When Tabular Foundation Models Transfer Across Modalities: A Systematic Evaluation Across 95 Datasets, 7 Modalities, and Two Regimes
Pith reviewed 2026-06-28 15:29 UTC · model grok-4.3
The pith
A single pipeline with ETF preprocessing and a tabular foundation model transfers competitively across seven modalities on 95 datasets while running 4 to 200 times faster than fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
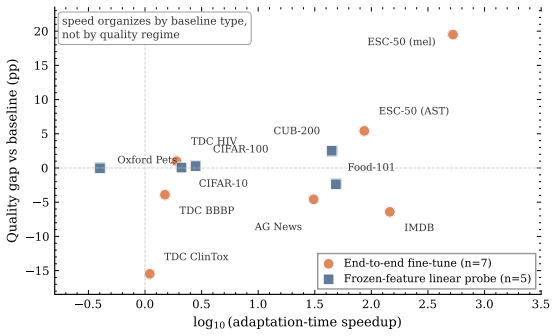
A single classification pipeline that maps any of seven signal modalities to fixed vectors, applies Equiangular Tight Frame preprocessing, and then runs a tabular foundation model for in-context inference matches the strongest lightweight tuned baselines on those same frozen features across 95 datasets while delivering inference speeds 4 to 200 times faster than full backbone fine-tuning, and produces well-calibrated probabilities after a post-hoc rescaling step.
What carries the argument
The pipeline that applies Equiangular Tight Frame (ETF) preprocessing followed by a tabular foundation model for in-context inference, applied identically once data is converted to fixed vector representations.
If this is right
- The pipeline can be deployed without a validation split by stopping ETF training at a fixed iteration count.
- Post-hoc rescaling restores calibration so that per-prediction confidence can serve as a trust threshold for gated deployment.
- The approach is not expected to help on tasks where the frozen features already carry modality-specific structure that a lightweight head cannot exploit.
- Specialized fine-tuning or oracle model selection can still outperform the pipeline on individual tasks, but at much higher compute cost.
Where Pith is reading between the lines
- If stronger frozen feature extractors become available, the same pipeline could close more of the gap to heavily tuned specialized models without changing its core structure.
- The speed advantage makes the pipeline attractive for rapid prototyping across new modalities before committing to full fine-tuning.
- Calibration that survives preprocessing suggests the in-context classifier itself supplies a stable probability geometry that practitioners can trust for downstream decision rules.
Load-bearing premise
Converting every modality to fixed vector representations creates a fair and representative input space, and performance against the strongest lightweight tuned baseline on those same frozen features is the right yardstick for measuring transfer benefit.
What would settle it
A new modality or dataset collection where the pipeline falls substantially below the strongest lightweight tuned baseline on the identical frozen features would falsify the transfer claim.
Figures

read the original abstract
We present a single classification pipeline that combines an Equiangular Tight Frame (ETF) preprocessing stage with a tabular foundation model for in-context inference, applied identically across modalities once data is mapped to fixed vector representations. We evaluate it on 95 datasets spanning seven signal modalities -- vision, audio, speech, text, molecular, time-series, and tabular. The main methodological contribution is to fix the comparison object: throughout the paper, performance is judged against the strongest lightweight tuned baseline on the same frozen features, while oracle selection, deployed selection, and specialized fine-tuning are reported separately. The pipeline is broadly competitive with strong lightweight tuned baselines on the same frozen features. It does not match the very best specialized models or heavily tuned pipelines on every task, but it stays close, and it runs much faster -- typically 4 to 200 times faster than full backbone fine-tuning, often at comparable quality. We describe how to deploy the pipeline in practice: when to apply ETF preprocessing, how to stop its training without a validation split, how to set up the in-context classifier, and how to calibrate the resulting probabilities. The calibration step is non-cosmetic: TabICL produces well-calibrated probabilities by construction, ETF preprocessing initially disrupts that calibration, and the post-hoc rescaling restores it -- yielding a per-prediction confidence signal that practitioners can use as a trust threshold for confidence-gated deployment. We also report where the pipeline should not be expected to help, and how to identify those cases in advance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a single classification pipeline that applies Equiangular Tight Frame (ETF) preprocessing followed by a tabular foundation model for in-context inference. The pipeline is evaluated identically on 95 datasets spanning seven modalities (vision, audio, speech, text, molecular, time-series, tabular) once data has been mapped to fixed vector representations by modality-specific backbones. The central claim is that the pipeline is broadly competitive with the strongest lightweight tuned baselines on those same frozen features, while being substantially faster (typically 4-200x) than full backbone fine-tuning, and the work supplies practical deployment guidance including when to use ETF, training stopping rules without a validation split, in-context classifier setup, and post-hoc calibration to restore well-calibrated probabilities.
