PlatonicNav: Unveiling Semantic Correspondence in Navigation with Platonic Topological Maps
Pith reviewed 2026-06-28 15:33 UTC · model grok-4.3
The pith
A training-free topological map from self-supervised vision alone grounds language goals via blind matching, unifying object-goal and vision-language navigation as interfaces to one semantic manifold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
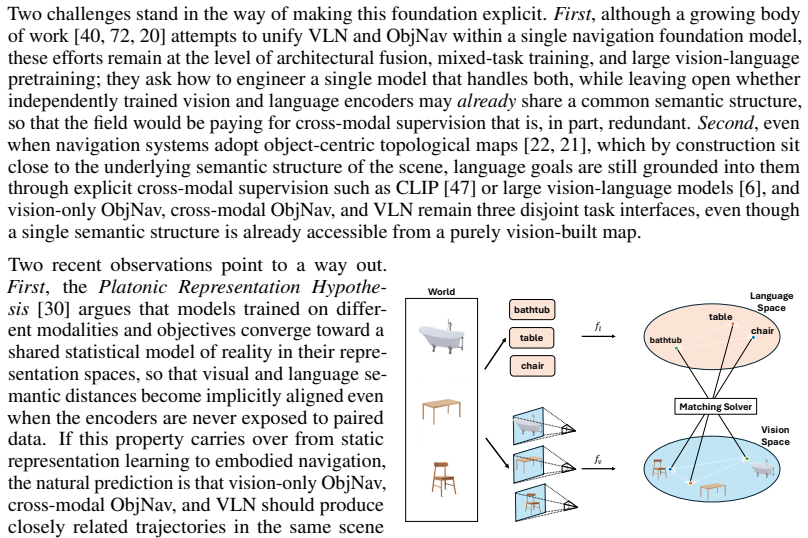
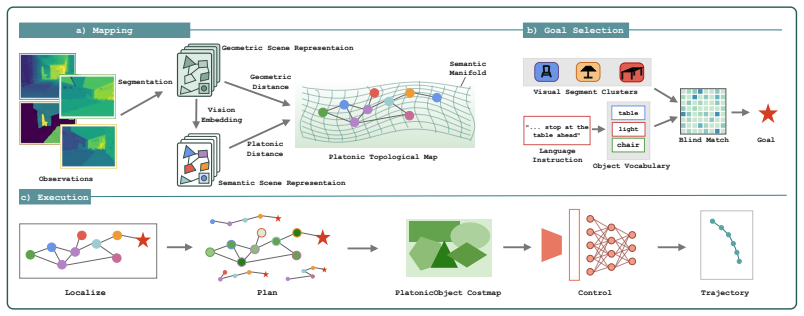
Extending the Platonic Representation Hypothesis to embodied navigation shows that vision-only ObjNav, cross-modal ObjNav, and VLN are three interfaces to the same object-centric semantic manifold. The Platonic Topological Map fuses geometric and semantic node distances from a self-supervised visual encoder and grounds language goals through blind matching without any paired vision-language data, allowing the same map to support all three tasks and to transfer to real robots without cross-modal training.
What carries the argument
The Platonic Topological Map, which fuses geometric and semantic node distances from a self-supervised visual encoder and performs blind matching to ground language goals.
If this is right
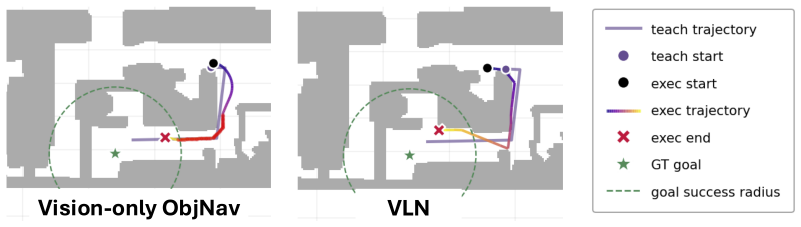
- The same map supports vision-only object goal navigation on HM3D-IIN and OVON without language input.
- The map also supports cross-modal object goal navigation and vision-language navigation on R2R-CE using the same blind matching step.
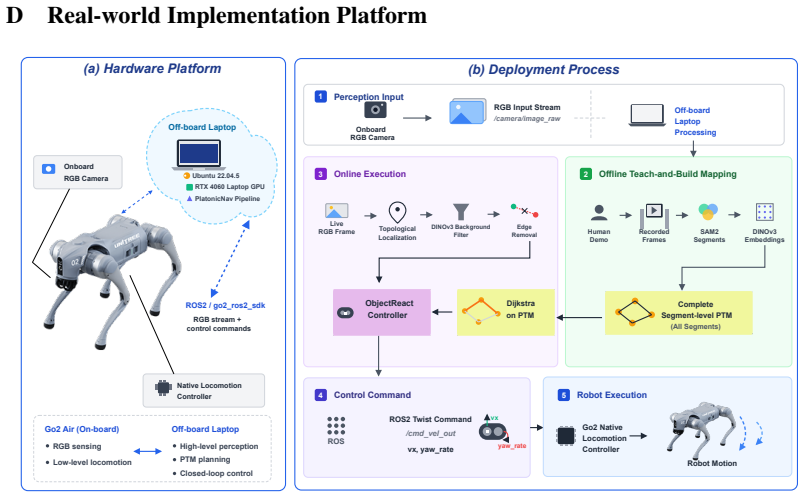
- The framework transfers directly to physical robots such as the Unitree Go2 without additional cross-modal training.
- No explicit supervision or paired data is required to switch between tasks or robot embodiments.
Where Pith is reading between the lines
- If the alignment is reliable, the same blind-matching approach could be tested on non-navigation tasks that require grounding language in visual scenes.
- Topological maps built this way might reduce dependence on large vision-language models for other embodied problems.
- The method invites direct comparison of success rates when the visual encoder is swapped for alternatives that lack semantic structure.
- Success on multiple benchmarks suggests the manifold view may extend to additional sensory modalities beyond vision and language.
Load-bearing premise
A self-supervised visual encoder already produces features whose semantic structure aligns with language closely enough for blind matching to map nodes to succeed without any paired vision-language data.
What would settle it
Apply the blind matching procedure on R2R-CE or OVON language goals against vision-built maps and measure success rate; if the rate equals or falls below random node selection, the claim that the alignment supports reliable navigation collapses.
