Pool-Select-Refine for Allocation-Aware Generative Dataset Distillation
Pith reviewed 2026-06-29 05:32 UTC · model grok-4.3
The pith
A Pool-Select-Refine framework improves diffusion-based dataset distillation by building an over-complete candidate pool, selecting a budget-sized subset, and refining in latent space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
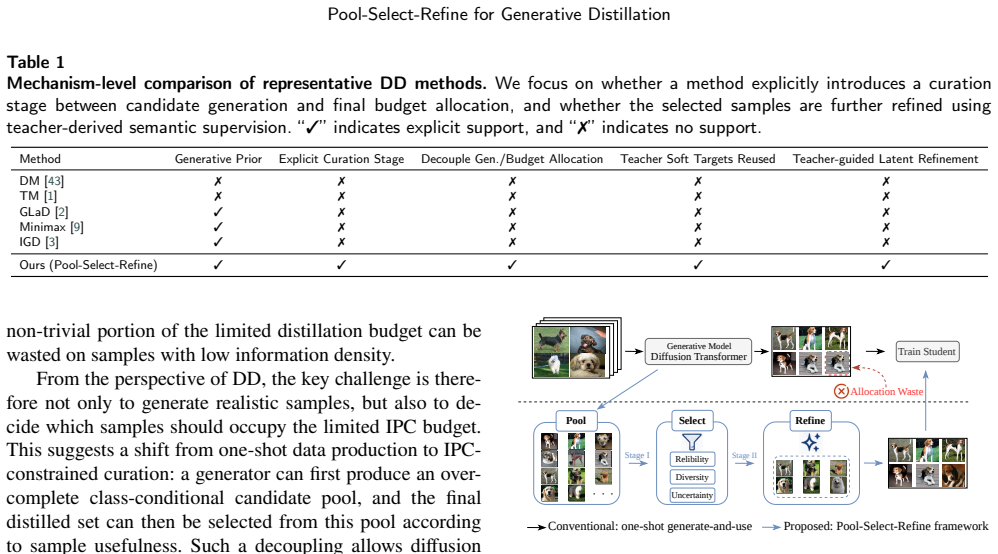
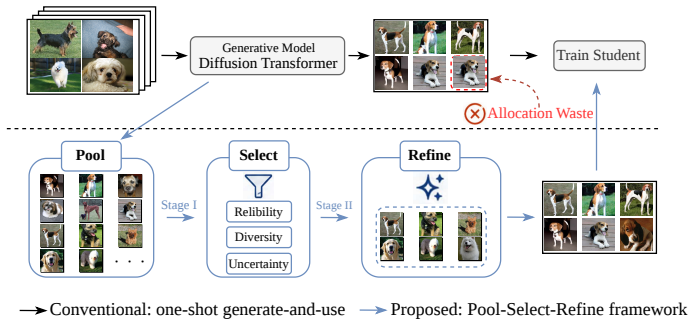
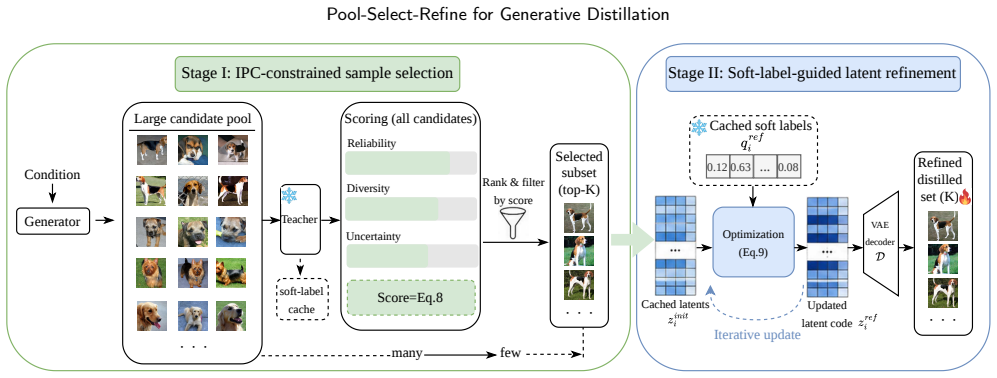
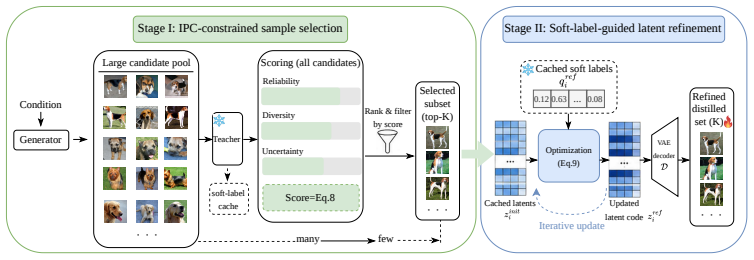
The Pool-Select-Refine framework decouples candidate generation from final budget allocation in generative dataset distillation. By first constructing an over-complete candidate pool from a pretrained diffusion model, selecting a compact subset that respects the target images-per-class budget, and then refining the selected samples in latent space with soft-label supervision derived from the teacher model, the method produces synthetic datasets that achieve higher downstream classification accuracy than the standard Generate-and-Use strategy.
