Conditional Graph Diffusion for Negotiation Support: Overcoming Discrete Infeasibility and Preference Elicitation Gaps
Pith reviewed 2026-06-28 12:16 UTC · model grok-4.3
The pith
Conditional graph diffusion generates negotiation recommendations in continuous utility space that meet individual rationality at rate 0.997.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
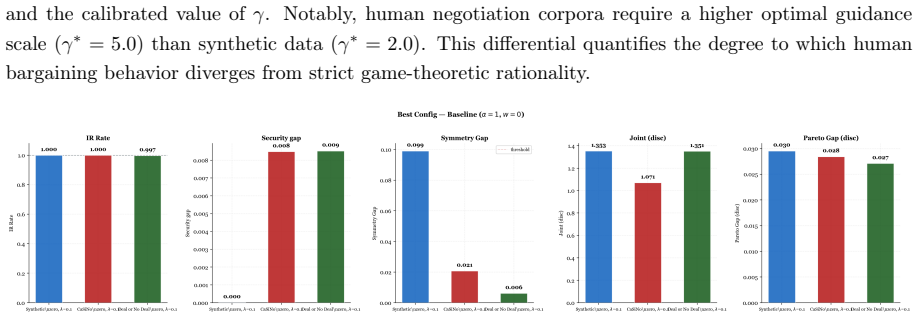
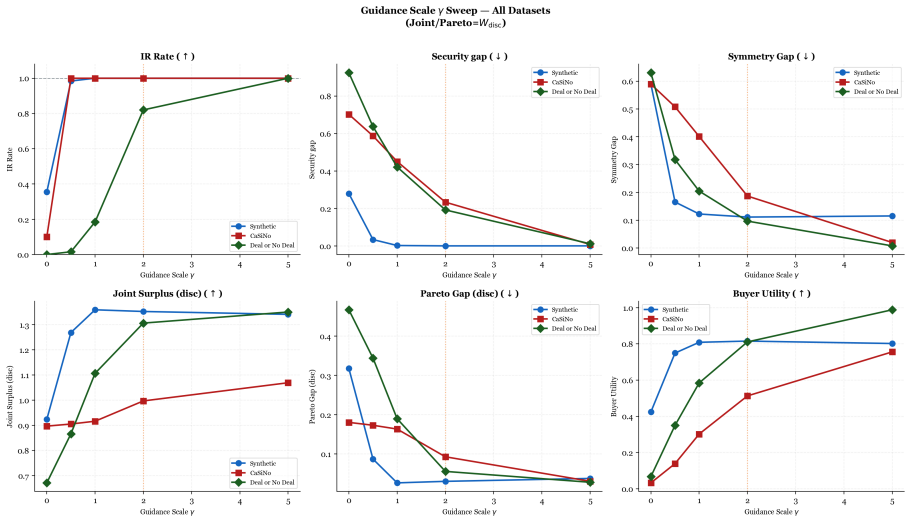
The Conditional Graph Diffusion framework generates bilateral negotiation recommendations in continuous utility space by encoding comparative preferences with GATv2 and fusing dialogue via cross-attention into a denoising diffusion model, then applying an analytically derived guidance gradient at inference to steer toward individual rationality, security proximity, and equitability, achieving rates of at least 0.997, gaps of at most 0.009, and symmetry within 0.15.
What carries the argument
The analytically derived normative guidance gradient applied at each reverse diffusion step to inject per-step monotonic corrections for normative properties.
If this is right
- Negotiation support systems can avoid structural infeasibility by generating in continuous rather than discrete space.
- Natural-language dialogue signals improve preference elicitation when fused through cross-attention.
- Normative compliance is decoupled from welfare maximization and can be recovered at inference time.
- Ablation shows that naive constraint minimization without the learned generative prior fails across corpora.
- The method preserves individual rationality while recovering Pareto efficiency on CaSiNo.
Where Pith is reading between the lines
- The continuous-space representation could support online updating of recommendations as dialogue evolves.
- Extending the graph encoder to multi-party settings would test whether the same guidance gradient scales beyond bilateral cases.
- The inference-time separation of normative and welfare objectives suggests similar guidance could be added to other generative models in game-theoretic domains.
Load-bearing premise
The analytically derived normative guidance gradient can be applied at each reverse diffusion step to steer generation toward individual rationality, security proximity, and equitability without retraining the model across heterogeneous corpora.
What would settle it
A new negotiation corpus on which the guidance gradient fails to produce individual rationality above 0.99 or the cross-attention fusion shows no improvement in the controlled misrepresentation experiment.