Figures


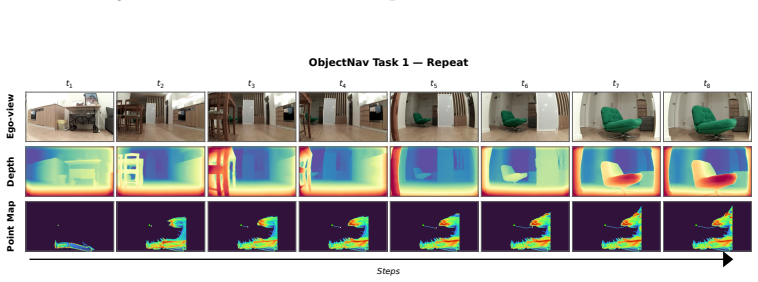
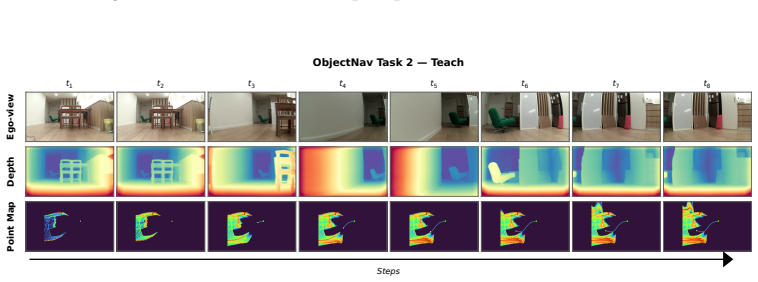
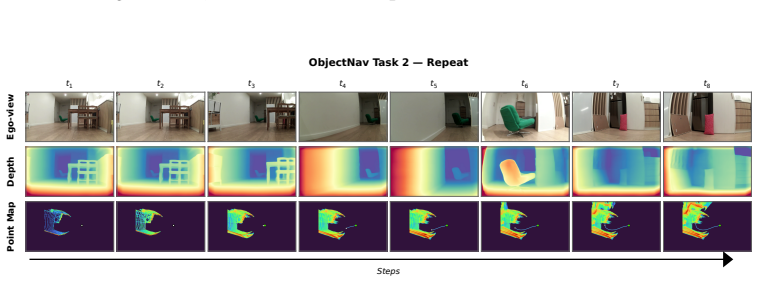
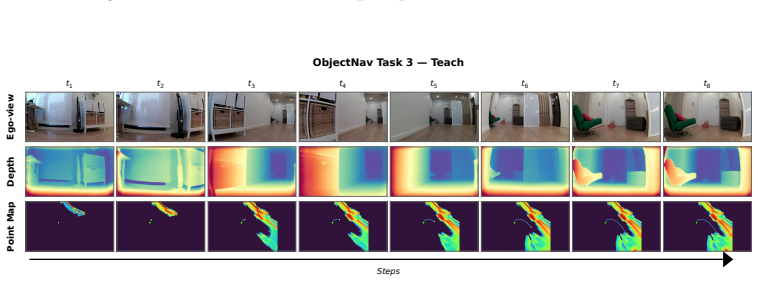
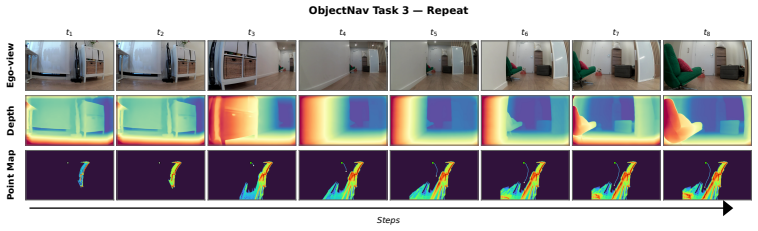
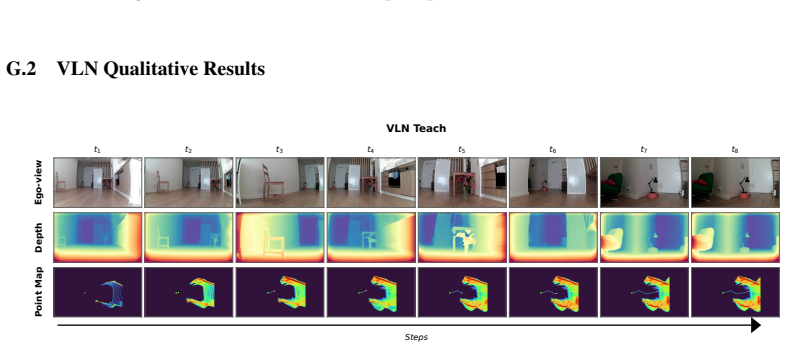
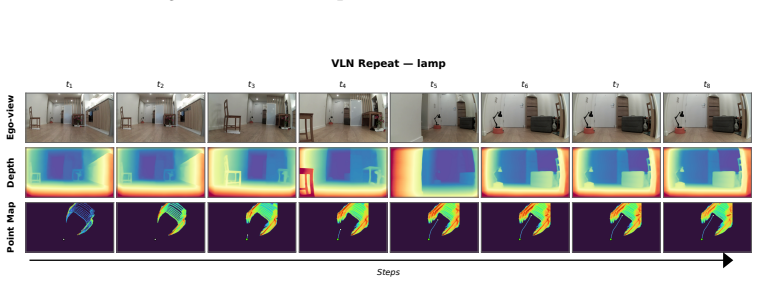
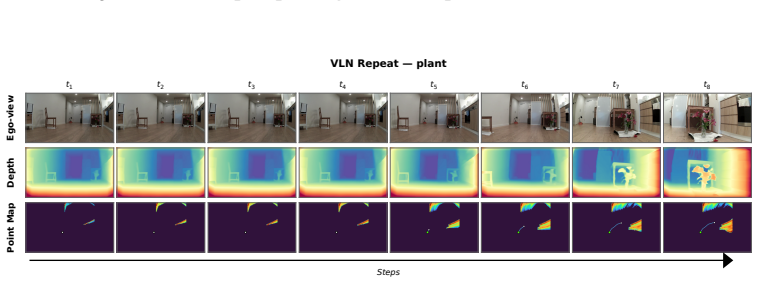
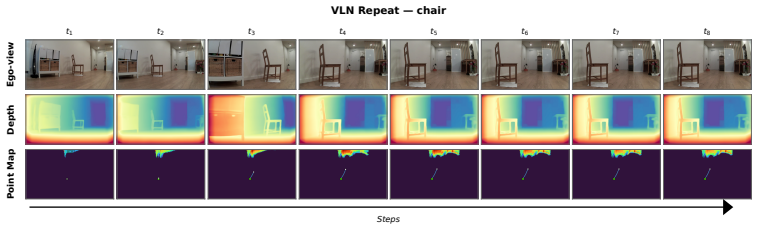
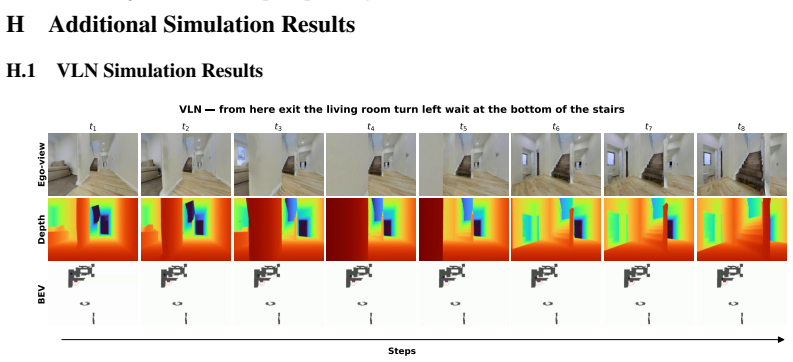
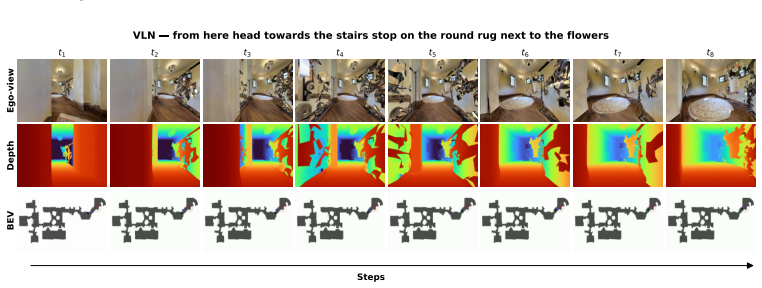
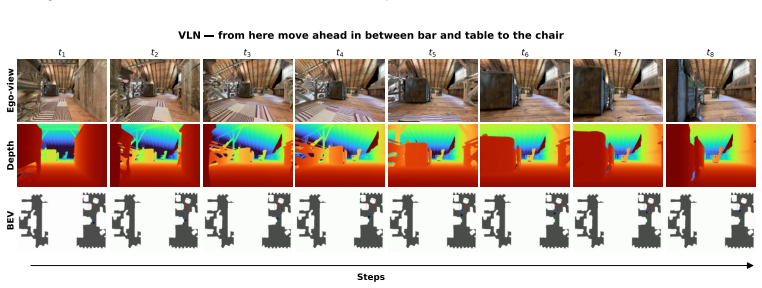

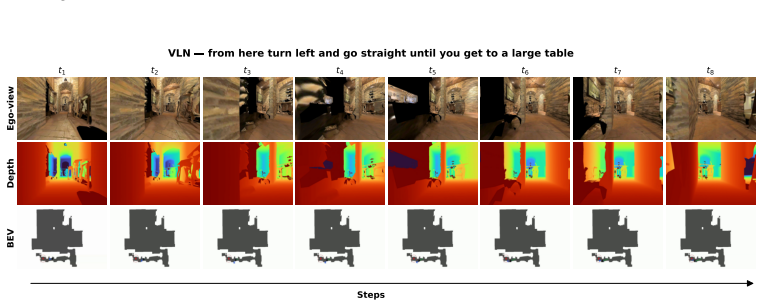
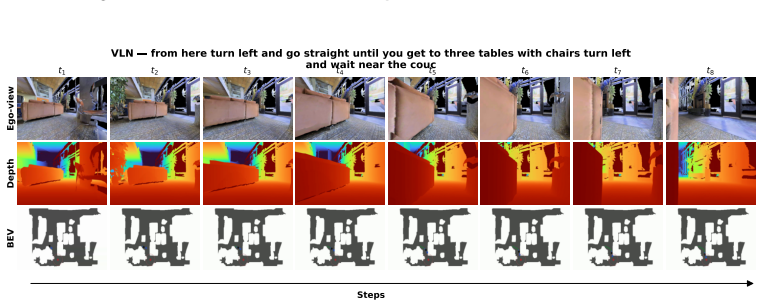

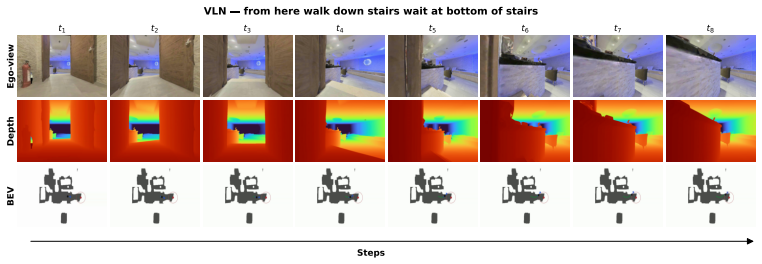
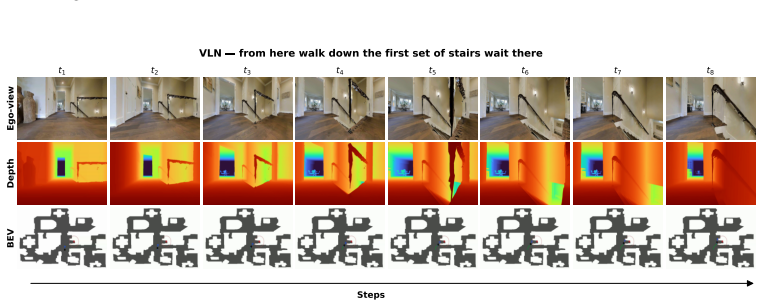
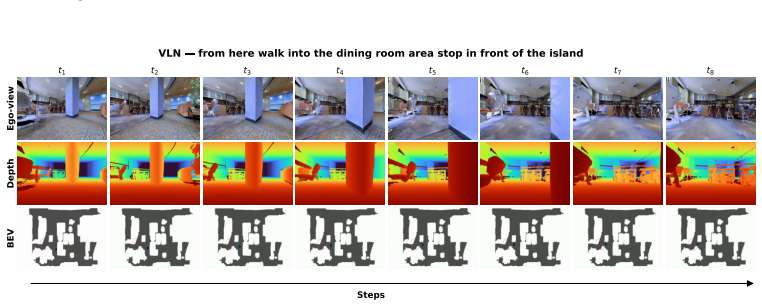
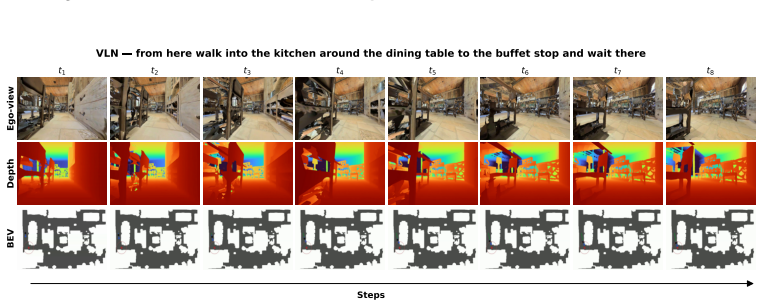
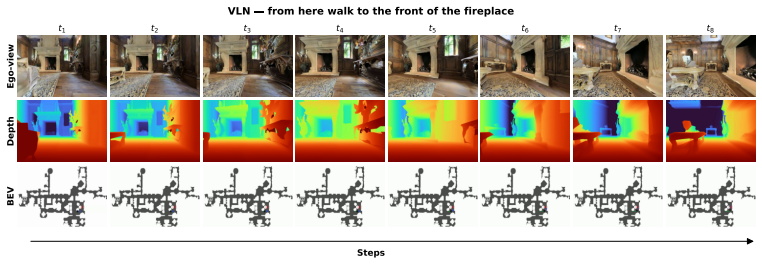
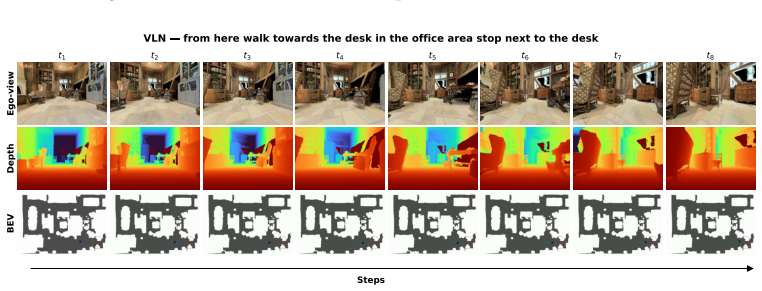
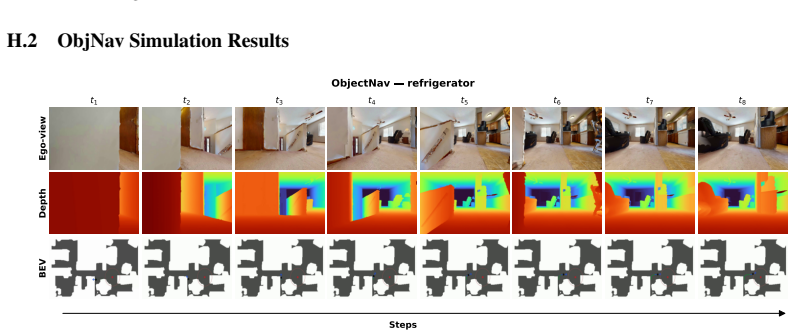
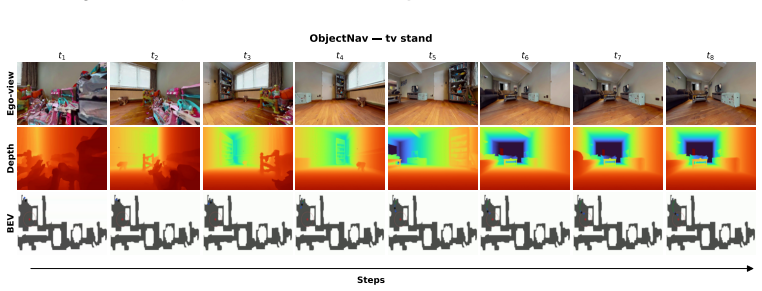
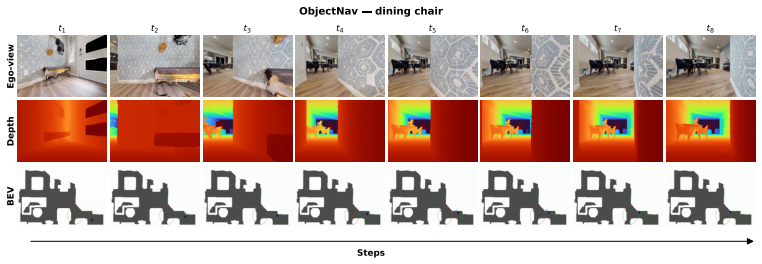
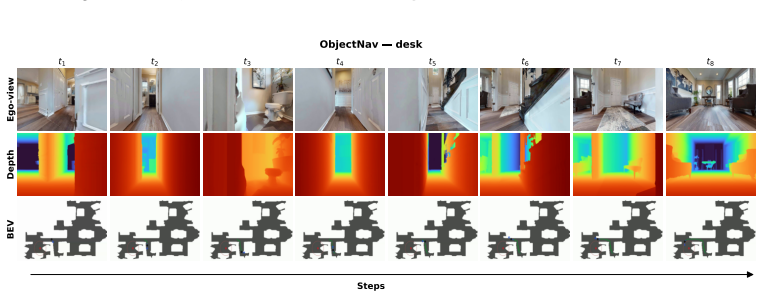
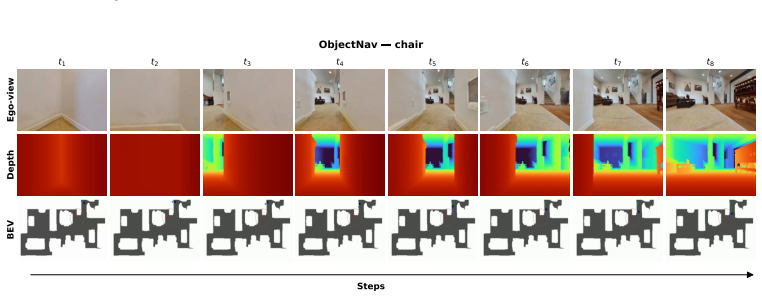
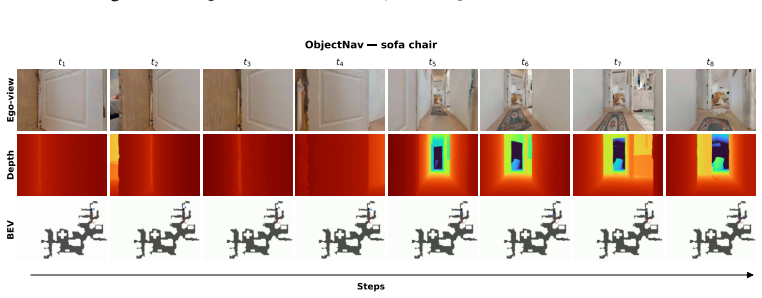
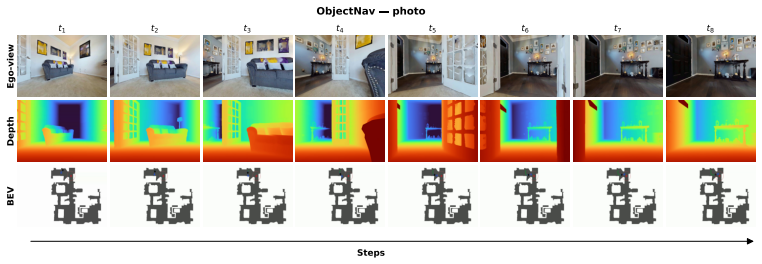
read the original abstract
