CRAFTQA: A Code-Driven Adaptive Framework for Complex Structured Data Reasoning
Pith reviewed 2026-06-28 14:29 UTC · model grok-4.3
The pith
CRAFTQA generates complete executable Python code sequences and dynamic custom functions to perform complex reasoning over heterogeneous structured data without being limited to predefined operations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
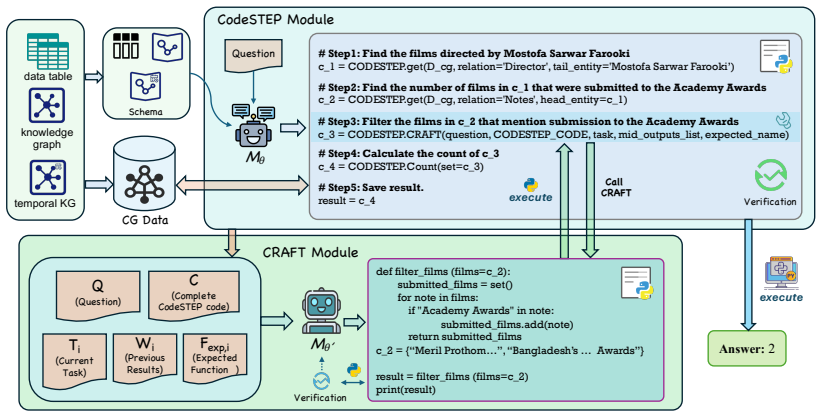
CRAFTQA is a code-driven adaptive framework whose CodeSTEP module produces complete executable Python code sequences containing step-by-step reasoning operations, while its CRAFT module dynamically generates custom code functions for operations outside any predefined set, allowing seamless handling of complex reasoning across different structured data types in one system.
What carries the argument
The CodeSTEP paradigm for generating executable Python code sequences, integrated with the CRAFT module that creates and inserts custom functions on demand.
If this is right
- Reasoning operations can extend beyond any initial predefined function library without redesigning the system.
- A single framework can process multiple structured data formats such as tables and knowledge graphs with comparable gains on complex tasks.
- Code execution becomes the direct carrier of multi-step reasoning instead of a separate post-processing step.
- Performance improvements concentrate in scenarios that require operations outside standard function sets.
Where Pith is reading between the lines
- The same code-generation pattern could be tested on other domains that currently rely on fixed tool libraries, such as web navigation or database querying.
- If code reliability varies with question complexity, hybrid systems that add runtime verification or fallback mechanisms become a natural next step.
- The framework implicitly treats code as the universal intermediate representation for heterogeneous data, which invites experiments swapping Python for other executable languages.
Load-bearing premise
Large language models can reliably output correct, executable Python code including novel custom functions that integrate without runtime errors and that actually answer the original question.
What would settle it
