RASER: Recoverability-Aware Selective Escalation Router for Multi-Hop Question Answering
Pith reviewed 2026-06-28 14:42 UTC · model grok-4.3
The pith
RASER routers use features from a single one-shot RAG pass to decide when to escalate retrieval in multi-hop question answering, matching state-of-the-art accuracy at reduced token cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
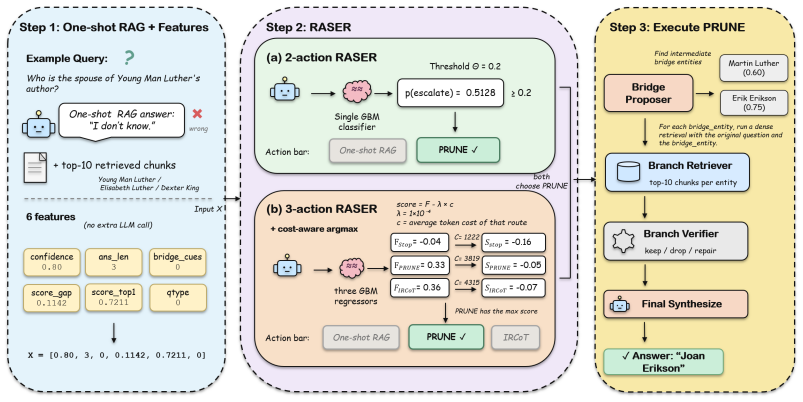
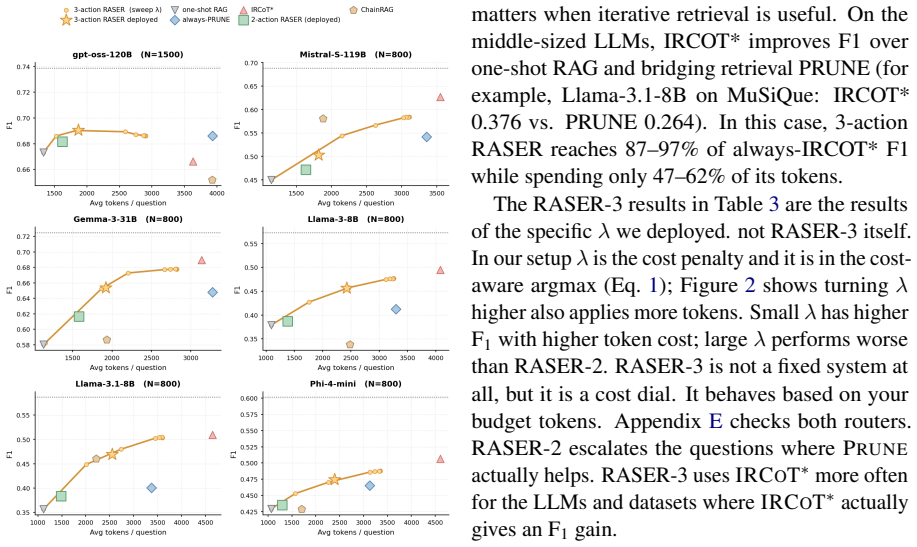
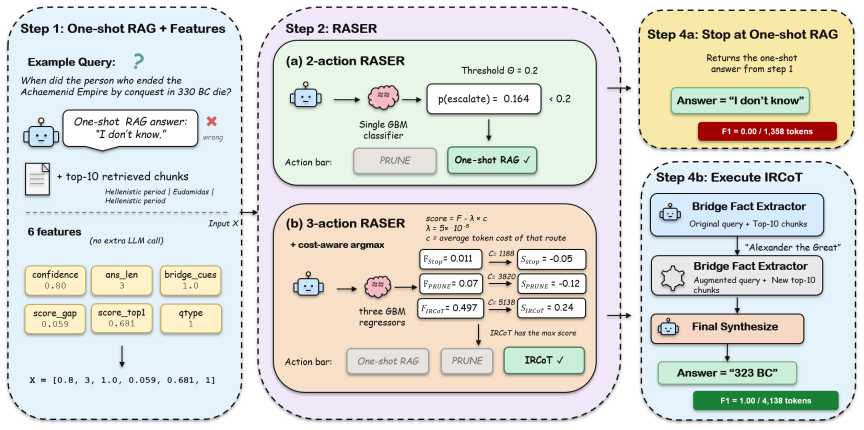
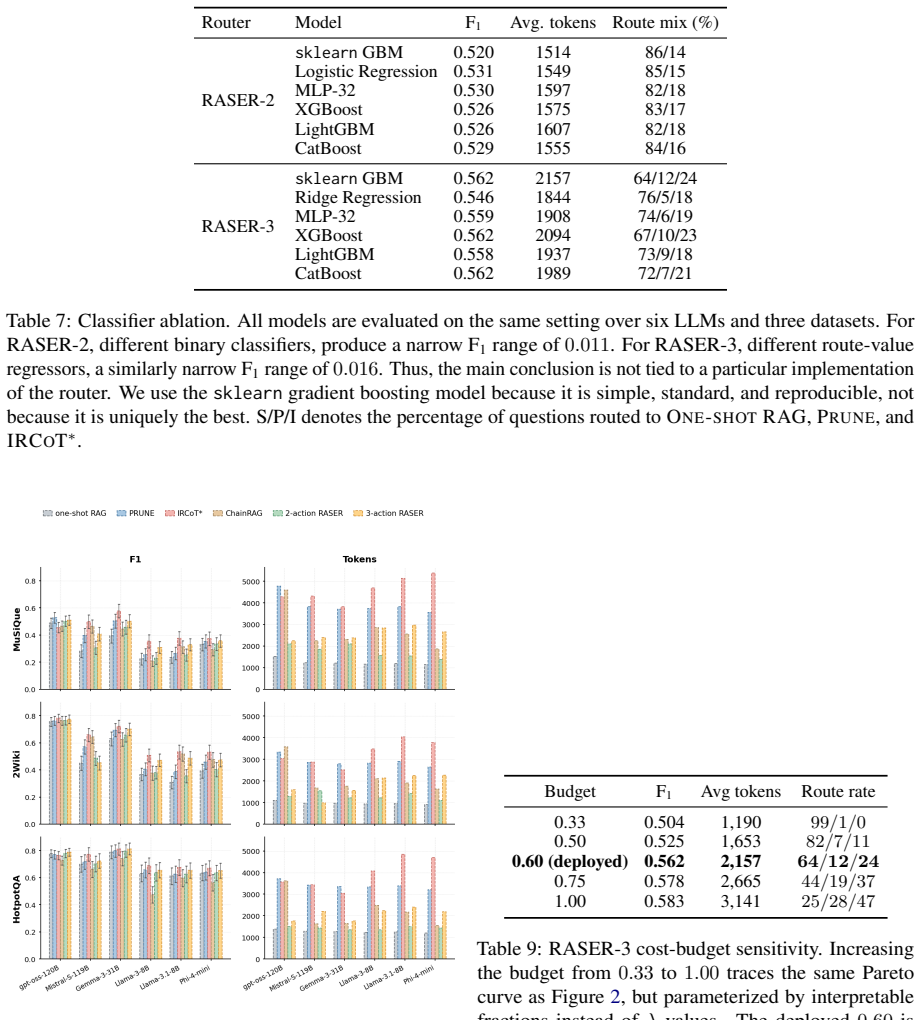
RASER is a family of routers built on one-shot RAG and six features from it. RASER-2 decides whether to stop or escalate to PRUNE. RASER-3 chooses among one-shot RAG, PRUNE, and IRCoT using the same features but adding an explicit cost-accuracy trade-off. Neither makes an extra LLM call. Across six LLMs and three benchmarks, they stay competitive in F1 while spending only 41-49% of always-prune's tokens and less than iterative and decomposition baselines.
What carries the argument
The RASER router, which predicts recoverability from six features extracted from a one-shot RAG pass to decide on selective escalation without additional LLM calls.
If this is right
- RASER-2 and RASER-3 achieve competitive F1 scores with only 41-49% of the tokens used by always-prune.
- The approach works across six different LLMs and three multi-hop QA benchmarks.
- RASER-3 provides an explicit trade-off between cost and accuracy by choosing among three strategies.
- No extra LLM calls are needed for the routing decision itself.
Where Pith is reading between the lines
- Similar feature-based routing could reduce costs in other multi-step LLM tasks beyond QA.
- If the six features capture recoverability well, the method might generalize to new retrieval strategies not tested here.
- Deploying such routers could make multi-hop systems more practical under tight token budgets.
- Testing on larger or more diverse question sets might reveal limits in the feature set's predictive power.
Load-bearing premise
The six features from a single one-shot RAG pass are sufficient to accurately predict whether a question needs escalated retrieval.
What would settle it
Running the routers on a held-out multi-hop QA benchmark where their selected strategies yield F1 scores substantially below those of always using PRUNE or IRCoT would show the prediction is not reliable.
