Dexterity-BEV: Aligning 3D World and Actions for Generalizable Robot Policies Learning
Pith reviewed 2026-06-28 14:40 UTC · model grok-4.3
The pith
Mapping pixel-wise 3D information and robot actions into a shared Bird's-Eye-View frame creates view-invariant inputs that support more generalizable manipulation policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
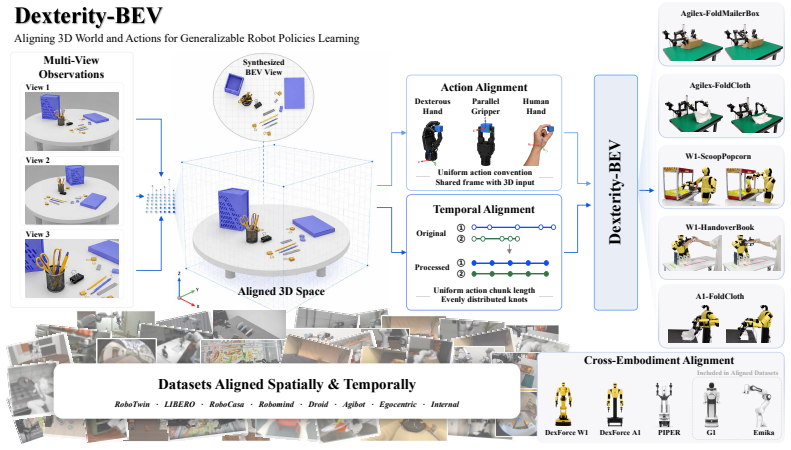
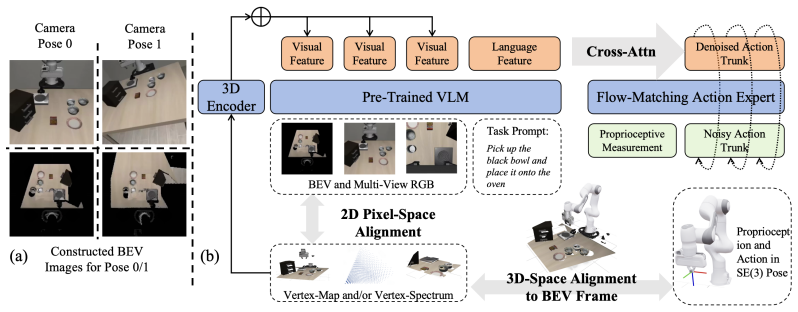
The authors claim that constructing BEV images from per-pixel 3D vertex information and aligning actions to the same canonical frame mitigates spatial-temporal misalignments, resulting in improved consistency and generalization for real-world robotic manipulation across diverse embodiments and camera setups.
What carries the argument
The canonical Bird's-Eye-View (BEV) frame, which serves as a shared coordinate system for both 3D visual inputs and robot actions to achieve view-invariance.
If this is right
- Training policies on BEV-aligned data reduces sensitivity to variations in camera pose.
- The temporal alignment scheme allows combining trajectories from different robots and human operators.
- Pretrained VLMs can be used with 3D awareness without losing their generalization benefits.
- The data processing pipeline supports scaling up training to larger datasets with proper alignments.
Where Pith is reading between the lines
- If successful, this method might allow policies to transfer more easily between simulated and real environments.
- The BEV construction could be applied to other perception tasks in robotics beyond manipulation.
- It suggests that many current 2D-based approaches could benefit from similar 3D-to-shared-frame lifts.
Load-bearing premise
Expressing per-pixel 3D information and robot actions into a shared canonical BEV frame will produce a view-invariant representation robust to camera pose variations and embodiment differences.