What carries the argument
The Pool-Select-Refine process: over-complete candidate pool from diffusion generation, followed by budget-constrained selection of a compact subset, followed by latent-space refinement using soft labels from the teacher model.
If this is right
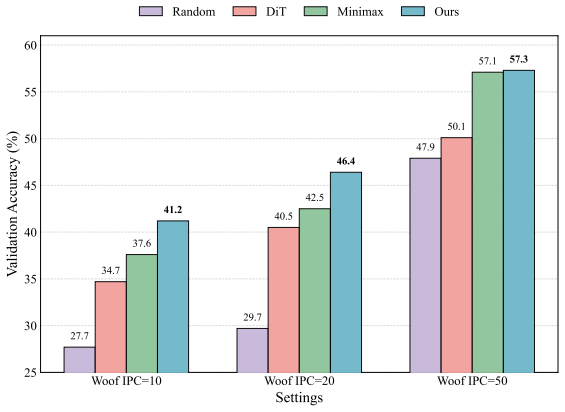
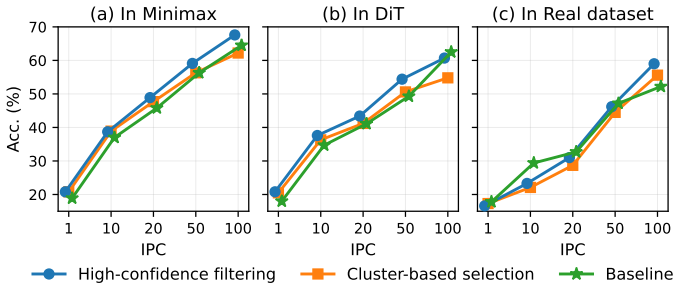
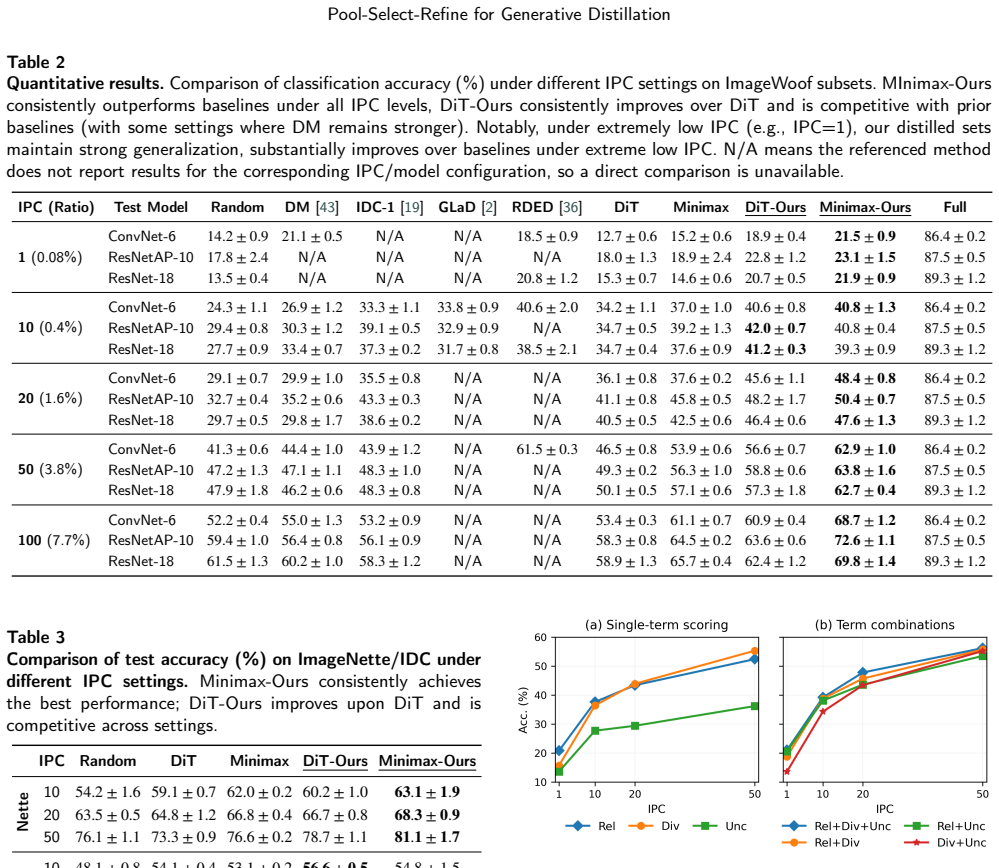
- Consistent accuracy gains over diffusion-based baselines on both large-scale and fine-grained image classification benchmarks.
