Not All Points Are Equal: Uncertainty-Aware 4D LiDAR Scene Synthesis
Pith reviewed 2026-06-28 14:52 UTC · model grok-4.3
The pith
U4D derives per-point uncertainty maps to guide 4D LiDAR synthesis by generating high-entropy regions first then completing the rest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
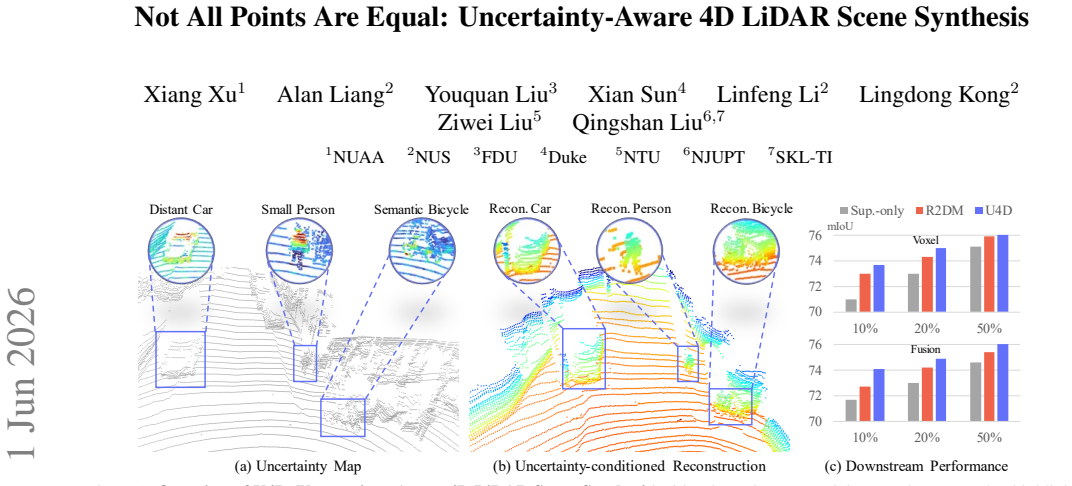
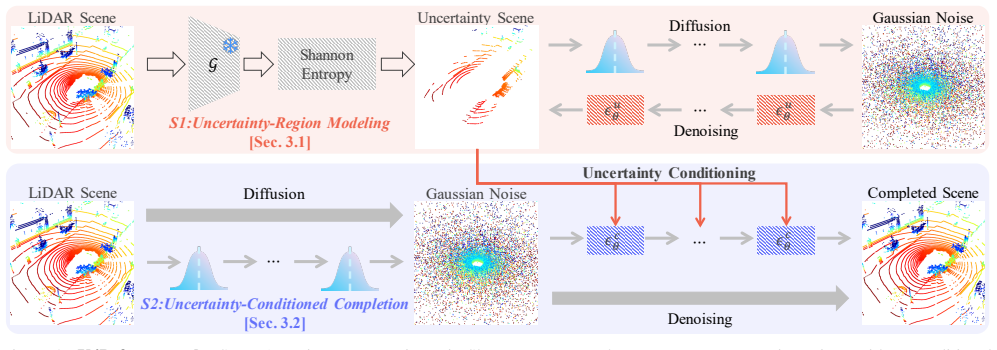
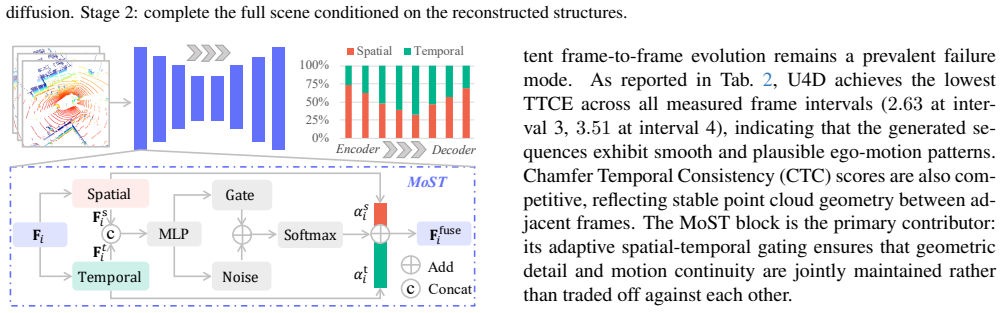
U4D derives per-point uncertainty maps via Shannon Entropy from a pretrained segmentor, then applies an unconditional diffusion stage to synthesize high-entropy areas with precise geometry, followed by a conditional completion stage that fills in the remaining regions using these structures as priors. A MoST block further maintains cross-frame coherence by dynamically balancing spatial detail and temporal continuity.
