MORPHOS: Autoregressive 4D Generation with Temporal Structured Latents
Pith reviewed 2026-06-28 15:01 UTC · model grok-4.3
The pith
MORPHOS autoregressively generates dynamic 3D assets from videos using temporal structured latents that support multiple representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
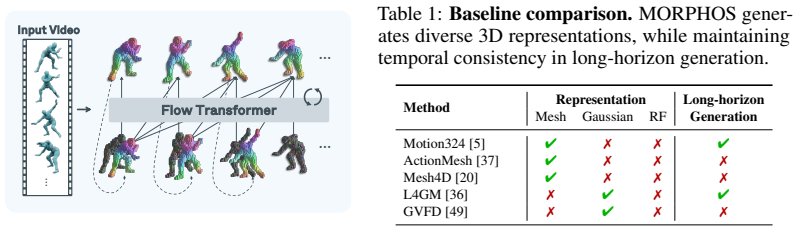
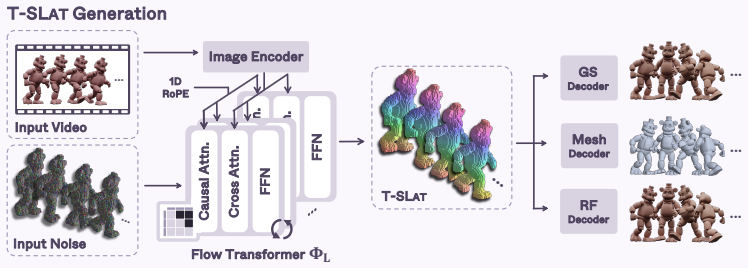
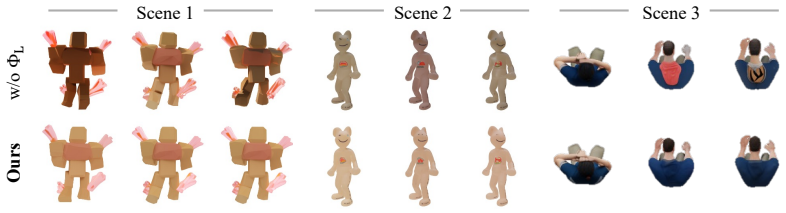
MORPHOS is a novel autoregressive framework that generates dynamic 3D assets from videos across diverse representations, including meshes, 3D Gaussians, and radiance fields, by introducing the Temporal Structured Latents (T-SLAT), a unified 4D representation that jointly encodes geometry and appearance along the temporal dimension, and leveraging it with causal attention to condition each frame on its preceding history for temporal consistency while handling evolving topologies, along with a temporal-structural augmentation to mitigate error accumulation.
What carries the argument
Temporal Structured Latents (T-SLAT), a unified 4D representation that jointly encodes geometry and appearance along the temporal dimension to enable autoregressive generation with causal attention.
If this is right
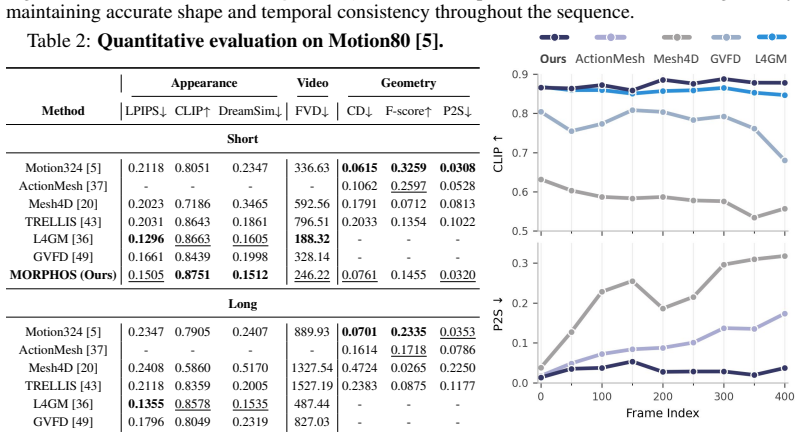
- State-of-the-art performance in appearance across multiple benchmarks.
- Competitive results in geometry.
- Superior generalization across various 3D representations.
- Robustness in long-horizon generation.
Where Pith is reading between the lines
- The causal conditioning could support interactive applications where users modify scenes mid-generation.
- Similar latent structures might apply to other sequential data like molecular dynamics or weather modeling.
- Reducing error accumulation opens the door to even longer sequence generation without retraining.
- Unified representation may simplify pipelines that currently switch between different 3D formats.
Load-bearing premise
The Temporal Structured Latents can jointly encode geometry and appearance along the temporal dimension to support autoregressive generation across meshes, Gaussians, and radiance fields.
