Equilibrated Diffusion: Frequency-aware Textual Embedding for Equilibrated Image Customization
Pith reviewed 2026-06-28 15:09 UTC · model grok-4.3
The pith
Equilibrated Diffusion separates low-frequency subject content from high-frequency styles in textual embeddings to reduce entanglement during image customization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Decomposing concepts into frequency-specific embeddings, optimizing them independently, and merging the results lets the denoiser treat style as detachable from subject identity while mask guidance and residual attention maintain spatial fidelity and text adherence.
What carries the argument
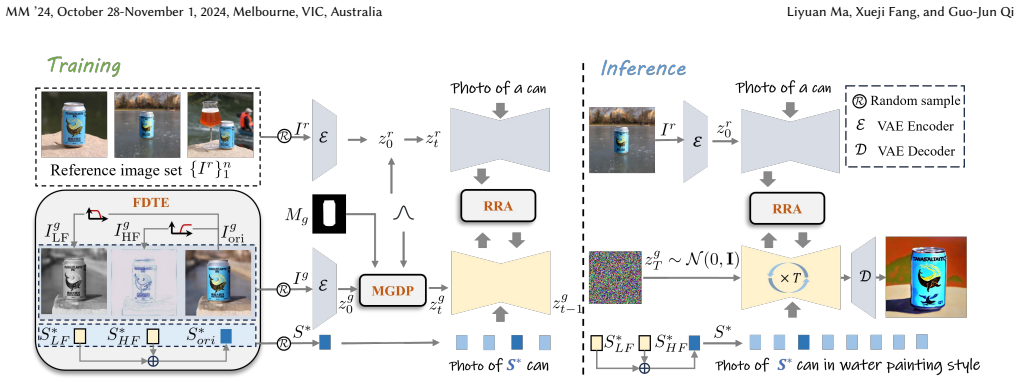
Frequency-aware textual embedding that decomposes reference images into low-frequency subject and high-frequency style components for separate optimization before merging.
If this is right
- Independent frequency embeddings allow the model to apply novel styles to the learned subject without retraining.
- Merging the optimized embeddings keeps the original spatial customization capability of the base diffusion model intact.
- Mask-guided diffusion restricts background alterations and improves prompt adherence during generation.
- Residual reference attention inserted in spatial layers preserves subject structure across varied prompts.
Where Pith is reading between the lines
- The same frequency split could be tested on video or 3D generation tasks where content-style separation is also desirable.
- Different frequency cutoffs or wavelet bases might be compared to find the split that maximizes disentanglement for a given dataset.
- The method might reduce the need for heavy fine-tuning data if the frequency prior already supplies useful separation.
Load-bearing premise
Low image frequencies inherently encode subject content while high frequencies encode style.
What would settle it
A controlled test in which low- and high-frequency embeddings are swapped at inference time yet produce no measurable drop in subject fidelity or rise in style leakage.
Figures






read the original abstract
Image customization learns target subjects from reference concept images and generates conditioned images per text prompts, mainly modifying styles or backgrounds. Prevailing methods adopt fine-tuning to pack diverse concept attributes into a unified latent embedding, yet entangled attributes hinder elimination of irrelevant disturbances from style and background. To address this issue, we propose Equilibrated Diffusion, a frequency-driven approach that disentangles tangled concept features for balanced customization and consistent text-visual matching. Unlike conventional methods learning full concepts with shared embeddings and unified tuning, our work utilizes the inherent link between image frequency components and semantics: low frequencies represent subject content and high frequencies correspond to styles. We decompose concepts in frequency space and optimize each embedding independently. This separate optimization enables the denoiser to capture style detached from subject identity and generalize better to unseen stylistic prompts. Merging multi-frequency embeddings preserves the model's original spatial customization ability. We further deploy mask-guided diffusion to restrict irrelevant background changes and boost text alignment. Residual Reference Attention (RRA) is inserted into spatial attention to retain subject structure and identity consistency. Experiments prove Equilibrated Diffusion exceeds mainstream baselines on subject fidelity and text adherence, verifying our method's superiority.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Equilibrated Diffusion, a frequency-driven method for image customization that decomposes reference concepts into separate low-frequency (subject content) and high-frequency (style) textual embeddings, optimizes them independently to reduce entanglement, and augments this with mask-guided diffusion and Residual Reference Attention (RRA) to improve text alignment and identity preservation. It claims this yields superior subject fidelity and text adherence over mainstream baselines.
Significance. If the frequency-semantics correspondence holds and produces verifiable disentanglement, the approach could meaningfully advance subject-driven customization by mitigating the attribute entanglement common in unified fine-tuning methods, enabling better generalization to novel stylistic prompts while preserving spatial control.
major comments (2)
- [Abstract] Abstract: The method's core strategy of independent optimization rests on the unvalidated assertion of an 'inherent link' where low frequencies encode subject identity and high frequencies encode styles. No derivation from the diffusion forward process, no frequency-domain analysis of the UNet, and no ablation isolating the effect of this split on disentanglement are provided, making the architectural novelty and superiority claims dependent on an untested premise.