What would settle it
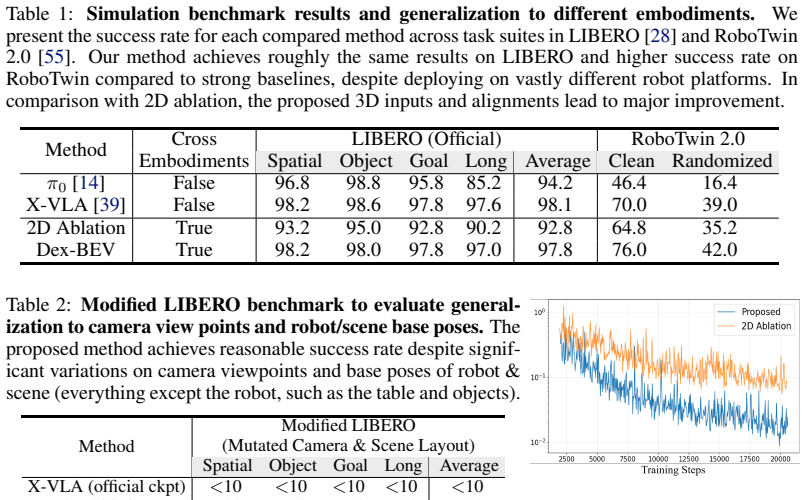
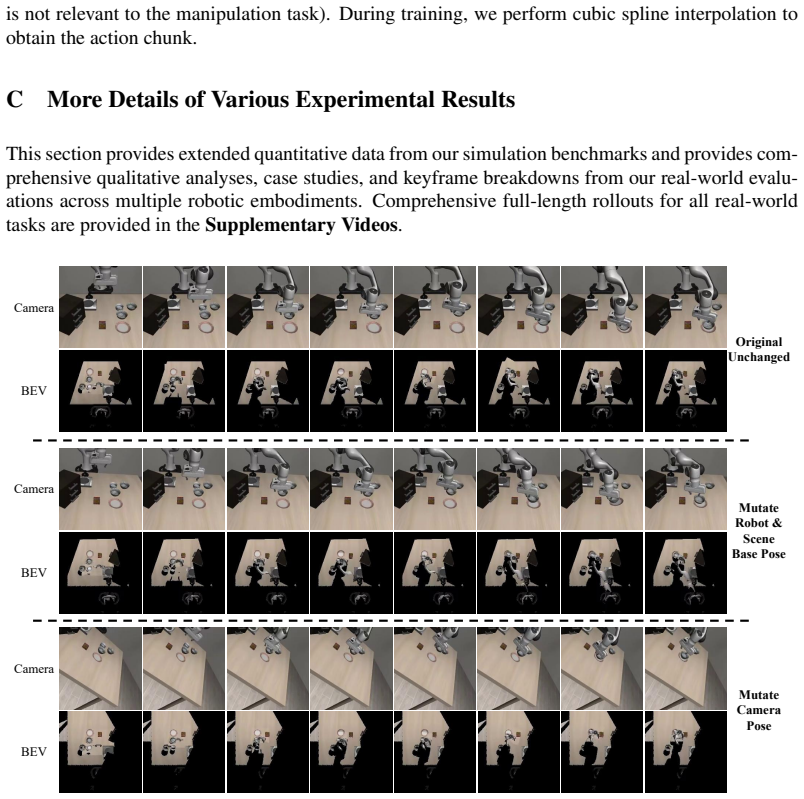
Testing whether policies trained using the BEV alignment show significantly lower success rates when evaluated with unseen camera positions or different robot arms compared to the training conditions.
