Thinking in Blender: Staged Executable Inverse Graphics with Vision-Language Models
Pith reviewed 2026-06-28 15:01 UTC · model grok-4.3
The pith
Pretrained vision-language models can turn single images into editable Blender scenes by writing code in successive refinement stages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
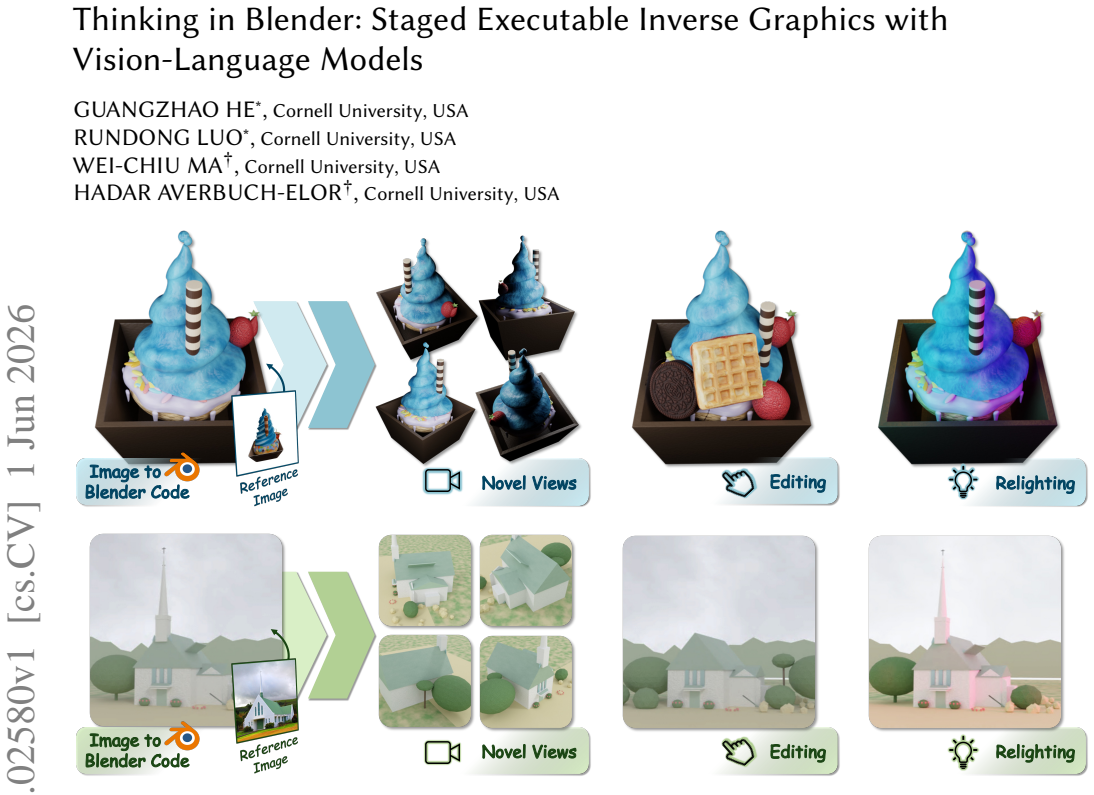
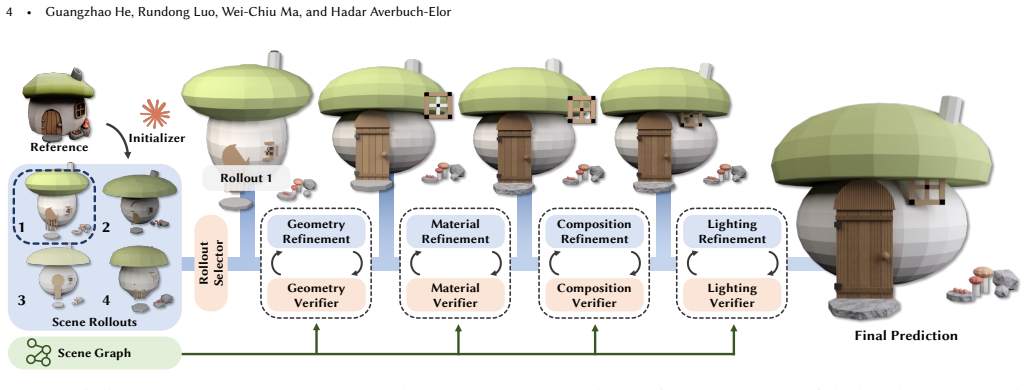
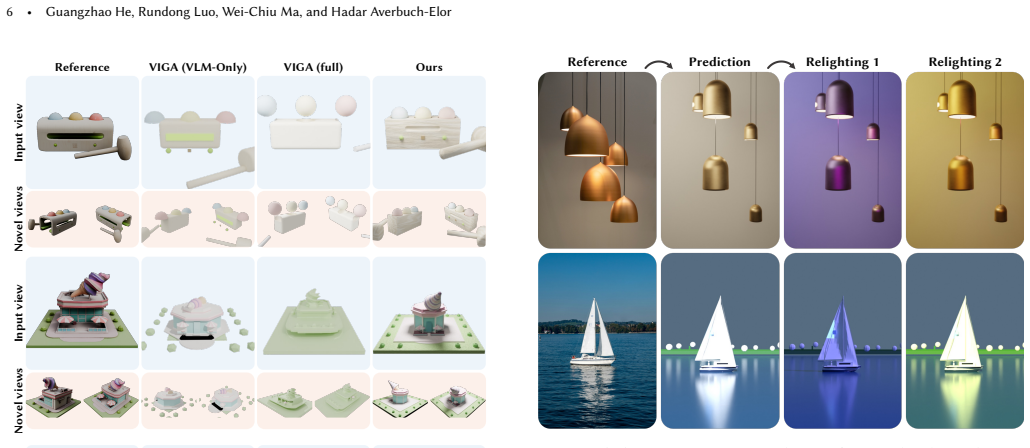
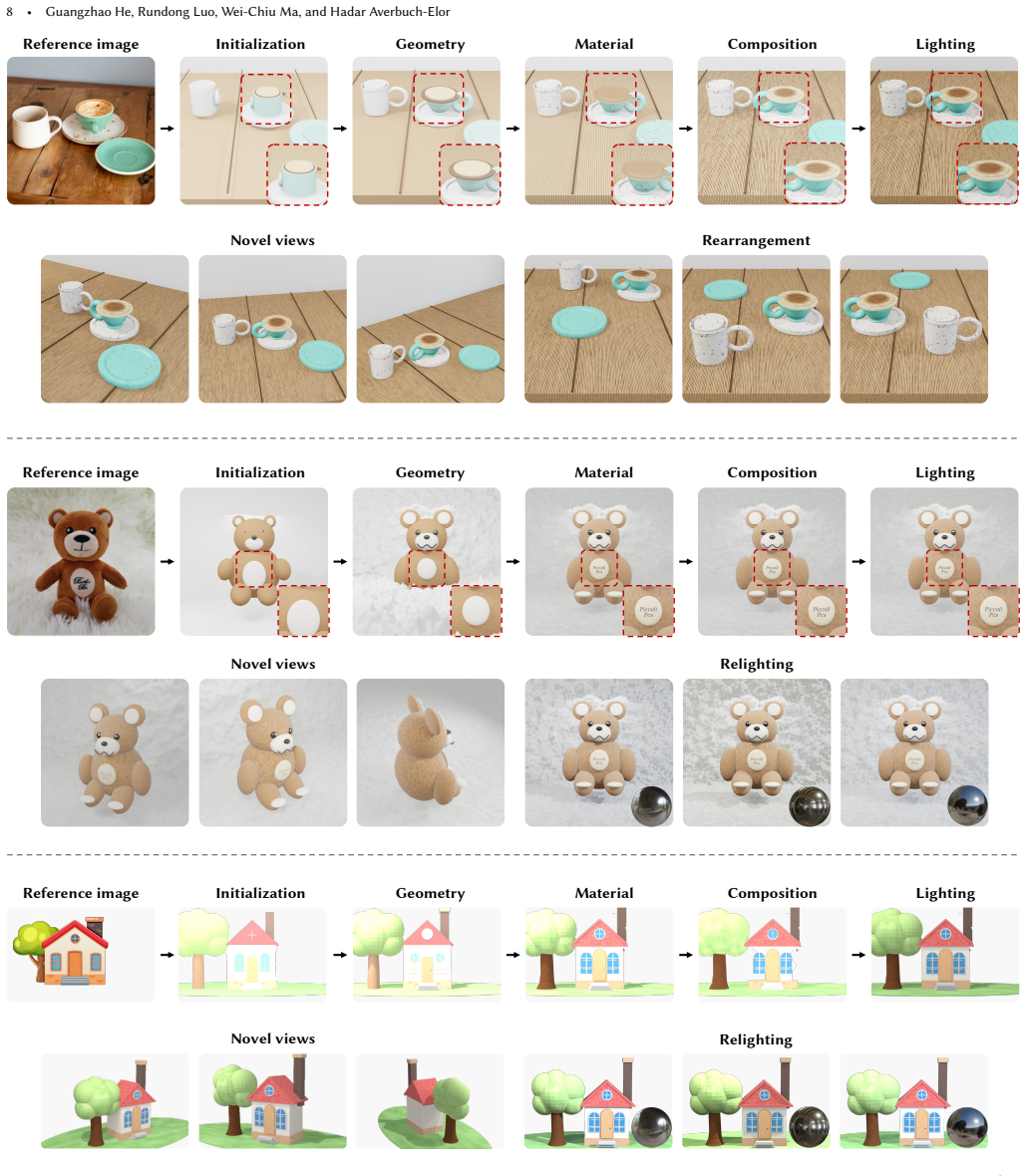
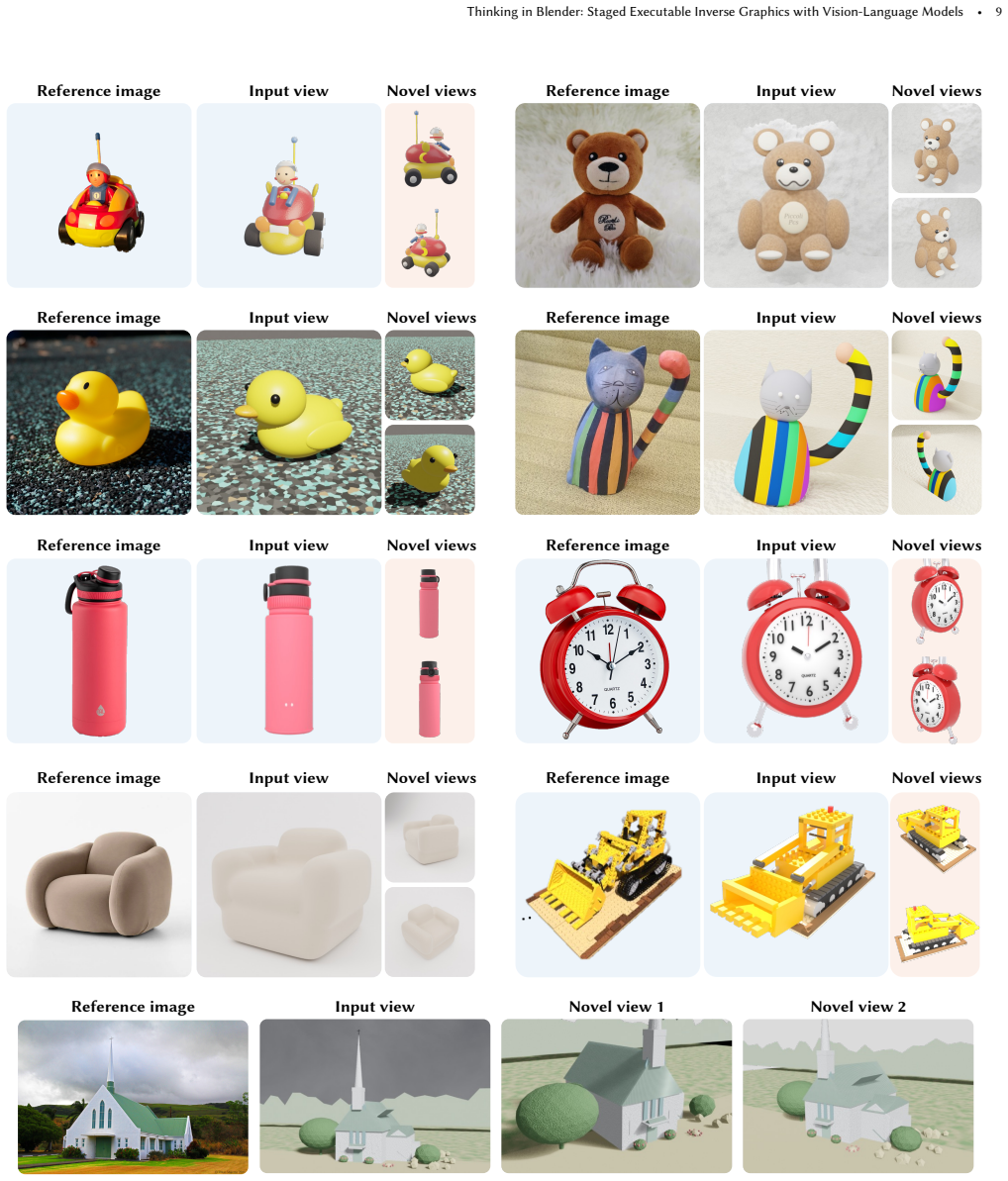
Staged Executable Inverse Graphics (SEIG) enables pretrained VLMs to perform executable inverse graphics from a single image by progressively refining scene factors including geometry, materials, composition, and lighting directly in executable Blender code space. The experiments demonstrate that this staged reconstruction substantially improves reconstruction fidelity over non-staged baselines.
What carries the argument
The SEIG framework that decomposes reconstruction into sequential refinements of geometry, materials, composition, and lighting inside executable Blender code.
If this is right
