ProbRes: Volatility Learning for Probabilistic Time-Series Forecasting
Pith reviewed 2026-06-28 12:43 UTC · model grok-4.3
The pith
ProbRes learns conditional volatility separately from the mean to produce calibrated predictive distributions for heteroskedastic time series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ProbRes is a post-hoc probabilistic calibration method that employs two architecture-agnostic modules to separately model the conditional mean and conditional volatility during training. At inference it generates predictive distributions by resampling normalized residuals. The method applies to both univariate and multivariate time series and remains robust under a wide range of error distributions, including non-Gaussian innovations with conditional heteroskedasticity. Theoretical results demonstrate ProbRes's validity and experiments on both synthetic and real-world datasets show that ProbRes accurately captures predictive distributions and produces well-calibrated prediction intervals.
What carries the argument
Two architecture-agnostic modules that separately model conditional mean and conditional volatility, followed by resampling of normalized residuals to construct predictive distributions.
If this is right
- The method can attach to any existing forecasting architecture because the modules are architecture-agnostic.
- It extends directly to both univariate and multivariate time series.
- It yields valid predictive distributions even when errors are non-Gaussian and exhibit conditional heteroskedasticity.
- It produces well-calibrated prediction intervals on both synthetic and real-world datasets.
Where Pith is reading between the lines
- The mean-volatility separation might transfer to other sequential prediction settings where variance dynamics matter, such as energy demand or traffic flow.
- Combining the resampling step with modern neural forecasters could improve uncertainty estimates in settings with long-range volatility clustering.
- In risk-sensitive domains the calibrated intervals could support more reliable downstream decisions like portfolio allocation without requiring changes to the base model.
Load-bearing premise
The assumption that separately modeling conditional mean and conditional volatility with architecture-agnostic modules, followed by resampling of normalized residuals, will produce valid predictive distributions under a wide range of error distributions including non-Gaussian innovations with conditional heteroskedasticity.
What would settle it
A dataset with strong conditional heteroskedasticity and non-Gaussian innovations where the prediction intervals produced by ProbRes fail to achieve nominal coverage rates, or a theoretical counter-example showing the resampling step does not yield valid distributions for some error process.
Figures
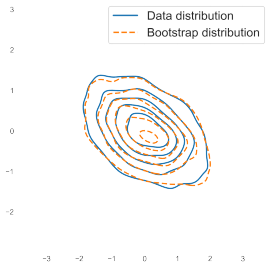
