Automated Essay Scoring and Language Certification: Assessing Generalizability, Agreement and Validity for French
Pith reviewed 2026-06-28 14:57 UTC · model grok-4.3
The pith
An enhanced validation framework uncovers capabilities and limits of automated essay scoring models for French exams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim on the paper's own terms is that an enhanced argument-based validation framework, by incorporating fairness analysis, correlations with linguistic features, prediction error evaluation, and model agreement with human raters, supplies a more practical and comprehensive assessment of automated essay scoring systems than current minimalist benchmarking practices, and that applying it to French data both clarifies model behavior and improves the state of the art for that language.
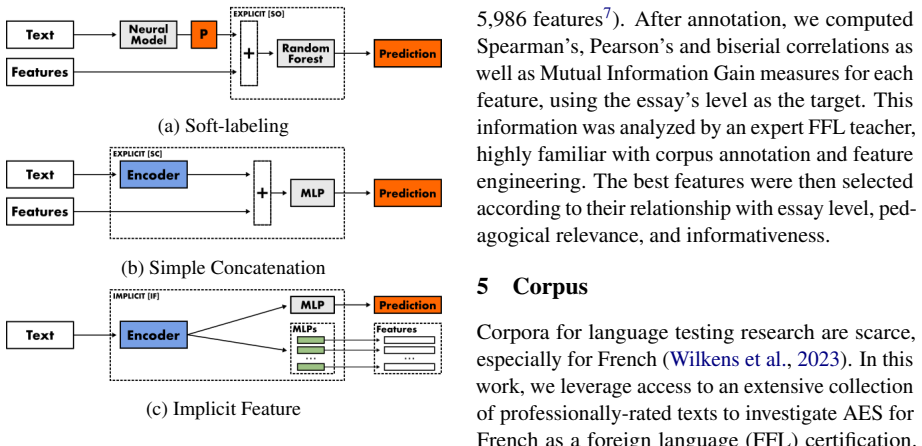
What carries the argument
The enhanced argument-based validation framework, which augments the original multidimensional assessment with four concrete analyses: fairness checks, linguistic-feature correlations, prediction-error breakdown, and multi-rater agreement measurement.
If this is right
- AES models for French can be ranked by how well their scores align with multiple independent human raters rather than single-rater agreement.
- Linguistic features that models rely on or ignore become visible through correlation analysis, guiding feature engineering.
- Prediction errors can be categorized to identify systematic biases such as over- or under-scoring particular essay types.
- Fairness audits can flag whether scoring differences persist across demographic or topic subgroups in the exam data.
Where Pith is reading between the lines
- The same extended validation steps could be tested on AES systems for other languages to check whether the added analyses transfer beyond French.
- Test designers might use the linguistic correlation results to decide which essay prompts better elicit the features models already capture reliably.
- Error analysis outputs could feed into targeted retraining loops that focus on the essay types where models currently diverge most from raters.
Load-bearing premise
That adding fairness analysis, linguistic correlations, error evaluation, and multi-rater agreement produces a more practical and comprehensive assessment than minimalist benchmarking.
What would settle it
An experiment in which minimalist accuracy metrics alone predict real-world deployment outcomes, fairness issues, and generalization performance as accurately as the full enhanced framework.
Figures
read the original abstract
In Automated Essay Scoring (AES), benchmarking practices have fostered minimalist evaluation practices, in contrast with the broader-view recommendations of evaluation frameworks, such as the argument-based validation framework (ABV), which argued in favor of a multidimensional assessment of systems, especially in the context of high-stakes language tests. In this paper, we introduce an enhanced and more practical version of the ABV framework, incorporating fairness analysis, correlations with linguistic features, prediction error evaluation, and model agreement compared with human raters. Applying this framework to French AES, we compare 8 model architectures on a corpus of 27k exam essays (2 raters each) and a generalization corpus of 961 essays (at least nine raters each). Our analyses illustrate the benefits of applying the ABV framework to better understand the capabilities and pitfalls of AES models, while also advancing the state-of-the-art for French AES.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that minimalist benchmarking in Automated Essay Scoring (AES) can be improved by an enhanced argument-based validation (ABV) framework that adds fairness analysis, linguistic feature correlations, prediction error evaluation, and human-rater agreement metrics. Applying the framework to French AES, the authors compare eight model architectures on a primary corpus of 27k exam essays (two raters each) and a generalization corpus of 961 essays (at least nine raters each), arguing that the multidimensional evaluation reveals model capabilities and pitfalls while advancing the state-of-the-art for French AES.