Figures



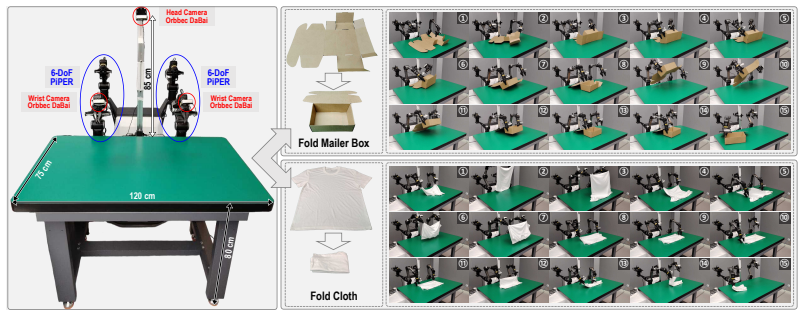




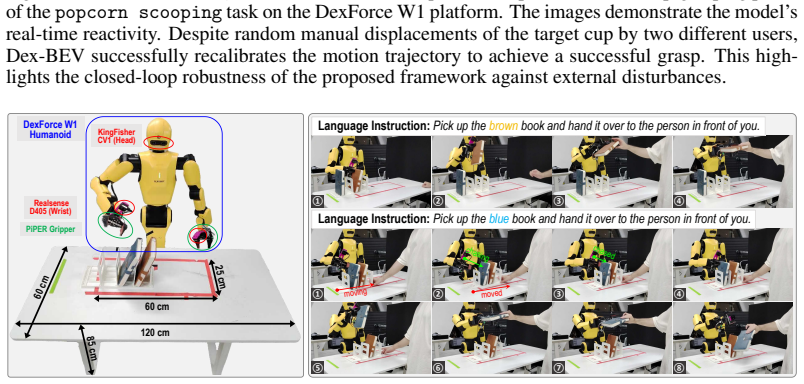

read the original abstract
End-to-end manipulation policies, combined with web-scale pretrained Vision-Language Models (VLMs), show the promise for generalizable and dexterous robotic manipulation. However, they inherit two key limitations from 2D foundation models: 1) the reliance on 2D RGB inputs that ignores the intrinsically 3D nature of manipulation; and 2) the lack of spatial 3D alignment between input-output spaces as well as across diverse robot embodiments, camera setups, and trajectory datasets. In this paper, we present a series of contributions to address these issues. First, we introduce aligned vertex map and vertex spectrum -- a pixel-wise 3D representation that elevates 2D visual inputs to 3D, using camera calibration and optional depth. This novel input representation marries 3D awareness with the generalization of 2D large VLMs. Then, we propose to align the inputs and outputs of manipulation policies by expressing per-pixel 3D information of each camera view and robot actions to a shared coordinate. Based on this, we designate a canonical Bird's-Eye-View (BEV) alignment frame and innovatively propose to construct BEV images, producing a view-invariant representation robust to camera pose variations. To enable training and evaluation at scale, we develop a comprehensive data processing pipeline to perform such alignments; we also introduce a novel temporal alignment scheme for trajectories across diverse robots, human operators, and datasets. These contributions collectively mitigate input and output spatial-temporal misalignments, improving the consistency and generalization for real-world manipulation. Pretrained checkpoint, source code and data processing pipeline are available in https://hnuzhy.github.io/projects/Dex-BEV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that end-to-end manipulation policies using 2D VLMs suffer from ignoring 3D structure and lacking spatial alignment across inputs, outputs, robots, cameras, and datasets. It introduces aligned vertex map and vertex spectrum as a pixel-wise 3D input representation derived from camera calibration and optional depth; aligns per-pixel 3D information and robot actions into a shared coordinate system; constructs canonical BEV images for view-invariant representations; develops a data processing pipeline for alignments at scale; and proposes a novel temporal alignment scheme for trajectories across robots and human operators. These steps are asserted to mitigate spatial-temporal misalignments and improve consistency and generalization, with code, checkpoint, and pipeline released.
