Chroma Clues: Leveraging Color Statistics to Detect Synthetic Images
Pith reviewed 2026-06-28 15:36 UTC · model grok-4.3
The pith
Color transformations expose mismatches in chrominance statistics that flag synthetic images from multiple generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
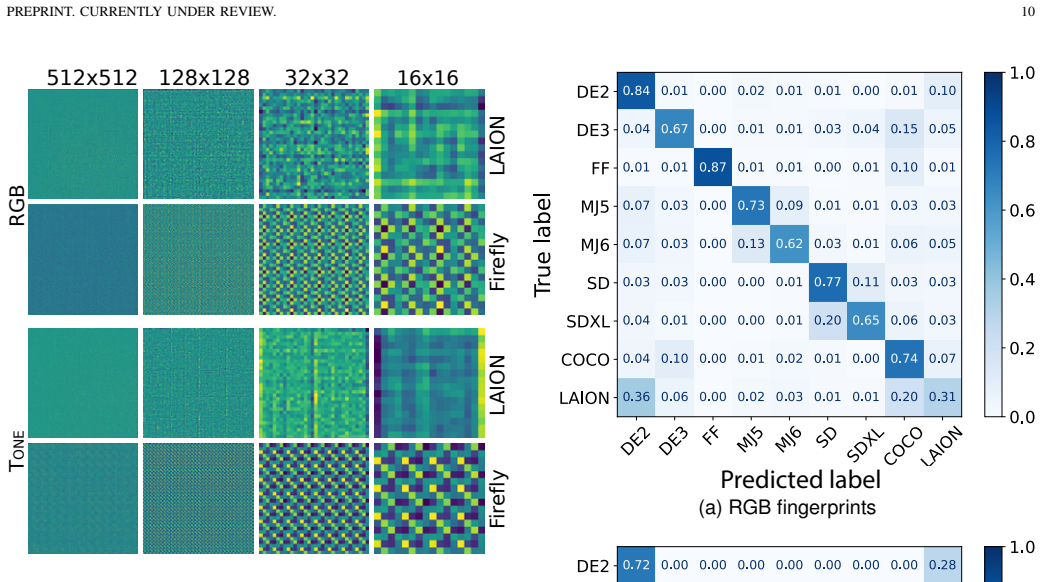
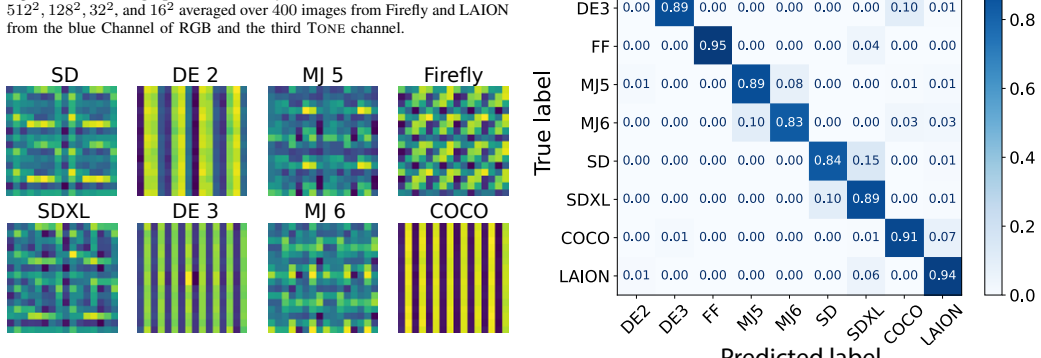
The authors establish that the LPIPS loss used to train image generators is less sensitive to chrominance than to luminance, creating exploitable statistical discrepancies in the colors of synthetic images. They introduce six hand-crafted color transformations and a method to learn a task-optimized color transform that statistically expose these discrepancies. The transformations support three uses: color-sensitive features for a simple classifier that achieves 93.27 percent generalization accuracy and robustness to six post-processing types, characteristic visual noise patterns for intuitive human evaluation, and enhanced color patterns that improve multiclass attribution of the source gene
What carries the argument
Hand-crafted and task-optimized color transformations that amplify chrominance discrepancies between natural and synthetic images for feature extraction, visual inspection, and attribution.
