Improving LLM-Based Go Code Review through Issue-List Generation and Context Augmentation
Pith reviewed 2026-06-28 13:52 UTC · model grok-4.3
The pith
Issue-list generation plus neighboring and co-change context lifts LLM Go code review to 28% refinement exact match.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
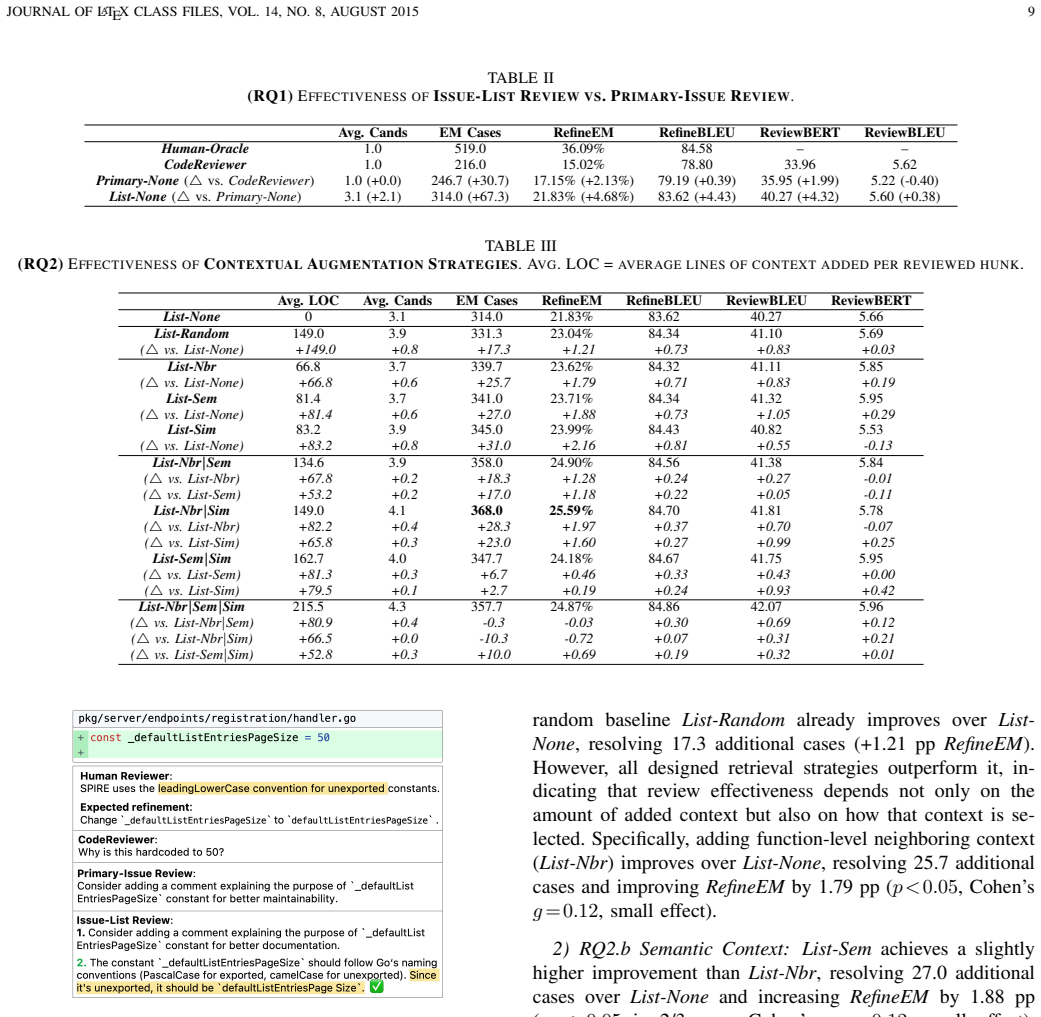
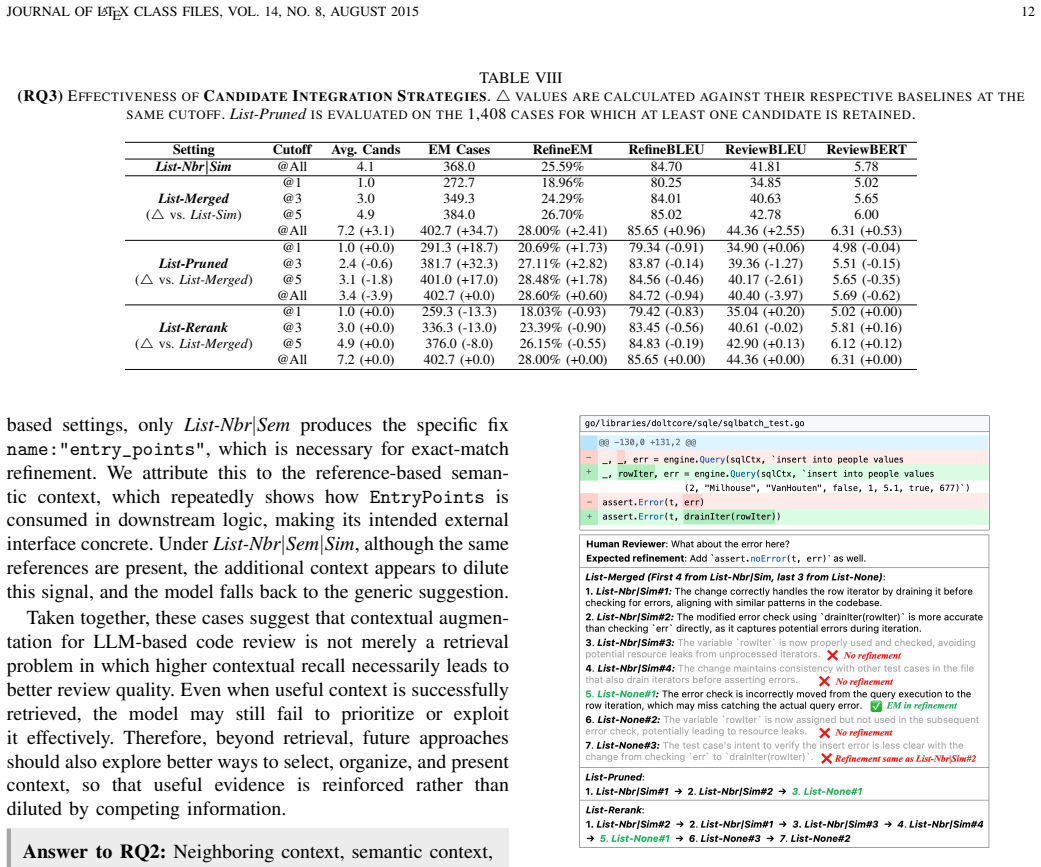
By shifting from primary-issue review to issue-list review and incorporating neighboring and similar co-change context, followed by integrating candidates and applying refinement-guided pruning, the approach achieves 28.00% refinement