LongLive-RAG: A General Retrieval-Augmented Framework for Long Video Generation
Pith reviewed 2026-06-28 15:27 UTC · model grok-4.3
The pith
Treating generated video latents as searchable memory reduces error accumulation in autoregressive long-video synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
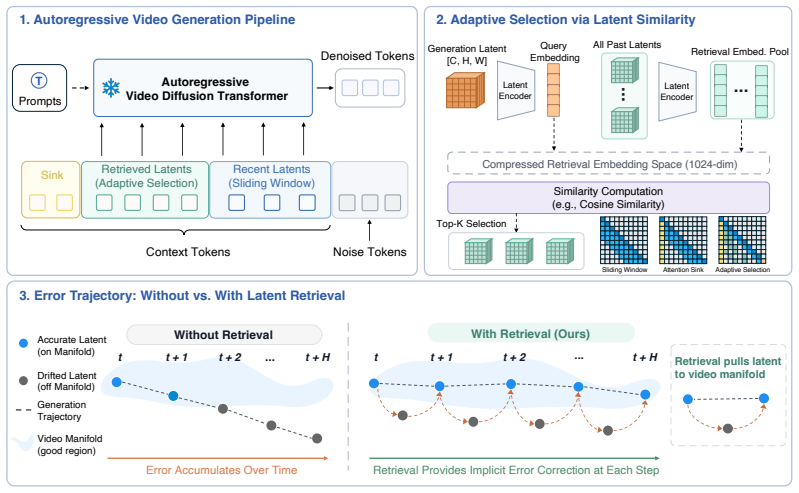
The paper claims that long video generation can be formulated as a retrieval-augmented generation problem in which self-generated latents form a searchable memory; retrieving non-local historical latents via query embeddings lets the autoregressive generator condition on corrective context rather than only the recent sliding window, thereby mitigating accumulated appearance errors and identity drift.
What carries the argument
LongLive-RAG retrieval step: a query embedding selects relevant historical latents from the full generated history to augment the sliding window during autoregressive diffusion.
If this is right
- Error accumulation caused by sliding-window attention is reduced when the generator conditions on retrieved non-local latents.
- The approach delivers the best average VBench-Long rank across tested autoregressive backbones and generation lengths.
- Retrieval adds only small overhead relative to the generation cost itself.
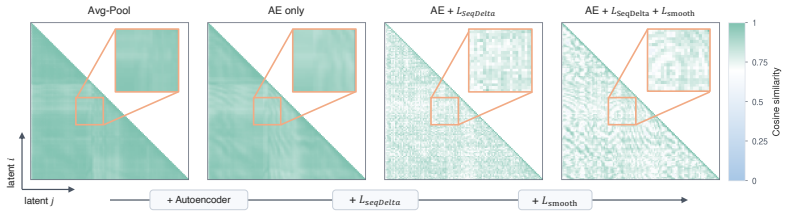
- The Window Temporal Delta Loss makes query embeddings more discriminative by suppressing local redundancy.
- Self-generated latent history becomes the first content-addressable retrieval memory in open-ended autoregressive long-video methods.
Where Pith is reading between the lines
- The same retrieval-from-history pattern could stabilize other autoregressive sequences such as long audio or motion trajectories.
- Scaling the history size might allow generation horizons far beyond current practical limits without proportional quality loss.
- Replacing the simple query embedding with a learned index could further reduce retrieval latency for very long videos.
Load-bearing premise
A lightweight query embedding can reliably fetch useful non-local historical latents that actually correct errors instead of adding retrieval noise or new inconsistencies.
What would settle it
An ablation that removes the retrieval module and measures whether identity-consistency and appearance-error metrics degrade over generation lengths exceeding the training window.
