SMH-Bench: Benchmarking LLM Agents for Environment-Grounded Reasoning and Action in Smart Homes
Pith reviewed 2026-06-28 14:41 UTC · model grok-4.3
The pith
Frontier LLMs handle explicit smart-home commands well but show clear gaps in scheduling, ambiguity resolution, and personalization as home complexity rises.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
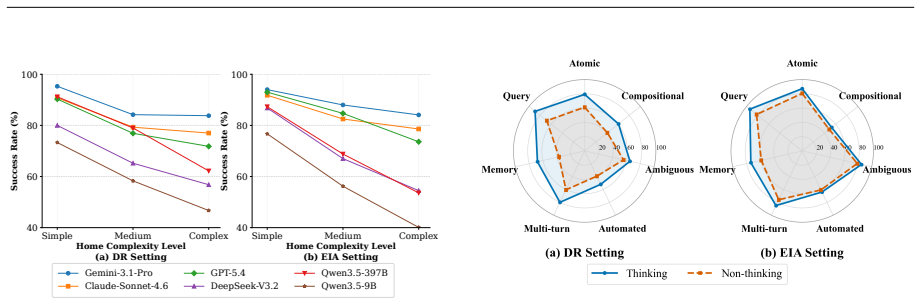
SMH-Bench shows that although frontier LLMs achieve strong performance on explicit control and query tasks, they still exhibit significant weaknesses in automation task scheduling, ambiguity handling and personalized reasoning, especially as home complexity increases from small apartments to dense multi-room environments with 135 devices.
What carries the argument
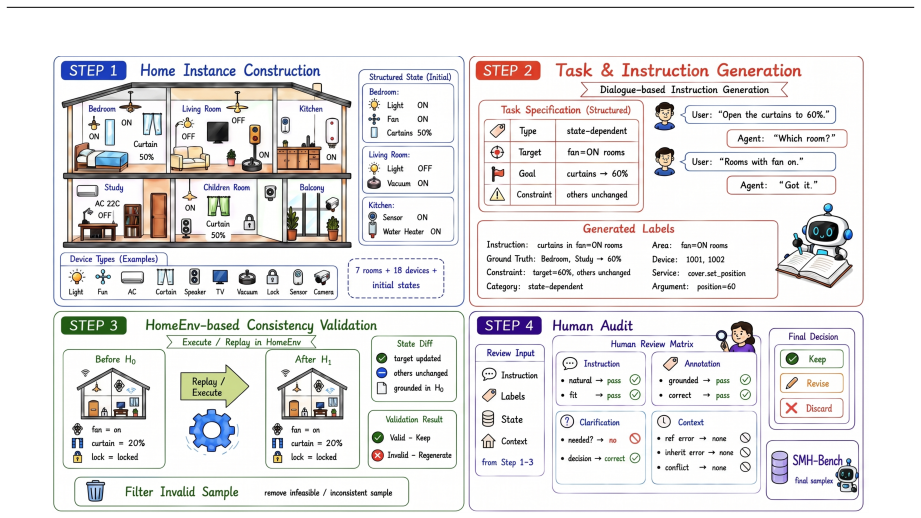
SMH-Bench, a collection of 1,100 tasks in seven categories and 22 subcategories executed inside the HomeEnv simulator and stratified by simple, medium, and complex home layouts.
If this is right
- Reliable smart-home agents will require dedicated improvements in long-horizon planning and preference modeling.
- Performance drops with device count imply that scaling laws alone will not close the observed gaps.
- Ambiguity handling must be treated as a distinct evaluation axis rather than assumed to follow from general instruction following.
- Benchmarks that stratify by environment size can serve as progress measures for iterative agent development.
Where Pith is reading between the lines
- If the weaknesses persist outside the simulator, LLM-based smart-home control may remain limited to simple commands for the foreseeable future.
- Hybrid architectures that combine LLMs with dedicated scheduling modules could bypass some of the identified limitations.
- Extending the benchmark to include multi-user households or changing device availability over time would test additional real-world dimensions.
Load-bearing premise
The 1,100 tasks and the division into simple, medium, and complex homes with up to 135 devices capture the actual difficulties that would appear in real deployed smart-home systems.
