PRIMA: Boosting Animal Mesh Recovery with Biological Priors and Test-Time Adaptation
Pith reviewed 2026-06-28 14:53 UTC · model grok-4.3
The pith
Biological priors from image embeddings combined with test-time adaptation using 2D constraints improve 3D mesh recovery for diverse quadruped species and poses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
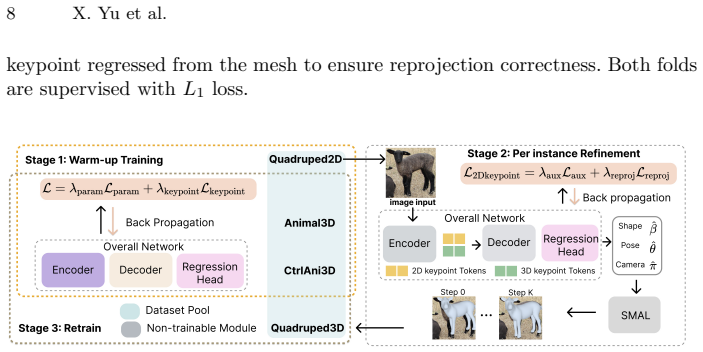
Biological priors supplied by BioCLIP embeddings, together with a test-time adaptation procedure that enforces 2D reprojection consistency and auxiliary keypoint constraints, enable more accurate and generalizable SMAL-based mesh predictions across quadrupeds; the same adaptation process can be used to bootstrap a large-scale pseudo-3D training set that further lifts performance.
What carries the argument
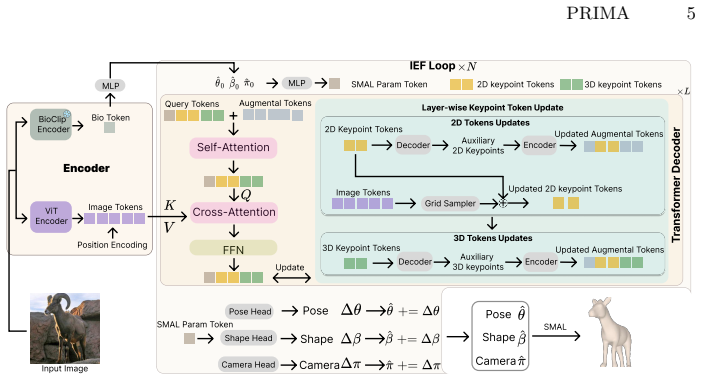
BioCLIP embeddings acting as biological priors to condition shape prediction, paired with a test-time adaptation loop that optimizes SMAL parameters against 2D reprojection and keypoint losses.
If this is right
- Models trained with the generated Quadruped3D dataset achieve higher accuracy on long-tailed species distributions.
- Test-time refinement produces usable pseudo-3D labels from ordinary 2D animal photographs.
- Performance gains concentrate on underrepresented species and extreme poses.
- The same prior-plus-adaptation pattern applies to any SMAL-style parametric model.
Where Pith is reading between the lines
- The method could be tested on non-quadruped animals or on other parametric body models by swapping the embedding source and loss terms.
- If the priors remain effective, similar adaptation pipelines might reduce reliance on expensive 3D animal capture in behavioral studies.
- One could measure whether the improvement scales with the diversity of the 2D source data used for adaptation.
Load-bearing premise
The embeddings carry semantic and morphological information that improves shape estimates across quadrupeds without importing unwanted biases from the image collection used to train them.
What would settle it
A controlled test on a held-out set of 2D images of rare species where independent 3D ground truth or expert-verified meshes show no improvement over a non-adapted baseline after PRIMA is applied.