Figures
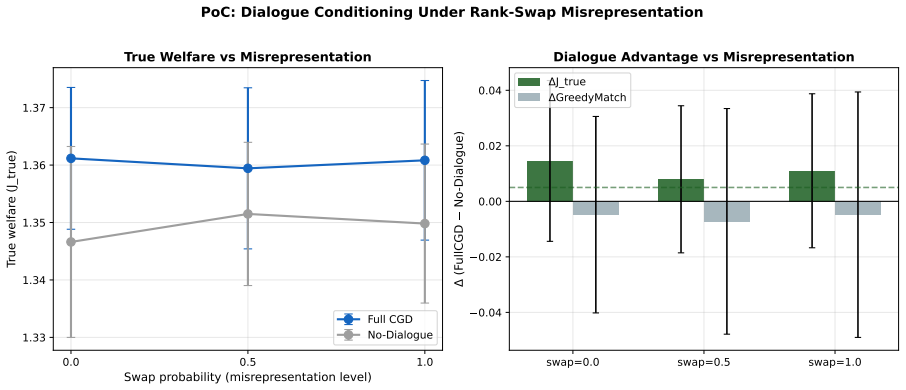
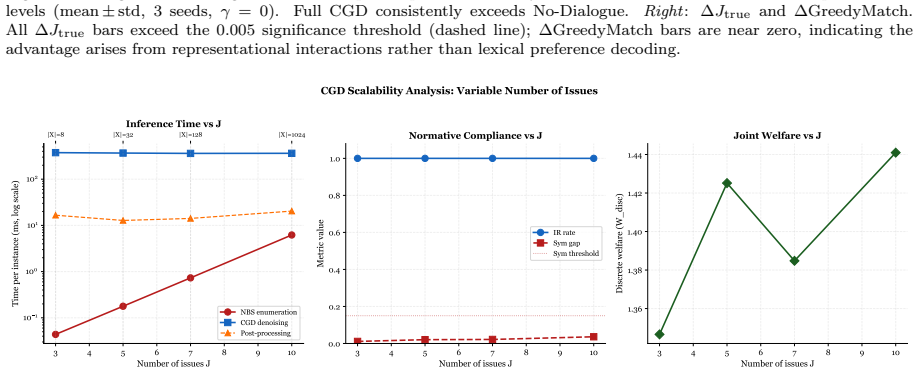

read the original abstract
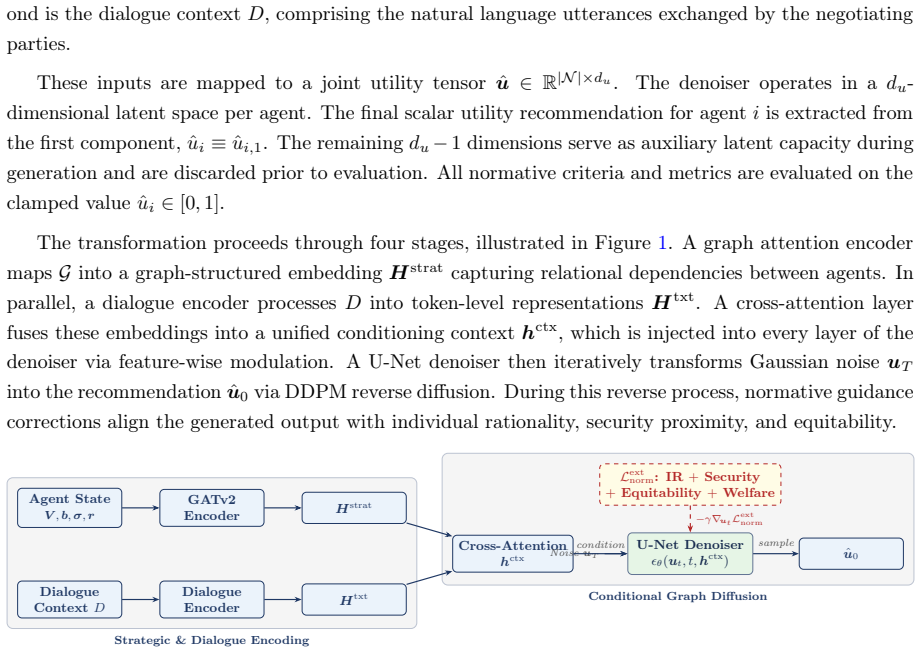
Traditional bilateral negotiation support systems search over discrete allocation spaces. This approach encounters structural infeasibility when no discrete outcome satisfies individual rationality. It fails to incorporate preference signals embedded in natural language dialogue. This study introduces the Conditional Graph Diffusion (CGD) framework to generate recommendations in a continuous bilateral utility space. A GATv2 encoder captures comparative bilateral preference structure through dynamic attention. A cross-attention mechanism fuses strategic embeddings with transformer-based dialogue representations into a unified conditioning context for a denoising diffusion probabilistic model. An analytically derived normative guidance gradient applies at inference time. It injects per-step monotonic corrections at each reverse diffusion step, steering generation toward individual rationality, security proximity, and equitability without retraining. Evaluation across synthetic, CaSiNo, and Deal or No Deal corpora confirms accumulated corrections achieve an individual rationality rate of at least 0.997, a security gap of at most 0.009, and a symmetry gap within 0.15. Relative to the Nash Bargaining Solution, CGD reduces security gaps by up to 70-fold at a maximum welfare cost of 3%. An ablation study demonstrates naive constraint minimization without a learned generative prior fails normative compliance across heterogeneous corpora. A controlled misrepresentation experiment establishes the architectural capacity of cross-attention fusion to exploit dialogue signals. An inference-time welfare guidance mechanism decouples normative compliance from welfare maximization, recovering Pareto efficiency on CaSiNo without retraining while preserving individual rationality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Conditional Graph Diffusion (CGD) framework to generate bilateral negotiation recommendations in continuous utility space. It employs a GATv2 encoder to capture comparative preferences, cross-attention to fuse dialogue representations with strategic embeddings, and