What would settle it
Running the same frontier models on an independent smart-home simulator or on physical hardware and finding that the reported gaps in scheduling and personalization vanish would falsify the central claim.
Figures


read the original abstract
Smart homes are evolving toward complex state-dependent living environments, requiring Large Language Models (LLMs) to reason over user intent, preferences, and multi-device interactions. However, existing smart-home benchmarks often focus on static instruction-to-API mapping or limited simulations, failing to evaluate whether LLMs can reason, interact, and act reliably in realistic household scenarios. To address these limitations, we introduce SMH-Bench, a comprehensive benchmark for evaluating LLMs in smart-home environments. Built upon HomeEnv, an executable and verifiable smart-home simulator, SMH-Bench contains 1,100 high-quality tasks spanning 7 categories and 22 fine-grained subcategories. It further stratifies tasks across simple, medium and complex homes, ranging from small apartments to dense multi-room environments with 135 devices. Experiments show that although frontier LLMs achieve strong performance on explicit control and query tasks, they still exhibit significant weaknesses in automation task scheduling, ambiguity handling and personalized reasoning, especially as home complexity increases. We hope SMH-Bench will facilitate the development of more reliable, context-aware, and practically deployable smart-home agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SMH-Bench, a benchmark of 1,100 tasks across 7 categories and 22 subcategories for LLM agents in smart homes. Built on the HomeEnv simulator, tasks are stratified into simple/medium/complex homes (up to 135 devices). Experiments claim frontier LLMs perform well on explicit control/query tasks but exhibit weaknesses in automation scheduling, ambiguity handling, and personalized reasoning that worsen with home complexity.
Significance. If the tasks prove representative of real deployments, the benchmark would provide a useful framework for identifying gaps in environment-grounded LLM reasoning and could guide development of more reliable smart-home agents.
major comments (3)
- [Abstract] Abstract: The central claim that the benchmark reveals 'practically relevant' weaknesses in scheduling, ambiguity handling, and personalization rests on the 1,100 tasks and simple/medium/complex stratification (up to 135 devices) being representative of actual smart-home systems, but the manuscript supplies no validation evidence such as user studies, device-log comparisons, or fidelity checks on HomeEnv state transitions and ambiguity distributions.
- [Task construction (likely §3)] Task construction section: No details are provided on the methodology for generating or curating the 1,100 tasks, including how categories and subcategories were defined, quality control procedures, or inter-annotator agreement, which is required to establish benchmark reliability.
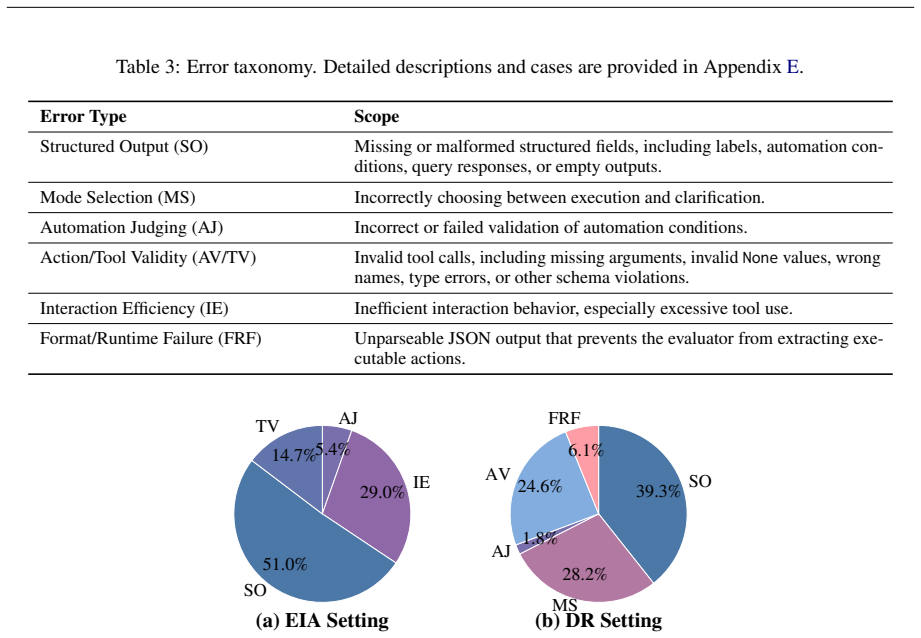
- [Experiments (likely §4-5)] Experiments section: Reported performance differences across task types and home complexities are presented without statistical significance tests, error bars, or sample-size details, leaving unclear whether the identified weaknesses are robust.