exact match on 1,438 Go review instances. This represents a statistically significant improvement of 10.85 percentage points over the 17.15% from primary-issue review without context. It also outperforms the specialized CodeReviewer model at 15.02% and approaches the human oracle at 36.09%, while pruning reduces average candidates to 3.1.
What carries the argument
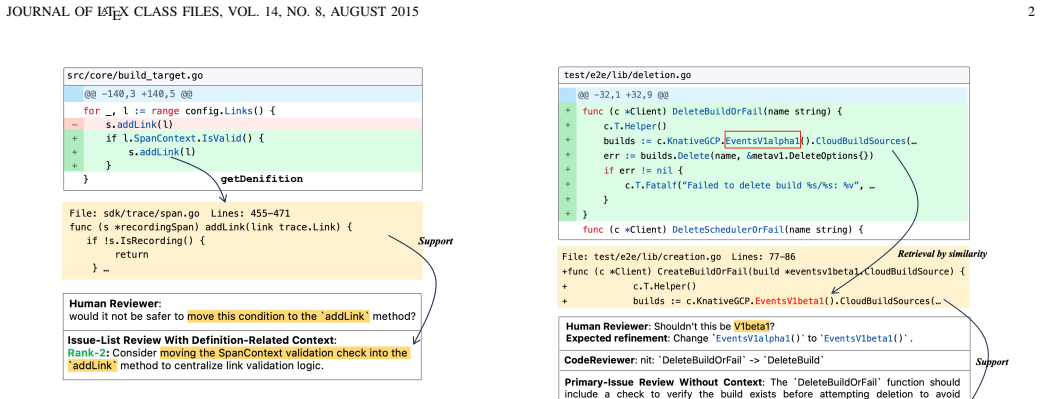
The issue-list review paradigm that has LLMs enumerate multiple potential issues, augmented by neighboring code context and IR-based similar co-change context, with refinement-guided pruning of integrated candidate lists.
