Provable Data Scaling Law for Meta Learning via Complexity Minimization
Pith reviewed 2026-06-28 12:57 UTC · model grok-4.3
The pith
A complexity minimization framework for meta-representation learning provably shows that few-shot adaptation error rates improve with more meta-training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By learning representations through evaluation of per-domain downstream model complexity followed by minimization of the worst-case such complexity across source domains, the framework ensures that the error rate of few-shot adaptation improves as the amount of meta-training data grows, as established by the full theoretical chain from pre-training to downstream regression.
What carries the argument
Complexity minimization, the mechanism that evaluates the downstream model complexity suited to each domain and minimizes its worst-case value across source domains to produce scalable representations.
If this is right
- The error rate of few-shot adaptation decreases as meta-training data volume increases.
- Representations produced by the framework exhibit scaling behavior in downstream regression tasks.
- Adding complexity regularization to existing meta-learning methods improves downstream sample efficiency.
- The scaling relation holds from the end-to-end analysis spanning pre-training to adaptation without extra restrictions on function classes.
Where Pith is reading between the lines
- The same worst-case complexity objective might be adapted to explain scaling in non-meta pre-training settings such as language model pre-training.
- If the per-domain complexity measure can be approximated efficiently, the framework could guide data collection priorities in large-scale meta-learning pipelines.
- Testing the predicted rate of error improvement against observed curves on standard few-shot benchmarks would provide a direct check on the derived scaling.
Load-bearing premise
Downstream model complexity can be meaningfully evaluated per domain such that minimizing its worst-case value across source domains makes the scaling of representation quality follow directly from meta-training data volume.
What would settle it
A concrete counterexample or experiment in which increasing the amount of meta-training data fails to reduce the few-shot adaptation error rate when representations are learned under complexity minimization.
Figures

read the original abstract
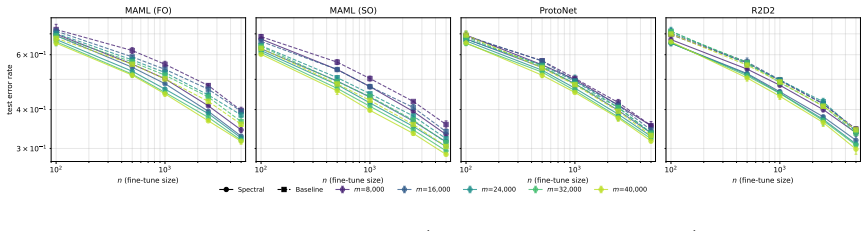