What would settle it
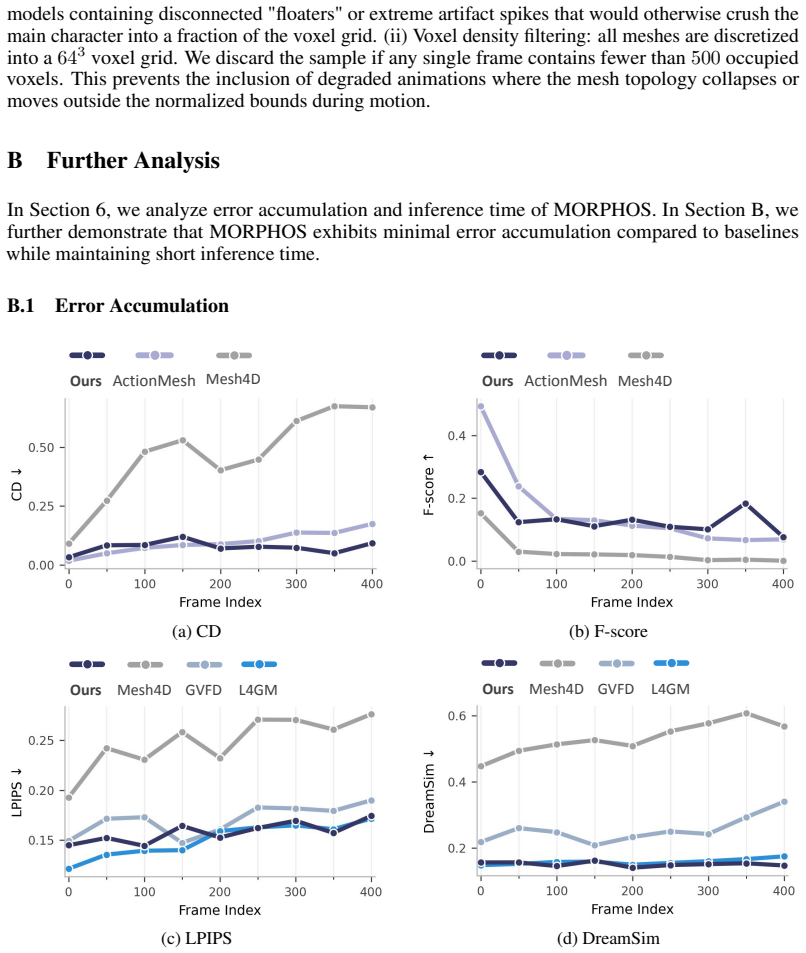
If generated assets show accumulating inconsistencies or fail to handle topology changes in long video sequences on the benchmarks, the effectiveness of the T-SLAT and autoregressive approach would be questioned.
Figures











read the original abstract
We present MORPHOS, a novel autoregressive framework that generates dynamic 3D assets from videos across diverse representations, including meshes, 3D Gaussians, and radiance fields. Existing methods are typically limited to a single representation, struggle to model topological changes, or fail to maintain temporal consistency over long videos. To address these limitations, we introduce the Temporal Structured Latents (T-SLAT), a unified 4D representation that jointly encodes geometry and appearance along the temporal dimension. Leveraging T-SLAT, MORPHOS autoregressively generates dynamic 3D assets via causal attention, conditioning each frame on its preceding history to ensure temporal consistency while handling evolving topologies. We also propose a temporal-structural augmentation to mitigate error accumulation in autoregressive generation. MORPHOS achieves state-of-the-art performance in appearance and competitive results in geometry across multiple benchmarks, demonstrating superior generalization across various representations and robustness in long-horizon generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MORPHOS, an autoregressive framework for generating dynamic 3D assets from videos across representations including meshes, 3D Gaussians, and radiance fields. It proposes Temporal Structured Latents (T-SLAT) as a unified 4D representation jointly encoding geometry and appearance along the temporal dimension. The method generates assets via causal attention, conditioning each frame on preceding history for temporal consistency while handling evolving topologies, and introduces a temporal-structural augmentation to mitigate error accumulation in autoregressive generation. It claims state-of-the-art appearance performance and competitive geometry results across multiple benchmarks, with superior generalization and robustness for long-horizon generation.
Significance. If the empirical claims are substantiated with detailed benchmarks and ablations, the work would be significant for unifying disparate 3D representations under a single autoregressive 4D model and for enabling consistent long-sequence generation with topological changes, which are open challenges in dynamic 3D content creation.
major comments (1)
- [Abstract] Abstract: The central claims of SOTA appearance performance and competitive geometry results are stated without any reference to specific quantitative metrics, baselines, benchmark datasets, or result tables, preventing verification of whether the data actually support the claims.