If this is right
- Color features support a simple interpretable classifier that reaches 93.27 percent average generalization accuracy across generators.
- Detection performance holds after six common post-processing operations.
- The transforms create visible noise patterns that distinguish natural from synthetic image regions.
- Enhanced color patterns improve multiclass attribution of which generator created a given image.
Where Pith is reading between the lines
- The method could be combined with texture- or frequency-based detectors to create an ensemble that covers multiple independent artifacts.
- If future generators adopt color-balanced training losses, the fixed transforms may need periodic re-optimization to remain effective.
- The visual noise patterns might serve as a lightweight triage tool for human analysts before automated classification is applied.
Load-bearing premise
The perceptual loss used to train current generators weights color differences less heavily than brightness differences, leaving detectable gaps in color statistics.
What would settle it
A generator trained with a loss that treats chrominance and luminance equally would produce images whose color statistics match natural images under the proposed transformations, dropping classifier accuracy to near chance.
Figures



read the original abstract
The evolution and dissemination of AI-synthesized images is occurring at an unprecedented rate. Image generators are making rapid progress in their goal of perfectly imitating natural images, which also challenges image forensics. In this work, we exploit an underexplored cue in current generative models, namely their weakness to imitate color statistics of natural images. We first show that the LPIPS loss used for training image generators is less sensitive to chrominance than to luminance, which may lead to statistical discrepancies in the colors of synthetic images. Building on this observation, we then introduce six hand-crafted color transformations and a method to learn a task-optimized color transform to statistically expose generated images. These transformations can be used in various ways. First, we define color-sensitive features at pixel-level or patch-level. A simple, interpretable classifier achieves with these features an average generalization accuracy of 93.27% and strong robustness against six types of post-processing. Second, we demonstrate that the transformations exhibit characteristic visual noise patterns in natural and synthetic image areas, which enables an intuitive visual image evaluation. Third, we demonstrate that the transforms can enhance color patterns in generated images for improved multiclass attribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that current generative models exhibit detectable discrepancies in color statistics because the LPIPS loss used in their training is less sensitive to chrominance than to luminance. The authors introduce six hand-crafted color transformations plus a learned task-optimized transform, extract pixel- or patch-level color-sensitive features from them, and show that a simple interpretable classifier achieves 93.27% average generalization accuracy while remaining robust to six post-processing operations. The same transforms are also shown to produce characteristic visual noise patterns useful for intuitive evaluation and to enhance color cues for multiclass generator attribution.
Significance. If the reported generalization accuracy and robustness hold under realistic distribution shifts, the work supplies a lightweight, interpretable, and complementary forensic cue based on color statistics. The empirical feature-engineering approach avoids circularity and offers practical advantages for both automated detection and human visual inspection.
major comments (3)
- [Abstract / motivation] Abstract and motivation section: the central premise that 'the LPIPS loss used for training image generators is less sensitive to chrominance than to luminance' is asserted without any quantitative measurement (e.g., gradient magnitudes with respect to luminance versus chrominance channels evaluated on actual generator training runs or ablations). This sensitivity difference is load-bearing for the design of all six hand-crafted transforms and the learned transform; absent such evidence, the 93.27% accuracy could be explained by incidental capture of non-color artifacts.
- [Experimental results] Results section reporting the 93.27% figure: the generalization accuracy is presented as an average across generators, yet the manuscript supplies no details on the precise cross-generator protocol, the number and diversity of generators, test-set sizes, or any measure of statistical variability (standard deviation, confidence intervals, or significance tests). Without these, it is impossible to evaluate whether the number supports the claim of strong generalization and robustness.
- [Method / color transforms] § on color-transform construction: all transforms are motivated by the LPIPS chrominance-insensitivity hypothesis, but no ablation is reported that isolates the contribution of color statistics from other low-level cues (e.g., by comparing performance when the same transforms are applied after luminance-only normalization). This leaves open whether the reported accuracy truly stems from the claimed color cue.
minor comments (2)
- [Method] The six hand-crafted transforms are described at a high level; explicit mathematical definitions or pseudocode for each would improve reproducibility and allow readers to verify the claimed color-statistic focus.