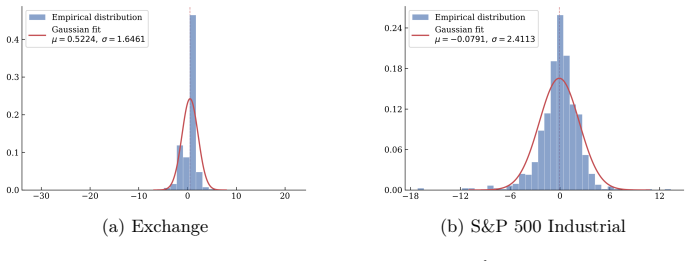
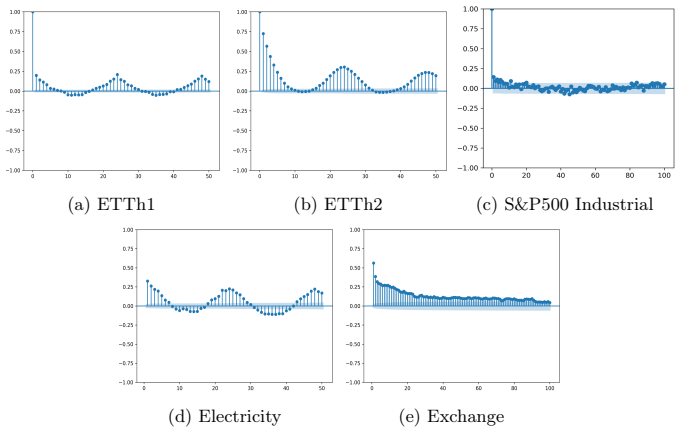
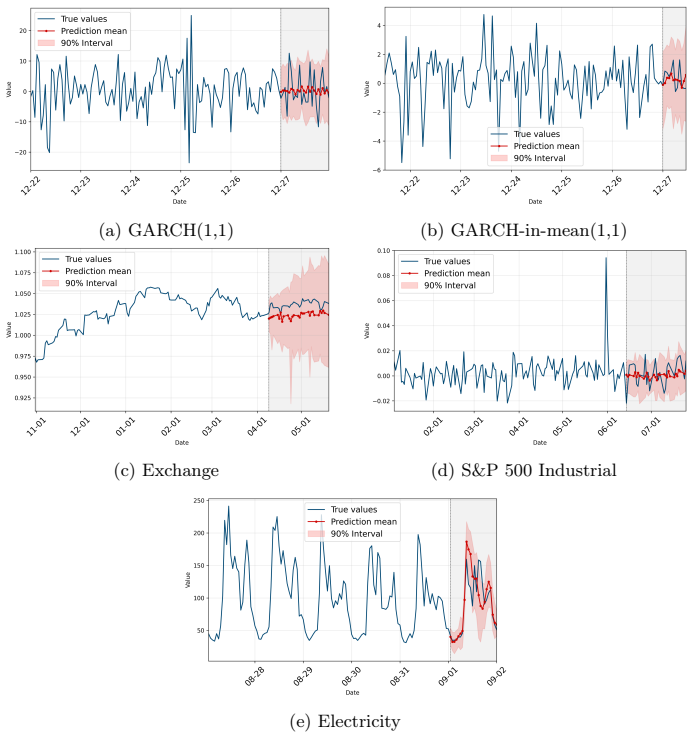
read the original abstract
Probabilistic time series forecasting has attracted increasing attention in financial applications due to the need to quantify risk and uncertainty in future observations. We propose ProbRes, a post-hoc probabilistic calibration method that explicitly learns and incorporates volatility dynamics into probabilistic forecasting, enabling effective handling of heteroskedastic data. During training, ProbRes employs two architecture-agnostic modules to separately model the conditional mean and conditional volatility. At the inference stage, it generates predictive distributions by resampling normalized residuals. ProbRes is applicable to both univariate and multivariate time series and remains robust under a wide range of error distributions, including non-Gaussian innovations with conditional heteroskedasticity. Theoretical results demonstrate ProbRes's validity and experiments on both synthetic and real-world datasets show that ProbRes accurately captures predictive distributions and produces well-calibrated prediction intervals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ProbRes, a post-hoc probabilistic calibration method for time-series forecasting. It employs two architecture-agnostic modules to separately model the conditional mean and conditional volatility during training, then generates predictive distributions at inference by resampling normalized residuals. The authors assert that this approach is theoretically valid and, via experiments on synthetic and real-world datasets, accurately captures predictive distributions while producing well-calibrated intervals even for non-Gaussian innovations with conditional heteroskedasticity; the method is claimed to apply to both univariate and multivariate series.
Significance. If the central claim holds, ProbRes would supply a flexible, model-agnostic route to incorporating volatility dynamics into existing forecasters, which is practically relevant for risk quantification in financial time series. The separation of mean and volatility modules plus residual resampling is a clean design choice that could avoid joint optimization difficulties, provided the resampling step is justified.
major comments (2)
- [Abstract] Abstract: The statement that 'theoretical results demonstrate ProbRes's validity' is not accompanied by any regularity conditions on the volatility estimator (or on the base forecaster) that would ensure the normalized residuals are approximately exchangeable. Without such conditions the resampling procedure cannot be guaranteed to recover the correct conditional law for non-Gaussian, conditionally heteroskedastic errors; this assumption is load-bearing for the central claim of robustness across error distributions.