Simulated Author's Rebuttal
We thank the referee for their review and for identifying this issue with the abstract. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of SOTA appearance performance and competitive geometry results are stated without any reference to specific quantitative metrics, baselines, benchmark datasets, or result tables, preventing verification of whether the data actually support the claims.
Authors: We agree that the abstract presents the performance claims at a high level without explicit pointers to the supporting quantitative evidence. The body of the manuscript (Section 4) contains the detailed comparisons, including specific metrics, baselines, and benchmark datasets, along with the corresponding result tables. To improve verifiability directly from the abstract, we will revise it to include concise references to the relevant benchmarks and tables. revision: yes
Circularity Check
No significant circularity
full rationale
The provided abstract and description introduce T-SLAT as a new unified 4D representation and MORPHOS as an autoregressive framework using causal attention and temporal-structural augmentation. No equations, derivations, or load-bearing steps are shown that reduce predictions to fitted inputs, self-definitions, or self-citation chains. Performance claims are presented as empirical results on external benchmarks, with no indication that any central result is equivalent to its inputs by construction. The derivation chain appears self-contained against external evaluation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Temporal Structured Latents (T-SLAT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Method for registration of 3-d shapes
Paul J Besl and Neil D McKay. Method for registration of 3-d shapes. InSensor fusion IV: control paradigms and data structures, volume 1611, pages 586–606. Spie, 1992
1992
-
[2]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[3]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[4]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2025
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2025
2025
-
[5]
Motion 3-to-4: 3d motion reconstruction for 4d synthesis.arXiv preprint arXiv:2601.14253, 2026
Hongyuan Chen, Xingyu Chen, Youjia Zhang, Zexiang Xu, and Anpei Chen. Motion 3-to-4: 3d motion reconstruction for 4d synthesis.arXiv preprint arXiv:2601.14253, 2026
arXiv 2026
-
[6]
Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
Pith/arXiv arXiv 2025
-
[7]
Yiwen Chen, Zhihao Li, Yikai Wang, Hu Zhang, Qin Li, Chi Zhang, and Guosheng Lin. Ultra3d: Efficient and high-fidelity 3d generation with part attention.arXiv preprint arXiv:2507.17745, 2025
arXiv 2025
-
[8]
Objaverse-xl: A universe of 10m+ 3d objects.arXiv preprint arXiv:2307.05663, 2023
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl V ondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, and Ali Farhadi. Objaverse-xl: A universe of 10m+ 3d objects.arXiv preprint arXiv:2307.05663, 2023
Pith/arXiv arXiv 2023
-
[9]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. arXiv preprint arXiv:2212.08051, 2022
arXiv 2022
-
[10]
One step diffusion via shortcut models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models. arXiv preprint arXiv:2410.12557, 2024
Pith/arXiv arXiv 2024
-
[11]
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data.arXiv preprint arXiv:2306.09344, 2023
Pith/arXiv arXiv 2023
-
[12]
Kaifeng Gao, Jiaxin Shi, Hanwang Zhang, Chunping Wang, Jun Xiao, and Long Chen. Ca2-vdm: Efficient autoregressive video diffusion model with causal generation and cache sharing.arXiv preprint arXiv:2411.16375, 2024
arXiv 2024
-
[13]
Yuchao Gu, Weijia Mao, and Mike Zheng Shou. Long-context autoregressive video modeling with next-frame prediction.arXiv preprint arXiv:2503.19325, 2025
Pith/arXiv arXiv 2025
-
[14]
Sparseflex: High-resolution and arbitrary-topology 3d shape modeling
Xianglong He, Zi-Xin Zou, Chia-Hao Chen, Yuan-Chen Guo, Ding Liang, Chun Yuan, Wanli Ouyang, Yan-Pei Cao, and Yangguang Li. Sparseflex: High-resolution and arbitrary-topology 3d shape modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14822–14833, 2025
2025
-
[15]
Video diffusion models.arXiv:2204.03458, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.arXiv:2204.03458, 2022
Pith/arXiv arXiv 2022
-
[16]
Binbin Huang, Haobin Duan, Yiqun Zhao, Zibo Zhao, Yi Ma, and Shenghua Gao. Cupid: Generative 3d reconstruction via joint object and pose modeling.arXiv preprint arXiv:2510.20776, 2025
arXiv 2025
-
[17]
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
Pith/arXiv arXiv 2025
-
[18]
AniGen: Unified S3 fields for animatable 3d asset generation.arXiv preprint arXiv:2604.08746, 2026
Yi-Hua Huang, Zi-Xin Zou, Yuting He, Chirui Chang, Cheng-Feng Pu, Ziyi Yang, Yuan-Chen Guo, Yan-Pei Cao, and Xiaojuan Qi. AniGen: Unified S3 fields for animatable 3d asset generation.arXiv preprint arXiv:2604.08746, 2026
Pith/arXiv arXiv 2026