Figures

read the original abstract
Multi-hop question-answering systems often use expensive retrieval on every question. They may decompose the question, run several retrieval rounds, or search through bridge entities before answering. All of these strategies rely on repeated LLM calls to rewrite or decompose the question, which increases extra token cost, and it is not fitting when the LLM budget is tight. However, our analysis shows that lots of multi-hop questions are already answered correctly by a single one-shot RAG, so running an extra retrieval on every question wastes the budget. We introduce RASER (Recoverability-Aware Selective Escalation Router), a family of cheap routers built on one-shot RAG and six features from it. RASER-2 decides whether to stop or escalate to the extra-retrieval action PRUNE. RASER-3 chooses among one-shot RAG, PRUNE, and iterative retrieval IRCoT, using the same features but adding an explicit cost-accuracy trade-off. Neither router makes an extra LLM call to decide. Across six LLMs and three multi-hop QA benchmarks, both routers stay competitive with the other state-of-the-art (SOTA) baselines in F1 while spending only 41-49% of always-prune's tokens and also less than the iterative and decomposition retrieval baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
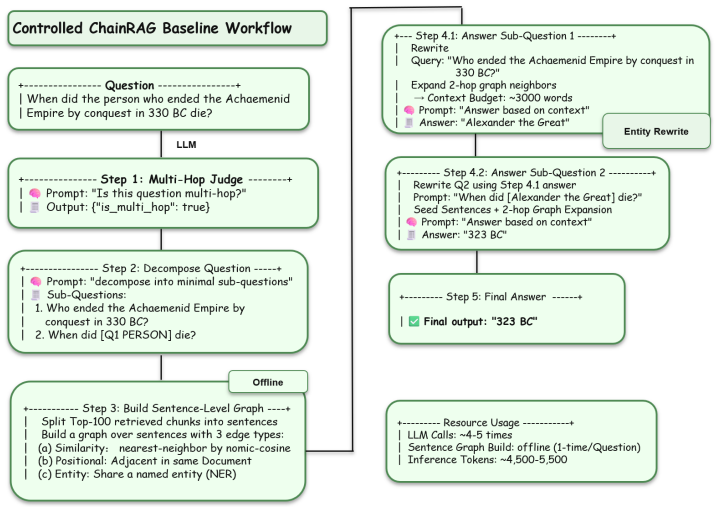
Summary. The paper introduces RASER (Recoverability-Aware Selective Escalation Router), a family of routers for multi-hop QA that extract six features from a single one-shot RAG pass to decide escalation without extra LLM calls. RASER-2 routes between one-shot RAG and PRUNE; RASER-3 adds IRCoT with an explicit cost-accuracy tradeoff. The central claim is that both variants remain competitive with SOTA baselines in F1 across six LLMs and three benchmarks while using only 41-49% of always-prune tokens and fewer tokens than iterative or decomposition baselines.
Significance. If the recoverability prediction from the six features holds, the work offers a practical, low-overhead method to avoid unnecessary expensive retrieval on questions already solvable by one-shot RAG, directly addressing token budgets in multi-hop QA. The no-extra-LLM-call design and evaluation across multiple LLMs and benchmarks are strengths that support potential impact in resource-constrained settings.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the headline F1-competitiveness and 41-49% token claim is load-bearing on the six one-shot RAG features being sufficient predictors of recoverability. No ablation or error analysis is described showing that these features capture (or fail to capture) cases such as missing bridge entities or multi-fact signals not reflected in the chosen statistics; without this, it is unclear whether the router systematically under- or over-escalates.
- [§4] §4 (experiments): the reported F1 and token numbers lack details on data splits, number of runs, variance, or statistical tests for the claimed competitiveness versus baselines. This information is required to verify that the efficiency-accuracy tradeoff is robust rather than an artifact of a particular split or single run.
minor comments (2)
- [§3] Notation for the six features should be introduced with explicit formulas or pseudocode in §3 rather than left as high-level descriptions.
- [Figures/Tables] Figure or table captions should explicitly state the exact token budgets and F1 values for RASER-2/3 versus each baseline to improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below and commit to revisions that strengthen the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the headline F1-competitiveness and 41-49% token claim is load-bearing on the six one-shot RAG features being sufficient predictors of recoverability. No ablation or error analysis is described showing that these features capture (or fail to capture) cases such as missing bridge entities or multi-fact signals not reflected in the chosen statistics; without this, it is unclear whether the router systematically under- or over-escalates.
Authors: We agree that the current manuscript lacks a dedicated ablation or error analysis examining how the six features perform on specific recoverability failure modes such as missing bridge entities or unreflected multi-fact signals. In the revision we will add a new subsection in §4 that includes (i) an error analysis of under- and over-escalation cases with qualitative examples drawn from the three benchmarks and (ii) a targeted ablation that isolates the contribution of each feature to recoverability prediction. This will directly address whether the chosen statistics systematically miss certain multi-hop signals. revision: yes
-
Referee: [§4] §4 (experiments): the reported F1 and token numbers lack details on data splits, number of runs, variance, or statistical tests for the claimed competitiveness versus baselines. This information is required to verify that the efficiency-accuracy tradeoff is robust rather than an artifact of a particular split or single run.