- More effective use of a fixed images-per-class budget by reducing redundancy among generated samples.
- Improved semantic alignment of the final synthetic set while the generative prior from the diffusion model remains intact.
- A curation stage inserted before refinement is sufficient to improve results without changing the underlying diffusion generator.
Where Pith is reading between the lines
- The same pool-then-select pattern could be tested on generative models other than diffusion while keeping the refinement step fixed.
- The method might allow the same downstream accuracy to be reached with smaller overall budgets than current direct-generation approaches.
- Selection criteria used in the pool stage could be made learnable rather than fixed, potentially further reducing bias.
Load-bearing premise
That selecting a subset from an over-complete pool and then refining will reliably yield more informative samples than generating exactly the budgeted number directly, without the selection step introducing biases that degrade the generative prior.
What would settle it
A controlled run of the same classification benchmarks in which the selection stage is removed, so that directly generated samples at the exact budget are used instead, and the resulting accuracy is equal to or higher than the full Pool-Select-Refine pipeline.
Figures



read the original abstract
Diffusion-based dataset distillation has recently emerged as a promising paradigm for condensing large-scale datasets into compact synthetic sets. By leveraging pretrained generative priors, these methods can produce realistic class-conditional samples more efficiently than traditional matching-based approaches. However, most existing diffusion-based methods still adopt a rigid ``Generate-and-Use'' strategy, where the generated samples are directly treated as the final distilled set under a fixed images-per-class budget. Such a design tightly couples candidate generation with final budget allocation, which may result in redundant waste of the limited budget or insufficiently informative samples. In this paper, we propose ``Pool-Select-Refine'', a two-stage framework for allocation-aware generative dataset distillation. First, instead of directly using a fixed number of generated samples, we construct an over-complete candidate pool and select a compact subset under the target budget. Second, we refine the selected samples in latent space using soft-label supervision derived from the teacher model, improving semantic alignment while preserving the generative prior. This design explicitly decouples generation, selection, and refinement, enabling more effective use of the distillation budget. Experiments on large-scale and fine-grained image classification benchmarks show that the proposed framework delivers consistent gains over diffusion-based baselines. The results suggest that introducing a curation stage before refinement is a simple yet effective way to improve diffusion-based dataset distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Pool-Select-Refine framework for diffusion-based dataset distillation. It decouples the process by first generating an over-complete candidate pool, then selecting a compact subset under a fixed images-per-class budget, and finally refining the selected samples in latent space via soft-label supervision from a teacher model. This is positioned as addressing limitations of rigid 'Generate-and-Use' strategies. Experiments on large-scale and fine-grained image classification benchmarks are claimed to show consistent gains over diffusion-based baselines.
Significance. If the selection step is shown to extract higher-value samples without introducing bias or extra cost, and if refinement preserves the generative prior, the approach could improve budget allocation efficiency in generative distillation. The explicit separation of generation, selection, and refinement stages is a clear structural contribution, though its empirical advantage requires verification against matched-budget controls.
major comments (2)
- [Abstract] Abstract: the claim that the framework 'delivers consistent gains' and that 'introducing a curation stage before refinement is a simple yet effective way' is presented without any quantitative results, baselines, error bars, or description of the selection criterion; this leaves the central empirical claim unsupported in the provided text and directly engages the skeptic concern that selection may not outperform random or direct generation under matched budgets.