- Staged decomposition raises reconstruction fidelity across pixel-level, perceptual, and semantic metrics.
- The resulting Blender programs support direct rendering, relighting, and object manipulation.
- The method operates with only a single image and off-the-shelf VLMs, without specialized 3D models or multi-view supervision.
- Reconstructed scenes enable downstream editing and rendering applications inside standard Blender.
Where Pith is reading between the lines
- If VLM code-generation accuracy continues to rise, the same staged approach could handle more cluttered or dynamic scenes.
- The decomposition pattern may transfer to other tasks that require generating long, structured code outputs from visual input.
- One could measure whether adding further intermediate stages beyond the four described continues to improve results or saturates.
- Editable Blender outputs could serve as starting points for interactive tools that let users adjust scenes through natural language.
Load-bearing premise
That pretrained vision-language models already contain enough spatial reasoning and code-generation ability to write correct Blender programs for diverse real scenes from a single view without 3D training or extra images.
What would settle it
Generate Blender programs from a test set of real single images, render them, and measure whether the rendered outputs match the input images in geometry and appearance at rates no better than non-staged baselines.
Figures



read the original abstract
Inverse graphics is a longstanding and highly underconstrained problem that seeks to reconstruct images as editable 3D scenes which can be rendered, relit, and manipulated. In this work, we investigate whether pretrained vision-language models (VLMs) can perform executable inverse graphics directly from a single image by reconstructing a scene as an editable Blender program, without relying on specialized 2D or 3D foundation models, differentiable rendering, or multi-view supervision. We introduce Staged Executable Inverse Graphics (SEIG), an agentic framework that reconstructs a 3D scene from a single image by progressively refining scene factors including geometry, materials, composition, and lighting directly in executable Blender code space. We evaluate our framework across diverse scenes using a range of reconstruction metrics spanning pixel-level, perceptual, and semantic fidelity. Our experiments show that staged reconstruction substantially improves reconstruction fidelity, highlighting the importance of task decomposition for executable inverse graphics with general-purpose VLMs. Finally, we showcase various downstream applications enabled by the reconstructed editable Blender scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Staged Executable Inverse Graphics (SEIG), an agentic framework in which pretrained vision-language models generate executable Blender programs to reconstruct editable 3D scenes from single images. The reconstruction proceeds by progressive refinement of scene factors (geometry, materials, composition, lighting) directly in code space, without specialized 3D models, differentiable rendering, or multi-view supervision. The central claim is that this staged decomposition substantially improves reconstruction fidelity over direct (non-staged) VLM prompting, as measured by pixel-level, perceptual, and semantic metrics, while also enabling downstream editing applications.