- [Abstract (and implied theoretical section)] The manuscript provides no argument or rate result showing that the architecture-agnostic volatility module produces a consistent estimator at a rate sufficient for the normalized residuals to converge in distribution. Any misspecification in the volatility module therefore propagates directly into invalid predictive intervals, undermining the claim that the method remains valid under a wide range of error distributions.
minor comments (1)
- [Abstract] The abstract states applicability to multivariate series but supplies no indication of how the resampling step is extended when residuals are vector-valued.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need for explicit regularity conditions and consistency arguments to support the central theoretical claims. We agree that these elements are currently insufficient in the manuscript and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that 'theoretical results demonstrate ProbRes's validity' is not accompanied by any regularity conditions on the volatility estimator (or on the base forecaster) that would ensure the normalized residuals are approximately exchangeable. Without such conditions the resampling procedure cannot be guaranteed to recover the correct conditional law for non-Gaussian, conditionally heteroskedastic errors; this assumption is load-bearing for the central claim of robustness across error distributions.
Authors: We accept the point. The manuscript invokes residual resampling under the assumption that normalized residuals are approximately exchangeable once volatility is modeled, but does not state the required regularity conditions. In revision we will add an explicit subsection listing sufficient conditions on the volatility estimator (uniform consistency, moment bounds, and continuity of the conditional distribution) and on the base forecaster that justify the exchangeability argument for non-Gaussian heteroskedastic innovations. revision: yes
-
Referee: [Abstract (and implied theoretical section)] The manuscript provides no argument or rate result showing that the architecture-agnostic volatility module produces a consistent estimator at a rate sufficient for the normalized residuals to converge in distribution. Any misspecification in the volatility module therefore propagates directly into invalid predictive intervals, undermining the claim that the method remains valid under a wide range of error distributions.
Authors: We agree that a convergence-rate argument is absent. The existing theory treats the volatility estimate as given and focuses on the resampling step; it does not quantify how fast the volatility module must converge. In the revision we will insert a paragraph discussing the necessary rate (e.g., o_p(1) uniform consistency) and note that the separate, architecture-agnostic volatility module is intended to facilitate such rates, while acknowledging that full misspecification analysis would require additional technical work. revision: yes
Circularity Check
No circularity; derivation relies on standard residual resampling without self-referential reduction.
full rationale
The provided abstract and description outline a post-hoc method that separately models conditional mean and volatility via architecture-agnostic modules, then resamples normalized residuals to form predictive distributions. No equations, fitted parameters renamed as predictions, or self-citations are quoted that would make any claimed validity or calibration equivalent to the inputs by construction. The theoretical validity claim is presented as external to the fitting process itself, and the approach aligns with established statistical resampling techniques without evident tautology. This is the most common honest finding for papers whose central procedure does not reduce to a fit or self-citation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Probabilistic forecasting.Annual Review of Statistics and Its Application, 1(Volume 1, 2014):125–151, 2014
Tilmann Gneiting and Matthias Katzfuss. Probabilistic forecasting.Annual Review of Statistics and Its Application, 1(Volume 1, 2014):125–151, 2014
2014
-
[2]
A neural stochas- tic volatility model.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), Apr
Rui Luo, Weinan Zhang, Xiaojun Xu, and Jun Wang. A neural stochas- tic volatility model.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), Apr. 2018