Significance. If the BEV alignment produces the claimed invariance, the work could meaningfully advance scalable, generalizable robot manipulation by bridging 2D foundation models with explicit 3D and action alignment. The public release of pretrained checkpoint, source code, and data pipeline is a clear strength for reproducibility and follow-on work.
major comments (1)
- [Abstract] Abstract: The central claim that mapping per-pixel 3D inputs and robot actions into a shared canonical BEV frame yields a representation 'robust to ... embodiment differences' rests on an unverified assumption. The description provides no mechanism (e.g., forward kinematics, learned adapters, or normalization of joint limits/action dimensionality) to resolve kinematic differences across embodiments; coordinate transformation alone does not guarantee invariance when action spaces differ in structure and semantics. This assumption is load-bearing for the generalization claim.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comment. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that mapping per-pixel 3D inputs and robot actions into a shared canonical BEV frame yields a representation 'robust to ... embodiment differences' rests on an unverified assumption. The description provides no mechanism (e.g., forward kinematics, learned adapters, or normalization of joint limits/action dimensionality) to resolve kinematic differences across embodiments; coordinate transformation alone does not guarantee invariance when action spaces differ in structure and semantics. This assumption is load-bearing for the generalization claim.
Authors: We agree the abstract is brief and does not spell out the action transformation details. The full manuscript (Section 3.2 and the data pipeline in Section 4) describes expressing robot actions in the shared canonical BEV frame via forward kinematics and camera extrinsics, so that the policy outputs 3D end-effector deltas rather than joint commands. This produces a common action representation across embodiments. Experiments in Section 5 demonstrate cross-robot generalization using this alignment. We will add a concise sentence to the abstract and a short clarifying paragraph in Section 3.2 in the revision. revision: partial
Circularity Check
No circularity: methodological design choices presented without self-referential reduction
full rationale
The paper's abstract and description outline a sequence of engineering contributions: a pixel-wise 3D vertex map representation, alignment of inputs/outputs to a shared coordinate, construction of canonical BEV images, a data processing pipeline, and a temporal alignment scheme. None of these steps are shown to reduce to their own inputs by construction, fitted parameters renamed as predictions, or load-bearing self-citations. No equations, uniqueness theorems, or ansatzes are quoted that would create a definitional loop. The invariance claim is framed as the result of the proposed alignment procedure itself, not derived from prior author work in a circular manner. This is a standard non-circular description of a new method pipeline.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Aligning per-pixel 3D information and robot actions to a shared canonical BEV frame produces a view-invariant representation robust to camera pose variations.
invented entities (2)
-
aligned vertex map and vertex spectrum
no independent evidence
-
BEV images
no independent evidence
Reference graph
Works this paper leans on
-
[1]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research (IJRR), 44(10-11):1684–1704, 2025
2025
-
[2]
Levine, C
S. Levine, C. Finn, T. Darrell, and P. Abbeel. End-to-end training of deep visuomotor policies.The Journal of Machine Learning Research, 17(1):1334–1373, 2016
2016
-
[3]
Y . Zhu, Z. Wang, J. Merel, A. Rusu, T. Erez, S. Cabi, S. Tunyasuvunakool, J. Kram ´ar, R. Hadsell, N. de Freitas, et al. Reinforcement and imitation learning for diverse visuomotor skills.arXiv preprint, 2018
2018
-
[4]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[5]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[6]
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[7]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, et al. Qwen2- vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[8]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning.Advances in Neural Information Processing Systems (NeurIPS), 36:34892–34916, 2023
2023
-
[9]
H. Liu, C. Li, Y . Li, and Y . J. Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26296–26306, 2024
2024
-
[10]
L. Maes, Q. L. Lidec, D. Scieur, Y . LeCun, and R. Balestriero. Leworldmodel: Stable end-to-end joint- embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
Pith/arXiv arXiv 2026
-
[11]
Y . Gao, H. Guo, T. Hoang, W. Huang, L. Jiang, F. Kong, H. Li, J. Li, L. Li, X. Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113, 2025
Pith/arXiv arXiv 2025
-
[12]
K. Team, J. Chen, Y . Ci, X. Du, Z. Feng, K. Gai, S. Guo, F. Han, J. He, K. He, et al. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
Pith/arXiv arXiv 2025
-
[13]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning (CoRL), pages 2679–2713. PMLR, 2025
2025
-
[14]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control. InProceedings of Robotics: Science and Systems (RSS), LosAngeles, CA, USA, June 2025. doi:10.15607/RSS.2025.XX.010. 9
-
[15]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InThe Thirteenth International Conference on Learning Representa- tions (ICLR), volume 2025, pages 29982–30009, 2025
2025
-
[16]
RT-1: robotics transformer for real-world control at scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. Joshi, R. Julian, D. Kalash- nikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manjunath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsch, J....
