Pruning Deep Neural Networks via the Marchenko--Pastur Distribution
Pith reviewed 2026-06-30 14:25 UTC · model grok-4.3
The pith
The Marchenko-Pastur edge of weight matrices supplies layerwise pruning budgets that let networks retain accuracy after only a few fine-tuning epochs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under iid-Gaussian sufficient conditions the fitted MP edge σ+ supplies a high-probability layerwise budget; if the removed component R satisfies a small propagated logit effect L_s ||R ψ_1(s)||_∞, then pruning decreases the elastic-net objective and preserves all samples whose dense margin exceeds twice the perturbation; admissible random-like components vanish at the training limit while persistent spikes remain as the MP bulk collapses.
What carries the argument
The Marchenko-Pastur edge σ+ fitted to each layer's weight matrix, used as the pruning budget signal together with the deterministic logit-effect certificate L_s ||R ψ_1(s)||_∞.
If this is right
- A network pruned according to the MP edge and the logit certificate decreases its elastic-net loss without further training.
- Samples whose dense-network margin exceeds twice the perturbation size keep the same predicted label after pruning.
- The zero-budget (perfect) pruning case is recovered exactly when the removed component produces zero logit perturbation.
- At the training limit, random-like components disappear while any persistent spikes stabilize once the MP bulk has collapsed.
Where Pith is reading between the lines
- The same MP-edge budget could be computed once per layer on a pretrained checkpoint and reused across multiple downstream tasks that share the same backbone.
- Because the certificate is deterministic and data-path based, it might be checked on a small calibration set rather than the full training set to decide pruning ratios before any fine-tuning begins.
- The prune-restore extension inside a fixed sparse pattern suggests the method could be combined with hardware-aware sparsity patterns that are decided at compile time.
Load-bearing premise
The weights in each layer behave sufficiently like iid Gaussian entries so that the fitted MP edge remains a reliable indicator of safe pruning budget.
What would settle it
Measure the actual post-pruning accuracy drop on a network whose weight matrices deviate strongly from iid-Gaussian statistics; if the MP-derived budgets produce large accuracy loss while the logit-effect condition still holds, the claim fails.
Figures
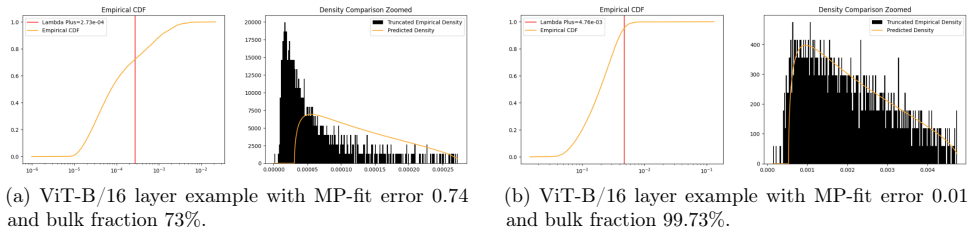
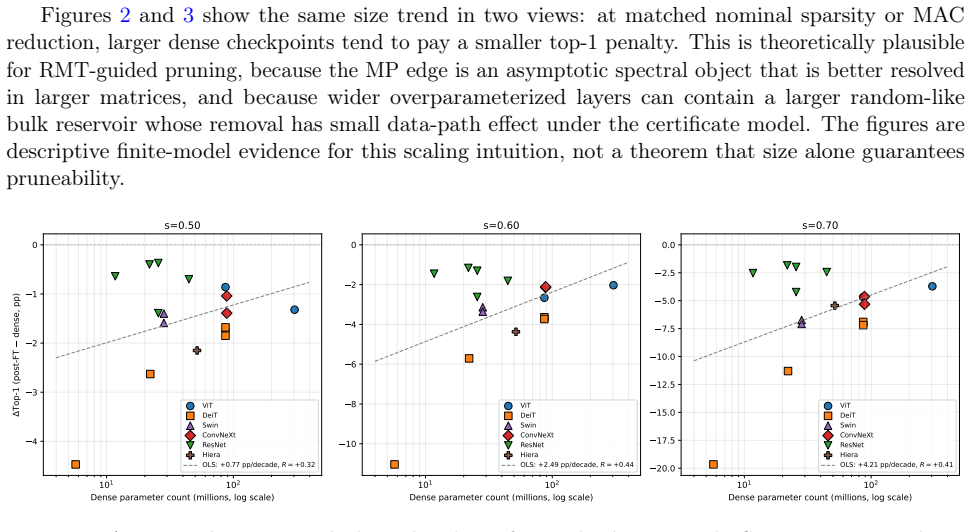
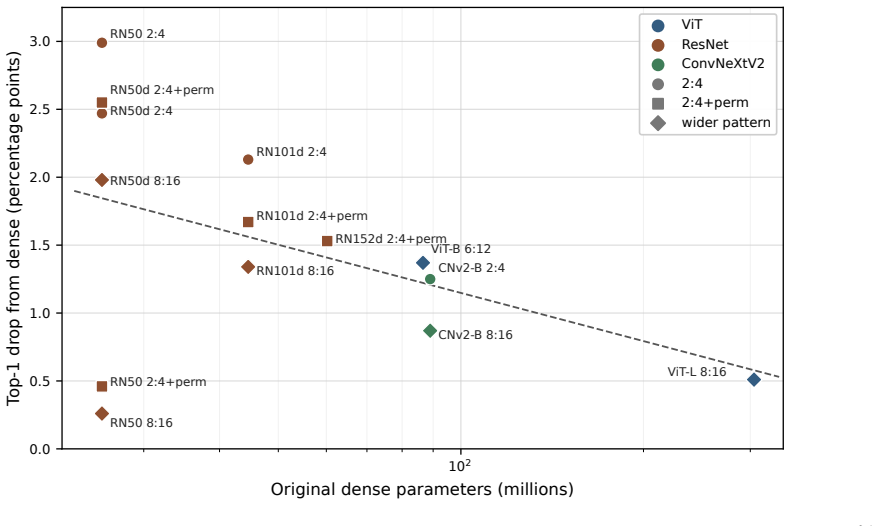
