Z. Yao, W. Lu, K. Peng, Q. Zheng, C. Song, W. Ouyang, and C. Gou, “Csbrain: A cross-scale spatiotemporal brain foundation model for eeg decoding,”arXiv preprint arXiv:2506.23075, 2025
-
[20]
BrainPro: Towards Large-scale Brain State-aware EEG Representation Learning
Y . Ding, M. Jiang, W. Jiang, S. Zhang, X. Zhou, C. Liu, S. Li, Y . Li, and C. Guan, “Brainpro: Towards large-scale brain state-aware eeg representation learning,”arXiv preprint arXiv:2509.22050, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Uni-ntfm: A unified foundation model for eeg signal representation learning,
Z. Chen, Y . Zhang, Q. Lan, T. Liu, H. Wang, Y . Ding, Z. Jia, R. Chen, K. Wang, and X. Zhou, “Uni-ntfm: A unified foundation model for eeg signal representation learning,”arXiv preprint arXiv:2509.24222, 2025
-
[22]
Deeperbrain: A neuro-grounded eeg foundation model towards universal bci,
J. Wang, S. Zhao, Y . Zhou, Y . Kang, S. Li, and G. Pan, “Deeperbrain: A neuro-grounded eeg foundation model towards universal bci,” 2026
2026
-
[23]
Emergent Abilities of Large Language Models
J. Wei, Y . Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzleret al., “Emergent abilities of large language models,”arXiv preprint arXiv:2206.07682, 2022. 17
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Are emergent abilities of large language models a mirage?
R. Schaeffer, B. Miranda, and S. Koyejo, “Are emergent abilities of large language models a mirage?”Advances in neural information processing systems, vol. 36, pp. 55 565–55 581, 2023
2023
-
[25]
A comprehensive survey of continual learning: Theory, method and application,
L. Wang, X. Zhang, H. Su, and J. Zhu, “A comprehensive survey of continual learning: Theory, method and application,”IEEE transactions on pattern analysis and machine intelligence, vol. 46, no. 8, pp. 5362– 5383, 2024
2024
-
[26]
A survey of signal processing algorithms in brain–computer interfaces based on electrical brain signals,
A. Bashashati, M. Fatourechi, R. K. Ward, and G. E. Birch, “A survey of signal processing algorithms in brain–computer interfaces based on electrical brain signals,”Journal of Neural engineering, vol. 4, no. 2, p. R32, 2007
2007
-
[27]
Probabilistic common spatial patterns for multichannel eeg analysis,
W. Wu, Z. Chen, X. Gao, Y . Li, E. N. Brown, and S. Gao, “Probabilistic common spatial patterns for multichannel eeg analysis,”IEEE transac- tions on pattern analysis and machine intelligence, vol. 37, no. 3, pp. 639–653, 2014
2014
-
[28]
Linear discriminant analysis-a brief tutorial,
S. Balakrishnama and A. Ganapathiraju, “Linear discriminant analysis-a brief tutorial,”Institute for Signal and information Processing, vol. 18, no. 1998, pp. 1–8, 1998
1998
-
[29]
Sup- port vector machines,
M. A. Hearst, S. T. Dumais, E. Osuna, J. Platt, and B. Scholkopf, “Sup- port vector machines,”IEEE Intelligent Systems and their applications, vol. 13, no. 4, pp. 18–28, 1998
1998
-
[30]
Deep learning,
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,”nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[31]
Deep learning with convolutional neural networks for eeg decoding and visualization,
R. T. Schirrmeister, J. T. Springenberg, L. D. J. Fiederer, M. Glasstetter, K. Eggensperger, M. Tangermann, F. Hutter, W. Burgard, and T. Ball, “Deep learning with convolutional neural networks for eeg decoding and visualization,”Human brain mapping, vol. 38, no. 11, pp. 5391–5420, 2017
2017
-
[32]
Learning temporal information for brain-computer interface using convolutional neural networks,
S. Sakhavi, C. Guan, and S. Yan, “Learning temporal information for brain-computer interface using convolutional neural networks,”IEEE transactions on neural networks and learning systems, vol. 29, no. 11, pp. 5619–5629, 2018
2018
-
[33]
Lstm-based eeg classification in motor imagery tasks,
P. Wang, A. Jiang, X. Liu, J. Shang, and L. Zhang, “Lstm-based eeg classification in motor imagery tasks,”IEEE transactions on neural systems and rehabilitation engineering, vol. 26, no. 11, pp. 2086–2095, 2018
2086
-
[34]
A deep learning approach for automatic seizure detection in children with epilepsy,
A. Abdelhameed and M. Bayoumi, “A deep learning approach for automatic seizure detection in children with epilepsy,”Frontiers in Computational Neuroscience, vol. 15, p. 650050, 2021
2021
-
[35]
Transformer-based spatial-temporal feature learning for eeg decoding,