If this is right
- More issues are identified when LLMs are prompted to list all potential problems rather than focusing on one.
- Neighboring and similar co-change contexts enhance the discovery of relevant issues in code reviews.
- Integrating outputs from context-free and context-enhanced generations improves overall review coverage.
- Refinement-guided pruning maintains most of the performance benefit while reducing the number of candidates developers must inspect.
Where Pith is reading between the lines
- The same prompting and pruning pattern could be tested on review data from languages other than Go to check whether the gains transfer.
- The refinement exact-match signal could be used directly as a reward during fine-tuning of review models.
- Embedding the pruned candidate lists inside an IDE might let developers accept or reject suggestions before the change is committed.
Load-bearing premise
That whether a generated comment would produce the same code change a human ultimately made is a sufficient measure of how useful the comment is in practice.
What would settle it
A controlled experiment in which developers are shown both the generated comment lists and the actual human comments, then asked which list they would rather receive, would show whether the refinement metric aligns with developer preference.
Figures




read the original abstract
LLMs have shown strong potential for automating code review, yet their practical utility depends heavily on the design of generation and context strategies. In this paper, we investigate how to improve LLM-based code review through generation strategy and contextual augmentation. We first propose an issue-list review paradigm, in which LLMs enumerate all potential issues rather than reporting only the single most important one (i.e., primary-issue review). We then systematically compare three types of code context augmentation -- neighboring, LSP-based semantics, and IR-based similar co-change context -- and study how they influence issue discovery. Finally, we integrate candidates from no-context and context-enhanced generation to improve review coverage, and introduce refinement-guided pruning to keep the candidate list at a practical size. We evaluate our approach on 1,438 Go review instances using downstream code refinement as the main metric, i.e., how often the candidate list contains at least one comment inducing the same code change as the final human revision. For comparison, we evaluate comments by CodeReviewer, a model trained specifically for review comment generation, as well as ground-truth human review comments (as a practical upper bound), under the same refinement-based evaluation. The results show that our best configuration, combining issue-list review, neighboring and similar co-change context, and candidate integration, reaches 28.00% refinement exact match, a statistically significant gain of +10.85 percentage points over primary-issue review without any additional context (17.15%), substantially outperforming CodeReviewer (15.02%) and approaching the human-oracle ceiling of 36.09%. Our refinement-guided pruning reduces the average candidate count from 7.2 to 3.1 at top-5 while retaining nearly the full benefit, making the candidate list easier to inspect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that shifting from primary-issue to issue-list review, augmenting with neighboring and similar co-change context, integrating candidates across configurations, and applying refinement-guided pruning improves LLM-generated Go code review comments. On 1,438 instances this yields 28.00% refinement exact match (a statistically significant +10.85 pp gain over the 17.15% no-context baseline), outperforming CodeReviewer (15.02%) while approaching the human-oracle ceiling of 36.09%.
Significance. If the central empirical result holds, the work supplies concrete, immediately usable prompting and context strategies that raise the fraction of LLM review comments capable of triggering the same edit as a human revision. The evaluation scale, direct comparison against a fine-tuned baseline, and explicit human upper bound are positive features; the pruning result that reduces candidate volume while preserving most of the gain is also a practical contribution.
major comments (1)
- [Evaluation] Evaluation (refinement exact match definition and human-oracle result): the primary success criterion treats 'contains at least one comment inducing the same code change as the final human revision' as the key indicator of usefulness. The reported human-oracle ceiling of only 36.09% already shows that many ground-truth comments fail the metric; without an additional human usefulness rating or inter-rater study on the generated comments, the +10.85 pp gain could be an artifact of the chosen proxy rather than evidence of improved review quality.
minor comments (1)
- [Abstract] Abstract: the claim of 'statistically significant gain' is stated without naming the test, exact p-value, or correction method; these details belong in the abstract or a methods footnote for immediate verifiability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation design. Below we address the major comment directly.
read point-by-point responses
-
Referee: [Evaluation] Evaluation (refinement exact match definition and human-oracle result): the primary success criterion treats 'contains at least one comment inducing the same code change as the final human revision' as the key indicator of usefulness. The reported human-oracle ceiling of only 36.09% already shows that many ground-truth comments fail the metric; without an additional human usefulness rating or inter-rater study on the generated comments, the +10.85 pp gain could be an artifact of the chosen proxy rather than evidence of improved review quality.