a DDPM whose reverse process is steered at inference time by an analytically derived normative guidance gradient. This gradient injects monotonic corrections to enforce individual rationality, security proximity, and equitability without model retraining. Experiments across synthetic, CaSiNo, and Deal or No Deal corpora report IR rates ≥0.997, security gaps ≤0.009, symmetry gaps ≤0.15, up to 70-fold security-gap reduction versus the Nash Bargaining Solution at ≤3% welfare cost, plus ablations showing the learned prior is necessary and a controlled misrepresentation test of dialogue fusion.
Significance. If the central claims hold, the work offers a principled way to overcome discrete infeasibility in negotiation support while incorporating natural-language preference signals. The inference-time guidance mechanism that decouples normative compliance from welfare maximization, together with the ablation evidence that naive constraint minimization fails across corpora, constitutes a substantive advance. The reported quantitative improvements and the capacity to recover Pareto efficiency on CaSiNo without retraining would be of clear interest to both the negotiation-support and generative-modeling communities.
major comments (2)
- [Method (guidance gradient)] Method section (guidance gradient): The abstract asserts that the normative guidance gradient is analytically derived and supplies per-step monotonic corrections, yet no explicit equations, derivation steps, or proof of monotonicity for the three normative objectives are supplied. This derivation is load-bearing for the claim that guidance can be applied at inference without retraining or introducing new parameters.
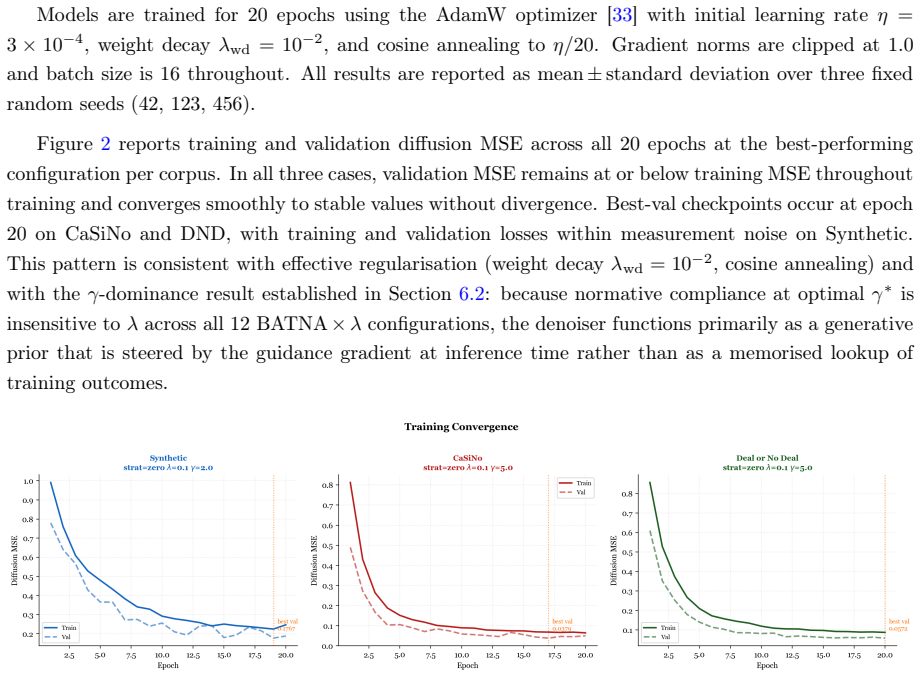
- [Experiments] Experiments section: The reported metrics (IR rate ≥0.997, 70-fold security-gap reduction, etc.) are presented as direct outcomes of accumulated corrections, but the manuscript provides no details on the number of diffusion steps, sampling procedure, statistical significance testing, or exact protocol for applying the guidance across the three heterogeneous corpora. These omissions prevent verification that the quantitative claims are free of post-hoc selection or implementation-specific artifacts.