A controlled test showing that the generated code often fails to execute, contains semantic errors, or produces no accuracy improvement over fixed-function baselines on complex structured-data questions would falsify the central claim.
Figures
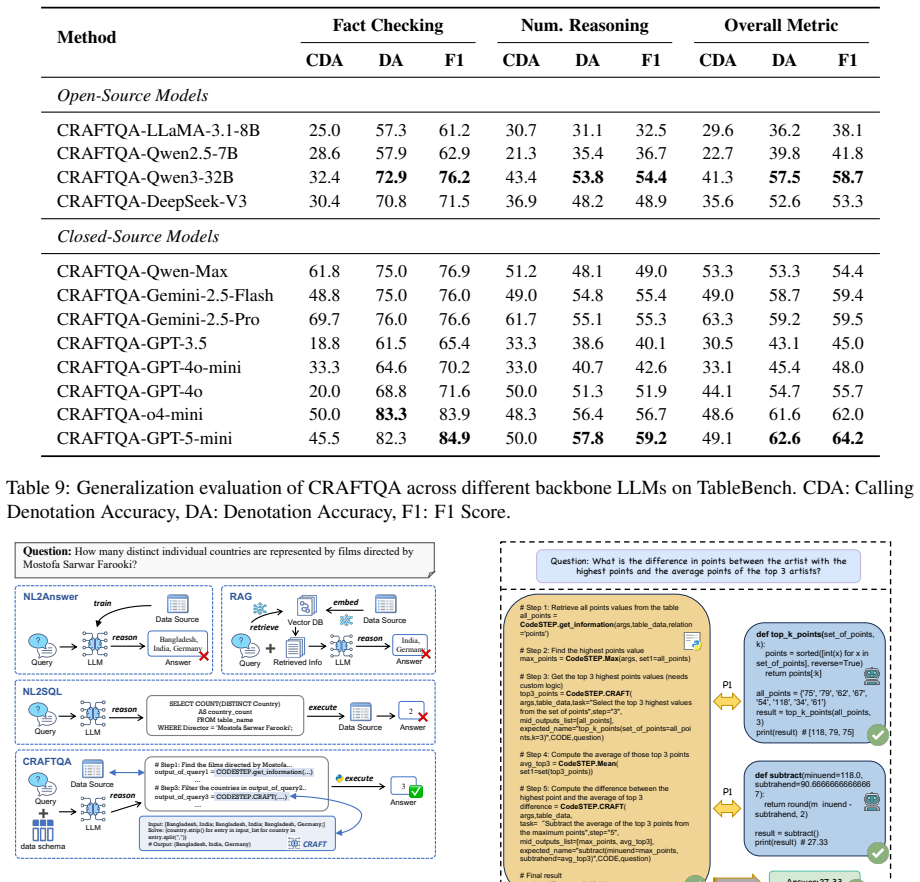
read the original abstract
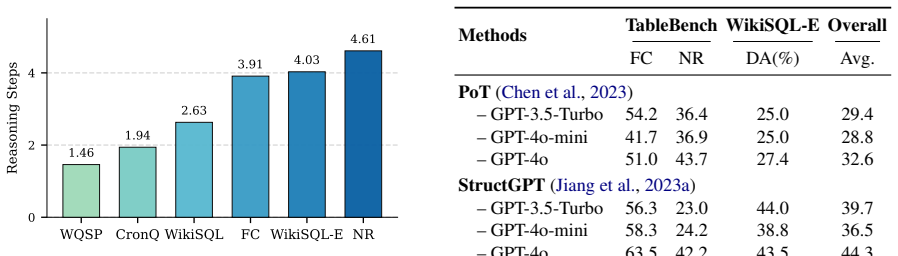
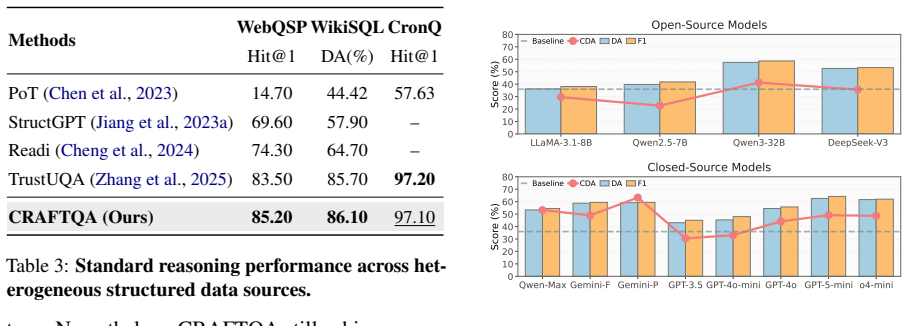
Real-world scenarios involve massive heterogeneous structured data (e.g., tables, knowledge graphs), making effective reasoning over such diverse data increasingly important. Unified structured data question answering has emerged as a prominent research trend, aiming to answer natural language questions across different structured data types within a single framework. However, existing unified methods share a common limitation: they rely on a set of predefined functions, which restricts their ability to perform complex reasoning beyond these predefined operations. To overcome this fundamental limitation, we propose CRAFTQA, a novel adaptive code-driven framework comprising two core modules, CodeSTEP and CRAFT. The CodeSTEP module is a paradigm that generates a complete executable Python code sequence, which contains step-by-step code-based reasoning operations based on the question. The CRAFT module dynamically generates custom code functions for operations beyond the predefined function set, and seamlessly integrates with CodeSTEP to significantly enhance flexibility in handling complex reasoning. Comprehensive experiments on multiple structured datasets demonstrate that CRAFTQA achieves remarkable improvements in complex reasoning scenarios compared to existing unified methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CRAFTQA, a code-driven adaptive framework for unified structured data question answering over heterogeneous data such as tables and knowledge graphs. It comprises two modules: CodeSTEP, which generates complete executable Python code sequences encoding step-by-step reasoning operations, and CRAFT, which dynamically creates custom code functions for operations outside any predefined set. The central claim is that this overcomes the restriction of prior unified methods to fixed function libraries and yields remarkable empirical improvements on multiple structured datasets.
