Consistency evaluation of benchmarks used for causal discovery
Pith reviewed 2026-06-28 14:23 UTC · model grok-4.3
The pith
Eleven popular causal discovery benchmarks show large differences in consistency with domain literature.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
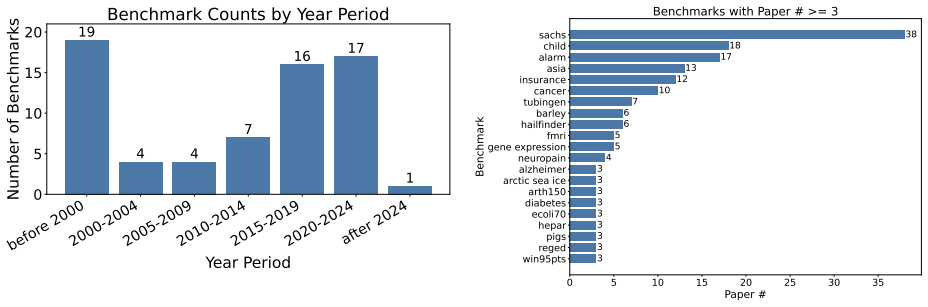
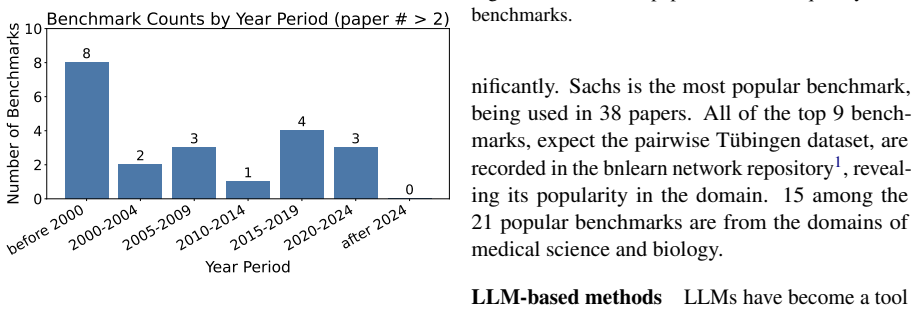
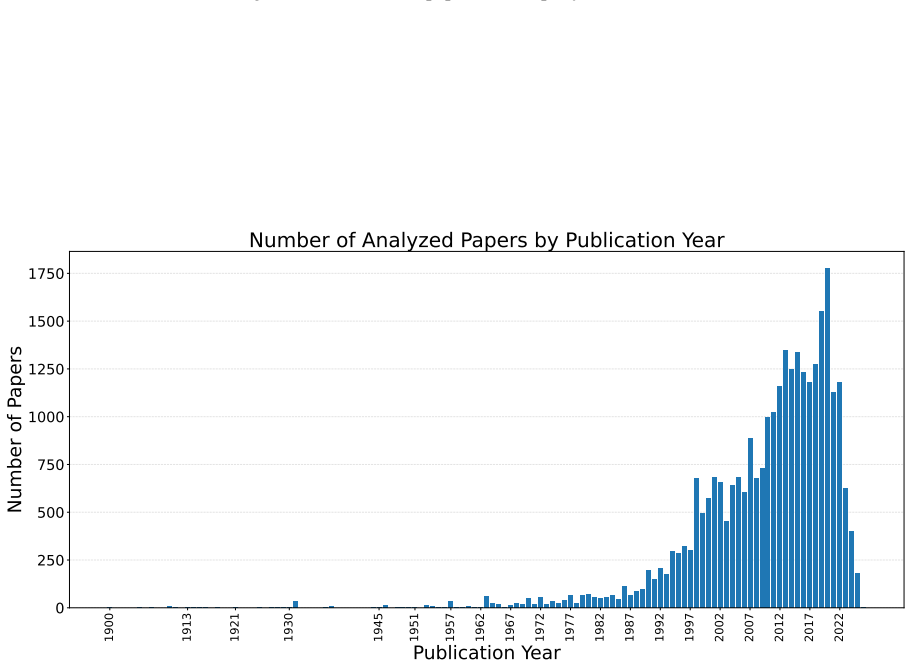
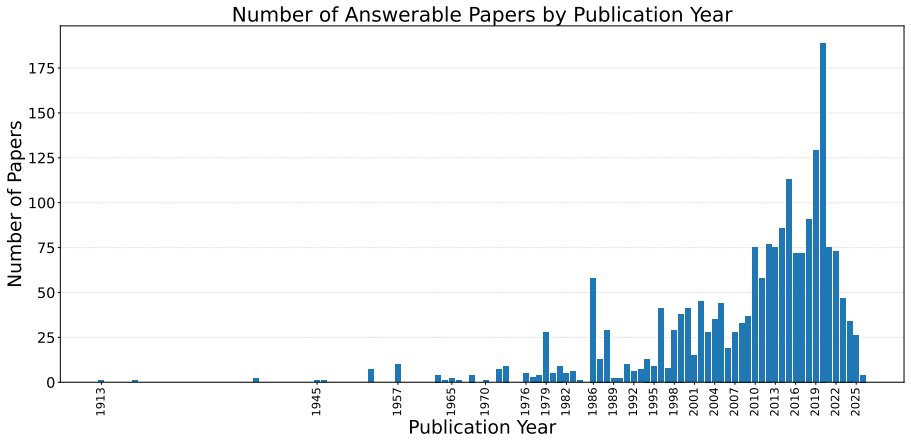
The paper establishes that popular benchmarks for causal discovery vary significantly in their consistency with domain research papers, as evaluated by an LLM-based pipeline that checks 38,081 papers across 11 benchmarks.
What carries the argument
An automated pipeline that retrieves relevant research papers and prompts LLMs to evaluate consistency between benchmark causal graphs and the papers.
If this is right
- Evaluations of causal discovery methods may be affected differently depending on the benchmark chosen.
- LLM-based causal discovery methods are particularly sensitive to benchmark misalignment due to new discoveries.
- Future benchmark creation should incorporate consistency checks with domain literature.