Significance. If the quantitative results and ablations hold, the work would provide evidence that general-purpose VLMs can be orchestrated for practical inverse-graphics tasks via executable code output, reducing dependence on 3D-specific foundation models. The emphasis on editability and the absence of invented parameters or closed-form derivations are consistent with an empirical agentic approach.
major comments (3)
- [Abstract] Abstract: the assertion that 'staged reconstruction substantially improves reconstruction fidelity' is presented without any numerical results, baseline descriptions, error analysis, or statistical tests; this is load-bearing for the central claim.
- [Evaluation / Experiments] Evaluation / Experiments: no ablation equalizes total VLM calls, token budget, or wall-clock inference cost between the staged SEIG pipeline and the direct baseline, so any measured lift cannot yet be attributed to task decomposition rather than extra inference opportunities.
- [Method / Evaluation] Method / Evaluation: the claim that pretrained VLMs suffice for correct Blender programs on diverse real scenes (without 3D training or multi-view data) is not accompanied by reported success rates, failure-case analysis, or comparison against 3D-specific baselines, leaving the weakest assumption untested.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below with honest responses and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'staged reconstruction substantially improves reconstruction fidelity' is presented without any numerical results, baseline descriptions, error analysis, or statistical tests; this is load-bearing for the central claim.
Authors: We agree the abstract should better support the central claim with concrete evidence. We will revise it to include key quantitative results (e.g., improvements in PSNR, LPIPS, and semantic metrics) and brief baseline descriptions drawn from the Experiments section. revision: yes
-
Referee: [Evaluation / Experiments] Evaluation / Experiments: no ablation equalizes total VLM calls, token budget, or wall-clock inference cost between the staged SEIG pipeline and the direct baseline, so any measured lift cannot yet be attributed to task decomposition rather than extra inference opportunities.
Authors: This is a valid point; the staged pipeline uses multiple VLM calls by design. We will add a controlled ablation that matches total VLM calls and token budget (e.g., by granting the direct baseline equivalent refinement iterations) to isolate the effect of decomposition. revision: yes
-
Referee: [Method / Evaluation] Method / Evaluation: the claim that pretrained VLMs suffice for correct Blender programs on diverse real scenes (without 3D training or multi-view data) is not accompanied by reported success rates, failure-case analysis, or comparison against 3D-specific baselines, leaving the weakest assumption untested.
Authors: We will add explicit success rates for valid executable program generation and a failure-case analysis section. Direct comparisons to 3D-specific baselines fall outside our focus on general-purpose VLMs without specialized training or multi-view data, but we will expand the discussion of related work for context. revision: partial
Circularity Check
No circularity: empirical agentic framework with independent evaluation
full rationale
The paper describes an empirical agentic pipeline (SEIG) that uses pretrained VLMs to generate staged Blender code from single images, with results measured on pixel, perceptual, and semantic metrics. No equations, derivations, or parameter-fitting steps are present that reduce outputs to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central claim rests on experimental comparisons rather than any closed mathematical reduction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained VLMs contain sufficient implicit 3D and code-generation knowledge to solve inverse graphics when prompted in stages.
