TabPrep: Closing the Feature Engineering Gap in Tabular Benchmarks
Pith reviewed 2026-06-28 15:41 UTC · model grok-4.3
The pith
TabPrep shows that a targeted preprocessing pipeline closes the feature engineering gap in tabular benchmarks by raising performance across model classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
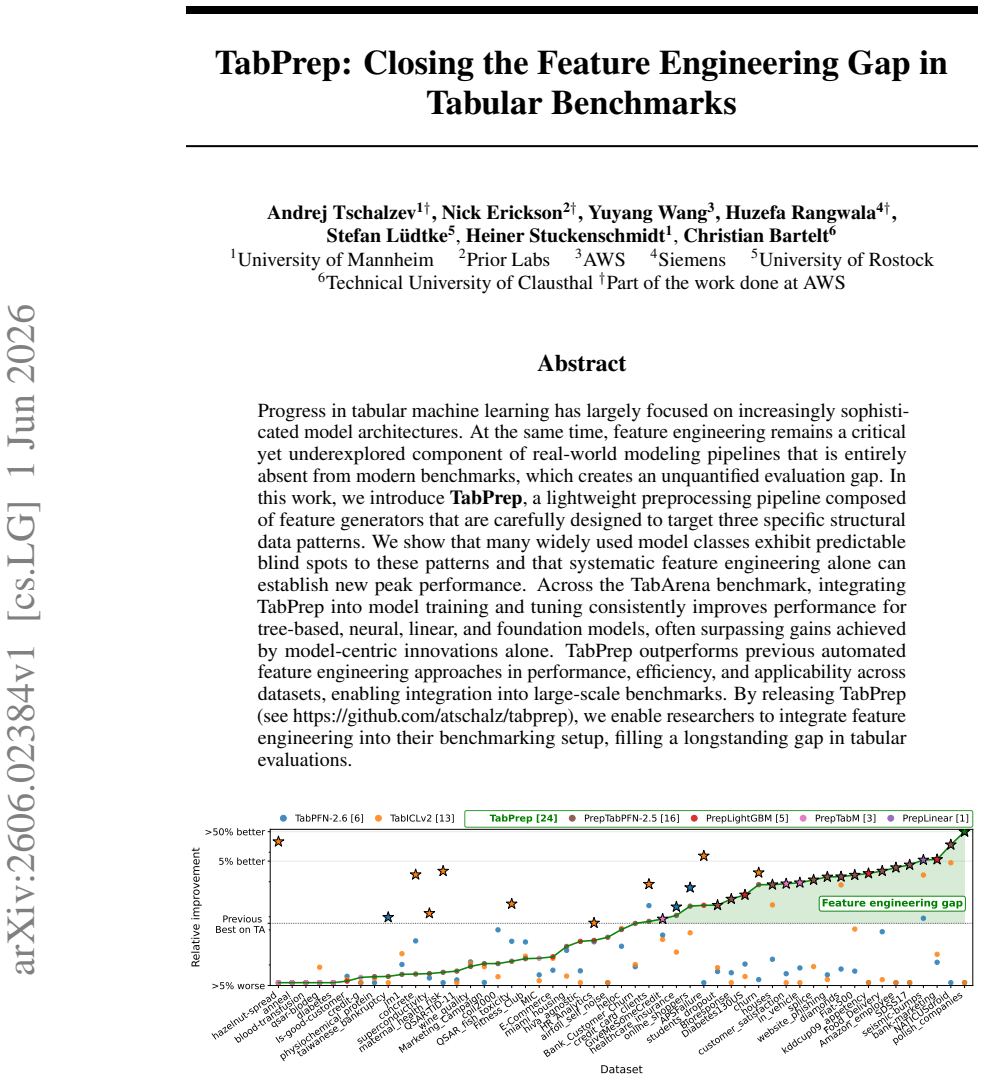
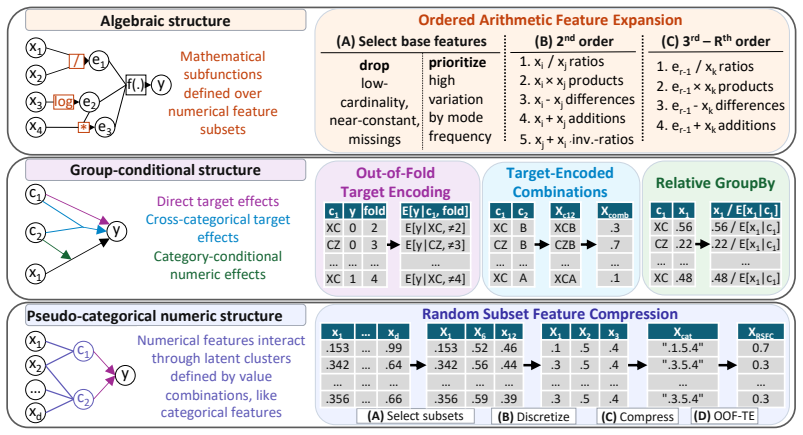
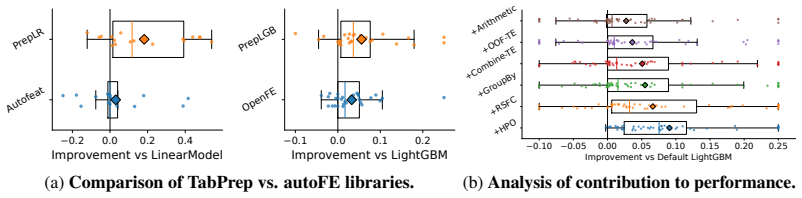
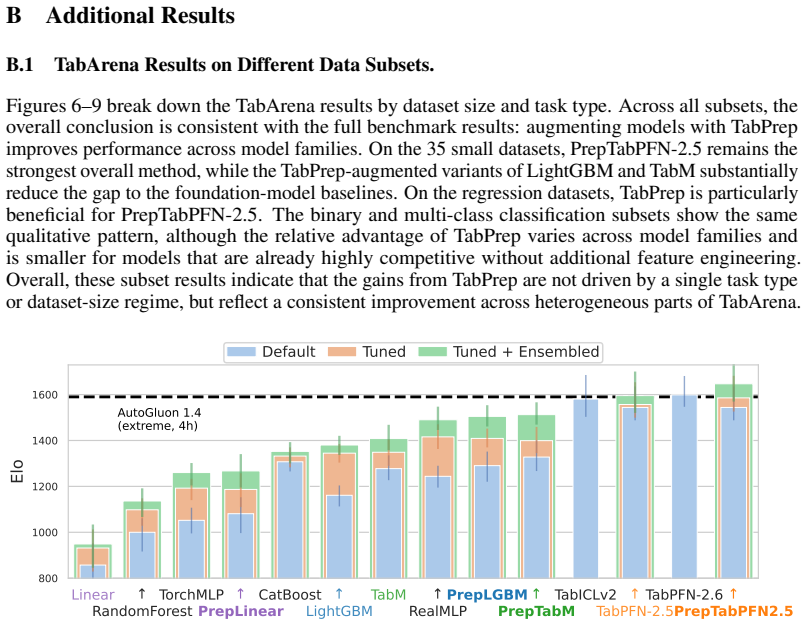
TabPrep is a preprocessing pipeline built from feature generators that target three specific structural data patterns. Many widely used model classes display predictable blind spots to these patterns. Systematic application of the generators during training and hyperparameter tuning produces higher performance on the TabArena benchmark for tree-based, neural, linear, and foundation models, with the improvements often larger than those obtained from model-centric changes alone. The same pipeline also surpasses prior automated feature-engineering methods in accuracy, speed, and dataset coverage, allowing feature engineering to be added to future tabular evaluations.
