PortBERT: Navigating the Depths of Portuguese Language Models
Pith reviewed 2026-06-28 14:41 UTC · model grok-4.3
The pith
PortBERT base and large models match or exceed prior Portuguese NLP performance on translated GLUE tasks while documenting efficiency metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
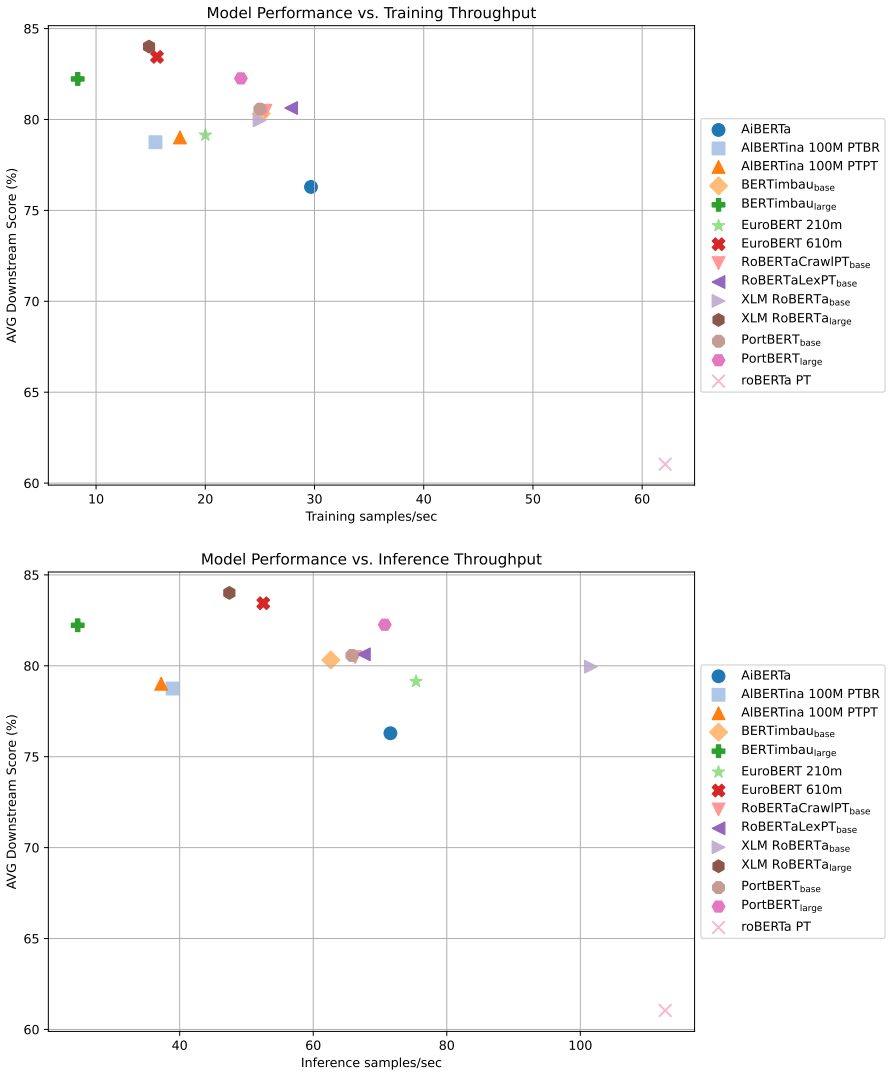
PortBERT consists of two RoBERTa-style transformer models trained from scratch on a large Portuguese corpus; when evaluated on the translated ExtraGLUE benchmark the base and large variants match or surpass the accuracy of prior monolingual and multilingual models while the authors also record training times, inference latency, and fine-tuning throughput to quantify efficiency.
What carries the argument
PortBERT, a pair of RoBERTa-based transformer language models trained from scratch on deduplicated Portuguese text with byte-level BPE tokenization and stable pre-training routines.
If this is right
- PortBERT base and large reach competitive or higher accuracy than prior models on the ExtraGLUE suite of Portuguese tasks.
- Training, inference, and fine-tuning throughput numbers are reported, allowing direct efficiency comparisons with other models.
- Public release of Hugging Face weights and fairseq checkpoints makes the models immediately usable for downstream Portuguese applications.
