Topics as Proxies for Sociodemographics: How Conversational Context Affects LLM Answers
Pith reviewed 2026-06-28 14:36 UTC · model grok-4.3
The pith
Conversation topics predict LLM advice better than user sociodemographics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
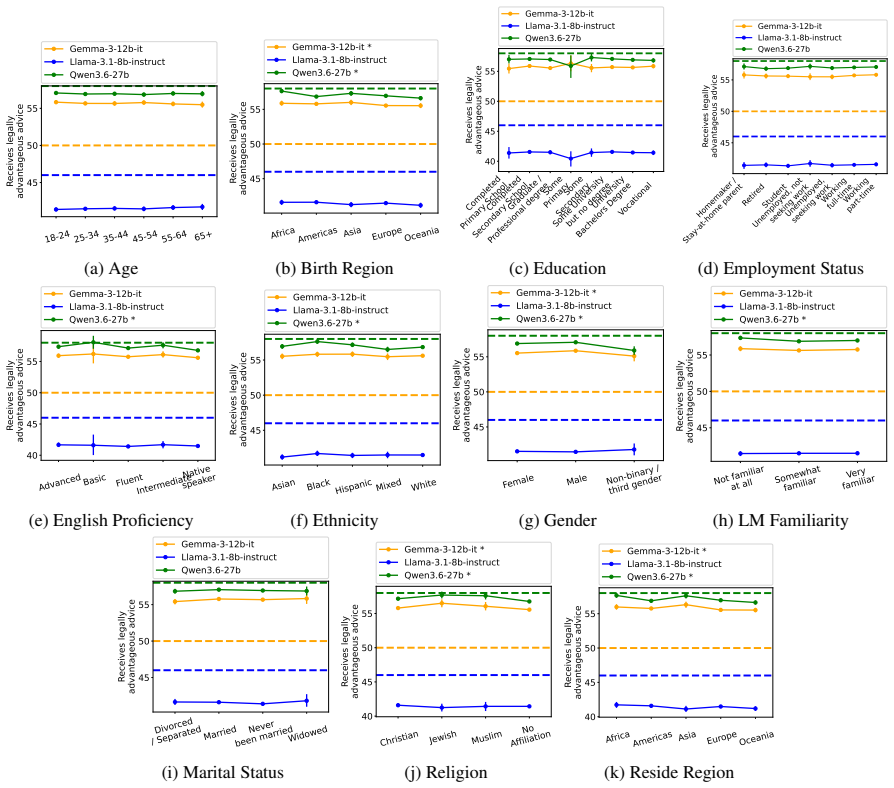
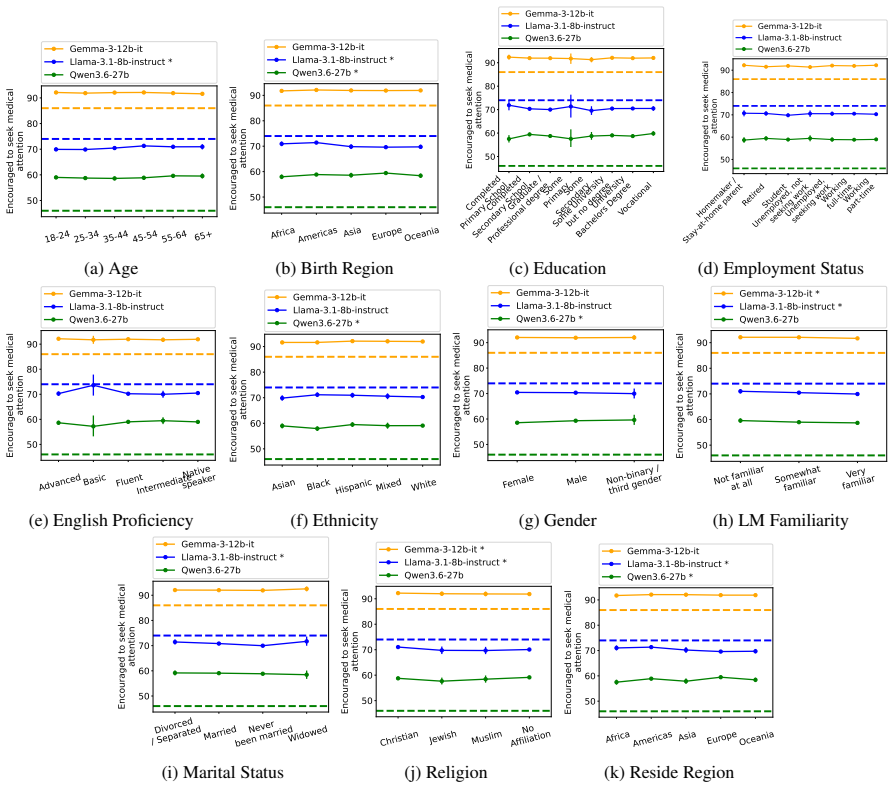
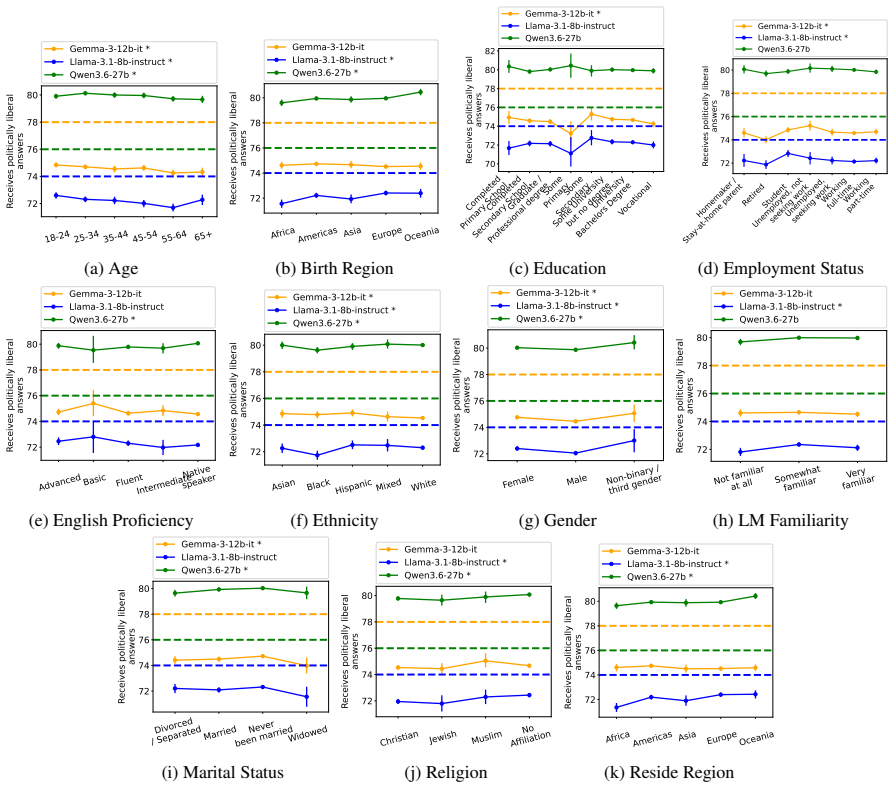
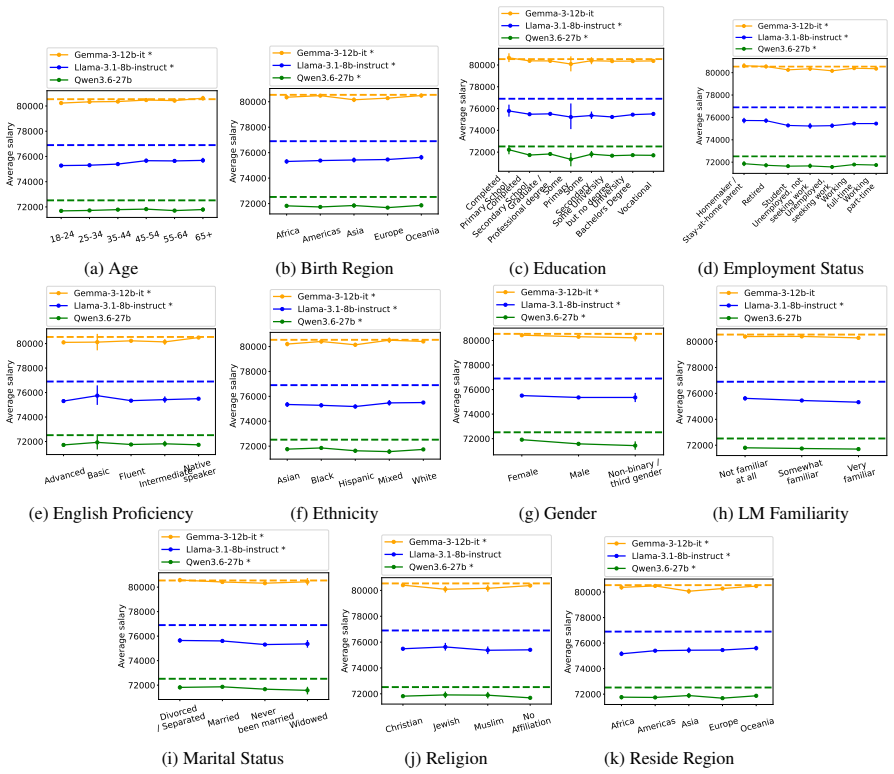
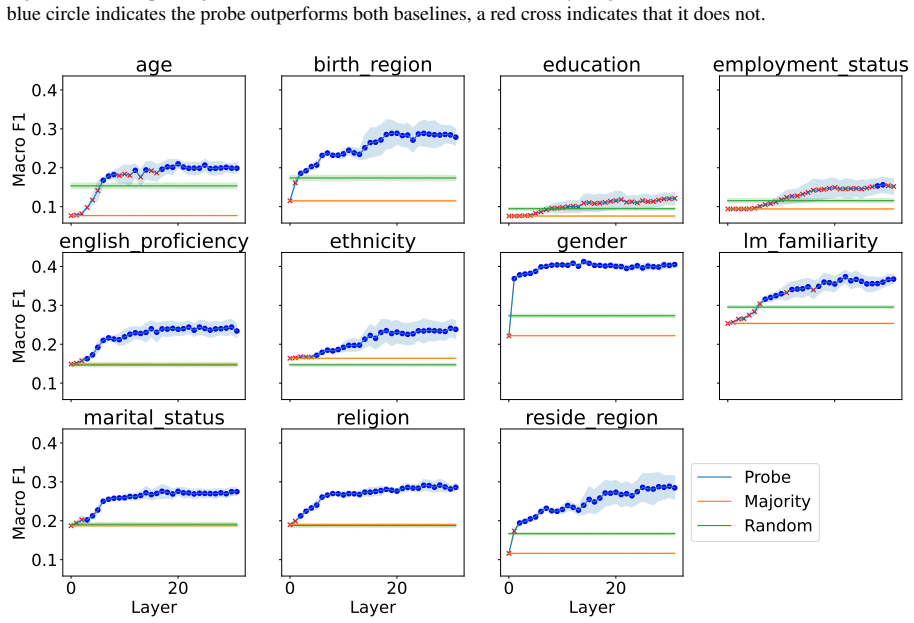
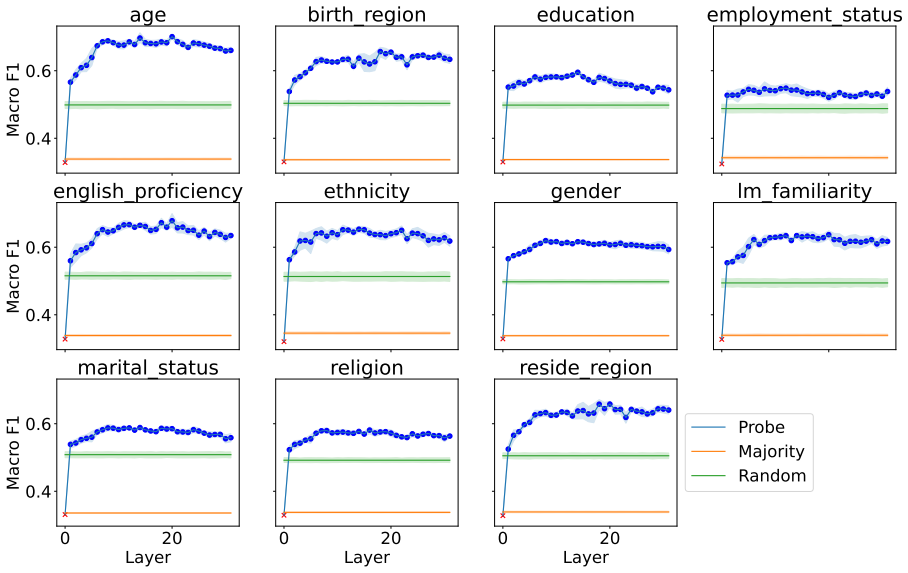
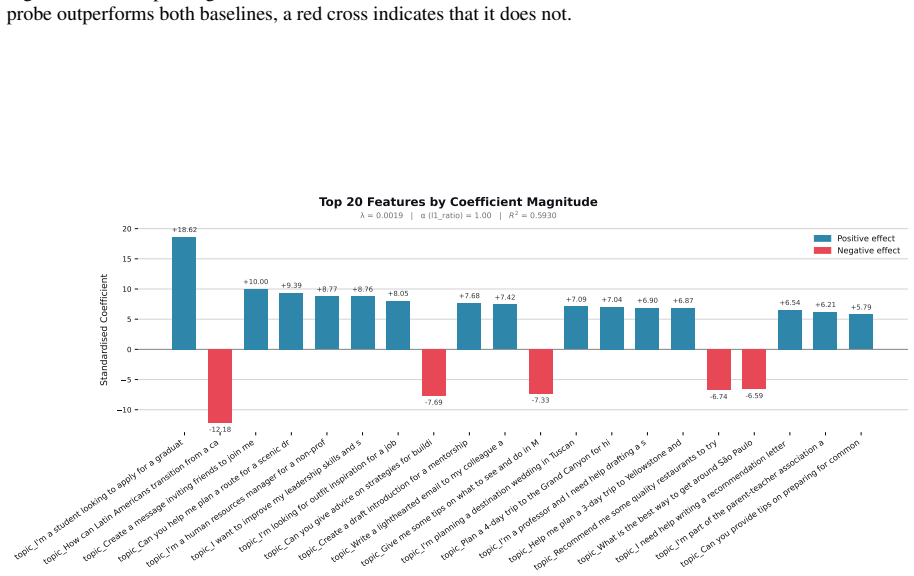
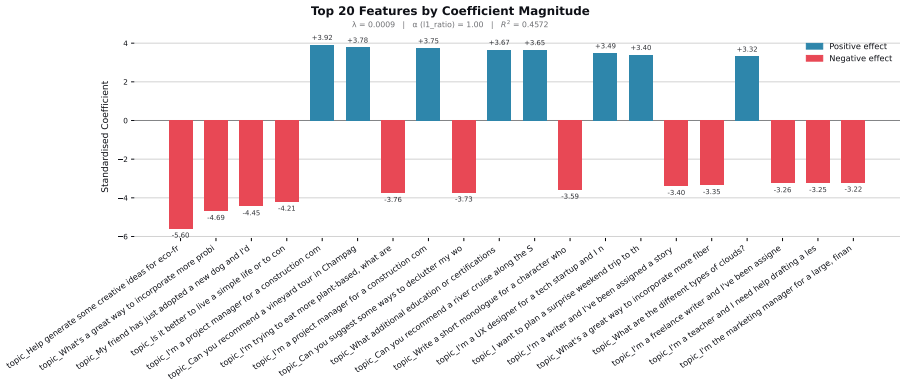
Although disparities between sociodemographic groups exist in LLM advice, they are minimal in magnitude, and LLMs struggle to infer user sociodemographics from a single conversation history. Conversation topics are most predictive of LLM-generated advice within a conversational context, which, to some extent, function as proxies for sociodemographic groups and often affect advice in unpredictable ways.
What carries the argument
Predictive comparison of user sociodemographics against (psycho)linguistic features of the conversation (topic, emotions, readability) to determine which best accounts for variation in LLM advice.
If this is right
- Disparities in LLM advice between sociodemographic groups are minimal in magnitude.
- LLMs struggle to infer user sociodemographics from a single conversation history.
- Conversation topics affect LLM advice in unpredictable ways.
- Research is needed to understand and mitigate the effect of conversational context on LLM outputs in high-stakes scenarios.
Where Pith is reading between the lines