Embodied visual navigation, where an agent perceives a complex environment and acts to reach a goal from raw sensory input, underpins a wide range of applications such as household service robotics, assistive robotics, and large-scale autonomous exploration. However, recent attempts to unify vision-and-language navigation (VLN) and object goal navigation (ObjNav) remain at the level of architectural fusion, mixed-task training, and large vision-language pretraining, without examining whether independently trained vision and language encoders may already share a common semantic structure. Moreover, even object-centric topological maps still ground language goals through explicit cross-modal supervision such as CLIP or large vision-language models, leaving open whether such grounding is possible from a purely vision-built map. To address these challenges, we extend the Platonic Representation Hypothesis to embodied navigation and recast vision-only ObjNav, cross-modal ObjNav, and VLN as three different interfaces to the same object-centric semantic manifold. We further introduce PlatonicNav, a training-free framework whose Platonic Topological Map fuses geometric and semantic node distances from a self-supervised visual encoder, and grounds language goals via blind matching without any paired vision-language data. Extensive experiments on simulation benchmarks including HM3D-IIN, OVON, and R2R-CE on MP3D, together with deployment on Unitree Go2, demonstrate that PlatonicNav generalizes across tasks, modalities, and embodiments without explicit cross-modal training. Code: https://github.com/AIGeeksGroup/PlatonicNav. Website: https://aigeeksgroup.github.io/PlatonicNav.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the Platonic Representation Hypothesis to embodied navigation by recasting vision-only ObjNav, cross-modal ObjNav, and VLN as interfaces to the same object-centric semantic manifold. It introduces the training-free PlatonicNav framework, whose Platonic Topological Map is built from a self-supervised visual encoder, fuses geometric and semantic node distances, and grounds language goals via blind matching without any paired vision-language data or explicit cross-modal supervision. Experiments on HM3D-IIN, OVON, and R2R-CE (MP3D) plus real-robot deployment on Unitree Go2 are presented as evidence of generalization across tasks, modalities, and embodiments.