Figures









read the original abstract
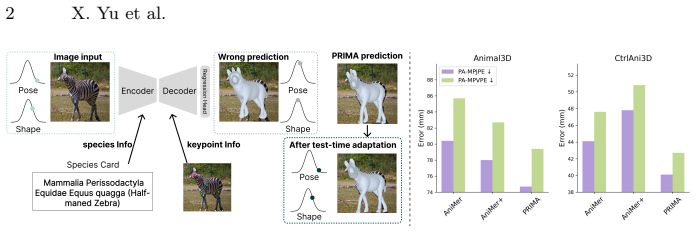
We present PRIMA (*PRI*ors for *M*esh *A*daptation), a framework for robust 3D quadruped mesh recovery under severe species and pose imbalance. Existing animal reconstruction methods often regress toward mean shapes and poses due to limited 3D supervision and long-tailed species distributions, resulting in poor generalization to underrepresented animals and rare articulations. PRIMA addresses this challenge through three key contributions. First, we incorporate BioCLIP embeddings as biological priors to inject semantic and morphological knowledge into the reconstruction process, enabling more accurate and generalizable shape prediction across diverse quadrupeds. Second, we introduce a test-time adaptation (TTA) strategy that refines SMAL predictions using 2D reprojection constraints together with auxiliary keypoint guidance, improving pose and shape estimation while enabling the generation of high-quality pseudo-3D annotations from existing 2D datasets. Third, leveraging this TTA framework, we construct Quadruped3D, a large-scale pseudo-3D dataset that covers diverse species and pose variations to systematically improve model performance. Extensive experiments on Animal3D, CtrlAni3D, Quadruped2D, and Animal Kingdom demonstrate that PRIMA achieves state-of-the-art results, with particularly strong improvements on underrepresented species and challenging poses. Our results highlight the importance of biological priors and adaptation-driven data expansion for scalable and generalizable animal mesh recovery. Code is available at https://github.com/AdaptiveMotorControlLab/PRIMA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
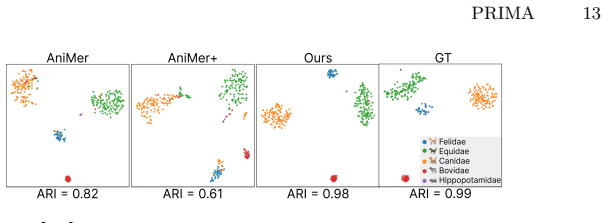
Summary. The paper presents PRIMA, a framework for 3D quadruped mesh recovery that injects BioCLIP embeddings as biological priors for shape prediction and employs test-time adaptation (TTA) with 2D reprojection and keypoint guidance on the SMAL model to generate pseudo-3D annotations. This enables construction of the Quadruped3D dataset from existing 2D sources to mitigate species/pose imbalance. The central empirical claim is state-of-the-art performance on Animal3D, CtrlAni3D, Quadruped2D, and Animal Kingdom, with largest gains on underrepresented species and rare poses; code is released.
Significance. If the pseudo-label quality and BioCLIP contribution hold under scrutiny, the work provides a practical route to scalable animal mesh recovery by combining semantic priors with adaptation-driven data expansion. The explicit release of code and the Quadruped3D construction process are concrete strengths that could support follow-on research on long-tailed 3D animal datasets.
major comments (3)
- [§3.3 and §4.1] §3.3 (TTA procedure) and §4.1 (Quadruped3D construction): the pseudo-3D labels are generated solely from 2D reprojection loss plus keypoint guidance without any held-out 3D ground-truth validation or cross-check against an independent 3D test set for tail species; this leaves open the possibility that reported gains on underrepresented animals simply reinforce systematic errors in the pseudo-annotations rather than demonstrate genuine generalization from BioCLIP priors.
- [§5] §5 (experiments): the main tables report SOTA numbers but provide no per-species error breakdowns, confidence intervals, or ablation isolating the BioCLIP embedding contribution from the TTA data-augmentation effect; without these controls it is difficult to attribute the claimed improvements on rare poses specifically to the biological priors.
- [§3.2] §3.2 (BioCLIP integration): the claim that BioCLIP supplies morphological knowledge that improves shape prediction across diverse quadrupeds is not accompanied by any analysis of domain shift between BioCLIP's pretraining corpus and the target animal images, nor by a controlled experiment replacing BioCLIP with a generic vision-language embedding.
minor comments (2)
- [Abstract and §1] The abstract and §1 refer to "Quadruped2D" and "Animal Kingdom" without citing the original dataset papers; add these references for completeness.
