DFlare: Scaling Up Draft Capacity for Block Diffusion Speculative Decoding
Pith reviewed 2026-06-28 14:46 UTC · model grok-4.3
The pith
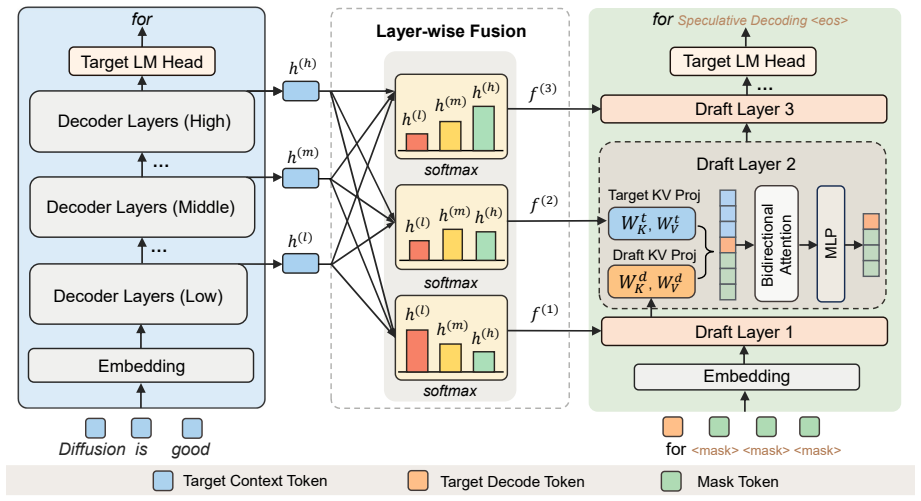
DFlare replaces DFlash's shared fusion with layer-wise combinations so each draft layer receives its own mix of target layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
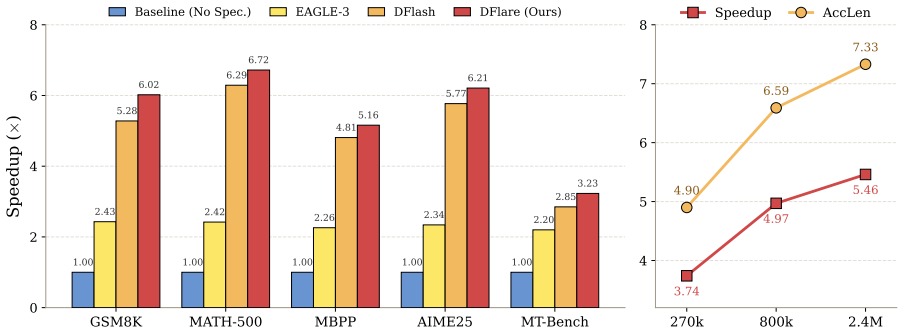
DFlare flares out the narrow conditioning bottleneck of DFlash through a lightweight layer-wise fusion mechanism where each draft layer attends to its own learnable combination of a broad set of target layers, injecting richer target knowledge and giving every draft layer a distinct input, which enables scaling the draft model to deeper architectures with consistent gains when also increasing training data to 2.4M samples.
What carries the argument
The lightweight layer-wise fusion mechanism that lets each draft layer attend to its own learnable combination of target layers.
If this is right
- Draft models can be scaled to greater depth while maintaining training stability.
- Wall-clock speedups reach 5.52x on Qwen3-4B and similar gains on larger models.
- Performance improves over prior methods by 5-11% on the tested benchmarks.
- Target model knowledge is utilized more effectively across draft layers.
Where Pith is reading between the lines
- If the layer-wise approach generalizes, similar per-layer conditioning could improve other draft-based acceleration techniques.
- Training larger draft models this way might reduce the need for very large target models in some inference scenarios.
- Future work could test whether the fusion weights reveal which target layers matter most for different draft depths.