minor comments (1)
- [Abstract] Abstract: The phrase 'symmetry gap within 0.15' should be accompanied by the precise definition of the symmetry gap and its units so that readers can interpret the bound without consulting later sections.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Method (guidance gradient)] Method section (guidance gradient): The abstract asserts that the normative guidance gradient is analytically derived and supplies per-step monotonic corrections, yet no explicit equations, derivation steps, or proof of monotonicity for the three normative objectives are supplied. This derivation is load-bearing for the claim that guidance can be applied at inference without retraining or introducing new parameters.
Authors: We agree that the explicit derivation, equations, and monotonicity proof are necessary to support the central claim. The current manuscript states that the gradient is analytically derived but does not include the detailed steps or proofs in the method section. In revision we will insert the full derivation of the per-step guidance gradients for individual rationality, security proximity, and equitability, together with the monotonicity argument, so that the inference-time mechanism can be verified without retraining. revision: yes
-
Referee: [Experiments] Experiments section: The reported metrics (IR rate ≥0.997, 70-fold security-gap reduction, etc.) are presented as direct outcomes of accumulated corrections, but the manuscript provides no details on the number of diffusion steps, sampling procedure, statistical significance testing, or exact protocol for applying the guidance across the three heterogeneous corpora. These omissions prevent verification that the quantitative claims are free of post-hoc selection or implementation-specific artifacts.
Authors: We acknowledge that the experimental protocol details are missing and that their absence hinders independent verification. The manuscript reports aggregate metrics but omits the diffusion step count, sampling procedure, significance testing, and the precise guidance application protocol used across corpora. In revision we will add a dedicated experimental protocol subsection specifying the number of diffusion steps, the DDPM sampling procedure with guidance, the statistical tests performed, and the uniform application protocol across the synthetic, CaSiNo, and Deal or No Deal datasets. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper claims an analytically derived normative guidance gradient that is applied at inference time to steer the diffusion process toward individual rationality, security, and equitability without retraining. This is presented as independent of the training process. Performance metrics (IR rate, security gap, symmetry gap) are reported as outcomes of empirical evaluation on synthetic, CaSiNo, and Deal or No Deal corpora. The ablation study demonstrates the role of the learned generative prior but does not reduce the guidance mechanism or results to a fit or self-citation by construction. No equations, self-citations, or renamings are quoted that would make any prediction equivalent to its inputs. The central claims rest on the analytical derivation and external benchmarks rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion probabilistic models can be effectively conditioned on fused graph and text embeddings for generation tasks.
- ad hoc to paper An analytically derived gradient can enforce normative properties like individual rationality at inference time.
invented entities (1)
-
Conditional Graph Diffusion (CGD) framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
T. Baarslag, M. J. C. Hendrikx, K. V. Hindriks, C. M. Jonker, Learning about the opponent in auto- mated bilateral negotiation: a comprehensive survey of opponent modeling techniques, Autonomous Agents and Multi-Agent Systems 30 (5) (2016) 849–898.doi:10.1007/s10458-015-9309-1
-
[2]
J. F. Nash, The bargaining problem, Econometrica 18 (2) (1950) 155–162.doi:10.2307/1907266
-
[3]
In: Palmer, M., Hwa, R., Riedel, S
M. Lewis, D. Yarats, Y. Dauphin, D. Parikh, D. Batra, Deal or no deal? end-to-end learning of negotiation dialogues, in: M. Palmer, R. Hwa, S. Riedel (Eds.), Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Copenhagen, Denmark, 2017, pp. 2443–2453.doi:10.18653/v1/D17-1259. U...