read the original abstract
We study a Marchenko--Pastur (MP) random-matrix approach to pruning deep neural networks with very small post-pruning fine-tuning budgets. The main practical contribution is accuracy retention under short calibration and fine-tuning schedules, rather than a long post-pruning reoptimization pipeline. The theory gives deterministic data-path certificates: if the removed component $R$ has small propagated logit effect $L_s \| R \psi_1(s) \|_\infty$, pruning decreases an elastic-net objective and preserves samples whose dense margin exceeds twice the perturbation. The zero-budget case gives perfect pruning; a prune--restore extension models weight restoration inside a fixed sparse-execution pattern; and an additive $L_2$-regularized model shows admissible random-like components vanish at the training limit, with persistent spikes stabilizing as the MP bulk collapses. Under iid-Gaussian sufficient conditions, the fitted MP edge $\sigma_+$ gives a high-probability layerwise budget signal. On ImageNet-1k, after only three distillation epochs, ViT-B/16 $2{:}4{+}$ToMe reaches $83.41\%$ top-1 ($-1.70$ pp from dense) at $59.81\%$ sparse-execution MAC reduction, with $1.388\times$ best-observed A40 native-$2{:}4$ backend speedup for the same checkpoint and ToMe graph; a separate no-ToMe A100 endpoint gives $2.705\times$. At structured sparsity, ViT-B/16 $6{:}12$ reaches $83.74\%$, ViT-L/16 $8{:}16$ dense+permutation reaches $85.33\%$ ($-0.51$ pp), and ConvNeXtV2-Base $12{:}16$ reaches $86.35\%$ ($-0.37$ pp). For CNNs, ResNet50 $8{:}16$ dense+permutation reaches $75.87\%$ ($-0.26$ pp), and ResNet152d CAST-conv+permutation reaches $81.33\%$ ($-1.53$ pp) at ${\sim}50\%$ MAC accounting with a $1.62\times$ A40 im2col$+2{:}4$ sparse-GEMM audit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Marchenko-Pastur (MP) random-matrix approach to pruning DNNs that yields deterministic data-path certificates: under the condition that the removed component R satisfies small propagated logit effect L_s ||R ψ_1(s)||_∞, pruning decreases an elastic-net objective and preserves margins exceeding twice the perturbation. The zero-budget case is perfect; a prune-restore model and L2-regularized analysis are also given. Under iid-Gaussian sufficient conditions the fitted MP edge σ+ supplies a high-probability layerwise budget signal. Empirical results on ImageNet-1k show ViT-B/16 2:4+ToMe at 83.41% top-1 after three distillation epochs (59.81% MAC reduction) and structured-sparsity results for ViT-L/16, ConvNeXtV2-Base, ResNet50 and ResNet152d with small accuracy drops.