Authors: We selected refinement exact match as the primary metric because it supplies an objective, reproducible, and downstream-oriented measure: whether a generated comment would have produced the identical code edit that the human revision ultimately applied. This avoids subjective interpretation while directly quantifying practical utility for the code-review workflow. The 36.09% human-oracle ceiling is reported precisely to make the metric's limitations transparent; it indicates that many human comments address issues orthogonal to the final change (e.g., rejected suggestions or stylistic remarks) rather than invalidating the proxy. All comparisons (our configurations, the no-context baseline, and CodeReviewer) are performed under identical conditions, and the reported +10.85 pp gain is statistically significant. We therefore view the improvement as evidence that the proposed strategies increase the likelihood of surfacing comments aligned with observed human edits. While additional human usefulness ratings would be informative, they are not required to demonstrate relative gains under a consistent, automated criterion already used in prior code-review automation studies. revision: no
Circularity Check
No circularity; purely empirical comparison of strategies
full rationale
The paper conducts an empirical evaluation of prompting paradigms (issue-list vs primary-issue) and context augmentations on 1,438 Go review instances, measuring refinement exact match against human revisions and baselines (CodeReviewer, human oracle). No equations, parameter fits, derivations, or self-citation chains appear; all claims rest on direct experimental outcomes with external benchmarks. The metric choice is an explicit design decision, not a self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Convergent contemporary software peer review practices,
P. C. Rigby and C. Bird, “Convergent contemporary software peer review practices,” inProceedings of the 2013 9th joint meeting on foundations of software engineering, 2013, pp. 202–212
2013
-
[2]
What types of defects are really dis- covered in code reviews?
M. V . M ¨antyl¨a and C. Lassenius, “What types of defects are really dis- covered in code reviews?”IEEE Transactions on Software Engineering, vol. 35, no. 3, pp. 430–448, 2008
2008
-
[3]
Modern code reviews in open-source projects: which problems do they fix?
M. Beller, A. Bacchelli, A. Zaidman, and E. J ¨urgens, “Modern code reviews in open-source projects: which problems do they fix?” in 11th Working Conference on Mining Software Repositories, MSR 2014, Proceedings, May 31 - June 1, 2014, Hyderabad, India, P. T. Devanbu, S. Kim, and M. Pinzger, Eds. ACM, 2014, pp. 202–211. [Online]. Available: https://doi.or...
-
[4]
What makes a code review useful to opendev developers? an empirical investigation,
A. K. Turzo and A. Bosu, “What makes a code review useful to opendev developers? an empirical investigation,”Empirical Software Engineering, vol. 29, no. 1, p. 6, 2024
2024
-
[5]
An empirical study of the impact of modern code review practices on software quality,
S. McIntosh, Y . Kamei, B. Adams, and A. E. Hassan, “An empirical study of the impact of modern code review practices on software quality,”Empirical Software Engineering, vol. 21, no. 5, pp. 2146–2189, 2016
2016
-
[6]
Potential technical debt and its resolution in code reviews: An exploratory study of the openstack and qt communities,
L. Fu, P. Liang, Z. Rasheed, Z. Li, A. Tahir, and X. Han, “Potential technical debt and its resolution in code reviews: An exploratory study of the openstack and qt communities,” inProceedings of the 16th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, 2022, pp. 216–226
2022
-
[7]
Expectations, outcomes, and challenges of modern code review,
A. Bacchelli and C. Bird, “Expectations, outcomes, and challenges of modern code review,” in2013 35th international conference on software engineering (ICSE). IEEE, 2013, pp. 712–721
2013
-
[8]
On the scalability of linux kernel maintainers’ work,
M. Zhou, Q. Chen, A. Mockus, and F. Wu, “On the scalability of linux kernel maintainers’ work,” inProceedings of the 2017 11th joint meeting on foundations of software engineering, 2017, pp. 27–37
2017
-
[9]
Using static analysis to find bugs,
N. Ayewah, W. Pugh, D. Hovemeyer, J. D. Morgenthaler, and J. Penix, “Using static analysis to find bugs,”IEEE software, vol. 25, no. 5, pp. 22–29, 2008
2008
-
[10]
Automating code review activities by large-scale pre-training,
