BADGER: Bridging Agentic and Deterministic Evaluation for Generative Enterprise Reasoning
Pith reviewed 2026-06-28 14:08 UTC · model grok-4.3
The pith
BADGER unifies text-to-SQL and agentic evaluation for enterprise AI via a hybrid metric that reaches substantial human agreement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
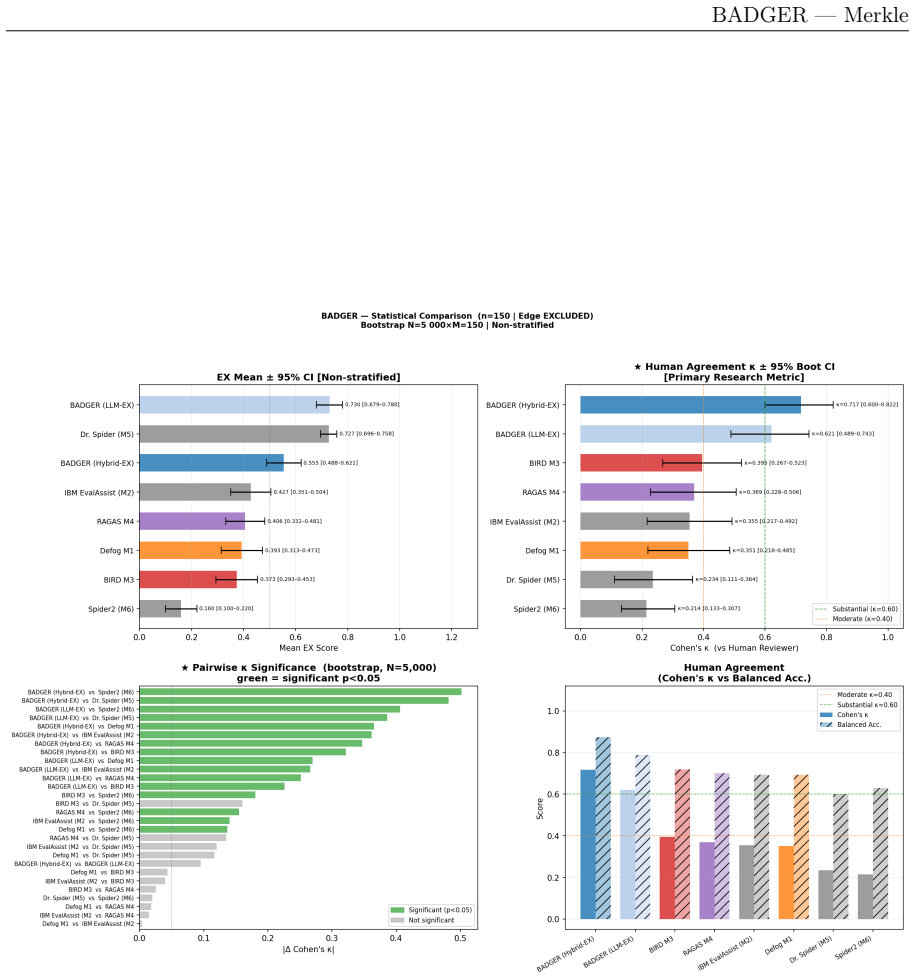
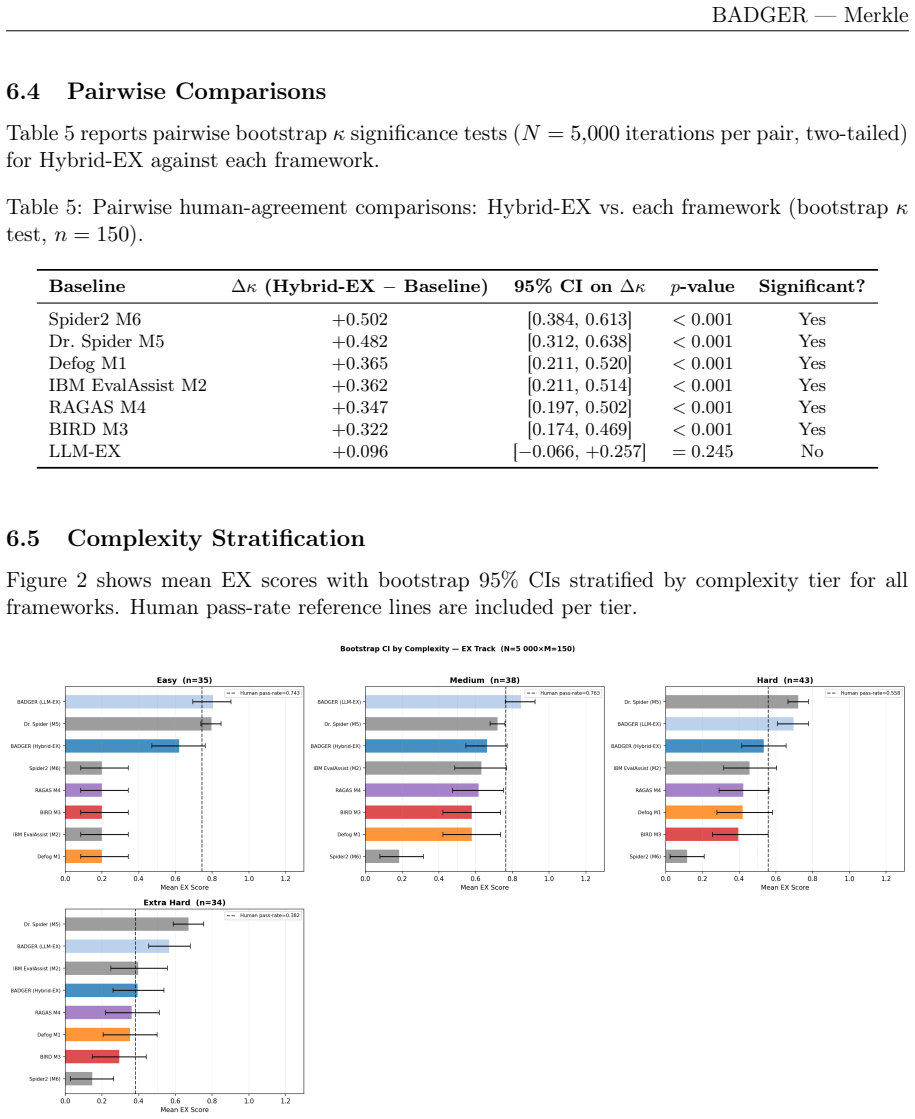
BADGER integrates text-to-SQL assessment with agentic behavior evaluation through three elements: LLM-assisted extraction that extends Spider methodology to CTE-heavy and dialect-specific queries, the Hybrid-EX metric that uses an LLM to infer structural alignments before deterministic cell-level scoring to address aliasing and tolerance brittleness, and a unified agentic suite that incorporates RAGAS, G-Eval and related metrics along with the novel Excess Tool Usage measure. On 150 human-annotated industry queries, Hybrid-EX attains Cohen's kappa of 0.717 with 95 percent CI 0.600-0.822 and 87.3 percent balanced accuracy, exceeding competing frameworks by delta-kappa values of 0.322 to 0.502
What carries the argument
Hybrid-EX, a hybrid execution accuracy metric that employs an LLM to infer structural alignments before deterministic cell-level scoring.
If this is right
- A single pipeline can evaluate both deterministic SQL correctness and multi-step agentic behavior in enterprise settings.
- Evaluation runs entirely inside the client's governed data environment without external data movement.
- Configurable LLM judge backends enable client-specific metric and judge prototyping.
- The system supports ongoing continuous evaluation rather than one-time quality gates.
Where Pith is reading between the lines
- Hybrid alignment-plus-deterministic scoring may generalize to other structured generation tasks such as API orchestration or report generation.
- Enterprises in regulated sectors could adopt the framework as a compliance-friendly evaluation layer.
- Re-running the validation on larger or temporally shifted query sets would test stability of the reported agreement levels.
Load-bearing premise
The 150 human-annotated industry queries form a representative sample of enterprise text-to-SQL and agentic tasks.
What would settle it
A new collection of 150 enterprise queries drawn from a different domain where Hybrid-EX agreement with human annotators falls below Cohen's kappa of 0.6.