Figures





read the original abstract
Autoregressive (AR) video diffusion enables variable-length synthesis, but long-horizon generation often suffers from accumulated errors and identity drift. For efficiency, existing methods commonly adopt sliding-window attention during generation. This creates an irreversible generation trajectory: once the active window accumulates appearance errors, subsequent generations can only condition on this degraded trajectory and drift further away. We address this limitation by formulating long video generation as a retrieval-augmented generation (RAG) problem. Rather than relying solely on the recent window, we treat previously generated latents as a dynamic, searchable history. We propose LongLive-RAG, a general retrieval framework for AR video generation. At each new block, LongLive-RAG uses a query embedding to retrieve relevant historical latents. This lightweight retrieval step adds only a small overhead relative to generation and lets the generator condition on non-local context instead of only the recent window. To make retrieval more discriminative, we introduce the Window Temporal Delta Loss that suppresses redundant local similarity and encourages embeddings to capture meaningful temporal changes. Together, these components help reduce error accumulation caused by sliding-window attention. Experiments across multiple AR backbones and generation lengths show improved long-video quality and the best average VBench-Long rank. To our knowledge, among open-ended AR long video generation methods, LongLive-RAG is the first to formulate self-generated latent history as content-addressable retrieval memory. Code is available at https://github.com/qixinhu11/LongLive-RAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates autoregressive long video diffusion as a retrieval-augmented generation (RAG) problem. LongLive-RAG retrieves relevant historical latents via a lightweight query embedding at each new block, allowing conditioning on non-local context rather than only the recent sliding window. A Window Temporal Delta Loss is introduced to suppress redundant local similarity and encourage embeddings to capture meaningful temporal changes. Experiments across multiple AR backbones and generation lengths report improved long-video quality and the best average VBench-Long rank; the work claims to be the first to treat self-generated latent history as content-addressable retrieval memory.
Significance. If the retrieval step is shown to be net beneficial, the RAG framing offers a practical way to mitigate irreversible error accumulation in sliding-window AR video generation. The lightweight overhead, general applicability across backbones, and public code release are strengths that support reproducibility and potential adoption. The novelty of casting self-generated latents as searchable memory distinguishes the contribution from prior sliding-window or memory-bank approaches.
minor comments (1)
- [Abstract] The abstract states that the approach 'helps reduce error accumulation' but does not quantify the reduction or compare against a no-retrieval baseline in the provided text; adding such metrics would strengthen the central claim.
Simulated Author's Rebuttal
We thank the referee for the positive summary of LongLive-RAG and for highlighting the practical benefits of the RAG framing, the lightweight overhead, and the novelty of treating self-generated latents as content-addressable memory. We are pleased that the significance assessment recognizes the potential to mitigate error accumulation in sliding-window autoregressive video generation. The recommendation is listed as uncertain, yet the major comments section contains no specific points. We would appreciate any additional feedback the referee may have so that we can address concerns directly.
Circularity Check
No significant circularity
full rationale
The paper proposes an engineering framework (LongLive-RAG) that augments AR video diffusion with retrieval from self-generated latents and introduces a Window Temporal Delta Loss for training embeddings. No derivation chain, equations, or first-principles predictions are presented that reduce by construction to fitted inputs or self-citations. The central claims rest on empirical results across backbones and lengths (VBench-Long ranks), with the retrieval step treated as an additive mechanism rather than a tautological re-expression of the sliding-window baseline. The formulation as a RAG problem is a modeling choice, not a self-referential definition, and no load-bearing uniqueness theorem or ansatz is imported from prior self-work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NTK-aware scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation
bloc97. NTK-aware scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. Reddit post, 2023. URL https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/
2023
-
[2]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. InProceedings of the 39th International Conference on Machine Learning, pages 2206–2240, 2022
2022
-
[3]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. OpenAI Blog, 1(8):1, 2024
2024
-
[4]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herve Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9650–9660, 2021
2021
-
[5]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
2024
-
[6]
Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025
Pith/arXiv arXiv 2025
-
[7]
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595, 2023
Pith/arXiv arXiv 2023
-
[8]
Shuo Chen, Cong Wei, Sun Sun, Ping Nie, Kai Zhou, Ge Zhang, Ming-Hsuan Yang, and Wenhu Chen. Context forcing: Consistent autoregressive video generation with long context.arXiv preprint arXiv:2602.06028, 2026
arXiv 2026
-
[9]
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation.arXiv preprint arXiv:2510.02283, 2025
Pith/arXiv arXiv 2025
-
[10]
Lol: Longer than longer, scaling video generation to hour.arXiv preprint arXiv:2601.16914, 2026
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Lol: Longer than longer, scaling video generation to hour.arXiv preprint arXiv:2601.16914, 2026
arXiv 2026
-
[11]
Autoregressive video generation without vector quantization
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, and Xinlong Wang. Autoregressive video generation without vector quantization. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=JE9tCwe3lp
2025
-
[12]
A survey on long-video storytelling generation: architectures, consistency, and cinematic quality
Mohamed Elmoghany, Ryan Rossi, Seunghyun Yoon, Subhojyoti Mukherjee, Eslam Mohamed Bakr, Puneet Mathur, Gang Wu, Viet Dac Lai, Nedim Lipka, Ruiyi Zhang, et al. A survey on long-video storytelling generation: architectures, consistency, and cinematic quality. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7023–7035, 2025
2025
-
[13]
Ruili Feng, Han Zhang, Zhantao Yang, Jie Xiao, Zhilei Shu, Zhiheng Liu, Andy Zheng, Yukun Huang, Yu Liu, and Hongyang Zhang. The matrix: Infinite-horizon world generation with real-time moving control.arXiv preprint arXiv:2412.03568, 2024
arXiv 2024
-
[14]
Ravi Ghadia, Avinash Kumar, Gaurav Jain, Prashant Nair, and Poulami Das. Dialogue without limits: Constant-sized kv caches for extended responses in llms.arXiv preprint arXiv:2503.00979, 2025
arXiv 2025
-
[15]
Gemini 3.1 pro model card, 2026
Google DeepMind. Gemini 3.1 pro model card, 2026. URL https://deepmind.google/ models/model-cards/gemini-3-1-pro/. 10
2026
-
[16]
Yuchao Gu, Weijia Mao, and Mike Zheng Shou. Long-context autoregressive video modeling with next-frame prediction.arXiv preprint arXiv:2503.19325, 2025
Pith/arXiv arXiv 2025
-
[17]
REALM: Retrieval-augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM: Retrieval-augmented language model pre-training. InProceedings of the 37th International Conference on Machine Learning, pages 3929–3938, 2020
2020
-
[18]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text
Roberto Henschel, Levon Khachatryan, Hayk Poghosyan, Daniil Hayrapetyan, Vahram Tade- vosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Streamingt2v: Consistent, dynamic, and extendable long video generation from text. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2568–2577, 2025
2025
-
[19]
Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, et al. Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
arXiv 2025
-
[20]
Gaia-1: A generative world model for autonomous driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
Pith/arXiv arXiv 2023
-
[21]
Self forcing: Bridging the train-test gap in autoregressive video diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview. net/forum?id=mSiN7i0BYH
2025
-