Significance. If the blind-matching results hold under the stated conditions, the work would be significant for showing that semantic alignment between independently trained vision and language representations can be exploited directly in navigation without additional cross-modal training or paired data. The public code release and website are strengths that support reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that language grounding occurs via 'blind matching' without paired vision-language data rests on the unverified assumption that a self-supervised visual encoder already produces node features whose geometry is sufficiently isomorphic to language embeddings for reliable nearest-neighbor matching; no description of the encoder, any projection or normalization step, or controls isolating this alignment from benchmark-specific artifacts is supplied.
- [Abstract] Abstract / Experiments: the generalization claim across three navigation tasks and a real robot is asserted, yet the abstract supplies no quantitative success rates, error bars, ablation results, or baseline comparisons; without these data it is impossible to determine whether the reported performance supports the 'three different interfaces to the same manifold' framing or is an artifact of the chosen benchmarks.
minor comments (1)
- [Abstract] The term 'Platonic Topological Map' is introduced as a new entity but its precise construction (node definition, distance fusion formula) is not formalized in the abstract, which hinders immediate assessment of the 'parameter-free' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we respond point-by-point to the major comments, clarifying the role of the abstract versus the full paper and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that language grounding occurs via 'blind matching' without paired vision-language data rests on the unverified assumption that a self-supervised visual encoder already produces node features whose geometry is sufficiently isomorphic to language embeddings for reliable nearest-neighbor matching; no description of the encoder, any projection or normalization step, or controls isolating this alignment from benchmark-specific artifacts is supplied.
Authors: The abstract is a concise summary and therefore omits implementation specifics that appear in the Methods section, where the self-supervised visual encoder (including its architecture and any normalization) is fully specified and the Platonic Topological Map construction is detailed. The claim of blind matching without paired data or projection layers is not an unverified assumption; it is empirically tested by the consistent navigation performance across three distinct benchmarks and a real-robot embodiment, none of which involve cross-modal fine-tuning. These results across varied environments function as the control isolating semantic alignment from benchmark artifacts. We will revise the abstract to name the encoder family and note the absence of learned projections. revision: partial
-
Referee: [Abstract] Abstract / Experiments: the generalization claim across three navigation tasks and a real robot is asserted, yet the abstract supplies no quantitative success rates, error bars, ablation results, or baseline comparisons; without these data it is impossible to determine whether the reported performance supports the 'three different interfaces to the same manifold' framing or is an artifact of the chosen benchmarks.
Authors: We agree that the abstract would be strengthened by including representative quantitative results. The full manuscript already reports success rates, standard deviations, ablations on geometric versus semantic distances, and baseline comparisons on HM3D-IIN, OVON, and R2R-CE, plus real-robot metrics on Unitree Go2; these numbers directly support the unified-manifold interpretation because the same map and matching procedure succeed without task-specific training. We will incorporate key quantitative highlights (e.g., success rates on the primary benchmarks) into the revised abstract. revision: yes
Circularity Check
No circularity; framework applies external pre-trained encoder without internal reduction
full rationale
The paper presents PlatonicNav as a training-free framework that builds a topological map from a self-supervised visual encoder and performs blind matching for language grounding. No equations, parameters, or steps are shown to reduce by construction to fitted inputs or self-citations within the paper itself. The claimed semantic alignment is imported from the external encoder's properties rather than derived or assumed via self-definition. The extension of the Platonic Representation Hypothesis is framed as an application to navigation tasks, with generalization demonstrated via external benchmarks (HM3D-IIN, OVON, R2R-CE) rather than internal fitting loops. This is the most common honest finding for papers that leverage pre-trained models without re-deriving their representations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Independently trained vision and language encoders share a common semantic structure (Platonic Representation Hypothesis)
- ad hoc to paper Blind matching of language goals to vision-derived map nodes works without paired vision-language data
invented entities (1)
-
Platonic Topological Map
no independent evidence
Reference graph
Works this paper leans on
-
[1]
BEVBert: Multimodal map pre-training for language-guided navigation
Dong An, Yuankai Qi, Yangguang Li, Yan Huang, Liang Wang, Tieniu Tan, and Jing Shao. BEVBert: Multimodal map pre-training for language-guided navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2022
2022
-
[2]
ETPNav: Evolving topological planning for vision-language navigation in continuous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
Dong An, Hanqing Wang, Wenguan Wang, Zun Wang, Yan Huang, Keji He, and Liang Wang. ETPNav: Evolving topological planning for vision-language navigation in continuous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[3]
1st place solutions for RxR-habitat vision-and-language navigation competition (CVPR 2022), 2022
Dong An, Zun Wang, Yangguang Li, Yi Wang, Yicong Hong, Yan Huang, Liang Wang, and Jing Shao. 1st place solutions for RxR-habitat vision-and-language navigation competition (CVPR 2022), 2022
2022
-
[4]
Chang, Devendra Singh Chaplot, Alexey Dosovitskiy, Saurabh Gupta, V
Peter Anderson, Angel X. Chang, Devendra Singh Chaplot, Alexey Dosovitskiy, Saurabh Gupta, V . Koltun, J. Kosecka, Jitendra Malik, Roozbeh Mottaghi, M. Savva, et al. On evaluation of embodied navigation agents.arXiv.org, 2018