Figures
read the original abstract
Enterprise AI systems that translate natural language into SQL queries and orchestrate multi-step agentic reasoning pipelines require evaluation approaches fundamentally different from academic benchmarks. Spider and BIRD established execution-accuracy protocols; G-Eval and RAGAS advanced LLM-based assessment; and recent work such as Spider 2.0, BEAVER, and BIRD-Interact has begun to address enterprise and agentic dimensions. No single framework unifies text-to-SQL assessment with agentic behavior evaluation into a production-grade pipeline calibrated against human expert judgment. We present BADGER, developed at Merkle, a unified evaluation framework integrating text-to-SQL assessment with agentic behavior evaluation. BADGER offers three contributions. First, LLM-assisted SQL component extraction extending Spider methodology to handle CTE-heavy, dialect-specific SQL. Second, a hybrid execution accuracy metric (Hybrid-EX) resolving column-aliasing and numeric-tolerance brittleness by using an LLM to infer structural alignments before deterministic cell-level scoring. Validated on 150 human-annotated industry queries, Hybrid-EX achieves Cohen's kappa=0.717 [95% CI: 0.600-0.822] (Substantial agreement) and 87.3% balanced accuracy, outperforming all six competing frameworks (Delta-kappa: 0.322-0.502, all p<=0.001). Third, an enterprise agentic evaluation suite assembling RAGAS, G-Eval, and agent benchmark metrics into a unified pipeline; Excess Tool Usage is the sole novel element. BADGER runs entirely within the client's governed data environment, supports configurable LLM judge backends, and enables rapid prototyping of client-specific judges and metrics, serving as a continuous evaluation backbone rather than a one-time quality gate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents BADGER, a unified evaluation framework for enterprise text-to-SQL and agentic reasoning systems. It contributes LLM-assisted SQL component extraction for CTE-heavy and dialect-specific queries, a hybrid execution accuracy metric (Hybrid-EX) that combines LLM structural alignment with deterministic cell-level scoring, and an integrated agentic evaluation suite drawing on RAGAS, G-Eval, and related metrics. The central empirical claim is that Hybrid-EX achieves Cohen's kappa=0.717 [95% CI: 0.600-0.822] and 87.3% balanced accuracy on 150 human-annotated industry queries, outperforming six baselines with delta-kappa 0.322-0.502 (all p<=0.001).
Significance. If the validation holds under representative sampling, BADGER would address a genuine gap by providing a production-calibrated bridge between deterministic execution metrics and agentic evaluation, with the hybrid LLM-deterministic design offering a concrete improvement over pure LLM judges or brittle execution accuracy. The explicit human-annotation grounding and statistical comparisons are strengths that could support adoption in governed enterprise environments.
major comments (2)
- [Abstract] Abstract (validation paragraph): the reported kappa=0.717 and balanced accuracy on 150 queries are presented without any sampling protocol, stratification by features such as CTE usage or dialect specificity, inter-annotator agreement, or comparison to production query logs. This directly affects the generalizability claim for enterprise workloads and must be addressed with explicit methodology before the performance deltas can be treated as load-bearing evidence.
- [Abstract] Abstract (validation paragraph): no data exclusion rules, error analysis, or breakdown by query type are supplied, leaving open the possibility that the observed outperformance is sample-specific rather than a property of Hybrid-EX. The central claim that the metric is production-grade therefore rests on an unverified representativeness assumption.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the validation claims. We agree that the abstract and manuscript require expanded methodological transparency to support the generalizability assertions, and we will make the requested revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (validation paragraph): the reported kappa=0.717 and balanced accuracy on 150 queries are presented without any sampling protocol, stratification by features such as CTE usage or dialect specificity, inter-annotator agreement, or comparison to production query logs. This directly affects the generalizability claim for enterprise workloads and must be addressed with explicit methodology before the performance deltas can be treated as load-bearing evidence.
Authors: We agree these details are currently insufficient. In revision we will add a dedicated 'Data Collection and Annotation' subsection in Methods that specifies: the sampling frame drawn from Merkle production query logs, explicit stratification criteria (CTE usage, dialect, query complexity), the annotation protocol (including whether multiple annotators were used and any inter-annotator agreement statistics), and a direct comparison of the 150-query sample statistics against the broader production log distribution. The abstract will be updated to reference this new section. revision: yes
-
Referee: [Abstract] Abstract (validation paragraph): no data exclusion rules, error analysis, or breakdown by query type are supplied, leaving open the possibility that the observed outperformance is sample-specific rather than a property of Hybrid-EX. The central claim that the metric is production-grade therefore rests on an unverified representativeness assumption.
