Training Prompt Matters: State-Adaptive Optimization for Robust Fine-Tuning
Pith reviewed 2026-06-28 15:08 UTC · model grok-4.3
The pith
Task loss before training identifies prompts that reduce forgetting and improve generalization in LLM fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
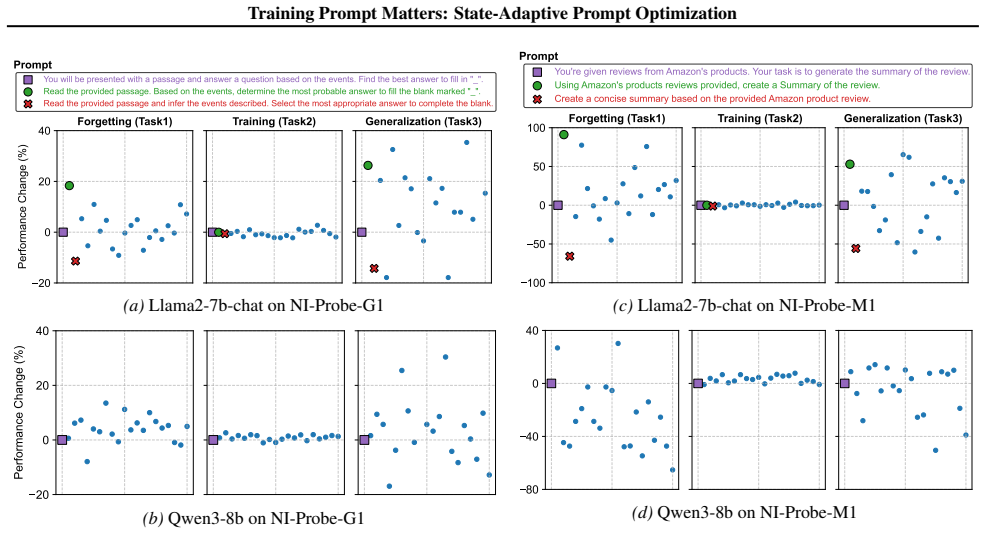
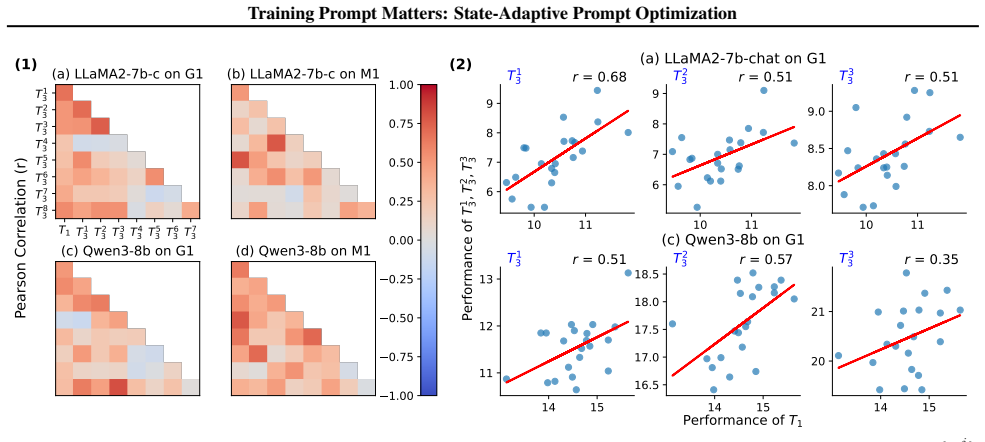
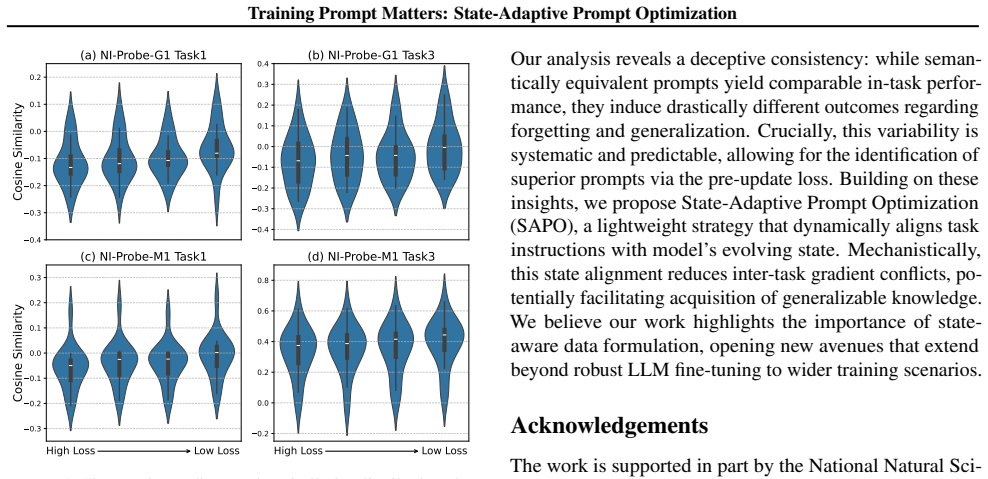
Paraphrased training prompts induce drastically different cross-task impacts on catastrophic forgetting and generalization even when in-task performance is comparable; these impacts correlate positively across tasks, allowing superior prompts to be identified by task loss prior to learning. SAPO exploits this by converting the prompt from a static input into a state-adaptive variable during training.