- Researchers should select benchmarks with higher consistency for more reliable evaluations.
Where Pith is reading between the lines
- Human verification of the LLM judgments could refine the consistency scores.
- This approach could be extended to other AI benchmarks beyond causal discovery.
- Periodic re-evaluation of benchmarks as new research emerges would help maintain their validity.
Load-bearing premise
The LLM prompts produce judgments of consistency that accurately reflect the true alignment between graphs and papers without systematic bias.
What would settle it
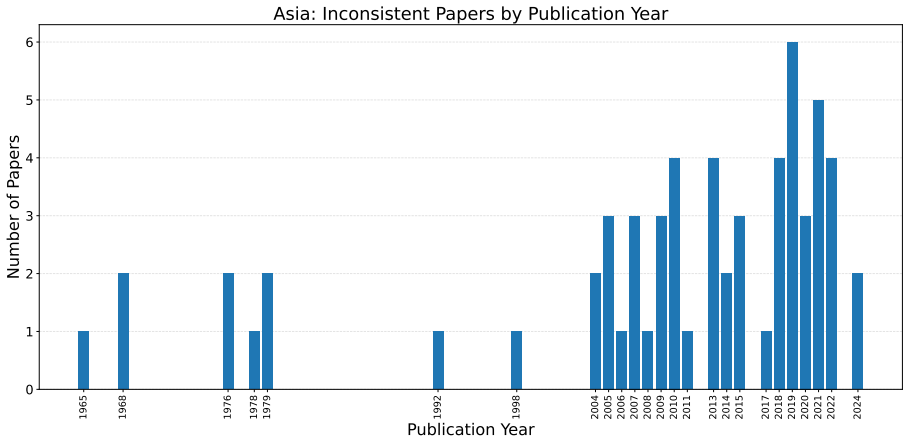
If independent human experts review a sample of the paper-graph pairs and find substantially different consistency rates than the LLM pipeline, the reported variation would not hold.
Figures

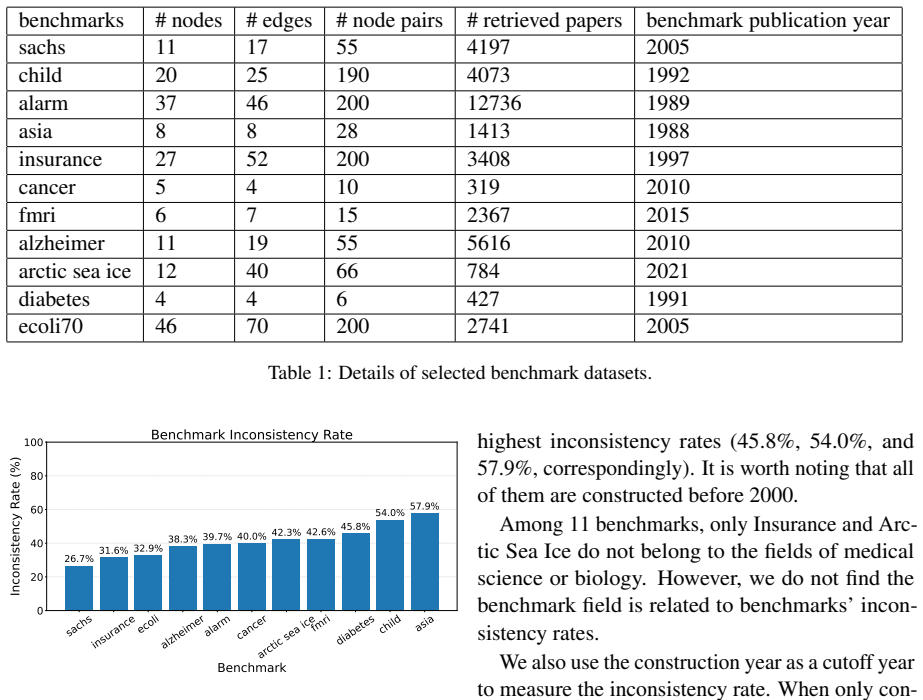
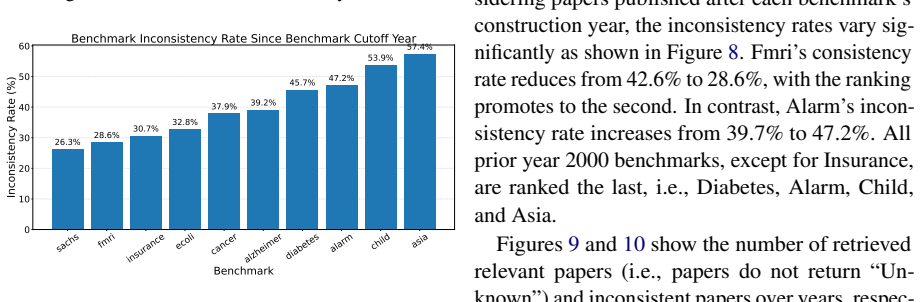
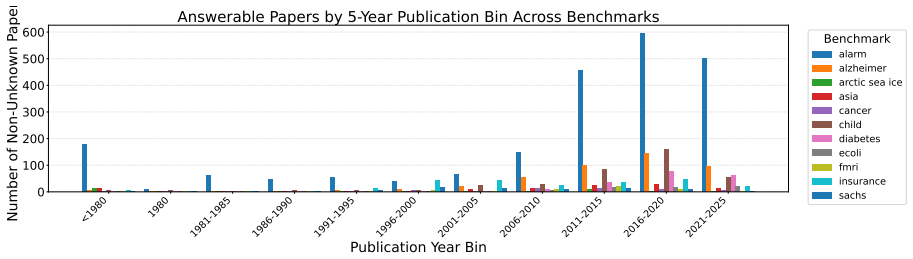
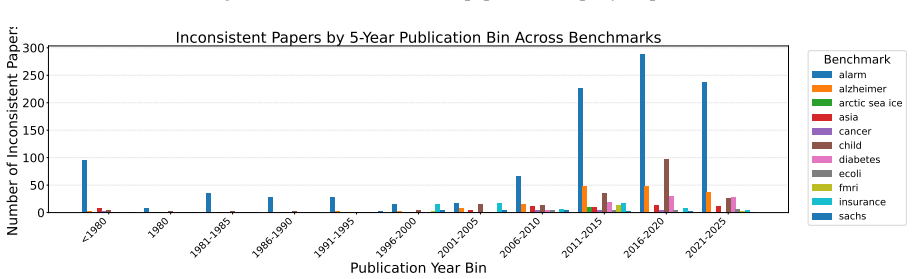
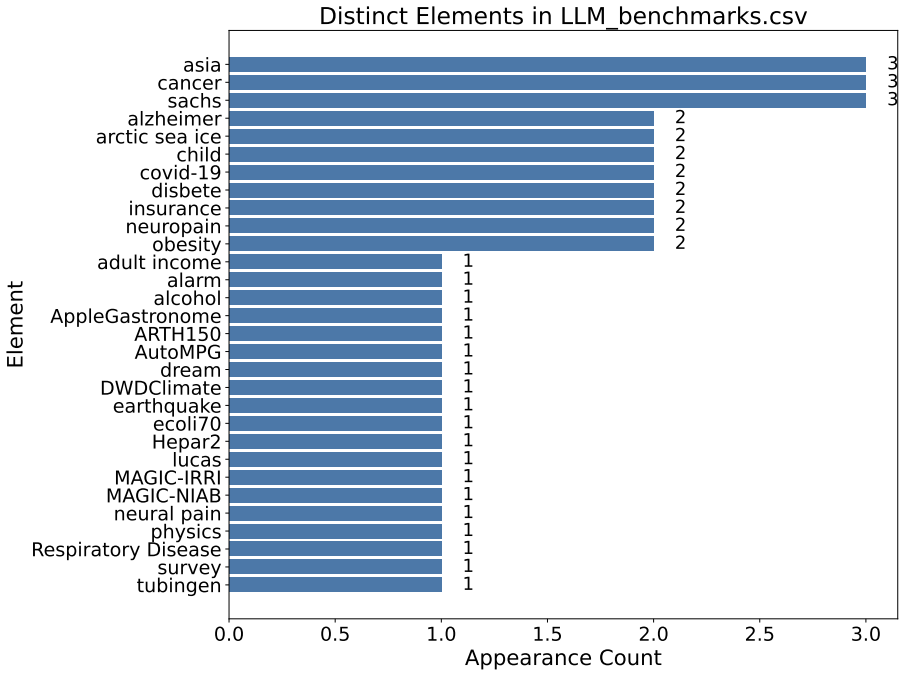
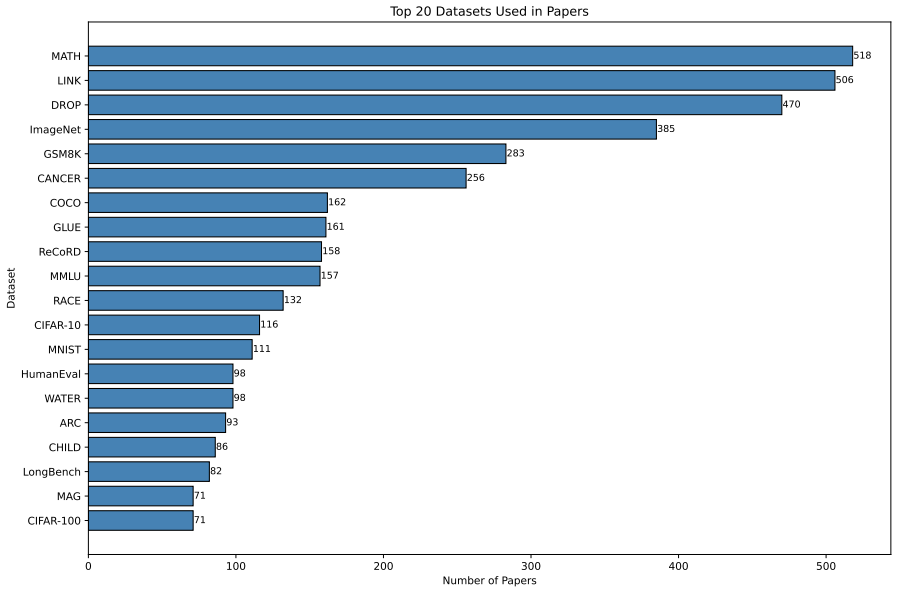
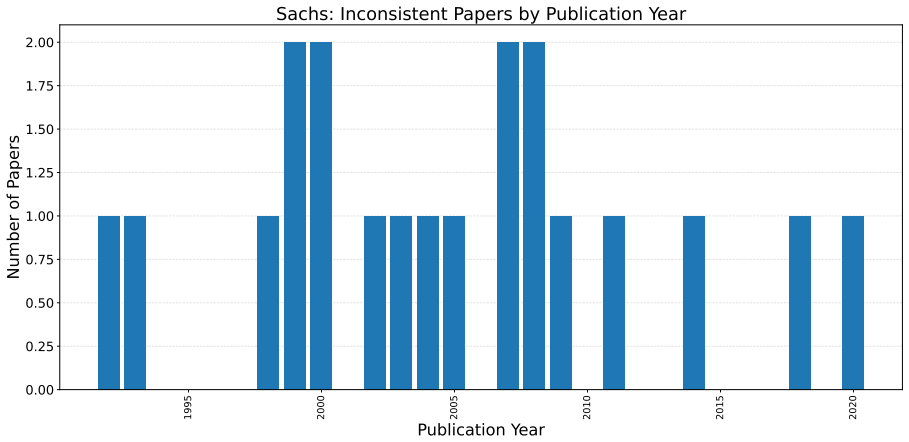
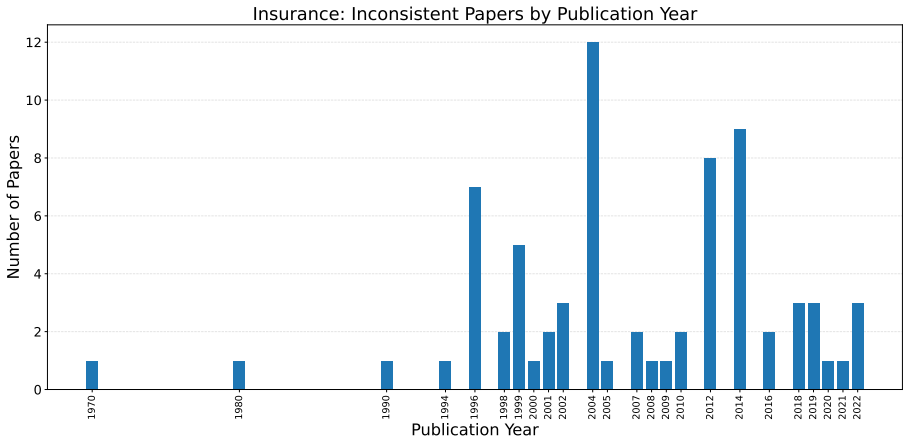
read the original abstract
In graphical causal model, causal discovery aims to construct a causal graph based on numerical data and domain knowledge in plain text. However, the evaluation of causal discovery methods remains a challenge in the area as the progress of domain researches often makes benchmark causal graphs contain mis-aligned knowledge. This problem especially affects the evaluation of large language model (LLM) based causal discovery methods as they are sensitive to the new discoveries in the literature. This work is the first to systematically study the quality of benchmark causal graphs. Specifically, we design a pipeline that automatically retrieves relevant research papers from scientific databases, and prompts LLMs to check the consistency between the benchmark causal graphs and domain research papers. We evaluate 11 popular real-world benchmarks, for which our pipeline in total proceeds 38,081 domain papers. Our results show that popular benchmarks vary significantly in their consistency with domain research, with clear implications for causal discovery research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an automated pipeline that retrieves relevant domain papers (38,081 in total) from scientific databases and prompts LLMs to judge consistency between the causal graphs in 11 popular real-world benchmarks and the retrieved literature. It reports that the benchmarks vary significantly in their consistency with domain research and draws implications for causal discovery evaluation, especially for LLM-based methods sensitive to new findings.