- [§5] Figure captions in §5 could more explicitly state whether reported metrics are mean per-vertex error or PA-MPJPE to aid direct comparison with prior animal mesh work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below with clarifications and commitments to revisions where they strengthen the work.
read point-by-point responses
-
Referee: [§3.3 and §4.1] the pseudo-3D labels are generated solely from 2D reprojection loss plus keypoint guidance without any held-out 3D ground-truth validation or cross-check against an independent 3D test set for tail species; this leaves open the possibility that reported gains on underrepresented animals simply reinforce systematic errors in the pseudo-annotations rather than demonstrate genuine generalization from BioCLIP priors.
Authors: We acknowledge the concern about pseudo-label validation for tail species. The TTA is driven by reliable 2D keypoints and reprojection from source datasets, and the final model is evaluated on held-out 3D benchmarks (Animal3D, CtrlAni3D) containing underrepresented species. Consistent SOTA gains across these sets indicate genuine improvement rather than error reinforcement. In revision we will expand §4.1 with additional details on pseudo-label quality, including qualitative examples and quantitative checks against any available 3D data. revision: partial
-
Referee: [§5] the main tables report SOTA numbers but provide no per-species error breakdowns, confidence intervals, or ablation isolating the BioCLIP embedding contribution from the TTA data-augmentation effect; without these controls it is difficult to attribute the claimed improvements on rare poses specifically to the biological priors.
Authors: We agree these controls would strengthen attribution of gains. The revised manuscript will add per-species error breakdowns on benchmarks with species annotations, include confidence intervals on main metrics, and present an ablation isolating BioCLIP priors from the TTA-driven Quadruped3D data expansion. revision: yes
-
Referee: [§3.2] the claim that BioCLIP supplies morphological knowledge that improves shape prediction across diverse quadrupeds is not accompanied by any analysis of domain shift between BioCLIP's pretraining corpus and the target animal images, nor by a controlled experiment replacing BioCLIP with a generic vision-language embedding.
Authors: We agree a direct comparison would better substantiate the biological priors. In revision we will add both a short discussion of domain considerations for BioCLIP and a controlled ablation in §5 that replaces BioCLIP with a generic vision-language embedding (e.g., CLIP) to quantify the specific benefit. revision: yes
Circularity Check
No circularity: derivation relies on external BioCLIP priors and standard TTA/reprojection losses without self-referential reduction
full rationale