What carries the argument
TabPrep, a lightweight preprocessing pipeline of feature generators that target three structural data patterns models commonly overlook.
If this is right
- Tree-based, neural, linear, and foundation models all register measurable gains once TabPrep is inserted into training and tuning.
- New peak results on tabular benchmarks can be reached through feature engineering without altering the underlying model architecture.
- TabPrep runs with low enough overhead to be used inside large-scale benchmark evaluations.
- The pipeline beats earlier automated feature engineering methods on accuracy, runtime, and breadth of applicable datasets.
Where Pith is reading between the lines
- Standard tabular benchmarks could be extended to require or strongly encourage the use of such preprocessing so that reported rankings better reflect complete pipelines.
- The three targeted patterns could be examined as a diagnostic checklist when new tabular datasets are released.
- If the patterns prove general, practitioners might default to running TabPrep before testing complex models, shifting effort from architecture search to data preparation.
- Researchers could measure how much of the current gap between benchmark and deployed performance disappears once feature generators of this form are included.
Load-bearing premise
The three structural data patterns the generators address are the main blind spots shared across model classes and the observed gains will hold on data outside the TabArena collection.
What would settle it
A fresh collection of tabular datasets on which adding TabPrep produces no consistent accuracy gain or produces losses for the same model families would falsify the central performance claim.
Figures


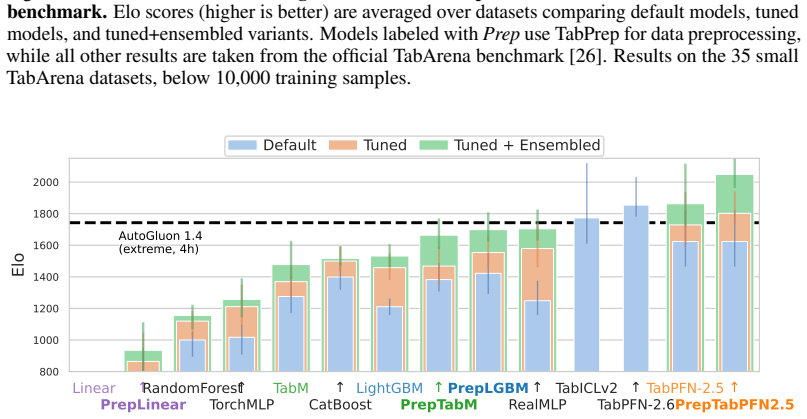
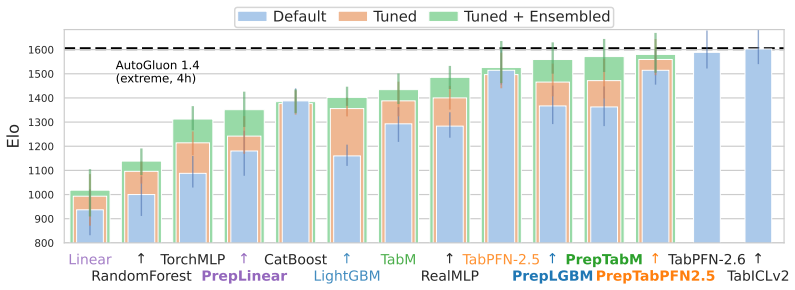
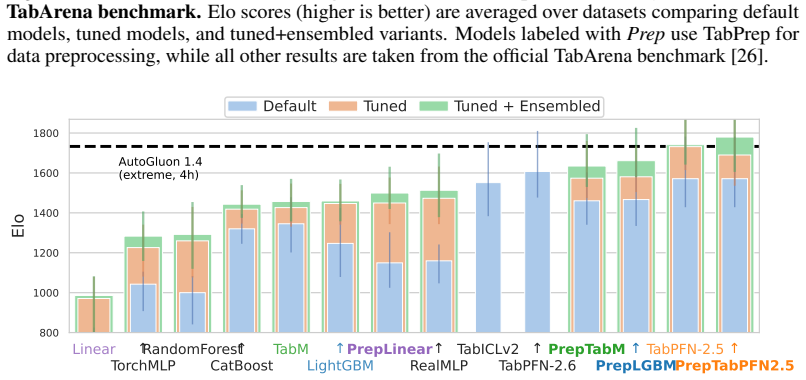
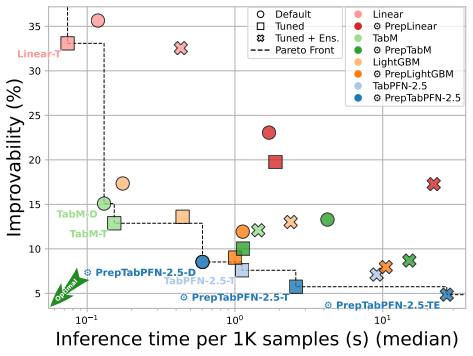
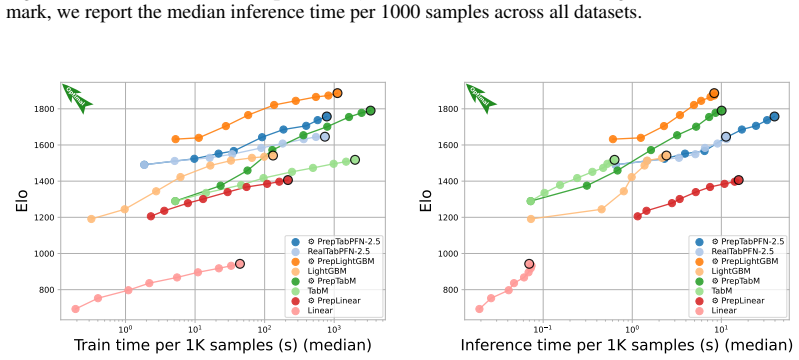
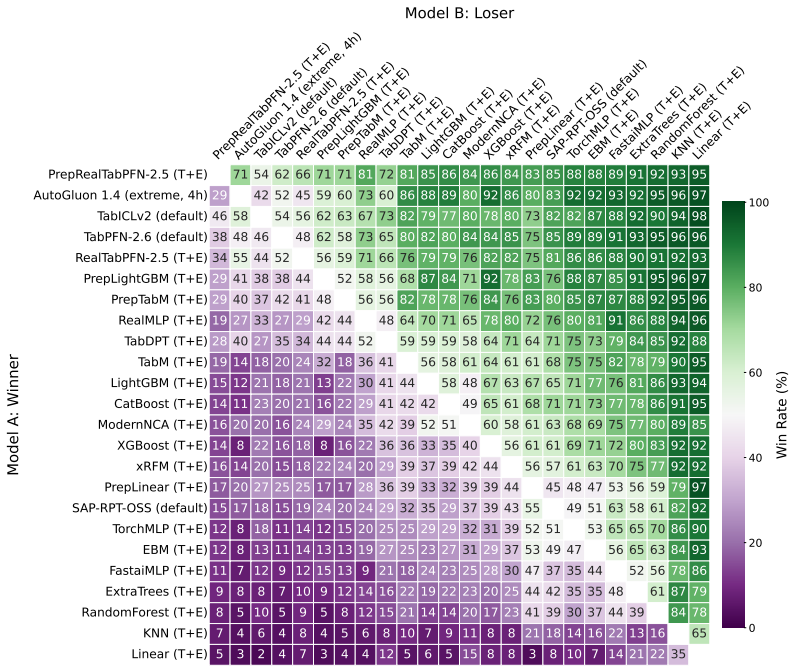
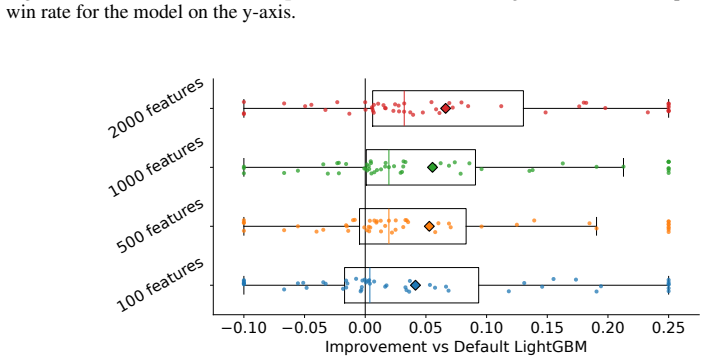
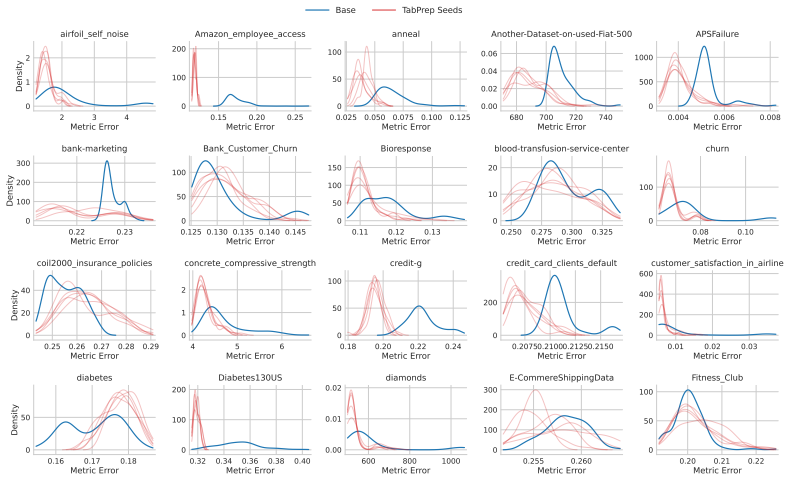
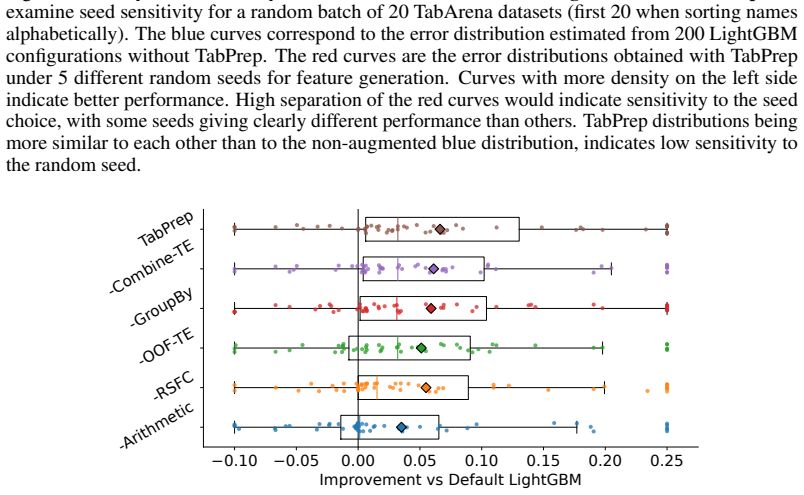
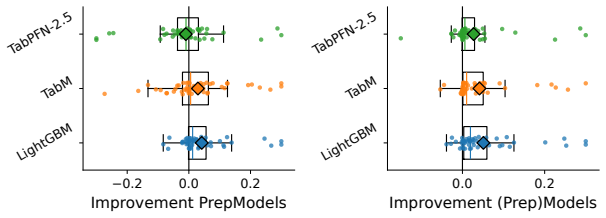
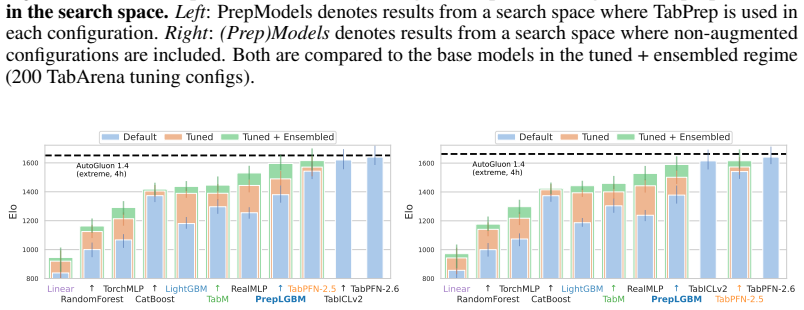
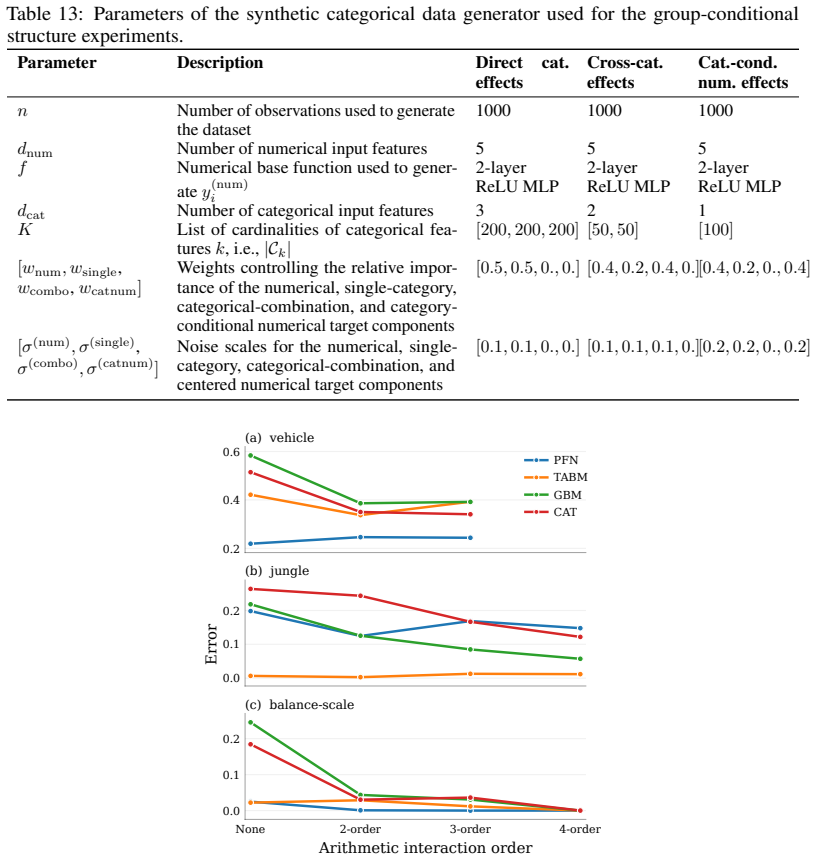

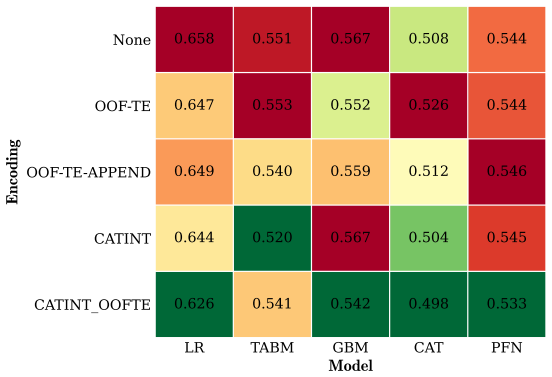
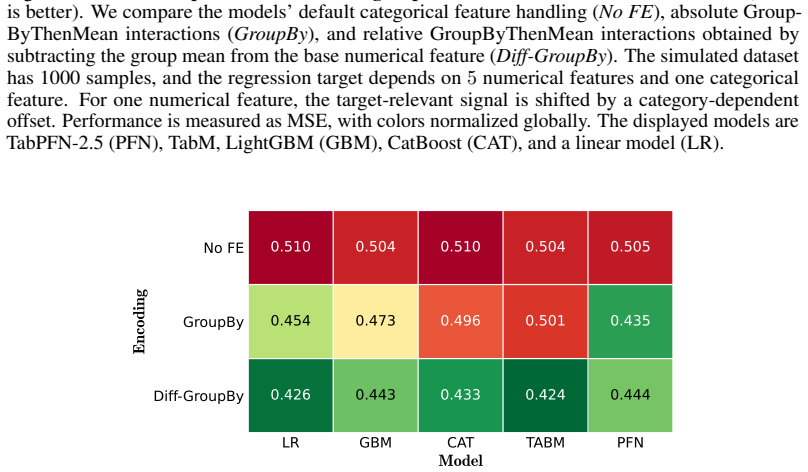
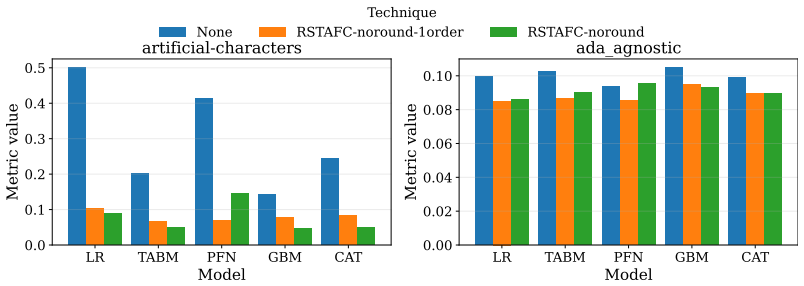

read the original abstract
Progress in tabular machine learning has largely focused on increasingly sophisticated model architectures. At the same time, feature engineering remains a critical yet underexplored component of real-world modeling pipelines that is entirely absent from modern benchmarks, which creates an unquantified evaluation gap. In this work, we introduce TabPrep, a lightweight preprocessing pipeline composed of feature generators that are carefully designed to target three specific structural data patterns. We show that many widely used model classes exhibit predictable blind spots to these patterns and that systematic feature engineering alone can establish new peak performance. Across the TabArena benchmark, integrating TabPrep into model training and tuning consistently improves performance for tree-based, neural, linear, and foundation models, often surpassing gains achieved by model-centric innovations alone. TabPrep outperforms previous automated feature engineering approaches in performance, efficiency, and applicability across datasets, enabling integration into large-scale benchmarks. By releasing TabPrep (see https://github.com/atschalz/tabprep), we enable researchers to integrate feature engineering into their benchmarking setup, filling a longstanding gap in tabular evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TabPrep, a lightweight preprocessing pipeline consisting of feature generators that target three specific structural data patterns in tabular data. The central claim is that widely used model classes (tree-based, neural, linear, and foundation models) exhibit predictable blind spots to these patterns, and that integrating TabPrep into training and tuning on the TabArena benchmark consistently improves performance, often surpassing gains from model-centric innovations alone. TabPrep is positioned as more efficient and broadly applicable than prior automated feature engineering methods, with open-source release to enable its use in large-scale benchmarks.