minor comments (1)
- [Benchmark description] The mapping from the 22 fine-grained subcategories to the 7 main categories could be presented more explicitly, perhaps in a table, to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for improving the clarity, rigor, and transparency of the benchmark description. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the benchmark reveals 'practically relevant' weaknesses in scheduling, ambiguity handling, and personalization rests on the 1,100 tasks and simple/medium/complex stratification (up to 135 devices) being representative of actual smart-home systems, but the manuscript supplies no validation evidence such as user studies, device-log comparisons, or fidelity checks on HomeEnv state transitions and ambiguity distributions.
Authors: We agree that the manuscript does not provide direct empirical validation evidence such as user studies or device-log comparisons. The task categories and stratification were designed based on common smart-home scenarios from prior literature and industry reports on device counts and interactions, with HomeEnv modeling standard device state transitions. To strengthen the presentation, we will add a dedicated subsection (likely in §3 or a new Limitations section) that explicitly discusses the design rationale, references supporting real-world statistics, and acknowledges the lack of user studies or fidelity checks as a limitation of the current work. This will better scope the claims about practical relevance without overstating representativeness. revision: partial
-
Referee: [Task construction (likely §3)] Task construction section: No details are provided on the methodology for generating or curating the 1,100 tasks, including how categories and subcategories were defined, quality control procedures, or inter-annotator agreement, which is required to establish benchmark reliability.
Authors: We acknowledge the need for greater methodological transparency. The revised manuscript will expand the Task Construction section to detail: (1) how the 7 categories and 22 subcategories were defined (drawing from smart-home API documentation and common user scenarios), (2) the curation and generation process for the 1,100 tasks, (3) quality control procedures including multi-reviewer checks, and (4) inter-annotator agreement metrics for any human-annotated elements. revision: yes
-
Referee: [Experiments (likely §4-5)] Experiments section: Reported performance differences across task types and home complexities are presented without statistical significance tests, error bars, or sample-size details, leaving unclear whether the identified weaknesses are robust.
Authors: We agree that the current presentation lacks statistical rigor. In the revised experiments section, we will incorporate appropriate statistical significance tests (e.g., paired t-tests or non-parametric equivalents) for performance differences, add error bars to relevant figures, and explicitly report sample sizes and variance information for all metrics and conditions. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential reductions
full rationale
This is an empirical benchmark introduction paper. It defines SMH-Bench via 1,100 tasks in HomeEnv and reports LLM performance across categories and home complexities. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text. The central claims rest on the existence and execution of the new tasks/simulator rather than any reduction to prior self-referential content. External validity concerns (representativeness of tasks) are separate from circularity per the analysis rules.