-
[17]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt- 2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), pages 2165–2183. PMLR, 2023
2023
-
[18]
S. Belkhale, T. Ding, T. Xiao, P. Sermanet, Q. Vuong, J. Tompson, Y . Chebotar, D. Dwibedi, and D. Sadigh. Rt-h: Action hierarchies using language. InProceedings of Robotics: Science and Systems (RSS), Delft, Netherlands, July 2024. doi:10.15607/RSS.2024.XX.049
-
[19]
A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
Pith/arXiv arXiv 2025
-
[20]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[21]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
Pith/arXiv arXiv 2026
-
[22]
G. Team, B. Wang, B. Li, C. Ni, G. Huang, G. Zhao, H. Li, J. Li, J. Lv, J. Liu, et al. Gigabrain-0.5 m*: a vla that learns from world model-based reinforcement learning.arXiv preprint arXiv:2602.12099, 2026
arXiv 2026
-
[23]
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan. 3d-vla: A 3d vision-language- action generative world model. InInternational Conference on Machine Learning (ICML), pages 61229– 61245. PMLR, 2024
2024
-
[24]
X. Li, L. Heng, J. Liu, Y . Shen, C. Gu, Z. Liu, H. Chen, N. Han, R. Zhang, H. Tang, et al. 3ds-vla: A 3d spatial-aware vision language action model for robust multi-task manipulation. InConference on Robot Learning (CoRL), pages 2344–2359. PMLR, 2025
2025
-
[25]
L. Sun, B. Xie, Y . Liu, H. Shi, T. Wang, and J. Cao. Geovla: Empowering 3d representations in vision- language-action models.arXiv preprint arXiv:2508.09071, 2025
arXiv 2025
-
[26]
Zhang, H
Z. Zhang, H. Li, Y . Dai, Z. Zhu, L. Zhou, C. Liu, D. Wang, F. E. H. Tay, S. Chen, Z. Liu, Y . Liu, X. Li, and P. Zhou. From spatial to actions: Grounding vision-language-action model in spatial foundation priors. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026. URL https://openreview.net/forum?id=fzmittHfq3
2026
-
[27]
X. Fan, S. Deng, X. Wu, Y . Lu, Z. Li, M. Yan, Y . Zhang, Z. Zhang, H. Wang, and H. Zhao. Any3d-vla: Enhancing vla robustness via diverse point clouds.arXiv preprint arXiv:2602.00807, 2026
Pith/arXiv arXiv 2026
-
[28]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems (NeurIPS), 36:44776– 44791, 2023
2023
-
[29]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5294–5306, 2025
2025
-
[30]
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, Y . Zhao, S. Peng, H. Guo, X. Zhou, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026. URLhttps://openreview.net/forum?id= yirunib8l8
2026
-
[31]
Y . Liu, T. Wang, X. Zhang, and J. Sun. Petr: Position embedding transformation for multi-view 3d object detection. InEuropean Conference on Computer Vision (ECCV), pages 531–548. Springer, 2022. 10
2022
-
[32]
Y . Liu, J. Yan, F. Jia, S. Li, A. Gao, T. Wang, and X. Zhang. Petrv2: A unified framework for 3d perception from multi-camera images. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3262–3272, 2023
2023
-
[33]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InProceedings of Robotics: Science and Systems (RSS), Daegu, Republic of Korea, July 2023. doi:10.15607/RSS.2023.XIX.016
-
[34]
Z. Fu, T. Z. Zhao, and C. Finn. Mobile aloha: Learning bimanual mobile manipulation using low-cost whole-body teleoperation. InConference on Robot Learning (CoRL), pages 4066–4083. PMLR, 2025
2025
-
[35]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Man- dlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models. InIEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[36]
DROID: A large-scale in-the-wild robot manipulation dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. InProceedings of Robotics: Science and Systems (RSS), Delft, Netherlands, July 2024. doi:10.15607/RSS.2024.XX.120
-
[37]
K. Wu, C. Hou, J. Liu, Z. Che, X. Ju, Z. Yang, M. Li, Y . Zhao, Z. Xu, G. Yang, S. Fan, X. Wang, F. Liao, Z. Zhao, G. Li, Z. Jin, L. Wang, J. Mao, N. Liu, P. Ren, Q. Zhang, Y . Lyu, M. Liu, H. Jingyang, Y . Luo, Z. Gao, C. Li, C. Gu, Y . Fu, D. Wu, X. Wang, S. Chen, Z. Wang, P. An, S. Qian, S. Zhang, and J. Tang. Robomind: Benchmark on multi-embodiment in...
