Boosting Multimodal Federated Learning via Chained Modality Optimization
Pith reviewed 2026-06-28 12:48 UTC · model grok-4.3
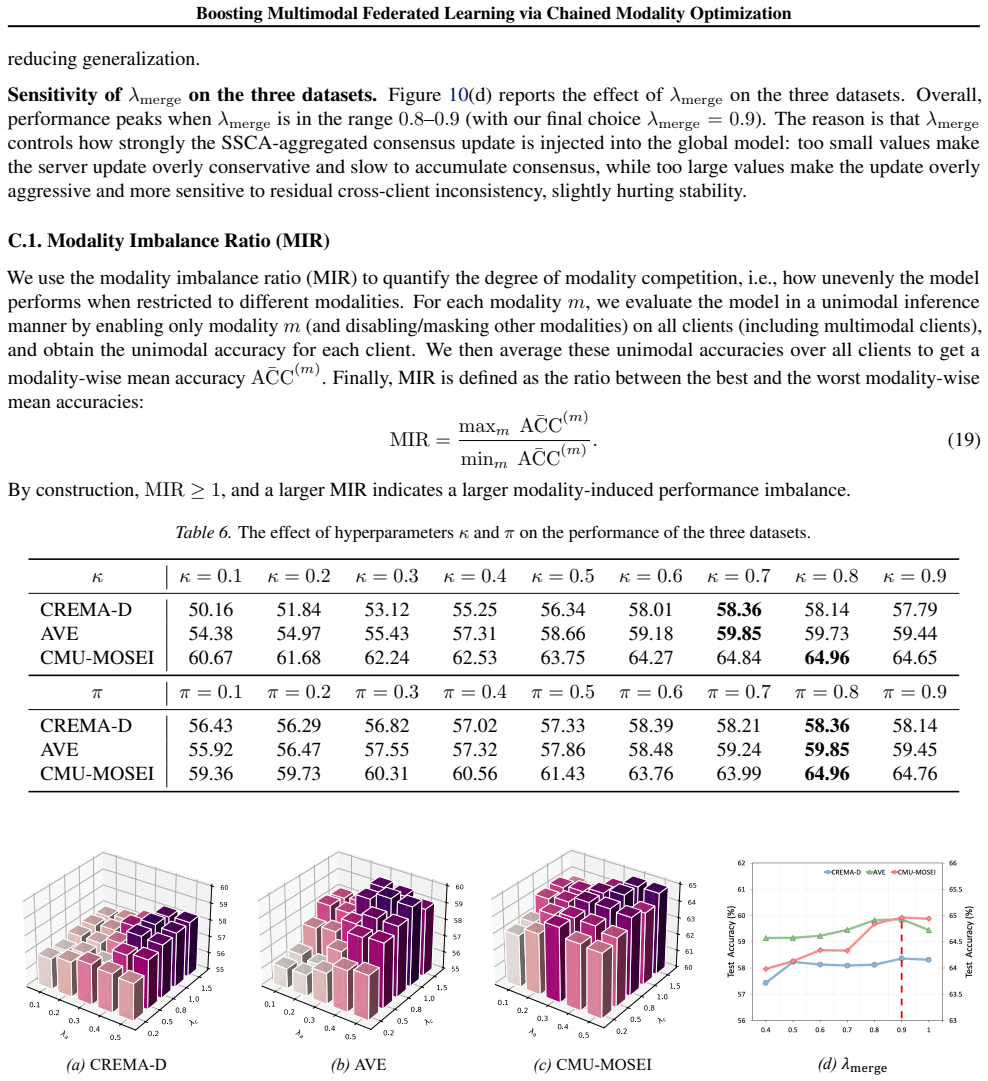
The pith
FedMChain structures multimodal federated learning as chained modality phases to reduce competition and cut communication overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
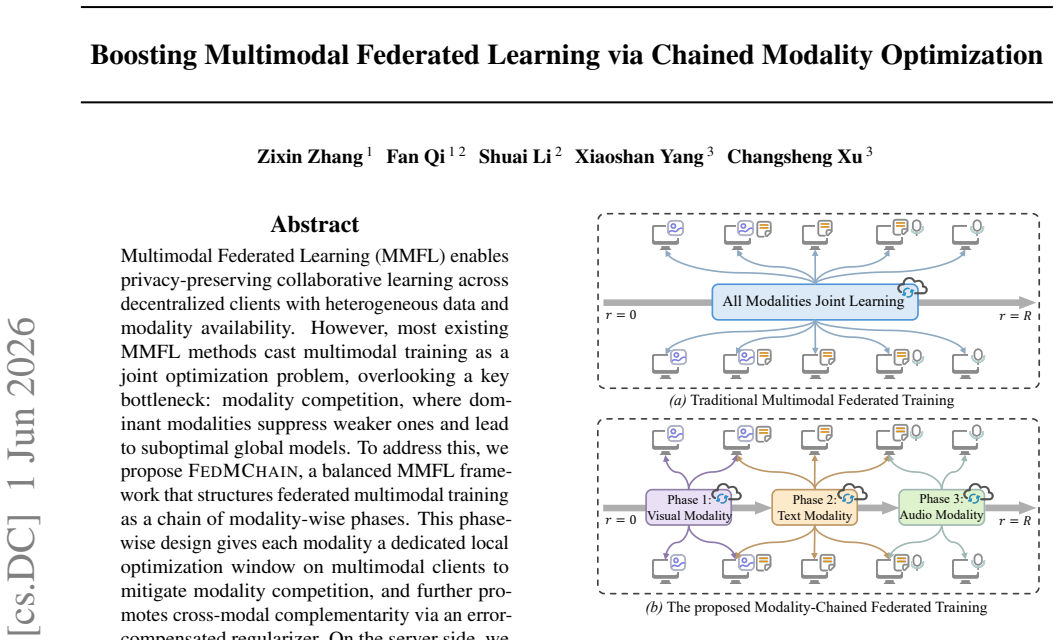
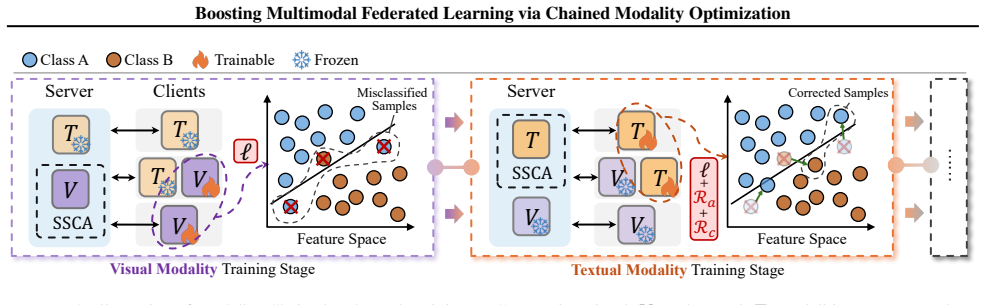
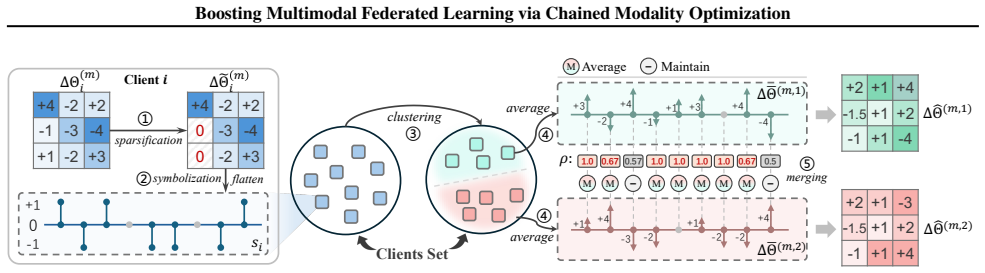
FedMChain structures federated multimodal training as a chain of modality-wise phases. This phase-wise design gives each modality a dedicated local optimization window on multimodal clients to mitigate modality competition, and further promotes cross-modal complementarity via an error-compensated regularizer. On the server side, a sparse sign-guided aggregation strategy leverages directional sign agreement for robust intra-modality aggregation, avoids destructive averaging, and supports less frequent synchronization to reduce communication overhead.