Significance. If the results hold, the work would be significant for tabular ML by providing a concrete, reproducible way to close the feature-engineering gap in benchmarks that currently focus almost exclusively on model architectures. The open-source release and emphasis on efficiency across model classes are strengths that could shift evaluation practices toward more realistic pipelines.
major comments (2)
- [§3] §3 (Pattern Selection and Generator Design): The manuscript provides no ablation or systematic justification for why these exact three structural patterns (rather than others) constitute the primary blind spots across model classes; without such evidence the claim that TabPrep systematically closes the benchmark gap does not follow from the TabArena results alone.
- [§5] §5 (TabArena Experiments): All reported gains are confined to the TabArena collection; no external datasets or cross-benchmark validation is presented to test whether the observed improvements generalize or whether equivalent gains could be obtained by generic preprocessing, which is load-bearing for the assertion that TabPrep establishes new peaks beyond model-centric advances.
minor comments (2)
- [Abstract] The abstract states performance improvements but contains no quantitative numbers, error bars, or dataset counts; adding a single sentence with key metrics would improve clarity.
- [§3] Notation for the three structural patterns is introduced without an explicit summary table; a small table listing each pattern, the corresponding generator, and the targeted model blind spot would aid readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. Below we respond point-by-point to the two major comments. Where the comments identify gaps that can be addressed by additional analysis or experiments, we commit to revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Pattern Selection and Generator Design): The manuscript provides no ablation or systematic justification for why these exact three structural patterns (rather than others) constitute the primary blind spots across model classes; without such evidence the claim that TabPrep systematically closes the benchmark gap does not follow from the TabArena results alone.
Authors: The three patterns were chosen after reviewing prior literature on tabular data characteristics that are known to challenge standard model families (e.g., interaction effects, missing-value mechanisms, and scale heterogeneity). Preliminary experiments on a subset of TabArena datasets confirmed that these patterns produced measurable performance drops when left unaddressed. We acknowledge, however, that a systematic ablation comparing these patterns against plausible alternatives was not included. In the revised manuscript we will add such an ablation (both on pattern inclusion and on alternative generators) to provide the requested justification. revision: yes
-
Referee: [§5] §5 (TabArena Experiments): All reported gains are confined to the TabArena collection; no external datasets or cross-benchmark validation is presented to test whether the observed improvements generalize or whether equivalent gains could be obtained by generic preprocessing, which is load-bearing for the assertion that TabPrep establishes new peaks beyond model-centric advances.
Authors: TabArena was selected because it is currently the largest and most standardized tabular benchmark that already controls for model tuning. Nevertheless, we agree that demonstrating generalization beyond this collection is important. In the revised manuscript we will report results on at least two additional public tabular datasets drawn from sources outside TabArena, together with a comparison against generic preprocessing baselines, to address the concern about external validity. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation is self-contained
full rationale
The paper introduces TabPrep as a preprocessing pipeline targeting three structural patterns and evaluates its impact via direct performance comparisons on the TabArena benchmark across model classes. All load-bearing claims (performance gains, outperformance of prior automated FE) are grounded in external empirical results rather than any derivation, equation, or self-citation that reduces to the paper's own inputs by construction. No self-definitional steps, fitted-input predictions, or uniqueness theorems appear; the work is a standard empirical contribution whose validity can be checked against the released code and benchmark data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tabpfn-2.6
Prior Labs. Tabpfn-2.6. https://huggingface.co/Prior-Labs/tabpfn_2_6, 2025. Hug- ging Face model card, version v1.0
2025
-
[2]
arXiv preprint arXiv:2602.11139 , year =
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. Tabiclv2: A better, faster, scalable, and open tabular foundation model.arXiv preprint arXiv:2602.11139, 2026
-
[3]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second.arXiv preprint arXiv:2207.01848, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Sascha Marton, Stefan Lüdtke, Christian Bartelt, and Heiner Stuckenschmidt. Grande: Gradient- based decision tree ensembles for tabular data.arXiv preprint arXiv:2309.17130, 2023
-
[5]
Better by default: Strong pre-tuned mlps and boosted trees on tabular data.Advances in Neural Information Processing Systems, 37:26577–26658, 2024
David Holzmüller, Léo Grinsztajn, and Ingo Steinwart. Better by default: Strong pre-tuned mlps and boosted trees on tabular data.Advances in Neural Information Processing Systems, 37:26577–26658, 2024
2024
-
[6]
Yury Gorishniy, Akim Kotelnikov, and Artem Babenko. Tabm: Advancing tabular deep learning with parameter-efficient ensembling.arXiv preprint arXiv:2410.24210, 2024. 10
-
[7]
Andrej Tschalzev, Paul Nitschke, Lukas Kirchdorfer, Stefan Lüdtke, Christian Bartelt, and Heiner Stuckenschmidt. Enabling mixed effects neural networks for diverse, clustered data using monte carlo methods.arXiv preprint arXiv:2407.01115, 2024
-
[8]
arXiv preprint arXiv:2410.18164 , year=