- [Figures] Figure captions and axis labels for the visual noise-pattern examples could be expanded to indicate the exact post-processing parameters used in the robustness experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas where additional evidence and clarity would strengthen the manuscript. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / motivation] Abstract and motivation section: the central premise that 'the LPIPS loss used for training image generators is less sensitive to chrominance than to luminance' is asserted without any quantitative measurement (e.g., gradient magnitudes with respect to luminance versus chrominance channels evaluated on actual generator training runs or ablations). This sensitivity difference is load-bearing for the design of all six hand-crafted transforms and the learned transform; absent such evidence, the 93.27% accuracy could be explained by incidental capture of non-color artifacts.
Authors: We agree that a quantitative demonstration of LPIPS chrominance insensitivity would better support the motivation. The manuscript references established properties of LPIPS but does not include direct measurements such as gradient analysis. We will add a new subsection with quantitative evidence (e.g., gradient magnitude comparisons on representative generator training data) to justify the premise and reduce the risk of alternative explanations. revision: yes
-
Referee: [Experimental results] Results section reporting the 93.27% figure: the generalization accuracy is presented as an average across generators, yet the manuscript supplies no details on the precise cross-generator protocol, the number and diversity of generators, test-set sizes, or any measure of statistical variability (standard deviation, confidence intervals, or significance tests). Without these, it is impossible to evaluate whether the number supports the claim of strong generalization and robustness.
Authors: The manuscript describes the cross-generator evaluation protocol and the set of generators used, but we acknowledge that explicit reporting of test-set sizes, statistical variability, and significance tests is missing. We will expand the results section to include these details, along with standard deviations and confidence intervals computed over multiple runs, to allow proper assessment of the reported accuracy. revision: yes
-
Referee: [Method / color transforms] § on color-transform construction: all transforms are motivated by the LPIPS chrominance-insensitivity hypothesis, but no ablation is reported that isolates the contribution of color statistics from other low-level cues (e.g., by comparing performance when the same transforms are applied after luminance-only normalization). This leaves open whether the reported accuracy truly stems from the claimed color cue.
Authors: We concur that an ablation isolating color statistics is necessary to confirm the source of the performance. No such experiment appears in the current manuscript. We will add an ablation study comparing performance with and without luminance normalization prior to applying the transforms, thereby directly testing whether the accuracy derives from the color cue as claimed. revision: yes
Circularity Check
No circularity: empirical feature engineering with measured generalization accuracy
full rationale
The paper's chain is observational and empirical. It states an assumption about LPIPS sensitivity to chrominance (abstract), designs six hand-crafted transforms plus one learned transform to exploit resulting color discrepancies, extracts pixel- or patch-level features, and reports measured classifier accuracy of 93.27% on held-out data with post-processing robustness. No equations, self-citations, or fitted parameters are presented that reduce the accuracy claim to a quantity defined by construction from the same inputs. The performance number is an external evaluation result, not a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LPIPS loss is less sensitive to chrominance than to luminance
Reference graph
Works this paper leans on
-
[1]
Midjourney Inc., Midjourney, 2025, https://www.midjourney.com/home
2025
-
[2]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P . Esser, and B. Ommer, Stable Diffusion, 2024, https://github.com/CompVis/stable-diffusion
2024
-
[3]
Adobe, Firefly, 2025, https://www.adobe.com/sensei/generative-ai/ firefly.html
2025
-
[4]
Farid, Lighting (In)consistency of Paint by Text , 2022, arXiv: 2207.13744
H. Farid, Lighting (In)consistency of Paint by Text , 2022, arXiv: 2207.13744
-
[5]
Do GANs Leave Artificial Fingerprints?