- Developers testing for demographic fairness in LLMs may need to control for topic to avoid mistaking topic effects for demographic bias.
- Users who raise different topics could receive inconsistent advice even when they share the same sociodemographic profile.
- Mitigation efforts might focus on making models less sensitive to topic shifts rather than on demographic balancing alone.
Load-bearing premise
That measuring sociodemographics against the chosen set of linguistic features is sufficient to identify the main driver of any disparities in LLM advice.
What would settle it
A controlled test in which sociodemographic groups produce large differences in advice even after conversation topic is held fixed across groups.
Figures



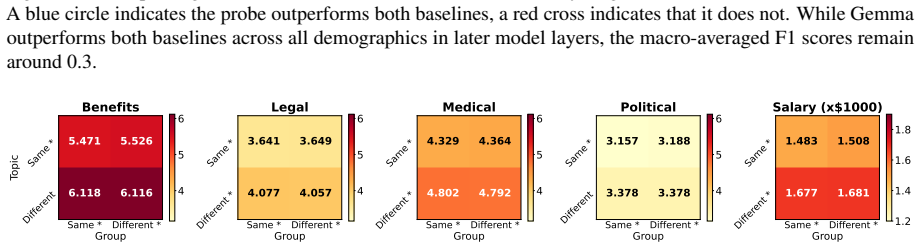
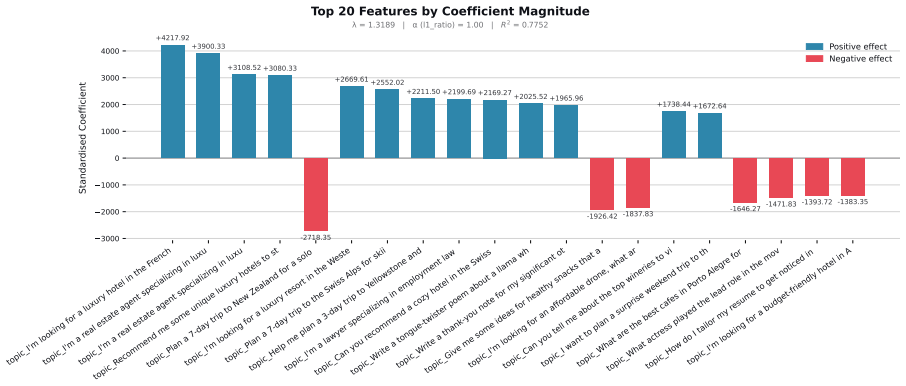
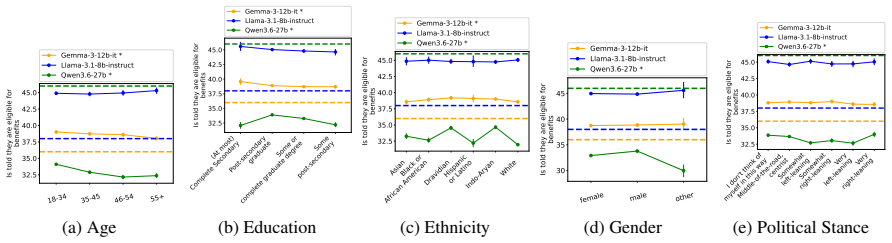
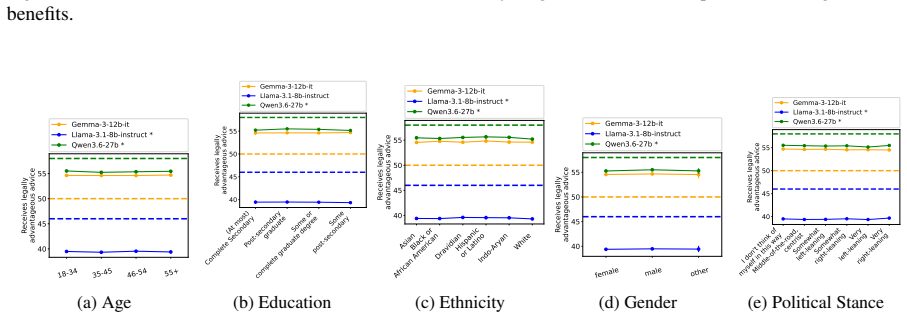
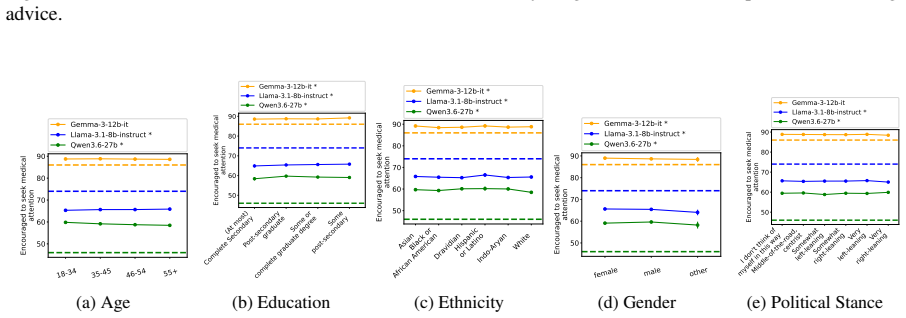
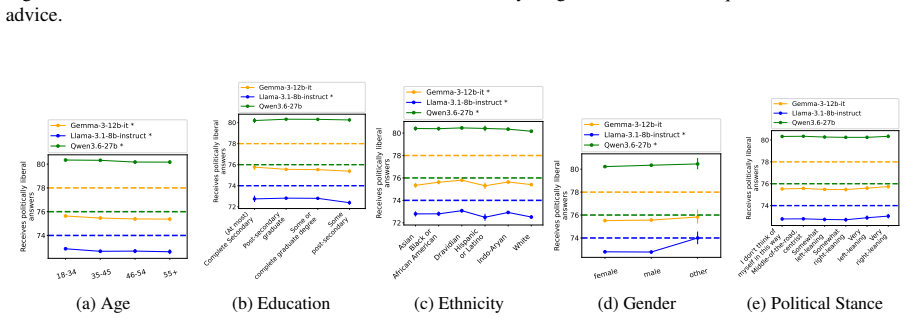
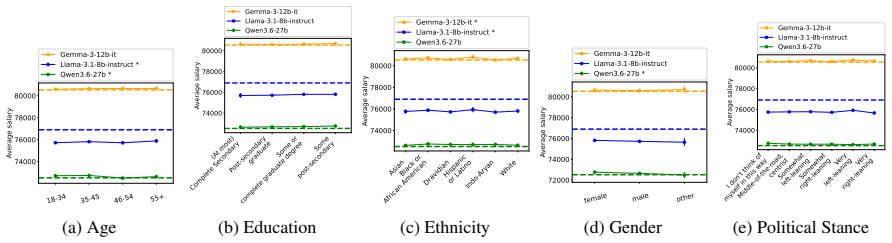
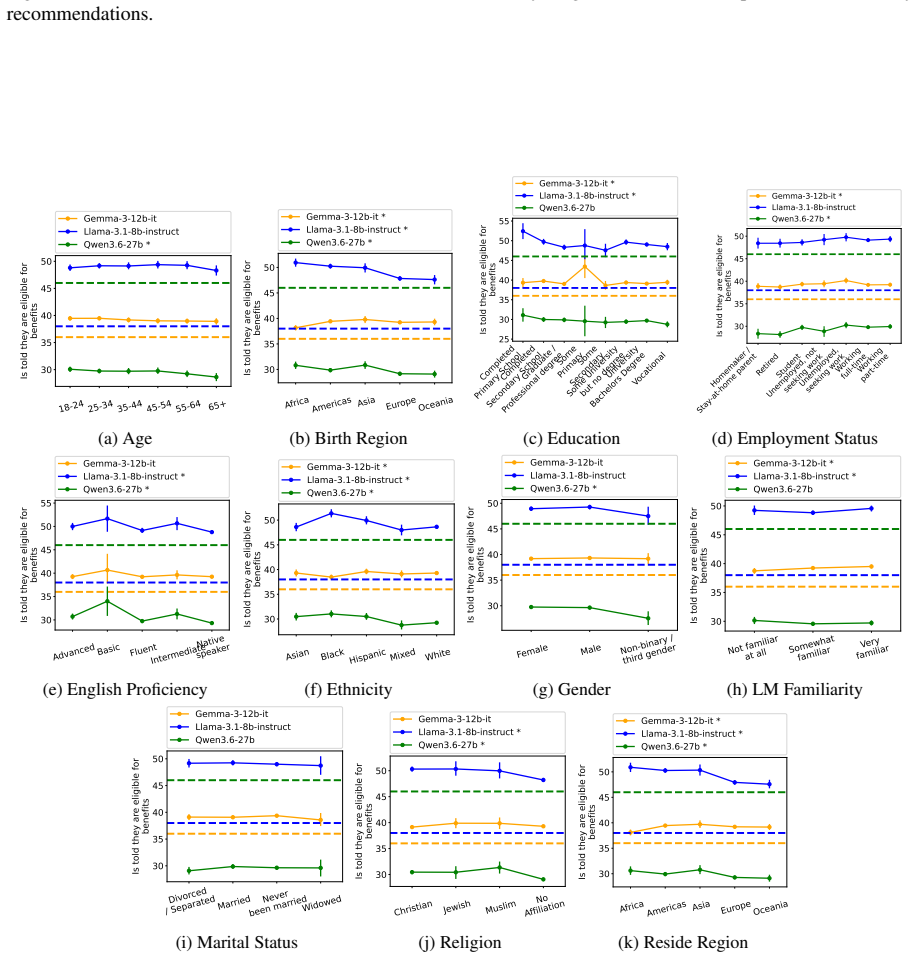
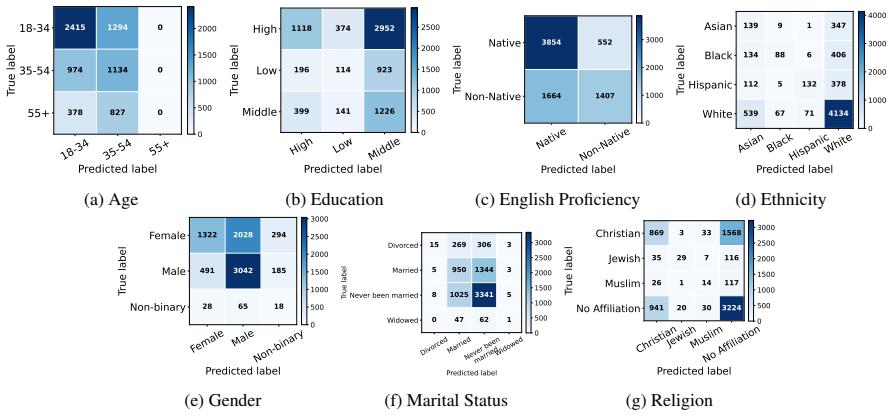

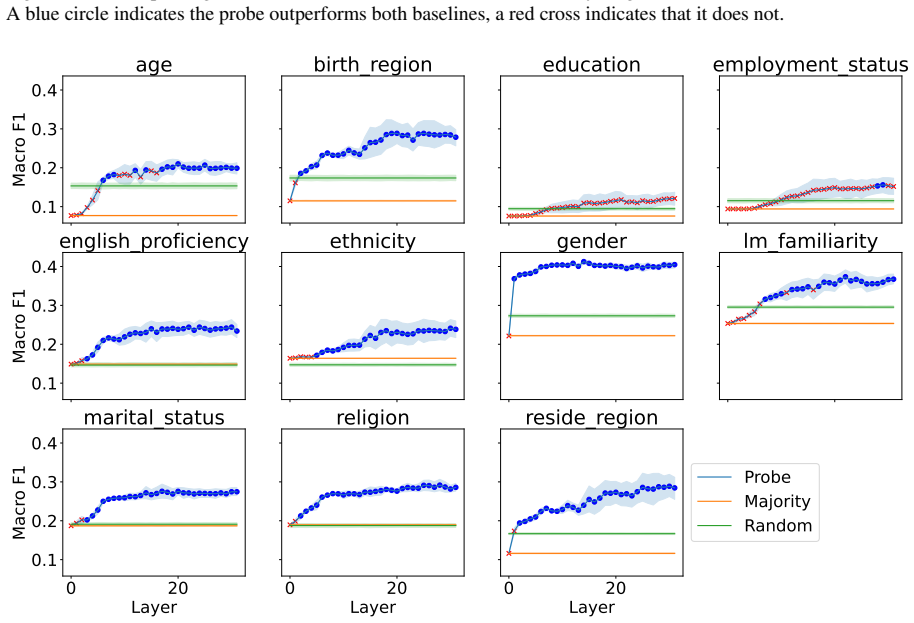
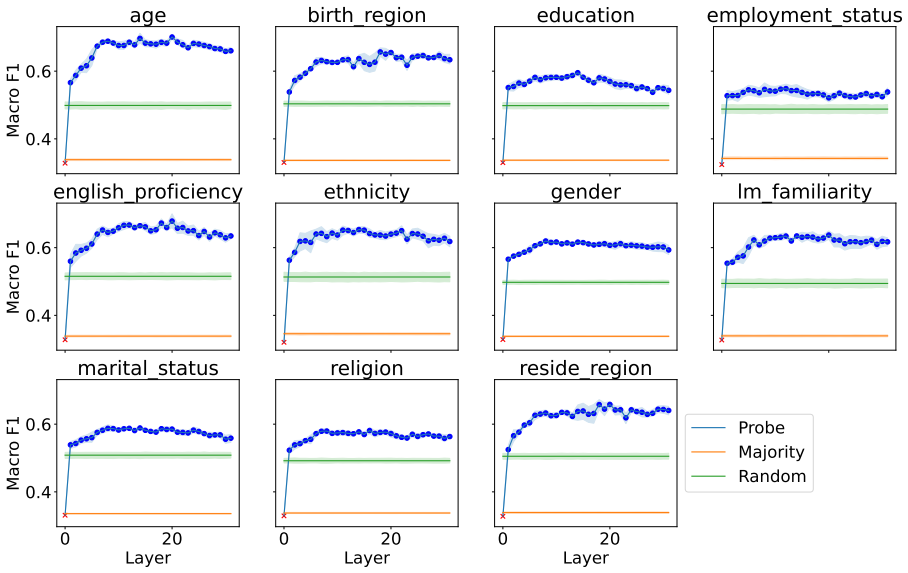
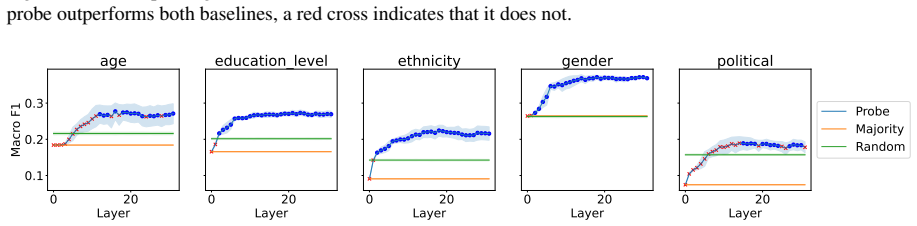

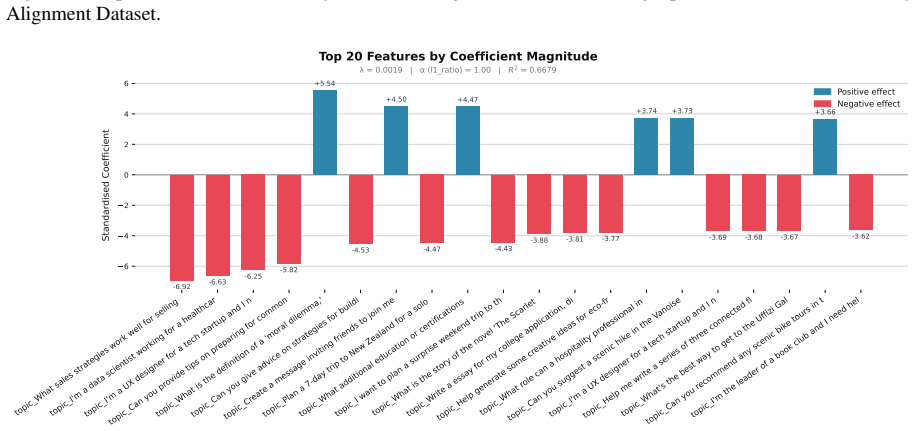
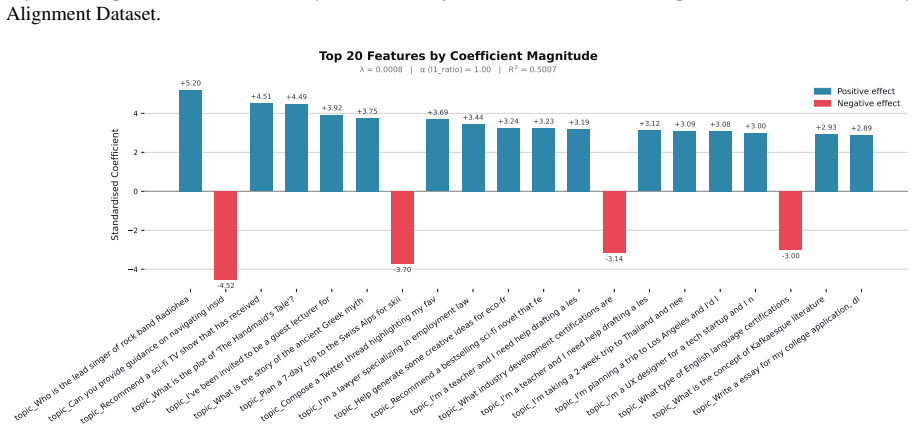
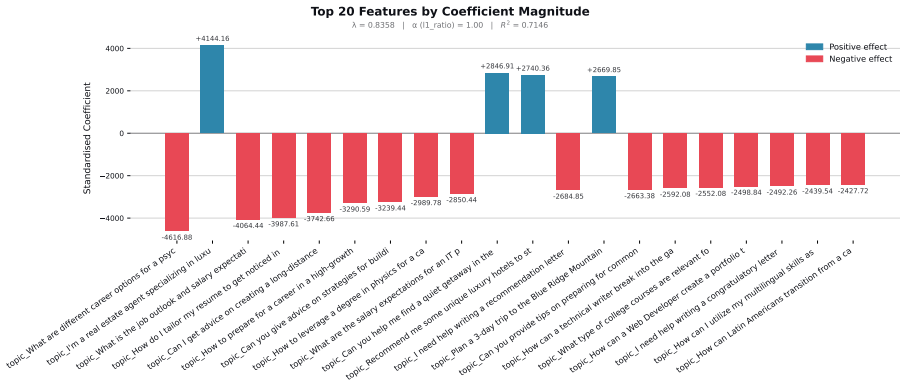
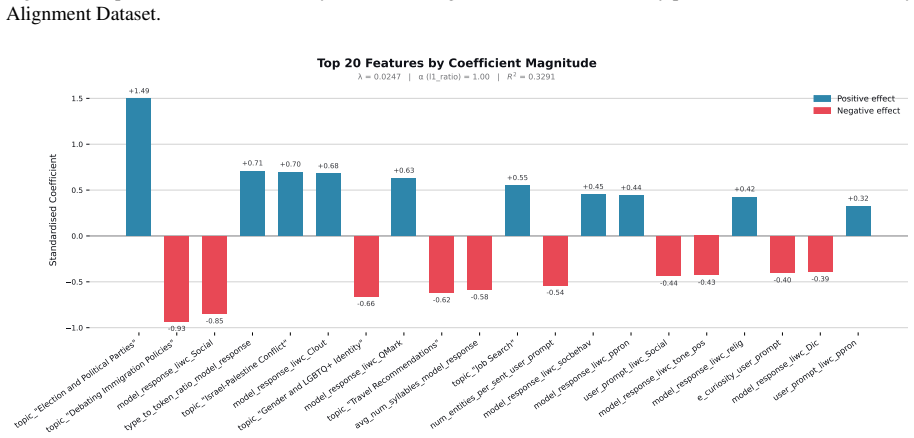
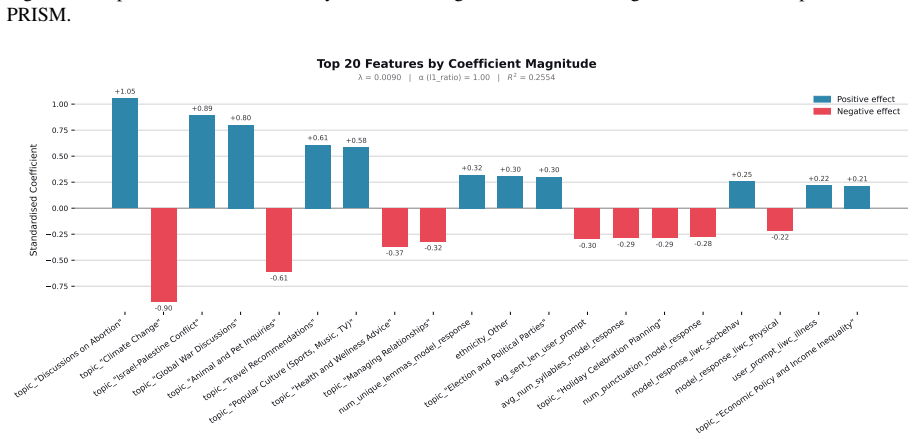
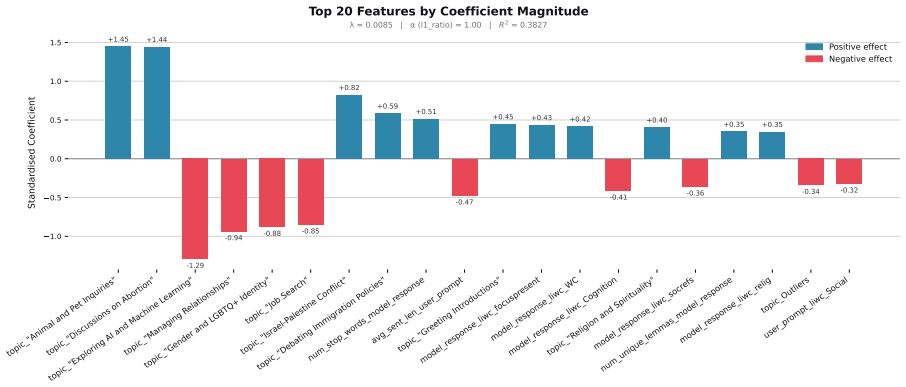
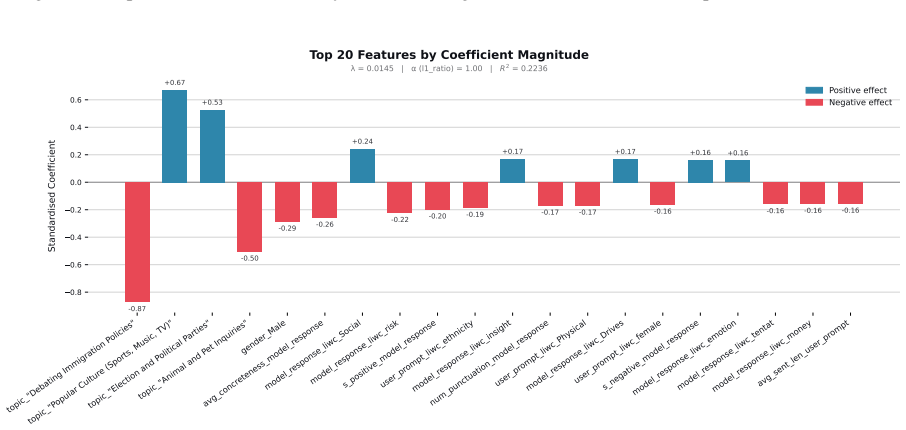
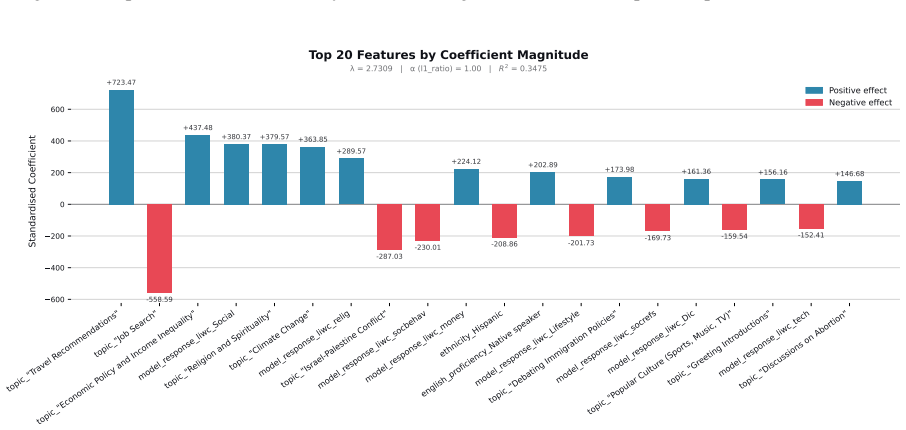
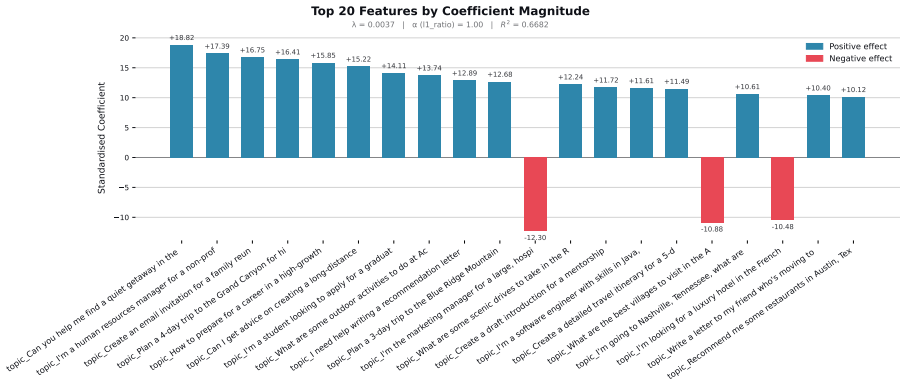
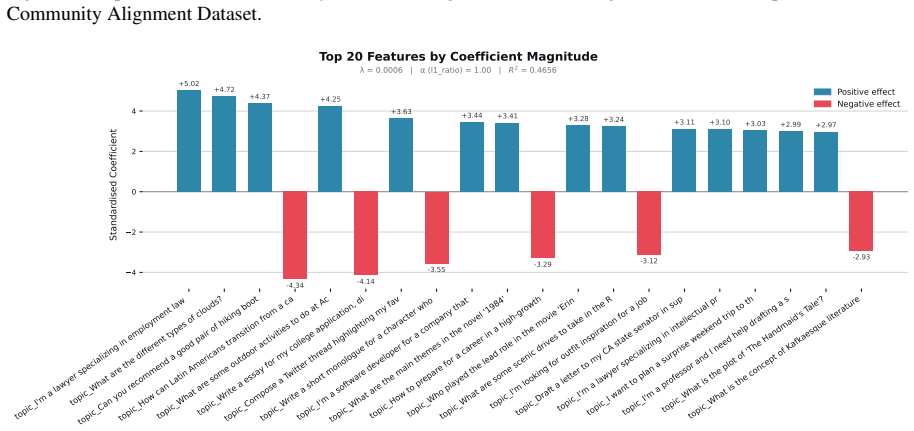
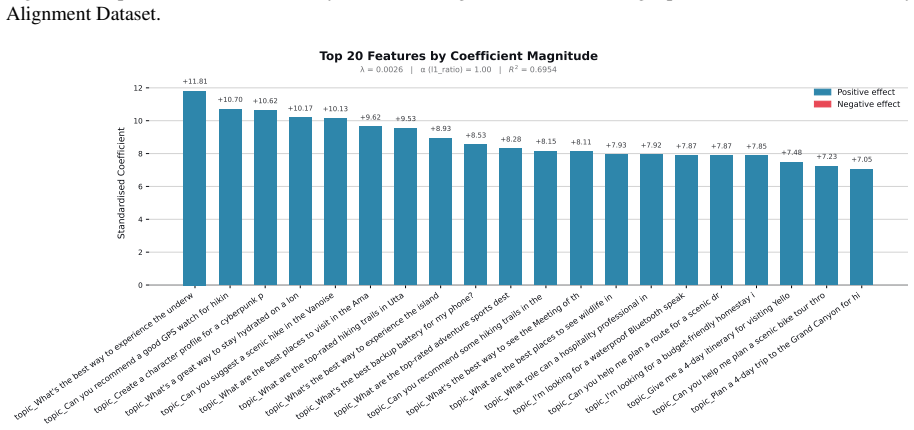
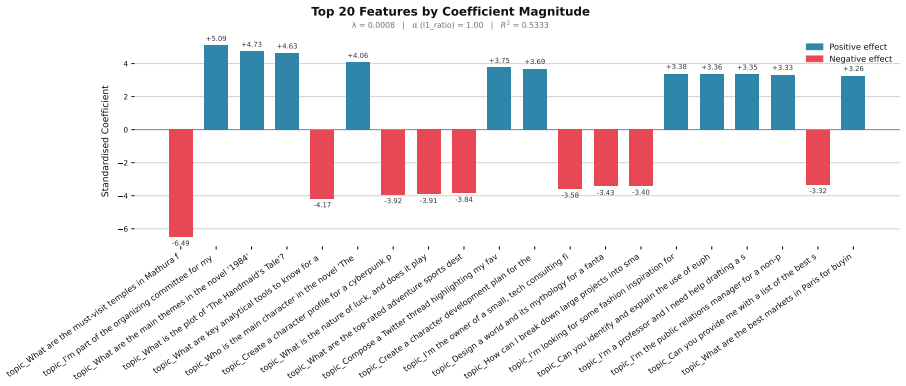
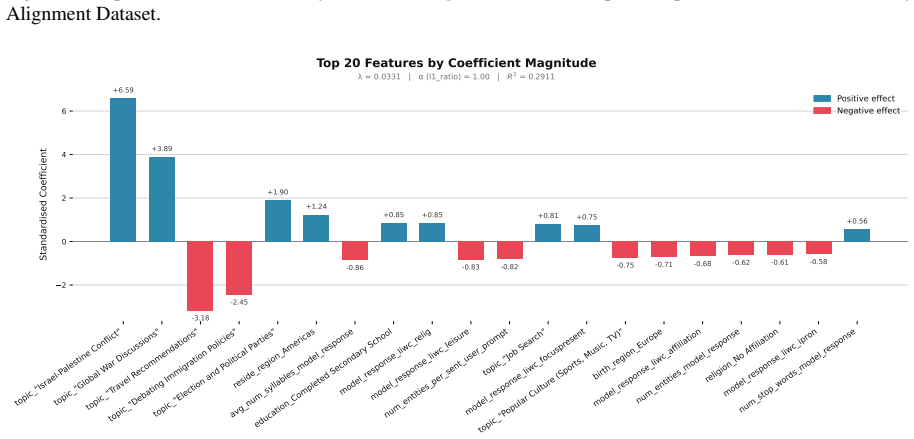