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Hamidreza Kamkari, Alex Labach, Jesse C Cresswell, Keyvan Golestan, Guangwei Yu, Maksims V olkovs, and Anthony L Caterini. Tabdpt: Scaling tabular foundation models.arXiv preprint arXiv:2410.18164, 2024
-
[9]
Han-Jia Ye, Huai-Hong Yin, and De-Chuan Zhan. Modern neighborhood components analysis: A deep tabular baseline two decades later.arXiv preprint arXiv:2407.03257, 2024
-
[10]
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. Tabicl: A tabular foundation model for in-context learning on large data.arXiv preprint arXiv:2502.05564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, et al. Tabpfn-2.5: Advancing the state of the art in tabular foundation models.arXiv preprint arXiv:2511.08667, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Xingxuan Zhang, Gang Ren, Han Yu, Hao Yuan, Hui Wang, Jiansheng Li, Jiayun Wu, Lang Mo, Li Mao, Mingchao Hao, et al. Limix: Unleashing structured-data modeling capability for generalist intelligence.arXiv preprint arXiv:2509.03505, 2025
-
[13]
Xiyuan Zhang, Danielle C Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W Mahoney, et al. Mitra: Mixed synthetic priors for enhancing tabular foundation models.arXiv preprint arXiv:2510.21204, 2025
-
[14]
Contexttab: A semantics-aware tabular in-context learner.arXiv preprint arXiv:2506.10707, 2025
Marco Spinaci, Marek Polewczyk, Maximilian Schambach, and Sam Thelin. Contexttab: A semantics-aware tabular in-context learner.arXiv preprint arXiv:2506.10707, 2025
-
[15]
Manu Joseph. Pytorch tabular: A framework for deep learning with tabular data.arXiv preprint arXiv:2104.13638, 2021
-
[16]
Anton Frederik Thielmann and Soheila Samiee. On the efficiency of nlp-inspired methods for tabular deep learning.arXiv preprint arXiv:2411.17207, 2024
-
[17]
Large scale transfer learning for tabular data via language modeling
Joshua P Gardner, Juan Carlos Perdomo, and Ludwig Schmidt. Large scale transfer learning for tabular data via language modeling. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[18]
A data-centric perspective on evaluating machine learning models for tabular data
Andrej Tschalzev, Sascha Marton, Stefan Lüdtke, Christian Bartelt, and Heiner Stuckenschmidt. A data-centric perspective on evaluating machine learning models for tabular data. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
2024
-
[19]
Unreflected use of tabular data repositories can undermine research quality
Andrej Tschalzev, Lennart Purucker, Stefan Lüdtke, Frank Hutter, Christian Bartelt, and Heiner Stuckenschmidt. Unreflected use of tabular data repositories can undermine research quality. In The Future of Machine Learning Data Practices and Repositories at ICLR 2025, 2025
2025
-
[20]
2023 kaggle ai report, 2023
Bojan Tunguz, Dieter, Heads or Tails, Karnika Kapoor, Parul Pandey, Paul Mooney, Phil Culliton, Rob Mulla, Sanyam Bhutani, and Will Cukierski. 2023 kaggle ai report, 2023. URL https://kaggle.com/competitions/2023-kaggle-ai-report
2023
-
[21]
Ivan Rubachev, Nikolay Kartashev, Yury Gorishniy, and Artem Babenko. Tabred: Analyzing pit- falls and filling the gaps in tabular deep learning benchmarks.arXiv preprint arXiv:2406.19380, 2024
-
[22]
Openfe: Automated feature generation with expert-level performance
Tianping Zhang, Zheyu Aqa Zhang, Zhiyuan Fan, Haoyan Luo, Fengyuan Liu, Qian Liu, Wei Cao, and Li Jian. Openfe: Automated feature generation with expert-level performance. In International Conference on Machine Learning, pages 41880–41901. PMLR, 2023
2023
-
[23]
The autofeat python library for automated feature engineering and selection
Franziska Horn, Robert Pack, and Michael Rieger. The autofeat python library for automated feature engineering and selection. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 111–120. Springer, 2019
2019
-
[24]
How usable is automated feature engineering for tabular data?arXiv preprint arXiv:2508.13932, 2025
Bastian Schäfer, Lennart Purucker, Maciej Janowski, and Frank Hutter. How usable is automated feature engineering for tabular data?arXiv preprint arXiv:2508.13932, 2025
-
[25]
Hollmann, S
N. Hollmann, S. Müller, L. Purucker, A. Krishnakumar, M. Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025. 11
2025
-
[26]
TabArena: A Living Benchmark for Machine Learning on Tabular Data
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. Tabarena: A living benchmark for machine learning on tabular data.arXiv preprint arXiv:2506.16791, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems, 35:507–520, 2022
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems, 35:507–520, 2022
2022
-
[28]
When do neural nets outperform boosted trees on tabular data?Advances in Neural Information Processing Systems, 36:76336–76369, 2023
Duncan McElfresh, Sujay Khandagale, Jonathan Valverde, Vishak Prasad C, Ganesh Ramakr- ishnan, Micah Goldblum, and Colin White. When do neural nets outperform boosted trees on tabular data?Advances in Neural Information Processing Systems, 36:76336–76369, 2023
2023
-
[29]
Openml: Insights from 10 years and more than a thousand papers.Patterns, 2025
Bernd Bischl, Giuseppe Casalicchio, Taniya Das, Matthias Feurer, Sebastian Fischer, Pieter Gijsbers, Subhaditya Mukherjee, Andreas C Müller, László Németh, Luis Oala, et al. Openml: Insights from 10 years and more than a thousand papers.Patterns, 2025
2025
- [31]
-
[32]
Revisiting deep learning models for tabular data.Advances in neural information processing systems, 34: 18932–18943, 2021
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data.Advances in neural information processing systems, 34: 18932–18943, 2021
2021
-
[33]
Lennart Purucker and Joeran Beel. Assembled-openml: creating efficient benchmarks for ensembles in automl with openml.arXiv preprint arXiv:2307.00285, 2023
-
[34]
Benchmarking distribution shift in tabular data with tableshift.Advances in Neural Information Processing Systems, 36:53385–53432, 2023
Josh Gardner, Zoran Popovic, and Ludwig Schmidt. Benchmarking distribution shift in tabular data with tableshift.Advances in Neural Information Processing Systems, 36:53385–53432, 2023