Authors: We accept this critique. The revised manuscript will include: (i) explicit data exclusion rules applied when curating the 150 queries, (ii) a full error analysis table showing disagreement cases between Hybrid-EX and human labels with qualitative categorization, and (iii) performance breakdowns stratified by query type (CTE-heavy, dialect-specific, multi-table, etc.). These additions will be summarized in the abstract and discussed in a new Limitations paragraph addressing representativeness. revision: yes
Circularity Check
No significant circularity; empirical validation is independent of inputs
full rationale
The paper's central claim is an empirical result: Hybrid-EX achieves Cohen's kappa=0.717 and 87.3% balanced accuracy on 150 human-annotated industry queries, outperforming baselines. This is framed as comparison against external human annotations with no equations, derivations, fitted parameters renamed as predictions, or self-citation chains that reduce the reported metrics to quantities derived from the same data by construction. The validation protocol supplies independent grounding via human judgment, consistent with the default expectation for non-circular empirical papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
BIRD-Interact: Comprehensive interactive evaluation for text-to-SQL mod- els
BIRD-Bench Team. BIRD-Interact: Comprehensive interactive evaluation for text-to-SQL mod- els. InInternational Conference on Learning Representations (ICLR 2026),
2026
-
[3]
URLhttps://arxiv.org/abs/2409.02038. Jacob Cohen. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46,
-
[4]
doi: 10.1609/aaai.v39i28.35351. URLhttps://ojs.aaai.org/index. php/AAAI/article/view/35351. Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. Chapman & Hall,
-
[5]
RAGAS: Automated evaluation of retrieval augmented generation.arXiv preprint arXiv:2309.15217,
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. RAGAS: Automated evaluation of retrieval augmented generation.arXiv preprint arXiv:2309.15217,
-
[6]
NL2SQL is a solved problem
Avrilia Floratou et al. NL2SQL is a solved problem... not! InConference on Innovative Data Systems Research (CIDR 2024),
2024
-
[7]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou
URLhttps://www.cidrdb.org/cidr2024/. Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. Text-to-SQL empowered by large language models: A benchmark evaluation.arXiv preprint arXiv:2308.15363,
-
[8]
FLEX: Expert-level false-less EXecution metric for reliable text-to-SQL benchmark
Heegyu Kim, Taeyang Jeon, Seunghwan Choi, Seungtaek Choi, and Hyunsouk Cho. FLEX: Expert-level false-less EXecution metric for reliable text-to-SQL benchmark. InProceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics,
2025
-
[10]
URLhttps://arxiv.org/ abs/2305.16265. J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data.Biometrics, 33(1):159–174,
-
[11]
KaggleDBQA: Realistic evaluation of text-to-SQL parsers
Chia-Hsuan Lee et al. KaggleDBQA: Realistic evaluation of text-to-SQL parsers. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021,
2021
-
[12]
Spider 2.0: Evaluating language models on real-world enterprise text-to-SQL workflows
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongshen Su, Zhangyin Suo, Hongbin Gao, Wenhao Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Rui Sun, Qian Liu, Sida Wang, and Tao Yu. Spider 2.0: Evaluating language models on real-world enterprise text-to-SQL workflows. InInternational Conference on Learning Representations (ICLR 2025),
2025
-
[13]
URLhttps://arxiv.org/abs/2411.07763. Oral. 27 BADGER — Merkle Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. The dawn of natural language to SQL: Are we fully ready?Proceedings of the VLDB Endowment, 17(11):3318– 3331, 2024a. Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xu...
arXiv 2023
-
[14]
NoahShinn, FedericoCassano, AshwinGopinath, KarthikNarasimhan, andShunyuYao
URLhttps://arxiv.org/abs/2304.11015. NoahShinn, FedericoCassano, AshwinGopinath, KarthikNarasimhan, andShunyuYao. Reflex- ion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36,
-
[15]
Weixu Sun, Jian Lu, and Xiaojun Jiang. MT-Teql: Evaluating and augmenting consistency of text-to-SQL models with metamorphic testing.arXiv preprint arXiv:2012.11163,
arXiv 2012
-
[16]
URLhttps://arxiv.org/abs/2307.10928. 28 BADGER — Merkle Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-SQL task. InProceedings of the 2018 Conferen...
arXiv 2018
-
[17]
URLhttps://arxiv.org/abs/1809.08887. Tao Yu, Rui Zhang, Heyang Er, Siyu Li, Eric Xue, Bo Pang, Xi Victoria Lin, Yi Chern Tan, Tianze Shi, Zihan Li, et al. CoSQL: A conversational text-to-SQL challenge towards cross- domain natural language interfaces to databases. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EM...
Pith/arXiv arXiv 2019
-
[18]
Semantic evaluation for text-to-SQL with distilled test suites
Ruiqi Zhong, Tao Yu, and Dan Klein. Semantic evaluation for text-to-SQL with distilled test suites. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2020
-
[19]
Victor Zhong, Caiming Xiong, and Richard Socher
URLhttps://arxiv.org/abs/2010.02840. Victor Zhong, Caiming Xiong, and Richard Socher. Seq2SQL: Generating structured queries from natural language using reinforcement learning.arXiv preprint arXiv:1709.00103,
arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.