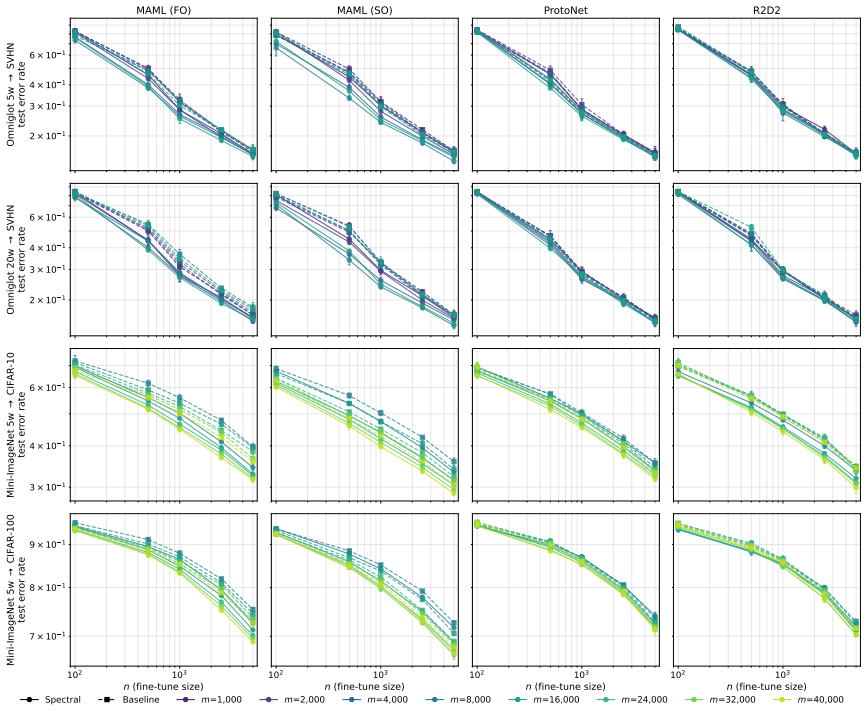
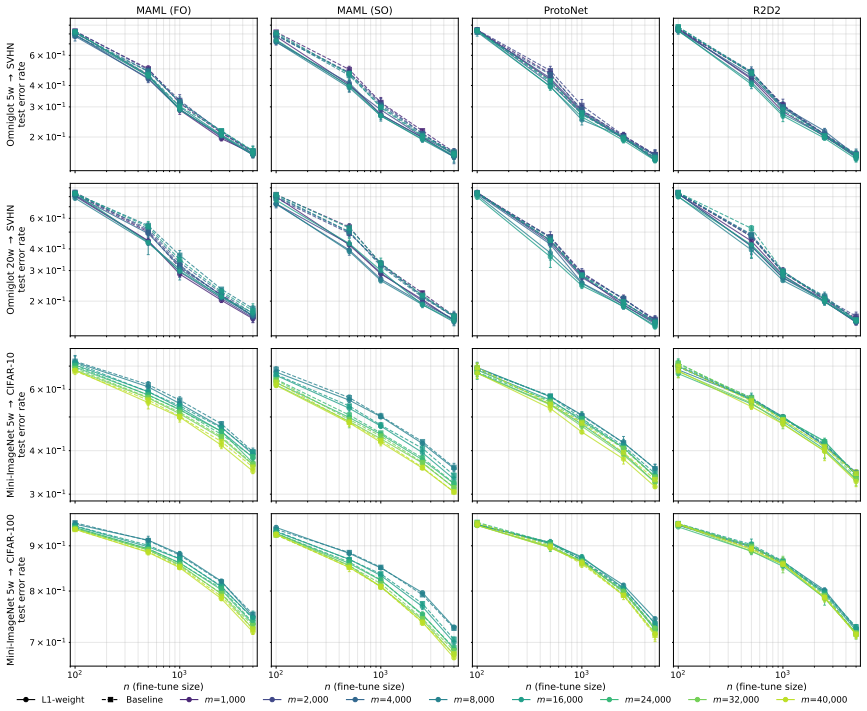
Pre-training has become a fundamental paradigm in modern machine learning, with one of its key empirical benefits being reduced downstream sample complexity as the scale of pre-training data increases. However, existing theoretical frameworks for pre-training do not fully explain this phenomenon. In this paper, we introduce complexity minimization, a novel meta-representation learning framework designed to enable theoretical analysis of this scaling behavior, which learns representations by evaluating the downstream model complexity best suited to each domain and minimizing the worst-case such complexity across source domains. Our end-to-end theoretical analysis, spanning pre-training through downstream regression, shows that this framework provably captures this scaling behavior; in particular, we show that the error rate of few-shot adaptation improves as the amount of meta-training data grows. Empirically, we demonstrate that incorporating complexity regularization into existing meta-learning methods consistently improves downstream sample efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a complexity minimization framework for meta-representation learning that learns representations by evaluating the downstream model complexity best suited to each domain and minimizing the worst-case such complexity across source domains. It claims an end-to-end theoretical analysis spanning pre-training through downstream regression that proves the error rate of few-shot adaptation improves as the amount of meta-training data grows. Empirically, incorporating complexity regularization into existing meta-learning methods is shown to improve downstream sample efficiency.
Significance. If the central theoretical claim holds under standard assumptions on function classes and data distributions, the work would be significant for supplying a provable account of data scaling in pre-training for meta-learning, a phenomenon not fully explained by prior frameworks. The combination of the claimed end-to-end guarantee with empirical gains on sample efficiency constitutes a substantive contribution.
minor comments (2)
- [Abstract] Abstract: the description of how complexity is evaluated per domain and how the worst-case minimization is formalized would benefit from one additional sentence to make the framework's objective fully explicit without requiring the reader to infer it from the scaling claim.