- The emphasis on compute-performance tradeoffs supplies a practical complement to earlier Portuguese models that focused mainly on scale or peak accuracy.
Where Pith is reading between the lines
- The reported efficiency numbers could help practitioners choose a model size that fits available hardware without sacrificing benchmark scores.
- The same data-filtering and hardware-agnostic training approach might be reused for other languages where large clean corpora exist but dedicated models are scarce.
- If native Portuguese benchmarks later show different relative rankings, the current ExtraGLUE results would need re-interpretation rather than direct transfer.
Load-bearing premise
Translated English GLUE and SuperGLUE tasks provide a faithful measure of Portuguese language understanding without meaningful distortion from translation or cultural mismatch.
What would settle it
New results on native, untranslated Portuguese understanding tasks that place PortBERT below the strongest existing models, or direct evidence that translation artifacts systematically inflate or deflate ExtraGLUE scores.
Figures
read the original abstract
Transformer models dominate modern NLP, but efficient, language-specific models remain scarce. In Portuguese, most focus on scale or accuracy, often neglecting training and deployment efficiency. In the present work, we introduce PortBERT, a family of RoBERTa-based language models for Portuguese, designed to balance performance and efficiency. Trained from scratch on over 450 GB of deduplicated and filtered mC4 and OSCAR23 from CulturaX using fairseq, PortBERT leverages byte-level BPE tokenization and stable pre-training routines across both GPU and TPU processors. We release two variants, PortBERT base and PortBERT large, and evaluate them on ExtraGLUE, a suite of translated GLUE and SuperGLUE tasks. Both models perform competitively, matching or surpassing existing monolingual and multilingual models. Beyond accuracy, we report training and inference times as well as fine-tuning throughput, providing practical insights into model efficiency. PortBERT thus complements prior work by addressing the underexplored dimension of compute-performance tradeoffs in Portuguese NLP. We release all models on Huggingface and provide fairseq checkpoints to support further research and applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PortBERT, a family of RoBERTa-based language models for Portuguese trained from scratch on over 450 GB of deduplicated mC4 and OSCAR23 data using fairseq with byte-level BPE. It releases base and large variants and evaluates them on ExtraGLUE (translated GLUE and SuperGLUE tasks), claiming competitive or superior performance relative to existing monolingual and multilingual models while also reporting training/inference times and fine-tuning throughput to highlight efficiency tradeoffs.
Significance. If the performance claims are substantiated, the work fills a gap in efficient Portuguese-specific models by emphasizing compute-performance balance and publicly releasing models on Hugging Face plus fairseq checkpoints, which supports reproducibility and further research in an underexplored language.
major comments (2)
- [Abstract] Abstract: the claim that 'both models perform competitively, matching or surpassing existing monolingual and multilingual models' on ExtraGLUE supplies no numerical scores, baseline details, statistical tests, or error bars, preventing verification of the central empirical claim.
- [Abstract / Evaluation] Evaluation (ExtraGLUE description): the paper states that tasks were translated but provides no evidence of translation-quality controls such as back-translation checks, human fidelity ratings, or side-by-side comparison against native Portuguese benchmarks; without this, translation artifacts remain a plausible confound that could invalidate ExtraGLUE as a faithful proxy for Portuguese understanding.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. The comments highlight opportunities to strengthen the abstract and evaluation section, and we address each point below with proposed revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'both models perform competitively, matching or surpassing existing monolingual and multilingual models' on ExtraGLUE supplies no numerical scores, baseline details, statistical tests, or error bars, preventing verification of the central empirical claim.
Authors: We agree that the abstract would benefit from concrete numerical support. In the revised manuscript we will update the abstract to reference key results from the evaluation section, including average ExtraGLUE scores for both PortBERT variants and direct comparisons to the main baselines (BERTimbau, mBERT, XLM-R). The full per-task scores, standard deviations where available, and baseline details remain in the tables and text; the abstract change will direct readers to these results for verification. revision: yes
-
Referee: [Abstract / Evaluation] Evaluation (ExtraGLUE description): the paper states that tasks were translated but provides no evidence of translation-quality controls such as back-translation checks, human fidelity ratings, or side-by-side comparison against native Portuguese benchmarks; without this, translation artifacts remain a plausible confound that could invalidate ExtraGLUE as a faithful proxy for Portuguese understanding.