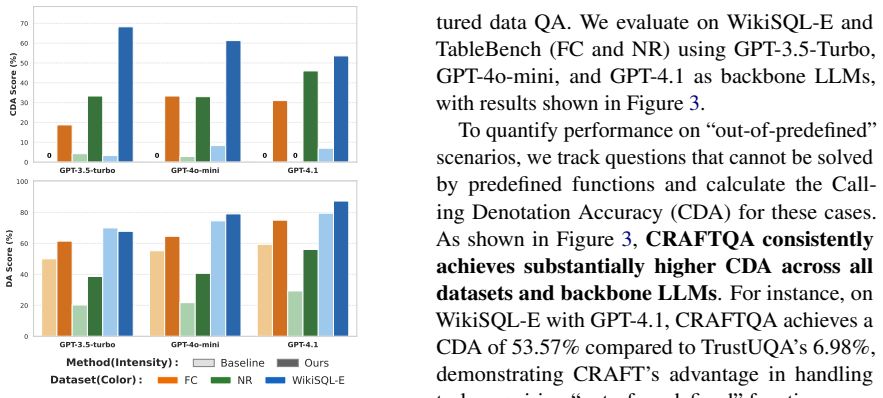
Significance. If the empirical gains are shown to be robust and the generated code is verifiably correct and executable at high rates, the framework would address a genuine limitation in existing unified structured-data QA approaches by enabling adaptive, open-ended reasoning via LLM-generated code. The core idea of dynamically extending the operation set through custom functions is a direct response to the predefined-function bottleneck.
major comments (2)
- [Abstract] Abstract: the assertion of 'remarkable improvements in complex reasoning scenarios compared to existing unified methods' is unsupported by any metrics, baselines, dataset sizes, error bars, or execution-success statistics, which is load-bearing for the central empirical claim.
- [Abstract / CodeSTEP and CRAFT modules] Abstract and method description: no verification, sandboxing, iterative repair, or error-handling procedure is described for the Python code sequences produced by CodeSTEP or the custom functions produced by CRAFT; without such a mechanism the claim that the generated code reliably parses the input data structures and answers the question cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. Below we address each major comment point by point, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'remarkable improvements in complex reasoning scenarios compared to existing unified methods' is unsupported by any metrics, baselines, dataset sizes, error bars, or execution-success statistics, which is load-bearing for the central empirical claim.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support. The full manuscript reports experiments across multiple structured datasets with specific baselines and performance metrics; however, these details are not summarized numerically in the abstract. We will revise the abstract to incorporate key results (dataset sizes, accuracy improvements, and execution success rates) drawn from the experimental section. revision: yes
-
Referee: [Abstract / CodeSTEP and CRAFT modules] Abstract and method description: no verification, sandboxing, iterative repair, or error-handling procedure is described for the Python code sequences produced by CodeSTEP or the custom functions produced by CRAFT; without such a mechanism the claim that the generated code reliably parses the input data structures and answers the question cannot be evaluated.
Authors: This observation is correct; the current manuscript text does not describe any verification, sandboxing, or error-handling procedures. We will add an explicit subsection detailing the code execution pipeline, including sandboxed execution, syntax and runtime error detection, iterative repair loops, and verification that the generated code correctly operates on the input structures before producing the final answer. revision: yes
Circularity Check
No circularity: empirical framework with experimental claims, no derivations or fitted predictions
full rationale
The paper describes an LLM-based code generation framework (CodeSTEP + CRAFT) for structured data QA and asserts empirical improvements on datasets. No equations, parameters, or first-principles derivations appear; the central claim is not a 'prediction' derived from inputs inside the paper but an experimental outcome. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations reduce the argument to its own construction. The method is self-contained as a proposed system whose validity rests on external evaluation rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can generate correct, executable Python code that performs the required data-reasoning steps.
Reference graph
Works this paper leans on
-
[1]
Question calibration and multi-hop modeling for temporal question answering. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19332–19340. Dayu Yang, Tianyang Liu, Daoan Zhang, Antoine Simoulin, Xiaoyi Liu, Yuwei Cao, Zhaopu Teng, Xin Qian, Grey Yang, Jiebo Luo, and 1 others. 2025. Code to think, think to code: A survey on...