- The empirical section would be strengthened by reporting the precise meta-learning baselines used and the magnitude of the sample-efficiency gains (e.g., reduction in shots needed to reach a target error).
Simulated Author's Rebuttal
We thank the referee for the positive review, accurate summary of our contributions, and recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The paper defines a new complexity-minimization framework for meta-representation learning and derives an end-to-end theoretical guarantee that few-shot regression error improves with meta-training data volume under that framework. No quoted equation or step reduces the scaling result to a tautology of the framework's own definitions, a fitted parameter renamed as prediction, or a self-citation chain. The analysis is presented as independent content within the stated assumptions on per-domain complexity evaluation and worst-case minimization; the derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Downstream model complexity can be evaluated per domain and minimized in the worst case across source domains
invented entities (1)
-
complexity minimization framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lourie, Nicholas and Hu, Michael Y. and Cho, Kyunghyun. Scaling Laws Are Unreliable for Downstream Tasks: A Reality Check. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.877
-
[2]
Scaling laws for transfer , author=. arXiv:2102.01293 , year=
-
[3]
Journal of Statistical Mechanics: Theory and Experiment , volume=
How feature learning can improve neural scaling laws , author=. Journal of Statistical Mechanics: Theory and Experiment , volume=. 2025 , publisher=
2025
-
[4]
Proceedings of the National Academy of Sciences , volume=
Explaining neural scaling laws , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
2024
-
[5]
Advances in Neural Information Processing Systems , year=
Training Compute-Optimal Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[6]
Scaling laws for neural language models , author=. arXiv:2001.08361 , year=
Pith/arXiv arXiv 2001
-
[7]
Deep learning scaling is predictable, empirically , author=. arXiv:1712.00409 , year=
-
[8]
Advances in neural information processing systems , volume=
Provable guarantees for self-supervised deep learning with spectral contrastive loss , author=. Advances in neural information processing systems , volume=
-
[9]
International conference on machine learning , pages=
A theoretical analysis of contrastive unsupervised representation learning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[10]
Forty-second International Conference on Machine Learning , year=
Nonlinear transformers can perform inference-time feature learning , author=. Forty-second International Conference on Machine Learning , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Feature learning via mean-field langevin dynamics: classifying sparse parities and beyond , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
High-dimensional asymptotics of feature learning: How one gradient step improves the representation , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Conference on Learning Theory , pages=
Kernel and rich regimes in overparametrized models , author=. Conference on Learning Theory , pages=. 2020 , organization=
2020
-
[14]
SIAM Journal on Applied Mathematics , volume=
Mean field analysis of neural networks: A law of large numbers , author=. SIAM Journal on Applied Mathematics , volume=. 2020 , publisher=
2020
-
[15]
Proceedings of the National Academy of Sciences , volume=
A mean field view of the landscape of two-layer neural networks , author=. Proceedings of the National Academy of Sciences , volume=. 2018 , publisher=
2018
-
[16]
Advances in neural information processing systems , volume=
On lazy training in differentiable programming , author=. Advances in neural information processing systems , volume=
-
[17]
International conference on machine learning , pages=
A convergence theory for deep learning via over-parameterization , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[18]
International Conference on Learning Representations , year=
Gradient descent provably optimizes over-parameterized neural networks , author=. International Conference on Learning Representations , year=
-
[19]
Advances in neural information processing systems , volume=
Neural tangent kernel: Convergence and generalization in neural networks , author=. Advances in neural information processing systems , volume=
-
[20]
Journal of Statistical Mechanics: Theory and Experiment , volume=
Deep double descent: Where bigger models and more data hurt , author=. Journal of Statistical Mechanics: Theory and Experiment , volume=. 2021 , publisher=
2021
-
[21]
Proceedings of the National Academy of Sciences , volume=
Reconciling modern machine-learning practice and the classical bias--variance trade-off , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