- [Abstract] Abstract (weakest assumption paragraph): the design is asserted to 'explicitly decouple generation, selection, and refinement' and to avoid 'redundant waste of the limited budget,' yet no mechanism is given for the selection criterion or any ablation showing that the over-complete pool plus selection adds value beyond simply generating more candidates; without this, the advantage over fixed-budget diffusion generation remains unverified.
minor comments (1)
- [Abstract] Abstract: the phrase 'allocation-aware' is introduced but never defined in operational terms relative to the budget or the selection step.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the abstract to strengthen the presentation of our claims while respecting length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the framework 'delivers consistent gains' and that 'introducing a curation stage before refinement is a simple yet effective way' is presented without any quantitative results, baselines, error bars, or description of the selection criterion; this leaves the central empirical claim unsupported in the provided text and directly engages the skeptic concern that selection may not outperform random or direct generation under matched budgets.
Authors: We agree the abstract, as a concise summary, does not embed the full quantitative results, error bars, or selection details. These are reported in Section 4 with matched-budget baselines and standard deviations across multiple runs. The selection criterion (informativeness-based ranking within the pool) is defined in Section 3.2. We will revise the abstract to include a short clause describing the selection approach and reference the observed gains (e.g., consistent improvements on CIFAR-100 and ImageNet subsets). Full numbers and ablations remain in the main text due to abstract length limits, but the revision will make the central claim more self-contained. revision: yes
-
Referee: [Abstract] Abstract (weakest assumption paragraph): the design is asserted to 'explicitly decouple generation, selection, and refinement' and to avoid 'redundant waste of the limited budget,' yet no mechanism is given for the selection criterion or any ablation showing that the over-complete pool plus selection adds value beyond simply generating more candidates; without this, the advantage over fixed-budget diffusion generation remains unverified.
Authors: The decoupling of stages and the selection mechanism (constructing an over-complete pool then choosing a budget-constrained subset via a learned or heuristic scorer) are detailed in Sections 3.1–3.2. Ablations comparing the full Pool-Select-Refine pipeline against direct fixed-budget generation and random selection from the same pool appear in Section 4.3. We will revise the abstract to briefly name the selection stage and its purpose, thereby clarifying how the over-complete pool enables better budget allocation without altering the core claims. revision: yes
Circularity Check
No circularity: empirical method proposal with no self-referential derivations or fitted predictions
full rationale
The paper introduces a Pool-Select-Refine pipeline as a procedural framework for dataset distillation and reports empirical gains on image classification benchmarks. No equations, parameter-fitting steps, uniqueness theorems, or self-citations appear in the provided text that would reduce any claimed result to its own inputs by construction. The central claim is presented as an outcome of the new allocation-aware procedure versus diffusion baselines, making the derivation self-contained against external experimental benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A. Efros. Dataset distillation, 2020
2020
-
[2]
Dataset distillation: A comprehen- sive review.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(1):150–170, January 2024
Ruonan Yu, Songhua Liu, and Xinchao Wang. Dataset distillation: A comprehen- sive review.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(1):150–170, January 2024
2024
-
[3]
Towards trustworthy dataset distillation.Pattern Recognition, 157:110875, 2025
Shijie Ma, Fei Zhu, Zhen Cheng, and Xu-Yao Zhang. Towards trustworthy dataset distillation.Pattern Recognition, 157:110875, 2025
2025
-
[4]
Compr: Efficient point cloud dataset condensation via bidirectional matching and point recycling.Pattern Recognition, 172:112494, 2026
Hongliang Zhang, Xiaoqi An, Jiawei Lian, Lei Luo, and Jian Yang. Compr: Efficient point cloud dataset condensation via bidirectional matching and point recycling.Pattern Recognition, 172:112494, 2026
2026
-
[5]
Towards reliable domain generalization: Insights from the pf2hc benchmark and dynamic evalua- tions.Pattern Recognition, 157:110926, 2025
Jiao Zhang, Xiang Ao, Xu-Yao Zhang, and Cheng-Lin Liu. Towards reliable domain generalization: Insights from the pf2hc benchmark and dynamic evalua- tions.Pattern Recognition, 157:110926, 2025
2025
-
[6]