Z. Li, S. Lu, D. Guo, N. Duan, S. Jannu, G. Jenks, D. Majumder, J. Green, A. Svyatkovskiy, S. Fuet al., “Automating code review activities by large-scale pre-training,” inProceedings of the 30th ACM joint European software engineering conference and symposium on the foundations of software engineering, 2022, pp. 1035–1047
2022
-
[11]
Using pre-trained models to boost code review automa- tion,
R. Tufano, S. Masiero, A. Mastropaolo, L. Pascarella, D. Poshyvanyk, and G. Bavota, “Using pre-trained models to boost code review automa- tion,” inProceedings of the 44th international conference on software engineering, 2022, pp. 2291–2302
2022
-
[12]
Large language models for software engi- neering: A systematic literature review,
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang, “Large language models for software engi- neering: A systematic literature review,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 8, pp. 1–79, 2024
2024
-
[13]
Automated code review in practice,
U. Cihan, V . Haratian, A. ˙Ic ¸¨oz, M. K. G ¨ul, ¨O. Devran, E. F. Bayendur, B. M. Uc ¸ar, and E. T¨uz¨un, “Automated code review in practice,” in2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 2025, pp. 425– 436
2025
-
[14]
Does ai code review lead to code changes? a case study of github actions,
K. Sun, H. Kuang, S. Baltes, X. Zhou, H. Zhang, X. Ma, G. Rong, D. Shao, and C. Treude, “Does ai code review lead to code changes? a case study of github actions,”IEEE Transactions on Software Engi- neering, 2026
2026
-
[15]
Assessing the students’ understanding and their mistakes in code review checklists: an experience report of 1,791 code review checklist questions from 394 students,
C. Y . Chong, P. Thongtanunam, and C. Tantithamthavorn, “Assessing the students’ understanding and their mistakes in code review checklists: an experience report of 1,791 code review checklist questions from 394 students,” in2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering Education and Training (ICSE-SEET). IEEE, ...
2021
-
[16]
What to look for in a code review,
Google, “What to look for in a code review,” https://google.github.io/ eng-practices/review/reviewer/looking-for.html, 2024, accessed: 2026- 04-15
2024
-
[17]
Deepcrceval: Revisiting the evaluation of code review comment generation,
J. Lu, X. Li, Z. Hua, L. Yu, S. Cheng, L. Yang, F. Zhang, and C. Zuo, “Deepcrceval: Revisiting the evaluation of code review comment generation,” inInternational Conference on Fundamental Approaches to Software Engineering. Springer, 2025, pp. 43–64
2025
-
[18]
Crscore: Grounding automated evaluation of code review comments in code claims and smells,
A. Naik, M. Alenius, D. Fried, and C. Rose, “Crscore: Grounding automated evaluation of code review comments in code claims and smells,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 9049–9076
2025
-
[19]
Replication package for LLMGoCodeReview,
Anonymous, “Replication package for LLMGoCodeReview,” To be pub- lished on Zenodo after acceptance. https://github.com/brinnarlyne8585/ LLMGoCodeReview, 2026
2026
-
[20]
Tree-sitter: A parser generator tool and an incremental parsing library,
M. Brunsfeldet al., “Tree-sitter: A parser generator tool and an incremental parsing library,” https://tree-sitter.github.io/tree-sitter/, 2026, accessed: 2026-03
2026
-
[21]
DeepSeek-AI, “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024. [Online]. Available: https://arxiv.org/abs/ 2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
gopls: The go language server,
Go Team, “gopls: The go language server,” https://github.com/golang/ tools/tree/master/gopls, 2026
2026
-
[23]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” inProceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
2002
-
[24]
Bertscore: Evaluating text generation with BERT,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with BERT,” in8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020. [Online]. Available: https://openreview.net/forum?id=SkeHuCVFDr
2020
-
[25]
Unixcoder: Unified cross-modal pre-training for code representation,
D. Guo, S. Lu, N. Duan, Y . Wang, M. Zhou, and J. Yin, “Unixcoder: Unified cross-modal pre-training for code representation,” inProceed- ings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 7212–7225
2022
-
[26]
Note on the sampling error of the difference between correlated proportions or percentages,
Q. McNemar, “Note on the sampling error of the difference between correlated proportions or percentages,”Psychometrika, vol. 12, no. 2, pp. 153–157, 1947
1947
-
[27]
Cohen,Statistical power analysis for the behavioral sciences