F. Marra, D. Gragnaniello, L. V erdoliva, and G. Poggi, “Do GANs Leave Artificial Fingerprints?” in IEEE Conference on Multimedia Information Processing and Retrieval , 2019
2019
-
[6]
Watch Y our Up-Convolution: CNN Based Generative Deep Neural Networks Are Failing to Reproduce Spectral Distributions,
R. Durall, M. Keuper, and J. Keuper, “Watch Y our Up-Convolution: CNN Based Generative Deep Neural Networks Are Failing to Reproduce Spectral Distributions,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2020
2020
-
[7]
Detecting and Simulating Artifacts in GAN Fake Images,
X. Zhang, S. Karaman, and S.-F. Chang, “Detecting and Simulating Artifacts in GAN Fake Images,” in IEEE International Workshop on Information F orensics and Security , 2019
2019
-
[8]
Detecting Deepfakes in Alternative Color Spaces to Withstand Unseen Corruptions,
K. Zeng, X. Y u, B. Liu, Y . Guan, and Y . Hu, “Detecting Deepfakes in Alternative Color Spaces to Withstand Unseen Corruptions,” in IEEE International Workshop on Biometrics and F orensics , 2023
2023
-
[9]
Identification of Deep Network Generated Images Using Disparities in Color Components,
H. Li, B. Li, S. Tan, and J. Huang, “Identification of Deep Network Generated Images Using Disparities in Color Components,” Signal Processing, vol. 174, September 2020, 107616
2020
-
[10]
AI-Generated Face Image Identification with Different Color Space Channel Combinations,
S. Mo, P . Lu, and X. Liu, “AI-Generated Face Image Identification with Different Color Space Channel Combinations,” Sensors, vol. 22, no. 21, October 2022, 8228
2022
-
[11]
CSC-Net: Cross-Color Spatial Co-occurrence Matrix Network for De- tecting Synthesized Fake Images,
T. Qiao, Y . Chen, X. Zhou, R. Shi, H. Shao, K. Shen, and X. Luo, “CSC-Net: Cross-Color Spatial Co-occurrence Matrix Network for De- tecting Synthesized Fake Images,” IEEE Transactions on Cognitive and Developmental Systems , vol. 16, no. 1, pp. 369–379, February 2023
2023
-
[12]
Exposing Deepfake Frames through Spectral Analysis of Color Channels in Frequency Domain,
M. Amin, Y . Hu, H. She, J. Li, Y . Guan, and M. Amin, “Exposing Deepfake Frames through Spectral Analysis of Color Channels in Frequency Domain,” in IEEE International Workshop on Biometrics and F orensics, 2023
2023
-
[13]
Detection of Fake Images via the Ensemble of Deep Representations from Multi Color Spaces,
P . He, H. Li, and H. Wang, “Detection of Fake Images via the Ensemble of Deep Representations from Multi Color Spaces,” in IEEE International Conference on Image Processing , 2019
2019
-
[14]
A Robust GAN- Generated Face Detection Method Based on Dual-Color Spaces and an Improved Xception,
B. Chen, X. Liu, Y . Zheng, G. Zhao, and Y .-Q. Shi, “A Robust GAN- Generated Face Detection Method Based on Dual-Color Spaces and an Improved Xception,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 6, pp. 3527–3538, June 2021
2021
-
[15]
Did Y ou Note My Palette? Unveiling Synthetic Images Through Color Statistics,
L. Uhlenbrock, D. Cozzolino, D. Moussa, L. V erdoliva, and C. Riess, “Did Y ou Note My Palette? Unveiling Synthetic Images Through Color Statistics,” in ACM Workshop on Information Hiding and Multimedia Security, 2024
2024
-
[16]
Exploiting Visual Artifacts to Expose Deepfakes and Face Manipulations,
F. Matern, C. Riess, and M. Stamminger, “Exploiting Visual Artifacts to Expose Deepfakes and Face Manipulations,” in IEEE Winter Appli- cations of Computer Vision Workshops , 2019
2019
-
[17]
ClueCatcher: Catching Domain- Wise Independent Clues for Deepfake Detection,
E.-G. Lee, I. Lee, and S.-B. Y oo, “ClueCatcher: Catching Domain- Wise Independent Clues for Deepfake Detection,” Mathematics, vol. 11, no. 18, September 2023, 3952
2023
-
[18]
Perceptual Artifacts Localization for Inpainting,
L. Zhang, Y . Zhou, C. Barnes, S. Amirghodsi, Z. Lin, E. Shechtman, and J. Shi, “Perceptual Artifacts Localization for Inpainting,” in European Conference on Computer Vision , 2022
2022
-
[19]