What carries the argument
State-Adaptive Prompt Optimization (SAPO), a training strategy that makes the prompt formulation a dynamic variable adapting to the model's current learning state.
If this is right
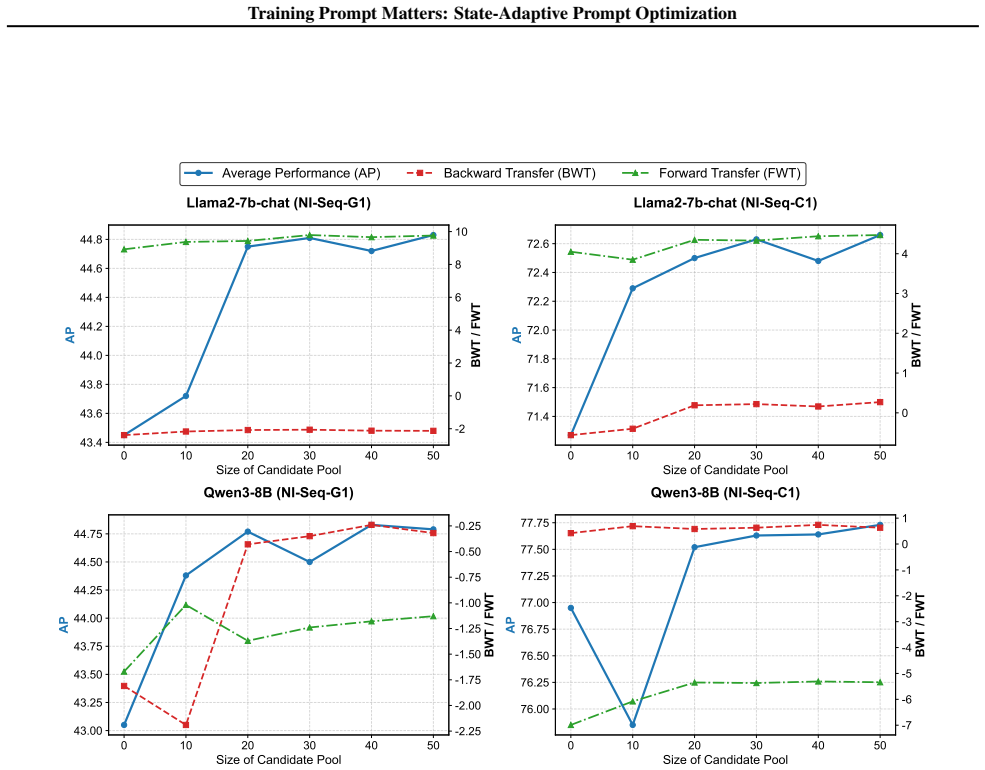
- Fine-tuning with SAPO produces models that retain performance on prior tasks more effectively than standard methods.
- The same models show improved performance on unseen tasks compared with fixed-prompt baselines.
- The approach requires only lightweight changes to existing fine-tuning pipelines.
- Gains hold across multiple diverse benchmarks and outperform current state-of-the-art prompt and fine-tuning techniques.
Where Pith is reading between the lines
- The correlation finding could support automated prompt selection pipelines that avoid running full fine-tuning trials for each candidate.
- The same pre-learning loss signal might transfer to other adaptation techniques such as parameter-efficient modules or in-context learning.
- If the correlation weakens at very large model scales, the identification step would need re-validation on those models.