Axiom & Free-Parameter Ledger
invented entities (1)
-
HomeEnv simulator
no independent evidence
Reference graph
Works this paper leans on
-
[2]
2025 , eprint=
ToolACE: Winning the Points of LLM Function Calling , author=. 2025 , eprint=
2025
-
[3]
Forty-second International Conference on Machine Learning , year=
The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[4]
2025 , eprint=
Modeling Future Conversation Turns to Teach LLMs to Ask Clarifying Questions , author=. 2025 , eprint=
2025
-
[5]
2021 , url=
Mohit Shridhar and Xingdi Yuan and Marc-Alexandre Cote and Yonatan Bisk and Adam Trischler and Matthew Hausknecht , booktitle=. 2021 , url=
2021
-
[6]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , url =
Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik , booktitle =. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , url =
-
[8]
2025 , eprint=
Harmony: A Human-Aware, Responsive, Modular Assistant with a Locally Deployed Large Language Model , author=. 2025 , eprint=
2025
-
[10]
AIoT Smart Home via Autonomous LLM Agents , year=
Rivkin, Dmitriy and Hogan, Francois and Feriani, Amal and Konar, Abhisek and Sigal, Adam and Liu, Xue and Dudek, Gregory , journal=. AIoT Smart Home via Autonomous LLM Agents , year=
-
[12]
2026 , eprint=
SimuHome: A Temporal- and Environment-Aware Benchmark for Smart Home LLM Agents , author=. 2026 , eprint=
2026
-
[14]
2022 , url =
Conversational Voice Assistants and a Case Study of Long-Term Users: A Human Information Behaviours Perspective , author =. 2022 , url =
2022
-
[16]
The Information Society , volume =
Privacy and Smart Speakers: A Multi-Dimensional Approach , author =. The Information Society , volume =. 2021 , doi =
2021
-
[17]
Proceedings of the 7th Asia-Pacific Workshop on Networking , pages =
ChatIoT: Zero-code Generation of Trigger-action Based IoT Programs with ChatGPT , author =. Proceedings of the 7th Asia-Pacific Workshop on Networking , pages =. 2023 , doi =
2023
-
[18]
2024 , eprint =
Bridging the Gap Between Natural User Expression with Complex Automation Programming in Smart Homes , author =. 2024 , eprint =
2024
-
[19]
2026 , eprint =
Leveraging LLMs for Efficient and Personalized Smart Home Automation , author =. 2026 , eprint =
2026
-
[21]
Computer , volume =
CASAS: A Smart Home in a Box , author =. Computer , volume =. 2013 , doi =
2013
-
[22]
2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops , pages=
ARAS human activity datasets in multiple homes with multiple residents , author=. 2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops , pages=. 2013 , organization=
2013
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
VirtualHome: Simulating Household Activities via Programs , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2018 , url =
2018
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2020 , url =
2020
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
TEACh: Task-Driven Embodied Agents That Chat , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2022 , doi =
2022
-
[26]
Proceedings of the 5th Conference on Robot Learning , series =
BEHAVIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments , author =. Proceedings of the 5th Conference on Robot Learning , series =. 2022 , publisher =
2022
-
[27]
2024 , eprint =
ReALFRED: An Embodied Instruction Following Benchmark in Photo-Realistic Environments , author =. 2024 , eprint =
2024
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , year =
SmartHome-Bench: A Comprehensive Benchmark for Video Anomaly Detection in Smart Homes Using Multi-Modal Large Language Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops , year =
-
[29]
2026 , eprint =
SmartBench: Evaluating LLMs in Smart Homes with Anomalous Device States and Behavioral Contexts , author =. 2026 , eprint =
2026
-
[30]
Hande Alemdar, Halil Ertan, Ozlem Durmaz Incel, and Cem Ersoy. 2013. Aras human activity datasets in multiple homes with multiple residents. In 2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops, pages 232--235. IEEE
2013
-
[31]
Ilias Chalkidis, Manos Fergadiotis, and Ion Androutsopoulos
Diane J. Cook, Aaron S. Crandall, Brian L. Thomas, and Narayanan C. Krishnan. 2013. https://doi.org/10.1109/MC.2012.328 Casas: A smart home in a box . Computer, 46(7):62--69
-
[32]
Xinyu Huang, Leming Shen, Zijing Ma, and Yuanqing Zheng. 2025. https://doi.org/10.48550/arXiv.2507.08878 Towards privacy-preserving and personalized smart homes via tailored small language models . Preprint, arXiv:2507.08878
-
[33]
Jeonghye Kim, Sojeong Rhee, Minbeom Kim, Dohyung Kim, Sangmook Lee, Youngchul Sung, and Kyomin Jung. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1697 R efl A ct: World-grounded decision making in LLM agents via goal-state reflection . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33433--33465, Suzho...