Y . Song, X. Jia, L. Yang, and L. Xie, “Transformer-based spatial-temporal feature learning for eeg decoding,”arXiv preprint arXiv:2106.11170, 2021
-
[36]
Eeg temporal–spatial transformer for person identification,
Y . Du, Y . Xu, X. Wang, L. Liu, and P. Ma, “Eeg temporal–spatial transformer for person identification,”Scientific Reports, vol. 12, no. 1, p. 14378, 2022
2022
-
[37]
Sleeptransformer: Automatic sleep staging with interpretability and un- certainty quantification,
H. Phan, K. Mikkelsen, O. Y . Ch´en, P. Koch, A. Mertins, and M. De V os, “Sleeptransformer: Automatic sleep staging with interpretability and un- certainty quantification,”IEEE Transactions on Biomedical Engineering, vol. 69, no. 8, pp. 2456–2467, 2022
2022
-
[38]
Eeg classification with transformer- based models,
J. Sun, J. Xie, and H. Zhou, “Eeg classification with transformer- based models,” in2021 ieee 3rd global conference on life sciences and technologies (lifetech). IEEE, 2021, pp. 92–93
2021
-
[39]
Eeg conformer: Convolutional transformer for eeg decoding and visualization,
Y . Song, Q. Zheng, B. Liu, and X. Gao, “Eeg conformer: Convolutional transformer for eeg decoding and visualization,”IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 31, pp. 710–719, 2022
2022
-
[40]
A transformer-based approach combining deep learning network and spatial-temporal information for raw eeg classification,
J. Xie, J. Zhang, J. Sun, Z. Ma, L. Qin, G. Li, H. Zhou, and Y . Zhan, “A transformer-based approach combining deep learning network and spatial-temporal information for raw eeg classification,”IEEE Transac- tions on Neural Systems and Rehabilitation Engineering, vol. 30, pp. 2126–2136, 2022
2022
-
[41]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[43]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 000–16 009
2022
-
[44]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[45]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[46]
A simple review of eeg foundation models: Datasets, advancements and future perspectives,
J. Lai, J. Wei, L. Yao, and Y . Wang, “A simple review of eeg foundation models: Datasets, advancements and future perspectives,”arXiv preprint arXiv:2504.20069, 2025
-
[47]
Eeg foundation models: A critical review of current progress and future directions,
G. Kuruppu, N. Wagh, and Y . Varatharajah, “Eeg foundation models: A critical review of current progress and future directions,”arXiv preprint arXiv:2507.11783, 2025
-
[48]
Eeg-fm-bench: A comprehensive benchmark for the systematic evaluation of eeg foundation models,
W. Xiong, J. Li, J. Li, and K. Zhu, “Eeg-fm-bench: A comprehensive benchmark for the systematic evaluation of eeg foundation models,” arXiv preprint arXiv:2508.17742, 2025
-
[49]
Brant-x: A unified physiological signal alignment framework,
D. Zhang, Z. Yuan, J. Chen, K. Chen, and Y . Yang, “Brant-x: A unified physiological signal alignment framework,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 4155–4166
2024
-
[50]
Eegformer: Towards transferable and interpretable large-scale eeg foun- dation model,
Y . Chen, K. Ren, K. Song, Y . Wang, Y . Wang, D. Li, and L. Qiu, “Eegformer: Towards transferable and interpretable large-scale eeg foun- dation model,”arXiv preprint arXiv:2401.10278, 2024
-
[51]
Neuro-gpt: Towards a foundation model for eeg,
W. Cui, W. Jeong, P. Th ¨olke, T. Medani, K. Jerbi, A. A. Joshi, and R. M. Leahy, “Neuro-gpt: Towards a foundation model for eeg,” in2024 IEEE International Symposium on Biomedical Imaging (ISBI). IEEE, 2024, pp. 1–5
2024
-
[52]
CodeBrain: Bridging Decoupled Tokenizer and Multi-Scale Architecture for EEG Foundation Model
J. Ma, F. Wu, Q. Lin, Y . Xing, C. Liu, Z. Jia, and M. Feng, “Code- brain: Bridging decoupled tokenizer and multi-scale architecture for eeg foundation model,”arXiv preprint arXiv:2506.09110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Comet: A contrastive-masked brain foundation model for universal eeg representation,
A. Li, Z. Wang, L. Yang, Z. Wang, T. Xu, H. Hu, and M. M. Van Hulle, “Comet: A contrastive-masked brain foundation model for universal eeg representation,”arXiv preprint arXiv:2509.00314, 2025
-
[54]
Mteeg: A multi-task learning framework for enhanced electroencephalography analysis using low-rank adaptation
S. Dai, K. Chen, H. Xiao, S. Yu, and Q. Ye, “Mteeg: A multi-task learning framework for enhanced electroencephalography analysis using low-rank adaptation.”