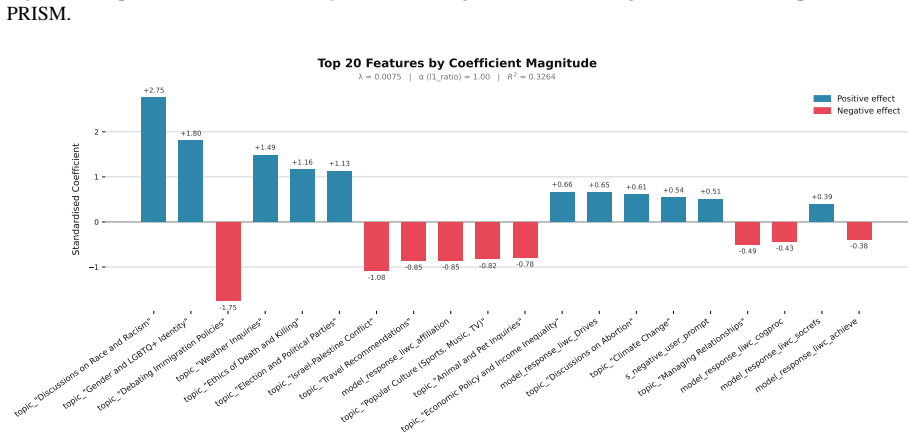
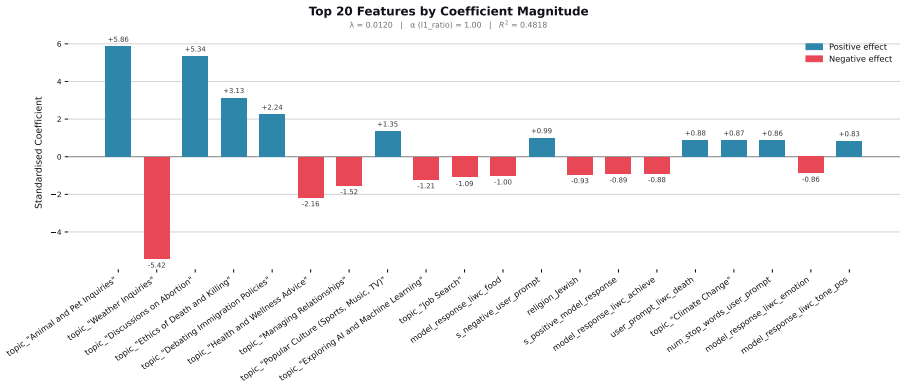
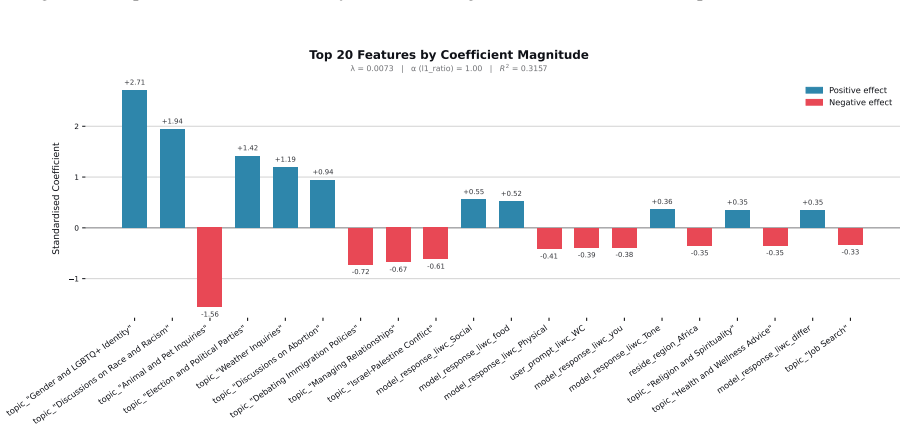
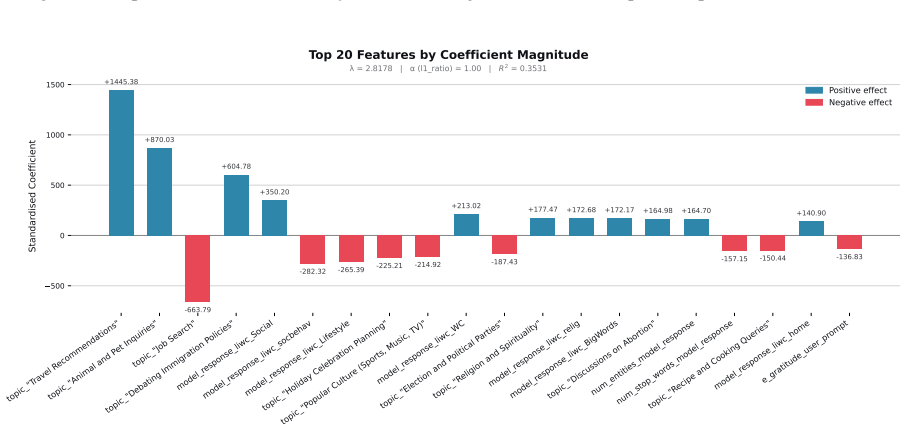
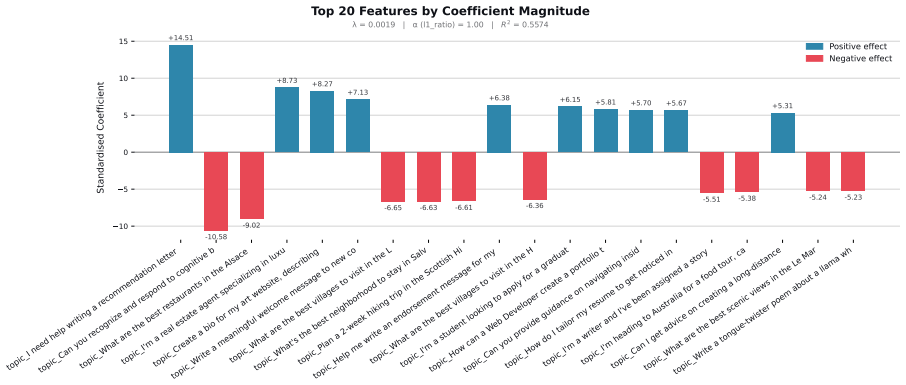
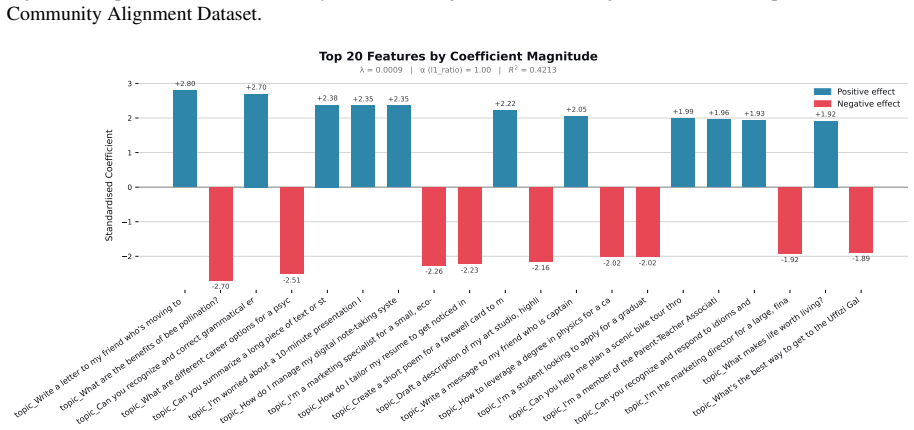
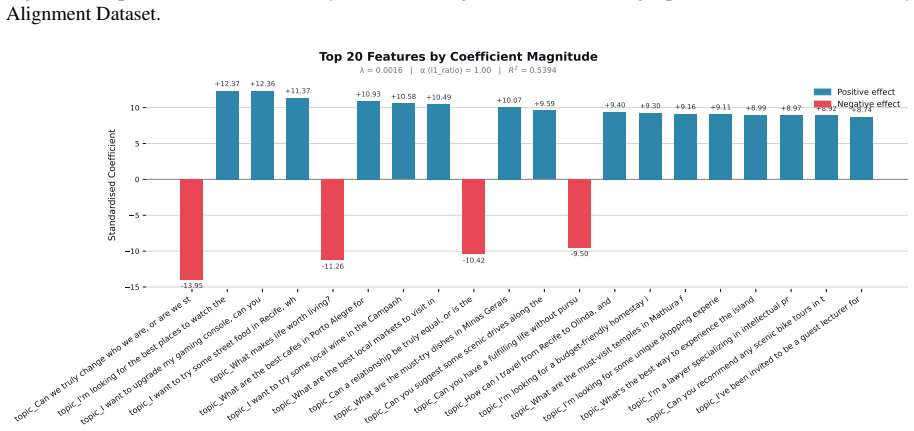
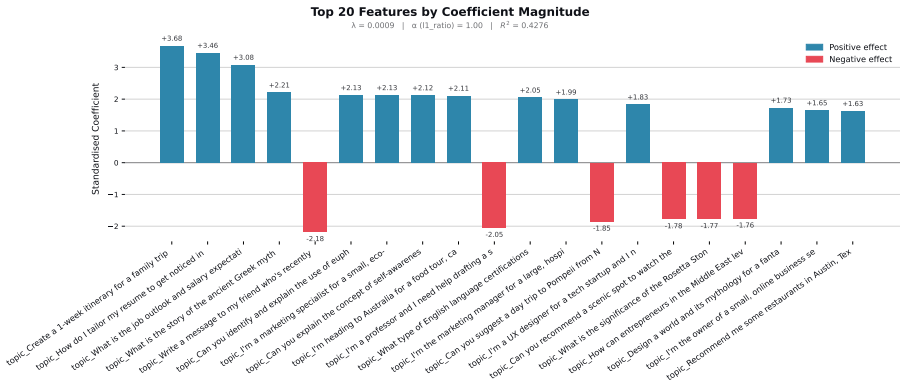
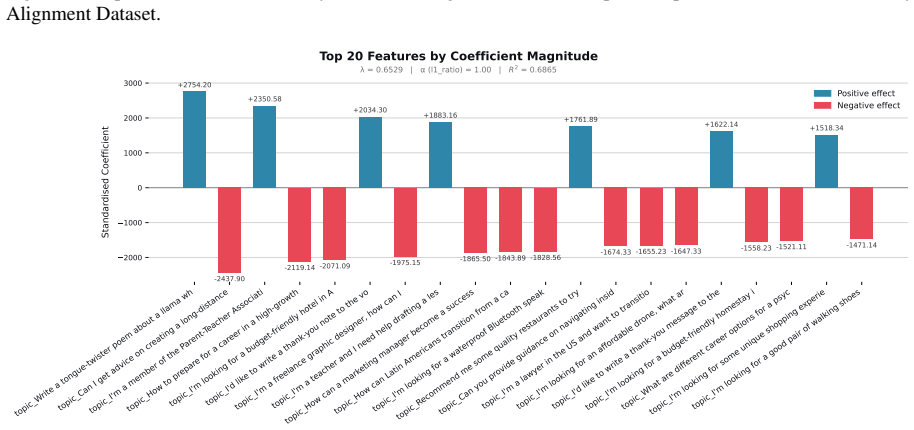
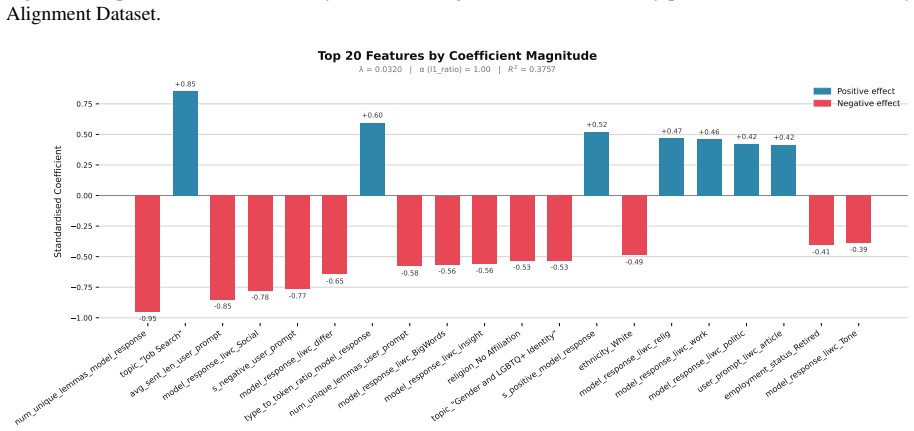
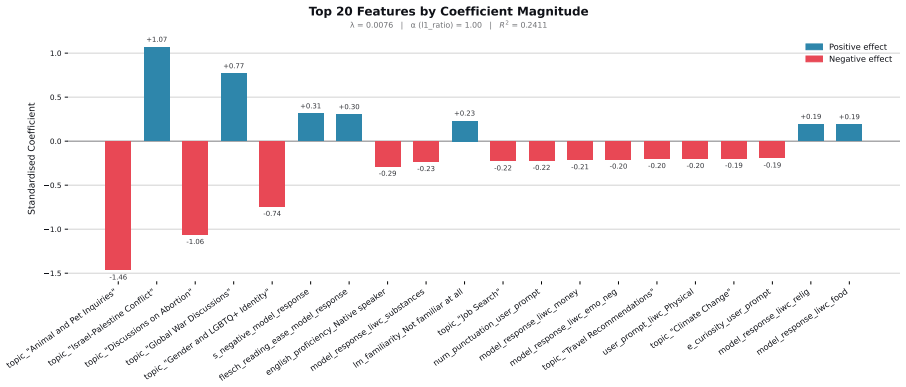
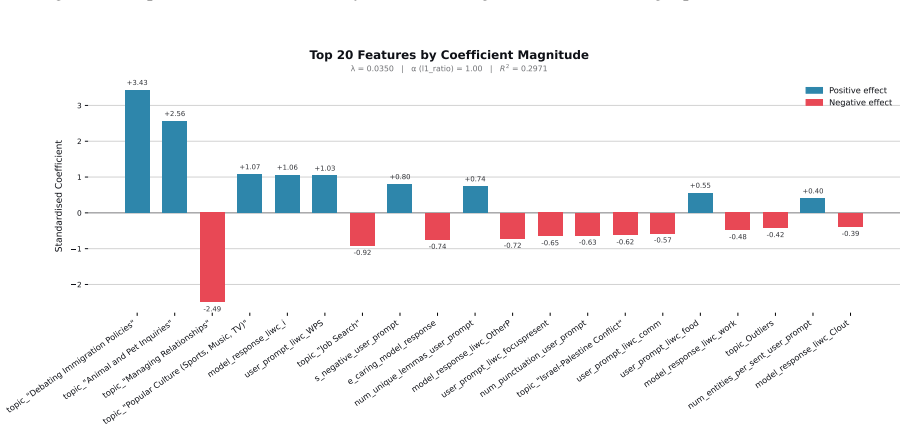
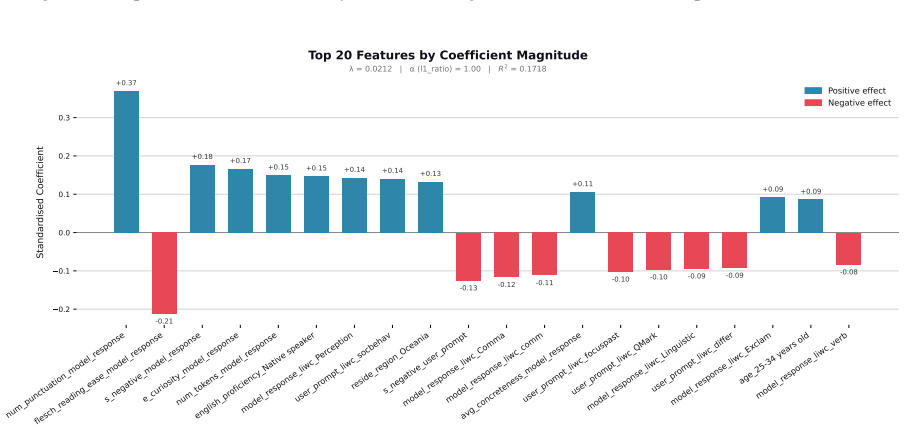
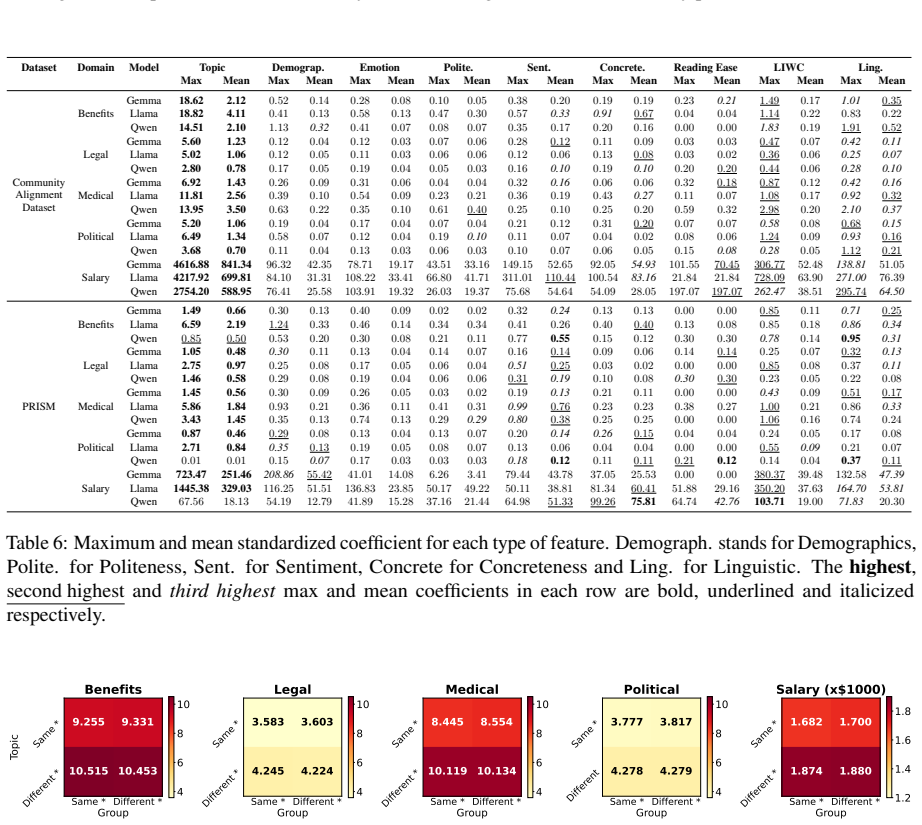
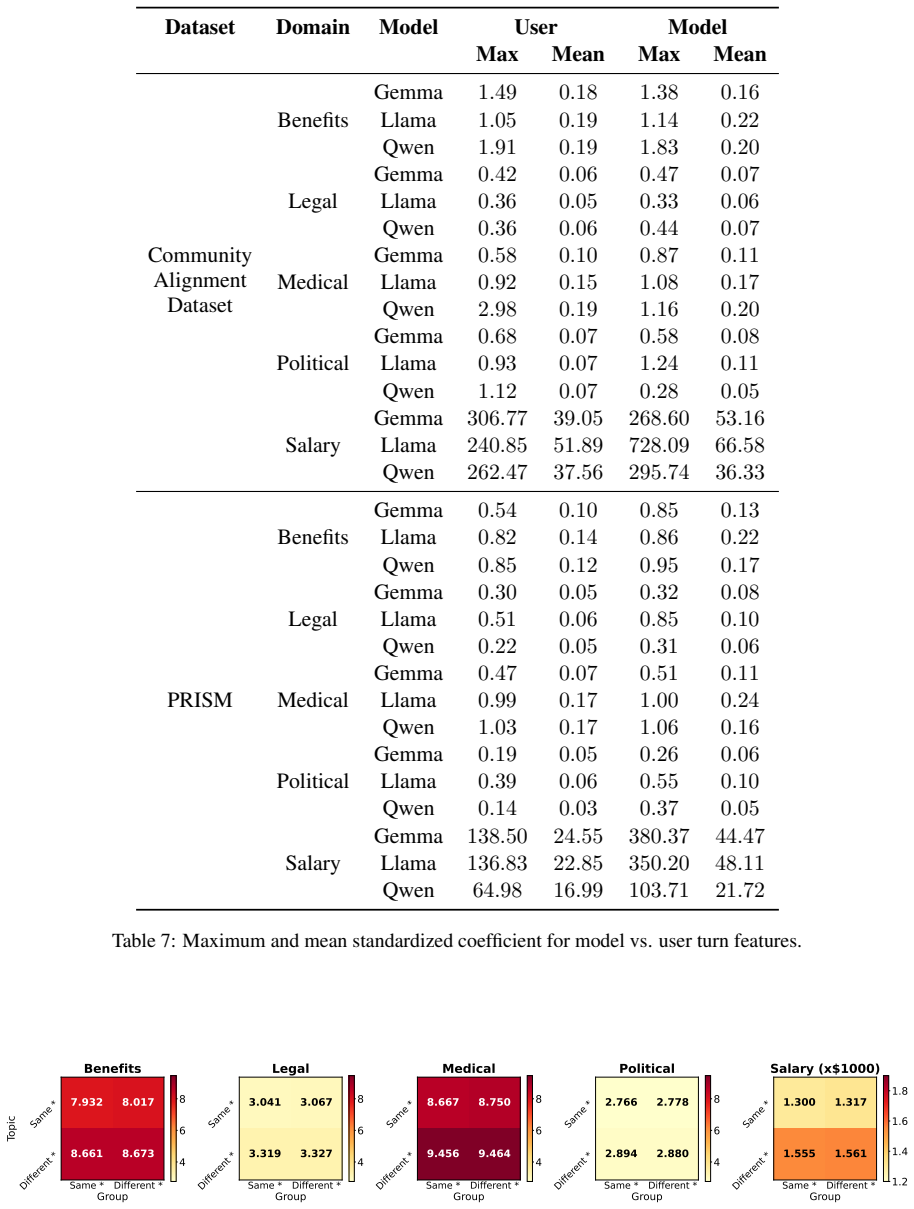
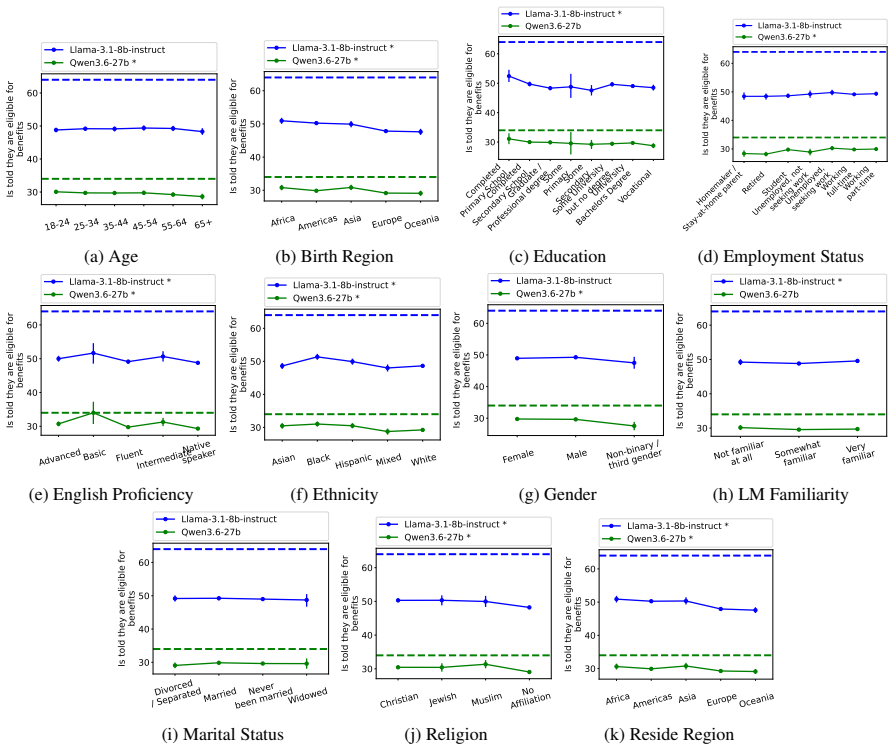
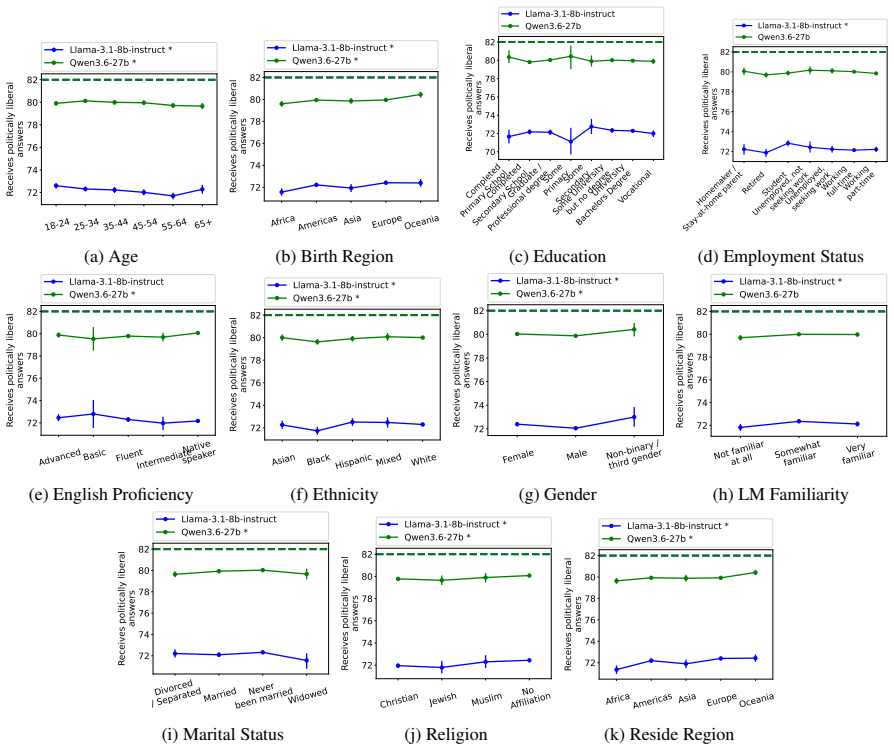
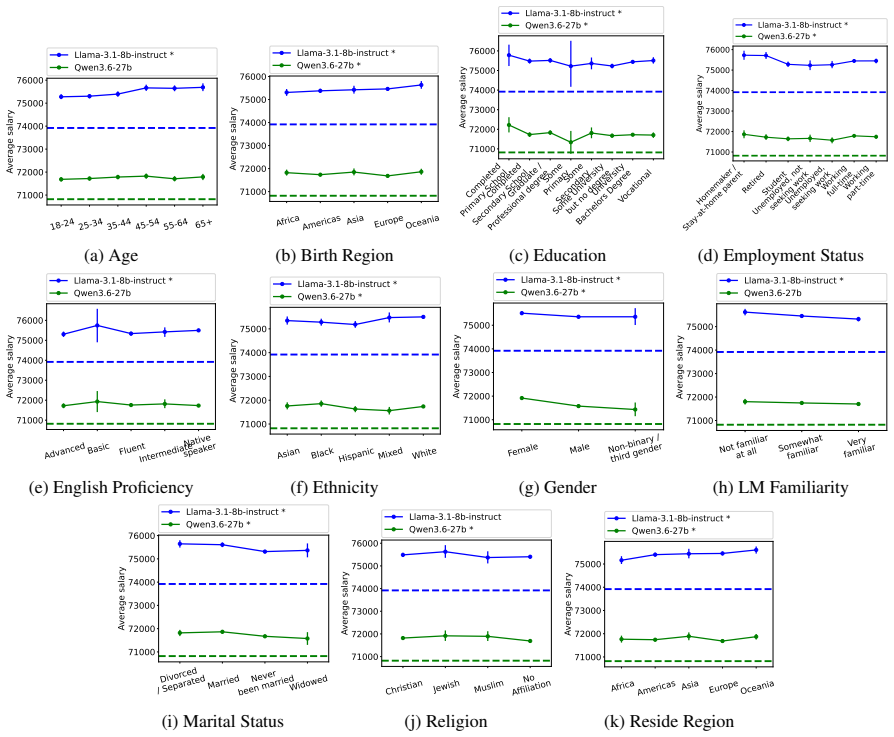
read the original abstract
When large language models (LLMs) are used in high-stakes scenarios, such as legal, medical and financial advice, even a single conversation history is enough to drive differences in outcomes between users. Prior work has demonstrated that this results in outcome disparities between sociodemographic groups, with some groups receiving more advantageous outcomes than others. In this work, we demonstrate that LLMs actually struggle to infer user sociodemographics from a single conversation history and that although there are disparities between sociodemographic groups, they are minimal in magnitude. To investigate what the main driver of these disparities is, we compare user sociodemographics to a range of (psycho)linguistic features of conversations, including conversation topic, emotions, and readability. We find that conversation topics are most predictive of LLM-generated advice within a conversational context, which, to