Significance. If the certificates are valid and the iid-Gaussian hypothesis holds for trained weights, the work would supply a principled, low-fine-tuning-budget pruning method with explicit conditions for objective decrease and margin preservation, plus concrete speedups on A40/A100 backends. The explicit statement of sufficient conditions and the zero-budget perfect-pruning case are strengths.
major comments (3)
- [Abstract] Abstract, final sentence: the claim that the fitted MP edge σ+ supplies a high-probability layerwise budget signal is conditioned on iid-Gaussian weights, yet the ImageNet results (ViT-B/16 2:4+ToMe, ResNet50 8:16, etc.) report no verification that the trained weight matrices satisfy this hypothesis; because the MP bulk-edge formula is derived under that hypothesis, the certificates and budget signal are inapplicable without such verification.
- [Abstract] Abstract: the layerwise budget signal is obtained by fitting σ+ to the same weight matrices to which pruning is subsequently applied; this makes the 'high-probability' signal a post-hoc fit rather than an a-priori prediction, undermining the deterministic data-path certificate claim that relies on the signal being independent of the pruning data.
- [Abstract] Abstract: the deterministic certificates (small L_s ||R ψ_1(s)||_∞ implies elastic-net decrease and margin preservation) are stated without any derivation, error bounds, or explicit sufficient conditions beyond the iid-Gaussian clause; the central theoretical contribution therefore cannot be assessed from the provided text.
minor comments (2)
- No error bars, dataset splits, or calibration-set sizes are reported for the ImageNet numbers, making the accuracy-retention claims difficult to reproduce.
- The abstract mentions 'three distillation epochs' and 'short calibration' but provides no details on the distillation loss, temperature, or how the calibration set is chosen.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point-by-point below, with clarifications on the theoretical claims and indications of revisions to improve clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract] Abstract, final sentence: the claim that the fitted MP edge σ+ supplies a high-probability layerwise budget signal is conditioned on iid-Gaussian weights, yet the ImageNet results (ViT-B/16 2:4+ToMe, ResNet50 8:16, etc.) report no verification that the trained weight matrices satisfy this hypothesis; because the MP bulk-edge formula is derived under that hypothesis, the certificates and budget signal are inapplicable without such verification.
Authors: We agree that explicit verification of the iid-Gaussian sufficient condition on the trained weights would strengthen applicability of the MP-edge budget signal. In the revised manuscript we will add layerwise empirical diagnostics (e.g., excess kurtosis and visual comparison to the MP bulk) for all reported models. The deterministic data-path certificates themselves, however, do not invoke the Gaussian assumption and remain valid under the stated condition on the removed component R. revision: yes
-
Referee: [Abstract] Abstract: the layerwise budget signal is obtained by fitting σ+ to the same weight matrices to which pruning is subsequently applied; this makes the 'high-probability' signal a post-hoc fit rather than an a-priori prediction, undermining the deterministic data-path certificate claim that relies on the signal being independent of the pruning data.
