Massive Spikes in LLMs are Bias Vectors: Mechanistic Uncovering and Spike-Free Quantization
Pith reviewed 2026-06-28 15:15 UTC · model grok-4.3
The pith
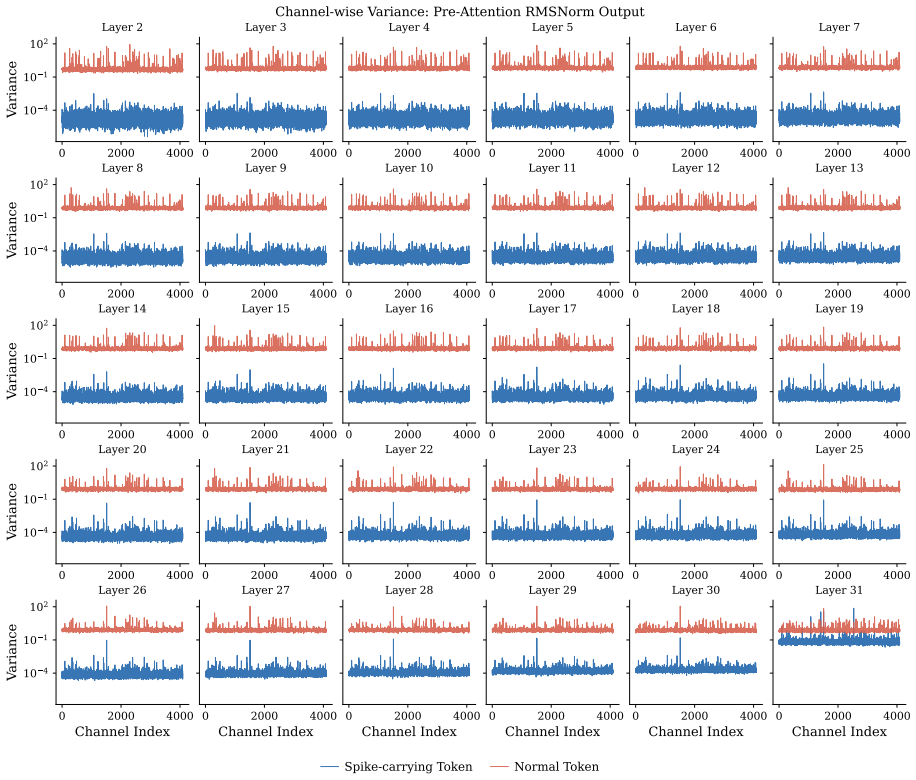
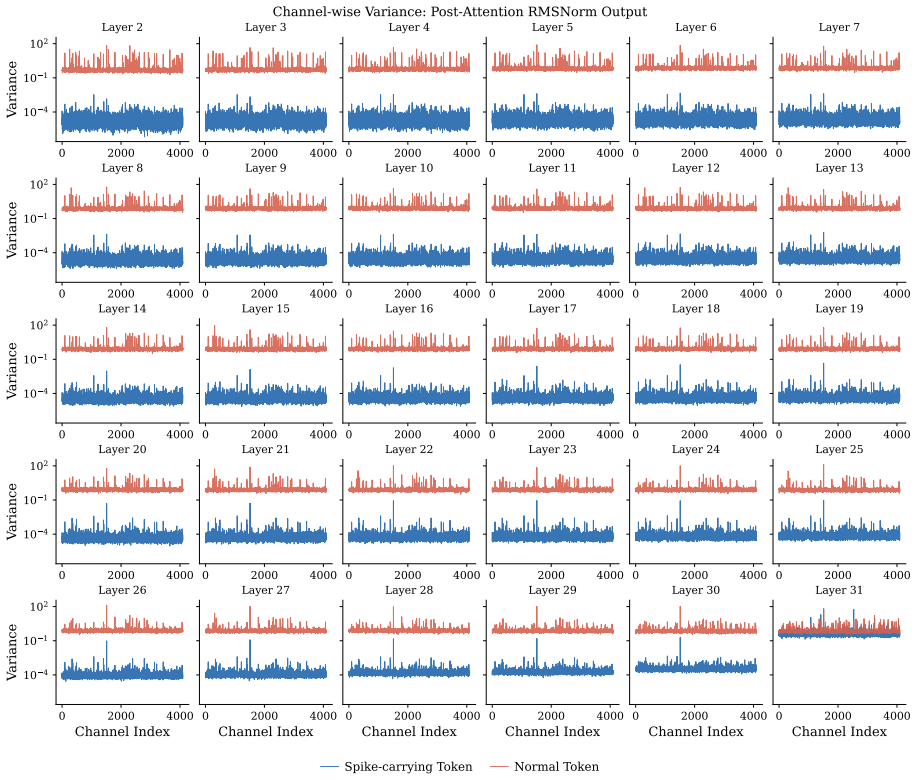
Massive activation spikes in LLMs are the scalar form of rigid structural vector biases in spike-carrying tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
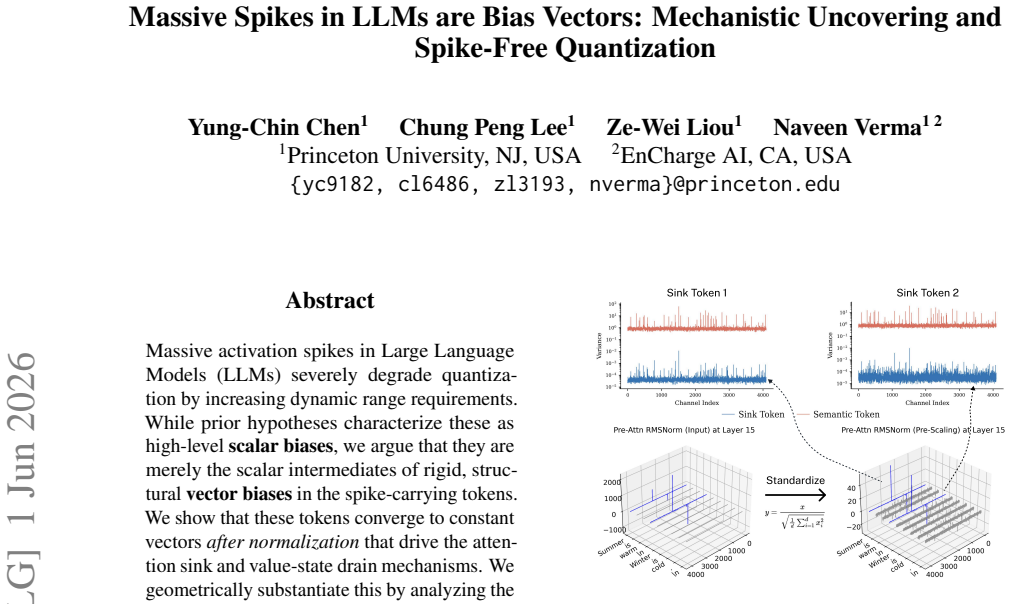
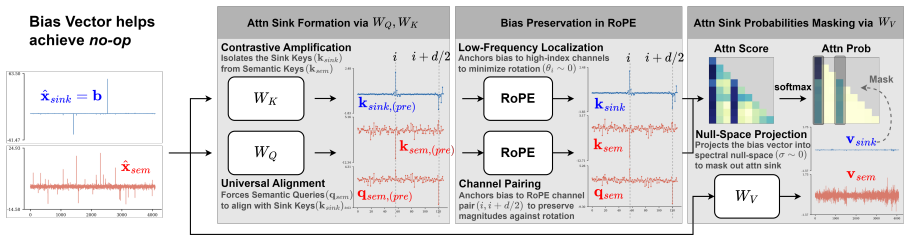
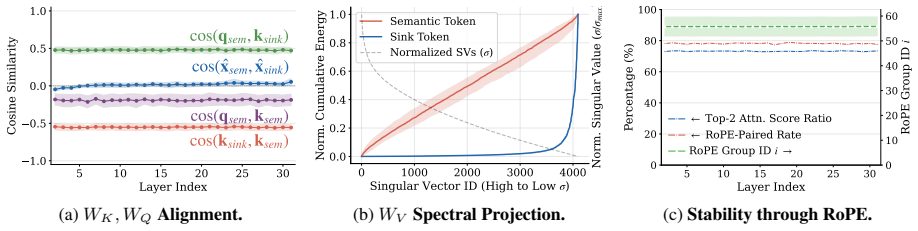
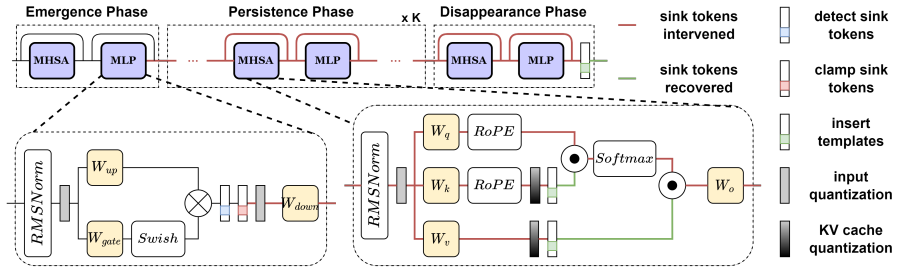
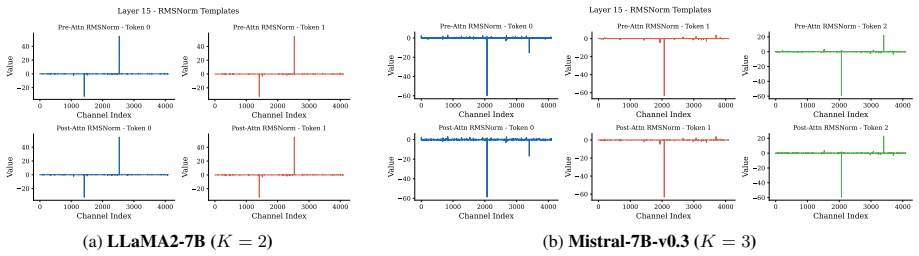
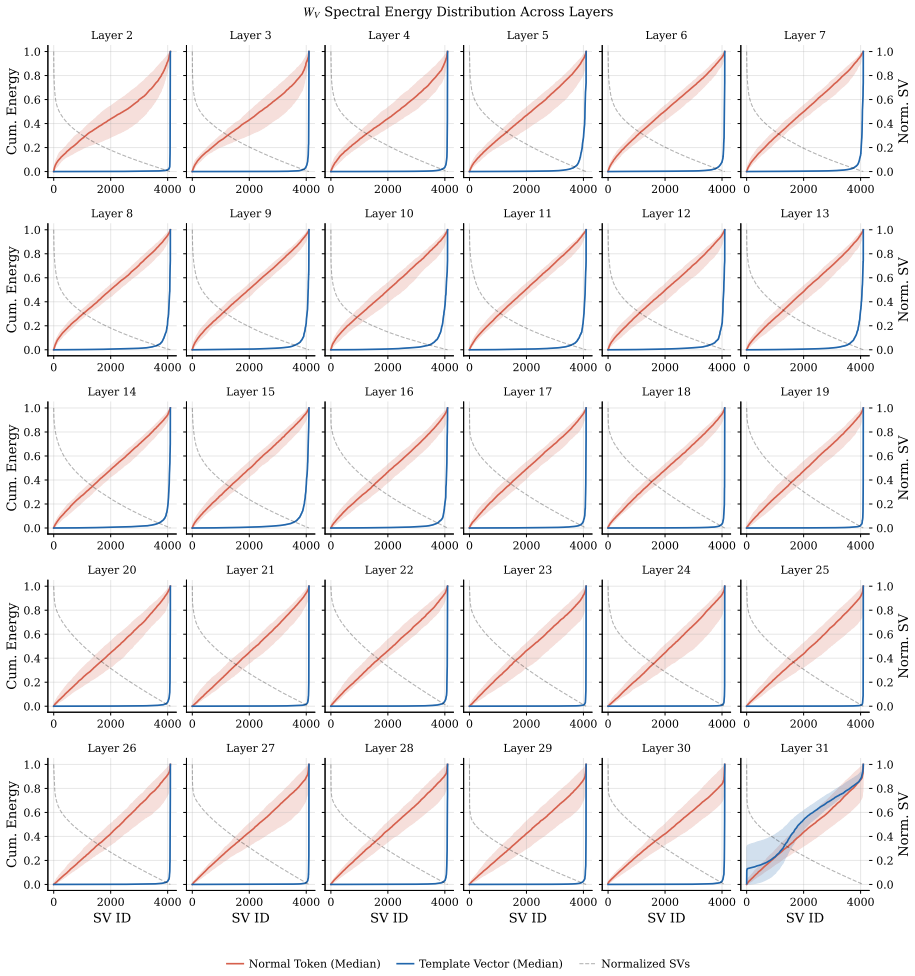
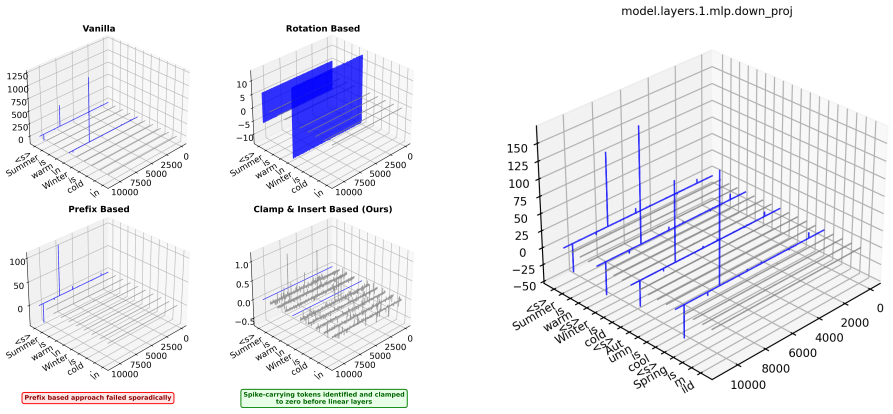
Spike-carrying tokens converge to constant vectors after normalization, with W_K contrastively amplifying the vector, W_Q aligning semantic tokens toward it, and W_V projecting it into the spectral null-space. The model preserves these structural biases against RoPE perturbations by localizing them in zones of rotational stability utilizing low-frequency bands and coherent channel pairs. This leads to INSERTQUANT, a PTQ framework that clamps spikes and restores their function via pre-computed template vectors, rendering activations strictly spike-free.