Load-bearing premise
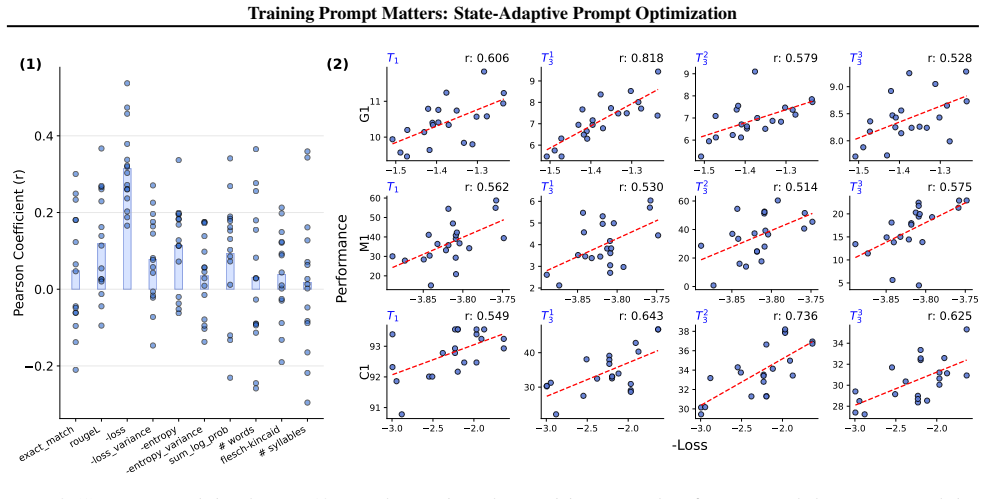
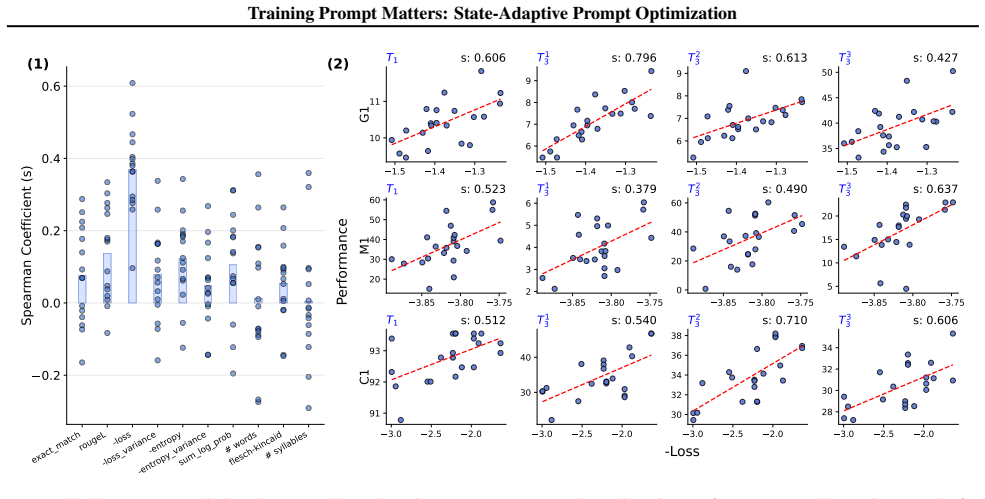
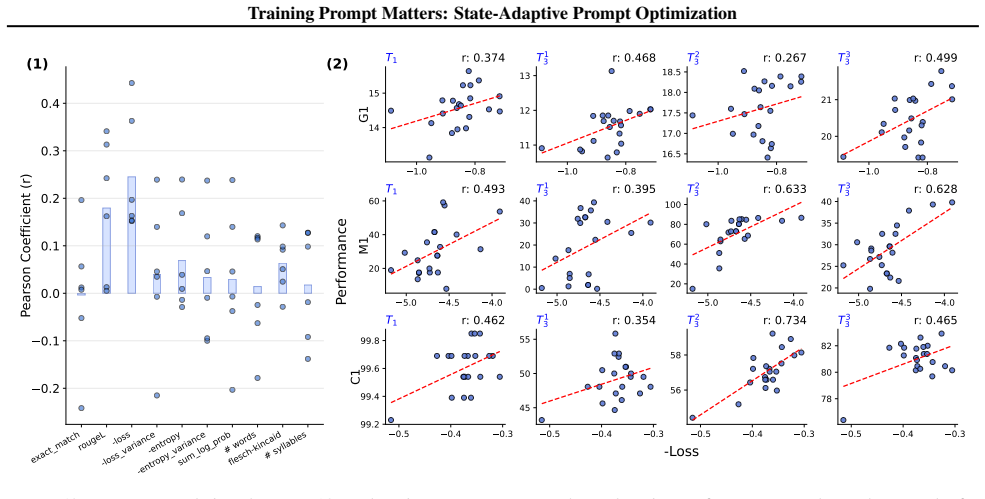
Task loss measured before learning starts reliably identifies the prompts that will produce better cross-task outcomes on forgetting and generalization.