Dataset meta-learning from kernel ridge-regression
Timothy Chieu Nguyen, Zhourong Chen, and Jaehoon Lee. Dataset meta-learning from kernel ridge-regression. InICLR 2021, 2021
2021
-
[7]
Dataset distillation using neural feature regression
Yongchao Zhou, Ehsan Nezhadarya, and Jimmy Ba. Dataset distillation using neural feature regression. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[8]
Efficient dataset distillation using random feature approximation
Noel Loo, Ramin Hasani, Mathias Lechner, and Daniela Rus. Efficient dataset distillation using random feature approximation. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2022
2022
-
[9]
arXiv preprint arXiv:2006.05929 (2020)
Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. Dataset condensation with gradient matching.CoRR, abs/2006.05929, 2020
-
[10]
Dataset condensation with differentiable siamese augmentation
Bo Zhao and Hakan Bilen. Dataset condensation with differentiable siamese augmentation. InInternational Conference on Machine Learning (ICML), pages 12674–12685, 2021. 25
2021
-
[11]
Dataset condensation with distribution matching
Bo Zhao and Hakan Bilen. Dataset condensation with distribution matching. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision 2023 (WACV), IEEE Winter Conference on Applications of Computer Vi- sion, pages 6503–6512, United States, January 2023. Institute of Electrical and Electronics Engineers
2023
-
[12]
Cafe: Learning to condense dataset by aligning features
Kai Wang, Bo Zhao, Xiangyu Peng, Zheng Zhu, Shuo Yang, Shuo Wang, Guan Huang, Hakan Bilen, Xinchao Wang, and Yang You. Cafe: Learning to condense dataset by aligning features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12196–12205, 2022
2022
-
[13]
Datadam: Efficient dataset distillation with at- tention matching
Ahmad Sajedi, Samir Khaki, Ehsan Amjadian, Lucy Z Liu, Yuri A Lawryshyn, and Konstantinos N Plataniotis. Datadam: Efficient dataset distillation with at- tention matching. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17097–17107, 2023
2023
-
[14]
Mim4dd: Mutual information max- imization for dataset distillation
Yuzhang Shang, Zhihang Yuan, and Yan Yan. Mim4dd: Mutual information max- imization for dataset distillation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[15]
Efros, and Jun-Yan Zhu
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A. Efros, and Jun-Yan Zhu. Dataset distillation by matching training trajectories. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[16]
Towards lossless dataset distillation via difficulty-aligned trajectory match- ing
Ziyao Guo, Kai Wang, George Cazenavette, Hui Li, Kaipeng Zhang, and Yang You. Towards lossless dataset distillation via difficulty-aligned trajectory match- ing. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[17]
Min- imizing the accumulated trajectory error to improve dataset distillation
Jiawei Du, Yidi Jiang, Vincent YF Tan, Joey Tianyi Zhou, and Haizhou Li. Min- imizing the accumulated trajectory error to improve dataset distillation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 3749–3758, 2023. 26
2023
-
[18]
Synthesizing informative training samples with GAN
Bo Zhao and Hakan Bilen. Synthesizing informative training samples with GAN. InNeurIPS 2022 Workshop on Synthetic Data for Empowering ML Research, 2022
2022
-
[19]
Efros, and Jun-Yan Zhu
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A. Efros, and Jun-Yan Zhu. Generalizing dataset distillation via deep generative prior.CVPR, 2023
2023
-
[20]
Hierarchical features matter: A deep exploration of gan priors for improved dataset distillation
Xinhao Zhong, Hao Fang, Bin Chen, Xulin Gu, Meikang Qiu, Shuhan Qi, and Shu-Tao Xia. Hierarchical features matter: A deep exploration of gan priors for improved dataset distillation. pages 30462–30471. Computer Vision Foundation /IEEE, 2025
2025
-
[21]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), vol- ume 33, pages 6840–6851, 2020
2020
-
[22]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[23]
Generative adver- sarial networks.Commun
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde- Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adver- sarial networks.Commun. ACM, 63(11):139–144, October 2020
2020
-
[24]
Efficient dataset distillation via minimax diffusion
Jianyang Gu, Saeed Vahidian, Vyacheslav Kungurtsev, Haonan Wang, Wei Jiang, Yang You, and Yiran Chen. Efficient dataset distillation via minimax diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15793–15803, June 2024
2024
-
[25]
D4m: Dataset distillation via disentangled diffusion model
Duo Su, Junjie Hou, Weizhi Gao, Yingjie Tian, and Bowen Tang. D4m: Dataset distillation via disentangled diffusion model. InCVPR, pages 5809–5818, 2024
2024
-
[26]
Influence-guided diffusion for dataset distillation
Mingyang Chen, Jiawei Du, Bo Huang, Yi Wang, Xiaobo Zhang, and Wei Wang. Influence-guided diffusion for dataset distillation. InThe Thirteenth International Conference on Learning Representations, 2025. 27