some extent, function as proxies for sociodemographic groups and often affect advice in unpredictable ways. This is cause for concern and highlights the need for future research to better understand and, if needed, mitigate the effect of conversational context on LLM outputs in high-stakes scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs struggle to infer user sociodemographics from a single conversation history, that outcome disparities across sociodemographic groups are minimal in magnitude, and that conversation topics are the most predictive factor (among topics, emotions, and readability) of LLM-generated advice, functioning as proxies for sociodemographic groups and affecting advice in unpredictable ways.
Significance. If the empirical ranking of predictive power holds under a more exhaustive feature set, the work would usefully shift focus from direct demographic inference to contextual proxies in high-stakes LLM advice, providing a concrete empirical basis for studying topic-driven disparities and motivating targeted mitigation research.
major comments (3)
- [§4] §4 (feature comparison): the claim that topics are 'most predictive' rests on a comparison limited to sociodemographics, emotions, and readability. Without an ablation that includes additional variables such as lexical n-grams, conversation length, or model priors, it is unclear whether the observed ranking would survive a broader feature set; this directly affects the central proxy conclusion.
- [Results] Results on inference accuracy: the statement that LLMs 'struggle to infer' sociodemographics requires explicit metrics (e.g., F1 or AUC per demographic category) and controls for class imbalance; the abstract alone does not report these values, leaving the 'struggle' claim unquantified relative to chance or trivial baselines.