Significance. If the LLM consistency judgments prove reliable, the work identifies a previously unquantified source of misalignment in standard benchmarks and supplies a scalable method for ongoing evaluation. The scale of the literature search is a clear strength. The result would directly affect how benchmark graphs are trusted when assessing causal discovery algorithms.
major comments (2)
- [Abstract (pipeline description)] The central quantitative results rest entirely on LLM judgments of consistency, yet the manuscript provides no validation of those judgments (human-expert agreement rates, calibration set, inter-LLM consistency, or handling of ambiguous papers). This assumption is load-bearing because every reported variation across the 11 benchmarks is derived from the LLM outputs.
- [Abstract (pipeline description)] No information is given on prompt engineering, sensitivity analysis, or inter-rater metrics for the LLM consistency checks. Without these, it is impossible to determine whether the observed differences among benchmarks reflect genuine literature misalignment or artifacts of the judge.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for validation and methodological transparency in our LLM-based pipeline. We agree these are important and will incorporate the requested details and analyses in a major revision.
read point-by-point responses
-
Referee: The central quantitative results rest entirely on LLM judgments of consistency, yet the manuscript provides no validation of those judgments (human-expert agreement rates, calibration set, inter-LLM consistency, or handling of ambiguous papers). This assumption is load-bearing because every reported variation across the 11 benchmarks is derived from the LLM outputs.
Authors: We acknowledge the manuscript currently lacks explicit validation of the LLM consistency judgments. In the revision we will add a dedicated validation subsection that reports: (i) human-expert agreement rates on a stratified sample of 500 paper-graph pairs, (ii) a calibration set of 100 expert-annotated examples, (iii) inter-LLM consistency across GPT-4, Claude-3, and Llama-3, and (iv) explicit handling rules for ambiguous papers (e.g., “insufficient information” category with frequency statistics). These additions will directly quantify the reliability of the reported benchmark differences. revision: yes
-
Referee: No information is given on prompt engineering, sensitivity analysis, or inter-rater metrics for the LLM consistency checks. Without these, it is impossible to determine whether the observed differences among benchmarks reflect genuine literature misalignment or artifacts of the judge.