2025
-
[27]
MGD3: Mode-guided dataset distillation using diffusion models
Jeffrey A Chan Santiago, praveen tirupattur, Gaurav Kumar Nayak, Gaowen Liu, and Mubarak Shah. MGD3: Mode-guided dataset distillation using diffusion models. InForty-second International Conference on Machine Learning, 2025
2025
-
[28]
Unlocking dataset distillation with diffusion models
Brian Bernhard Moser, Federico Raue, Sebastian Palacio, Stanislav Frolov, and Andreas Dengel. Unlocking dataset distillation with diffusion models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[29]
Plataniotis
Linfeng Ye, Shayan Mohajer Hamidi, Guang Li, Takahiro Ogawa, Miki Haseyama, and Konstantinos N. Plataniotis. Information-guided diffusion sam- pling for dataset distillation. InNeurIPS 2025 Workshop on Structured Proba- bilistic Inference&Generative Modeling, 2025
2025
-
[30]
Enhancing diffusion-based dataset distillation via adversary-guided curriculum sampling
Lexiao Zou, Yanda Chen, et al. Enhancing diffusion-based dataset distillation via adversary-guided curriculum sampling. InIEEE International Conference on Multimedia and Expo (ICME), 2025
2025
-
[31]
Cao2: Rectifying inconsistencies in diffusion-based dataset distillation
Haoxuan Wang, Zhenghao Zhao, Junyi Wu, Yuzhang Shang, Gaowen Liu, and Yan Yan. Cao2: Rectifying inconsistencies in diffusion-based dataset distillation. In2025 IEEE/CVF International Conference on Computer Vision (ICCV), pages 4722–4731, 2025
2025
-
[32]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, 2023
2023
-
[33]
A label is worth a thousand images in dataset distillation
Tian Qin, Zhiwei Deng, and David Alvarez-Melis. A label is worth a thousand images in dataset distillation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[34]
A baseline for detecting misclassified and out-of-distribution examples in neural networks.Proceedings of the International Conference on Learning Representations (ICLR), 2017
Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks.Proceedings of the International Conference on Learning Representations (ICLR), 2017. 28
2017
-
[35]
Weinberger
Chuan Guo, GeoffPleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In Doina Precup and Yee Whye Teh, editors,Proceed- ings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1321–1330. PMLR, 06–11 Aug 2017
2017
-
[36]
Active learning for convolutional neural net- works: A core-set approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural net- works: A core-set approach. InInternational Conference on Learning Represen- tations (ICLR), 2018
2018
-
[37]
Active learning literature survey
Burr Settles. Active learning literature survey. Technical Report 1648, University of Wisconsin-Madison, 2009
2009
-
[38]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 10684–10695, 2022
2022
-
[39]
Revisiting confidence estimation: Towards reliable failure prediction.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3370–3387, 2024
Fei Zhu, Xu-Yao Zhang, Zhen Cheng, and Cheng-Lin Liu. Revisiting confidence estimation: Towards reliable failure prediction.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3370–3387, 2024
2024
-
[40]
Dataset condensation via efficient synthetic-data parameterization
Jang-Hyun Kim, Jinuk Kim, Seong Joon Oh, Sangdoo Yun, Hwanjun Song, Joon- hyun Jeong, Jung-Woo Ha, and Hyun Oh Song. Dataset condensation via efficient synthetic-data parameterization. InProceedings of the 39th International Confer- ence on Machine Learning (ICML), pages 11102–11118, 2022
2022
-
[41]
On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm
Peng Sun, Bei Shi, Daiwei Yu, and Tao Lin. On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9390–9399, 2024
2024
-
[42]
Dynamic few-shot visual learning with- out forgetting
Spyros Gidaris and Nikos Komodakis. Dynamic few-shot visual learning with- out forgetting. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4367–4375, 2018. 29
2018
-
[43]
Deep residual learn- ing for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learn- ing for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
2016
-
[44]
A convnet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Dar- rell, and Saining Xie. A convnet for the 2020s. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11976– 11986, 2022
2022
-
[45]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 248–255, 2009
2009
-
[46]
Imagenette: A smaller subset of 10 easily classified classes from imagenet.https://github.com/fastai/imagenette, 2019
Jeremy Howard. Imagenette: A smaller subset of 10 easily classified classes from imagenet.https://github.com/fastai/imagenette, 2019
2019
-
[47]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[48]
Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
Ya Le and Xuan Yang. Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015. 30
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.