Farid, Perspective (In)consistency of Paint by Text , 2022, arXiv: 2206.14617
H. Farid, Perspective (In)consistency of Paint by Text , 2022, arXiv: 2206.14617
-
[20]
Shadows Don’t Lie and Lines Can’t Bend! Generative Models don’t know Projective Geometry... for Now,
A. Sarkar, H. Mai, A. Mahapatra, S. Lazebnik, D. A. Forsyth, and A. Bhattad, “Shadows Don’t Lie and Lines Can’t Bend! Generative Models don’t know Projective Geometry... for Now,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024
2024
- [21]
-
[22]
Intriguing Properties of Synthetic Images: From Generative Adversarial Networks to Diffusion Models,
R. Corvi, D. Cozzolino, G. Poggi, K. Nagano, and L. V erdoliva, “Intriguing Properties of Synthetic Images: From Generative Adversarial Networks to Diffusion Models,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2023
2023
-
[23]
Misleading Deep- Fake Detection with GAN Fingerprints,
V . Wesselkamp, K. Rieck, D. Arp, and E. Quiring, “Misleading Deep- Fake Detection with GAN Fingerprints,” in IEEE Security and Privacy Workshops, 2022
2022
-
[24]
Rethink- ing the Up-Sampling Operations in CNN-Based Generative Network for Generalizable Deepfake Detection,
C. Tan, H. Liu, Y . Zhao, S. Wei, G. Gu, P . Liu, and Y . Wei, “Rethink- ing the Up-Sampling Operations in CNN-Based Generative Network for Generalizable Deepfake Detection,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024
2024
-
[25]
Improving Synthetic Image Detection Towards Generalization: An Image Transformation Perspective,
O. Li, J. Cai, Y . Hao, X. Jiang, Y . Hu, and F. Feng, “Improving Synthetic Image Detection Towards Generalization: An Image Transformation Perspective,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining , 2025
2025
-
[26]
Fighting Deepfake by Exposing the Convolutional Traces on Images,
L. Guarnera, O. Giudice, and S. Battiato, “Fighting Deepfake by Exposing the Convolutional Traces on Images,” IEEE Access , vol. 8, pp. 165 085–165 098, 2020
2020
-
[27]
Simple detection of ai-generated images based on noise correlation,
A. Mallet, A. Méreur, M. Kuribayashi, R. Cogranne, and P . Bas, “Simple detection of ai-generated images based on noise correlation,” in International conference on Advanced Machine Learning and Data Science, 2025
2025
-
[28]
CNN- Generated Images Are Surprisingly Easy to Spot... for Now,
S.-Y . Wang, O. Wang, R. Zhang, A. Owens, and A. Efros, “CNN- Generated Images Are Surprisingly Easy to Spot... for Now,” in PREPRINT. CURRENTL Y UNDER REVIEW. 13 IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2020
2020
-
[29]
Are GAN Generated Images Easy to Detect? A Critical Analysis of the State-of-the-Art,
D. Gragnaniello, D. Cozzolino, F. Marra, G. Poggi, and L. V erdoliva, “Are GAN Generated Images Easy to Detect? A Critical Analysis of the State-of-the-Art,” in IEEE International Conference on Multimedia and Expo , 2021
2021
-
[30]
Detecting Generated Images by Real Images,
B. Liu, F. Y ang, X. Bi, B. Xiao, W. Li, and X. Gao, “Detecting Generated Images by Real Images,” in European Conference on Computer Vision , 2022
2022
-
[31]
Learning on Gradi- ents: Generalized Artifacts Representation for GAN-Generated Images Detection,
C. Tan, Y . Zhao, S. Wei, G. Gu, and Y . Wei, “Learning on Gradi- ents: Generalized Artifacts Representation for GAN-Generated Images Detection,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[32]
On the Detection of Synthetic Images Generated by Diffusion Models,
R. Corvi, D. Cozzolino, G. Zingarini, G. Poggi, K. Nagano, and L. V erdoliva, “On the Detection of Synthetic Images Generated by Diffusion Models,” in IEEE International Conference on Acoustics, Speech and Signal Processing , 2023
2023
-
[33]
DIRE for diffusion-generated image detection,
Z. Wang, J. Bao, W. Zhou, W. Wang, H. Hu, H. Chen, and H. Li, “DIRE for diffusion-generated image detection,” in IEEE/CVF International Conference on Computer Vision , 2023
2023
-
[34]
CNN Detection of GAN-Generated Face Images Based on Cross-Band Co-Occurrences Analysis,