2019
-
[22]
International Conference on Learning Representations , year=
Understanding deep learning requires rethinking generalization , author=. International Conference on Learning Representations , year=
-
[23]
International Conference on Learning Representations , year=
A PAC-Bayesian Approach to Spectrally-Normalized Margin Bounds for Neural Networks , author=. International Conference on Learning Representations , year=
-
[24]
Advances in neural information processing systems , volume=
Spectrally-normalized margin bounds for neural networks , author=. Advances in neural information processing systems , volume=
-
[25]
International Conference on Machine Learning , pages=
Diffusion models are minimax optimal distribution estimators , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[26]
International Conference on Machine Learning , pages=
Approximation and estimation ability of transformers for sequence-to-sequence functions with infinite dimensional input , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[27]
International conference on machine learning , pages=
Approximation and non-parametric estimation of ResNet-type convolutional neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[28]
2019 , booktitle=
Adaptivity of deep ReLU network for learning in Besov and mixed smooth Besov spaces: optimal rate and curse of dimensionality , author=. 2019 , booktitle=
2019
-
[29]
Neural networks , volume=
Error bounds for approximations with deep ReLU networks , author=. Neural networks , volume=. 2017 , publisher=
2017
-
[30]
arXiv preprint arXiv:2212.06817 , year=
Rt-1: Robotics transformer for real-world control at scale , author=. arXiv preprint arXiv:2212.06817 , year=
-
[31]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[32]
nature , volume=
Highly accurate protein structure prediction with AlphaFold , author=. nature , volume=. 2021 , publisher=
2021
-
[33]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[34]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[35]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[36]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[37]
International Conference on Learning Representations , year=
Meta-learning with differentiable closed-form solvers , author=. International Conference on Learning Representations , year=
-
[38]
Advances in neural information processing systems , volume=
Uniform convergence may be unable to explain generalization in deep learning , author=. Advances in neural information processing systems , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Generalization bounds for meta-learning: An information-theoretic analysis , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
International Conference on Machine Learning , pages=
Meta-learning by adjusting priors based on extended PAC-Bayes theory , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[41]
International Conference on Machine Learning , pages=
A PAC-Bayesian bound for lifelong learning , author=. International Conference on Machine Learning , pages=. 2014 , organization=
2014
-
[42]
Journal of machine learning research , volume=
Stability and generalization , author=. Journal of machine learning research , volume=
-
[43]
Advances in neural information processing systems , volume=
Understanding benign overfitting in gradient-based meta learning , author=. Advances in neural information processing systems , volume=
-
[44]
Advances in Neural Information Processing Systems , volume=
Provable generalization of overparameterized meta-learning trained with sgd , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Advances in Neural Information Processing Systems , volume=
On the stability and generalization of meta-learning , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
International Conference on Machine Learning , pages=
A unified view on pac-bayes bounds for meta-learning , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[47]
Advances in Neural Information Processing Systems , volume=
Towards sample-efficient overparameterized meta-learning , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
International conference on machine learning , pages=
Provable meta-learning of linear representations , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[49]
International conference on machine learning , pages=
Sparse coding for multitask and transfer learning , author=. International conference on machine learning , pages=. 2013 , organization=
2013
-
[50]
Journal of Machine Learning Research , volume=
The benefit of multitask representation learning , author=. Journal of Machine Learning Research , volume=
-
[51]
Journal of artificial intelligence research , volume=
A model of inductive bias learning , author=. Journal of artificial intelligence research , volume=
-
[52]
IEEE transactions on pattern analysis and machine intelligence , volume=