The paper's core steps—injecting BioCLIP embeddings as biological priors, applying TTA with 2D reprojection and keypoint guidance on the external SMAL model to generate Quadruped3D pseudo-labels, then training and evaluating on held-out benchmarks (Animal3D, CtrlAni3D, etc.)—do not reduce any claimed prediction or result to quantities defined inside the paper by construction. No equations equate fitted parameters to outputs, no self-citation chain bears the central claim, and the TTA-generated dataset is an input expansion step whose value is assessed via external metrics rather than tautological reuse. This matches the default non-circular case.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption BioCLIP embeddings capture useful semantic and morphological knowledge for quadruped shape prediction
- domain assumption Test-time adaptation with 2D reprojection constraints improves pose and shape estimates without accumulating errors
Reference graph
Works this paper leans on
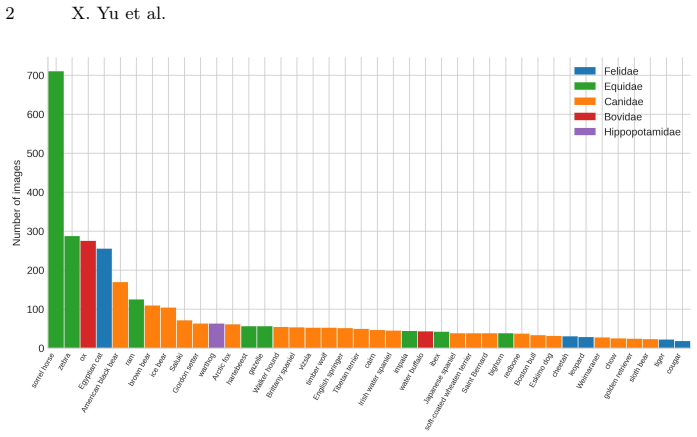
-
[1]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
An, L., Lyu, J., Lin, L., Cheng, P., Liu, Y., Tang, X.: Animer+: Unified pose and shape estimation across mammalia and aves via family-aware transformer. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[2]
In: ECCV
Badger, M., Wang, Y., Modh, A., Perkes, A., Kolotouros, N., Pfrommer, B.G., Schmidt, M.F., Daniilidis, K.: 3d bird reconstruction: a dataset, model, and shape recovery from a single view. In: ECCV. pp. 1–17. Springer (2020)
2020
-
[3]
Neurocomputing611, 128605 (2025)
Bidulka, L., Gholami, M., Zheng, J., McKeown, M.J., Wang, Z.J.: Escape: Energy- based selective adaptive correction for out-of-distribution 3d human pose estima- tion. Neurocomputing611, 128605 (2025)
2025
-
[4]
In: ECCV
Biggs, B., Boyne, O., Charles, J., Fitzgibbon, A., Cipolla, R.: Who left the dogs out? 3d animal reconstruction with expectation maximization in the loop. In: ECCV. pp. 195–211. Springer (2020)
2020
-
[5]
In: ACCV (2018)
Biggs, B., Roddick, T., Fitzgibbon, A., Cipolla, R.: Creatures great and SMAL: Recovering the shape and motion of animals from video. In: ACCV (2018)
2018
-
[6]
In: ECCV
Bogo, F., Kanazawa, A., Lassner, C., Gehler, P., Romero, J., Black, M.J.: Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. In: ECCV. pp. 561–578 (2016)
2016
-
[7]
cho et al
Cho, G., Kang, C., Soon, D., Joo, K.: Dogrecon: Canine prior-guided animatable 3d gaussian dog reconstruction from a single image: G. cho et al. International Journal of Computer Vision133(9), 6332–6346 (2025)
2025
-
[8]
In: CVPR
Dwivedi, S.K., Sun, Y., Patel, P., Feng, Y., Black, M.J.: Tokenhmr: Advancing human mesh recovery with a tokenized pose representation. In: CVPR. pp. 1323– 1333 (2024)
2024
-
[9]
In: CVPR (2021)
Fang, Q., Shuai, Q., Dong, J., Bao, H., Zhou, X.: Reconstructing 3d human pose by watching humans in the mirror. In: CVPR (2021)
2021
-
[10]
arXiv preprint arXiv:2511.15586 (2025)
Ferguson, A., Osman, A.A., Bescos, B., Stoll, C., Twigg, C., Lassner, C., Otte, D., Vignola, E., Prada, F., Bogo, F., et al.: Mhr: Momentum human rig. arXiv preprint arXiv:2511.15586 (2025)
-
[12]
In: ICCV
Goel, S., Pavlakos, G., Rajasegaran, J., Kanazawa, A., Malik, J.: Humans in 4d: Reconstructing and tracking humans with transformers. In: ICCV. pp. 14783– 14794 (2023)
2023
-
[13]
arXiv preprint arXiv:2505.23883 (2025)
Gu, J., Stevens, S., Campolongo, E.G., Thompson, M.J., Zhang, N., Wu, J., Kopanev, A., Mai, Z., White, A.E., Balhoff, J., et al.: Bioclip 2: Emergent proper- ties from scaling hierarchical contrastive learning. arXiv preprint arXiv:2505.23883 (2025)