Authors: We acknowledge the omission of these experimental details. The revised §4 will report: the exact train/validation/test splits used for each benchmark, the number of independent runs (with different random seeds), standard deviation or confidence intervals on F1 and token counts, and the results of paired statistical tests (e.g., t-tests) comparing RASER variants against the strongest baselines. These additions will substantiate the robustness of the reported efficiency-accuracy trade-offs. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces RASER as an empirical router that extracts six features from one-shot RAG to decide escalation (to PRUNE or IRCoT) without extra LLM calls. Its claims are supported by direct experimental comparisons of F1 and token cost on external multi-hop QA benchmarks across six LLMs. No equations, fitted parameters renamed as predictions, or self-citation chains are present that would reduce the reported efficiency-accuracy trade-off to a definitional identity or input fit. The recoverability prediction is a standard supervised classification task whose success is measured against held-out benchmark outcomes rather than by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[2]
Ho, Xanh and Duong Nguyen, Anh-Khoa and Sugawara, Saku and Aizawa, Akiko. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.580
-
[3]
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish. ♫ M u S i Q ue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00475
-
[4]
Jeong, Soyeong and Baek, Jinheon and Cho, Sukmin and Hwang, Sung Ju and Park, Jong. Adaptive- RAG : Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). ...
-
[5]
Mitigating Lost-in-Retrieval Problems in Retrieval Augmented Multi-Hop Question Answering
Zhu, Rongzhi and Liu, Xiangyu and Sun, Zequn and Wang, Yiwei and Hu, Wei. Mitigating Lost-in-Retrieval Problems in Retrieval Augmented Multi-Hop Question Answering. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1089
-
[6]
K i RAG : Knowledge-Driven Iterative Retriever for Enhancing Retrieval-Augmented Generation
Fang, Jinyuan and Meng, Zaiqiao and MacDonald, Craig. K i RAG : Knowledge-Driven Iterative Retriever for Enhancing Retrieval-Augmented Generation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.929
-
[7]
D eep S ieve: Information Sieving via LLM -as-a-Knowledge-Router
Guo, Minghao and Zeng, Qingcheng and Zhao, Xujiang and Liu, Yanchi and Yu, Wenchao and Du, Mengnan and Chen, Haifeng and Cheng, Wei. D eep S ieve: Information Sieving via LLM -as-a-Knowledge-Router. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026. doi:10.18653/v1/2026.findings-eacl.160
-
[8]
2026 , eprint=
A2RAG: Adaptive Agentic Graph Retrieval for Cost-Aware and Reliable Reasoning , author=. 2026 , eprint=
2026
-
[9]
2026 , eprint=
BridgeRAG: Training-Free Bridge-Conditioned Retrieval for Multi-Hop Question Answering , author=. 2026 , eprint=
2026
-
[10]
2026 , eprint=
Doctor-RAG: Failure-Aware Repair for Agentic Retrieval-Augmented Generation , author=. 2026 , eprint=
2026
-
[11]
Selective Classification for Deep Neural Networks , url =
Geifman, Yonatan and El-Yaniv, Ran , booktitle =. Selective Classification for Deep Neural Networks , url =
-
[12]
Xu and Luyu Gao and Zhiqing Sun and Qian Liu and Jane Dwivedi
Jiang, Zhengbao and Xu, Frank and Gao, Luyu and Sun, Zhiqing and Liu, Qian and Dwivedi-Yu, Jane and Yang, Yiming and Callan, Jamie and Neubig, Graham. Active Retrieval Augmented Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.495
-
[13]
2023 , eprint=
Decomposed Prompting: A Modular Approach for Solving Complex Tasks , author=. 2023 , eprint=
2023
-
[14]
Measuring and Narrowing the Compositionality Gap in Language Models
Press, Ofir and Zhang, Muru and Min, Sewon and Schmidt, Ludwig and Smith, Noah and Lewis, Mike. Measuring and Narrowing the Compositionality Gap in Language Models. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.378
-
[15]
Findings of the Association for Computational Linguistics: EMNLP 2023 , month = dec, year =
Shao, Zhihong and Gong, Yeyun and Shen, Yelong and Huang, Minlie and Duan, Nan and Chen, Weizhu. Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.620
-
[16]
We are to start with the Navigator’s Guide:
Su, Weihang and Tang, Yichen and Ai, Qingyao and Wu, Zhijing and Liu, Yiqun. DRAGIN : Dynamic Retrieval Augmented Generation based on the Real-time Information Needs of Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.702
-
[17]
The Eleventh International Conference on Learning Representations , year=
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[18]
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish. Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.557
-
[19]
2018 , eprint=
Scikit-learn: Machine Learning in Python , author=. 2018 , eprint=
2018
-
[20]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[21]
2026 , howpublished =
Introducing Mistral Small 4 , author =. 2026 , howpublished =
2026
-
[22]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[23]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[24]
2025 , eprint=
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
Nomic Embed: Training a Reproducible Long Context Text Embedder , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.