VISReg: Variance-Invariance-Sketching Regularization for JEPA training
Pith reviewed 2026-06-28 15:15 UTC · model grok-4.3
The pith
VISReg replaces covariance with Sliced-Wasserstein sketching to enforce full embedding distribution shape while retaining variance for scale control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
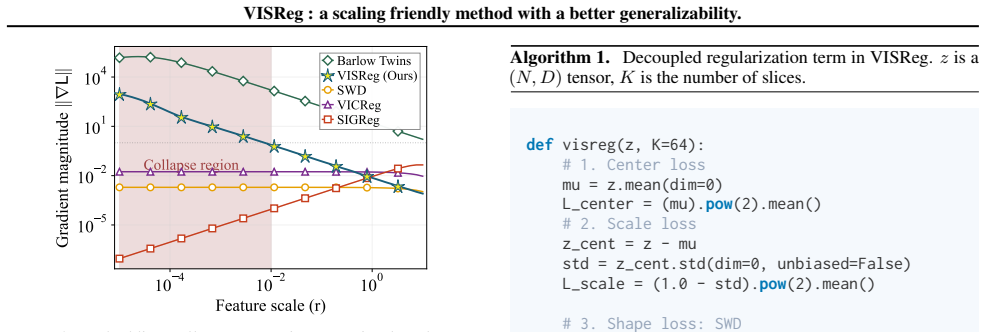
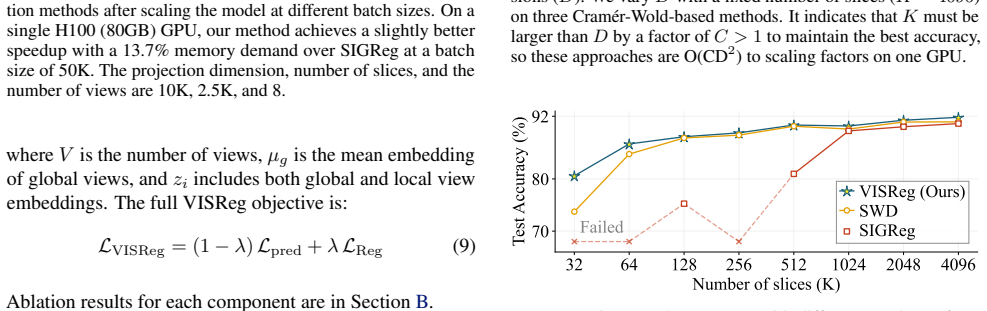
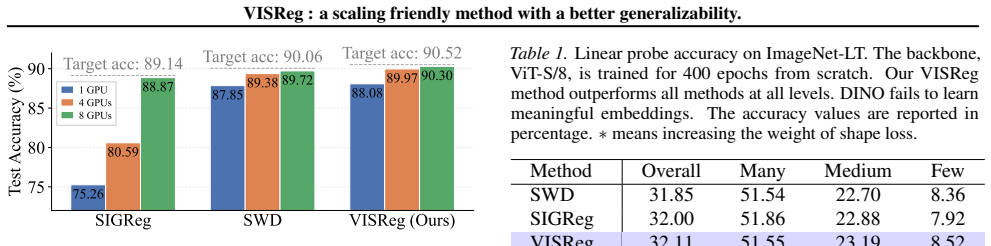
VISReg decouples scale and shape regularization by retaining the variance term from VICReg while substituting the covariance term with a Sliced-Wasserstein sketching objective that aligns embeddings to an isotropic Gaussian; this produces stable training gradients under collapse, linear scaling, and improved resilience on low-quality, long-tailed, and low-rank data regimes, yielding state-of-the-art out-of-distribution performance after ImageNet-1K pretraining and parity with DINOv2 after ImageNet-22K pretraining using one-tenth the data.
What carries the argument
The Sliced-Wasserstein sketching objective that replaces covariance in the regularization loss, enforcing full distributional shape while the separate variance term controls scale.