Authors: We agree that prompt details and robustness checks are missing. The revised manuscript will include: the complete system and user prompts in an appendix, a description of the iterative prompt-engineering process (including few-shot examples and chain-of-thought instructions), sensitivity results across three prompt variants and two temperature settings, and inter-rater metrics (both LLM-LLM and LLM-human) already referenced in the new validation section. These additions will allow readers to assess whether the observed benchmark variations are robust to judge artifacts. revision: yes
Circularity Check
No significant circularity; empirical pipeline is self-contained
full rationale
The paper describes an empirical pipeline that retrieves domain papers from databases and applies LLM prompts to judge consistency with benchmark causal graphs. No equations, fitted parameters, predictions derived from fits, or self-referential definitions appear in the derivation. The central claim (variation in benchmark consistency) is produced by processing external literature rather than by construction from the paper's own inputs or prior self-citations. Self-citation load-bearing, ansatz smuggling, and renaming patterns are absent. The absence of validation metrics for LLM judgments is a potential reliability concern but does not create circularity under the defined criteria.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs prompted with benchmark graphs and paper abstracts can produce accurate and unbiased consistency assessments.
- domain assumption The 38,081 retrieved papers constitute a sufficient and unbiased sample of the relevant domain literature for each benchmark.
Reference graph
Works this paper leans on
-
[1]
Journal of the Royal Statistical Society: Series B (Methodological), 50(2):157–194
Local computations with probabilities on graphi- cal structures and their application to expert systems. Journal of the Royal Statistical Society: Series B (Methodological), 50(2):157–194. Ahmed Abdulaal, Adamos Hadjivasiliou, Nina Montana-Brown, Tiantian He, Ayodeji Ijishakin, Ivana Drobnjak, Daniel Castro, and Daniel Alexander
-
[2]
InInternational Conference on Learning Representations, volume 2024, pages 57559–57610
Causal modelling agents: Causal graph dis- covery through synergising metadata-and data-driven reasoning. InInternational Conference on Learning Representations, volume 2024, pages 57559–57610. Bruce Abramson, John Brown, Ward Edwards, Allan Murphy, and Robert L Winkler. 1996. Hailfinder: A bayesian system for forecasting severe weather. International Jou...