Significance. If the empirical results hold with appropriate controls, the work offers a concrete, reproducible demonstration that tabular foundation models can serve as a fast, competitive drop-in component for multi-modal classification tasks under a frozen-feature regime. The explicit methodological choice to benchmark exclusively against lightweight tuned baselines on identical embeddings, while reporting specialized fine-tuning separately, clarifies the scope and reduces ambiguity in the comparison. The calibration analysis, which shows that ETF disrupts but post-hoc rescaling restores calibration, supplies a usable per-prediction confidence signal for practitioners.
major comments (2)
- [Abstract and §1] Abstract and §1: The title frames the contribution as tabular foundation models transferring 'across modalities,' yet the experimental design maps each modality through its own specialized backbone before the tabular model ever sees the data. All reported competitiveness is therefore measured inside a shared frozen vector space rather than testing whether the tabular model itself performs cross-modal generalization. This narrows the claim relative to the title; the manuscript should explicitly state that the transfer benefit is demonstrated only after modality-specific vectorization.
- [Results] Results (tables reporting per-modality or aggregate accuracy): The abstract asserts 'broad competitiveness' and 'often at comparable quality,' but the provided summary contains no quantitative numbers, error bars, dataset breakdowns, or baseline-tuning protocols. If the full manuscript tables do not include these (e.g., per-modality win rates, statistical tests against the strongest lightweight baseline, and details on hyperparameter search budgets), the central empirical claim cannot be verified at the required standard.
minor comments (2)
- [Deployment guidance] Deployment guidance section: The description of stopping ETF training without a validation split would be clearer with an explicit algorithm box or numbered steps rather than prose alone.
- Notation: Ensure consistent use of 'TabICL' versus 'tabular foundation model' throughout; the two appear interchangeable in the abstract but should be defined once.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The title frames the contribution as tabular foundation models transferring 'across modalities,' yet the experimental design maps each modality through its own specialized backbone before the tabular model ever sees the data. All reported competitiveness is therefore measured inside a shared frozen vector space rather than testing whether the tabular model itself performs cross-modal generalization. This narrows the claim relative to the title; the manuscript should explicitly state that the transfer benefit is demonstrated only after modality-specific vectorization.
Authors: We agree that the experimental design applies modality-specific backbones to produce fixed vector representations before the tabular foundation model is applied, so the demonstrated transfer occurs within that shared frozen feature space rather than testing direct cross-modal generalization by the tabular model itself. To remove any potential ambiguity between the title and the actual scope, we will revise the abstract and §1 to explicitly state that the transfer benefit is shown only after modality-specific vectorization. revision: yes
-
Referee: [Results] Results (tables reporting per-modality or aggregate accuracy): The abstract asserts 'broad competitiveness' and 'often at comparable quality,' but the provided summary contains no quantitative numbers, error bars, dataset breakdowns, or baseline-tuning protocols. If the full manuscript tables do not include these (e.g., per-modality win rates, statistical tests against the strongest lightweight baseline, and details on hyperparameter search budgets), the central empirical claim cannot be verified at the required standard.