If this is right
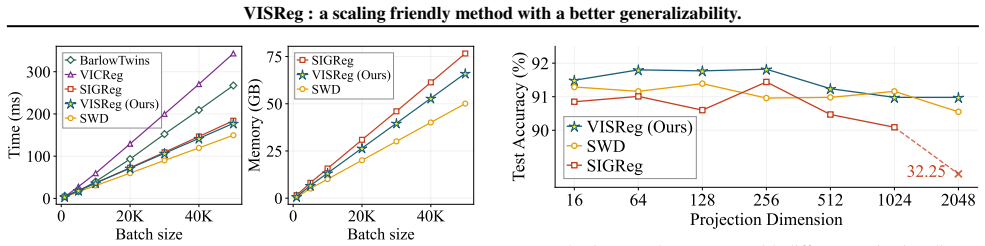
- VISReg scales linearly with dataset size.
- It outperforms prior regularization on low-quality, long-tailed, and low-rank datasets.
- It achieves state-of-the-art out-of-distribution accuracy after ImageNet-1K pretraining.
- It matches DINOv2 out-of-distribution performance after ImageNet-22K pretraining despite using one-tenth the data.
Where Pith is reading between the lines
- The scale-shape decoupling could be ported to other self-supervised objectives that currently rely on covariance.
- The method's reported resilience to long-tailed data suggests possible gains on imbalanced real-world image collections.
- Direct measurement of embedding histograms during training could verify whether the Gaussian target is actually reached in practice.
Load-bearing premise
That the Sliced-Wasserstein sketching objective can enforce the required full distributional shape for stable training without the vanishing-gradient problems seen in prior sketching methods.
What would settle it
A training run on a collapse-prone dataset in which VISReg still exhibits vanishing gradients or produces embeddings whose empirical distribution deviates from the target isotropic Gaussian would falsify the central claim.
Figures


read the original abstract
Self-supervised learning methods prevent embedding collapse via modeling heuristics or explicit regularization of the embedding space. Among the latter, VICReg decomposes regularization into variance and covariance objectives, offering flexibility and interpretability. However, covariance captures only second-order statistics -- encouraging decorrelation but failing to enforce the full distributional shape needed for stable training. Sketching-based methods such as SIGReg address this by aligning embeddings to an isotropic Gaussian, but lack flexibility and suffer from vanishing gradients under collapse. We propose Variance-Invariance-Sketching Regularization (VISReg), which replaces covariance with a Sliced-Wasserstein-based sketching objective that enforces full distributional shape, while retaining a variance term for scale control. By decoupling scale and shape, VISReg combines VICReg's flexibility with the distributional rigor of sketching methods, providing robust gradients even under collapse. We show that VISReg scales linearly, outperforms existing regularization on low-quality datasets, and is resilient to long-tailed and low-rank regimes. Pre-trained on ImageNet-1K, VISReg achieves state-of-the-art performance on out-of-distribution datasets. Pre-trained on ImageNet-22K, it matches DINOv2's OOD performance despite the latter using 10x more data (LVD-142M). Project and code: https://haiyuwu.github.io/visreg.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Variance-Invariance-Sketching Regularization (VISReg) for JEPA-based self-supervised learning. It extends VICReg by retaining the variance and invariance terms while replacing the covariance regularizer with a Sliced-Wasserstein sketching objective that aligns embeddings to an isotropic Gaussian target. The method is claimed to enforce full distributional shape, decouple scale from shape, supply non-vanishing gradients under collapse, scale linearly, and deliver state-of-the-art out-of-distribution performance after ImageNet-1K pre-training as well as DINOv2-level OOD results after ImageNet-22K pre-training despite using far less data.
Significance. If the empirical and mechanistic claims are substantiated, VISReg would supply a regularization approach that combines VICReg-style flexibility with the distributional enforcement of sketching methods, potentially improving robustness of joint-embedding architectures on low-quality, long-tailed, or low-rank data regimes. The public release of code and project page is a clear strength that supports reproducibility.
major comments (3)
- [§3] The central claim that the Sliced-Wasserstein sketching term supplies robust gradients even under collapse (abstract and §3) is load-bearing for the method's advantage over SIGReg, yet the manuscript supplies neither gradient-norm measurements nor a controlled collapse protocol that directly compares VISReg to SIGReg or VICReg in the low-rank regime.
- [Table 2] Table 2 and the OOD evaluation protocol: the reported SOTA numbers on ImageNet-1K pre-training are presented without ablations that isolate the contribution of the sketching term versus the retained variance term, so it is impossible to attribute the OOD gains to the proposed replacement of covariance.