-
[14]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2022)
Guan, S., Xu, J., He, M.Z., Wang, Y., Ni, B., Yang, X.: Out-of-domain human mesh reconstruction via dynamic bilevel online adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2022)
2022
-
[15]
IEEE Transactions on Pattern Analysis and Machine Intelligence36(7), 1325–1339 (2013)
Ionescu, C., Papava, D., Olaru, V., Sminchisescu, C.: Human3.6m: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Transactions on Pattern Analysis and Machine Intelligence36(7), 1325–1339 (2013)
2013
-
[16]
Joo, H., Neverova, N., Vedaldi, A.: Exemplar fine-tuning for 3D human model fitting towards in-the-wild 3D human pose estimation. In: 3DV. pp. 42–52. IEEE (2021) 16 X. Yu et al
2021
-
[17]
In: CVPR
Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end recovery of human shape and pose. In: CVPR. pp. 7122–7131 (2018)
2018
-
[18]
In: ECCV
Kanazawa, A., Tulsiani, S., Efros, A.A., Malik, J.: Learning category-specific mesh reconstruction from image collections. In: ECCV. pp. 371–386 (2018)
2018
-
[19]
In: CVPR
Kulits, P., Black, M.J., Zuffi, S.: Reconstructing animals and the wild. In: CVPR. pp. 16565–16577 (June 2025)
2025
-
[20]
In: CVPR
Kulkarni, N., Gupta, A., Fouhey, D.F., Tulsiani, S.: Articulation-aware canonical surface mapping. In: CVPR. pp. 452–461 (2020)
2020
-
[21]
Advances in Neural Information Processing Systems34, 11757–11768 (2021)
Li, C., Lee, G.H.: Coarse-to-fine animal pose and shape estimation. Advances in Neural Information Processing Systems34, 11757–11768 (2021)
2021
-
[22]
arXiv preprint arXiv:2106.10102 (2021)
Li, C., Ghorbani, N., Broom´ e, S., Rashid, M., Black, M.J., Hernlund, E., Kjell- str¨ om, H., Zuffi, S.: hsmal: Detailed horse shape and pose reconstruction for motion pattern recognition. arXiv preprint arXiv:2106.10102 (2021)
-
[23]
In: Proceedings of the Asian Conference on Computer Vision
Li, C., Yang, Y., Weng, Z., Hernlund, E., Zuffi, S., Kjellstr¨ om, H.: Dessie: Disen- tanglement for articulated 3d horse shape and pose estimation from images. In: Proceedings of the Asian Conference on Computer Vision. pp. 764–783 (2024)
2024
-
[24]
arXiv preprint arXiv:2508.16062 (2025)
Li, Z., Amrani, A., Rai, S., Laga, H.: Advances and trends in the 3d reconstruction of the shape and motion of animals. arXiv preprint arXiv:2508.16062 (2025)
-
[25]
In: CVPR
Li, Z., Litvak, D., Li, R., Zhang, Y., Jakab, T., Rupprecht, C., Wu, S., Vedaldi, A., Wu, J.: Learning the 3d fauna of the web. In: CVPR. pp. 9752–9762 (2024)
2024
-
[26]
ACM TOG34(6), 1–16 (2015)
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinned multi-person linear model. ACM TOG34(6), 1–16 (2015)
2015
-
[27]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
In: CVPR
Lyu, J., Zhu, T., Gu, Y., Lin, L., Cheng, P., Liu, Y., Tang, X., An, L.: Animer: Animal pose and shape estimation using family aware transformer. In: CVPR. pp. 17486–17496 (2025)
2025
-
[29]
Journal of machine learning research9(11) (2008)
Van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of machine learning research9(11) (2008)
2008
-
[30]
In: ICCV
Mahmood, N., Ghorbani, N., Troje, N.F., Pons-Moll, G., Black, M.J.: AMASS: Archive of motion capture as surface shapes. In: ICCV. pp. 5442–5451 (Oct 2019)