2025
-
[38]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems (RSS), Delft, Netherlands, July 2024. doi:10.15607/RSS.2024.XX.090
-
[39]
Zheng, J
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, T. Wang, Y .-Q. Zhang, J. Liu, and X. Zhan. X-vla: Soft-prompted transformer as scalable cross-embodiment vision- language-action model. InThe Fourteenth International Conference on Learning Representations (ICLR),
-
[40]
URLhttps://openreview.net/forum?id=kt51kZH4aG
-
[41]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π 0.5: a vision-language-action model with open-world generalization. InConference on Robot Learning (CoRL), pages 17–40. PMLR, 2025
2025
-
[42]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[43]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, J. Gu, Z. Wang, Y . Ding, B. Zhao, D. Wang, and X. Li. Spatialvla: Exploring spatial representations for visual-language-action models. InProceedings of Robotics: Science and Systems (RSS), LosAngeles, CA, USA, June 2025. doi:10.15607/RSS.2025.XX.011
-
[44]
T. Yuan, Y . Liu, C. Lu, Z. Chen, T. Jiang, and H. Zhao. Depthvla: Enhancing vision-language-action models with depth-aware spatial reasoning.arXiv preprint arXiv:2510.13375, 2025
arXiv 2025
-
[45]
S. Deng, M. Yan, Y . Zheng, J. Su, W. Zhang, X. Zhao, H. Cui, Z. Zhang, and H. Wang. Stereovla: Enhancing vision-language-action models with stereo vision.arXiv preprint arXiv:2512.21970, 2025
arXiv 2025
-
[46]
C. Li, J. Wen, Y . Peng, Y . Peng, and Y . Zhu. Pointvla: Injecting the 3d world into vision-language-action models.IEEE Robotics and Automation Letters (RAL), 11(3):2506–2513, 2026
2026
-
[47]
Q. Yu, X. Yuan, Y . Jiang, J. Chen, D. Zheng, C. Hao, Y . You, Y . Chen, Y . Mu, L. Liu, et al. Artgs: 3d gaussian splatting for interactive visual-physical modeling and manipulation of articulated objects. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13170–13177. IEEE, 2025
2025
-
[48]
F. Li, W. Song, H. Zhao, J. Wang, P. Ding, D. Wang, L. ZENG, and H. Li. Spatial forcing: Implicit spatial representation alignment for vision-language-action model. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026. URLhttps://openreview.net/forum?id=euMVC1DO4k
2026
-
[49]
P. Li, Y . Chen, H. Wu, X. Ma, X. Wu, Y . Huang, L. Wang, T. Kong, and T. Tan. Bridgevla: Input- output alignment for efficient 3d manipulation learning with vision-language models. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025. URLhttps: //openreview.net/forum?id=ffBF6hYuQv. 11
2025
-
[50]
Y . Chen, S. Liu, X. Shen, and J. Jia. Dsgn: Deep stereo geometry network for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12536–12545, 2020
2020
-
[51]
Reading, A
C. Reading, A. Harakeh, J. Chae, and S. L. Waslander. Categorical depth distribution network for monoc- ular 3d object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8555–8564, 2021
2021
-
[52]
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y . Qiao, and J. Dai. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. InEuropean Conference on Computer Vision (ECCV), pages 1–18. Springer, 2022
2022
-