-
[34]
Taewoong Kim, Cheolhong Min, Byeonghwi Kim, Jinyeon Kim, Wonje Jeung, and Jonghyun Choi. 2024. https://arxiv.org/abs/2407.18550 Realfred: An embodied instruction following benchmark in photo-realistic environments . Preprint, arXiv:2407.18550
arXiv 2024
-
[35]
Evan King, Haoxiang Yu, Sangsu Lee, and Christine Julien. 2024. https://doi.org/10.1145/3643505 Sasha: Creative goal-oriented reasoning in smart homes with large language models . Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8(1):1–38
-
[36]
Fu Li, Jiaming Huang, Yi Gao, and Wei Dong. 2023. https://doi.org/10.1145/3600061.3603141 Chatiot: Zero-code generation of trigger-action based iot programs with chatgpt . In Proceedings of the 7th Asia-Pacific Workshop on Networking, pages 219--220
-
[37]
Silin Li, Yuhang Guo, Jiashu Yao, Zeming Liu, and Haifeng Wang. 2025. https://doi.org/10.18653/v1/2025.acl-long.597 homebench : Evaluating LLM s in smart homes with valid and invalid instructions across single and multiple devices . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12...
-
[38]
Weiwen Liu, Xu Huang, Xingshan Zeng, Xinlong Hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, Zezhong Wang, Yuxian Wang, Wu Ning, Yutai Hou, Bin Wang, Chuhan Wu, Xinzhi Wang, Yong Liu, Yasheng Wang, and 8 others. 2025. https://arxiv.org/abs/2409.00920 Toolace: Winning the points of llm function calling . Preprint, arXiv:2409.00920
arXiv 2025
-
[39]
Christoph Lutz and Gemma Newlands. 2021. https://doi.org/10.1080/01972243.2021.1897914 Privacy and smart speakers: A multi-dimensional approach . The Information Society, 37(3):147--162
-
[40]
Indra Mckie, Bhuva Narayan, and Baki Kocaballi. 2022. https://www.tandfonline.com/doi/full/10.1080/24750158.2022.2104738 Conversational voice assistants and a case study of long-term users: A human information behaviours perspective
-
[41]
Aishwarya Padmakumar, Jesse Thomason, Ayush Shrivastava, Patrick Lange, Anjali Narayan-Chen, Spandana Gella, Robinson Piramuthu, Gokhan Tur, and Dilek Hakkani-Tur. 2022. https://doi.org/10.1609/aaai.v36i2.20097 Teach: Task-driven embodied agents that chat . Proceedings of the AAAI Conference on Artificial Intelligence, 36(2):2017--2025
-
[42]
Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. 2025. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. In Forty-second International Conference on Machine Learning
2025
-
[43]
Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidler, and Antonio Torralba. 2018. http://openaccess.thecvf.com/content_cvpr_2018/html/Puig_VirtualHome_Simulating_Household_CVPR_2018_paper.html Virtualhome: Simulating household activities via programs . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition...
2018
-
[44]
Dmitriy Rivkin, Francois Hogan, Amal Feriani, Abhisek Konar, Adam Sigal, Steve Liu, and Greg Dudek. 2023. https://doi.org/10.48550/arXiv.2311.00772 Sage: Smart home agent with grounded execution . Preprint, arXiv:2311.00772
-
[45]
Dmitriy Rivkin, Francois Hogan, Amal Feriani, Abhisek Konar, Adam Sigal, Xue Liu, and Gregory Dudek. 2025. https://doi.org/10.1109/JIOT.2024.3471904 Aiot smart home via autonomous llm agents . IEEE Internet of Things Journal, 12(3):2458--2472
-
[46]
Gyuhyeon Seo, Jungwoo Yang, Junseong Pyo, Nalim Kim, Jonggeun Lee, and Yohan Jo. 2026. https://arxiv.org/abs/2509.24282 Simuhome: A temporal- and environment-aware benchmark for smart home llm agents . Preprint, arXiv:2509.24282
arXiv 2026
-
[47]
Yingtian Shi, Xiaoyi Liu, Chun Yu, Tianao Yang, Cheng Gao, Chen Liang, and Yuanchun Shi. 2024. https://arxiv.org/abs/2408.12687 Bridging the gap between natural user expression with complex automation programming in smart homes . Preprint, arXiv:2408.12687
arXiv 2024
-
[48]
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. 2020. https://openaccess.thecvf.com/content_CVPR_2020/html/Shridhar_ALFRED_A_Benchmark_for_Interpreting_Grounded_Instructions_for_Everyday_Tasks_CVPR_2020_paper.html Alfred: A benchmark for interpreting grounded instructions for eve...