2024
-
[3]
Virginia Aglietti, Alan Malek, Ira Ktena, and Silvia Chiappa
Collaborative causal discovery with atomic interventions.Advances in Neural Information Pro- cessing Systems, 34:12761–12773. Virginia Aglietti, Alan Malek, Ira Ktena, and Silvia Chiappa. 2023. Constrained causal bayesian opti- mization. InInternational Conference on Machine Learning, pages 304–321. PMLR. Sina Akbari, Ehsan Mokhtarian, AmirEmad Ghassami, ...
-
[4]
Springer
Proceedings, pages 247–256. Springer. Alexis Bellot, Junzhe Zhang, and Elias Bareinboim
-
[5]
InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 38, pages 11043–11051
Scores for learning discrete causal graphs with unobserved confounders. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 38, pages 11043–11051. John Binder, Daphne Koller, Stuart Russell, and Keiji Kanazawa. 1997. Adaptive probabilistic networks with hidden variables.Machine Learning, 29(2):213– 244. Philippe Brouillard, Chandler ...
-
[6]
Haoyue Dai, Yiwen Qiu, Ignavier Ng, Xinshuai Dong, Peter Spirtes, and Kun Zhang
Bcd nets: Scalable variational approaches for bayesian causal discovery.Advances in Neural Information Processing Systems, 34:7095–7110. Haoyue Dai, Yiwen Qiu, Ignavier Ng, Xinshuai Dong, Peter Spirtes, and Kun Zhang. 2025. Latent variable causal discovery under selection bias.arXiv preprint arXiv:2512.11219. Haoyue Dai, Peter Spirtes, and Kun Zhang. 2022...
-
[7]
Anish Dhir, Ruby Sedgwick, Avinash Kori, Ben Glocker, and Mark Van Der Wilk
Bivariate causal discovery using bayesian model selection.arXiv preprint arXiv:2306.02931. Anish Dhir, Ruby Sedgwick, Avinash Kori, Ben Glocker, and Mark Van Der Wilk. 2024. Contin- uous bayesian model selection for multivariate causal discovery.arXiv preprint arXiv:2411.10154. Shuyu Dong, Michele Sebag, Kento Uemura, Akito Fujii, Shuang Chang, Yusuke Koy...
-
[8]
Multimodal pooled perturb-cite-seq screens in patient models define mechanisms of cancer immune evasion.Nature genetics, 53(3):332–341. Jensen FV . 1996.An introduction to Bayesian networks. London, UK: UCL Press. Amanda Gentzel, Dan Garant, and David Jensen. 2019. The case for evaluating causal models using inter- ventional measures and empirical data.Ad...
-
[9]
Efficient Causal Graph Discovery Using Large Language Models
An expert system for control of waste water treatment—a pilot project. Technical report, Techni- cal report, Judex Datasystemer A/S, Aalborg, 1989. In Danish. Thomas Jiralerspong, Xiaoyin Chen, Yash More, Vedant Shah, and Yoshua Bengio. 2024. Efficient causal graph discovery using large language models. Preprint, arXiv:2402.01207. Diviyan Kalainathan and ...
work page internal anchor Pith review Pith/arXiv arXiv 1989
-
[10]
Peter JF Lucas, Linda C Van der Gaag, and Ameen Abu- Hanna
Can large language models build causal graphs? InNeurIPS 2022 Workshop on Causality for Real-world Impact. Peter JF Lucas, Linda C Van der Gaag, and Ameen Abu- Hanna. 2004. Bayesian networks in biomedicine and health-care. Alessandro Magrini, Stefano Di Blasi, Federico Mattia Stefanini, and 1 others. 2017. A conditional linear gaussian network to assess t...
2022
-
[11]
InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 8975–8982
Discovering fully oriented causal networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 8975–8982. Ehsan Mokhtarian, Mohmmadsadegh Khorasani, Jalal Etesami, and Negar Kiyavash. 2023. Novel ordering- based approaches for causal structure learning in the presence of unobserved variables. InProceedings of the AAAI Confer...
-
[12]
Tim Van den Bulcke, Koenraad Van Leemput, Bart Naudts, Piet van Remortel, Hongwu Ma, Alain Ver- schoren, Bart De Moor, and Kathleen Marchal
International Conference on Learning Repre- sentations, ICLR. Tim Van den Bulcke, Koenraad Van Leemput, Bart Naudts, Piet van Remortel, Hongwu Ma, Alain Ver- schoren, Bart De Moor, and Kathleen Marchal. 2006. Syntren: a generator of synthetic gene expression data for design and analysis of structure learning al- gorithms.BMC bioinformatics, 7(1):43. Anike...
2006
-
[13]
InInternational Conference on Ma- chine Learning, pages 50650–50668
Optimal kernel choice for score function-based causal discovery. InInternational Conference on Ma- chine Learning, pages 50650–50668. PMLR. 14 X Wang, Y Du, S Zhu, L Ke, Z Chen, J Hao, and J Wang
-
[14]
InProceedings of the Thirtieth International Joint Conference on Artificial Intelli- gence (IJCAI-21), pages 3566–3573
Ordering-based causal discovery with rein- forcement learning. InProceedings of the Thirtieth International Joint Conference on Artificial Intelli- gence (IJCAI-21), pages 3566–3573. IJCAI Interna- tional Joint Conferences on Artificial Intelligence Organization. Yunxia Wang, Fuyuan Cao, Kui Yu, and Jiye Liang
-
[15]
InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 8584–8593
Efficient causal structure learning from mul- tiple interventional datasets with unknown targets. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 8584–8593. Yunxia Wang, CAO Fuyuan, Kui Yu, and Jiye Liang. 2025a. Federated causal structure learning with non- identical variable sets. InForty-second International Conference...