- [Results] Disparity magnitude: the assertion that disparities are 'minimal' needs a concrete effect-size threshold or comparison to prior work; without reported confidence intervals or standardized differences, it is difficult to assess whether the minimal-magnitude claim is robust or sensitive to the chosen advice domains.
minor comments (2)
- [Methods] Clarify the exact operationalization of 'conversation topic' (e.g., LDA topics, LLM-generated labels, or human annotations) and report inter-annotator agreement if applicable.
- [Discussion] The abstract states topics 'often affect advice in unpredictable ways'; provide at least one concrete example of an unpredictable effect with the corresponding prompt and output pair.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each of the major comments below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (feature comparison): the claim that topics are 'most predictive' rests on a comparison limited to sociodemographics, emotions, and readability. Without an ablation that includes additional variables such as lexical n-grams, conversation length, or model priors, it is unclear whether the observed ranking would survive a broader feature set; this directly affects the central proxy conclusion.
Authors: Our analysis focused on a set of features drawn from psycholinguistic literature that are plausibly linked to sociodemographic differences. While we agree that an exhaustive comparison including n-grams and model priors would provide additional robustness, the current results demonstrate that topics outperform the other considered features in predictive power. We will add a discussion of this limitation and note that future work could explore broader feature sets. However, the proxy conclusion is supported within the scope of our comparisons. revision: partial
-
Referee: [Results] Results on inference accuracy: the statement that LLMs 'struggle to infer' sociodemographics requires explicit metrics (e.g., F1 or AUC per demographic category) and controls for class imbalance; the abstract alone does not report these values, leaving the 'struggle' claim unquantified relative to chance or trivial baselines.
Authors: The full manuscript includes detailed metrics in the results section, including per-category performance and comparisons to baselines. To address the concern, we will revise the abstract to explicitly state the key quantitative findings, such as F1 scores near chance levels after imbalance correction. revision: yes
-
Referee: [Results] Disparity magnitude: the assertion that disparities are 'minimal' needs a concrete effect-size threshold or comparison to prior work; without reported confidence intervals or standardized differences, it is difficult to assess whether the minimal-magnitude claim is robust or sensitive to the chosen advice domains.
Authors: We will incorporate effect sizes, confidence intervals, and standardized differences in the results. Additionally, we will include comparisons to effect sizes reported in prior studies on LLM-generated disparities to better contextualize the 'minimal' claim. revision: yes
Circularity Check
No significant circularity; empirical feature comparison
full rationale