M. Barni, K. Kallas, E. Nowroozi, and B. Tondi, “CNN Detection of GAN-Generated Face Images Based on Cross-Band Co-Occurrences Analysis,” in IEEE International Workshop on Information F orensics and Security , 2020
2020
-
[35]
DE-FAKE: Detection and Attribu- tion of Fake Images Generated by Text-to-Image Generation Models,
Z. Sha, Z. Li, N. Y u, and Y . Zhang, “DE-FAKE: Detection and Attribu- tion of Fake Images Generated by Text-to-Image Generation Models,” in ACM SIGSAC Conference on Computer and Communications Security , 2023
2023
-
[36]
Junhao Zhuang, Yanhong Zeng, Wenran Liu, Chun Yuan, and Kai Chen
N. Zhong, Y . Xu, S. Li, Z. Qian, and X. Zhang, Patchcraft: Exploring Texture Patch for Efficient AI-Generated Image Detection , 2023, arXiv: 2311.12397
- [37]
-
[38]
Learning Transferable Visual Models from Natural Language Supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P . Mishkin, J. Clark et al. , “Learning Transferable Visual Models from Natural Language Supervision,” in International Conference on Machine Learning , 2021
2021
-
[39]
Towards Universal Fake Image Detectors that Generalize Across Generative Models,
U. Ojha, Y . Li, and Y . Lee, “Towards Universal Fake Image Detectors that Generalize Across Generative Models,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2023
2023
-
[40]
Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images,
L. Lin, I. Amerini, X. Wang, S. Hu et al., “Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images,” in IEEE International Conference on Advanced Video and Signal Based Surveillance , 2024
2024
-
[41]
CLIPping the Deception: Adapting Vision-Language Models for Universal Deepfake Detection,
S. A. Khan and D.-T. Dang-Nguyen, “CLIPping the Deception: Adapting Vision-Language Models for Universal Deepfake Detection,” in ACM International Conference on Multimedia Retrieval , 2024
2024
-
[42]
Raising the Bar of AI-generated Image Detection with CLIP,
D. Cozzolino, G. Poggi, R. Corvi, M. Nießner, and L. V erdoliva, “Raising the Bar of AI-generated Image Detection with CLIP,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024
2024
- [43]
-
[44]
A. Moskowitz, T. Gaona, and J. Peterson, Detecting AI-Generated Images via CLIP , 2024, arXiv: 2404.08788
- [45]
-
[46]
DeCLIP: Decoding CLIP Repre- sentations for Deepfake Localization,
S. Smeu, E. Oneata, and D. Oneata, “DeCLIP: Decoding CLIP Repre- sentations for Deepfake Localization,” in IEEE/CVF Winter Conference on Applications of Computer Vision, , 2025
2025
-
[47]
OpenAI, DALL-E 3 , 2024, https://openai.com/dall-e-3
2024
-
[48]
Detecting GAN-Generated Imagery Using Saturation Cues,
S. McCloskey and M. Albright, “Detecting GAN-Generated Imagery Using Saturation Cues,” in IEEE International Conference on Image Processing, 2019
2019
-
[49]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric,
R. Zhang, P . Isola, A. A. Efros, E. Shechtman, and O. Wang, “The Unreasonable Effectiveness of Deep Features as a Perceptual Metric,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2018
2018
-
[50]
Super-Resolution with Deep Convolutional Sufficient Statistics
J. Bruna, P . Sprechmann, and Y . LeCun, Super-Resolution with Deep Convolutional Sufficient Statistics , 2015, arXiv: 1511.05666
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[51]
Generating Images with Perceptual Similarity Metrics Based on Deep Networks,
A. Dosovitskiy and T. Brox, “Generating Images with Perceptual Similarity Metrics Based on Deep Networks,” in Advances in Neural Information Processing Systems , 2016
2016
-
[52]
Perceptual Losses for Real- Time Style Transfer and Super-Resolution,
J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual Losses for Real- Time Style Transfer and Super-Resolution,” in European Conference on Computer Vision , 2016
2016
-
[53]
Rich Models for Steganalysis of Digital Images,
J. J. Fridrich and J. Kodovský, “Rich Models for Steganalysis of Digital Images,” IEEE Transactions on Information F orensics and Security , vol. 7, no. 3, pp. 868–882, 2012