-
[16]
InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 40, pages 36757–36765
Robust causal discovery under imperfect struc- tural constraints. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 40, pages 36757–36765. Zidong Wang, Fei Liu, Qi Feng, Qingfu Zhang, and Xi- aoguang Gao. 2025b. Llm-enhanced score function evolution for causal structure learning. InProceed- ings of the Thirty-Fourth International J...
-
[17]
Causal-driven skill prerequisite structure dis- covery. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 20604– 20612. Yan Zeng, Shohei Shimizu, Ruichu Cai, Feng Xie, Mi- chio Yamamoto, and Zhifeng Hao. 2021. Causal discovery with multi-domain lingam for latent fac- tors. InCausal Analysis Workshop Series, pages 1–4. PMLR....
-
[18]
Sachs Original paper (Sachs et al., 2005) Papers using it: (Eulig et al., 2025; Shen et al., 2025; Roy et al., 2025; Shahverdikondori et al., 2024; Kang et al., 2026; Aglietti et al., 2023; Olko et al., 2023; Annadani et al., 2023; Perry et al., 2022; Dai et al., 2022; Addanki and Kasiviswanathan, 2021; Cundy et al., 2021; Wang et al., 2025a; Li et al., 2...
2005
-
[19]
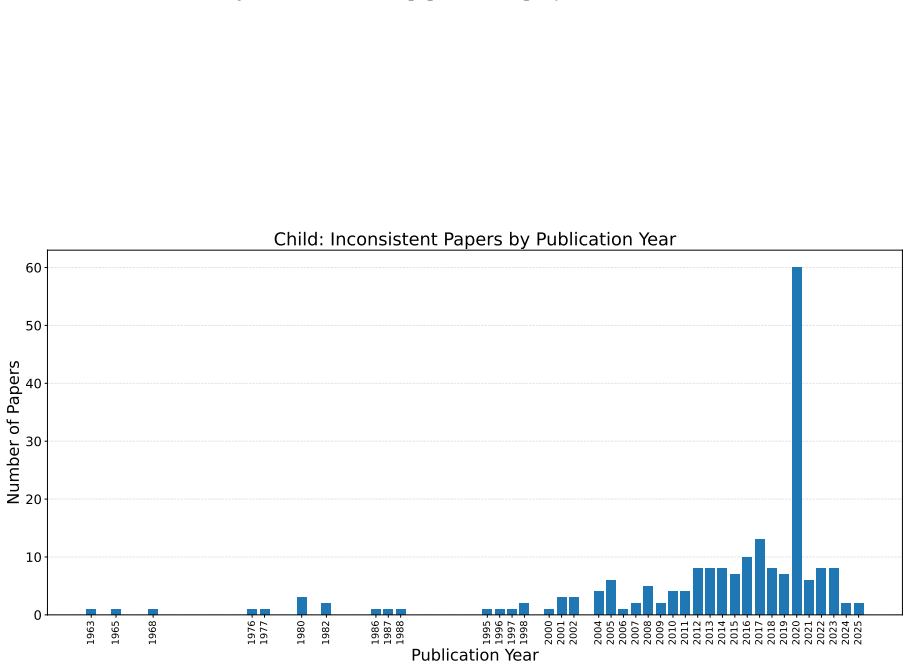
Child Original paper (Spiegelhalter, 1992) Papers using it: (Shen et al., 2025; Peyrard and West, 2020; Olko et al., 2023; Wang et al., 2025a, 2024; Vashishtha et al., 2025; Duong et al., 2025; Ke et al., 2022; Lippe et al., 2021; Guo et al., 2024a; Zhang et al., 2023b, 2022; Wang et al., 2022; Ling et al., 2025b; Guo et al., 2024b; Cui et al., 2022)
1992
-
[20]
Alarm Original paper (Beinlich et al., 1989) Papers using it: (Akbari et al., 2021; Roy et al., 2025; Xie et al., 2024; Li et al., 2022; Olko et al., 2023; Wang et al., 2025a; Duong et al., 2025; Lippe et al., 2021; Guo et al., 2024a; Zhang et al., 2023b, 2022; Wang et al., 2022; Zhang et al., 2021; Ling et al., 2025b; Guo et al., 2024b; Cui et al., 2022)
1989
-
[21]
Asia Original paper (lau, 1988) Papers using it: (Shen et al., 2025; Roy et al., 2025; Shahverdikondori et al., 2024; Olko et al., 2023; Kocaoglu, 2023; Addanki and Kasiviswanathan, 2021; Vashishtha et al., 2025; Duong et al., 2025; Ke et al., 2022; Lippe et al., 2021; Bellot et al., 2024; Zhang et al., 2023b, 2022)
1988
-
[22]
Insurance Original paper (Binder et al., 1997) Papers using it: (Mokhtarian et al., 2023; Akbari et al., 2021; Feng et al., 2025a,b; Peyrard and West, 2020; Wang et al., 2025a; Guo et al., 2024a; Zhang et al., 2022; Wang et al., 2022; Zhang et al., 2021; Guo et al., 2024b; Cui et al., 2022)
1997
-
[23]
Cancer Original paper (Korb and Nicholson, 2010) Papers using it: (Feng et al., 2025a,b; Shahverdikondori et al., 2024; Peyrard and West, 2020; Olko et al., 2023; Vashishtha et al., 2025; Duong et al., 2025; Lippe et al., 2021; Zhang et al., 2023b, 2022)
2010
-
[24]
Barley Original paper (Kristensen and Rasmussen, 2002) Papers using it: (Akbari et al., 2021; Wang et al., 2025a; Ling et al., 2025c; Zhang et al., 2022, 2021; Ling et al., 2025b)
2002
-
[25]
Hailfinder Original paper (Abramson et al., 1996) Papers using it: (Mokhtarian et al., 2023; Akbari et al., 2021; Li et al., 2022; Zhang et al., 2021; Ling et al., 2025b; Cui et al., 2022)