[53]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations (ICLR), 2023. URLhttps: //openreview.net/forum?id=PqvMRDCJT9t
2023
-
[54]
B. Wen, M. Trepte, J. Aribido, J. Kautz, O. Gallo, and S. Birchfield. Foundationstereo: Zero-shot stereo matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5249–5260, 2025
2025
-
[55]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[56]
Y . Mu, T. Chen, Z. Chen, S. Peng, Z. Lan, Z. Gao, Z. Liang, Q. Yu, Y . Zou, M. Xu, et al. Robotwin: Dual-arm robot benchmark with generative digital twins. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27649–27660, 2025
2025
-
[57]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
Pith/arXiv arXiv 2025
-
[58]
J. Wang, M. Chen, S. Zhang, N. Karaev, J. Sch ¨onberger, P. Labatut, P. Bojanowski, D. Novotny, A. Vedaldi, and C. Rupprecht. Vggt-Ω.arXiv preprint arXiv:2605.15195, 2026
Pith/arXiv arXiv 2026
-
[59]
M. Shi, L. Chen, J. Chen, Y . Lu, C. Liu, G. Ren, P. Luo, D. Huang, M. Yao, and H. Li. Is diversity all you need for scalable robotic manipulation?IEEE Transactions on Robotics (TRO), 2026
2026
-
[60]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. InProceedings of Robotics: Science and Systems (RSS), Delft, Netherlands, July 2024. doi:10.15607/RSS.2024.XX.067
-
[61]
Zheng, Y
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daum´e III, A. Kolobov, F. Huang, and J. Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InInternational Conference on Learning Representations (ICLR), volume 2025, pages 54277–54296, 2025
2025
-
[62]
Zhang, Y
J. Zhang, Y . Chen, Y . Xu, Z. Huang, Y . Zhou, Y .-J. Yuan, X. Cai, G. Huang, X. Quan, H. Xu, et al. 4d- vla: Spatiotemporal vision-language-action pretraining with cross-scene calibration.Advances in Neural Information Processing Systems (NeurIPS), 38:33914–33937, 2025
2025
-
[63]
Zhang, H
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge.Advances in Neural Information Processing Systems (NeurIPS), 38:24195–24228, 2025
2025
-
[64]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Learning to act anywhere with task- centric latent actions. InProceedings of Robotics: Science and Systems (RSS), LosAngeles, CA, USA, June 2025. doi:10.15607/RSS.2025.XXI.014
-
[65]
J. Qian, B. Han, C. Shi, L. Xiao, L. Yang, S. Shi, and L. Jiang. Geopredict: Leveraging predictive kinematics and 3d gaussian geometry for precise vla manipulation.arXiv preprint arXiv:2512.16811, 2025
Pith/arXiv arXiv 2025
-
[66]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success. InProceedings of Robotics: Science and Systems (RSS), LosAngeles, CA, USA, June 2025. doi:10.15607/RSS.2025.XXI.017. 12 This appendix provides supplementary materials to support and expand upon the core methodolo- gies, architectural implementations,...
-
[67]
top-down
picking up and orienting a rigid scooping shovel with the opposite hand, 3) executing a deep gran- ular scoop to fill the shovel cavity, and 4) executing multi-limb spatial synchronization to pour the granular materials smoothly into the target cup without spilling. A.3 DexForce W1 Humanoid Setup:Handover Book Hardware and Sensory Configuration:To maximiz...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.