2023
-
[35]
Tabrepo: A large scale repository of tabular model evaluations and its automl applications
David Salinas and Nick Erickson. Tabrepo: A large scale repository of tabular model evaluations and its automl applications. InAutoML Conference 2024 (ABCD Track), 2024
2024
-
[36]
Towards quantifying the effect of datasets for benchmarking: A look at tabular machine learning
Ravin Kohli, Matthias Feurer, Katharina Eggensperger, Bernd Bischl, and Frank Hutter. Towards quantifying the effect of datasets for benchmarking: A look at tabular machine learning. In ICLR Workshop, volume 2, page 6, 2024
2024
-
[37]
Assaf Shmuel, Oren Glickman, and Teddy Lazebnik. A comprehensive benchmark of machine and deep learning across diverse tabular datasets.arXiv preprint arXiv:2408.14817, 2024
-
[38]
Guri Zabërgja, Arlind Kadra, Christian Frey, and Josif Grabocka. Is deep learning finally better than decision trees on tabular data?arXiv preprint arXiv:2402.03970, 2024
-
[39]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. 12:2825–2830, 2011
2011
-
[40]
Feature-engine: A python package for feature engineering for machine learning
Soledad Galli. Feature-engine: A python package for feature engineering for machine learning. Journal of Open Source Software, 6(65):3642, 2021
2021
-
[41]
Category encoders: a scikit-learn- contrib package of transformers for encoding categorical data.Journal of Open Source Software, 3(21):501, 2018
William D McGinnis, Chapman Siu, Hanyu Huang, et al. Category encoders: a scikit-learn- contrib package of transformers for encoding categorical data.Journal of Open Source Software, 3(21):501, 2018
2018
-
[42]
Special issue on feature engineering editorial.Machine learning, 113(7):3917–3928, 2024
Tim Verdonck, Bart Baesens, María Óskarsdóttir, and Seppe vanden Broucke. Special issue on feature engineering editorial.Machine learning, 113(7):3917–3928, 2024
2024
-
[43]
Climb: Class-imbalanced learning benchmark on tabular data.arXiv preprint arXiv:2505.17451, 2025
Zhining Liu, Zihao Li, Ze Yang, Tianxin Wei, Jian Kang, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. Climb: Class-imbalanced learning benchmark on tabular data.arXiv preprint arXiv:2505.17451, 2025
-
[44]
Imputation for prediction: beware of diminishing returns.arXiv preprint arXiv:2407.19804, 2024
Marine Le Morvan and Gaël Varoquaux. Imputation for prediction: beware of diminishing returns.arXiv preprint arXiv:2407.19804, 2024
-
[45]
AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications
Luo Yuanfei, Wang Mengshuo, Zhou Hao, Yao Quanming, Tu WeiWei, Chen Yuqiang, Yang Qiang, and Dai Wenyuan. Autocross: Automatic feature crossing for tabular data in real-world applications.arXiv preprint arXiv:1904.12857, 2019. 12
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[46]
Deep feature synthesis: Towards automating data science endeavors
James Max Kanter and Kalyan Veeramachaneni. Deep feature synthesis: Towards automating data science endeavors. In2015 IEEE international conference on data science and advanced analytics (DSAA), pages 1–10. IEEE, 2015
2015
-
[47]
Auto- mated data science for relational data
Hoang Thanh Lam, Beat Buesser, Hong Min, Tran Ngoc Minh, Martin Wistuba, Udayan Khurana, Gregory Bramble, Theodoros Salonidis, Dakuo Wang, and Horst Samulowitz. Auto- mated data science for relational data. In2021 IEEE 37th International Conference on Data Engineering (ICDE), pages 2689–2692. IEEE, 2021
2021
-
[48]
Generalized and heuristic-free feature construction for improved accuracy
Wei Fan, Erheng Zhong, Jing Peng, Olivier Verscheure, Kun Zhang, Jiangtao Ren, Rong Yan, and Qiang Yang. Generalized and heuristic-free feature construction for improved accuracy. InProceedings of the 2010 SIAM International Conference on Data Mining, pages 629–640. SIAM, 2010
2010
-
[49]
Safe: Scalable automatic feature engineering framework for industrial tasks
Qitao Shi, Ya-Lin Zhang, Longfei Li, Xinxing Yang, Meng Li, and Jun Zhou. Safe: Scalable automatic feature engineering framework for industrial tasks. In2020 IEEE 36th International Conference on Data Engineering (ICDE), pages 1645–1656. IEEE, 2020
2020
-
[50]
Learning feature engineering for classification
Fatemeh Nargesian, Horst Samulowitz, Udayan Khurana, Elias B Khalil, and Deepak S Turaga. Learning feature engineering for classification. InIjcai, volume 17, pages 2529–2535, 2017
2017
-
[51]
Bioautoml: automated feature engineering and metalearning to predict noncoding rnas in bacteria.Briefings in Bioinformatics, 23(4):bbac218, 2022
Robson P Bonidia, Anderson P Avila Santos, Breno LS de Almeida, Peter F Stadler, Ulisses N da Rocha, Danilo S Sanches, and André CPLF de Carvalho. Bioautoml: automated feature engineering and metalearning to predict noncoding rnas in bacteria.Briefings in Bioinformatics, 23(4):bbac218, 2022
2022
-
[52]
Adafs: Adaptive feature selection in deep recommender system
Weilin Lin, Xiangyu Zhao, Yejing Wang, Tong Xu, and Xian Wu. Adafs: Adaptive feature selection in deep recommender system. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, pages 3309–3317, 2022
2022
-
[53]
An introduction to variable and feature selection.Journal of machine learning research, 3(Mar):1157–1182, 2003
Isabelle Guyon and André Elisseeff. An introduction to variable and feature selection.Journal of machine learning research, 3(Mar):1157–1182, 2003
2003
-
[54]
Hybrid bag-of-visual-words and featurewiz selection for content-based visual information retrieval
Samy Bakheet, Ayoub Al-Hamadi, Emadeldeen Soliman, and Mohamed Heshmat. Hybrid bag-of-visual-words and featurewiz selection for content-based visual information retrieval. Sensors, 23(3):1653, 2023
2023
-
[55]
Feature selection for high-dimensional data: A fast correlation-based filter solution
Lei Yu and Huan Liu. Feature selection for high-dimensional data: A fast correlation-based filter solution. InProceedings of the 20th international conference on machine learning (ICML-03), pages 856–863, 2003