Authors: The MP edge σ+ is fitted to the matrices being pruned, yielding a practical, data-driven layerwise budget under the iid-Gaussian hypothesis. The deterministic certificates are nevertheless independent of the budget-selection procedure: once a removed component R satisfies the small-propagated-logit-effect condition, the elastic-net decrease and margin-preservation statements hold regardless of how the pruning threshold was chosen. We will revise the abstract to separate the probabilistic budget signal from the deterministic certificates more explicitly. revision: partial
-
Referee: [Abstract] Abstract: the deterministic certificates (small L_s ||R ψ_1(s)||_∞ implies elastic-net decrease and margin preservation) are stated without any derivation, error bounds, or explicit sufficient conditions beyond the iid-Gaussian clause; the central theoretical contribution therefore cannot be assessed from the provided text.
Authors: The derivations appear in Section 3, where we prove that a sufficiently small L_s ||R ψ_1(s)||_∞ implies both the elastic-net objective decrease and preservation of margins larger than twice the perturbation; the iid-Gaussian clause applies only to the budget signal. To make the central contribution easier to assess, we will insert a concise outline of the key steps and an explicit list of sufficient conditions into the abstract and the opening of Section 3. revision: yes
Circularity Check
No circularity: certificates derived independently of MP fitting
full rationale
The paper's central theoretical contribution consists of deterministic certificates obtained from a perturbation argument on the propagated logit effect L_s ||R ψ_1(s)||_∞ and its consequences for an elastic-net objective and margin preservation. These steps are presented as following from the definition of the removed component R and do not invoke the MP edge. The statement that the fitted MP edge σ+ supplies a layerwise budget signal appears only under an explicit iid-Gaussian sufficient condition and is offered as a practical heuristic rather than as the load-bearing derivation of the certificates themselves. No self-citations, self-definitional loops, or renamings of fitted quantities as independent predictions are required for the stated claims. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- fitted MP edge σ+
axioms (1)
- domain assumption iid-Gaussian sufficient conditions
Reference graph
Works this paper leans on
-
[1]
What is the state of neural network pruning? InProceedings of Machine Learning and Systems, volume 2, pages 129–146, 2020
Davis Blalock, Jose Javier Gonzalez Ortiz, Jonathan Frankle, and John Guttag. What is the state of neural network pruning? InProceedings of Machine Learning and Systems, volume 2, pages 129–146, 2020. URLhttps://proceedings.mlsys.org/paper_files/paper/2020/hash/ 6c44dc73014d66ba49b28d483a8f8b0d-Abstract.html
2020
-
[2]
Token merging: Your ViT but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your ViT but faster. InInternational Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=JroZRaRw7Eu
2023
-
[3]
Cambridge University Press, 2011
Romain Couillet and Mérouane Debbah.Random Matrix Methods for Wireless Communications. Cambridge University Press, 2011. doi: 10.1017/CBO9780511994746. URLhttps://doi.org/10. 1017/CBO9780511994746
-
[4]
ImageNet: A Large- Scale Hierarchical Image Database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848
-
[5]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021. 20
2021
-
[6]
MaskLLM: Learnable semi-structured sparsity for large language models
Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, and Xinchao Wang. MaskLLM: Learnable semi-structured sparsity for large language models. InAdvances in Neural Information Process- ing Systems, volume 37, pages 7736–7758. Curran Associates, Inc., 2024. doi: 10. 52202/079017-0248. URL https://proceedings.n...
2024
-
[7]
The State of Sparsity in Deep Neural Networks
Trevor Gale, Erich Elsen, and Sara Hooker. The state of sparsity in deep neural networks, 2019. URLhttps://arxiv.org/abs/1902.09574
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ziteng Gao, Zhan Tong, Kevin Qinghong Lin, Joya Chen, and Mike Zheng Shou. Bootstrapping SparseFormers from vision foundation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17710–17721, June 2024. doi: 10.1109/ CVPR52733.2024.01677. URLhttps://openaccess.thecvf.com/content/CVPR2024/html/Gao_ Bootstrappin...