- [§4.3] §4.3 (long-tailed and low-rank regimes): the resilience claims rest on performance tables, but no quantitative verification is given that the combined loss remains non-vanishing when embeddings approach rank deficiency, which is the precise regime the paper claims to handle better than prior sketching methods.
minor comments (2)
- [Eq. (3)] Notation for the sketching objective in Eq. (3) is introduced without an explicit statement of the number of projection directions or the Monte-Carlo sampling procedure used to approximate the Sliced-Wasserstein distance.
- [§4.1] The linear scaling claim in §4.1 would be clearer if wall-clock or FLOPs measurements were reported alongside the batch-size scaling curves.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to provide the requested empirical support.
read point-by-point responses
-
Referee: [§3] The central claim that the Sliced-Wasserstein sketching term supplies robust gradients even under collapse (abstract and §3) is load-bearing for the method's advantage over SIGReg, yet the manuscript supplies neither gradient-norm measurements nor a controlled collapse protocol that directly compares VISReg to SIGReg or VICReg in the low-rank regime.
Authors: We agree that empirical gradient-norm measurements and a controlled collapse protocol would strengthen the mechanistic claim. In the revision we will add these to §3 (or a new appendix subsection): a synthetic low-rank protocol that progressively reduces embedding rank while monitoring per-term gradient norms for VISReg, SIGReg, and VICReg, plus real-training gradient statistics on ImageNet subsets. revision: yes
-
Referee: [Table 2] Table 2 and the OOD evaluation protocol: the reported SOTA numbers on ImageNet-1K pre-training are presented without ablations that isolate the contribution of the sketching term versus the retained variance term, so it is impossible to attribute the OOD gains to the proposed replacement of covariance.
Authors: We acknowledge the attribution gap. The revision will augment Table 2 (or add a companion ablation table) with results for the variance+invariance baseline (no sketching term) versus full VISReg on the same OOD suites, allowing direct isolation of the sketching term's contribution to the reported gains. revision: yes
-
Referee: [§4.3] §4.3 (long-tailed and low-rank regimes): the resilience claims rest on performance tables, but no quantitative verification is given that the combined loss remains non-vanishing when embeddings approach rank deficiency, which is the precise regime the paper claims to handle better than prior sketching methods.
Authors: We agree that explicit verification of non-vanishing loss/gradients at rank deficiency is needed. The revision will add, within §4.3, quantitative monitoring: singular-value spectra of embeddings during long-tailed training together with per-component loss and gradient-norm curves, demonstrating that the sketching term keeps gradients non-vanishing where covariance-based terms vanish. revision: yes
Circularity Check
No circularity: new regularization objective defined independently of prior fits or self-citations
full rationale
The paper defines VISReg explicitly as the sum of a retained variance term (from VICReg) plus a new Sliced-Wasserstein sketching term that replaces covariance; no equation reduces the claimed gradient robustness or OOD gains to a quantity fitted from the authors' own prior parameters. No self-citation is invoked as a uniqueness theorem or load-bearing premise, and no prediction is obtained by renaming a fitted input. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
Balestriero, R. and LeCun, Y . Lejepa: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Improved Baselines with Momentum Contrastive Learning
Chen, X., Fan, H., Girshick, R., and He, K. Improved baselines with momentum contrastive learning.arXiv preprint arXiv:2003.04297, 2020c. Chen, X., Xie, S., and He, K. An empirical study of training self-supervised vision transformers. InICCV, pp. 9640– 9649,
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[3]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[4]
Kuang, Y ., Dagade, Y ., Rudner, T. G., Balestriero, R., and LeCun, Y . Rectified lpjepa: Joint-embedding predictive architectures with sparse and maximum-entropy repre- sentations.arXiv preprint arXiv:2602.01456,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
LeCun, Y . et al. A path towards autonomous machine intel- ligence version 0.9. 2, 2022-06-27.Open Review,
2022
-
[6]
Accessed: 2026-01-11. Li, A. C., Efros, A. A., and Pathak, D. Understanding col- lapse in non-contrastive siamese representation learning. InECCV,
2026
-
[7]
Fine-Grained Visual Classification of Aircraft
Maji, S., Rahtu, E., Kannala, J., Blaschko, M., and Vedaldi, A. Fine-grained visual classification of aircraft.arXiv preprint arXiv:1306.5151,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Imagenet-21k pretraining for the masses.arXiv preprint arXiv:2104.10972,
Ridnik, T., Ben-Baruch, E., Noy, A., and Zelnik-Manor, L. Imagenet-21k pretraining for the masses.arXiv preprint arXiv:2104.10972,
-
[9]
Siméoni, O., V o, H. V ., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V ., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2512.10794 , year=
Singh, J., Leng, X., Wu, Z., Zheng, L., Zhang, R., Shecht- man, E., and Xie, S. What matters for representation alignment: Global information or spatial structure?arXiv preprint arXiv:2512.10794,
-
[11]
Zimmermann, E., Wiltzer, H., Szeto, J., Alvarez-Melis, D., and Mackey, L. Kerjepa: Kernel discrepancies for euclidean self-supervised learning.arXiv preprint arXiv:2512.19605,
-
[12]
Both models are trained from scratch using the VISReg regularization objective and timm for backbones
(1.28M training images): VISReg-B(ViT-B/16, 86M parameters) andVISReg-L(ViT-L/14, 304M parameters). Both models are trained from scratch using the VISReg regularization objective and timm for backbones. We adopt DINO-style multi-crop augmentation (Caron et al., 2021): each image produces Ng=4 global crops (224×224, scale [0.3,1.0] ) and Nl=6 local crops (...