Authors: The full manuscript (Section 4 and Appendix) contains the requested quantitative details: per-modality and aggregate accuracy tables with standard deviations, win rates against the strongest lightweight tuned baselines on identical frozen features, dataset-level breakdowns, and explicit descriptions of the hyperparameter search budgets and evaluation protocols. The abstract summarizes the high-level findings without numbers solely for space reasons; all supporting statistics and protocols are provided in the main results and supplementary sections. revision: no
Circularity Check
No circularity: pure empirical evaluation with no derivations
full rationale
The paper is a systematic empirical study comparing a fixed pipeline (ETF + tabular ICL) against baselines on frozen features across 95 datasets. No equations, derivations, or self-referential definitions appear in the provided text. Performance claims are direct experimental outcomes, not quantities fitted to the same data and then relabeled as predictions. The explicit methodological choice to judge only against lightweight tuned baselines on identical features is stated as such and does not reduce to a tautology. Self-citations, if present, are not load-bearing for any claimed result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2010.09885 , year=
S. Chithrananda, G. Grand, and B. Ramsundar. Chemberta: Large-scale self-supervised pretraining for molecular property prediction.arXiv preprint arXiv:2010.09885,
- [2]
-
[3]
K. K. Ben Hicham, J. G. Rittig, M. Grohe, and A. Mitsos. Tabular foundation models for in-context prediction of molecular properties.arXiv preprint arXiv:2604.16123,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
W. Kim, C. Song, and H. Kim. MultiModalPFN: Extending prior-data fitted networks for multimodal tabular learning.arXiv preprint arXiv:2602.20223,
work page internal anchor Pith review Pith/arXiv arXiv
- [5]
-
[6]
Morris et al
C. Morris et al. Tudataset: A collection of benchmark datasets for learning with graphs. InICML 2020 Workshop on Graph Representation Learning,
2020
- [7]
-
[8]
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv preprint arXiv:2602.11139,
-
[9]
rescue” regime.An earlier version of the analysis used a non-tuned linear-probe baseline and identified a three-regime structure with a “rescue
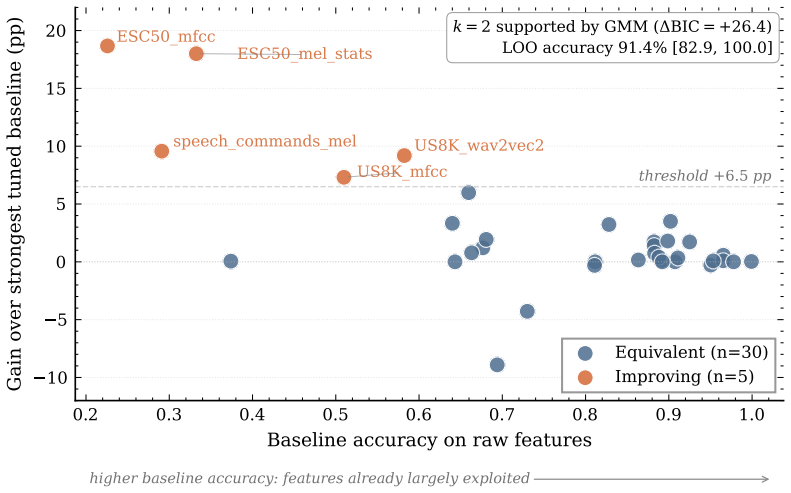
12 A Detailed regime characterization This appendix gives the per-dataset breakdown of the two regimes identified in Section 4.2 and documents how the earlier “rescue” regime collapsed under baseline correction. The five improving cases.Table 4 lists the Panel A datasets in the improving regime ( n= 5 , mean gain +12.6pp). Three of the five are low-dimens...
2017
-
[10]
Panel B (held-out tabular).60 datasets selected as a feature-dimensionality-stratified subset of TabArena [Erickson et al., 2025]
Panel A datasets.Table 6 lists all 35 Panel A datasets with their source, feature extractor, dimen- sionality, and baseline. Panel B (held-out tabular).60 datasets selected as a feature-dimensionality-stratified subset of TabArena [Erickson et al., 2025]. One dataset ( tabarena_Click_prediction) is missing a complete baseline, so n= 59 enters the win-rate...
2025
-
[11]
x-axis: gain on raw features
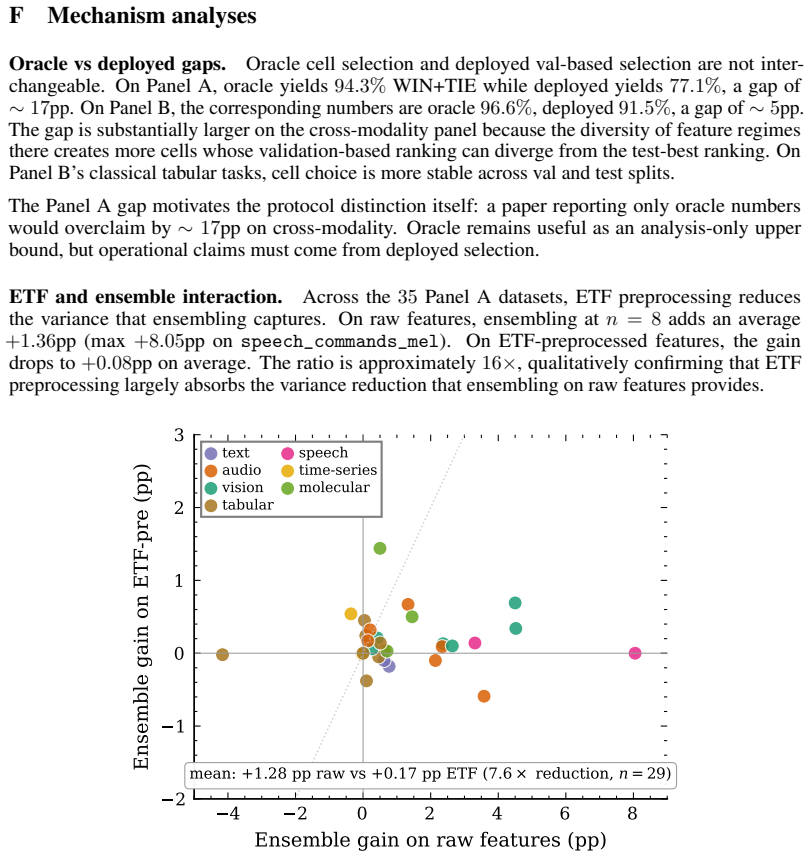
text audio vision tabular speech time-series molecular Figure 7: Per-dataset ensemble gain scatter. x-axis: gain on raw features. y-axis: gain on ETF- preprocessed features. Points cluster low along the y-axis, consistent with ETF reducing the variance ensembling captures. Calibration.ETF preprocessing improves separability but produces overconfident logi...