1996
-
[26]
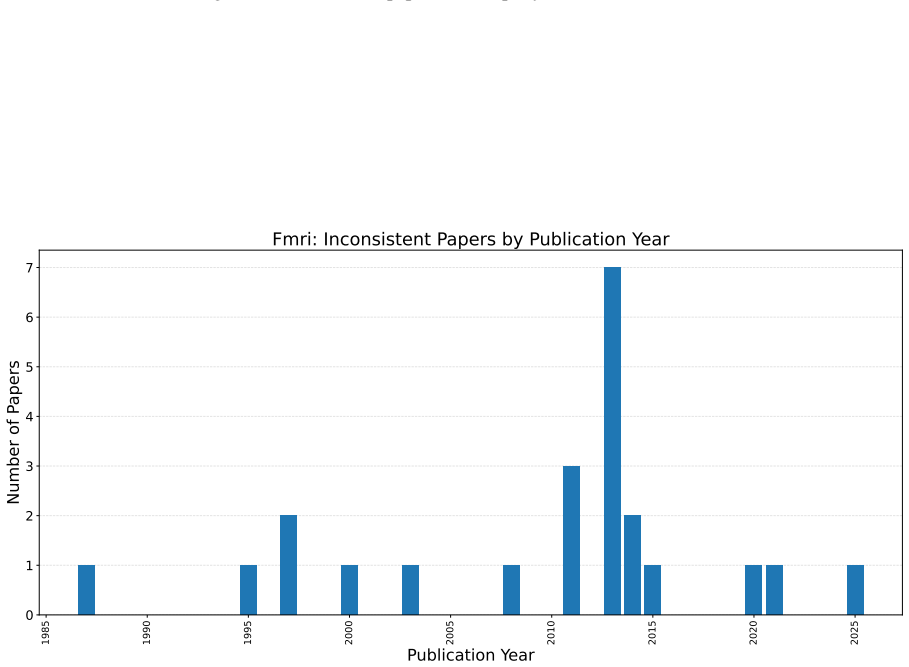
Fmri hippocampus Original paper (Poldrack et al., 2015) Papers using it: (Li et al., 2024b; Chen et al., 2024; Zeng et al., 2021)
2015
-
[27]
Alzheimer Original paper (Petersen et al., 2010; Shen et al., 2020) Papers using it: (Abdulaal et al., 2024; Feng et al., 2025a; Vashishtha et al., 2025)
2010
-
[28]
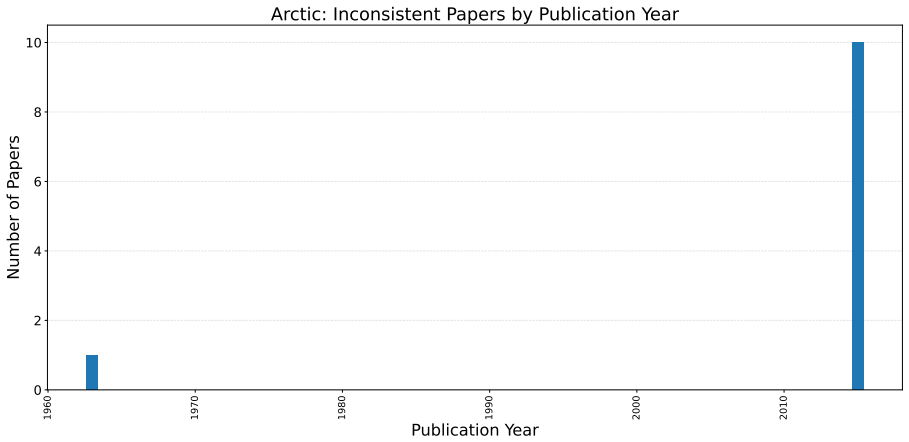
Arctic sea ice Original paper (Huang et al., 2021) Papers using it: (Abdulaal et al., 2024; Feng et al., 2025b; Kiciman et al., 2023) 17
2021
-
[29]
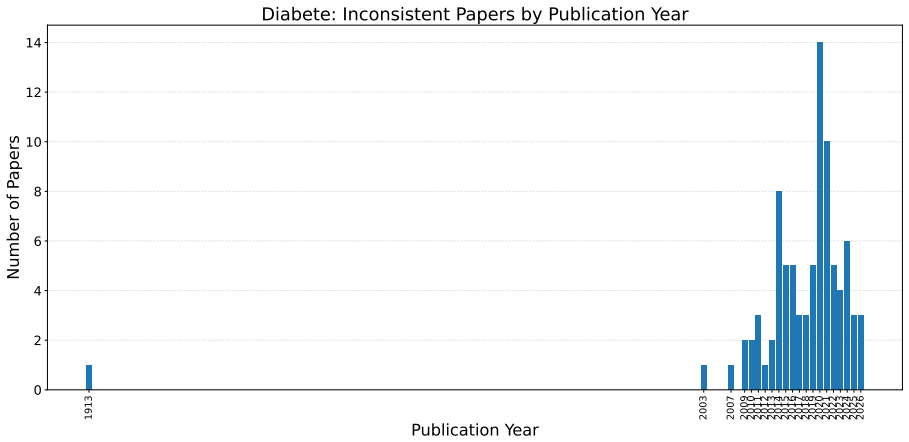
Diabetes Original paper (Long et al., 2022) Papers using it: (Feng et al., 2025a,b; Lippe et al., 2021)
2022
-
[30]
Ecoli70(100) Original paper (Schäfer and Strimmer, 2005) Papers using it: (Mokhtarian et al., 2023; Akbari et al., 2021; Kang et al., 2026; Chen et al., 2021)
2005
-
[31]
Gene expression Original paper (Sethuraman et al., 2023) Papers using it: (Guruswamy Sethuraman and Fekri, 2026; Xie et al., 2024; Li et al., 2025b; Guo et al., 2024a; Ling et al., 2025b)
2023
-
[32]
Hepar2 Original paper (Onisko, 2003) Papers using it: (Mokhtarian et al., 2023; Roy et al., 2025; Li et al., 2022)
2003
-
[33]
Pigs Original paper (FV, 1996) Papers using it: (Lippe et al., 2021; Guo et al., 2024a; Ling et al., 2025b)
1996
-
[34]
Reged Original paper (Statnikov et al., 2015) Papers using it: (Mian et al., 2021; Kaltenpoth and Vreeken, 2023; Guo et al., 2024b)
2015
-
[35]
Andes Original paper (Conati et al., 1997) Papers using it: (Xie et al., 2024; Li et al., 2022)
1997
-
[36]
Arth150 Original paper (Opgen-Rhein and Strimmer, 2007) Papers using it: (Mokhtarian et al., 2023; Akbari et al., 2021; Kang et al., 2026)
2007
-
[37]
Auto mpg Original paper (Quinlan, 1993) Papers using it: (Eulig et al., 2025; Shen et al., 2025)
1993
-
[38]
Carpo Original paper Link Papers using it: (Mokhtarian et al., 2023; Akbari et al., 2021)
2023
-
[39]
HK stock Original paper (Huang et al., 2020) Papers using it: (Li et al., 2024b; Cai et al., 2023)
2020
-
[40]
Link Original paper (Jensen and Kong, 1999) Papers using it: (Wang et al., 2022; Ling et al., 2025b)
1999
-
[41]
Mildew Original paper (Jensen and Jensen, 1996) Papers using it: (Xie et al., 2024; Li et al., 2022)
1996
-
[42]
Neuropain Original paper (Tu et al., 2019) Papers using it: (Liu et al., 2024a; Feng et al., 2025a; Kiciman et al., 2023; Vashishtha et al., 2025) 18
2019
-
[43]
Obesity Original paper (Long et al., 2022) Papers using it: (Feng et al., 2025a,b)
2022
-
[44]
Syntren Original paper (Van den Bulcke et al., 2006) Papers using it: (Dhir et al., 2024; Ling et al., 2025b)
2006
-
[45]
WIN95PTS Original paper (Heckerman et al., 1995) Papers using it: (Xie et al., 2024; Wang et al., 2022; Zhang et al., 2021)
1995
-
[46]
CE-Tueb Original paper (Mooij et al., 2016) Papers using it: (Dhir et al., 2023)
2016
-
[47]
CE-cha Original paper (Guyon et al., 2019) Papers using it: (Dhir et al., 2023)
2019
-
[48]