What carries the argument
zones of rotational stability that localize structural vector biases using low-frequency bands and coherent channel pairs to preserve them against Rotary Positional Embedding perturbations
If this is right
- Clamping spikes and using template vectors maintains model function without new errors from the substitution.
- Activations become strictly spike-free, enabling robust low-bit quantization.
- The method achieves parity with state-of-the-art per-tensor quantization methods on LLMs.
- It generalizes beyond text to other modalities such as vision transformers.
Where Pith is reading between the lines
- Similar bias mechanisms may exist in other transformer architectures beyond the tested LLMs.
- Understanding these stability zones could inform better positional embedding designs.
- Template restoration might be adapted for dynamic input distributions by learning templates on the fly.
Load-bearing premise
Pre-computed template vectors can fully restore the function of the original spike-carrying tokens without introducing new errors in downstream layers or across different input distributions.
What would settle it
Measuring whether model performance drops when template vectors are used on a new input distribution or in a different model variant where the spike mechanism differs.
Figures
read the original abstract
Massive activation spikes in Large Language Models (LLMs) severely degrade quantization by stretching dynamic ranges. While prior hypotheses characterize these as high-level scalar biases, we argue that they are merely the scalar intermediates of rigid, structural vector biases in the spike-carrying tokens. We show that these tokens converge to constant vectors after normalization that drive the attention sink and value-state drain mechanisms. We geometrically substantiate this by analyzing the coordination of projection weights: $W_K$ contrastively amplifies the vector, $W_Q$ aligns semantic tokens toward it, and $W_V$ projects it into the spectral null-space. Furthermore, we reveal that the model actively preserves these structural biases against Rotary Positional Embedding (RoPE) perturbations by localizing them in "zones of rotational stability" utilizing low-frequency bands and coherent channel pairs. Leveraging this, we propose INSERTQUANT, a post-training quantization (PTQ) framework that clamps spikes and restores their function via pre-computed template vectors. This renders activations strictly spike-free, enabling robust low-bit quantization with high fidelity. INSERTQUANT achieves parity with state-of-the-art per-tensor quantization methods on LLMs and uniquely generalizes beyond text to other modalities such as ViTs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that massive activation spikes in LLMs are scalar intermediates of rigid structural vector biases in spike-carrying tokens. These tokens converge to constant vectors after normalization, driving attention sink and value-state drain. The authors geometrically analyze the coordination of W_K (contrastive amplification), W_Q (semantic alignment), and W_V (spectral null-space projection), and show that the model preserves these biases in 'zones of rotational stability' via low-frequency bands and coherent channel pairs despite RoPE perturbations. They propose INSERTQUANT, a PTQ framework that clamps spikes and restores function with pre-computed template vectors to produce strictly spike-free activations, achieving parity with SOTA per-tensor quantization on LLMs while generalizing to ViTs.