Significance. If the central claims hold, the work would strengthen evaluation standards for high-stakes language certification by demonstrating a practical, multidimensional ABV approach that goes beyond single-metric benchmarking. Credit is due for the explicit use of two corpora to probe generalizability and for extending ABV with concrete analyses (fairness, linguistic correlations, error evaluation) tailored to AES. The contribution would be most valuable if label reliability is established.
major comments (1)
- [§3 (Datasets)] §3 (Datasets): The primary 27k-essay corpus is scored by only two human raters per essay. Because quadratic weighted kappa, fairness metrics, linguistic correlations, prediction error analysis, and model-vs-human agreement all depend on these labels, low inter-rater reliability would directly undermine the trustworthiness of the reported insights into model capabilities and pitfalls as well as the SOTA advancement claims. The 961-essay set uses ≥9 raters, yet the bulk of the eight-architecture comparisons and conclusions appear to rest on the two-rater corpus.
minor comments (1)
- [Abstract] Abstract: the statement that the framework 'advances the state-of-the-art for French AES' would be strengthened by a brief quantitative comparison against previously published French AES results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for emphasizing the importance of establishing label reliability when applying the enhanced ABV framework to high-stakes AES. We address the single major comment point by point below.
read point-by-point responses
-
Referee: [§3 (Datasets)] §3 (Datasets): The primary 27k-essay corpus is scored by only two human raters per essay. Because quadratic weighted kappa, fairness metrics, linguistic correlations, prediction error analysis, and model-vs-human agreement all depend on these labels, low inter-rater reliability would directly undermine the trustworthiness of the reported insights into model capabilities and pitfalls as well as the SOTA advancement claims. The 961-essay set uses ≥9 raters, yet the bulk of the eight-architecture comparisons and conclusions appear to rest on the two-rater corpus.
Authors: We agree that inter-rater reliability is foundational for the validity of all label-dependent metrics in the primary corpus. The manuscript already reports the quadratic weighted kappa between the two raters in Section 3 as part of the dataset description. However, to make this foundation more explicit and to directly respond to the concern, we will revise the paper to add a dedicated paragraph in Section 3 that (a) states the observed QWK value, (b) discusses its implications for the fairness, linguistic-correlation, error, and agreement analyses, and (c) contrasts the two-rater setting with the multi-rater generalization corpus. We will also add a short note in the discussion section explaining how the 961-essay results serve as an external check on the primary-corpus findings. These additions do not change any numerical results but increase transparency and address the referee’s point about trustworthiness. revision: yes
Circularity Check
No circularity: empirical comparison of AES models on external corpora using extended ABV framework
full rationale
The paper's core contribution is an empirical evaluation: it applies an enhanced version of the externally cited argument-based validation (ABV) framework to compare 8 model architectures on two fixed corpora (27k essays with 2 raters; 961 essays with ≥9 raters). No derivation chain, equations, or first-principles results are presented that reduce to the inputs by construction. The enhancements (fairness analysis, linguistic correlations, error evaluation, rater agreement) are additive methodological choices, not self-definitional or fitted predictions. No self-citation load-bearing step is required for the central claims, which rest on direct data analysis rather than prior author work. The work is self-contained against the reported corpora and external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AERA, APA, and NCME associations. 2014. Standards for educational and psychological testing. American Educational Research Association
2014
-
[2]
Y Attali. 2009. Evaluating automated scoring for operational use in consequential language assessment—the ets experience. In annual meeting of the National Council on Measurement in Education, San Diego, CA
2009
-
[3]
Beata Beigman Klebanov and Nitin Madnani. 2020. https://doi.org/10.18653/v1/2020.acl-main.697 Automated evaluation of writing -- 50 years and counting . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7796--7810, Online. Association for Computational Linguistics
-
[4]
Randy Elliot Bennett and Isaac I Bejar. 1998. Validity and automad scoring: It's not only the scoring. Educational Measurement: Issues and Practice, 17(4):9--17
1998
-
[5]
Daniel Blanchard, Joel Tetreault, Derrick Higgins, Aoife Cahill, and Martin Chodorow. 2013. Toefl11: A corpus of non-native english. ETS Research Report Series, 2013(2):i--15
2013
-
[6]
Renske Bouwer, Anton B \'e guin, Ted Sanders, and Huub Van den Bergh. 2015. Effect of genre on the generalizability of writing scores. Language Testing, 32(1):83--100
2015
-
[7]
Adriane Boyd, Jirka Hana, Lionel Nicolas, Detmar Meurers, Katrin Wisniewski, Andrea Abel, Karin Schöne, Barbora Stindlová, and Chiara Vettori. 2014. The MERLIN corpus: Learner language and the CEFR . In Proceedings of the Ninth International Conference on Language Resources and Evaluation, pages 1281--–1288
2014
-
[8]
Brent Bridgeman, Catherine Trapani, and Yigal Attali. 2009. Considering fairness and validity in evaluating automated scoring. In annual meeting of the National Council on Measurement in Education, San Diego, CA
2009
-
[9]
Jill Burstein and Martin Chodorow. 1999. Automated essay scoring for nonnative english speakers. In Computer mediated language assessment and evaluation in natural language processing
1999
-
[10]
Jill Burstein, Karen Kukich, Susanne Wolff, Chi Lu, Martin Chodorow, Lisa Braden-Harder, and Mary Dee Harris. 1998. https://doi.org/10.3115/980845.980879 Automated scoring using a hybrid feature identification technique . In 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics,...