2018
-
[3]
Nam Nguyen and Brian Quanz. Temporal latent auto-encoder: A method for probabilistic multivariate time series forecasting.Proceedings of the AAAI Conference on Artificial Intelligence, 35(10):9117–9125, May 2021
2021
-
[4]
Kejin Wu and Dimitris N. Politis. Bootstrap prediction inference of nonlinear autoregressive models.Journal of Time Series Analysis, 45(5):800–822, 2024
2024
-
[5]
Probabilistic forecasting with generative networks via scoring rule minimization.Journal of Machine Learning Research, 25(45):1–64, 2024
Lorenzo Pacchiardi, Rilwan A Adewoyin, Peter Dueben, and Ritabrata Dutta. Probabilistic forecasting with generative networks via scoring rule minimization.Journal of Machine Learning Research, 25(45):1–64, 2024
2024
-
[6]
KooNPro: A variance- aware koopman probabilistic model enhanced by neural process for time series forecasting
Ronghua Zheng, Hanru Bai, and Weiyang Ding. KooNPro: A variance- aware koopman probabilistic model enhanced by neural process for time series forecasting. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[7]
Analysis of financial time series.John Eiley and Sons, 2005
Ruey S Tsay. Analysis of financial time series.John Eiley and Sons, 2005
2005
-
[8]
Li Pan and Dimitris N. Politis. Bootstrap prediction intervals for linear, nonlinear and nonparametric autoregressions.Journal of Statistical Planning and Inference, 177:1–27, 2016
2016
-
[9]
Learning quantile functions without quantile crossing for distribution-free time series forecasting
Youngsuk Park, Danielle Maddix, François-Xavier Aubet, Kelvin Kan, Jan Gasthaus, and Yuyang Wang. Learning quantile functions without quantile crossing for distribution-free time series forecasting. In Gustau Camps-Valls, Francisco J. R. Ruiz, and Isabel Valera, editors,Proceedings of The 25th International Conference on Artificial Intelligence and Statis...
2022
-
[10]
Nonparametric quantile regression with reLU-activated recurrent neural networks
Hang Yu, Lyumin Wu, Wenxin Zhou, and Zhao Ren. Nonparametric quantile regression with reLU-activated recurrent neural networks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[11]
Predict, refine, synthe- size: Self-guiding diffusion models for probabilistic time series forecasting
Marcel Kollovieh, Abdul Fatir Ansari, Michael Bohlke-Schneider, Jasper Zschiegner, Hao Wang, and Yuyang (Bernie) Wang. Predict, refine, synthe- size: Self-guiding diffusion models for probabilistic time series forecasting. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, 26 editors,Advances in Neural Information Processing Systems, ...
2023
-
[12]
Maddix, Hao Wang, Michael W
Abdul Fatir Ansari, Lorenzo Stella, Ali Caner Turkmen, Xiyuan Zhang, Pe- dro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Bernie Wang. Chronos: Learning the lan...
-
[13]
Expert Certification
-
[14]
Robert F. Engle. Autoregressive conditional heteroscedasticity with esti- mates of the variance of united kingdom inflation.Econometrica, 50(4):987– 1007, 1982
1982
-
[15]
Generalized autoregressive conditional heteroskedasticity
Tim Bollerslev. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics, 31(3):307–327, 1986
1986
-
[16]
Predictive quantile regressions under persistence and conditional heteroskedasticity.Journal of Econometrics, 213(1):261–280,
Rui Fan and Ji Hyung Lee. Predictive quantile regressions under persistence and conditional heteroskedasticity.Journal of Econometrics, 213(1):261–280,
-
[17]
Annals: In Honor of Roger Koenker
-
[18]
Options and volatility.Economic Review, 81(3-6):21, 1996
Peter A Abken and Saikat Nandi. Options and volatility.Economic Review, 81(3-6):21, 1996
1996
-
[19]
McMurran, and Megan N
Harindra De Silva, Gregory M. McMurran, and Megan N. Miller. 14 - diversification and the volatility risk premium. In Emmanuel Jurczenko, editor,Factor Investing, pages 365–387. Elsevier, 2017
2017
-
[20]
Are transformers effective for time series forecasting?Proceedings of the AAAI Conference on Artificial Intelligence, 37(9):11121–11128, Jun
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting?Proceedings of the AAAI Conference on Artificial Intelligence, 37(9):11121–11128, Jun. 2023
2023
-
[21]
Cyclenet: Enhancing time series forecasting through modeling periodic patterns