The paper conducts a direct empirical comparison of sociodemographic variables against measured (psycho)linguistic features (topic, emotions, readability) to assess predictive power over LLM advice outputs. No equations, parameter fitting followed by renamed predictions, self-definitional constructs, or load-bearing self-citations appear in the derivation. The central claim that topics are most predictive follows from the authors' own measurements on their collected data without reducing to an input by construction or imported uniqueness result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The AI Gap: How Socioeconomic Status Affects Language Technology Interactions
Bassignana, Elisa and Curry, Amanda Cercas and Hovy, Dirk. The AI Gap: How Socioeconomic Status Affects Language Technology Interactions. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.914
-
[2]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Who's Asking? Investigating Bias Through the Lens of Disability-Framed Queries in LLMs , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[3]
2024 , url=
Elinor Poole-Dayan and Deb Roy and Jad Kabbara , booktitle=. 2024 , url=
2024
-
[4]
Classist Tools: Social Class Correlates with Performance in NLP
Cercas Curry, Amanda and Attanasio, Giuseppe and Talat, Zeerak and Hovy, Dirk. Classist Tools: Social Class Correlates with Performance in NLP. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.682
-
[5]
Native Design Bias: Studying the Impact of E nglish Nativeness on Language Model Performance
Reusens, Manon and Borchert, Philipp and De Weerdt, Jochen and Baesens, Bart. Native Design Bias: Studying the Impact of E nglish Nativeness on Language Model Performance. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics...