-
[4]
K. Chawla, J. Ramirez, R. Clever, G. Lucas, J. May, J. Gratch, Casino: A corpus of campsite negotiation dialogues for automatic negotiation systems, in: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2021, pp. 3167–3185.doi:10.18653/v1/2021.naacl-main.254
-
[5]
Chevaleyre, P
Y. Chevaleyre, P. E. Dunne, U. Endriss, J. Lang, M. Lemaître, N. Maudet, J. Padget, S. Phelps, J. A. Rodríguez-Aguilar, P. Sousa, Issues in multiagent resource allocation, Informatica 30 (1) (2006). URLhttps://www.informatica.si/index.php/informatica/article/view/70
2006
-
[6]
B. M. Renting, T. M. Moerland, H. H. Hoos, C. M. Jonker, Towards general negotiation strategies with end-to-end reinforcement learning (2024).arXiv:2406.15096. URLhttps://arxiv.org/abs/2406.15096
arXiv 2024
-
[7]
Bianchi, P
F. Bianchi, P. J. Chia, M. Yuksekgonul, J. Tagliabue, D. Jurafsky, J. Zou, How well can llms nego- tiate? negotiationarena platform and analysis, in: Proceedings of the 41st International Conference on Machine Learning, ICML’24, JMLR.org, 2024
2024
-
[8]
D. Kwon, J. Hae, E. Clift, D. Shamsoddini, J. Gratch, G. Lucas, ASTRA: A negotiation agent with adaptive and strategic reasoning via tool-integrated action for dynamic offer optimization, in: C. Christodoulopoulos, T. Chakraborty, C. Rose, V. Peng (Eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Association f...
-
[9]
Janner, Y
M. Janner, Y. Du, J. Tenenbaum, S. Levine, Planning with diffusion for flexible behavior synthesis, in: International Conference on Machine Learning, PMLR, 2022, pp. 9902–9915
2022
-
[10]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y. Du, B. Burchfiel, S. Song, Diffusion policy: Visuomotor policy learning via action diffusion, The International Journal of Robotics Research 44 (10-11) (2025) 1684–1704.doi:10.1177/02783649241273668. URLhttps://journals.sagepub.com/doi/full/10.1177/02783649241273668
-
[11]
J. Ho, A. Jain, P. Abbeel, Denoising diffusion probabilistic models, in: Advances in Neural Informa- tion Processing Systems (NeurIPS) 33, 2020, pp. 6840–6851.doi:10.48550/arXiv.2006.11239
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2006.11239 2020
-
[12]
J. Ho, T. Salimans, Classifier-free diffusion guidance (2022).arXiv:2207.12598. URLhttps://arxiv.org/abs/2207.12598
Pith/arXiv arXiv 2022
-
[13]
C. M. Bishop, Pattern Recognition and Machine Learning, Springer, 2006, see Dirichlet distribution in Section 2.2
2006
-
[14]
Bagga, N
P. Bagga, N. Paoletti, K. Stathis, Deep learnable strategy templates for multi-issue bilateral negoti- ation, in: Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, AAMAS ’22, International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, 2022, p. 1533–1535
2022
-
[15]
X. Zhang, Y. Xu, Y. Dou, Autonomous negotiation via deep reinforcement learning agents: Efficiency, fairness, and mechanisms, SSRN Electronic JournalAvailable at SSRN: https://ssrn.com/abstract=6007494 (February 2026).doi:10.2139/ssrn.6007494. URLhttps://ssrn.com/abstract=6007494
-
[16]
K.Nakamura, Collectiveorindividualrationalityinthenashbargainingsolution: efficiency-freechar- acterizations, Social Choice and Welfare 62 (2024) 629–642.doi:10.1007/s00355-024-01513-6
-
[17]
Y. Zeng, X. Yang, L. Chen, C. C. Ferrer, M. Jin, M. I. Jordan, R. Jia, Fairness-aware meta-learning via nash bargaining, Advances in Neural Information Processing Systems 37 (2024) 83235–83267
2024
-
[18]
J. Wu, Y. Sun, An automated negotiation model based on agents’ attribute preference with emo- tional deception, Expert Systems with Applications 278 (2025) 127448.doi:10.1016/j.eswa.2025. 127448
-
[19]
K. Chawla, I. Wu, Y. Rong, G. Lucas, J. Gratch, Be selfish, but wisely: Investigating the impact of agent personality in mixed-motive human-agent interactions, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), Singapore, 2023, pp. 13078–13092. doi:10.18653/v1/2023.emnlp-main.808
-
[20]
Bhattacharya, G
A. Bhattacharya, G. Svedas, A. Lyskov, M. Strasser, L. Barberis Canonico, Evaluating negotiation capabilities of large language models: From ultimatum games to nash bargaining, in: Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Vol. 69, SAGE Publications, 2025, pp. 1881–1886
2025
-
[21]
Y. Fu, X. Liu, B. Yu, Pd-gatv2: positive difference second generation graph attention network based on multi-granularity in information systems for classification, Applied Intelligence 54 (2024) 5081–5096.doi:10.1007/s10489-024-05432-y
-
[22]
P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, Y. Bengio, Graph attention networks, in: International Conference on Learning Representations (ICLR), 2018.doi:10.48550/arXiv.1710. 10903. 35
-
[23]
How Attentive are Graph Attention Networks?