2003
-
[56]
Feature selection with the boruta package.Journal of statistical software, 36:1–13, 2010
Miron B Kursa and Witold R Rudnicki. Feature selection with the boruta package.Journal of statistical software, 36:1–13, 2010
2010
-
[57]
Concrete autoencoders: Differentiable feature selection and reconstruction
Muhammed Fatih Balın, Abubakar Abid, and James Zou. Concrete autoencoders: Differentiable feature selection and reconstruction. InInternational conference on machine learning, pages 444–453. PMLR, 2019
2019
-
[58]
Feature selection using stochastic gates
Yutaro Yamada, Ofir Lindenbaum, Sahand Negahban, and Yuval Kluger. Feature selection using stochastic gates. InInternational conference on machine learning, pages 10648–10659. PMLR, 2020
2020
-
[59]
A tutorial-based survey on feature selection: Recent advancements on feature selection.Engineering applications of artificial intelligence, 126:107136, 2023
Amir Moslemi. A tutorial-based survey on feature selection: Recent advancements on feature selection.Engineering applications of artificial intelligence, 126:107136, 2023
2023
-
[60]
A performance-driven benchmark for feature selection in tabular deep learning.Advances in Neural Information Processing Systems, 36:41956–41979, 2023
Valeriia Cherepanova, Roman Levin, Gowthami Somepalli, Jonas Geiping, C Bayan Bruss, Andrew G Wilson, Tom Goldstein, and Micah Goldblum. A performance-driven benchmark for feature selection in tabular deep learning.Advances in Neural Information Processing Systems, 36:41956–41979, 2023
2023
-
[61]
Analysis and compar- ison of feature selection methods towards performance and stability.Expert Systems with Applications, 249:123667, 2024
Matheus Cezimbra Barbieri, Bruno Iochins Grisci, and Márcio Dorn. Analysis and compar- ison of feature selection methods towards performance and stability.Expert Systems with Applications, 249:123667, 2024
2024
-
[62]
Noah Hollmann, Samuel Müller, and Frank Hutter. Large language models for automated data science: Introducing caafe for context-aware automated feature engineering.Advances in Neural Information Processing Systems, 36:44753–44775, 2023
2023
-
[63]
LLM-FE: Automated Feature Engineering for Tabular Data with LLMs as Evolutionary Optimizers
Nikhil Abhyankar, Parshin Shojaee, and Chandan K Reddy. Llm-fe: Automated feature engi- neering for tabular data with llms as evolutionary optimizers.arXiv preprint arXiv:2503.14434, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Jaris Küken, Lennart Purucker, and Frank Hutter. Large language models engineer too many simple features for tabular data.arXiv preprint arXiv:2410.17787, 2024
-
[65]
Elephants never forget: Memorization and learning of tabular data in large language models
Sebastian Bordt, Harsha Nori, Vanessa Cristiny Rodrigues Vasconcelos, Besmira Nushi, and Rich Caruana. Elephants never forget: Memorization and learning of tabular data in large language models. InFirst Conference on Language Modeling, 2024
2024
-
[66]
Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989
1989
-
[67]
T. M. Mitchell. The need for biases in learning generalizations. Technical report, Computer Science Department, Rutgers University, New Brunswick, MA, 1980
1980
-
[68]
A model of inductive bias learning.Journal of artificial intelligence research, 12:149–198, 2000
Jonathan Baxter. A model of inductive bias learning.Journal of artificial intelligence research, 12:149–198, 2000
2000
-
[69]
Neural arithmetic logic units.Advances in neural information processing systems, 31, 2018
Andrew Trask, Felix Hill, Scott E Reed, Jack Rae, Chris Dyer, and Phil Blunsom. Neural arithmetic logic units.Advances in neural information processing systems, 31, 2018
2018
-
[70]
Neural arithmetic units.arXiv preprint arXiv:2001.05016, 2020
Andreas Madsen and Alexander Rosenberg Johansen. Neural arithmetic units.arXiv preprint arXiv:2001.05016, 2020
-
[71]
Rodrigo Nogueira, Zhiying Jiang, and Jimmy Lin. Investigating the limitations of transformers with simple arithmetic tasks.arXiv preprint arXiv:2102.13019, 2021
-
[72]
Springer, 2009
Alain F Zuur, Elena N Ieno, Neil J Walker, Anatoly A Saveliev, Graham M Smith, et al.Mixed effects models and extensions in ecology with R, volume 574. Springer, 2009
2009
-
[73]
lme4: Mixed-effects modeling with r, 2010
Douglas M Bates. lme4: Mixed-effects modeling with r, 2010
2010
-
[74]
Linear mixed-effects model
Andrzej Gałecki and Tomasz Burzykowski. Linear mixed-effects model. InLinear mixed-effects models using R: a step-by-step approach, pages 245–273. Springer, 2012
2012
-
[75]
Regularized target encoding outperforms traditional methods in supervised machine learning with high cardinality features
Florian Pargent, Florian Pfisterer, Janek Thomas, and Bernd Bischl. Regularized target encoding outperforms traditional methods in supervised machine learning with high cardinality features. Computational Statistics, 37(5):2671–2692, 2022
2022
-
[76]
Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
2017
-
[77]
Catboost: unbiased boosting with categorical features.Advances in neural information processing systems, 31, 2018
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin. Catboost: unbiased boosting with categorical features.Advances in neural information processing systems, 31, 2018
2018
-
[78]
A preprocessing scheme for high-cardinality categorical attributes in classification and prediction problems.ACM SIGKDD explorations newsletter, 3(1):27–32, 2001
Daniele Micci-Barreca. A preprocessing scheme for high-cardinality categorical attributes in classification and prediction problems.ACM SIGKDD explorations newsletter, 3(1):27–32, 2001
2001
- [79]
-
[80]
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
N. Erickson, J. Mueller, A. Shirkov, H. Zhang, P. Larroy, M. Li, and A. Smola. Autogluon- tabular: Robust and accurate automl for structured data.arXiv:2003.06505 [stat.ML], 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[81]
L. Breiman. Random forests. 45:5–32, 2001
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.