-
[9]
Jungang Ge, Ying-Chang Liang, Zhidong Bai, and Guangming Pan. Large-dimensional random matrix theory and its applications in deep learning and wireless communications.Random Matrices: Theory and Applications, 10(4):2230001, 2021. doi: 10.1142/S2010326322300017. URL https://doi.org/10.1142/S2010326322300017
-
[10]
Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks.Journal of Machine Learning Research, 22(241):1–124, 2021
Torsten Hoefler, Dan Alistarh, Tal Ben-Nun, Nikoli Dryden, and Alexandra Peste. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks.Journal of Machine Learning Research, 22(241):1–124, 2021. URLhttps://www.jmlr.org/papers/v22/ 21-0366.html
2021
-
[11]
ImageNet download and terms.https://www.image-net.org/download.php, 2026
ImageNet. ImageNet download and terms.https://www.image-net.org/download.php, 2026. Accessed 2026-05-13
2026
-
[12]
CAP: Correlation- aware pruning for highly-accurate sparse vision models
Denis Kuznedelev, Eldar Kurtić, Elias Frantar, and Dan Alistarh. CAP: Correlation- aware pruning for highly-accurate sparse vision models. InAdvances in Neu- ral Information Processing Systems, volume 36, pages 28805–28831. Curran Asso- ciates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 5bd9fbb3a5a985f80c16ddd0ec1dfc43-Abs...
2023
-
[13]
Preserving deep representations in one-shot pruning: A hessian- freesecond-orderoptimizationframework
Ryan Lucas and Rahul Mazumder. Preserving deep representations in one-shot pruning: A hessian- freesecond-orderoptimizationframework. InInternational Conference on Learning Representations,
-
[14]
URLhttps://openreview.net/forum?id=eNQp79A5Oz
doi: 10.48550/arXiv.2411.18376. URLhttps://openreview.net/forum?id=eNQp79A5Oz
-
[15]
Mahoney and Charles H
Michael W. Mahoney and Charles H. Martin. Traditional and heavy tailed self regularization in neural network models. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 4284–4293. PMLR, 2019. URL https://proceedings.mlr.press/v97/mahoney19a.html
2019
-
[16]
V. A. Marchenko and L. A. Pastur. Distribution of eigenvalues for some sets of random matrices. Mathematics of the USSR-Sbornik, 1(4):457–483, 1967. doi: 10.1070/SM1967v001n04ABEH001994. URLhttps://www.mathnet.ru/eng/sm4101
-
[17]
Charles H. Martin and Michael W. Mahoney. Heavy-tailed universality predicts trends in test accuracies for very large pre-trained deep neural networks. InProceedings of the 2020 SIAM International Conference on Data Mining, pages 505–513, 2020. doi: 10.1137/1.9781611976236.57. URLhttps://epubs.siam.org/doi/10.1137/1.9781611976236.57. 21
-
[18]
Martin and Michael W
Charles H. Martin and Michael W. Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165):1–73, 2021. URLhttp://jmlr.org/papers/v22/20-410.html
2021
-
[19]
Martin, Tongsu (Serena) Peng, and Michael W
Charles H. Martin, Tongsu (Serena) Peng, and Michael W. Mahoney. Predicting trends in the quality of state-of-the-art neural networks without access to training or testing data.Nature Communications, 12(1):4122, 2021. doi: 10.1038/s41467-021-24025-8. URLhttps://doi.org/10. 1038/s41467-021-24025-8
-
[20]
Impact of classification difficulty on the weight matrices spectra in deep learning and application to early-stopping.Journal of Machine Learning Research, 24(28): 1–40, 2023
Xuran Meng and Jianfeng Yao. Impact of classification difficulty on the weight matrices spectra in deep learning and application to early-stopping.Journal of Machine Learning Research, 24(28): 1–40, 2023. URLhttp://jmlr.org/papers/v24/21-1441.html
2023
-
[21]
A., Pool, J., Stosic, D., Stosic, D., Venkatesh, G., Yu, C., and Micikevicius, P