What would settle it
A test set of tasks where the prompt with the lowest initial task loss produces higher forgetting or lower generalization than other prompts after fine-tuning.
Figures
read the original abstract
While prompt engineering is instrumental in maximizing the capabilities of Large Language Models (LLMs) during inference, the role of prompts during training remains critically underexplored. Prevailing fine-tuning paradigms typically treat training prompts as mere surface forms, assuming that semantically equivalent instructions yield identical learning outcomes. However, we reveal that this equivalence is deceptive: while paraphrased prompts often lead to comparable in-task performance, they induce drastically different cross-task impacts regarding catastrophic forgetting and generalization. Crucially, these impacts are positively correlated across tasks, indicating the existence of superior prompts that consistently yield better performance. Furthermore, we discover that these superior prompts can be robustly identified by task loss prior to learning. Leveraging these insights, we introduce State-Adaptive Prompt Optimization (SAPO), a lightweight yet effective training strategy that shifts task formulation from a static input to a dynamic, state-adaptive variable. Comprehensive experiments on diverse benchmarks confirm its effectiveness, which significantly mitigates forgetting while improving generalization, achieving substantial performance gains over state-of-the-art methods. These results provide insights into how training prompts shape learning dynamics and offer a practical recipe for robust fine-tuning. Our code is available at https://github.com/Eric8932/SAPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that paraphrased training prompts yield similar in-task performance but induce correlated differences in cross-task catastrophic forgetting and generalization; these correlations indicate the existence of consistently superior prompts that can be identified via pre-training task loss. It introduces State-Adaptive Prompt Optimization (SAPO), which treats the prompt as a dynamic, state-dependent variable during fine-tuning, and reports that SAPO reduces forgetting, improves generalization, and outperforms prior methods on diverse benchmarks.
Significance. If the reported correlations and identification procedure are robustly validated with proper controls, the work supplies a practical, low-overhead recipe for prompt selection during fine-tuning and a new perspective on how surface-form choices affect learning dynamics beyond in-task accuracy.
major comments (2)
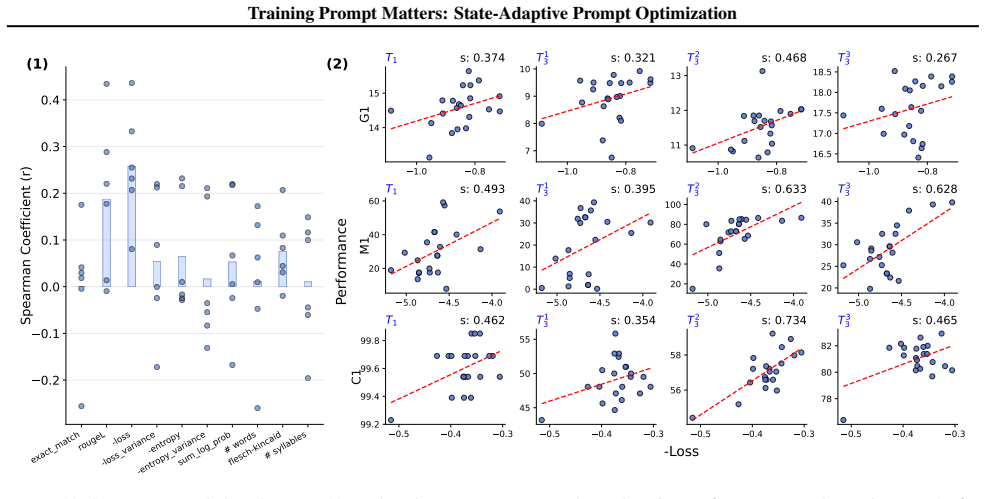
- [§3 (Method) and §4.1 (Correlation Analysis)] The central identification claim (superior prompts identified by pre-learning task loss) is load-bearing yet the procedure for computing the cross-task correlation and for selecting prompts from loss values is not formalized; without an explicit selection rule or held-out validation, the risk that the correlation is measured on the same tasks used to define superiority cannot be assessed.
- [§4.2 (Main Results)] Table 2 (or equivalent results table) reports performance gains for SAPO but does not include per-run standard deviations, number of random seeds, or statistical significance tests against the strongest baseline; this undermines the claim of 'substantial performance gains' when the method is positioned as robust.
minor comments (2)
- [§3.1] Notation for the state variable in SAPO is introduced without an accompanying equation; adding a compact definition (e.g., Eq. (3)) would clarify how the prompt is updated from the current model state.