Cognition and Aging in the Chronic Fatigue Syndrome Original paper (Heins et al., 2013) Papers using it: (Qiao et al., 2024a)
2013
-
[49]
DWDClimate Original paper (Mooij et al., 2016) Papers using it: (Shen et al., 2025)
2016
-
[50]
MAGIC-IRRI Original paper (Scutari, 2016) Papers using it: (Kang et al., 2026)
2016
-
[51]
MAGIC-NIAB Original paper (Scutari et al., 2014) Papers using it: (Kang et al., 2026)
2014
-
[52]
New York Times Original paper Link Papers using it: (Liu et al., 2024a)
-
[53]
Pittsburgh Bridges Original paper (Reich and Fenves, 1989) Papers using it: (Ni, 2022)
1989
-
[54]
Categorical Cause-Effect Pairs Original paper (Ni, 2022) Papers using it: (Ni, 2022)
2022
-
[55]
Abalone Original paper (Warwick et al., 1994) Papers using it: (Ni, 2022)
1994
-
[56]
Alcohol Original paper (Long et al., 2022) Papers using it: (Feng et al., 2025b) 19
2022
-
[57]
Algibra I Original paper Link Papers using it: (Yu et al., 2024)
2024
-
[58]
APM Original paper Link Papers using it: (Eulig et al., 2025)
2025
-
[59]
Apple gastronome Original paper (Liu et al., 2024a) Papers using it: (Feng et al., 2025a)
-
[60]
Big five Original paper Link Papers using it: (Dai et al., 2025; Dong et al., 2024)
2025
-
[61]
Brain tumor Original paper Link Papers using it: (Liu et al., 2024a)
-
[62]
Chemical Original paper (Ke et al., 2021) Papers using it: (Zhao et al., 2025)
2021
-
[63]
(no?)Chemistry image Original paper (Schäfer and Strimmer, 2005) Papers using it: tba
2005
-
[64]
climatic analysis Original paper (Compo et al., 2011) Papers using it: (Liu et al., 2024a)
2011
-
[65]
COVID-19 Original paper Link Papers using it: (Wang et al., 2025b; Vashishtha et al., 2025)
2025
-
[66]
Credit Original paper (Quinlan, 1987) Papers using it: (Li et al., 2022)
1987
-
[67]
dream Original paper (Kalainathan and Goudet, 2019) Papers using it: (Roy et al., 2025)
2019
-
[68]
football Original paper Link Papers using it: (Qiao et al., 2024b)
-
[69]
G7 Original paper (Demirer et al., 2018) Papers using it: (Jalaldoust et al., 2022)
2018
-
[70]
General social survey Original paper Link Papers using it: (Li et al., 2025b) 20
-
[71]
IHDP Original paper (Hill, 2011) Papers using it: (Ashman et al., 2023)
2011
-
[72]
Lucas Original paper (Lucas et al., 2004) Papers using it: (Roy et al., 2025)
2004
-
[73]
Magnetic Original paper (Hwang et al., 2024) Papers using it: (Zhao et al., 2025)
2024
-
[74]
(tba)Micro24 Original paper (Schäfer and Strimmer, 2005) Papers using it: tba
2005
-
[75]
(tba)Micro25 Original paper (Schäfer and Strimmer, 2005) Papers using it: tba
2005
-
[76]
Munin Original paper (Andreassen et al., 1989) Papers using it: (Dong et al., 2025; Wang et al., 2022)
1989
-
[77]
Pacific walker circulation Original paper (Runge et al., 2019) Papers using it: (Liu and Kuang, 2023)
2019
-
[78]
Pathfinder Original paper (Heckerman et al., 1992) Papers using it: (Zhang et al., 2021)
1992
-
[79]
Pharmacokinetics Original paper (Grzegorzewski et al., 2021) Papers using it: (Li et al., 2024a)
2021
-
[80]
Physics Original paper (Lee et al., 2024) Papers using it: (Kang et al., 2026)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.