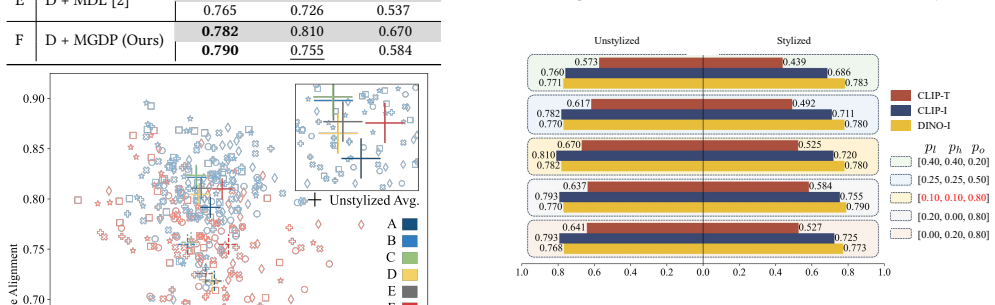
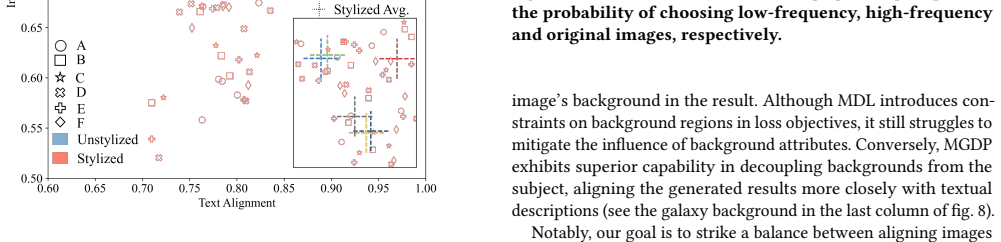
- [Abstract] Abstract: The claim that 'Experiments prove Equilibrated Diffusion exceeds mainstream baselines on subject fidelity and text adherence' is unsupported by any quantitative metrics, error bars, dataset specifications, baseline details, or ablation results in the provided text, preventing verification of the central empirical assertion.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The method's core strategy of independent optimization rests on the unvalidated assertion of an 'inherent link' where low frequencies encode subject identity and high frequencies encode styles. No derivation from the diffusion forward process, no frequency-domain analysis of the UNet, and no ablation isolating the effect of this split on disentanglement are provided, making the architectural novelty and superiority claims dependent on an untested premise.
Authors: We acknowledge that the abstract presents the frequency-semantics correspondence as an inherent link without supporting derivation or analysis. While this correspondence draws from established image processing observations (low frequencies capture global structure and semantics, high frequencies capture textures and style), we agree that a direct connection to the diffusion forward process and UNet behavior requires explicit validation. In the revised manuscript we will add a concise frequency-domain analysis of the diffusion process together with an ablation that isolates the contribution of the low/high-frequency split to disentanglement. These additions will be placed in the method or experiments section and referenced from the abstract. revision: yes
-
Referee: [Abstract] Abstract: The claim that 'Experiments prove Equilibrated Diffusion exceeds mainstream baselines on subject fidelity and text adherence' is unsupported by any quantitative metrics, error bars, dataset specifications, baseline details, or ablation results in the provided text, preventing verification of the central empirical assertion.
Authors: The abstract is written as a concise summary; the full manuscript contains the quantitative evaluations, including subject fidelity and text-alignment metrics, baseline comparisons, dataset details, and ablations. Nevertheless, we agree that the abstract claim would be more verifiable if it referenced key results. We will revise the abstract to include brief quantitative highlights (e.g., relative improvements on standard metrics) while still keeping it within length limits, and we will ensure the abstract explicitly points to the experiments section for full details, error bars, and dataset specifications. revision: yes
Circularity Check
No significant circularity: method applies stated frequency-semantics assumption without self-referential reduction or fitted predictions
full rationale
The abstract presents the core premise as an 'inherent link' between frequency components and semantics (low frequencies = subject content, high frequencies = styles) and describes independent optimization of embeddings as a direct consequence. No equations, derivations, or self-citations are shown that would make any claimed prediction equivalent to its inputs by construction. The approach is self-contained once the frequency-semantics correspondence is granted as an external modeling choice; experiments compare against baselines rather than relying on internal consistency alone. This is the normal case of an assumption-driven method without circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low frequencies represent subject content and high frequencies correspond to styles
Reference graph
Works this paper leans on
-
[1]
Yuval Alaluf, Elad Richardson, Gal Metzer, and Daniel Cohen-Or. 2023. A Neural Space-Time Representation for Text-to-Image Personalization.ACM Transactions on Graphics (TOG)42, 6 (2023), 1–10
2023
-
[2]
Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen-Or, and Dani Lischin- ski. 2023. Break-a-scene: Extracting multiple concepts from a single image. In SIGGRAPH Asia 2023 Conference Papers. 1–12
2023
-
[3]
Yufei Cai, Yuxiang Wei, Zhilong Ji, Jinfeng Bai, Hu Han, and Wangmeng Zuo. 2024. Decoupled textual embeddings for customized image generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 909–917
2024
-
[4]
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xiaohu Qie, and Yinqiang Zheng. 2023. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision. 22560–22570
2023
-
[5]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision. 9650–9660
2021
-
[6]
Hong Chen, Yipeng Zhang, Simin Wu, Xin Wang, Xuguang Duan, Yuwei Zhou, and Wenwu Zhu. 2023. Disenbooth: Identity-preserving disentangled tuning for subject-driven text-to-image generation. InThe Twelfth International Conference on Learning Representations
2023
-
[7]