Shengsheng Lin, Weiwei Lin, Xinyi HU, Wentai Wu, Ruichao Mo, and Haocheng Zhong. Cyclenet: Enhancing time series forecasting through modeling periodic patterns. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[22]
B. Efron. Bootstrap methods: another look at the jackknife.Ann. Statist., 7(1):1–26, 1979
1979
-
[23]
C. F. J. Wu. Jackknife, Bootstrap and Other Resampling Methods in Regression Analysis.The Annals of Statistics, 14(4):1261 – 1295, 1986
1986
-
[24]
Robert A. Stine. Bootstrap prediction intervals for regression.Journal of the American Statistical Association, 80(392):1026–1031, 1985
1985
-
[25]
A wild boot- strap for degenerate kernel tests
Kacper Chwialkowski, Dino Sejdinovic, and Arthur Gretton. A wild boot- strap for degenerate kernel tests. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K.Q. Weinberger, editors,Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc., 2014. 27
2014
-
[26]
Interval estimation for reinforcement- learning algorithms in continuous-state domains
Martha White and Adam White. Interval estimation for reinforcement- learning algorithms in continuous-state domains. In J. Lafferty, C. Williams, J. Shawe-Taylor, R. Zemel, and A. Culotta, editors,Advances in Neural Information Processing Systems, volume 23. Curran Associates, Inc., 2010
2010
-
[27]
Asymptotics of the bootstrap via stability with applications to inference with model selection
Morgane Austern and Vasilis Syrgkanis. Asymptotics of the bootstrap via stability with applications to inference with model selection. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 10705–10717. Curran Associates, Inc., 2021
2021
-
[28]
Bootstrap AutoEncoders with contrastive paradigm for self-supervised gaze estimation
Yaoming Wang, Jin Li, Wenrui Dai, Bowen Shi, Xiaopeng Zhang, Chenglin Li, and Hongkai Xiong. Bootstrap AutoEncoders with contrastive paradigm for self-supervised gaze estimation. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Confer...
2024
-
[29]
Metamath: Bootstrap your own mathematical questions for large language models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng YU, Zhengying Liu, Yu Zhang, James Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[30]
Conformalized quantile regression.Advances in neural information processing systems, 32, 2019
Yaniv Romano, Evan Patterson, and Emmanuel Candes. Conformalized quantile regression.Advances in neural information processing systems, 32, 2019
2019
-
[31]
Sequential predictive conformal inference for time series
Chen Xu and Yao Xie. Sequential predictive conformal inference for time series. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[32]
Con- formal pid control for time series prediction.Advances in neural information processing systems, 36:23047–23074, 2023
Anastasios Angelopoulos, Emmanuel Candes, and Ryan J Tibshirani. Con- formal pid control for time series prediction.Advances in neural information processing systems, 36:23047–23074, 2023
2023
-
[33]
Confor- mal prediction for time series with modern hopfield networks
Andreas Auer, Martin Gauch, Daniel Klotz, and Sepp Hochreiter. Confor- mal prediction for time series with modern hopfield networks. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 56027–56074. Curran Associates, Inc., 2023
2023
-
[34]
Conformalized time series with semantic features.Advances in Neural Information Processing Systems, 37:121449–121474, 2024
Baiting Chen, Zhimei Ren, and Lu Cheng. Conformalized time series with semantic features.Advances in Neural Information Processing Systems, 37:121449–121474, 2024
2024
-
[35]
Le, Timothy D
Ichiro Takeuchi, Quoc V. Le, Timothy D. Sears, and Alexander J. Smola. Nonparametric quantile estimation.Journal of Machine Learning Research, 7(45):1231–1264, 2006. 28
2006
-
[36]
Distributed high-dimensional quantile regression: estimation efficiency and support recovery
Caixing Wang and Ziliang Shen. Distributed high-dimensional quantile regression: estimation efficiency and support recovery. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[37]
Au- toregressive denoising diffusion models for multivariate probabilistic time series forecasting
Kashif Rasul, Calvin Seward, Ingmar Schuster, and Roland Vollgraf. Au- toregressive denoising diffusion models for multivariate probabilistic time series forecasting. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8857–8868. PMLR, 1...