Authors: This observation is correct: the manuscript describes ExtraGLUE as translated tasks but supplies no additional quality-control evidence. We will revise the evaluation section to describe the translation pipeline used, explicitly note the absence of back-translation or human fidelity checks as a limitation, and discuss how this setup aligns with prior Portuguese NLP work that relies on the same translated benchmarks. These additions will improve transparency without altering the reported experimental results. revision: yes
Circularity Check
No derivation chain present; empirical model training and benchmark evaluation
full rationale
The paper describes training RoBERTa-based models on Portuguese corpora and evaluating them on translated GLUE/SuperGLUE tasks (ExtraGLUE). No equations, derivations, fitted parameters, or predictions are claimed. All performance statements rest on direct external benchmark comparisons rather than any internal reduction or self-referential construction. No self-citation load-bearing steps or ansatz smuggling occur. The contribution is a standard empirical release and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
HuggingFace's Transformers: State-of-the-art Natural Language Processing , journal =
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and R. HuggingFace's Transformers: State-of-the-art Natural Language Processing , journal =. 2019 , url =
2019
-
[3]
Proceedings of the KONVENS GermEval Shared Task on Named Entity Recognition , pages=
Benikova, Darina and Biemann, Chris and Kisselew, Max and Padó, Sebastian , year =. Proceedings of the KONVENS GermEval Shared Task on Named Entity Recognition , pages=
-
[4]
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Rémi and Funtowicz, Morgan and Brew, Jamie , month = oct, year =
-
[5]
arXiv:1904.03323 [cs] , author =
Publicly. arXiv:1904.03323 [cs] , author =. 2019 , note =
Pith/arXiv arXiv 1904
-
[6]
arXiv:1402.3722 [cs, stat] , author =
word2vec. arXiv:1402.3722 [cs, stat] , author =. 2014 , note =
Pith/arXiv arXiv 2014
-
[7]
arXiv:1301.3781 [cs] , author =
Efficient. arXiv:1301.3781 [cs] , author =. 2013 , note =
Pith/arXiv arXiv 2013
-
[8]
arXiv:1508.07709 [cs, stat] , author =
Word. arXiv:1508.07709 [cs, stat] , author =. 2016 , note =
Pith/arXiv arXiv 2016
- [9]
-
[10]
Medium , author =
Meet. Medium , author =. 2019 , file =
2019
- [11]
- [12]
- [13]
- [14]
-
[15]
arXiv:2001.04451 [cs, stat] , author =
Reformer:. arXiv:2001.04451 [cs, stat] , author =. 2020 , note =
Pith/arXiv arXiv 2001
- [16]
- [17]
-
[18]
Wu, Shijie and Dredze, Mark , month = nov, year =. Beto,. Proceedings of the 2019. doi:10.18653/v1/D19-1077 , abstract =
- [19]
- [20]
-
[21]
arXiv:1611.01734 [cs] , author =
Deep. arXiv:1611.01734 [cs] , author =. 2017 , note =
Pith/arXiv arXiv 2017
-
[22]
arXiv:1901.07291 [cs] , author =
Cross-lingual. arXiv:1901.07291 [cs] , author =. 2019 , note =
Pith/arXiv arXiv 1901
-
[23]
arXiv:1804.10959 [cs] , author =
Subword. arXiv:1804.10959 [cs] , author =. 2018 , note =
Pith/arXiv arXiv 2018
-
[24]
Kudo, Taku and Richardson, John , month = nov, year =. Proceedings of the 2018. doi:10.18653/v1/D18-2012 , abstract =
work page internal anchor Pith review doi:10.18653/v1/d18-2012 2018
-
[25]
arXiv:1904.00962 [cs, stat] , author =
Large. arXiv:1904.00962 [cs, stat] , author =. 2020 , note =
Pith/arXiv arXiv 1904
- [26]
- [27]
- [28]
-
[29]
OpenAI Blog , author =
Language models are unsupervised multitask learners , volume =. OpenAI Blog , author =. 2019 , pages =
2019
-
[30]
attardi/wikiextractor , url =
Attardi, Giuseppe , month = may, year =. attardi/wikiextractor , url =