What carries the argument
Chained modality-wise optimization phases, paired with an error-compensated regularizer and sparse sign-guided aggregation.
If this is right
- Each modality receives a dedicated optimization window that limits suppression by stronger modalities.
- The error-compensated regularizer increases cross-modal complementarity during local training.
- Sparse sign-guided aggregation supports robust intra-modality combination and fewer synchronization steps.
- Predictive performance rises on multimodal benchmarks while communication frequency drops.
Where Pith is reading between the lines
- The chaining idea could extend to other heterogeneous client data distributions beyond modality types.
- Clients with missing modalities might be handled more gracefully by skipping the corresponding phase.
- The sign-guided aggregation rule may combine usefully with existing federated averaging variants.
Load-bearing premise
The assumption that dedicating separate local optimization phases to each modality will reliably mitigate competition and promote complementarity without creating new instabilities or suboptimal convergence in the global model.
What would settle it
Running the same multimodal benchmarks and finding that chained phases produce no accuracy gain or require more communication rounds than joint-optimization baselines would falsify the claim.
Figures

read the original abstract
Multimodal Federated Learning (MMFL) enables privacy-preserving collaborative learning across decentralized clients with heterogeneous data and modality availability. However, most existing MMFL methods cast multimodal training as a joint optimization problem, overlooking a key bottleneck: modality competition, where dominant modalities suppress weaker ones and lead to suboptimal global models. To address this, we propose FedMChain, a balanced MMFL framework that structures federated multimodal training as a chain of modality-wise phases. This phase-wise design gives each modality a dedicated local optimization window on multimodal clients to mitigate modality competition, and further promotes cross-modal complementarity via an error-compensated regularizer. On the server side, we employ a sparse sign-guided aggregation strategy that leverages directional sign agreement for robust intra-modality aggregation, avoids destructive averaging, and supports less frequent synchronization to reduce communication overhead. Extensive experiments on multimodal benchmarks demonstrate that FedMChain consistently improves predictive performance while requiring less frequent communication than baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FedMChain for multimodal federated learning (MMFL). It structures training as a chain of modality-wise local optimization phases to mitigate modality competition, augments this with an error-compensated regularizer to promote cross-modal complementarity, and applies sign-guided sparse aggregation on the server to support robust intra-modality updates and less frequent synchronization rounds. The central claim is that this yields improved predictive performance while reducing communication frequency relative to baselines on multimodal benchmarks.
Significance. If the empirical claims are substantiated with complete experimental protocols, the chained-phase design and sparse aggregation constitute a concrete methodological advance for handling modality imbalance in federated multimodal settings. The approach is presented as an explicit algorithmic choice rather than a fitted construction, which strengthens its potential utility for privacy-preserving multimodal applications.
major comments (2)
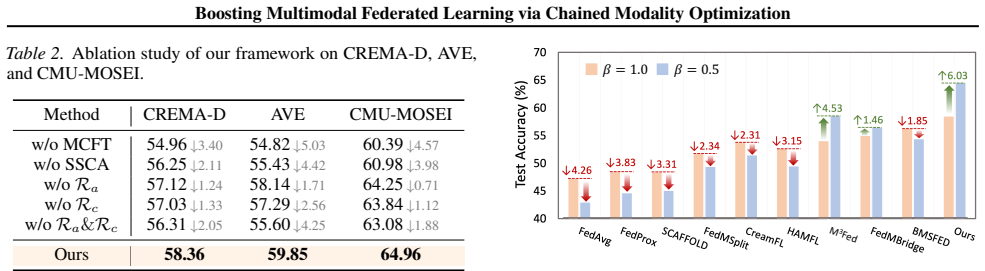
- [Abstract and §4] Abstract and §4 (Experiments): the central performance claim is stated without reported baselines, error bars, dataset splits, or statistical tests. This information is load-bearing for assessing whether FedMChain delivers consistent gains.
- [§3] §3 (Chained modality optimization): the assumption that dedicated per-modality local phases reliably reduce competition without introducing new convergence instabilities or suboptimal global-model equilibria is not accompanied by supporting analysis or ablation; this is the key modeling premise.
minor comments (2)
- [§3] Ensure the error-compensated regularizer and sign-guided aggregation are accompanied by explicit pseudocode or algorithmic listing for reproducibility.