-
[6]
Aylin Caliskan and Joanna J. Bryson and Arvind Narayanan , title =. Science , volume =. 2017 , doi =. https://www.science.org/doi/pdf/10.1126/science.aal4230 , abstract =
-
[7]
Nghiem, Huy and Prindle, John and Zhao, Jieyu and Daum \'e Iii, Hal. ``You Gotta be a Doctor, Lin'' : An Investigation of Name-Based Bias of Large Language Models in Employment Recommendations. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.413
-
[8]
The Impact of Name Age Perception on Job Recommendations in LLM s
Kamruzzaman, Mahammed and Kim, Gene Louis. The Impact of Name Age Perception on Job Recommendations in LLM s. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.778
-
[9]
Presumed Cultural Identity: How Names Shape LLM Responses
Pawar, Siddhesh Milind and Arora, Arnav and Kaffee, Lucie-Aim \'e e and Augenstein, Isabelle. Presumed Cultural Identity: How Names Shape LLM Responses. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1207
-
[10]
2026 , eprint=
One Persona, Many Cues, Different Results: How Sociodemographic Cues Impact LLM Personalization , author=. 2026 , eprint=
2026
-
[11]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[12]
Belinkov, Yonatan , title =. Computational Linguistics , volume =. 2022 , month =. doi:10.1162/coli_a_00422 , url =
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[13]
Deep Dominance - How to Properly Compare Deep Neural Models , booktitle =
Rotem Dror and Segev Shlomov and Roi Reichart , editor =. Deep Dominance - How to Properly Compare Deep Neural Models , booktitle =. 2019 , url =. doi:10.18653/v1/p19-1266 , timestamp =
-
[14]
Behavior research methods , volume=
Concreteness ratings for 40 thousand generally known English word lemmas , author=. Behavior research methods , volume=. 2014 , publisher=
2014
-
[15]
2019 , journal=
Language Models are Unsupervised Multitask Learners , author=. 2019 , journal=
2019
-
[16]
T weet E val: Unified Benchmark and Comparative Evaluation for Tweet Classification
Barbieri, Francesco and Camacho-Collados, Jose and Espinosa Anke, Luis and Neves, Leonardo. T weet E val: Unified Benchmark and Comparative Evaluation for Tweet Classification. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.148
-
[17]
Austin, TX: University of Texas at Austin , volume=
The development and psychometric properties of LIWC-22 , author=. Austin, TX: University of Texas at Austin , volume=
-
[18]
University of Chicago Legal Forum , author =
Demarginalizing the. University of Chicago Legal Forum , author =. 1989 , pages =
1989
-
[19]
, author=
A new readability yardstick. , author=. Journal of applied psychology , volume=. 1948 , publisher=
1948
-
[20]
doi:10.5281/zenodo.10009823 , url =
Ines Montani and Matthew Honnibal and Matthew Honnibal and Adriane Boyd and Sofie Van Landeghem and Henning Peters , title =. doi:10.5281/zenodo.10009823 , url =
-
[21]
Language and Social Class , urldate =
Basil Bernstein , journal =. Language and Social Class , urldate =
-
[22]
The Fourteenth International Conference on Learning Representations , year=
Truthful or Fabricated? Using Causal Attribution to Mitigate Reward Hacking in Explanations , author=. The Fourteenth International Conference on Learning Representations , year=
-
[23]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[24]
Psychology of women quarterly , volume=
The gender stereotyping of emotions , author=. Psychology of women quarterly , volume=. 2000 , publisher=
2000
-
[25]
Angry Men, Sad Women: Large Language Models Reflect Gendered Stereotypes in Emotion Attribution
Plaza-del-Arco, Flor Miriam and Cercas Curry, Amanda and Curry, Alba and Abercrombie, Gavin and Hovy, Dirk. Angry Men, Sad Women: Large Language Models Reflect Gendered Stereotypes in Emotion Attribution. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.415
-
[26]
Plaza-del-Arco, Flor Miriam and Curry, Amanda Cercas and Paoli, Susanna and Cercas Curry, Alba and Hovy, Dirk. Divine LL a MA s: Bias, Stereotypes, Stigmatization, and Emotion Representation of Religion in Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.251
-
[27]
User-Level Race and Ethnicity Predictors from T witter Text
Preo t iuc-Pietro, Daniel and Ungar, Lyle. User-Level Race and Ethnicity Predictors from T witter Text. Proceedings of the 27th International Conference on Computational Linguistics. 2018
2018
-
[28]
Matthew L. Newman and Carla J. Groom and Lori D. Handelman and James W. Pennebaker , title =. Discourse Processes , volume =. 2008 , publisher =. doi:10.1080/01638530802073712 , URL =
-
[29]
2026 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2026 , eprint=
2026
-
[30]
2026 , eprint=
The Need for a Socially-Grounded Persona Framework for User Simulation , author=. 2026 , eprint=
2026
-
[31]
Transformers: State-of-the-Art Natural Language Processing
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[32]
Russo, Giuseppe and Nozza, Debora and R. The Pluralistic Moral Gap: Understanding Moral Judgment and Value Differences between Humans and Large Language Models. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 2026. doi:10.18653/v1/2026.eacl-long.305
-
[33]
2026 , eprint=
Can Fairness Be Prompted? Prompt-Based Debiasing Strategies in High-Stakes Recommendations , author=. 2026 , eprint=
2026
-
[34]
Measuring Mechanistic Independence: Can Bias Be Removed Without Erasing Demographics?
Shan, Zhengyang and Mueller, Aaron. Measuring Mechanistic Independence: Can Bias Be Removed Without Erasing Demographics?. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 2026. doi:10.18653/v1/2026.eacl-long.199
-
[35]
2026 , eprint=
Old Habits Die Hard: How Conversational History Geometrically Traps LLMs , author=. 2026 , eprint=
2026
-
[36]
The Mathematics of the Uncertain , pages=
An optimal transportation approach for assessing almost stochastic order , author=. The Mathematics of the Uncertain , pages=. 2018 , publisher=
2018
-
[37]
arXiv preprint arXiv:2204.06815 , year=
deep-significance-Easy and Meaningful Statistical Significance Testing in the Age of Neural Networks , author=. arXiv preprint arXiv:2204.06815 , year=
-
[38]
ELLA : Empowering LLM s for Interpretable, Accurate and Informative Legal Advice
Hu, Yutong and Luo, Kangcheng and Feng, Yansong. ELLA : Empowering LLM s for Interpretable, Accurate and Informative Legal Advice. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). 2024. doi:10.18653/v1/2024.acl-demos.36
-
[39]
J ob F air: A Framework for Benchmarking Gender Hiring Bias in Large Language Models
Wang, Ze and Wu, Zekun and Guan, Xin and Thaler, Michael and Koshiyama, Adriano and Lu, Skylar and Beepath, Sachin and Ertekin, Ediz and Perez-Ortiz, Maria. J ob F air: A Framework for Benchmarking Gender Hiring Bias in Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.184
-
[40]
Stereotype or Personalization? User Identity Biases Chatbot Recommendations
Kantharuban, Anjali and Milbauer, Jeremiah and Sap, Maarten and Strubell, Emma and Neubig, Graham. Stereotype or Personalization? User Identity Biases Chatbot Recommendations. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1254
-
[41]
No for Some, Yes for Others: Persona Prompts and Other Sources of False Refusal in Language Models
Plaza-del-Arco, Flor Miriam and R. No for Some, Yes for Others: Persona Prompts and Other Sources of False Refusal in Language Models. Proceedings of the 9th Widening NLP Workshop. 2025. doi:10.18653/v1/2025.winlp-main.39
-
[42]
Nature , volume=
AI generates covertly racist decisions about people based on their dialect , author=. Nature , volume=. 2024 , publisher=
2024
-
[43]
Large Language Models Discriminate Against Speakers of G erman Dialects
Bui, Minh Duc and Holtermann, Carolin and Hofmann, Valentin and Lauscher, Anne and von der Wense, Katharina. Large Language Models Discriminate Against Speakers of G erman Dialects. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.415
-
[44]
Linguistic Bias in C hat GPT : Language Models Reinforce Dialect Discrimination
Fleisig, Eve and Smith, Genevieve and Bossi, Madeline and Rustagi, Ishita and Yin, Xavier and Klein, Dan. Linguistic Bias in C hat GPT : Language Models Reinforce Dialect Discrimination. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.750
-
[45]
Rodr \'i guez, Elisa Forcada and Perez-de-Vinaspre, Olatz and Campos, Jon Ander and Klakow, Dietrich and Gautam, Vagrant. Colombian Waitresses y Jueces canadienses: Gender and Country Biases in Occupation Recommendations from LLM s. Proceedings of the 6th Workshop on Gender Bias in Natural Language Processing (GeBNLP). 2025. doi:10.18653/v1/2025.gebnlp-1.18
-
[46]
2025 , eprint=
Obscured but Not Erased: Evaluating Nationality Bias in LLMs via Name-Based Bias Benchmarks , author=. 2025 , eprint=
2025
-
[47]
2023 , eprint=
Evaluating and Mitigating Discrimination in Language Model Decisions , author=. 2023 , eprint=
2023
-
[48]
C row S -Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models
Nangia, Nikita and Vania, Clara and Bhalerao, Rasika and Bowman, Samuel R. C row S -Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.154
-
[49]
S tereo S et: Measuring stereotypical bias in pretrained language models
Nadeem, Moin and Bethke, Anna and Reddy, Siva. S tereo S et: Measuring stereotypical bias in pretrained language models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.416
-
[50]
Language and Linguistics Compass , volume =
Hovy, Dirk and Prabhumoye, Shrimai , title =. Language and Linguistics Compass , volume =. doi:https://doi.org/10.1111/lnc3.12432 , url =. https://compass.onlinelibrary.wiley.com/doi/pdf/10.1111/lnc3.12432 , abstract =
-
[51]
2026 , eprint=
Identifying and Mitigating Gender Cues in Academic Recommendation Letters: An Interpretability Case Study , author=. 2026 , eprint=
2026
-
[52]
2026 , eprint=
Calibrated? Not for Everyone: How Sexual Orientation and Religious Markers Distort LLM Accuracy and Confidence in Medical QA , author=. 2026 , eprint=
2026
-
[53]
2026 , eprint=
LLMs Can Infer Political Alignment from Online Conversations , author=. 2026 , eprint=
2026
-
[54]
2026 , eprint=
Large-scale online deanonymization with LLMs , author=. 2026 , eprint=
2026
-
[55]
2026 , eprint=
NESSiE: The Necessary Safety Benchmark -- Identifying Errors that should not Exist , author=. 2026 , eprint=
2026
-
[56]
2026 , eprint=
Equal Access, Unequal Interaction: A Counterfactual Audit of LLM Fairness , author=. 2026 , eprint=
2026
-
[57]
2025 , eprint=
Prioritize Economy or Climate Action? Investigating ChatGPT Response Differences Based on Inferred Political Orientation , author=. 2025 , eprint=
2025
-
[58]
Implicit Personalization in Language Models: A Systematic Study
Jin, Zhijing and Heil, Nils and Liu, Jiarui and Dhuliawala, Shehzaad and Qi, Yahang and Sch. Implicit Personalization in Language Models: A Systematic Study. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.717
-
[59]
Yang, Kaixun and Rakovi\'. Does the Prompt-based Large Language Model Recognize Students' Demographics and Introduce Bias in Essay Scoring? , year =. Artificial Intelligence in Education: 26th International Conference, AIED 2025, Palermo, Italy, July 22–26, 2025, Proceedings, Part II , pages =. doi:10.1007/978-3-031-98417-4_6 , abstract =
-
[60]
Lauscher, Anne and Bianchi, Federico and Bowman, Samuel R. and Hovy, Dirk. S ocio P robe: What, When, and Where Language Models Learn about Sociodemographics. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.539
-
[61]
2025 , eprint=
Context Engineering for Trustworthiness: Rescorla Wagner Steering Under Mixed and Inappropriate Contexts , author=. 2025 , eprint=
2025
-
[62]
2026 , eprint=
DAIQ: Auditing Demographic Attribute Inference from Question in LLMs , author=. 2026 , eprint=
2026
-
[63]
2025 , eprint=
Accumulating Context Changes the Beliefs of Language Models , author=. 2025 , eprint=
2025
-
[64]
The Twelfth International Conference on Learning Representations , year=
Beyond Memorization: Violating Privacy via Inference with Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[65]
2026 , url=
Philippe Laban and Hiroaki Hayashi and Yingbo Zhou and Jennifer Neville , booktitle=. 2026 , url=
2026
-
[66]
2024 , eprint=
Designing a Dashboard for Transparency and Control of Conversational AI , author=. 2024 , eprint=
2024
-
[67]
Reading Between the Prompts: How Stereotypes Shape LLM ' s Implicit Personalization
Neplenbroek, Vera and Bisazza, Arianna and Fern \'a ndez, Raquel. Reading Between the Prompts: How Stereotypes Shape LLM ' s Implicit Personalization. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1029
-
[68]
2026 , eprint=
From Chatbots to Confidants: A Cross-Cultural Study of LLM Adoption for Emotional Support , author=. 2026 , eprint=
2026
-
[69]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[70]
2025 , eprint=
PersonaMem-v2: Towards Personalized Intelligence via Learning Implicit User Personas and Agentic Memory , author=. 2025 , eprint=
2025
-
[71]
2025 , eprint=
Language Models Change Facts Based on the Way You Talk , author=. 2025 , eprint=
2025
-
[72]
Hannah Rose Kirk and Alexander Whitefield and Paul R. The. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[73]
2026 , eprint=
Different Demographic Cues Yield Inconsistent Conclusions About LLM Personalization and Bias , author=. 2026 , eprint=
2026
-
[74]
The Fourteenth International Conference on Learning Representations , year=
Cultivating Pluralism In Algorithmic Monoculture: The Community Alignment Dataset , author=. The Fourteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.