Representation learning: A review and new perspectives , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
2013
-
[53]
IEEE Transactions on knowledge and data engineering , volume=
A survey on transfer learning , author=. IEEE Transactions on knowledge and data engineering , volume=. 2009 , publisher=
2009
-
[54]
A simple neural attentive meta-learner , author=. arXiv:1707.03141 , year=
-
[55]
Advances in neural information processing systems , volume=
Learning to learn by gradient descent by gradient descent , author=. Advances in neural information processing systems , volume=
-
[56]
International conference on artificial neural networks , pages=
Learning to learn using gradient descent , author=. International conference on artificial neural networks , pages=. 2001 , organization=
2001
-
[57]
International conference on learning representations , year=
Optimization as a model for few-shot learning , author=. International conference on learning representations , year=
-
[58]
International conference on machine learning , pages=
Meta-learning with memory-augmented neural networks , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[59]
Advances in neural information processing systems , volume=
Meta-learning with implicit gradients , author=. Advances in neural information processing systems , volume=
-
[60]
Meta-sgd: Learning to learn quickly for few-shot learning , author=. arXiv:1707.09835 , year=
-
[61]
On first-order meta-learning algorithms , author=. arXiv:1803.02999 , year=
-
[62]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Learning to compare: Relation network for few-shot learning , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[63]
Advances in neural information processing systems , volume=
Prototypical networks for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[64]
Advances in neural information processing systems , volume=
Matching networks for one shot learning , author=. Advances in neural information processing systems , volume=
-
[65]
ACM computing surveys (csur) , volume=
Generalizing from a few examples: A survey on few-shot learning , author=. ACM computing surveys (csur) , volume=. 2020 , publisher=
2020
-
[66]
IEEE transactions on pattern analysis and machine intelligence , volume=
Meta-learning in neural networks: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2021 , publisher=
2021
-
[67]
Lepskii, O. V. , date =. On a. doi:10.1137/1135065 , url =
-
[68]
Lepski, O. V. and Mammen, E. and Spokoiny, V. G. , date =. Optimal Spatial Adaptation to Inhomogeneous Smoothness: An Approach Based on Kernel Estimates with Variable Bandwidth Selectors , shorttitle =. doi:10.1214/aos/1069362731 , url =
-
[69]
and Lee, Jason D
Du, Simon Shaolei and Hu, Wei and Kakade, Sham M. and Lee, Jason D. and Lei, Qi , date =. Few-. International
-
[70]
Transformers as
Bai, Yu and Chen, Fan and Wang, Huan and Xiong, Caiming and Mei, Song , date =. Transformers as. Advances in
-
[71]
Transformers Are
Kim, Juno and Nakamaki, Tai and Suzuki, Taiji , date =. Transformers Are. Advances in
-
[72]
Transformers as
Li, Yingcong and Ildiz, Muhammed Emrullah and Papailiopoulos, Dimitris and Oymak, Samet , date =. Transformers as. Proceedings of the 40th
-
[73]
Scaling Laws for Neural Language Models
Kaplan, Jared and McCandlish, Sam and Henighan, Tom and Brown, Tom B. and Chess, Benjamin and Child, Rewon and Gray, Scott and Radford, Alec and Wu, Jeffrey and Amodei, Dario , date =. Scaling. doi:10.48550/arXiv.2001.08361 , url =. 2001.08361 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2001
-
[74]
Scaling Laws for Autoregressive Generative Modeling
Henighan, Tom and Kaplan, Jared and Katz, Mor and Chen, Mark and Hesse, Christopher and Jackson, Jacob and Jun, Heewoo and Brown, Tom B. and Dhariwal, Prafulla and Gray, Scott and Hallacy, Chris and Mann, Benjamin and Radford, Alec and Ramesh, Aditya and Ryder, Nick and Ziegler, Daniel M. and Schulman, John and Amodei, Dario and McCandlish, Sam , date =. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.14701 2010
-
[75]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
A Scaling Law for Syn2real Transfer: How Much Is Your Pre-training Effective? , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2022 , organization=
2022
-
[76]
Finn, Chelsea and Abbeel, Pieter and Levine, Sergey , date =. Model-. Proceedings of the 34th
-
[77]
Hospedales, Timothy and Antoniou, Antreas and Micaelli, Paul and Storkey, Amos , date =. Meta-. doi:10.1109/TPAMI.2021.3079209 , url =
-
[78]
Proceedings of the 39th
Collins, Liam and Mokhtari, Aryan and Oh, Sewoong and Shakkottai, Sanjay , date =. Proceedings of the 39th
-
[79]
The Thirty Seventh Annual Conference on Learning Theory , pages=
Metalearning with very few samples per task , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
2024
-
[80]
Provable
Huang, Yu and Liang, Yingbin and Huang, Longbo , date =. Provable
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.