2021
-
[38]
Multivariate probabilistic time series forecasting via conditioned normalizing flows
Kashif Rasul, Abdul-Saboor Sheikh, Ingmar Schuster, Urs M Bergmann, and Roland Vollgraf. Multivariate probabilistic time series forecasting via conditioned normalizing flows. InInternational Conference on Learning Representations, 2021
2021
-
[39]
Generative time series forecasting with diffusion, denoise, and disentanglement
Yan Li, Xinjiang Lu, Yaqing Wang, and Dejing Dou. Generative time series forecasting with diffusion, denoise, and disentanglement. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 23009–23022. Curran Associates, Inc., 2022
2022
-
[40]
Recurrent interpolants for probabilistic time series prediction
Yu Chen, Marin Biloš, Sarthak Mittal, Wei Deng, Kashif Rasul, and Ander- son Schneider. Recurrent interpolants for probabilistic time series prediction. arXiv preprint arXiv:2409.11684, 2024
-
[41]
Probabilistic forecasting with stochastic interpolants and föllmer processes
Yifan Chen, Mark Goldstein, Mengjian Hua, Michael Samuel Albergo, Nicholas Matthew Boffi, and Eric Vanden-Eijnden. Probabilistic forecasting with stochastic interpolants and föllmer processes. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scar- lett, and Felix Berkenkamp, editors,Proceedings of the 41st Inte...
2024
-
[42]
Csdi: condi- tional score-based diffusion models for probabilistic time series imputation
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. Csdi: condi- tional score-based diffusion models for probabilistic time series imputation. InProceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY, USA, 2021. Curran Associates Inc
2021
-
[43]
Transformer-modulated diffusion models for probabilistic multivariate time series forecasting
Yuxin Li, Wenchao Chen, Xinyue Hu, Bo Chen, baolin sun, and Mingyuan Zhou. Transformer-modulated diffusion models for probabilistic multivariate time series forecasting. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[44]
Flow matching with gaussian process priors for probabilistic 29 time series forecasting
Marcel Kollovieh, Marten Lienen, David Lüdke, Leo Schwinn, and Stephan Günnemann. Flow matching with gaussian process priors for probabilistic 29 time series forecasting. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[45]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 6840–6851. Curran Associates, Inc., 2020
2020
-
[46]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[47]
Auto-regressive moving diffusion models for time series forecasting.Proceedings of the AAAI Conference on Artificial Intelligence, 39(16):16727–16735, Apr
Jiaxin Gao, Qinglong Cao, and Yuntian Chen. Auto-regressive moving diffusion models for time series forecasting.Proceedings of the AAAI Conference on Artificial Intelligence, 39(16):16727–16735, Apr. 2025
2025
-
[48]
Deep state space models for time series forecasting
Syama Sundar Rangapuram, Matthias W Seeger, Jan Gasthaus, Lorenzo Stella, Yuyang Wang, and Tim Januschowski. Deep state space models for time series forecasting. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[49]
Learning interpretable deep state space model for probabilistic time series forecasting
Longyuan Li, Junchi Yan, Xiaokang Yang, and Yaohui Jin. Learning interpretable deep state space model for probabilistic time series forecasting. InProceedings of the 28th International Joint Conference on Artificial Intelligence, IJCAI’19, page 2901–2908. AAAI Press, 2019
2019
-
[50]
End-to-end learning of coherent probabilistic forecasts for hierarchical time series
Syama Sundar Rangapuram, Lucien D Werner, Konstantinos Benidis, Pedro Mercado, Jan Gasthaus, and Tim Januschowski. End-to-end learning of coherent probabilistic forecasts for hierarchical time series. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning R...