-
[31]
2020 , note =
musixmatchresearch/umberto , copyright =. 2020 , note =
2020
-
[32]
deepset -
Chan, Branden and Möller, Timo and Pietsch, Malte and Soni, Tanay and Yeung, Chin Man , note =. deepset -
-
[33]
2020 , note =
deepset-ai/. 2020 , note =
2020
-
[34]
and Trenkle, John M
Cavnar, William B. and Trenkle, John M. , year =. N-. In
-
[35]
Qualität der
Hammwöhner, Rainer and Fuchs, Karl-Peter and Kattenbeck, Markus and Sax, Christian , editor =. Qualität der. Open. 2007 , pages =
2007
-
[36]
kommunikation @ gesellschaft , author =
Qualitätsaspekte der. kommunikation @ gesellschaft , author =. 2007 , keywords =
2007
-
[37]
arXiv:1806.03822 [cs] , author =
Know. arXiv:1806.03822 [cs] , author =. 2018 , note =
Pith/arXiv arXiv 2018
-
[38]
Tjong Kim Sang, Erik F. and De Meulder, Fien , year =. Introduction to the. doi:10.3115/1119176.1119195 , booktitle =
-
[39]
Risch, Julian and Krebs, Eva and Löser, Alexander and Riese, Alexander and Krestel, Ralf , month = sep, year =. Fine-. Proceedings of
-
[40]
2020 , note =
Medium , author =. 2020 , note =
2020
-
[41]
Unsupervised Cross-lingual Representation Learning at Scale , journal =
Alexis Conneau and Kartikay Khandelwal and Naman Goyal and Vishrav Chaudhary and Guillaume Wenzek and Francisco Guzm. Unsupervised Cross-lingual Representation Learning at Scale , journal =. 2019 , url =
2019
-
[42]
Cross-lingual Language Model Pretraining , url =
Conneau, Alexis and Lample, Guillaume , booktitle =. Cross-lingual Language Model Pretraining , url =
-
[43]
arXiv:1912.07076 [cs] , author =
Multilingual is not enough:. arXiv:1912.07076 [cs] , author =. 2019 , note =
arXiv 1912
-
[44]
Introduction to
Potapov, Sergey , month = jul, year =. Introduction to
-
[45]
arXiv:1904.01038 [cs] , author =
fairseq:. arXiv:1904.01038 [cs] , author =. 2019 , note =
Pith/arXiv arXiv 1904
-
[46]
Språktidningen , author =
Små bokstäver ökade avståndet till tyskarna , url =. Språktidningen , author =. 2009 , note =
2009
-
[47]
Crystal, David and Crystal, Honorary Professor of Linguistics David , month = aug, year =. The
-
[48]
arXiv:1806.00187 [cs] , author =
Scaling. arXiv:1806.00187 [cs] , author =. 2018 , note =
Pith/arXiv arXiv 2018
-
[49]
arXiv:1901.08256 [cs, stat] , author =
Large-. arXiv:1901.08256 [cs, stat] , author =. 2019 , note =
Pith/arXiv arXiv 1901
-
[50]
Lexical and orthographic distances between
Gooskens, Charlotte and Bezooijen, Renée van , year =. Lexical and orthographic distances between. doi:10.3726/978-3-653-03517-9/8 , abstract =
-
[51]
arXiv:2005.14165 [cs] , author =
Language. arXiv:2005.14165 [cs] , author =. 2020 , note =
Pith/arXiv arXiv 2005
- [52]
-
[53]
Wikipedia , month = nov, year =
Deutsche. Wikipedia , month = nov, year =
-
[54]
Wikipedia , month = oct, year =
Wikipedia:. Wikipedia , month = oct, year =
-
[55]
Emigh, W. and Herring, S.C. , month = jan, year =. Collaborative. Proceedings of the 38th. doi:10.1109/HICSS.2005.149 , abstract =
-
[56]
Asynchronous pipelines for processing huge corpora on medium to low resource infrastructures , url =
Suárez, Pedro Javier Ortiz and Sagot, Benoît and Romary, Laurent , editor =. Asynchronous pipelines for processing huge corpora on medium to low resource infrastructures , url =. 2019 , pages =. doi:10.14618/ids-pub-9021 , abstract =
-
[57]
Recent advances in natural language processing , author =
News from. Recent advances in natural language processing , author =. 2009 , pages =
2009
-
[58]