[22]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[23]
Pyramidal flow matching for efficient video generative modeling
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong MU, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. InThe Thirteenth International Conference on Learning Representations,
-
[24]
URLhttps://openreview.net/forum?id=66NzcRQuOq
-
[25]
Youngrae Kim, Qixin Hu, C-C Jay Kuo, and Peter A Beerel. Memrope: Training-free infinite video generation via evolving memory tokens.arXiv preprint arXiv:2603.12513, 2026
arXiv 2026
-
[26]
Streamdit: Real-time streaming text-to-video generation.arXiv preprint arXiv:2507.03745, 2025
Akio Kodaira, Tingbo Hou, Ji Hou, Markos Georgopoulos, Felix Juefei-Xu, Masayoshi Tomizuka, and Yue Zhao. Streamdit: Real-time streaming text-to-video generation.arXiv preprint arXiv:2507.03745, 2025
arXiv 2025
-
[27]
Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video generation.arXiv preprint arXiv:2312.14125, 2023
Pith/arXiv arXiv 2023
-
[28]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[29]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020
2020
-
[30]
Haodong Li, Shaoteng Liu, Zhe Lin, and Manmohan Chandraker. Rolling sink: Bridging limited-horizon training and open-ended testing in autoregressive video diffusion.arXiv preprint arXiv:2602.07775, 2026
Pith/arXiv arXiv 2026
-
[31]
Vmem: Consistent interactive video scene generation with surfel-indexed view memory
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. Vmem: Consistent interactive video scene generation with surfel-indexed view memory. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25690–25699, 2025. 11
2025
-
[32]
Snapkv: Llm knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024
2024
-
[33]
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
Pith/arXiv arXiv 2025
-
[34]
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, et al. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024
Pith/arXiv arXiv 2024
-
[35]
Yunhong Lu, Yanhong Zeng, Haobo Li, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Jiapeng Zhu, Hengyuan Cao, Zhipeng Zhang, Xing Zhu, et al. Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation.arXiv preprint arXiv:2512.04678, 2025
Pith/arXiv arXiv 2025
-
[36]
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071, 2023
Pith/arXiv arXiv 2023
-
[37]
Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
Pith/arXiv arXiv 2024
-
[38]
Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
-
[39]
Xuanchi Ren, Yifan Lu, Tianshi Cao, Ruiyuan Gao, Shengyu Huang, Amirmojtaba Sabour, Tianchang Shen, Tobias Pfaff, Jay Zhangjie Wu, Runjian Chen, et al. Cosmos-drive-dreams: Scalable synthetic driving data generation with world foundation models.arXiv preprint arXiv:2506.09042, 2025
arXiv 2025
-
[40]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[41]
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. Worldplay: Towards long-term geometric consistency for real-time interactive world modeling.arXiv preprint arXiv:2512.14614, 2025
Pith/arXiv arXiv 2025
-
[42]
Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
Pith/arXiv arXiv 2025
-
[43]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[44]
Zhongwei Wan, Xinjian Wu, Yu Zhang, Yi Xin, Chaofan Tao, Zhihong Zhu, Xin Wang, Siqi Luo, Jing Xiong, and Mi Zhang. D2o: Dynamic discriminative operations for efficient generative inference of large language models.arXiv preprint arXiv:2406.13035, 2, 2024
arXiv 2024
-
[45]
Zheng Wang, Boxiao Jin, Zhongzhi Yu, and Minjia Zhang. Model tells you where to merge: Adaptive kv cache merging for llms on long-context tasks.arXiv preprint arXiv:2407.08454, 2024
arXiv 2024
-
[46]
Ruiqi Wu, Xuanhua He, Meng Cheng, Tianyu Yang, Yong Zhang, Zhuoliang Kang, Xun- liang Cai, Xiaoming Wei, Chunle Guo, Chongyi Li, et al. Infinite-world: Scaling interactive world models to 1000-frame horizons via pose-free hierarchical memory.arXiv preprint arXiv:2602.02393, 2026
arXiv 2026
-
[47]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=NG7sS51zVF
2024
-
[48]
Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xin- gang Pan. Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025. 12
arXiv 2025
-
[49]
Videogpt: Video generation using vq-vae and transformers.arXiv preprint arXiv:2104.10157, 2021
Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers.arXiv preprint arXiv:2104.10157, 2021