2018
-
[5]
Reid, Stephen Gould, and Anton van den Hengel
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, I. Reid, Stephen Gould, and Anton van den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017
2017
-
[6]
Qwen3-vl technical report.arXiv.org, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xiong-Hui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Rongyao Fang, Chang Gao, et al. Qwen3-vl technical report.arXiv.org, 2025
2025
-
[7]
Objectnav revisited: On evaluation of embodied agents navigating to objects, 2020
Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Oleksandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, and Erik Wijmans. Objectnav revisited: On evaluation of embodied agents navigating to objects, 2020
2020
-
[8]
Mairal, Piotr Bojanowski, and Armand Joulin
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv’e J’egou, J. Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InIEEE International Conference on Computer Vision, pages 9630–9640. IEEE, 2021
2021
-
[9]
Chang, Angela Dai, T
Angel X. Chang, Angela Dai, T. Funkhouser, Maciej Halber, M. Nießner, M. Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments.International Conference on 3D Vision, pages 667–676, 2017
2017
-
[10]
Gandhi, Abhinav Gupta, and Russ Salakhutdinov
Devendra Singh Chaplot, Dhiraj P. Gandhi, Abhinav Gupta, and Russ Salakhutdinov. Object goal navigation using goal-oriented semantic exploration. InNeural Information Processing Systems, 2020
2020
-
[11]
Neural topological SLAM for visual navigation
Devendra Singh Chaplot, Ruslan Salakhutdinov, Abhinav Gupta, and Saurabh Gupta. Neural topological SLAM for visual navigation. InComputer Vision and Pattern Recognition, pages 12872–12881. IEEE, 2020
2020
-
[12]
Jiaqi Chen, Bingqian Lin, Xinmin Liu, Xiaodan Liang, and Kwan-Yee K. Wong. Affordances- oriented planning using foundation models for continuous vision-language navigation. InAAAI Conference on Artificial Intelligence, 2024
2024
-
[13]
Jiaqi Chen, Bingqian Lin, Ran Xu, Zhenhua Chai, Xiaodan Liang, and Kwan-Yee K. Wong. MapGPT: Map-guided prompting with adaptive path planning for vision-and-language naviga- tion. InAnnual Meeting of the Association for Computational Linguistics, pages 9796–9810. Association for Computational Linguistics, 2024
2024
-
[14]
V’azquez, and S
Kevin Chen, Junshen Chen, Jo Chuang, M. V’azquez, and S. Savarese. Topological plan- ning with transformers for vision-and-language navigation. InComputer Vision and Pattern Recognition, pages 11276–11286, 2020
2020
-
[15]
Li, Mingkui Tan, and Chuang Gan
Peihao Chen, Dongyu Ji, Kunyang Lin, Runhao Zeng, Thomas H. Li, Mingkui Tan, and Chuang Gan. Weakly-supervised multi-granularity map learning for vision-and-language navigation. In Neural Information Processing Systems, volume 35, pages 38149–38161. Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2022. 10
2022
-
[16]
History aware multimodal transformer for vision-and-language navigation
Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-and-language navigation. InNeural Information Processing Systems, 2021
2021
-
[17]
Think global, act local: Dual-scale graph transformer for vision-and-language navigation
Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. Think global, act local: Dual-scale graph transformer for vision-and-language navigation. InComputer Vision and Pattern Recognition, pages 16516–16526. IEEE, 2022
2022
-
[18]
NaVILA: Legged robot vision-language-action model for navigation.Robotics, 2024
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Xueyan Zou, Jan Kautz, Erdem Biyik, Hongxu Yin, Sifei Liu, and Xiaolong Wang. NaVILA: Legged robot vision-language-action model for navigation.Robotics, 2024
2024
-
[19]
CoWs on pasture: Baselines and benchmarks for language-driven zero-shot object navigation
Samir Yitzhak Gadre, Mitchell Wortsman, Gabriel Ilharco, Ludwig Schmidt, and Shuran Song. CoWs on pasture: Baselines and benchmarks for language-driven zero-shot object navigation. InComputer Vision and Pattern Recognition, 2022
2022
-
[20]
Octonav: Towards generalist embodied navigation.arXiv.org, 2025
Chen Gao, Liankai Jin, Xingyu Peng, Jiazhao Zhang, Yue Deng, Annan Li, He Wang, and Si Liu. Octonav: Towards generalist embodied navigation.arXiv.org, 2025
2025
-
[21]
Objectreact: Learning object-relative control for visual navigation
Sourav Garg, Dustin Craggs, Vineeth Bhat, Lachlan Mares, Stefan Podgorski, Madhava Krishna, Feras Dayoub, and Ian Reid. Objectreact: Learning object-relative control for visual navigation. arXiv.org, 2025
2025
-
[22]
Hosseinzadeh, Lachlan Mares, Niko Sunderhauf, Feras Dayoub, and Ian Reid
Sourav Garg, Krishan Rana, M. Hosseinzadeh, Lachlan Mares, Niko Sunderhauf, Feras Dayoub, and Ian Reid. Robohop: Segment-based topological map representation for open-world visual navigation. InIEEE International Conference on Robotics and Automation, pages 4090–4097. IEEE, IEEE, 2024
2024
-
[23]
Cross-modal map learning for vision and language navigation
Georgios Georgakis, Karl Schmeckpeper, Karan Wanchoo, Soham Dan, Eleni Miltsakaki, Dan Roth, and Kostas Daniilidis. Cross-modal map learning for vision and language navigation. In Computer Vision and Pattern Recognition, pages 15439–15449. IEEE, 2022
2022
-
[24]
Revisiting the platonic representation hypothesis: An aristotelian view.arXiv.org, 2026
Fabian Gröger, Shuo Wen, and Maria Brbi’c. Revisiting the platonic representation hypothesis: An aristotelian view.arXiv.org, 2026
2026
-
[25]
Concept- graphs: Open-vocabulary 3D scene graphs for perception and planning
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Ramalingam Chellappa, et al. Concept- graphs: Open-vocabulary 3D scene graphs for perception and planning. InIEEE International Conference on Robotics and Automation, 2023
2023
-
[26]
Girshick
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll’ar, and Ross B. Girshick. Masked autoencoders are scalable vision learners. InComputer Vision and Pattern Recognition, 2021
2021
-
[27]
Learning navigational visual representations with semantic map supervision
Yicong Hong, Yang Zhou, Ruiyi Zhang, Franck Dernoncourt, Trung Bui, Stephen Gould, and Hao Tan. Learning navigational visual representations with semantic map supervision. InIEEE International Conference on Computer Vision, pages 3032–3044. IEEE, 2023
2023
-
[28]
Visual language maps for robot navigation
Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard. Visual language maps for robot navigation. InIEEE International Conference on Robotics and Automation, 2022