-
[11]
Carol A Chapelle, Mary K Enright, and Joan M Jamieson. 2008. Building a validity argument for the Test of English as a Foreign Language. Routledge
2008
-
[12]
Brian E Clauser, Michael T Kane, and David B Swanson. 2002. Validity issues for performance-based tests scored with computer-automated scoring systems. Applied Measurement in Education, 15(4):413--432
2002
-
[13]
Open Cambridge Learner Corpus. 2017. Distributed by lexical computing limited on behalf of cambridge university press and cambridge english language assessment
2017
-
[14]
Council of Europe . 2020. Common European Framework of Reference for Languages: Learning, Teaching, Assessment -- Companion Volume. Council of Europe Publishing
2020
-
[15]
Bastien De Clercq and Alex Housen. 2017. A cross-linguistic perspective on syntactic complexity in l2 development: Syntactic elaboration and diversity. The Modern Language Journal, 101(2):315--334
2017
-
[16]
Afrizal Doewes, Nughthoh Kurdhi, and Akrati Saxena. 2023. Evaluating quadratic weighted kappa as the standard performance metric for automated essay scoring. In 16th International Conference on Educational Data Mining, EDM 2023, pages 103--113. International Educational Data Mining Society (IEDMS)
2023
-
[17]
T. Eckes. 2009. https://doi.org/10.4324/9781315187815 Quantitative Data Analysis for Language Assessment Volume I : Fundamental Techniques , 1 edition. Routledge
-
[18]
Fanny Forsberg Lundell and Christina Lindqvist. 2014. Vocabulary aspects of advanced l2 french: Do lexical formulaic sequences and lexical richness develop at the same rate? In The Acquisition of French as a Second Language: New developmental perspectives, pages 75--94. John Benjamins Publishing Company
2014
-
[19]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. 2017. http://arxiv.org/abs/1706.04599 On calibration of modern neural networks
Pith/arXiv arXiv 2017
-
[20]
Kilem L Gwet. 2014. Handbook of inter-rater reliability: The definitive guide to measuring the extent of agreement among raters. Advanced Analytics, LLC
2014
-
[21]
Jinyan Huang and Patrick B Whipple. 2023. Rater variability and reliability of constructed response questions in new york state high-stakes tests of english language arts and mathematics: implications for educational assessment policy. Humanities and Social Sciences Communications, 10(1):1--10
2023
-
[22]
Shi Huawei and Vahid Aryadoust. 2023. A systematic review of automated writing evaluation systems. Education and Information Technologies, 28(1):771--795
2023
-
[23]
Zhiwei Jiang, Tianyi Gao, Yafeng Yin, Meng Liu, Hua Yu, Zifeng Cheng, and Qing Gu. 2023. https://doi.org/10.18653/v1/2023.acl-long.696 Improving domain generalization for prompt-aware essay scoring via disentangled representation learning . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ...