2021
-
[13]
The multi-crop strategy uses Ng=2 global crops and Nl=8 local crops (98×98), still yielding 10 views per image
(14.2M images) with ViT-L/14 for 100 epochs on 16 NVIDIA H100 80GB GPUs (4 nodes × 4 GPUs). The multi-crop strategy uses Ng=2 global crops and Nl=8 local crops (98×98), still yielding 10 views per image. We use per-GPU batch size 64 (effective batch size 1,024), learning rate 8×10−4, λ=0.8, dp=384, and K=4096 random projections. All other settings (optimi...
2024
-
[14]
is a fine-grained vehicle classification dataset with 8,144 training and 8,041 test images covering 196 car models from 98 manufacturers, spanning decades of automotive design from 1950 to
1950
-
[15]
The shape component is the most impactful of the three DSSO objectives
so thatλalone controls the overall regularization magnitude. The shape component is the most impactful of the three DSSO objectives. On ImageNet-LT and Galaxy10, shifting weight toward shape monotonically improves accuracy, with shape 4:1 outperforming the equal baseline by +3.2% and +1.3%, respectively. Conversely, emphasizing scale or center consistentl...
2025
-
[16]
15 VISReg : a scaling friendly method with a better generalizability
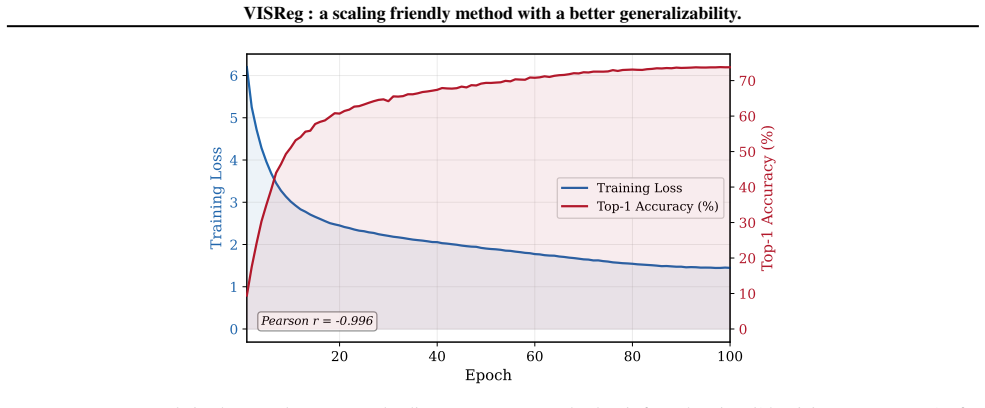
The pronounced -0.996 correlation show the loss curve can be used to reflect the learning curve of the model. 15 VISReg : a scaling friendly method with a better generalizability. 20 40 60 80 100 Epoch 0 1 2 3 4 5 6Training Loss Pearson r = -0.996 Training Loss Top-1 Accuracy (%) 0 10 20 30 40 50 60 70 Top-1 Accuracy (%) Figure 7.Pearson correlation betwe...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.