-
[55]
UniMind: Unleashing the Power of LLMs for Unified Multi-Task Brain Decoding
W. Lu, C. Song, J. Wu, P. Zhu, Y . Zhou, W. Mai, Q. Zheng, and W. Ouyang, “Unimind: Unleashing the power of llms for unified multi- task brain decoding,”arXiv preprint arXiv:2506.18962, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,”Pro- ceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[57]
Continual learning through synaptic intelligence,
F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” inInternational conference on machine learning. PMLR, 2017, pp. 3987–3995
2017
-
[58]
A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell, “Progressive neural networks,”arXiv preprint arXiv:1606.04671, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[59]
Packnet: Adding multiple tasks to a single network by iterative pruning,
A. Mallya and S. Lazebnik, “Packnet: Adding multiple tasks to a single network by iterative pruning,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 7765–7773
2018
-
[60]
icarl: Incremental classifier and representation learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 2001–2010
2017
-
[61]
End-to-end incremental learning,
F. M. Castro, M. J. Mar ´ın-Jim´enez, N. Guil, C. Schmid, and K. Alahari, “End-to-end incremental learning,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 233–248
2018
-
[62]
Replay with stochastic neural transformation for online continual eeg classifi- cation,
T. Duan, Z. Wang, G. Doretto, F. Li, C. Tao, and D. Adjeroh, “Replay with stochastic neural transformation for online continual eeg classifi- cation,” in2023 IEEE international conference on bioinformatics and biomedicine (BIBM). IEEE, 2023, pp. 1874–1879
2023
-
[63]
Resource-efficient continual learning for personalized online seizure detection,
A. Shahbazinia, F. Ponzina, J. A. Miranda, J. Dan, G. Ansaloni, and D. Atienza, “Resource-efficient continual learning for personalized online seizure detection,” in2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2024, pp. 1–7
2024
-
[64]
Affective eeg-based person identi- fication with continual learning,
J. Jin, Z. Chen, H. Cai, and J. Pan, “Affective eeg-based person identi- fication with continual learning,”IEEE Transactions on Instrumentation and Measurement, vol. 73, pp. 1–16, 2024
2024
-
[65]
Personalized continual eeg decoding: Retaining and transferring knowledge,
D. Li, H.-B. Shin, and K. Yin, “Personalized continual eeg decoding: Retaining and transferring knowledge,” in2025 13th International Conference on Brain-Computer Interface (BCI). IEEE, 2025, pp. 1–4
2025
-
[66]
Brainuicl: An unsupervised individual continual learning framework for eeg applications,
Y . Zhou, S. Zhao, J. Wang, H. Jiang, S. Li, T. Li, and G. Pan, “Brainuicl: An unsupervised individual continual learning framework for eeg applications,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[67]
Spiced: A synaptic homeostasis-inspired framework for un- 18 supervised continual eeg decoding,
——, “Spiced: A synaptic homeostasis-inspired framework for un- 18 supervised continual eeg decoding,”Advances in Neural Information Processing Systems, vol. 38, pp. 153 014–153 040, 2026
2026
-
[68]
A large finer-grained affective computing eeg dataset,
J. Chen, X. Wang, C. Huang, X. Hu, X. Shen, and D. Zhang, “A large finer-grained affective computing eeg dataset,”Scientific Data, vol. 10, no. 1, p. 740, 2023
2023
-
[69]
Bci competition 2008–graz data set a,