Load-bearing premise
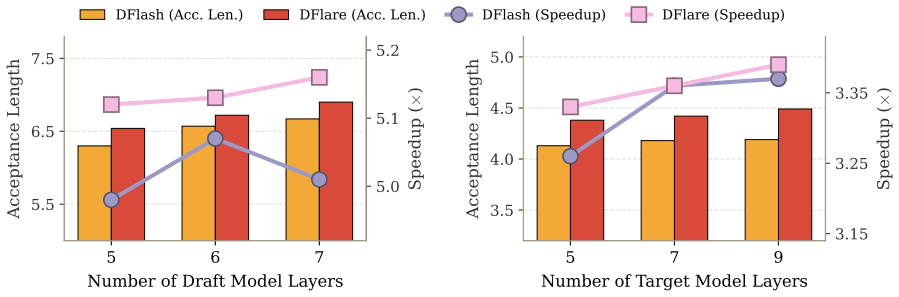
The gains are driven by the per-layer expressiveness of the fusion rather than simply by training on more data or using deeper models.
What would settle it
A controlled experiment training DFlare without the layer-specific combinations and measuring whether speedups drop back to DFlash levels on the same benchmarks and models.
Figures
read the original abstract
Block diffusion speculative decoding accelerates LLM inference by predicting all tokens within a block simultaneously for the target model to verify in parallel. Predicting an entire block at once requires a sufficiently capable draft model and effective utilization of the target model's internal knowledge. However, the state-of-the-art method DFlash constrains all draft layers to share a single fused representation derived from only a few target layers, limiting per-layer expressiveness and hindering further scaling of draft capacity. In this paper, we present \modelname, which flares out the narrow conditioning bottleneck of DFlash through a lightweight layer-wise fusion mechanism: each draft layer attends to its own learnable combination of a broad set of target layers at negligible overhead, simultaneously injecting richer target knowledge and providing every draft layer with a distinct input. This enhanced per-layer expressiveness enables scaling the draft model to deeper architectures with consistent gains. We further scale training data from 800K to 2.4M samples to fully exploit the enlarged capacity. On six benchmarks spanning mathematical reasoning, code generation, and conversation, \modelname attains average wall-clock speedups of 5.52x on Qwen3-4B, 5.46x on Qwen3-8B, and 3.91x on GPT-OSS-20B, improving over DFlash by roughly 11\%, 8\%, and 5\% respectively. Our code is available at https://github.com/Tencent/AngelSlim.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DFlare, an extension of block diffusion speculative decoding that replaces DFlash's shared fused representation with a lightweight layer-wise fusion mechanism. Each draft layer now attends to its own learnable combination of a broad set of target layers, enabling deeper draft architectures and richer per-layer conditioning. The authors also triple the training data (800K to 2.4M samples) and report average wall-clock speedups of 5.52× on Qwen3-4B, 5.46× on Qwen3-8B, and 3.91× on GPT-OSS-20B, which are 11%, 8%, and 5% higher than DFlash on six benchmarks.
Significance. If the per-layer fusion is shown to be the primary driver rather than the data increase, the method would provide a low-overhead way to scale draft capacity in speculative decoding, which could meaningfully improve inference throughput for large models. The open code release is a positive factor for reproducibility.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the 11%/8%/5% gains over DFlash are presented as resulting from the layer-wise fusion, yet the manuscript simultaneously triples the training data (800K→2.4M). No ablation is described that holds data volume fixed while varying only the fusion mechanism (shared vs. layer-wise) or holds the architecture fixed while varying only data volume. This prevents confident attribution of the reported speedups to the claimed architectural change.
- [Abstract] Abstract: the speedups are given as point estimates with no error bars, standard deviations across runs, or statistical tests. Without these, it is impossible to assess whether the 5–11% margins over DFlash are reliable or could be explained by run-to-run variance.
- [Abstract] Abstract: the evaluation is limited to three target models and a single (unspecified) sampling temperature. No results are shown for additional temperatures, different target architectures, or verification that the gains survive changes in the target model's internal representations.
minor comments (1)
- [Abstract] The abstract states that the fusion operates “at negligible overhead,” but no concrete FLOPs or latency measurements for the fusion module itself are provided to support this claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the major concerns, committing to revisions that strengthen attribution and reporting while noting the scope of feasible additions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the 11%/8%/5% gains over DFlash are presented as resulting from the layer-wise fusion, yet the manuscript simultaneously triples the training data (800K→2.4M). No ablation is described that holds data volume fixed while varying only the fusion mechanism (shared vs. layer-wise) or holds the architecture fixed while varying only data volume. This prevents confident attribution of the reported speedups to the claimed architectural change.