-
[24]
Cancan Jin, Ben He, Kai Hui, and Le Sun. 2018. Tdnn: a two-stage deep neural network for prompt-independent automated essay scoring. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1088--1097
2018
-
[25]
Michael T Kane. 2013. Validating the interpretations and uses of test scores. Journal of educational measurement, 50(1):1--73
2013
-
[26]
Beata Beigman Klebanov and Nitin Madnani. 2021. Automated essay scoring. Synthesis Lectures on Human Language Technologies, 14(5):1--314
2021
-
[27]
Jason Sebastian Kusuma, Kevin Halim, Edgard Jonathan Putra Pranoto, Bayu Kanigoro, and Edy Irwansyah. 2022. Automated essay scoring using machine learning. In 2022 4th International Conference on Cybernetics and Intelligent System (ICORIS), pages 1--5. IEEE
2022
-
[29]
Guoxi Liang, Byung-Won On, Dongwon Jeong, Hyun-Chul Kim, and Gyu Sang Choi. 2018. Automated essay scoring: A siamese bidirectional lstm neural network architecture. Symmetry, 10(12):682
2018
-
[30]
Susan Lottridge, Chris Ormerod, and Amir Jafari. 2023. Psychometric considerations when using deep learning for automated scoring. Advancing natural language processing in educational assessment, pages 15--30
2023
-
[31]
Anastassia Loukina, Nitin Madnani, and Klaus Zechner. 2019. The many dimensions of algorithmic fairness in educational applications. In Proceedings of the fourteenth workshop on innovative use of NLP for building educational applications, pages 1--10
2019
-
[32]
Anastassia Loukina, Klaus Zechner, James Bruno, and Beata Beigman Klebanov. 2018. https://doi.org/10.18653/v1/W18-0501 Using exemplar responses for training and evaluating automated speech scoring systems . In Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications , pages 1--12, New Orleans, Louisiana. Associ...
-
[33]
Nitin Madnani and Aoife Cahill. 2018. https://aclanthology.org/C18-1094 Automated scoring: Beyond natural language processing . In Proceedings of the 27th International Conference on Computational Linguistics, pages 1099--1109, Santa Fe, New Mexico, USA. Association for Computational Linguistics
2018
-
[34]
Louis Martin, Benjamin Muller, Pedro Javier Ortiz Su \'a rez, Yoann Dupont, Laurent Romary, \'E ric de la Clergerie, Djam \'e Seddah, and Beno \^ t Sagot. 2020. https://doi.org/10.18653/v1/2020.acl-main.645 C amem BERT : a tasty F rench language model . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7203-...
-
[35]
Elijah Mayfield and Alan W Black. 2020. Should you fine-tune bert for automated essay scoring? In Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications, pages 151--162
2020
-
[36]
Daniel F McCaffrey, Jodi M Casabianca, Kathryn L Ricker-Pedley, Ren \'e R Lawless, and Cathy Wendler. 2022. Best practices for constructed-response scoring. ETS Research Report Series, 2022(1):1--58
2022
-
[37]
Am \'a lia Mendes, Sandra Antunes, Maarten Janssen, and Anabela Gon c alves. 2016. https://aclanthology.org/L16-1511 The COPLE 2 corpus: a learner corpus for P ortuguese . In Proceedings of the Tenth International Conference on Language Resources and Evaluation ( LREC '16) , pages 3207--3214, Portoro z , Slovenia. European Language Resources Association (ELRA)
2016
-
[38]
Samuel Messick. 1990. Validity of test interpretation and use. Technical Report ETS-RR-90-11, ETS, Princeton, N.J
1990
-
[39]
Atsushi Mizumoto and Masaki Eguchi. 2023. Exploring the potential of using an ai language model for automated essay scoring. Research Methods in Applied Linguistics, 2(2):100050
2023
-
[40]
Ricardo Mu \ n oz S \'a nchez, David Alfter, Simon Dobnik, Maria Irena Szawerna, and Elena Volodina. 2024. https://aclanthology.org/2024.nlp4call-1.11/ Jingle BERT , jingle BERT , frozen all the way: Freezing layers to identify CEFR levels of second language learners using BERT . In Proceedings of the 13th Workshop on Natural Language Processing for Compu...