C. Brunner, R. Leeb, G. M ¨uller-Putz, A. Schl ¨ogl, and G. Pfurtscheller, “Bci competition 2008–graz data set a,”Institute for knowledge dis- covery (laboratory of brain-computer interfaces), Graz University of Technology, vol. 16, no. 1-6, p. 34, 2008
2008
-
[70]
Isruc-sleep: A comprehensive public dataset for sleep researchers,
S. Khalighi, T. Sousa, J. M. Santos, and U. Nunes, “Isruc-sleep: A comprehensive public dataset for sleep researchers,”Computer Methods and Programs in Biomedicine, vol. 124, pp. 180–192, 2016
2016
-
[71]
2020 international brain–computer interface competition: A review,
J.-H. Jeong, J.-H. Cho, Y .-E. Lee, S.-H. Lee, G.-H. Shin, Y .-S. Kweon, J. d. R. Mill ´an, K.-R. M ¨uller, and S.-W. Lee, “2020 international brain–computer interface competition: A review,”Frontiers in human neuroscience, vol. 16, p. 898300, 2022
2020
-
[72]
Electroencephalogram (eeg)-based computer-aided technique to diagnose major depressive disorder (mdd),
W. Mumtaz, L. Xia, S. S. A. Ali, M. A. M. Yasin, M. Hussain, and A. S. Malik, “Electroencephalogram (eeg)-based computer-aided technique to diagnose major depressive disorder (mdd),”Biomedical Signal Processing and Control, vol. 31, pp. 108–115, 2017
2017
-
[73]
Aasm scoring manual updates for 2017 (version 2.4),
R. B. Berry, R. Brooks, C. Gamaldo, S. M. Harding, R. M. Lloyd, S. F. Quan, M. T. Troester, and B. V . Vaughn, “Aasm scoring manual updates for 2017 (version 2.4),” pp. 665–666, 2017
2017
-
[74]
A kernel method for the two-sample-problem,
A. Gretton, K. Borgwardt, M. Rasch, B. Sch ¨olkopf, and A. Smola, “A kernel method for the two-sample-problem,”Advances in neural information processing systems, vol. 19, 2006
2006
-
[75]
Learning without forgetting,
Z. Li and D. Hoiem, “Learning without forgetting,”IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 2935– 2947, 2017
2017
-
[76]
Dark experience for general continual learning: a strong, simple baseline,
P. Buzzega, M. Boschini, A. Porrello, D. Abati, and S. Calderara, “Dark experience for general continual learning: a strong, simple baseline,” Advances in neural information processing systems, vol. 33, pp. 15 920– 15 930, 2020
2020
-
[77]
Efficient Lifelong Learning with A-GEM
A. Chaudhry, M. Ranzato, M. Rohrbach, and M. Elhoseiny, “Efficient lifelong learning with a-gem,”arXiv preprint arXiv:1812.00420, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[78]
Learning to learn and remember super long multi-domain task sequence,
Z. Wang, L. Shen, T. Duan, D. Zhan, L. Fang, and M. Gao, “Learning to learn and remember super long multi-domain task sequence,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 7982–7992
2022
-
[79]
Couda: Continual unsupervised domain adaptation for industrial fault diagnosis under dynamic working conditions,
B. Chen, X. Zhang, C. Shen, Q. Li, and Z. Song, “Couda: Continual unsupervised domain adaptation for industrial fault diagnosis under dynamic working conditions,”IEEE Transactions on Industrial Infor- matics, 2025
2025
-
[80]
Adaptformer: Adapting vision transformers for scalable visual recogni- tion,
S. Chen, C. Ge, Z. Tong, J. Wang, Y . Song, J. Wang, and P. Luo, “Adaptformer: Adapting vision transformers for scalable visual recogni- tion,”Advances in Neural Information Processing Systems, vol. 35, pp. 16 664–16 678, 2022. VIII. BIOGRAPHYSECTION Yangxuan Zhoureceived the B.S. degree in Elec- tronic Information from Shanghai University, Shang- hai, Ch...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.