2019
-
[31]
In: CVPR (June 2020)
Mu, J., Qiu, W., Hager, G.D., Yuille, A.L.: Learning from synthetic animals. In: CVPR (June 2020)
2020
-
[32]
In: ICCV
Nam, H., Jung, D.S., Oh, Y., Lee, K.M.: Cyclic test-time adaptation on monocular video for 3d human mesh reconstruction. In: ICCV. pp. 14829–14839 (2023)
2023
-
[33]
In: ICCV
Niewiadomski, T., Yiannakidis, A., Cuevas-Velasquez, H., Sanyal, S., Black, M.J., Zuffi, S., Kulits, P.: Generative zoo. In: ICCV. pp. 8492–8502 (2025)
2025
-
[34]
In: CVPR
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single image. In: CVPR. pp. 10975–10985 (2019)
2019
-
[35]
In: CVPR
Pavlakos, G., Shan, D., Radosavovic, I., Kanazawa, A., Fouhey, D., Malik, J.: Reconstructing hands in 3d with transformers. In: CVPR. pp. 9826–9836 (2024)
2024
-
[36]
In: CVPR (2021)
Peng, S., Zhang, Y., Xu, Y., Wang, Q., Shuai, Q., Bao, H., Zhou, X.: Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In: CVPR (2021)
2021
-
[37]
In: ICCV
Rempe, D., Birdal, T., Hertzmann, A., Yang, J., Sridhar, S., Guibas, L.J.: Humor: 3d human motion model for robust pose estimation. In: ICCV. pp. 11488–11499 (2021)
2021
-
[38]
In: CVPR
Rueegg, N., Zuffi, S., Schindler, K., Black, M.J.: Barc: Learning to regress 3d dog shape from images by exploiting breed information. In: CVPR. pp. 3876–3884 (2022) PRIMA 17
2022
-
[39]
In: CVPR
R¨ uegg, N., Tripathi, S., Schindler, K., Black, M.J., Zuffi, S.: Bite: Beyond priors for improved three-d dog pose estimation. In: CVPR. pp. 8867–8876 (2023)
2023
-
[40]
In: ECCV
Sabathier, R., Mitra, N.J., Novotny, D.: Animal avatars: Reconstructing animat- able 3d animals from casual videos. In: ECCV. pp. 270–287. Springer (2024)
2024
-
[41]
In: CVPR
Stevens, S., Wu, J., Thompson, M.J., Campolongo, E.G., Song, C.H., Carlyn, D.E., Dong, L., Dahdul, W.M., Stewart, C., Berger-Wolf, T., Chao, W.L., Su, Y.: Bio- CLIP: A vision foundation model for the tree of life. In: CVPR. pp. 19412–19424 (2024)
2024
-
[42]
In: CVPR
Tan, J., Yang, G., Ramanan, D.: Distilling neural fields for real-time articulated shape reconstruction. In: CVPR. pp. 4692–4701 (2023)
2023
-
[43]
IEEE Transactions on Multimedia (2026)
Wang, T., Liu, M., Liu, H., Ren, B., You, Y., Li, W., Sebe, N., Li, X.: Uncertainty- aware testing-time optimization for 3d human pose estimation. IEEE Transactions on Multimedia (2026)
2026
-
[44]
In: CVPR
Wang, Y., Kolotouros, N., Daniilidis, K., Badger, M.: Birds of a feather: Capturing avian shape models from images. In: CVPR. pp. 14739–14749 (2021)
2021
-
[45]
arXiv preprint arXiv:2404.06507 (2024)
Wu, J., Pavlakos, G., Gkioxari, G., Malik, J.: Reconstructing hand-held objects in 3d from images and videos. arXiv preprint arXiv:2404.06507 (2024)
-
[46]
In: ICCV
Xu, J., Zhang, Y., Peng, J., Ma, W., Jesslen, A., Ji, P., Hu, Q., Zhang, J., Liu, Q., Wang, J., et al.: Animal3d: A comprehensive dataset of 3d animal pose and shape. In: ICCV. pp. 9099–9109 (2023)
2023
-
[47]
Sam 3d body: Robust full-body human mesh recovery
Yang, X., Kukreja, D., Pinkus, D., Sagar, A., Fan, T., Park, J., Shin, S., Cao, J., Liu, J., Ugrinovic, N., Feiszli, M., Malik, J., Dollar, P., Kitani, K.: Sam 3d body: Robust full-body human mesh recovery. arXiv preprint arXiv:2602.15989 (2026)