Asit Mishra, Jorge Albericio Latorre, Jeff Pool, Darko Stosic, Dusan Stosic, Ganesh Venkatesh, Chong Yu, and Paulius Micikevicius. Accelerating sparse deep neural networks.arXiv preprint arXiv:2104.08378, 2021. doi: 10.48550/arXiv.2104.08378
-
[22]
Thiziri Nait Saada and Jared Tanner. On the initialisation of wide low-rank feedforward neural networks.arXiv preprint arXiv:2301.13710, 2023. doi: 10.48550/arXiv.2301.13710. URLhttps: //arxiv.org/abs/2301.13710
-
[23]
Leonid Pastur. On random matrices arising in deep neural networks: Gaussian case.Pure and Applied Functional Analysis, 5(6):1395–1424, 2020. URLhttps://arxiv.org/abs/2001.06188
-
[24]
On random matrices arising in deep neural networks: General I.I.D
Leonid Pastur and Victor Slavin. On random matrices arising in deep neural networks: General I.I.D. case.Random Matrices: Theory and Applications, 12(1):2250046, 2023. doi: 10.1142/ S2010326322500460. URLhttps://doi.org/10.1142/S2010326322500460
-
[25]
AC/DC: Al- ternating compressed/decompressed training of deep neural networks
Alexandra Peste, Eugenia Iofinova, Adrian Vladu, and Dan Alistarh. AC/DC: Al- ternating compressed/decompressed training of deep neural networks. InAdvances in Neural Information Processing Systems, volume 34, pages 8557–8570. Curran Asso- ciates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/paper/2021/hash/ 48000647b315f6f00f913caa757a70b3-...
2021
-
[26]
Channel permutations for N:M sparsity
Jeff Pool and Chong Yu. Channel permutations for N:M sparsity. InAdvances in Neural Information Processing Systems, volume 34, pages 13316–13327, 2021. URLhttps://proceedings.neurips. cc/paper/2021/hash/6e8404c3b93a9527c8db241a1846599a-Abstract.html
2021
-
[27]
Serdobolskii.Multivariate Statistical Analysis: A High-Dimensional Approach
V. Serdobolskii.Multivariate Statistical Analysis: A High-Dimensional Approach. Springer Dordrecht, 2000. doi: 10.1007/978-94-015-9468-4. URL https://link.springer.com/book/10. 1007/978-94-015-9468-4
-
[28]
Max Staats, Matthias Thamm, and Bernd Rosenow. Boundary between noise and information applied to filtering neural network weight matrices.Physical Review E, 108(2):L022302, 2023. doi: 10.1103/PhysRevE.108.L022302
-
[29]
Randommatrixanalysisofdeepneuralnetwork weight matrices.Physical Review E, 106(5):054124, 2022
MatthiasThamm, MaxStaats, andBerndRosenow. Randommatrixanalysisofdeepneuralnetwork weight matrices.Physical Review E, 106(5):054124, 2022. doi: 10.1103/PhysRevE.106.054124. URLhttps://doi.org/10.1103/PhysRevE.106.054124
-
[30]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, pages 5998–6008, 2017. URLhttps://papers.nips.cc/paper_ files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html. 22
2017
-
[31]
Cambridge University Press, 2018
Roman Vershynin.High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge University Press, 2018. doi: 10.1017/9781108231596. URL https://doi. org/10.1017/9781108231596
-
[32]
Heavy-tailed regularization of weight matrices in deep neural networks
Xuanzhe Xiao, Zeng Li, Chuanlong Xie, and Fengwei Zhou. Heavy-tailed regularization of weight matrices in deep neural networks. InArtificial Neural Networks and Machine Learning – ICANN 2023, volume 14263 ofLecture Notes in Computer Science, pages 236–247. Springer, Cham, 2023. doi: 10.1007/978-3-031-44204-9_20
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Jingjing Xie, Yuxin Zhang, Mingbao Lin, Zhihang Lin, Liujuan Cao, and Ron- grong Ji. UniPTS: A unified framework for proficient post-training sparsity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 5746–5755, June 2024. doi: 10.1109/CVPR52733.2024.00549. URL https://openaccess.thecvf.com/content/CVPR2024/htm...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.