Reference graph
Works this paper leans on
-
[1]
European Conference on Computer Vision , year =
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis , author =. European Conference on Computer Vision , year =
-
[2]
ACM Transactions on Graphics , year =
3D Gaussian Splatting for Real-Time Radiance Field Rendering , author =. ACM Transactions on Graphics , year =
-
[3]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Deep 3d capture: Geometry and reflectance from sparse multi-view images , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[4]
ACM Transactions on Graphics , year=
Practical svbrdf acquisition of 3d objects with unstructured flash photography , author=. ACM Transactions on Graphics , year=
-
[5]
ACM Transactions on Graphics , year=
Appearance-from-motion: Recovering spatially varying surface reflectance under unknown lighting , author=. ACM Transactions on Graphics , year=
-
[6]
ACM Transactions on Graphics , year=
Learning to reconstruct shape and spatially-varying reflectance from a single image , author=. ACM Transactions on Graphics , year=
-
[7]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Csgnet: Neural shape parser for constructive solid geometry , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[8]
Advances in Neural Information Processing Systems , year=
Differentiable blocks world: Qualitative 3d decomposition by rendering primitives , author=. Advances in Neural Information Processing Systems , year=
-
[9]
IEEE/CVF Winter Conference on Applications of Computer Vision , year=
Volumetric disentanglement for 3d scene manipulation , author=. IEEE/CVF Winter Conference on Applications of Computer Vision , year=
-
[10]
IEEE/CVF International Conference on Computer Vision , year=
Learning object-compositional neural radiance field for editable scene rendering , author=. IEEE/CVF International Conference on Computer Vision , year=
-
[11]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Dynamic lidar re-simulation using compositional neural fields , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[12]
International Conference on Learning Representations , year=
Omnire: Omni urban scene reconstruction , author=. International Conference on Learning Representations , year=
-
[13]
Shape from shading: A method for obtaining the shape of a smooth opaque object from one view , author=
-
[14]
Computer Vision Systems , year=
Recovering intrinsic scene characteristics , author=. Computer Vision Systems , year=
-
[15]
1963 , school=
Machine perception of three-dimensional solids , author=. 1963 , school=
1963
-
[16]
arXiv preprint arXiv:2601.11109 , year =
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning , author =. arXiv preprint arXiv:2601.11109 , year =
-
[17]
arXiv preprint arXiv:2410.13882 , year =
Articulate-Anything: Automatic Modeling of Articulated Objects via a Vision-Language Foundation Model , author =. arXiv preprint arXiv:2410.13882 , year =
-
[18]
arXiv preprint arXiv:2505.05469 , year =
Generating Physically Stable and Buildable Brick Structures from Text , author =. arXiv preprint arXiv:2505.05469 , year =
-
[19]
arXiv preprint arXiv:2307.05663 , year =
Objaverse-XL: A Universe of 10M+ 3D Objects , author =. arXiv preprint arXiv:2307.05663 , year =
-
[20]
Inverse Rendering for Computer Graphics , author =
-
[21]
ACM SIGGRAPH , year =
A Signal-Processing Framework for Inverse Rendering , author =. ACM SIGGRAPH , year =
-
[22]
Advances in Neural Information Processing Systems , year =
Deep Convolutional Inverse Graphics Network , author =. Advances in Neural Information Processing Systems , year =
-
[23]
arXiv preprint arXiv:2404.15228 , year =
Re-Thinking Inverse Graphics With Large Language Models , author =. arXiv preprint arXiv:2404.15228 , year =
-
[24]
arXiv preprint arXiv:2405.14871 , year =
NeRF-Casting: Improved View-Dependent Appearance with Consistent Reflections , author =. arXiv preprint arXiv:2405.14871 , year =
-
[25]
arXiv preprint arXiv:2304.12461 , year =
TensoIR: Tensorial Inverse Rendering , author =. arXiv preprint arXiv:2304.12461 , year =
-
[26]
IEEE/CVF International Conference on Computer Vision , year =
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions , author =. IEEE/CVF International Conference on Computer Vision , year =
-
[27]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
DRAWER: Digital Reconstruction and Articulation With Environment Realism , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[28]
Advances in Neural Information Processing Systems , year =