Pith/arXiv arXiv 2021
-
[50]
Longlive: Real-time interactive long video generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Ying-Cong Chen, Yao Lu, Song Han, and Yukang Chen. Longlive: Real-time interactive long video generation. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=nCAODkpsPJ
2026
-
[51]
Ying Yang, Zhengyao Lv, Tianlin Pan, Haofan Wang, Binxin Yang, Hubery Yin, Chen Li, Ziwei Liu, and Chenyang Si. Stableworld: Towards stable and consistent long interactive video generation.arXiv preprint arXiv:2601.15281, 2026
arXiv 2026
-
[52]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
Pith/arXiv arXiv 2024
-
[53]
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self- rollout.arXiv preprint arXiv:2511.20649, 2025
arXiv 2025
-
[54]
Deep forcing: Training-free long video generation with deep sink and participative compression
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep forcing: Training-free long video generation with deep sink and participative compression. arXiv preprint arXiv:2512.05081, 2025
arXiv 2025
-
[55]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
2024
-
[56]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22963–22974, 2025
2025
-
[57]
Context as memory: Scene-consistent interactive long video generation with memory retrieval
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025
2025
-
[58]
Magvit: Masked generative video transformer
Lijun Yu, Yong Cheng, Kihyuk Sohn, José Lezama, Han Zhang, Huiwen Chang, Alexander G Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, et al. Magvit: Masked generative video transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10459–10469, 2023
2023
-
[59]
Language model beats diffusion - tokenizer is key to visual generation
Lijun Yu, Jose Lezama, Nitesh Bharadwaj Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G Hauptmann, Boqing Gong, Ming-Hsuan Yang, Irfan Essa, David A Ross, and Lu Jiang. Language model beats diffusion - tokenizer is key to visual generation. InThe Twelfth International Conference on Learning Representati...
2024
-
[60]
Yifei Yu, Xiaoshan Wu, Xinting Hu, Tao Hu, Yangtian Sun, Xiaoyang Lyu, Bo Wang, Lin Ma, Yuewen Ma, Zhongrui Wang, et al. Videossm: Autoregressive long video generation with hybrid state-space memory.arXiv preprint arXiv:2512.04519, 2025
arXiv 2025
-
[61]
Stargen: A spatiotemporal autoregression framework with video diffusion model for scalable and controllable scene generation
Shangjin Zhai, Zhichao Ye, Jialin Liu, Weijian Xie, Jiaqi Hu, Zhen Peng, Hua Xue, Danpeng Chen, Xiaomeng Wang, Lei Yang, et al. Stargen: A spatiotemporal autoregression framework with video diffusion model for scalable and controllable scene generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26822–26833, 2025
2025
-
[62]
Packing input frame context in next-frame prediction models for video generation.arXiv e-prints, pages arXiv–2504, 2025
Lvmin Zhang and Maneesh Agrawala. Packing input frame context in next-frame prediction models for video generation.arXiv e-prints, pages arXiv–2504, 2025
2025
-
[63]
Lvmin Zhang, Shengqu Cai, Muyang Li, Chong Zeng, Beijia Lu, Anyi Rao, Song Han, Gordon Wetzstein, and Maneesh Agrawala. Pretraining frame preservation in autoregressive video memory compression.arXiv preprint arXiv:2512.23851, 2025. 13
Pith/arXiv arXiv 2025
-
[64]
Cam: Cache merging for memory-efficient llms inference
Yuxin Zhang, Yuxuan Du, Gen Luo, Yunshan Zhong, Zhenyu Zhang, Shiwei Liu, and Rongrong Ji. Cam: Cache merging for memory-efficient llms inference. InForty-first international conference on machine learning, 2024
2024
-
[65]
H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
2023
-
[66]
RIFLEx: A free lunch for length extrapolation in video diffusion transformers
Min Zhao, Guande He, Yixiao Chen, Hongzhou Zhu, Chongxuan Li, and Jun Zhu. RIFLEx: A free lunch for length extrapolation in video diffusion transformers. InForty-second Inter- national Conference on Machine Learning, 2025. URLhttps://openreview.net/forum? id=v3B79m7t8Z
2025
-
[67]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video generation.arXiv preprint arXiv:2602.02214, 2026. 14 A Limitations LongLive-RAG builds on a frozen base checkpoint. It improves how the model selects and reuses generated histo...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.