Authors: We agree that an explicit ablation isolating the fusion mechanism from data scaling would improve attribution. The layer-wise fusion enables deeper drafts that benefit from additional data, but to clarify the architectural contribution we will add, in the revision, an ablation that trains both DFlash and DFlare on the original 800K samples and reports the resulting speedups. revision: yes
-
Referee: [Abstract] Abstract: the speedups are given as point estimates with no error bars, standard deviations across runs, or statistical tests. Without these, it is impossible to assess whether the 5–11% margins over DFlash are reliable or could be explained by run-to-run variance.
Authors: We acknowledge that variability metrics are needed to assess reliability. In the revised manuscript we will report standard deviations obtained from three independent training and evaluation runs for each model and include paired statistical tests comparing DFlare against DFlash. revision: yes
-
Referee: [Abstract] Abstract: the evaluation is limited to three target models and a single (unspecified) sampling temperature. No results are shown for additional temperatures, different target architectures, or verification that the gains survive changes in the target model's internal representations.
Authors: The evaluation uses three models spanning 4B–20B parameters and six benchmarks. We will add speedups at temperatures 0.5, 0.7 and 1.0 for all models in the revision. Extending to further architectures or internal-representation probes would require substantial new compute; we will note this scope limitation explicitly. revision: partial
Circularity Check
No significant circularity; empirical speedups measured on fixed benchmarks
full rationale
The paper describes an architectural change (layer-wise fusion) plus data scaling, then reports measured wall-clock speedups on six benchmarks. No equations, fitted parameters, or self-citations are presented that reduce the claimed gains to a definition or self-referential construction. The central result is an external empirical measurement rather than a derivation that collapses into its inputs by construction. This is the normal case of a self-contained empirical claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning , pages=
Fast inference from transformers via speculative decoding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
Accelerating large language model decoding with speculative sampling , author=. arXiv preprint arXiv:2302.01318 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Better & faster large language models via multi-token prediction , year =
Gloeckle, Fabian and Idrissi, Badr Youbi and Rozi\`. Better & faster large language models via multi-token prediction , year =. Proceedings of the 41st International Conference on Machine Learning , articleno =
-
[4]
2025 , eprint=
TiDAR: Think in Diffusion, Talk in Autoregression , author=. 2025 , eprint=
2025
-
[5]
Proceedings of the 41st International Conference on Machine Learning , pages=
MEDUSA: Simple LLM inference acceleration framework with multiple decoding heads , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[6]
2026 , eprint=
P-EAGLE: Parallel-Drafting EAGLE with Scalable Training , author=. 2026 , eprint=
2026
-
[7]
2026 , eprint=
DFlash: Block Diffusion for Flash Speculative Decoding , author=. 2026 , eprint=
2026
-
[8]
2025 , eprint=
Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion , author=. 2025 , eprint=
2025
-
[9]
2025 , eprint=
SpecDiff-2: Scaling Diffusion Drafter Alignment For Faster Speculative Decoding , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
DiffuSpec: Unlocking Diffusion Language Models for Speculative Decoding , author=. 2025 , eprint=
2025
-
[11]
International Conference on Machine Learning , year =
Yuhui Li and Fangyun Wei and Chao Zhang and Hongyang Zhang , title =. International Conference on Machine Learning , year =
-
[12]
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Eagle-3: Scaling up inference acceleration of large language models via training-time test , author=. arXiv preprint arXiv:2503.01840 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2025 , eprint=
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding , author=. 2025 , eprint=
2025
-
[14]
2025 , eprint=
Fast-dLLM v2: Efficient Block-Diffusion LLM , author=. 2025 , eprint=
2025
-
[15]
The Thirteenth International Conference on Learning Representations , year=
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[16]
2025 , eprint=
SpecDec++: Boosting Speculative Decoding via Adaptive Candidate Lengths , author=. 2025 , eprint=
2025
-
[17]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[18]