- [Appendix / Code Availability] The GitHub link is provided but the repository should include the exact prompt templates and task-loss computation scripts used for the correlation study to enable reproduction.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript. We address each major comment below and commit to revisions that strengthen the paper's rigor and clarity.
read point-by-point responses
-
Referee: [§3 (Method) and §4.1 (Correlation Analysis)] The central identification claim (superior prompts identified by pre-learning task loss) is load-bearing yet the procedure for computing the cross-task correlation and for selecting prompts from loss values is not formalized; without an explicit selection rule or held-out validation, the risk that the correlation is measured on the same tasks used to define superiority cannot be assessed.
Authors: We acknowledge that an explicit formalization of the correlation computation and prompt selection procedure would enhance reproducibility. In the revised version, we will add a formal definition of the cross-task correlation metric and the selection rule based on pre-learning task loss. Regarding held-out validation, we will perform additional experiments using a held-out set of tasks to validate that the identified superior prompts generalize beyond the tasks used for correlation measurement. This addresses the concern about potential data leakage in the identification process. revision: yes
-
Referee: [§4.2 (Main Results)] Table 2 (or equivalent results table) reports performance gains for SAPO but does not include per-run standard deviations, number of random seeds, or statistical significance tests against the strongest baseline; this undermines the claim of 'substantial performance gains' when the method is positioned as robust.
Authors: We agree that reporting variability and statistical significance is important for robust claims. In the revision, we will rerun the experiments with at least 3 random seeds, report mean and standard deviation in the results tables, and include statistical significance tests (e.g., paired t-tests) comparing SAPO to the strongest baselines. This will provide stronger evidence for the performance improvements. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on empirical observations: paraphrased prompts produce correlated cross-task effects on forgetting and generalization, and initial task loss identifies superior prompts. These are presented as data-driven discoveries rather than derivations. No equations, self-citations, or selection procedures are shown that reduce the identification of 'superior prompts' or the SAPO method to a fit or definition by construction. The argument is self-contained against external benchmarks and does not invoke load-bearing self-citations or ansatzes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://api.semanticscholar. org/CorpusID:257532815. Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901, 2020. Buzzega, P., Boschini, M., Porrello, A., Abati, D., and ...
-
[4]
php/AAAI/article/view/12028/11887
URL https://openreview.net/forum? id=nZeVKeeFYf9. Huang, J., Cui, L., Wang, A., Yang, C., Liao, X., Song, L., Yao, J., and Su, J. Mitigating catastrophic forgetting in large language models with self-synthesized rehearsal. InProceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers), pp. 1416–1428, 20...
-
[5]
URL https://openreview.net/forum? id=gc8QAQfXv6. Kincaid, J. P., Fishburne Jr, R. P., Rogers, R. L., and Chissom, B. S. Derivation of new readability formulas (automated readability index, fog count and flesch read- ing ease formula) for navy enlisted personnel. Technical report, 1975. Kirkpatrick, J., Pascanu, R., Rabinowitz, N. C., Veness, J., Desjardin...
arXiv 1975
-
[6]
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
URL https://openreview.net/forum? id=bqMJToTkvT. 11 Training Prompt Matters: State-Adaptive Prompt Optimization Kotha, S., Springer, J. M., and Raghunathan, A. Understand- ing catastrophic forgetting in language models via im- plicit inference. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3560815 2024
-
[7]
Generalized Slow Roll for Tensors
URL https://openreview.net/forum? id=8sKcAWOf2D. Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019. Rajbhandari, S., Rasley, J., Ruwase, O., and He, Y . Zero: memory optimizations toward training trillion parameter models. In Cuicchi, C., Qualters, I., ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00024 2019
-
[8]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
URL https://openreview.net/forum? id=UJTgQBc91_. Reimers, N., Beyer, P., and Gurevych, I. Task-oriented intrinsic evaluation of semantic textual similarity. In Cal- zolari, N., Matsumoto, Y ., and Prasad, R. (eds.),COLING 2016, 26th International Conference on Computational Linguistics, Proceedings of the Conference: Technical Papers, December 11-16, 2016...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.330 2016
-
[10]
Llama 2: Open Foundation and Fine-Tuned Chat Models
doi: 10.48550/ARXIV .2307.09288. URL https: //doi.org/10.48550/arXiv.2307.09288. Wang, X., Chen, T., Ge, Q., Xia, H., Bao, R., Zheng, R., Zhang, Q., Gui, T., and Huang, X. Orthogonal sub- space learning for language model continual learning. In Bouamor, H., Pino, J., and Bali, K. (eds.),Find- ings of the Association for Computational Linguistics: EMNLP 20...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[11]
URL https://doi.org/10.18653/v1/ 2023.findings-emnlp.715. Wang, X., Zhang, Y ., Chen, T., Gao, S., Jin, S., Yang, X., Xi, Z., Zheng, R., Zou, Y ., Gui, T., Zhang, Q., and Huang, X. TRACE: A comprehensive benchmark for continual learn- ing in large language models.CoRR, abs/2310.06762, 2023b. doi: 10.48550/ARXIV .2310.06762. URLhttps: //doi.org/10.48550/ar...