2017
-
[12]
The unfiltered overall accuracy on this pool is86.0%. The trade-off is dataset-dependent: per-modality at τ= 0.9 , vision foundation reaches 96.7% conditional accuracy at 85.3% coverage, audio foundation reaches 97.2% at 76.4% coverage, and text foundation reaches 87.9% at 68.9% coverage. Text foundation has the largest post-rescaling ECE (0.081) and the ...
-
[13]
−ETF” column equals “Full
The LR-raw floor ( 51.4%) places the full pipeline at +25.7pp above the trivial baseline. †Temperature scaling does not change argmax predictions; the 0pp verdict effect is expected, the calibration effect is reported separately (ECE drops from0.093to0.032). ModalitynFull−ETF−ens. ETF+LR LR raw Audio classical 4100% 100% 100% 100% 25% Audio foundation 367...
2020
-
[14]
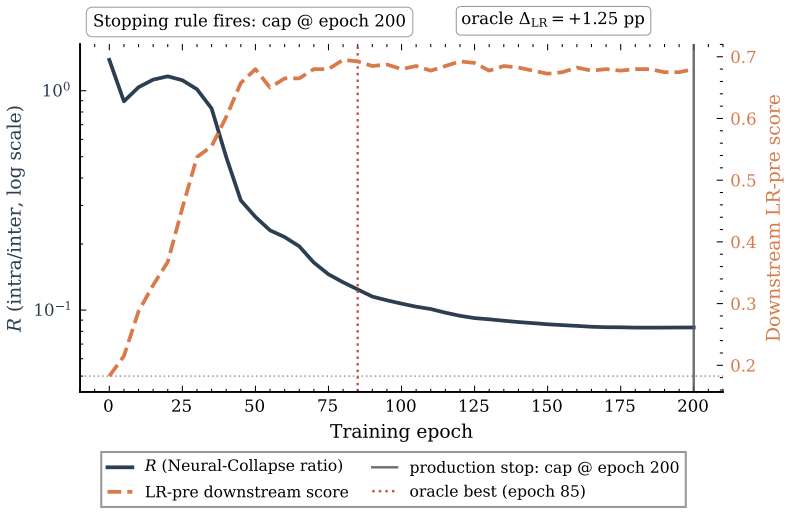
and the cap fires on the other five; overfit_patience is implemented as a guard but does not activate on any audited trajectory. The audit yields downstream checkpoints that exceed the cap-epoch checkpoint by an average of+0.38pp for LR-pre and +0.43pp for TabICL-pre on the three foundation datasets where the rule activates pre-cap (median displacement fr...
2025
-
[15]
reformulated graph node classification as a tabular problem, showing that TabPFNv2 can outperform GNN baselines via flattened structural features. The MultiModalPFN line [Kim et al., 2026], contemporaneous with our work and accepted at CVPR 2026, extends TabPFN topairedmultimodal inputs (tabular plus image, or tabular plus text) on a curated set of 9 data...
2026
-
[16]
The differences with our work are substantive
also observe that with image-only input projected to tabular tokens, MMPFN reaches accuracy within∼1 pp of a tuned DINOv2 linear probe on a single dataset (PU20) – corroborating, on a single encoder, the broader claim we substantiate at scale here. The differences with our work are substantive. Each prior effort restricts itself to a single non-tabular mo...
2026
-
[17]
(TabArena) is a recent effort to provide a living, cross-validated benchmark for tabular methods with a transparent evaluation pipeline; we use a feature-dimension-stratified subset of TabArena as our held-out Panel B precisely because it provides a controlled tabular reference distribution outside the cross-modality discovery panel. Neural collapse, pre-...
2020
-
[18]
preventing within-class variability collapse to a certain extent during pre-training leads to better transferability,
reported that “preventing within-class variability collapse to a certain extent during pre-training leads to better transferability,” establishing empirically the value ofpre-collapse representations – but in the pre-training regime, with the collapse modulation built into the source- model training objective. They use this insight to design parameter-eff...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.