J. Cohen,Statistical power analysis for the behavioral sciences. rout- ledge, 2013
2013
-
[28]
Classifying change types for qualifying change couplings,
B. Fluri and H. C. Gall, “Classifying change types for qualifying change couplings,” in14th IEEE International Conference on Program Comprehension (ICPC’06). IEEE, 2006, pp. 35–45
2006
-
[29]
Change distilling: Tree differencing for fine-grained source code change extraction,
B. Fluri, M. Wursch, M. PInzger, and H. Gall, “Change distilling: Tree differencing for fine-grained source code change extraction,”IEEE Transactions on software engineering, vol. 33, no. 11, pp. 725–743, 2007
2007
-
[30]
Fine-tuning and prompt en- gineering for large language models-based code review automation,
C. Pornprasit and C. Tantithamthavorn, “Fine-tuning and prompt en- gineering for large language models-based code review automation,” Information and Software Technology, vol. 175, p. 107523, 2024
2024
-
[31]
The code review comprehension assessment for large language models,
H. Y . Lin, C. Liu, H. Gao, P. Thongtanunam, and C. Treude, “The code review comprehension assessment for large language models,” in Findings of the Association for Computational Linguistics: ACL 2025, 2025
2025
-
[32]
Towards automating code review at scale,
V . J. Hellendoorn, J. Tsay, M. Mukherjee, and M. Hirzel, “Towards automating code review at scale,” inProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2021, pp. 1479–1482
2021
-
[33]
Auger: automatically generating review comments with pre-training models,
L. Li, L. Yang, H. Jiang, J. Yan, T. Luo, Z. Hua, G. Liang, and C. Zuo, “Auger: automatically generating review comments with pre-training models,” inProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2022, pp. 1009–1021
2022
-
[34]
Improving automated code reviews: Learning from experience,
H. Y . Lin, P. Thongtanunam, C. Treude, and W. Charoenwet, “Improving automated code reviews: Learning from experience,” inProceedings of the 21st International Conference on Mining Software Repositories, 2024, pp. 278–283
2024
-
[35]
Augmenting large language models with static code analysis for automated code quality improvements,
S. M. Abtahi and A. Azim, “Augmenting large language models with static code analysis for automated code quality improvements,” in2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge). IEEE, 2025, pp. 82–92
2025
-
[36]
Llama-reviewer: Advancing code review automation with large language models through parameter- efficient fine-tuning,
J. Lu, L. Yu, X. Li, L. Yang, and C. Zuo, “Llama-reviewer: Advancing code review automation with large language models through parameter- efficient fine-tuning,” in2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2023, pp. 647–658
2023
-
[37]
Fine-tuning large language models to improve accuracy and comprehensibility of automated code review,
Y . Yu, G. Rong, H. Shen, H. Zhang, D. Shao, M. Wang, Z. Wei, Y . Xu, and J. Wang, “Fine-tuning large language models to improve accuracy and comprehensibility of automated code review,”ACM transactions on software engineering and methodology, vol. 34, no. 1, pp. 1–26, 2024
2024
-
[38]
Laura: Enhanc- ing code review generation with context-enriched retrieval-augmented llm,
Y . Zhang, Y . Zhang, Z. Sun, Y . Jiang, and H. Liu, “Laura: Enhanc- ing code review generation with context-enriched retrieval-augmented llm,” in2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2025, pp. 2983–2995
2025
-
[39]
icodereviewer: Improving secure code review with mixture of prompts,
Y . Peng, K. Kim, L. Meng, and K. Liu, “icodereviewer: Improving secure code review with mixture of prompts,” in2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2025, pp. 3204–3215
2025
-
[40]
Bitsai-cr: Automated code review via llm in practice,
T. Sun, J. Xu, Y . Li, Z. Yan, G. Zhang, L. Xie, L. Geng, Z. Wang, Y . Chen, Q. Linet al., “Bitsai-cr: Automated code review via llm in practice,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, 2025, pp. 274–285
2025
-
[41]
Cr-bench: Evaluating the real-world utility of ai code review agents,
K. Pereira, N. Sinha, R. Ghosh, and D. Dutta, “Cr-bench: Evaluating the real-world utility of ai code review agents,”arXiv preprint arXiv:2603.11078, 2026. [Online]. Available: https://arxiv.org/pdf/2603. 11078
-
[42]
Y . Zhang, Z. Pan, I. N. B. Yusuf, H. Ruan, R. Shariffdeen, and A. Roychoudhury, “Code review agent benchmark,”arXiv preprint arXiv:2603.23448, 2026. [Online]. Available: https://arxiv.org/abs/2603. 23448
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.