2024
-
[41]
Diane Nicholls. 2003. The C ambridge L earner C orpus: E rror coding and analysis for lexicography and ELT . In Proceedings of the Corpus Linguistics 2003 conference, volume 16, pages 572--581
2003
-
[42]
Nicholas Parslow. 2015. http://rgdoi.net/10.13140/RG.2.1.2833.5204 Automated Analysis of L2 French Writing : a preliminary study . Master's thesis. Publisher: Unpublished
-
[43]
Pearson. 2019. Pte academic automated scoring. re- trieved from: https://assets.ctfassets.net/yqwtwibiobs4/018RxttvPWsMkkGIQJ5Gg3/6f410437ceb2c6f2762fbcdfa8a28e8c/2021_PTEA_White_Paper_Institutions_Automated_Scoring_White_Paper-May-2018.pdf, accessed june 30th, 2024
2019
-
[45]
Bojana Ranković, Sarah Smirnow, Martin Jaggi, and Martin J. Tomasik. 2020. Automated Essay Scoring in Foreign Language Students Based on Deep Contextualised Word Representations . In LAK20 -10th International Conference on Learning Analytics & Knowledge . Issue: CONF
2020
-
[47]
Rudner, Veronica Garcia, and Catherine Welch
Lawrence M. Rudner, Veronica Garcia, and Catherine Welch. 2006. An evaluation of IntelliMetric essay scoring system. The Journal of Technology, Learning and Assessment, 4(4)
2006
-
[49]
Elana Shohamy, Smadar Donitsa-Schmidt, and Irit Ferman. 1996. Test impact revisited: Washback effect over time. Language testing, 13(3):298--317
1996
-
[50]
Steven E Stemler and Jessica Tsai. 2008. Best practices in interrater reliability three common approaches. Best practices in quantitative methods, pages 29--49
2008
-
[51]
Kaveh Taghipour and Hwee Tou Ng. 2016. A neural approach to automated essay scoring. In Proceedings of the 2016 conference on empirical methods in natural language processing, pages 1882--1891
2016
-
[52]
Yi Tay, Minh Phan, Luu Anh Tuan, and Siu Cheung Hui. 2018. Skipflow: Incorporating neural coherence features for end-to-end automatic text scoring. In Proceedings of the AAAI conference on artificial intelligence, volume 32
2018
-
[53]
Kari Tenfjord, Paul Meurer, and Knut Hofland. 2006. http://www.lrec-conf.org/proceedings/lrec2006/pdf/573_pdf.pdf The ASK corpus - a language learner corpus of N orwegian as a second language . In Proceedings of the Fifth International Conference on Language Resources and Evaluation ( LREC ' 06) , Genoa, Italy. European Language Resources Association (ELRA)
2006
-
[54]
Masaki Uto, Itsuki Aomi, Emiko Tsutsumi, and Maomi Ueno. 2023. Integration of prediction scores from various automated essay scoring models using item response theory. IEEE Transactions on Learning Technologies
2023
-
[55]
Masaki Uto, Yikuan Xie, and Maomi Ueno. 2020. Neural automated essay scoring incorporating handcrafted features. In Proceedings of the 28th International Conference on Computational Linguistics, pages 6077--6088
2020
-
[56]
Salvatore Valenti, Francesca Neri, and Alessandro Cucchiarelli. 2003. An overview of current research on automated essay grading. Journal of Information Technology Education: Research, 2(1):319--330. Publisher: Informing Science Institute
2003
-
[57]
Alexander Von Eye and Eun Young Mun. 2014. Analyzing rater agreement: Manifest variable methods. Psychology Press
2014
-
[59]
Yancey, and Thomas Fran c ois
Rodrigo Wilkens, David Alfter, Xiaoou Wang, Alice Pintard, Ana \" s Tack, Kevin P. Yancey, and Thomas Fran c ois. 2022. https://aclanthology.org/2022.lrec-1.130 FABRA : F rench aggregator-based readability assessment toolkit . In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 1217--1233, Marseille, France. European Langu...