Significance. If the mechanistic reinterpretation and template-based restoration hold with the required invariance properties, the work would advance understanding of activation spikes beyond scalar-bias hypotheses and provide a practical route to robust low-bit quantization. The cross-modal generalization, if experimentally supported, would increase impact. The attempt to tie geometric weight coordination and rotational stability to quantization is a positive direction.
major comments (2)
- [Abstract] Abstract (final paragraph): the claim that pre-computed template vectors fully restore the original function of spike-carrying tokens without introducing new errors in downstream layers or across input distributions lacks any reported validation of downstream activation invariance, attention-map preservation, or cross-distribution stability. This assumption is load-bearing for both the spike-free property and the reported parity with SOTA methods.
- [Abstract] Abstract: the geometric substantiation that W_K contrastively amplifies the vector, W_Q aligns semantic tokens, and W_V projects into the spectral null-space is stated at a high level without explicit equations, derivation steps, or quantitative measures of these effects. This analysis underpins the central claim that spikes are structural vector biases rather than scalar phenomena.
minor comments (1)
- [Abstract] The terms 'zones of rotational stability' and 'coherent channel pairs' are introduced without a forward reference to their definition or operationalization in later sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, proposing revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the claim that pre-computed template vectors fully restore the original function of spike-carrying tokens without introducing new errors in downstream layers or across input distributions lacks any reported validation of downstream activation invariance, attention-map preservation, or cross-distribution stability. This assumption is load-bearing for both the spike-free property and the reported parity with SOTA methods.
Authors: We acknowledge this point. The manuscript reports that INSERTQUANT achieves parity with SOTA per-tensor quantization on LLMs and generalizes to ViTs, which serves as empirical support for the restoration of function. However, to directly address the request for validation of downstream activation invariance, attention-map preservation, and cross-distribution stability, we will add targeted experiments and analysis in the revised version of the paper. revision: yes
-
Referee: [Abstract] Abstract: the geometric substantiation that W_K contrastively amplifies the vector, W_Q aligns semantic tokens, and W_V projects into the spectral null-space is stated at a high level without explicit equations, derivation steps, or quantitative measures of these effects. This analysis underpins the central claim that spikes are structural vector biases rather than scalar phenomena.
Authors: The full geometric analysis with equations, derivation steps, and quantitative measures is provided in Section 3 of the manuscript. To improve the self-contained nature of the abstract, we will incorporate a concise reference to these elements or key quantitative findings in the revised abstract. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives its mechanistic claims about spikes as vector biases from geometric analysis of W_Q/W_K/W_V coordination and RoPE stability zones, then proposes INSERTQUANT as a separate PTQ technique using pre-computed templates. No step reduces a claimed result to its own inputs by definition, no fitted parameter is relabeled as a prediction, and no load-bearing self-citation chain is present. The template restoration is a design choice whose fidelity is evaluated externally against SOTA methods rather than guaranteed by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- template vectors
axioms (1)
- domain assumption Spike-carrying tokens converge to constant vectors after normalization
invented entities (1)
-
zones of rotational stability
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Why do llms attend to the first token?arXiv preprint arXiv:2504.02732,
Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213–100240. Federico Barbero, Alvaro Arroyo, Xiangming Gu, Christos Perivolaropoulos, Michael Bronstein, Petar Veliˇckovi´c, and Razvan Pascanu. 2025. Why do llms attend to the first token?arXiv preprint arXiv:2504.02732. Yonatan Bisk, Rowan Zelle...
-
[2]
What are you sinking? a geometric approach on attention sink.arXiv preprint arXiv:2508.02546. Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, and 1 others. 2015. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3...