Koehn, Philipp and Hoang, Hieu and Birch, Alexandra and Callison-Burch, Chris and Federico, Marcello and Bertoldi, Nicola and Cowan, Brooke and Shen, Wade and Moran, Christine and Zens, Richard and Dyer, Chris and Bojar, Ondřej and Constantin, Alexandra and Herbst, Evan , month = jun, year =. Moses:. Proceedings of the 45th
-
[59]
Schabus, Dietmar and Skowron, Marcin and Trapp, Martin , month = aug, year =. One. doi:10.1145/3077136.3080711 , booktitle =
-
[60]
Academic-
Schabus, Dietmar and Skowron, Marcin , month = may, year =. Academic-. Proceedings of the 11th
- [61]
-
[62]
, year =
Jurafsky, Daniel and Martin, James H. , year =. Speech and
-
[63]
Information Processing and Management of Uncertainty in Knowledge-Based Systems , author =
Automatic. Information Processing and Management of Uncertainty in Knowledge-Based Systems , author =. 2020 , pmid =. doi:10.1007/978-3-030-50146-4_52 , abstract =
-
[64]
Proceedings of the 58th
Martin, Louis and Muller, Benjamin and Ortiz Suárez, Pedro Javier and Dupont, Yoann and Romary, Laurent and de la Clergerie, \'. Proceedings of the 58th. 2020 , pages =
2020
-
[65]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , month = jun, year =. Proceedings of the 2019. doi:10.18653/v1/N19-1423 , abstract =
-
[66]
Attention is
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, Łukasz and Polosukhin, Illia , editor =. Attention is. Advances in. 2017 , pages =
2017
-
[67]
GloVe: Global vectors for word representation,
Pennington, Jeffrey and Socher, Richard and Manning, Christopher , month = oct, year =. Proceedings of the 2014. doi:10.3115/v1/D14-1162 , urldate =
-
[68]
Transactions of the Association for Computational Linguistics , author =
Enriching. Transactions of the Association for Computational Linguistics , author =. 2017 , pages =
2017
-
[69]
arXiv preprint arXiv:1612.03651 , author =
-
[70]
Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Mikolov, Tomas , month = apr, year =. Bag of. Proceedings of the 15th
-
[71]
Ortiz Suárez, Pedro Javier and Romary, Laurent and Sagot, Benoît , month = jul, year =. A. Proceedings of the 58th
- [72]
-
[73]
Advances in
Mikolov, Tomas and Grave, Edouard and Bojanowski, Piotr and Puhrsch, Christian and Joulin, Armand , month = may, year =. Advances in. Proceedings of the
-
[75]
Akbik, Alan and Bergmann, Tanja and Blythe, Duncan and Rasul, Kashif and Schweter, Stefan and Vollgraf, Roland , month = jun, year =. Proceedings of the 2019. doi:10.18653/v1/N19-4010 , abstract =
-
[76]
Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey , month = aug, year =. Facebook. Proceedings of the. doi:10.18653/v1/W19-5333 , abstract =
-
[77]
arXiv:1508.07909 [cs] , author =
Neural. arXiv:1508.07909 [cs] , author =. 2016 , note =
Pith/arXiv arXiv 2016
-
[78]
Schuster, Mike and Nakajima, Kaisuke , month = mar, year =. Japanese and. 2012. doi:10.1109/ICASSP.2012.6289079 , abstract =
-
[79]
GitHub , author =
Multilingual. GitHub , author =. 2018 , file =
2018
-
[80]
Dagstuhl-Seminar 99121: Unsupervised Learning , pages=
Single-class support vector machines , author=. Dagstuhl-Seminar 99121: Unsupervised Learning , pages=. 1999 , organization=
1999
-
[81]
German's Next Language Model , journal =
Branden Chan and Stefan Schweter and Timo M. German's Next Language Model , journal =. 2020 , url =. 2010.10906 , timestamp =
arXiv 2020
-
[82]
MarIA: Spanish Language Models , ISSN=
Gutiérrez-Fandiño, Asier and Armengol-Estapé, Jordi and Pàmies, Marc and Llop-Palao, Joan and Silveira-Ocampo, Joaquin and Carrino, Casimiro Pio and Armentano-Oller, Carme and Rodriguez-Penagos, Carlos and Gonzalez-Agirre, Aitor and Villegas, Marta , year=. MarIA: Spanish Language Models , ISSN=. doi:10.26342/2022-68-3 , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.