2021
-
[51]
Multi-scale attention flow for probabilistic time series forecasting.IEEE Trans
Shibo Feng, Chunyan Miao, Ke Xu, Jiaxiang Wu, Pengcheng Wu, Yang Zhang, and Peilin Zhao. Multi-scale attention flow for probabilistic time series forecasting.IEEE Trans. on Knowl. and Data Eng., 36(5):2056–2068, May 2024
2056
-
[52]
Probabilistic time series forecasting with shape and temporal diversity
Vincent Le Guen and Nicolas Thome. Probabilistic time series forecasting with shape and temporal diversity. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 4427–4440. Curran Associates, Inc., 2020
2020
-
[53]
Proba- bilistic forecasting: A level-set approach
Hilaf Hasson, Bernie Wang, Tim Januschowski, and Jan Gasthaus. Proba- bilistic forecasting: A level-set approach. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 6404–6416. Curran Associates, Inc., 2021. 30
2021
-
[54]
Sutranets: Sub-series autoregressive networks for long-sequence, probabilistic forecasting
Shane Bergsma, Tim Zeyl, and Lei Guo. Sutranets: Sub-series autoregressive networks for long-sequence, probabilistic forecasting. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 30518–30533. Curran Associates, Inc., 2023
2023
-
[55]
Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation.Econometrica: Journal of the econometric society, pages 987–1007, 1982
Robert F Engle. Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation.Econometrica: Journal of the econometric society, pages 987–1007, 1982
1982
-
[56]
HyperIV: Real-time implied volatility smoothing
Yongxin Yang, Wenqi Chen, Chao Shu, and Timothy Hospedales. HyperIV: Real-time implied volatility smoothing. InForty-second International Con- ference on Machine Learning, 2025
2025
-
[57]
Ni, Jun Pan, and Allen M
Sophie X. Ni, Jun Pan, and Allen M. Poteshman. Volatility information trading in the option market.The Journal of Finance, 63(3):1059–1091, 2008
2008
-
[58]
Volatility, the macroeconomy, and asset prices.The Journal of Finance, 69(6):2471–2511, 2014
Ravi Bansal, Dana Kiku, Ivan Shaliastovich, and Amir Yaron. Volatility, the macroeconomy, and asset prices.The Journal of Finance, 69(6):2471–2511, 2014
2014
-
[59]
Deep smoothing of the implied volatility surface
Damien Ackerer, Natasa Tagasovska, and Thibault Vatter. Deep smoothing of the implied volatility surface. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 11552–11563. Curran Associates, Inc., 2020
2020
-
[60]
Arbitrage-free implied volatility surface generation with variational autoencoders.SIAM Journal on Financial Mathematics, 14(4):1004–1027, 2023
Brian (Xin) Ning, Sebastian Jaimungal, Xiaorong Zhang, and Maxime Berg- eron. Arbitrage-free implied volatility surface generation with variational autoencoders.SIAM Journal on Financial Mathematics, 14(4):1004–1027, 2023
2023
-
[61]
Operator deep smoothing for implied volatility
Ruben Wiedemann, Antoine Jacquier, and Lukas Gonon. Operator deep smoothing for implied volatility. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[62]
Forecasting realized volatility with spillover effects: Perspectives from graph neural networks.International Journal of Forecasting, 41(1):377–397, 2025
Chao Zhang, Xingyue Pu, Mihai Cucuringu, and Xiaowen Dong. Forecasting realized volatility with spillover effects: Perspectives from graph neural networks.International Journal of Forecasting, 41(1):377–397, 2025
2025
-
[63]
Incorporating prior financial domain knowledge into neural networks for implied volatility surface predic- tion
Yu Zheng, Yongxin Yang, and Bowei Chen. Incorporating prior financial domain knowledge into neural networks for implied volatility surface predic- tion. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, KDD ’21, page 3968–3975, New York, NY, USA,
-
[64]
Association for Computing Machinery
-
[65]
Deepar: Probabilistic forecasting with autoregressive recurrent networks