-
[12]
Zhang, X
URL https://openreview.net/forum? id=gSHyqBijPFO. Zhang, X. and Wu, J. Dissecting learning and forgetting in language model finetuning. InThe Twelfth Interna- tional Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net,
2024
-
[13]
URL https://openreview.net/forum? id=tmsqb6WpLz. Zhao, W., Wang, S., Hu, Y ., Zhao, Y ., Qin, B., Zhang, X., Yang, Q., Xu, D., and Che, W. SAPT: A shared atten- tion framework for parameter-efficient continual learn- ing of large language models. In Ku, L., Martins, A., and Srikumar, V . (eds.),Proceedings of the 62nd Annual Meeting of the Association for...
-
[14]
14 Training Prompt Matters: State-Adaptive Prompt Optimization A
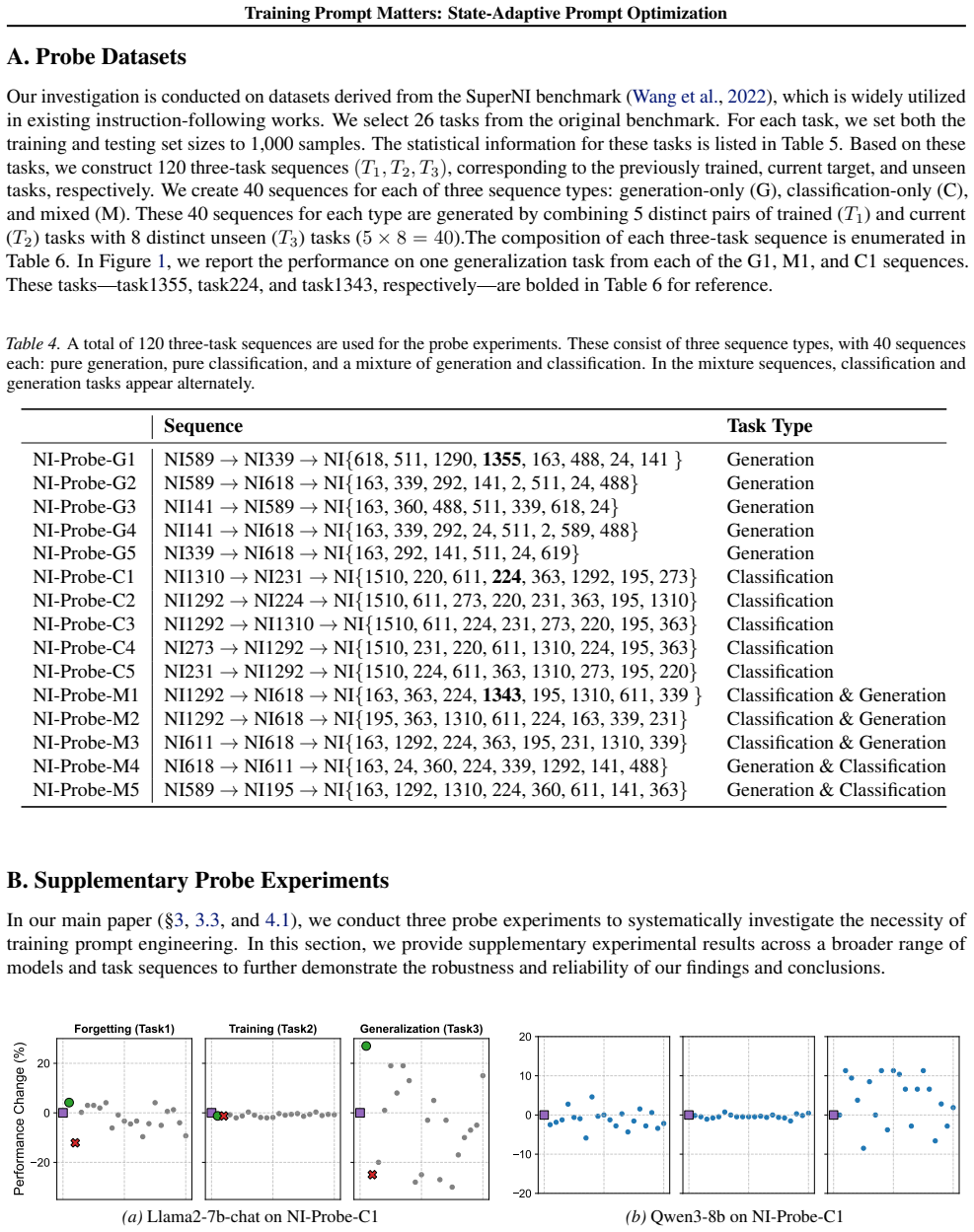
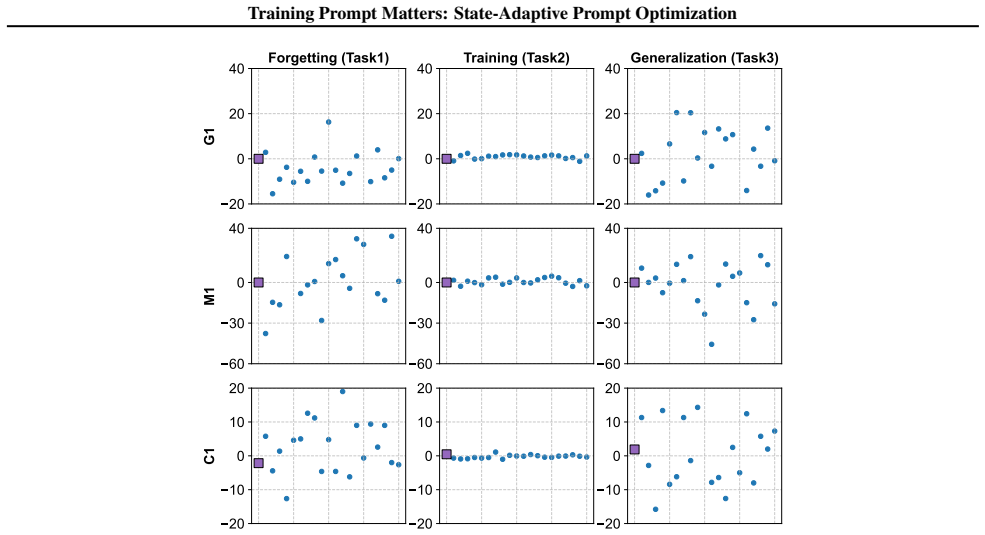
URL https://openreview.net/forum? id=92gvk82DE-. 