- [§4] Clarify the precise definition of 'less frequent communication' (e.g., rounds per modality or total bits) when comparing against baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below with specific plans for revision where warranted.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central performance claim is stated without reported baselines, error bars, dataset splits, or statistical tests. This information is load-bearing for assessing whether FedMChain delivers consistent gains.
Authors: We agree that the experimental reporting requires greater completeness to substantiate the claims. In the revised manuscript we will expand §4 to list all baseline methods with citations, report mean performance with standard deviation error bars over at least five independent runs, specify the exact train/validation/test splits for each dataset, and include statistical significance tests (paired t-tests with p-values) comparing FedMChain against the strongest baselines. Corresponding clarifications will be added to the abstract. revision: yes
-
Referee: [§3] §3 (Chained modality optimization): the assumption that dedicated per-modality local phases reliably reduce competition without introducing new convergence instabilities or suboptimal global-model equilibria is not accompanied by supporting analysis or ablation; this is the key modeling premise.
Authors: The referee is correct that the modeling premise would benefit from explicit supporting evidence. We will insert a new subsection in §3 that provides a brief convergence argument based on the error-compensated regularizer and adds an ablation comparing chained-phase training against joint optimization. The ablation will report modality-wise contribution metrics, training loss curves, and final global-model accuracy to demonstrate that the phase-wise schedule reduces competition without inducing instabilities or inferior equilibria. revision: yes
Circularity Check
No significant circularity; design choices are explicit and non-reductive
full rationale
The paper introduces FedMChain as an explicit framework consisting of chained modality-wise local optimization phases, an error-compensated regularizer, and sign-guided sparse aggregation. These are presented as architectural decisions to address modality competition, not as outputs of a derivation or prediction that reduces to fitted inputs or prior self-citations. No equations, uniqueness theorems, or ansatzes are shown that loop back to the method's own definitions. The performance and communication claims rest on experimental benchmarks rather than any self-referential mathematical chain. This is the common case of a self-contained empirical method proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bao, G., Zhang, Q., Miao, D., Gong, Z., Hu, L., Liu, K., Liu, Y ., and Shi, C. Multimodal federated learning with missing modality via prototype mask and contrast.arXiv preprint arXiv:2312.13508,
-
[2]
J., Manoel, A., Joshi, G., Sim, R., and Dimitriadis, D
Cho, Y . J., Manoel, A., Joshi, G., Sim, R., and Dimitriadis, D. Heterogeneous ensemble knowledge transfer for train- ing large models in federated learning.arXiv preprint arXiv:2204.12703,
-
[3]
Small-footprint keyword spotting using deep neural networks
doi: 10.1109/ICASSP. 2014.6853739. Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding,
-
[4]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
URL https://arxiv. org/abs/1810.04805. Du, C., Teng, J., Li, T., Liu, Y ., Yuan, T., Wang, Y ., Yuan, Y ., and Zhao, H. On uni-modal feature learning in supervised multi-modal learning. InInternational Conference on Machine Learning, pp. 8632–8656. PMLR, 2023a. Du, C., Teng, J., Li, T., Liu, Y ., Yuan, T., Wang, Y ., Yuan, Y ., and Zhao, H. On uni-modal f...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Overcome modal bias in multi-modal federated learning via balanced modality selection, 2024a
Fan, Y ., Xu, W., Wang, H., Huo, F., Chen, J., and Guo, S. Overcome modal bias in multi-modal federated learning via balanced modality selection, 2024a. URL https: //arxiv.org/abs/2401.00403. Fan, Y ., Xu, W., Wang, H., Liu, J., and Guo, S. Detached and interactive multimodal learning. InProceedings of the 32nd ACM International Conference on Multimedia, ...