David Salinas, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. Deepar: Probabilistic forecasting with autoregressive recurrent networks. International Journal of Forecasting, 36(3):1181–1191, 2020. 31
2020
-
[66]
Kejin Wu and Dimitris N. Politis. Scalable subsampling inference for deep neural networks.ACM / IMS J. Data Sci., 2(1), February 2025
2025
-
[67]
Leveraging temporal dependency in probabilistic electric load forecasting.Applied Soft Computing, 169:112611, 2025
Yaoli Zhang, Ye Tian, and Yunyi Zhang. Leveraging temporal dependency in probabilistic electric load forecasting.Applied Soft Computing, 169:112611, 2025
2025
-
[68]
Asymptotic theory for a vector arma- garch model.Econometric Theory, 19(2):280–310, 2003
Shiqing Ling and Michael McAleer. Asymptotic theory for a vector arma- garch model.Econometric Theory, 19(2):280–310, 2003
2003
-
[69]
Non-stationary diffusion for probabilistic time series forecasting, 2025
Weiwei Ye, Zhuopeng Xu, and Ning Gui. Non-stationary diffusion for probabilistic time series forecasting, 2025
2025
-
[70]
Crossformer: Transformer utilizing cross- dimension dependency for multivariate time series forecasting
Yunhao Zhang and Junchi Yan. Crossformer: Transformer utilizing cross- dimension dependency for multivariate time series forecasting. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[71]
Bootstrap model aggregation for distributed statistical learning
JUN HAN and Qiang Liu. Bootstrap model aggregation for distributed statistical learning. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016
2016
-
[72]
Small resamples, sharp guarantees: Convergence rates for resampled studentized quantile estimators
Imon Banerjee and Sayak Chakrabarty. Small resamples, sharp guarantees: Convergence rates for resampled studentized quantile estimators. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[73]
A time series is worth 64 words: Long-term forecasting with transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. In The Eleventh International Conference on Learning Representations, 2023
2023
-
[74]
Timemixer: Decomposable multiscale mixing for time series forecasting
Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Y Zhang, and JUN ZHOU. Timemixer: Decomposable multiscale mixing for time series forecasting. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[75]
Estimating conditional quantiles with the help of the pinball loss.Bernoulli, 17(1):211 – 225, 2011
Ingo Steinwart and Andreas Christmann. Estimating conditional quantiles with the help of the pinball loss.Bernoulli, 17(1):211 – 225, 2011
2011
-
[76]
Online quantile regression
Yinan Shen, Dong Xia, and Wen-Xin Zhou. Online quantile regression. Journal of Machine Learning Research, 26(231):1–55, 2025
2025
-
[77]
High-dimensional multivariate forecasting with low-rank gaussian copula processes
David Salinas, Michael Bohlke-Schneider, Laurent Callot, Roberto Medico, and Jan Gasthaus. High-dimensional multivariate forecasting with low-rank gaussian copula processes. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors,Advances in Neural Infor- mation Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
-
[78]
Sampling-based multi- dimensional recalibration
Youngseog Chung, Ian Char, and Jeff Schneider. Sampling-based multi- dimensional recalibration. InForty-first International Conference on Ma- chine Learning, 2024. 32
2024
-
[79]
Skip sampling: subsampling in the frequency domain.Biometrika, 111(4):1241–1256, 08 2024
Tucker McElroy and Dimitris N Politis. Skip sampling: subsampling in the frequency domain.Biometrika, 111(4):1241–1256, 08 2024
2024
-
[80]
Springer Berlin Heidelberg, Berlin, Heidelberg, 2011
Olimjon Shukurovich Sharipov.Glivenko-Cantelli Theorems, pages 612–614. Springer Berlin Heidelberg, Berlin, Heidelberg, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.