2022
-
[61]
Rodrigo Wilkens, Patrick Watrin, R \'e mi Cardon, Alice Pintard, Isabelle Gribomont, and Thomas Fran c ois. 2024. Exploring hybrid approaches to readability: experiments on the complementarity between linguistic features and transformers. In Findings of the Association for Computational Linguistics: EACL 2024, pages 2316--2331
2024
-
[62]
David M Williamson, Xiaoming Xi, and F Jay Breyer. 2012. A framework for evaluation and use of automated scoring. Educational measurement: issues and practice, 31(1):2--13
2012
-
[63]
Xiaoming Xi. 2008. What and how much evidence do we need? critical considerations in validating an automated scoring system. In C.A. Chapelle, Y.R. Chung, and J. Xu, editors, Towards adaptive CALL: Natural language processing for diagnostic language assessment, pages 102--114. Iowa State University Ames, IA
2008
-
[64]
Jiayi Xie, Kaiwei Cai, Li Kong, Junsheng Zhou, and Weiguang Qu. 2022. https://aclanthology.org/2022.coling-1.240 Automated essay scoring via pairwise contrastive regression . In Proceedings of the 29th International Conference on Computational Linguistics, pages 2724--2733, Gyeongju, Republic of Korea. International Committee on Computational Linguistics
2022
-
[65]
Duanli Yan and Brent Bridgeman. 2020. Validation of automated scoring systems. In Handbook of Automated Scoring, pages 297--318. Chapman and Hall/CRC
2020
-
[66]
Duanli Yan, Andr \'e A Rupp, and Peter W Foltz. 2020. Handbook of automated scoring: Theory into practice. CRC Press
2020
-
[67]
Ruosong Yang, Jiannong Cao, Zhiyuan Wen, Youzheng Wu, and Xiaodong He. 2020. Enhancing automated essay scoring performance via fine-tuning pre-trained language models with combination of regression and ranking. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1560--1569
2020
-
[68]
Tal Yarkoni, David Balota, and Melvin Yap. 2008. Moving beyond coltheart’s n: A new measure of orthographic similarity. Psychonomic bulletin & review, 15(5):971--979
2008
-
[69]
Wajdi Zaghouani. 2002. AUTO -É VAL : vers un modèle d'évaluation automatique des textes. In Actes du colloque des étudiants en sciences du langage, page 16, Montréal, Canada. Université du Québec à Montréal
2002
-
[70]
Torsten Zesch, Michael Wojatzki, and Dirk Scholten-Akoun. 2015. Task-independent features for automated essay grading. In Proceedings of the tenth workshop on innovative use of NLP for building educational applications, pages 224--232
2015
-
[71]
Proceedings of the tenth workshop on innovative use of NLP for building educational applications , pages=
Task-independent features for automated essay grading , author=. Proceedings of the tenth workshop on innovative use of NLP for building educational applications , pages=
-
[72]
Language testing , volume=
Test impact revisited: Washback effect over time , author=. Language testing , volume=. 1996 , publisher=
1996
-
[73]
The Modern Language Journal , volume=
A cross-linguistic perspective on syntactic complexity in L2 development: Syntactic elaboration and diversity , author=. The Modern Language Journal , volume=. 2017 , publisher=
2017
-
[74]
The Acquisition of French as a Second Language: New developmental perspectives , pages=
Vocabulary aspects of advanced L2 French: Do lexical formulaic sequences and lexical richness develop at the same rate? , author=. The Acquisition of French as a Second Language: New developmental perspectives , pages=. 2014 , publisher=
2014
-
[75]
2008 , publisher=
Building a validity argument for the Test of English as a Foreign Language , author=. 2008 , publisher=
2008
-
[76]
Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
Automated essay scoring by maximizing human-machine agreement , author=. Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
2013
-
[77]
Nicholls, Diane , booktitle=. The
-
[78]
2017 , school=
Robust trait-specific essay scoring using neural networks and density estimators , author=. 2017 , school=
2017
-
[79]
PTE academic automated scoring
Pearson , year =. PTE academic automated scoring. Re- trieved from:
-
[80]
annual meeting of the National Council on Measurement in Education, San Diego, CA , year=
Evaluating automated scoring for operational use in consequential language assessment—the ETS experience , author=. annual meeting of the National Council on Measurement in Education, San Diego, CA , year=
-
[81]
annual meeting of the National Council on Measurement in Education, San Diego, CA , year=
Considering fairness and validity in evaluating automated scoring , author=. annual meeting of the National Council on Measurement in Education, San Diego, CA , year=
-
[82]
18th Conference of the European Chapter of the Association for Computational Linguistics , year=
Exploring hybrid approaches to readability: experiments on the complementarity between linguistic features and transformers , author=. 18th Conference of the European Chapter of the Association for Computational Linguistics , year=
-
[83]
Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications , pages=
Automated essay scoring for Swedish , author=. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications , pages=
-
[84]
Distributed by Lexical Computing Limited on behalf of Cambridge University Press and Cambridge English Language Assessment , author=
-
[85]
2017 , eprint=
On Calibration of Modern Neural Networks , author=. 2017 , eprint=
2017
-
[86]
Boyd, Adriane and Hana, Jirka and Nicolas, Lionel and Meurers, Detmar and Wisniewski, Katrin and Abel, Andrea and Schöne, Karin and Stindlová, Barbora and Vettori, Chiara , keywords =. The. Proceedings of the Ninth International Conference on Language Resources and Evaluation , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.