Visual Instruction Tuning , author =. Advances in Neural Information Processing Systems , year =
-
[29]
arXiv preprint arXiv:2409.12191 , year =
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author =. arXiv preprint arXiv:2409.12191 , year =
-
[30]
arXiv preprint arXiv:2508.08228 , year =
LL3M: Large Language 3D Modelers , author =. arXiv preprint arXiv:2508.08228 , year =
-
[31]
arXiv preprint arXiv:2512.11061 , year =
VDAWorld: World Modelling via VLM-Directed Abstraction and Simulation , author =. arXiv preprint arXiv:2512.11061 , year =
-
[32]
ACM Transactions on Graphics , year =
NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination , author =. ACM Transactions on Graphics , year =
-
[33]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
VGGT: Visual Geometry Grounded Transformer , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[34]
2024 , journal=
The Scene Language: Representing Scenes with Programs, Words, and Embeddings , author=. 2024 , journal=
2024
-
[35]
Advances in Neural Information Processing Systems , year=
CAT3D: Create Anything in 3D with Multi-View Diffusion Models , author=. Advances in Neural Information Processing Systems , year=
-
[36]
Barron and Pratul P
Dor Verbin and Peter Hedman and Ben Mildenhall and Todd Zickler and Jonathan T. Barron and Pratul P. Srinivasan , booktitle=
-
[37]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
PhySG: Inverse Rendering with Spherical Gaussians for Physics-based Material Editing and Relighting , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[38]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Extracting Triangular 3D Models, Materials, and Lighting From Images , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[39]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
GS-IR: 3D Gaussian Splatting for Inverse Rendering , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[40]
GPT-4V(ision) System Card , author =
-
[41]
Gemini: A Family of Highly Capable Multimodal Models , author =
-
[42]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[43]
2025 , howpublished =
Claude Opus 4.7 , author =. 2025 , howpublished =
2025
-
[44]
Transactions on Machine Learning Research , year =
Unsupervised Discovery of Object-Centric Neural Fields , author =. Transactions on Machine Learning Research , year =
-
[45]
arXiv preprint arXiv:2312.09738 , year =
3DAxiesPrompts: Unleashing the 3D Spatial Task Capabilities of GPT-4V , author =. arXiv preprint arXiv:2312.09738 , year =
-
[46]
International Conference on Machine Learning , year =
SceneCraft: An LLM Agent for Synthesizing 3D Scenes as Blender Code , author =. International Conference on Machine Learning , year =
-
[47]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
BlenderGym: Benchmarking Foundational Model Systems for Graphics Editing , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[48]
arXiv preprint arXiv:2508.14879 , year =
MeshCoder: LLM-Powered Structured Mesh Code Generation from Point Clouds , author =. arXiv preprint arXiv:2508.14879 , year =
-
[49]
arXiv preprint arXiv:2506.23329 , year =
IR3D-Bench: Evaluating Vision-Language Model Scene Understanding as Agentic Inverse Rendering , author =. arXiv preprint arXiv:2506.23329 , year =
-
[50]
International Conference on 3D Vision , year =
Voxhammer: Training-free precise and coherent 3d editing in native 3d space , author =. International Conference on 3D Vision , year =
-
[51]
IEEE/CVF International Conference on Computer Vision , year =
Segment Anything , author =. IEEE/CVF International Conference on Computer Vision , year =
-
[52]
arXiv preprint arXiv:2511.16624 , year =
SAM 3D: 3Dfy Anything in Images , author =. arXiv preprint arXiv:2511.16624 , year =
-
[53]
Advances in Neural Information Processing Systems , year =
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data , author =. Advances in Neural Information Processing Systems , year =
-
[54]
International Conference on Machine Learning , year =
Learning Transferable Visual Models From Natural Language Supervision , author =. International Conference on Machine Learning , year =
-
[55]
Advances in Neural Information Processing Systems , year =
Non-rigid Point Cloud Registration with Neural Deformation Pyramid , author =. Advances in Neural Information Processing Systems , year =
-
[56]
Transactions on Machine Learning Research , year =
DINOv2: Learning Robust Visual Features without Supervision , author =. Transactions on Machine Learning Research , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.