2022
-
[29]
Ting Huang, Dongjian Li, Rui Yang, Zeyu Zhang, Zida Yang, and Hao Tang. Mobilevla-r1: Reinforcing vision-language-action for mobile robots.arXiv preprint arXiv:2511.17889, 2025
-
[30]
The platonic representation hypothesis.International Conference on Machine Learning, 2024
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis.International Conference on Machine Learning, 2024
2024
-
[31]
Omama, Tao Chen, Shuang Li, Ganesh Iyer, Soroush Saryazdi, Nikhil Varma Keetha, A
Krishna Murthy Jatavallabhula, Ali Kuwajerwala, Qiao Gu, Mohd. Omama, Tao Chen, Shuang Li, Ganesh Iyer, Soroush Saryazdi, Nikhil Varma Keetha, A. Tewari, et al. Conceptfusion: Open-set multimodal 3D mapping. InRobotics: Science and Systems. Robotics: Science and Systems Foundation, 2023
2023
-
[32]
Le, Yun- Hsuan Sung, Zhen Li, and Tom Duerig
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V . Le, Yun- Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational Conference on Machine Learning, 2021. 11
2021
-
[33]
Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloé Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, A
A. Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloé Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, A. Berg, Wan-Yen Lo, et al. Segment anything. InIEEE International Conference on Computer Vision, pages 3992–4003. IEEE, 2023
2023
-
[34]
Back into Plato's Cave: Examining Cross-modal Representational Convergence at Scale
A. Sophia Koepke, Daniil Zverev, Shiry Ginosar, and Alexei A. Efros. Back into Plato’s cave: Examining cross-modal representational convergence at scale.arXiv preprint arXiv:2604.18572, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Sim-2-sim transfer for vision-and-language navigation in contin- uous environments
Jacob Krantz and Stefan Lee. Sim-2-sim transfer for vision-and-language navigation in contin- uous environments. InEuropean Conference on Computer Vision, pages 588–603. Springer Nature Switzerland, 2022
2022
-
[36]
Instance- specific image goal navigation: Training embodied agents to find object instances, 2022
Jacob Krantz, Stefan Lee, Jitendra Malik, Dhruv Batra, and Devendra Singh Chaplot. Instance- specific image goal navigation: Training embodied agents to find object instances, 2022
2022
-
[37]
Beyond the nav- graph: Vision and language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav- graph: Vision and language navigation in continuous environments. InEuropean Conference on Computer Vision, pages 104–120. Springer International Publishing, 2020
2020
-
[38]
Beyond the nav- graph: Vision-and-language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav- graph: Vision-and-language navigation in continuous environments. InEuropean Conference on Computer Vision, pages 104–120. Springer, 2020
2020
-
[39]
Room-Across- Room: Multilingual vision-and-language navigation with dense spatiotemporal grounding
Alexander Ku, Peter Anderson, Roma Patel, Eugene Ie, and Jason Baldridge. Room-Across- Room: Multilingual vision-and-language navigation with dense spatiotemporal grounding. InConference on Empirical Methods in Natural Language Processing, pages 4392–4412. Association for Computational Linguistics, 2020
2020
-
[40]
Nav-r1: Reasoning and navigation in embodied scenes.arXiv preprint arXiv:2509.10884, 2025
Qingxiang Liu, Ting Huang, Zeyu Zhang, and Hao Tang. Nav-r1: Reasoning and navigation in embodied scenes.arXiv preprint arXiv:2509.10884, 2025
-
[41]
Instructnav: Zero-shot system for generic instruction navigation in unexplored environment, 2024
Yuxing Long, Wenzhe Cai, Hongcheng Wang, Guanqi Zhan, and Hao Dong. Instructnav: Zero-shot system for generic instruction navigation in unexplored environment, 2024
2024
-
[42]
ZSON: Zero-shot object-goal navigation using multimodal goal embeddings
Arjun Majumdar, Gunjan Aggarwal, Bhavika Devnani, Judy Hoffman, and Dhruv Batra. ZSON: Zero-shot object-goal navigation using multimodal goal embeddings. InNeural Information Processing Systems, pages 32340–32352. Neural Information Processing Systems Foundation, Inc. (NeurIPS), 2022
2022
-
[43]
Hall, Ming-Wei Chang, et al
Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernández Abrego, Ji Ma, Vincent Zhao, Yi Luan, Keith B. Hall, Ming-Wei Chang, et al. Large dual encoders are generalizable retrievers. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Conference on Empirical Methods in Natural Language Processing, 2021
2021
-
[44]
Oquab, Timothée Darcet, Théo Moutakanni, Huy V
M. Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervision.Trans. Mach. Learn. Res., 2023
2023
-
[45]
Pollefeys, and T
Songyou Peng, Kyle Genova, ChiyuMaxJiang, Andrea Tagliasacchi, M. Pollefeys, and T. Funkhouser. Openscene: 3D scene understanding with open vocabularies. InComputer Vision and Pattern Recognition, 2022
2022
-
[46]
VLN-R1: Vision-language navigation via reinforcement fine-tuning, 2025
Zhangyang Qi, Zhixiong Zhang, Yizhou Yu, Jiaqi Wang, and Hengshuang Zhao. VLN-R1: Vision-language navigation via reinforcement fine-tuning, 2025
2025
-
[47]
Ramesh, Gabriel Goh, S
Alec Radford, Jong Wook Kim, Chris Hallacy, A. Ramesh, Gabriel Goh, S. Agarwal, G. Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[48]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2019. 12
2019
-
[49]
Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI
Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexan- der Clegg, John M Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, et al. Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI. InNeurIPS Datasets and Benchmarks, 2021
2021
-
[50]
PIRLNav: Pretraining with imitation and RL finetuning for ObjectNav
Ram Ramrakhya, Dhruv Batra, Erik Wijmans, and Abhishek Das. PIRLNav: Pretraining with imitation and RL finetuning for ObjectNav. InComputer Vision and Pattern Recognition, pages 17896–17906. IEEE, 2023
2023
-
[51]
Habitat-Web: Learning embodied object-search strategies from human demonstrations at scale
Ram Ramrakhya, Eric Undersander, Dhruv Batra, and Abhishek Das. Habitat-Web: Learning embodied object-search strategies from human demonstrations at scale. InComputer Vision and Pattern Recognition, pages 5163–5173. IEEE, 2022
2022
-
[52]
Language- aligned waypoint (LAW) supervision for vision-and-language navigation in continuous environ- ments
Sonia Raychaudhuri, Saim Wani, Shivansh Patel, Unnat Jain, and Angel Chang. Language- aligned waypoint (LAW) supervision for vision-and-language navigation in continuous environ- ments. InConference on Empirical Methods in Natural Language Processing, pages 4018–4028. Association for Computational Linguistics, 2021