-
[2]
Decaf: Joint decoding of answers and logical forms for question answering over knowledge bases. InThe Eleventh International Conference on Learn- ing Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. Fei Yu, Hongbo Zhang, Prayag Tiwari, and Benyou Wang. 2024. Natural language reasoning, a survey. ACM Computing Surveys, 56(12):1–39...
-
[3]
Knowledge-Based Systems, 242:108252
Improving complex knowledge base ques- tion answering via structural information learning. Knowledge-Based Systems, 242:108252. Wen Zhang, Long Jin, Yushan Zhu, Jiaoyan Chen, Zhi- wei Huang, Junjie Wang, Yin Hua, Lei Liang, and Huajun Chen. 2025. Trustuqa: A trustful framework for unified structured data question answering. In Proceedings of the AAAI Conf...
2025
-
[4]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Seq2sql: Generating structured queries from natural language using reinforcement learning.arXiv preprint arXiv:1709.00103. A Datasets and Evaluation Metrics We evaluate on multiple standard QA datasets span- ning different structured data types,WebQSP(Yih et al., 2016) is a KGQA dataset requiring reason- ing over Freebase. We use Hit@1 as the evalua- tion...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
This mode returns a set of row identifiers where that column matches the value, e.g.{‘[line_2]’, ‘[line_7]’, ‘[line_1]’}
relation + tail_entity: ‘relation’ is a column name, and ‘tail_entity’ is a specific value in that column. This mode returns a set of row identifiers where that column matches the value, e.g.{‘[line_2]’, ‘[line_7]’, ‘[line_1]’}
-
[6]
This mode returns a set of values from the specified column for those rows
relation + head_entity: ‘relation’ is a column name, and ‘head_entity’ is one or more row identifier(s) in the‘[line_id]’format. This mode returns a set of values from the specified column for those rows. Constraints & Usage Guidelines [Note 1]: The first call to theget_informationfunction requiresis_first=True. [Note 2 - Strict Constraint]: In theget_inf...
-
[7]
Try to use the functions in the provided preset function list to solve the query at each step
-
[8]
If the preset functions are insufficient, you may useCODESTEP.CRAFT()to process the query
-
[9]
Use Set and Calculator functions as necessary to complete the task
-
[10]
use_CRAFT
Record whetherCODESTEP.CRAFT()was used by setting the “use_CRAFT” variable toTrueorFalse. Preset Function List Conditional Graph Query functions: •CODESTEP.get_information(args, table_data=table_data, relation=None, head_entity=None, tail_entity=None, key=None, value=None, tail_entity_cmp=’=’, value_cmp=’=’, target_type=target_type_ms, is_first=False) Set...
-
[11]
You can get the specific data required for the current step processing from [Previous Steps and Results]
-
[12]
In [Previous Steps and Results], if a step result does not contain data of type ‘[line_id]’, then the original result is directly represented, that is, ‘stepx’:{{‘original result of this step’}}
-
[13]
# Output Requirements Code Generation
In [Previous Steps and Results], if a step result contains data of type ‘[line_id]’, which means the data of a row, then the data information corresponding to each column of the row will be represented accordingly (column name: value), that is, the result of this step will be represented as‘stepx’:{{‘original result of this step’:‘specific information cor...
-
[14]
Must useprint()for final result output
-
[15]
Code must be self-contained (executable independently)
-
[16]
Result Handling
Result format: Single-line text/number. Result Handling
-
[17]
Return ONLY current step’s processed result
-
[18]
Prohibit intermediate processes/explanations
-
[19]
a set, a string, etc.), but must never be a dictionary! # Processing Rules
Output must match the data type required by the current step (e.g. a set, a string, etc.), but must never be a dictionary! # Processing Rules
-
[20]
Prioritize input data from [Previous Steps and Results]
-
[21]
Ensure output directly contributes to solving [Final Question]
-
[22]
Table 11: Prompt template for the CRAFT module
Solve the current task by writing code based on the information and constraints provided. Table 11: Prompt template for the CRAFT module. The system prompt guides the LLM Mθ′ to generate self- contained custom code functions for reasoning steps beyond predefined operations
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.