2020
-
[49]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Cote, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2021. https://openreview.net/forum?id=0IOX0YcCdTn \ ALFW \ orld: Aligning text and embodied environments for interactive learning . In International Conference on Learning Representations
2021
-
[50]
Karen Liu, Silvio Savarese, Hyowon Gweon, Jiajun Wu, and Li Fei-Fei
Sanjana Srivastava, Chengshu Li, Michael Lingelbach, Roberto Mart \' n-Mart \' n, Fei Xia, Kent Elliott Vainio, Zheng Lian, Cem Gokmen, Shyamal Buch, C. Karen Liu, Silvio Savarese, Hyowon Gweon, Jiajun Wu, and Li Fei-Fei. 2022. https://proceedings.mlr.press/v164/srivastava22a.html Behavior: Benchmark for everyday household activities in virtual, interacti...
2022
-
[51]
Wenxuan Wang, Shi Juluan, Zixuan Ling, Yuk-Kit Chan, Chaozheng Wang, Cheryl Lee, Youliang Yuan, Jen-tse Huang, Wenxiang Jiao, and Michael R. Lyu. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1104 Learning to ask: When LLM agents meet unclear instruction . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages...
-
[52]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/82ad13ec01f9fe44c01cb91814fd7b8c-Paper-Conference.pdf Webshop: Towards scalable real-world web interaction with grounded language agents . In Advances in Neural Information Processing Systems, volume 35, pages 20744--20757. Curran A...
2022
-
[53]
Ziqi Yin, Mingxin Zhang, and Daisuke Kawahara. 2025. https://arxiv.org/abs/2410.14252 Harmony: A human-aware, responsive, modular assistant with a locally deployed large language model . Preprint, arXiv:2410.14252
arXiv 2025
-
[54]
Ko, Young-Bae Ko, and Sangeun Oh
Chaerin Yu, Chihun Choi, Sunjae Lee, Hyosu Kim, Steven Y. Ko, Young-Bae Ko, and Sangeun Oh. 2026. https://arxiv.org/abs/2601.04680 Leveraging llms for efficient and personalized smart home automation . Preprint, arXiv:2601.04680
arXiv 2026
-
[55]
Nima Zargham, Leon Reicherts, Michael Bonfert, Sarah Theres V \"o lkel, Johannes Sch \"o ning, Rainer Malaka, and Yvonne Rogers. 2022. https://doi.org/10.1145/3543829.3543834 Understanding circumstances for desirable proactive behaviour of voice assistants: The proactivity dilemma . In Proceedings of the 4th Conference on Conversational User Interfaces, G...
-
[56]
Michael J. Q. Zhang, W. Bradley Knox, and Eunsol Choi. 2025. https://arxiv.org/abs/2410.13788 Modeling future conversation turns to teach llms to ask clarifying questions . Preprint, arXiv:2410.13788
arXiv 2025
-
[57]
Xinyi Zhao, Congjing Zhang, Pei Guo, Wei Li, Lin Chen, Chaoyue Zhao, and Shuai Huang. 2025. https://openaccess.thecvf.com/content/CVPR2025W/VAND/html/Zhao_SmartHome-Bench_A_Comprehensive_Benchmark_for_Video_Anomaly_Detection_in_Smart_CVPRW_2025_paper.html Smarthome-bench: A comprehensive benchmark for video anomaly detection in smart homes using multi-mod...
2025
-
[58]
Qingsong Zou, Zhi Yan, Zhiyao Xu, Kuofeng Gao, Jingyu Xiao, and Yong Jiang. 2026. https://arxiv.org/abs/2603.06636 Smartbench: Evaluating llms in smart homes with anomalous device states and behavioral contexts . Preprint, arXiv:2603.06636
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.