2012
-
[54]
Rich Model for Steganalysis of Color Images,
M. Goljan, J. J. Fridrich, and R. Cogranne, “Rich Model for Steganalysis of Color Images,” in IEEE International Workshop on Information F orensics and Security, 2014, 2014
2014
-
[55]
Noiseprint: A CNN-Based Camera Model Fingerprint,
D. Cozzolino and L. V erdoliva, “Noiseprint: A CNN-Based Camera Model Fingerprint,” IEEE Transactions on Information F orensics and Security, vol. 15, pp. 144–159, 2019
2019
-
[56]
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification,
K. He, X. Zhang, S. Ren, and J. Sun, “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification,” in IEEE International Conference on Computer Vision , 2015
2015
-
[57]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Z. Y ang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, PyTorch: An Imperative Style, High- Performance Deep Learning Library , 2019, arXiv: 1912.01703
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[58]
A bias-free training paradigm for more general ai-generated image detection,
F. Guillaro, G. Zingarini, B. Usman, A. Sud, D. Cozzolino, and L. V erdo- liva, “A bias-free training paradigm for more general ai-generated image detection,” in Computer Vision and Pattern Recognition Conference , 2025
2025
-
[59]
TGIF: Text-Guided Inpainting Forgery Dataset,
H. Mareen, D. Karageorgiou, G. V . Wallendael, P . Lambert, and S. Pa- padopoulos, “TGIF: Text-Guided Inpainting Forgery Dataset,” in IEEE International Workshop on Information F orensics and Security , 2024
2024
-
[60]
A mathematical theory of communication,
C. E. Shannon, “A mathematical theory of communication,” The Bell System Technical Journal , vol. 27, no. 4, pp. 623–656, 1948
1948
-
[61]
Probabilistic Outputs for Support V ector Machines and Com- parisons to Regularized Likelihood Methods,
J. Platt, “Probabilistic Outputs for Support V ector Machines and Com- parisons to Regularized Likelihood Methods,” Advances in Large Margin Classifiers, vol. 10, pp. 61–74, June 1999
1999
-
[62]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rombach, “SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis,” in International Conference on Learning Representations , 2023
2023
-
[63]
Microsoft COCO: Common Objects in Context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P . Perona, D. Ramanan, P . Dollár, and C. Zitnick, “Microsoft COCO: Common Objects in Context,” in European Conference on Computer Vision , 2014
2014
-
[64]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
C. Schuhmann, R. V encu, R. Beaumont, R. Kaczmarczyk, C. Mullis, A. Katta, T. Coombes, J. Jitsev, and A. Komatsuzaki, Laion-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs , 2021, arXiv: 2111.02114
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[65]
Forensic Analysis of AI-Compression Traces in Spatial and Frequency Domain,
S. Bergmann, D. Moussa, F. Brand, A. Kaup, and C. Riess, “Forensic Analysis of AI-Compression Traces in Spatial and Frequency Domain,” Pattern Recognition Letters , vol. 180, pp. 41–47, April 2024
2024
- [66]
-
[67]
Synthbuster: Towards detection of diffusion model gener- ated images,
Q. Bammey, “Synthbuster: Towards detection of diffusion model gener- ated images,” IEEE Open Journal of Signal Processing , vol. 5, 2023
2023
-
[68]
Deep Image Fingerprint: Towards Low Budget Synthetic Image Detection and Model Lineage Analysis,
S. Sinitsa and O. Fried, “Deep Image Fingerprint: Towards Low Budget Synthetic Image Detection and Model Lineage Analysis,” in IEEE/CVF Winter Conference on Applications of Computer Vision , 2024
2024
-
[69]
Union, Regulation (EU) 2024/1689 of the European Parliament and of the Council , 2024, http://data.europa.eu/eli/reg/2024/1689/oj
E. Union, Regulation (EU) 2024/1689 of the European Parliament and of the Council , 2024, http://data.europa.eu/eli/reg/2024/1689/oj
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.