14 Training Prompt Matters: State-Adaptive Prompt Optimization A. Probe Datasets Our investigation is conducted on datasets derived from the SuperNI benchmark (Wang et al., 2022), which is widely utilized in existing instruction-following works. We select 26 tasks from the original benchmark. For each task,...
2022
-
[15]
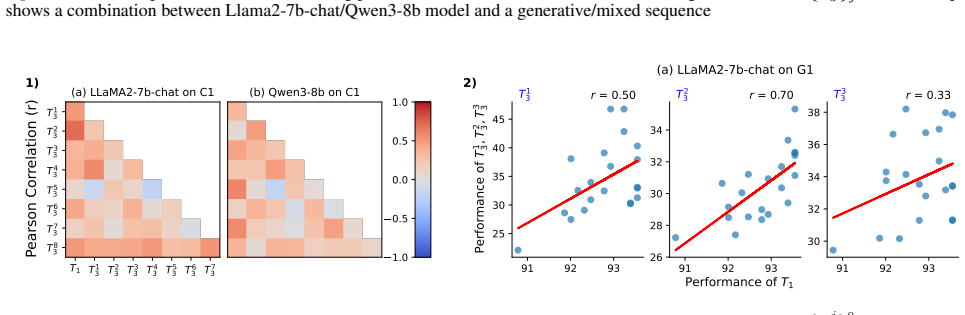
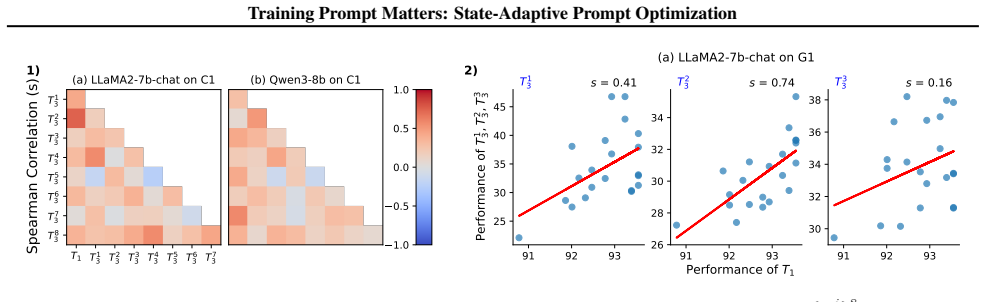
Each subplot shows the results of Llama2-7b-chat and Qwen3-14b on a classification sequence
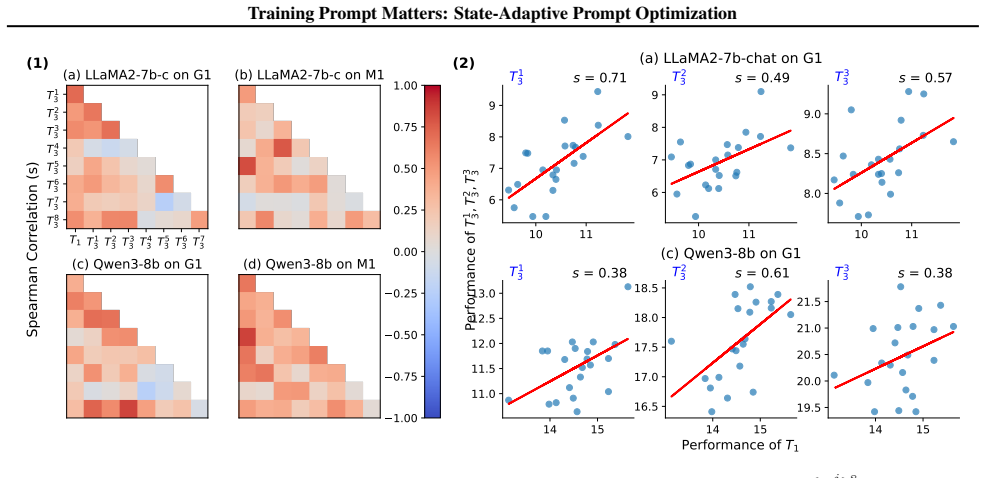
2) Figure 8.Pairwise Pearson correlations among performances across the trained task T1 and eight unseen tasks {T j 3 }8 j=1. Each subplot shows the results of Llama2-7b-chat and Qwen3-14b on a classification sequence. C. Details of Empirical Experiments C.1. Training and Evaluation We adopt Llama2-7b-chat, Llama2-13b-chat (Touvron et al., 2023), Qwen3-8b...
2023
-
[16]
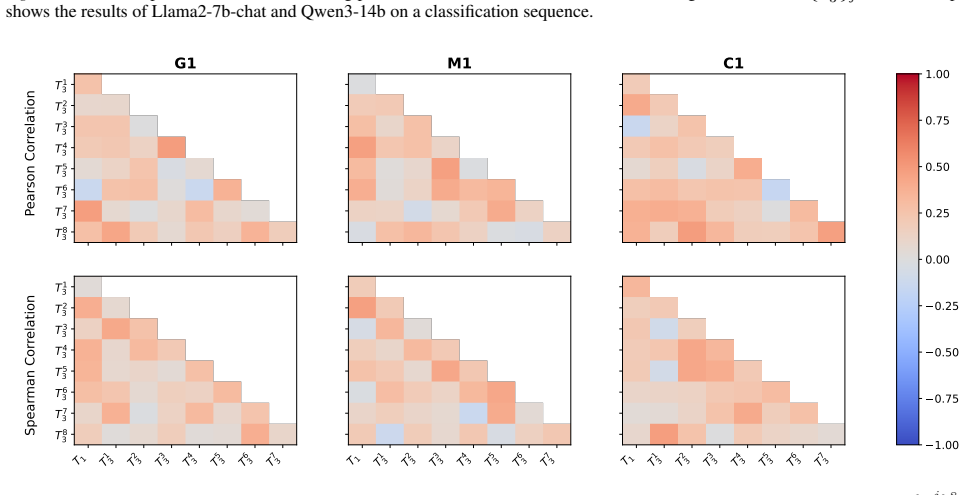
Each subplot shows the results of Llama2-7b-chat and Qwen3-14b on a classification sequence
2) Figure 9.Pairwise Spearman correlations among performances across the trained task T1 and eight unseen tasks {T j 3 }8 j=1. Each subplot shows the results of Llama2-7b-chat and Qwen3-14b on a classification sequence. 1.00 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00 T1 3 T2 3 T3 3 T4 3 T5 3 T6 3 T7 3 T8 3 G1 M1 C1 T1 T13 T23 T33 T43 T53 T63 T73 T1 3 T2 3 T3...
2022
-
[17]
Performance on all tasks is similarly evaluated using the ROUGE-L metric
Unlike the SuperNI benchmark, where 1,000 samples are used per task, we utilize 3,000 samples per task for training on TRACE. Performance on all tasks is similarly evaluated using the ROUGE-L metric. C.4. Implementation Details We compare our method against representative state-of-the-art (SOTA) continual learning methods from the three primary families. ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.