What carries the argument
Per-point uncertainty maps from Shannon entropy that schedule a two-stage diffusion process (unconditional high-entropy synthesis first, then conditional completion) together with the MoST block that enforces spatio-temporal balance.
If this is right
- State-of-the-art scene fidelity and temporal consistency on nuScenes and SemanticKITTI benchmarks.
- Improved performance on downstream tasks that rely on the synthesized 4D scenes.
- Explicit separation of hard and easy regions reduces wasted modeling capacity on simple surfaces.
Where Pith is reading between the lines
- The same uncertainty-driven ordering could be tested on other point-cloud modalities such as indoor RGB-D sequences where occlusion patterns differ.
- Replacing the segmentor-derived entropy with model-internal uncertainty estimates might remove dependence on an external pretrained network.
- Extending the schedule to multi-modal inputs that combine LiDAR with camera data could further tighten cross-sensor coherence.
Load-bearing premise
Uncertainty values computed from a pretrained segmentor via Shannon entropy correctly identify the spatial regions whose synthesis difficulty matches what the generative model needs to prioritize.
What would settle it
Running the same diffusion architecture on nuScenes and SemanticKITTI with uniform capacity allocation instead of the uncertainty-guided schedule and measuring whether scene fidelity and temporal consistency metrics drop, stay flat, or improve.
Figures
read the original abstract
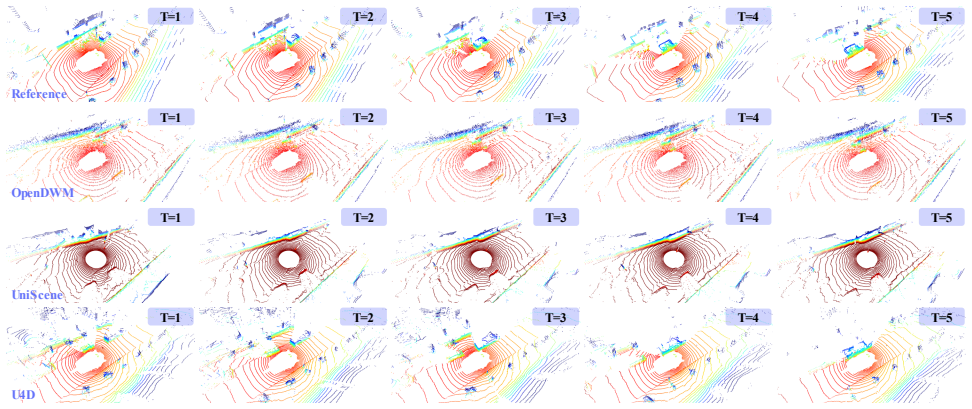
Constructing faithful 4D worlds from LiDAR-acquired sequences is crucial for embodied AI, yet current generative frameworks apply uniform modeling capacity across all spatial regions. This ignores that perceptual difficulty varies dramatically within a single scan: distant surfaces, occluded boundaries, and small-scale objects carry far higher uncertainty than well-observed structures. We present U4D, a new framework that explicitly leverages spatial uncertainty to guide LiDAR scene generation in a "hard-to-easy" schedule. U4D derives per-point uncertainty maps via Shannon Entropy from a pretrained segmentor, then applies an unconditional diffusion stage to synthesize high-entropy areas with precise geometry, followed by a conditional completion stage that fills in the remaining regions using these structures as priors. A MoST (Mixture of Spatio-Temporal) block further maintains cross-frame coherence by dynamically balancing spatial detail and temporal continuity. Extensive experiments on nuScenes and SemanticKITTI demonstrate state-of-the-art scene fidelity, temporal consistency, and downstream performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces U4D, a framework for 4D LiDAR scene synthesis that derives per-point uncertainty maps via Shannon entropy from a pretrained segmentor. It uses these to implement a hard-to-easy schedule consisting of an unconditional diffusion stage on high-entropy regions followed by conditional completion on the rest, with a new MoST (Mixture of Spatio-Temporal) block to enforce cross-frame coherence. Experiments on nuScenes and SemanticKITTI are claimed to show state-of-the-art scene fidelity, temporal consistency, and downstream task performance.