S. Brody, U. Alon, E. Yahav, How attentive are graph attention networks?, in: International Con- ference on Learning Representations, 2022.doi:10.48550/arXiv.2105.14491
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2105.14491 2022
-
[24]
Faber, R
L. Faber, R. Wattenhofer, Gwac: Gnns with asynchronous communication, in: S. Villar, B. Cham- berlain (Eds.), Proceedings of the Second Learning on Graphs Conference, Vol. 231 of Proceedings of Machine Learning Research, PMLR, 2024, pp. 8:1–8:20. URLhttps://proceedings.mlr.press/v231/faber24a.html
2024
-
[25]
Li, Efficient planning with latent diffusion, arXiv preprint arXiv:2310.00311 (2023)
W. Li, Efficient planning with latent diffusion, arXiv preprint arXiv:2310.00311 (2023)
arXiv 2023
-
[26]
Z. Zhu, H. Zhao, H. He, Y. Zhong, S. Zhang, H. Guo, T. Chen, W. Zhang, Diffusion models for reinforcement learning: A survey, arXiv preprint arXiv:2311.01223 (2023)
arXiv 2023
-
[27]
Zhang, L
J. Zhang, L. Zhao, A. Papachristodoulou, J. Umenberger, Constrained diffusers for safe planning and control, in: Advances in Neural Information Processing Systems (NeurIPS), 2025, poster. URLhttps://neurips.cc/virtual/2025/loc/san-diego/poster/115579
2025
-
[28]
URLhttps://arxiv.org/abs/2211.15657
A.Ajay, Y.Du, A.Gupta, J.Tenenbaum, T.Jaakkola, P.Agrawal, Isconditionalgenerativemodeling all you need for decision-making? (2023).arXiv:2211.15657. URLhttps://arxiv.org/abs/2211.15657
Pith/arXiv arXiv 2023
-
[29]
C. Chen, F. Deng, K. Kawaguchi, C. Gulcehre, S. Ahn, Simple hierarchical planning with diffusion (2024).arXiv:2401.02644. URLhttps://arxiv.org/abs/2401.02644
arXiv 2024
-
[30]
A. Mouri Zadeh Khaki, A. Choi, Evaluating fairness in llm negotiator agents via economic games using multi-agent systems, Mathematics 14 (3) (2026) 458.doi:10.3390/math14030458. URLhttps://doi.org/10.3390/math14030458
-
[31]
Wang, Game-theoretic understandings of multi-agent systems with multiple objectives (2025)
Y. Wang, Game-theoretic understandings of multi-agent systems with multiple objectives (2025). arXiv:2509.23026. URLhttps://arxiv.org/abs/2509.23026
arXiv 2025
-
[32]
FiLM: Visual Reasoning with a General Conditioning Layer
E. Perez, F. Strub, H. de Vries, V. Dumoulin, A. Courville, Film: Visual reasoning with a general conditioning layer, in: Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI), 2018.doi:10.48550/arXiv.1709.07871
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1709.07871 2018
-
[33]
Decoupled Weight Decay Regularization
I. Loshchilov, F. Hutter, Decoupled weight decay regularization, in: International Conference on Learning Representations (ICLR) 2019, 2019.doi:10.48550/arXiv.1711.05101
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101 2019
-
[34]
T. N. Kipf, M. Welling, Semi-supervised classification with graph convolutional networks (2017). arXiv:1609.02907. URLhttps://arxiv.org/abs/1609.02907
Pith/arXiv arXiv 2017
-
[35]
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, V. Stoyanov, Roberta: A robustly optimized bert pretraining approach (2019).arXiv:1907.11692. URLhttps://arxiv.org/abs/1907.11692 36
Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.