- [6]
-
[7]
Reconboost: Boosting can achieve modality reconcilement,
Hua, C., Xu, Q., Bao, S., Yang, Z., and Huang, Q. Re- conboost: Boosting can achieve modality reconcilement. arXiv preprint arXiv:2405.09321,
-
[8]
URLhttps://arxiv.org/abs/2203.12221. Hwang, S.-H., Choi, S., and Whang, S. E. Midas: Misalignment-based data augmentation strategy for im- balanced multimodal learning,
-
[9]
Jiang, Q.-Y ., Chi, Z., and Yang, Y
URL https: //arxiv.org/abs/2509.25831. Jiang, Q.-Y ., Chi, Z., and Yang, Y . Multimodal classification via modal-aware interactive enhancement.arXiv preprint arXiv:2407.04587,
-
[10]
Le, H. Q., Thwal, C. M., Qiao, Y ., Tun, Y . L., Nguyen, M. N., and Hong, C. S. Cross-modal prototype based multimodal federated learning under severely missing modality.arXiv preprint arXiv:2401.13898,
-
[11]
Orzikulova, A., Kwak, J., Shin, J., and Lee, S.-J. Federated learning for time-series healthcare sensing with incom- plete modalities.arXiv preprint arXiv:2405.11828,
-
[12]
Balanced multimodal learning via on-the-fly gradient modulation
Peng, X., Wei, Y ., Deng, A., Wang, D., and Hu, D. Balanced multimodal learning via on-the-fly gradient modulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8238–8247, 2022a. Peng, X., Wei, Y ., Deng, A., Wang, D., and Hu, D. Bal- anced multimodal learning via on-the-fly gradient mod- ulation, 2022b. URL htt...
- [13]
-
[14]
Local SGD Converges Fast and Communicates Little
URL https://openreview. net/forum?id=S1g2JnRcFX. arXiv:1805.09767. Tian, Y ., Shi, J., Li, B., Duan, Z., and Xu, C. Audio- visual event localization in unconstrained videos. In Proceedings of the European conference on computer vision (ECCV), pp. 247–263,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Wei, Y . and Hu, D. Mmpareto: Boosting multimodal learn- ing with innocent unimodal assistance.arXiv preprint arXiv:2405.17730,
-
[16]
URL https://ojs.aaai. org/index.php/AAAI/article/view/4514. arXiv:1807.06629. Yu, Q., Liu, Y ., Wang, Y ., Xu, K., and Liu, J. Multimodal federated learning via contrastive representation ensem- ble.arXiv preprint arXiv:2302.08888,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
URLhttps://arxiv.org/abs/2310.07048. Zadeh, A. B., Liang, P. P., Poria, S., Cambria, E., and Morency, L.-P. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fu- sion graph. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2236–2246,
-
[18]
Open-vocabulary federated learning with multimodal prototyping.arXiv preprint arXiv:2404.01232,
10 Boosting Multimodal Federated Learning via Chained Modality Optimization Zeng, H., Yue, Z., and Wang, D. Open-vocabulary federated learning with multimodal prototyping.arXiv preprint arXiv:2404.01232,
-
[19]
Zhang, H., Li, Y ., and Li, X. Constrained bipartite graph learning for imbalanced multi-modal retrieval.IEEE Transactions on Multimedia, 26:4502–4514, 2023a. Zhang, R., Chi, X., Liu, G., Zhang, W., Du, Y ., and Wang, F. Unimodal training-multimodal prediction: Cross-modal federated learning with hierarchical aggregation.arXiv preprint arXiv:2303.15486, 2...
-
[20]
(74 dimensions), respectively. These features are passed through modality-specific encoders to produce 128-dimensional latent representations. In particular, AudioNet and VisualNet adopt a three-layer MLP backbone, where each layer is followed by ReLU, dropout, and layer normalization, and then a linear layer is used to output modality-specific prediction...
-
[21]
round-start ideal
Lemma D.8( E-step local progress bound).Under the conditions of Lemma D.7, for any client i and any aggregation round r, E−1X s=0 E ∇f(m) i (Θs i,r) 2 ≤ 2 η Ef(m) i (Θr)−Ef (m) i (ΘE i,r) +LηEσ 2.(29) Proof.Apply Lemma D.7 to eachs= 0, . . . ,E −1and sum. Rearrange terms. D.4. Local drift under periodic aggregation Define the “round-start ideal” local upd...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.