Significance. If the alignment between segmentor-derived entropy and generative difficulty holds and the quantitative results are confirmed, the selective allocation of modeling capacity could improve efficiency and quality in 4D LiDAR generation for embodied AI applications. The explicit handling of spatial uncertainty is a conceptually attractive departure from uniform modeling.
major comments (3)
- [Abstract / Method] Abstract and method overview: The central pipeline rests on the claim that Shannon entropy from an external pretrained segmentor identifies regions whose synthesis difficulty matches the diffusion model's needs. No correlation analysis, ablation on alternative uncertainty sources, or comparison to geometry/occlusion-based difficulty measures is described, leaving the mapping between semantic ambiguity and geometric synthesis hardness unverified.
- [Experiments] Experiments section: The abstract asserts state-of-the-art performance on nuScenes and SemanticKITTI, yet the provided text supplies no quantitative metrics, baseline tables, ablation studies on the uncertainty schedule or MoST block, or error analysis. Without these, the SOTA claim and the contribution of the hard-to-easy schedule cannot be evaluated.
- [Method / MoST] MoST block description: The claim that the Mixture of Spatio-Temporal block maintains cross-frame coherence without introducing new inconsistencies is stated without supporting ablation or failure-case analysis showing that the dynamic balancing of spatial detail and temporal continuity actually improves over standard spatio-temporal attention.
minor comments (2)
- [Method] Notation for the uncertainty map and the two-stage diffusion schedule should be formalized with explicit equations rather than prose descriptions.
- [Abstract] The abstract mentions 'extensive experiments' but the text does not list the specific metrics (e.g., Chamfer distance, temporal consistency scores) used to support the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method overview: The central pipeline rests on the claim that Shannon entropy from an external pretrained segmentor identifies regions whose synthesis difficulty matches the diffusion model's needs. No correlation analysis, ablation on alternative uncertainty sources, or comparison to geometry/occlusion-based difficulty measures is described, leaving the mapping between semantic ambiguity and geometric synthesis hardness unverified.
Authors: We acknowledge the importance of validating the assumed alignment between segmentor-derived entropy and generative difficulty. Our motivation for Shannon entropy stems from its capture of semantic ambiguity, which frequently coincides with geometrically challenging regions (e.g., boundaries, distant surfaces) in LiDAR data. In the revised manuscript we will add a correlation analysis between entropy maps and per-point synthesis errors from a uniform baseline diffusion model, plus an ablation comparing the entropy schedule against geometry-based alternatives such as local point density and occlusion estimation. revision: yes
-
Referee: [Experiments] Experiments section: The abstract asserts state-of-the-art performance on nuScenes and SemanticKITTI, yet the provided text supplies no quantitative metrics, baseline tables, ablation studies on the uncertainty schedule or MoST block, or error analysis. Without these, the SOTA claim and the contribution of the hard-to-easy schedule cannot be evaluated.
Authors: The full manuscript contains quantitative tables and ablations in Section 4; however, we agree that the presentation must be strengthened for clarity. We will expand the Experiments section to prominently feature all metrics (fidelity, temporal consistency, downstream task performance), baseline comparisons, ablations on the uncertainty schedule and MoST block, and error analysis in the revised version. revision: yes
-
Referee: [Method / MoST] MoST block description: The claim that the Mixture of Spatio-Temporal block maintains cross-frame coherence without introducing new inconsistencies is stated without supporting ablation or failure-case analysis showing that the dynamic balancing of spatial detail and temporal continuity actually improves over standard spatio-temporal attention.