-
[19]
Yanqin Jiang, Li Zhang, Jin Gao, Weimin Hu, and Yao Yao. Consistent4d: Consistent 360{\deg} dynamic object generation from monocular video.arXiv preprint arXiv:2311.02848, 2023. 22
arXiv 2023
-
[20]
Zeren Jiang, Chuanxia Zheng, Iro Laina, Diane Larlus, and Andrea Vedaldi. Mesh4d: 4d mesh reconstruc- tion and tracking from monocular video.arXiv preprint arXiv:2601.05251, 2026
arXiv 2026
-
[21]
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling.arXiv preprint arXiv:2410.05954, 2024
arXiv 2024
-
[22]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[23]
Weiyu Li, Jiarui Liu, Hongyu Yan, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, and Xiaoxiao Long. Craftsman3d: High-fidelity mesh generation with 3d native generation and interactive geometry refiner. arXiv preprint arXiv:2405.14979, 2024
arXiv 2024
-
[24]
Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets
Weiyu Li, Xuanyang Zhang, Zheng Sun, Di Qi, Hao Li, Wei Cheng, Weiwei Cai, Shihao Wu, Jiarui Liu, Zihao Wang, et al. Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets. arXiv preprint arXiv:2505.07747, 2025
arXiv 2025
-
[25]
Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, et al. Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[26]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[27]
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
Pith/arXiv arXiv 2025
-
[28]
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
Pith/arXiv arXiv 2022
-
[29]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[30]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
2021
-
[31]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[32]
Nerfies: Deformable neural radiance fields
Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. InProceedings of the IEEE/CVF international conference on computer vision, pages 5865–5874, 2021
2021
-
[33]
The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017
Pith/arXiv arXiv 2017
-
[34]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[35]
Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
-
[36]
L4gm: Large 4d gaussian reconstruction model.Advances in Neural Information Processing Systems, 37:56828–56858, 2024
Jiawei Ren, Kevin Xie, Ashkan Mirzaei, Hanxue Liang, Xiaohui Zeng, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung W Kim, et al. L4gm: Large 4d gaussian reconstruction model.Advances in Neural Information Processing Systems, 37:56828–56858, 2024
2024
-
[37]
Remy Sabathier, David Novotny, Niloy J Mitra, and Tom Monnier. Actionmesh: Animated 3d mesh generation with temporal 3d diffusion.arXiv preprint arXiv:2601.16148, 2026
arXiv 2026
-
[38]
History- guided video diffusion.arXiv preprint arXiv:2502.06764, 2025
Kiwhan Song, Boyuan Chen, Max Simchowitz, Yilun Du, Russ Tedrake, and Vincent Sitzmann. History- guided video diffusion.arXiv preprint arXiv:2502.06764, 2025. 23
Pith/arXiv arXiv 2025
-
[39]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[40]
Fvd: A new metric for video generation
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation. 2019
2019
-
[41]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[42]
Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, et al. Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
Pith/arXiv arXiv 2025
-
[43]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21469–21480, 2025
2025
-
[44]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
Pith/arXiv arXiv 2024
-
[45]
Jiraphon Yenphraphai, Ashkan Mirzaei, Jianqi Chen, Jiaxu Zou, Sergey Tulyakov, Raymond A Yeh, Peter Wonka, and Chaoyang Wang. Shapegen4d: Towards high quality 4d shape generation from videos.arXiv preprint arXiv:2510.06208, 2025
arXiv 2025
-
[46]
Minghao Yin, Wenbo Hu, Jiale Xu, Ying Shan, and Kai Han. Sculpt4d: Generating 4d shapes via sparse-attention diffusion transformers.arXiv preprint arXiv:2604.21592, 2026
Pith/arXiv arXiv 2026
-
[47]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. 2025
2025
-
[48]
3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023
2023
-
[49]
Gaussian variation field diffusion for high-fidelity video-to-4d synthesis
Bowen Zhang, Sicheng Xu, Chuxin Wang, Jiaolong Yang, Feng Zhao, Dong Chen, and Baining Guo. Gaussian variation field diffusion for high-fidelity video-to-4d synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12502–12513, 2025
2025
-
[50]
Clay: A controllable large-scale generative model for creating high-quality 3d assets.ACM Transactions on Graphics (TOG), 43(4):1–20, 2024
Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, Wei Yang, Lan Xu, and Jingyi Yu. Clay: A controllable large-scale generative model for creating high-quality 3d assets.ACM Transactions on Graphics (TOG), 43(4):1–20, 2024
2024
-
[51]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[52]
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, et al. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202, 2025. 24
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.