2021 , eprint=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
2021
-
[19]
American Invitational Mathematics Examination (AIME) 2025 , author=
2025
-
[20]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[21]
2021 , eprint=
Program Synthesis with Large Language Models , author=. 2021 , eprint=
2021
-
[22]
2024 , eprint=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. 2024 , eprint=
2024
-
[23]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[24]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[25]
2025 , eprint=
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model , author=. 2025 , eprint=
2025
-
[26]
Step 3.5 Flash: Open frontier-level intelligence with 11b active parameters, 2026
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters , author=. arXiv preprint arXiv:2602.10604 , year=
-
[27]
2023 , eprint=
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations , author=. 2023 , eprint=
2023
-
[28]
2024 , eprint=
EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees , author=. 2024 , eprint=
2024
-
[29]
arXiv preprint arXiv:2509.22134 , year=
Bridging Draft Policy Misalignment: Group Tree Optimization for Speculative Decoding , author=. arXiv preprint arXiv:2509.22134 , year=
-
[30]
arXiv preprint arXiv:2305.09781 , year=
Specinfer: Accelerating generative large language model serving with tree-based speculative inference and verification , author=. arXiv preprint arXiv:2305.09781 , year=
-
[31]
GitHub repository , howpublished =
Sahil Chaudhary , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[32]
2024 , eprint=
Hydra: Sequentially-Dependent Draft Heads for Medusa Decoding , author=. 2024 , eprint=
2024
-
[33]
2025 , eprint=
Learning Harmonized Representations for Speculative Sampling , author=. 2025 , eprint=
2025
-
[34]
2025 , eprint=
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty , author=. 2025 , eprint=
2025
-
[35]
2024 , eprint=
GliDe with a CaPE: A Low-Hassle Method to Accelerate Speculative Decoding , author=. 2024 , eprint=
2024
-
[36]
2024 , eprint=
Dynamic Depth Decoding: Faster Speculative Decoding for LLMs , author=. 2024 , eprint=
2024
-
[37]
2025 , eprint=
Draft Model Knows When to Stop: Self-Verification Speculative Decoding for Long-Form Generation , author=. 2025 , eprint=
2025
-
[38]
2025 , eprint=
Token-Driven GammaTune: Adaptive Calibration for Enhanced Speculative Decoding , author=. 2025 , eprint=
2025
-
[39]
2024 , eprint=
Dynamic Speculation Lookahead Accelerates Speculative Decoding of Large Language Models , author=. 2024 , eprint=
2024
-
[40]
2025 , eprint=
C2T: A Classifier-Based Tree Construction Method in Speculative Decoding , author=. 2025 , eprint=
2025
-
[41]
2024 , eprint=
SGLang: Efficient Execution of Structured Language Model Programs , author=. 2024 , eprint=
2024
-
[42]
2025 , eprint=
Scaling Laws for Speculative Decoding , author=. 2025 , eprint=
2025
-
[43]
Xia, Heming and Yang, Zhe and Dong, Qingxiu and Wang, Peiyi and Li, Yongqi and Ge, Tao and Liu, Tianyu and Li, Wenjie and Sui, Zhifang. Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding. Findings of the Association for Computational Linguistics ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.456
-
[44]
Distillspec: Improving speculative decoding via knowledge distillation , author=. arXiv preprint arXiv:2310.08461 , year=
-
[45]
Online speculative decoding , author=. arXiv preprint arXiv:2310.07177 , year=
-
[46]
2025 , eprint=
GRIFFIN: Effective Token Alignment for Faster Speculative Decoding , author=. 2025 , eprint=
2025
-
[47]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[48]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
arXiv preprint arXiv:2602.21233 , year=
AngelSlim: A more accessible, comprehensive, and efficient toolkit for large model compression , author=. arXiv preprint arXiv:2602.21233 , year=
-
[50]
2022 , eprint=
Diffusion-LM Improves Controllable Text Generation , author=. 2022 , eprint=
2022
-
[51]
2022 , eprint=
Self-conditioned Embedding Diffusion for Text Generation , author=. 2022 , eprint=
2022
-
[52]
2023 , eprint=
Structured Denoising Diffusion Models in Discrete State-Spaces , author=. 2023 , eprint=
2023
-
[53]
2022 , eprint=
DiffusionBERT: Improving Generative Masked Language Models with Diffusion Models , author=. 2022 , eprint=
2022
-
[54]
2024 , eprint=
Simple and Effective Masked Diffusion Language Models , author=. 2024 , eprint=
2024
-
[55]
2025 , eprint=
Simplified and Generalized Masked Diffusion for Discrete Data , author=. 2025 , eprint=
2025
-
[56]
A Survey on Diffusion Language Models
A survey on diffusion language models , author=. arXiv preprint arXiv:2508.10875 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.