Authors: We agree that empirical support for the MoST block is required. The revision will include an ablation study contrasting MoST against standard spatio-temporal attention on temporal consistency metrics, together with failure-case analysis demonstrating where the dynamic balancing of spatial and temporal components reduces inconsistencies. revision: yes
Circularity Check
No circularity; uncertainty signal is external and independent of generative parameters
full rationale
The derivation chain begins with per-point uncertainty computed via Shannon entropy on outputs of a pretrained segmentor that is external to the diffusion model. This signal then drives the unconditional-then-conditional schedule and MoST block. No equation or step reduces a model prediction to a quantity fitted inside the generative process itself, nor does any load-bearing premise rest on a self-citation whose content is unverified. The central claims therefore remain independent of the target data's fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Shannon entropy computed from a pretrained segmentor provides a valid proxy for synthesis difficulty in LiDAR point clouds
invented entities (1)
-
MoST (Mixture of Spatio-Temporal) block
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Behley et al
J. Behley et al. SemanticKITTI: A dataset for semantic scene understanding of LiDAR sequences. InICCV, 2019
2019
-
[2]
Caesar et al
H. Caesar et al. nuScenes: A multimodal dataset for au- tonomous driving. InCVPR, pages 11621–11631, 2020
2020
-
[3]
Choy et al
C. Choy et al. 4D spatio-temporal convnets: Minkowski con- volutional neural networks. InCVPR, 2019
2019
-
[4]
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
M. Chu et al. Agentic world modeling: Foundations, capa- bilities, laws, and beyond.arXiv preprint arXiv:2604.22748, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Ho et al
J. Ho et al. Denoising diffusion probabilistic models. In NeurIPS, volume 33, pages 6840–6851, 2020
2020
-
[6]
Kong et al
L. Kong et al. LaserMix for semi-supervised LiDAR seman- tic segmentation. InCVPR, pages 21705–21715, 2023
2023
-
[7]
3d and 4d world modeling: A survey.arXiv preprint arXiv:2509.07996, 2025
L. Kong et al. 3D and 4D world modeling: A survey.arXiv preprint arXiv:2509.07996, 2025
-
[8]
Kong et al
L. Kong et al. Calib3D: Calibrating model preferences for reliable 3D scene understanding. InWACV, 2025
2025
-
[9]
Kong et al
L. Kong et al. Multi-modal data-efficient 3D scene under- standing for autonomous driving.IEEE TPAMI, 47(5):3748– 3765, 2025
2025
-
[10]
Li et al
B. Li et al. UniScene: Unified occupancy-centric driving scene generation. InCVPR, pages 11971–11981, 2025
2025
-
[11]
Liang et al
A. Liang et al. LiDARCrafter: Dynamic 4D world modeling from LiDAR sequences. InAAAI, pages 18406–18414, 2026
2026
-
[12]
Liang et al
A. Liang et al. WorldLens: Full-spectrum evaluations of driving world models in real world. InCVPR, 2026
2026
-
[13]
Liu et al
Y . Liu et al. La La LiDAR: Large-scale layout generation from LiDAR data. InAAAI, 2026
2026
-
[14]
OmniLiDAR: A Unified Diffusion Framework for Multi-Domain 3D LiDAR Generation
Y . Liu et al. OmniLiDAR: A unified diffusion framework for multi-domain 3D LiDAR generation.arXiv preprint arXiv:2605.13815, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Nakashima et al
K. Nakashima et al. LiDAR data synthesis with denoising diffusion probabilistic models. InICRA, 2024
2024
-
[16]
Ni et al
J. Ni et al. OpenDWM: Open driving world mod- els.https : / / github . com / SenseTime - FVG / OpenDWM, 2025
2025
-
[17]
Ran et al
H. Ran et al. Towards realistic scene generation with LiDAR diffusion models. InCVPR, 2024
2024
-
[18]
C. E. Shannon. A mathematical theory of communication. The Bell System Technical Journal, 27(3):379–423, 1948
1948
-
[19]
Tang et al
H. Tang et al. Searching efficient 3D architectures with sparse point-voxel convolution. InECCV, 2020
2020
-
[20]
Wu et al
Y . Wu et al. Text2LiDAR: Text-guided LiDAR point cloud generation via equirectangular transformer. InECCV, pages 291–310, 2024
2024
-
[21]
Xu et al
X. Xu et al. LiMoE: Mixture of LiDAR representation learn- ers from automotive scenes. InCVPR, 2025
2025
-
[22]
Xu et al
X. Xu et al. U4D: Uncertainty-aware 4D world modeling from lidar sequences. InCVPR, pages 10027–10039, 2026
2026
-
[23]
Zyrianov et al
V . Zyrianov et al. Learning to generate realistic LiDAR point clouds. InECCV, pages 17–35, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.