2021
-
[53]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InConference on Empirical Methods in Natural Language Processing, pages 3980–3990. Association for Computational Linguistics, 2019
2019
-
[54]
Gordon, and J
Stéphane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InInternational Conference on Artificial Intelligence and Statistics, pages 627–635, 2010
2010
-
[55]
Semi-parametric topological memory for navigation
Nikolay Savinov, Alexey Dosovitskiy, and Vladlen Koltun. Semi-parametric topological memory for navigation. InInternational Conference on Learning Representations, 2018
2018
-
[56]
Habitat: A platform for embodied AI research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied AI research. InIEEE International Conference on Computer Vision, pages 9338–9346. IEEE, 2019
2019
-
[57]
It’s a (blind) match! towards vision- language correspondence without parallel data
Dominik Schnaus, Nikita Araslanov, and Daniel Cremers. It’s a (blind) match! towards vision- language correspondence without parallel data. InComputer Vision and Pattern Recognition, pages 24983–24992. IEEE, 2025
2025
-
[58]
Proximal policy optimization algorithms.arXiv.org, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv.org, 2017
2017
-
[59]
Navigation with large language models: Semantic guesswork as a heuristic for planning
Dhruv Shah, Michael Equi, Blazej Osinski, Fei Xia, Brian Ichter, and Sergey Levine. Navigation with large language models: Semantic guesswork as a heuristic for planning. InConference on Robot Learning, 2023
2023
-
[60]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Gool, and Wenguan Wang
Hanqing Wang, Wei Liang, L. Gool, and Wenguan Wang. DREAMW ALKER: Mental planning for continuous vision-language navigation. InIEEE International Conference on Computer Vision, pages 10839–10849. IEEE, 2023
2023
-
[62]
Lookahead exploration with neural radiance representation for continuous vision-language navigation
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, Junjie Hu, Ming Jiang, and Shuqiang Jiang. Lookahead exploration with neural radiance representation for continuous vision-language navigation. InComputer Vision and Pattern Recognition, pages 13753–13762. IEEE, 2024
2024
-
[63]
Gridmm: Grid memory map for vision-and-language navigation
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. Gridmm: Grid memory map for vision-and-language navigation. InIEEE International Conference on Computer Vision, pages 15579–15590. IEEE, 2023
2023
-
[64]
Streamvln: Streaming vision-and-language navigation via slowfast context modeling.arXiv.org, 2025
Meng Wei, Chenyang Wan, Xiqian Yu, Tai Wang, Yuqiang Yang, Xiaohan Mao, Chenming Zhu, Wenzhe Cai, Hanqing Wang, Yilun Chen, et al. Streamvln: Streaming vision-and-language navigation via slowfast context modeling.arXiv.org, 2025. 13
2025
-
[65]
DD-PPO: Learning near-perfect pointgoal navigators from 2.5 billion frames
Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, and Dhruv Batra. DD-PPO: Learning near-perfect pointgoal navigators from 2.5 billion frames. InInternational Conference on Learning Representations, 2019
2019
-
[66]
VLFM: Vision-language frontier maps for zero-shot semantic navigation
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. VLFM: Vision-language frontier maps for zero-shot semantic navigation. InIEEE International Confer- ence on Robotics and Automation, 2023
2023
-
[67]
HM3D- OVON: A dataset and benchmark for open-vocabulary object goal navigation
Naoki Yokoyama, Ram Ramrakhya, Abhishek Das, Dhruv Batra, and Sehoon Ha. HM3D- OVON: A dataset and benchmark for open-vocabulary object goal navigation. InIEEE/RJS International Conference on Intelligent RObots and Systems, pages 5543–5550. IEEE, 2024
2024
-
[68]
Escaping Plato’s cave: JAM for aligning independently trained vision and language models.arXiv.org, 2025
Lauren Hyoseo Yoon, Yisong Yue, and Been Kim. Escaping Plato’s cave: JAM for aligning independently trained vision and language models.arXiv.org, 2025
2025
-
[69]
L3MVN: Leveraging large language models for visual target navigation
Bangguo Yu, Hamidreza Kasaei, and Ming Cao. L3MVN: Leveraging large language models for visual target navigation. InIEEE/RJS International Conference on Intelligent RObots and Systems, pages 3554–3560. IEEE, 2023
2023
-
[70]
Correctnav: Self-correction flywheel empowers vision-language-action navigation model, 2025
Zhuoyuan Yu, Yuxing Long, Zihan Yang, Chengyan Zeng, Hongwei Fan, Jiyao Zhang, and Hao Dong. Correctnav: Self-correction flywheel empowers vision-language-action navigation model, 2025
2025
-
[71]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InIEEE International Conference on Computer Vision, pages 11941–11952. IEEE, 2023
2023
-
[72]
Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks.arXiv.org, 2024
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks.arXiv.org, 2024
2024
-
[73]
Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks. InarXiv.org, 2024
2024
-
[74]
NaVid: Video-based VLM plans the next step for vision-and-language navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and Wanggui He. NaVid: Video-based VLM plans the next step for vision-and-language navigation. InRobotics: Science and Systems. Robotics: Science and Systems Foundation, 2024
2024
-
[75]
Fast segment anything.arXiv.org, 2023
Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu, Min Li, Ming Tang, and Jinqiao Wang. Fast segment anything.arXiv.org, 2023
2023
-
[76]
NavGPT: Explicit reasoning in vision-and-language navigation with large language models
Gengze Zhou, Yicong Hong, and Qi Wu. NavGPT: Explicit reasoning in vision-and-language navigation with large language models. InAAAI Conference on Artificial Intelligence, 2023
2023
-
[77]
ESC: Exploration with soft commonsense constraints for zero-shot object navigation
Kaiwen Zhou, Kaizhi Zheng, Connor Pryor, Yilin Shen, Hongxia Jin, Lise Getoor, and Xin Eric Wang. ESC: Exploration with soft commonsense constraints for zero-shot object navigation. In International Conference on Machine Learning, 2023
2023
-
[78]
Move to understand a 3D scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation
Ziyu Zhu, Xilin Wang, Yixuan Li, Zhuofan Zhang, Xiaojian Ma, Yixin Chen, Baoxiong Jia, Wei Liang, Qian Yu, Zhidong Deng, et al. Move to understand a 3D scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation. InIEEE International Conference on Computer Vision, pages 8120–8132. IEEE, 2025. 14 A Preliminaries A.1 Pla...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.