-
[48]
Advances in Neural Information Processing Systems35, 15296–15308 (2022)
Yao, C.H., Hung, W.C., Li, Y., Rubinstein, M., Yang, M.H., Jampani, V.: Lassie: Learning articulated shapes from sparse image ensemble via 3d part discovery. Advances in Neural Information Processing Systems35, 15296–15308 (2022)
2022
-
[49]
In: CVPR
Yao, C.H., Hung, W.C., Li, Y., Rubinstein, M., Yang, M.H., Jampani, V.: Hi-lassie: High-fidelity articulated shape and skeleton discovery from sparse image ensemble. In: CVPR. pp. 4853–4862 (2023)
2023
-
[50]
Nature communications15(1), 5165 (2024)
Ye, S., Filippova, A., Lauer, J., Schneider, S., Vidal, M., Qiu, T., Mathis, A., Mathis, M.W.: Superanimal pretrained pose estimation models for behavioral anal- ysis. Nature communications15(1), 5165 (2024)
2024
-
[51]
In: ICCV
You, Y., Liu, H., Wang, T., Li, W., Ding, R., Li, X.: Co-evolution of pose and mesh for 3d human body estimation from video. In: ICCV. pp. 14963–14973 (2023)
2023
-
[52]
In: NeurIPS
Zhang, J., Nie, X., Feng, J.: Inference stage optimization for cross-scenario 3D human pose estimation. In: NeurIPS. pp. 2408–2419 (2020)
2020
-
[53]
In: ICCV (October 2019)
Zheng, Z., Yu, T., Wei, Y., Dai, Q., Liu, Y.: Deephuman: 3d human reconstruction from a single image. In: ICCV (October 2019)
2019
-
[54]
In: CVPR
Zioulis, N., O’Brien, J.F.: Kbody: Towards general, robust, and aligned monocular whole-body estimation. In: CVPR. pp. 6215–6225 (2023)
2023
-
[55]
In: ECCV
Zuffi, S., Black, M.J.: Awol: Analysis without synthesis using language. In: ECCV. pp. 1–19. Springer (2024)
2024
-
[56]
In: ICCV
Zuffi, S., Kanazawa, A., Berger-Wolf, T., Black, M.J.: Three-d safari: Learning to estimate zebra pose, shape, and texture from images” in the wild”. In: ICCV. pp. 5359–5368 (2019)
2019
-
[57]
In: CVPR (Jul 2017)
Zuffi, S., Kanazawa, A., Jacobs, D., Black, M.J.: 3D menagerie: Modeling the 3D shape and pose of animals. In: CVPR (Jul 2017)
2017
-
[58]
In: CVPR
Zuffi, S., Mellbin, Y., Li, C., Hoeschle, M., Kjellstr¨ om, H., Polikovsky, S., Hernlund, E., Black, M.J.: Varen: Very accurate and realistic equine network. In: CVPR. pp. 5374–5383 (2024) PRIMA: Boosting Animal Mesh Recovery with Biological Priors and Test-Time Adaptation Supplementary Material A Dataset Statistics: Taxonomic Distribution To characterize...
2024
-
[59]
As shown in Fig
dataset. As shown in Fig. 2, the dataset contains 40 animal species, but the number of samples per species varies significantly. The resulting distribution exhibits a long-tailed pattern, where a small subset of species accounts for the majority of samples, while many species have relatively few instances. Such an imbalance may hinder the learning of robu...
-
[60]
The ViT encoder extracts visual representations, producing a sequence of feature tokens of size 192×1280
These features are subsequently projected to a 1280-dimensional bio-token space. The ViT encoder extracts visual representations, producing a sequence of feature tokens of size 192×1280 . For the keypoint-aware decoder, we employ an Iterative Error Feedback (IEF) loop to progressively refine the SMAL param- eters. In our configuration, we perform N= 3 Ite...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.