Wenhu Chen, Hexiang Hu, Yandong Li, Nataniel Ruiz, Xuhui Jia, Ming-Wei Chang, and William W Cohen. 2024. Subject-driven text-to-image generation via apprenticeship learning.Advances in Neural Information Processing Systems 36 (2024)
2024
- [8]
- [9]
- [10]
-
[11]
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-or. 2023. An Image is Worth One Word: Per- sonalizing Text-to-Image Generation using Textual Inversion. InThe Eleventh International Conference on Learning Representations. https://openreview.net/ forum?id=NAQvF08TcyG
2023
-
[12]
Rinon Gal, Moab Arar, Yuval Atzmon, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. 2023. Encoder-based domain tuning for fast personalization of text- to-image models.ACM Transactions on Graphics (TOG)42, 4 (2023), 1–13
2023
-
[13]
Ligong Han, Yinxiao Li, Han Zhang, Peyman Milanfar, Dimitris Metaxas, and Feng Yang. 2023. Svdiff: Compact parameter space for diffusion fine-tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 7323– 7334
2023
-
[14]
Shaozhe Hao, Kai Han, Shihao Zhao, and Kwan-Yee K Wong. 2023. ViCo: Plug- and-play Visual Condition for Personalized Text-to-image Generation. (2023)
2023
-
[15]
Feihong He, Gang Li, Mengyuan Zhang, Leilei Yan, Lingyu Si, and Fanzhang Li
-
[16]
arXiv preprint arXiv:2401.15636(2024)
Freestyle: Free lunch for text-guided style transfer using diffusion models. arXiv preprint arXiv:2401.15636(2024)
-
[17]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
2020
- [18]
- [19]
-
[20]
Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. 2021. Focal frequency loss for image reconstruction and synthesis. InProceedings of the IEEE/CVF international conference on computer vision. 13919–13929
2021
-
[21]
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu
-
[22]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1931–1941
1931
-
[23]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Liyuan Ma, Tingwei Gao, Haibin Shen, and Kejie Huang. 2023. Freqhpt: Frequency-aware attention and flow fusion for human pose transfer. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3490–3495
2023
- [25]
- [26]
-
[27]
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. 2021. Glide: Towards photorealistic image generation and editing with text-guided diffusion models.arXiv preprint arXiv:2112.10741(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
R OpenAI. 2023. Gpt-4 technical report. arxiv 2303.08774.View in Article2, 5 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Zhongwei Qiu, Huan Yang, Jianlong Fu, and Dongmei Fu. 2022. Learning spa- tiotemporal frequency-transformer for compressed video super-resolution. In European Conference on Computer Vision. Springer, 257–273
2022
-
[30]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PMLR, 8748–8763
2021
-
[31]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
-
[32]
Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.061251, 2 (2022), 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. 2024. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10684–10695
2022
-
[35]
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22500–22510
2023
-
[36]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. 2022. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems35 (2022), 36479–36494
2022
- [37]
-
[38]
Chenyang Si, Weihao Yu, Pan Zhou, Yichen Zhou, Xinchao Wang, and Shuicheng Yan. 2022. Inception transformer.Advances in Neural Information Processing Systems35 (2022), 23495–23509
2022
-
[39]
Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [40]
-
[41]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2020. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[42]
Yoad Tewel, Rinon Gal, Gal Chechik, and Yuval Atzmon. 2023. Key-locked rank one editing for text-to-image personalization. InACM SIGGRAPH 2023 Conference Proceedings. 1–11
2023
-
[43]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[44]
Andrey Voynov, Kfir Aberman, and Daniel Cohen-Or. 2023. Sketch-guided text- to-image diffusion models. InACM SIGGRAPH 2023 Conference Proceedings. 1–11
2023
-
[45]
arXiv preprint arXiv:2303.09522 , year=
Andrey Voynov, Qinghao Chu, Daniel Cohen-Or, and Kfir Aberman. 2023.𝑃+: Extended Textual Conditioning in Text-to-Image Generation.arXiv preprint arXiv:2303.09522(2023)
-
[46]
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, and Anthony Chen. 2024. In- stantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [47]
-
[48]
Yuxiang Wei, Yabo Zhang, Zhilong Ji, Jinfeng Bai, Lei Zhang, and Wangmeng Zuo
-
[49]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 15943–15953
-
[50]
Shaoan Xie, Zhifei Zhang, Zhe Lin, Tobias Hinz, and Kun Zhang. 2023. Smart- brush: Text and shape guided object inpainting with diffusion model. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22428–22437
2023
-
[51]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. 2023. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.