-
[3]
Mitigating quantization errors due to activation spikes in glu-based llms,
Mitigating quantization errors due to acti- vation spikes in glu-based llms.arXiv preprint arXiv:2405.14428. Peter Young, Alice Lai, Micah Hodosh, and Julia Hock- enmaier. 2014. From image descriptions to visual denotations: New similarity metrics for semantic in- ference over event descriptions.Transactions of the association for computational linguistic...
-
[4]
Push- Pull
Consequently, by Layer 31, these tokens no longer carry the rigid sink signal and return to a standard semantic variance profile. E Geometric and Spectral Characterization of Attention Sinks In this section, we provide the detailed experimen- tal setup and mathematical formulation used to derive the mechanistic analysis of attention sinks presented in Sec...
2024
-
[5]
modulo 64
The learnable scaling factor is merged to the subsequent weights. Here for sink tokens, we show the second bias vectorb 2 of LLaMA2-7B, which has slightly larger variances compared tob 1 ology for computing channel contribution scores, and finally present granular evidence of channel pairing. F.1 RoPE Mechanics and Implementation Differences While the ori...
2024
-
[6]
Due to the nascent state of the activation patterns, only the subset of sink tokens exhibiting early-onset spikes are detected
Stage 1 (Layer 0):We perform an initial scan at the input of the Layer 0 Down-Projection us- ing another threshold (α0). Due to the nascent state of the activation patterns, only the subset of sink tokens exhibiting early-onset spikes are detected. The remaining sink tokens, whose spikes have not yet fully formed, are simply not detected (false negatives)...
-
[7]
This stage captures any remaining sink tokens that did not spark in Layer 0
Stage 2 (Layer 1):We perform the defini- tive scan at the input of the Layer 1 Down- Projection (the standard emergence point). This stage captures any remaining sink tokens that did not spark in Layer 0. The union of indices detected in Stage 1 and Stage 2 forms the final set of sink token indices S, which is frozen and shared for all subsequent layers. ...
-
[8]
Sequential Alignment ( Nsink =K ):In standard sequences where the number of de- tected sink tokens matches the template count exactly, we assign templates based on their sequential order (i.e., the first detected sink maps to t1, the second to t2, etc.). We hy- pothesize that template types naturally follow a consistent sequential order due to the causal ...
-
[9]
MSE-Based Fallback (Nsink ̸=K ):In cases where the counts do not match, we resolve the mapping ambiguity by computing the Mean Squared Error (MSE) between the detected token’s statexs and the candidate templates. The token is assigned to the template k∗ that minimizes the reconstruction error: k∗ = arg min k ∥xs −t (detection) k ∥2 2 (11) Runtime Persiste...
2024
-
[10]
Semantic-Only MSE Objective.Since IN- SERTQUANTintentionally clamps sink tokens to zero—introducing a massive theoretical error at the current layer that is corrected via insertion in the subsequent layer—including these tokens in the loss calculation would skew the optimization. Instead, we compute the reconstruction error exclu- sively over the semantic...
-
[11]
sink token
Structure Preservation Constraint.Aggres- sive clipping can suppress activation magnitudes, potentially altering the set of tokens identified as spikes by our detection algorithm (false negatives). To prevent this, we constrain the search space. We define thedetection correctnessR correct as: Rcorrect = |Squant ∩ Sf p| |Sf p| (13) where Squant and Sf p ar...
2024
-
[12]
(CC BY-SA 4.0), BoolQ (Clark et al.,
-
[13]
(CC BY-SA 3.0), PIQA (Bisk et al.,
-
[14]
• Vision: ImageNet-1K (Deng et al., 2009) (Custom; Non-Commercial), and Flickr30k (Young et al., 2014) (Custom; Research Use) via [HuggingFace]
(Apache 2.0), OpenBookQA (Mihaylov et al., 2018) (Apache 2.0), Winogrande (Sak- aguchi et al., 2021) (Apache 2.0), and So- cialIQA (Sap et al., 2019) (CC BY 4.0). • Vision: ImageNet-1K (Deng et al., 2009) (Custom; Non-Commercial), and Flickr30k (Young et al., 2014) (Custom; Research Use) via [HuggingFace]. K.3 Software and Frameworks The following open-so...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.