Adaptive Accelerated Mirror Descent in Primal and Dual Spaces
Pith reviewed 2026-06-28 13:15 UTC · model grok-4.3
The pith
Adaptive Accelerated Mirror Descent achieves accelerated convergence for convex problems by tolerating local descent failures through an accumulated Lyapunov perturbation budget under dual relative smoothness and a mirror-geometry compatibi
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AAMD is a flow-based optimization method that combines nonlinear preconditioning, acceleration, and adaptivity in mirror geometry. The central mechanism is an accumulated Lyapunov perturbation budget that tolerates local descent failures provided the cumulative budget remains nonpositive. Under dual relative smoothness and convexity together with a mirror-geometry compatibility condition, the method achieves accelerated convergence. For convex objectives, homotopy under a bounded-sublevel-set assumption delivers an O(1/k^2) rate.
What carries the argument
The accumulated Lyapunov perturbation budget, which permits local descent failures provided the total budget remains nonpositive and triggers line search only when stability is at risk.
If this is right
- Accelerated convergence holds under dual relative smoothness or convexity paired with the mirror-geometry compatibility condition.
- An O(1/k^2) rate follows for convex objectives via homotopy once sublevel sets are bounded.
- Practical performance improves when preconditioning, acceleration, and adaptivity are used together on relative-smoothness problems.
Where Pith is reading between the lines
- The budget mechanism could be tested in stochastic or noisy gradient settings where occasional step failures are routine.
- The same compatibility condition between primal and dual geometries may suggest new ways to choose mirror maps for other first-order schemes.
- The homotopy construction might be adapted to obtain fast rates in settings where standard acceleration assumptions are only partially satisfied.
Load-bearing premise
The mirror-geometry compatibility condition and the bounded-sublevel-set assumption must both hold for the homotopy to produce the O(1/k^2) rate.
What would settle it
An explicit convex problem satisfying dual relative smoothness and convexity but violating the mirror-geometry compatibility condition where the claimed accelerated rate fails to appear, or an unbounded sublevel set where the homotopy argument ceases to deliver O(1/k^2).
Figures

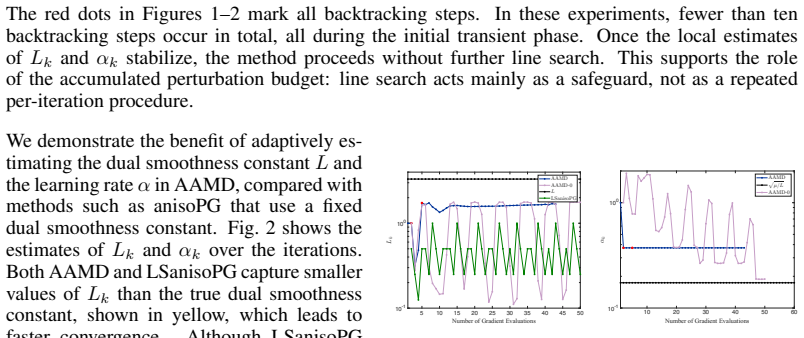

read the original abstract
We propose Adaptive Accelerated Mirror Descent (AAMD), a flow-based method that combines nonlinear preconditioning, acceleration, and adaptivity in mirror geometry. The key ingredient is an accumulated Lyapunov perturbation budget: local descent failures are allowed as long as the total budget remains nonpositive, so line search is used only when stability is at risk. We prove accelerated convergence under dual relative smoothness/convexity and a mirror-geometry compatibility condition, and obtain an $O(1/k^2)$ rate for convex objectives by homotopy under a bounded-sublevel-set assumption. Experiments on relative-smoothness problems show that combining preconditioning, acceleration, and adaptivity gives substantial gains over methods using only part of this structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive Accelerated Mirror Descent (AAMD), a flow-based method that combines nonlinear preconditioning, acceleration, and adaptivity in mirror geometry. The key ingredient is an accumulated Lyapunov perturbation budget: local descent failures are allowed as long as the total budget remains nonpositive, so line search is used only when stability is at risk. The authors prove accelerated convergence under dual relative smoothness/convexity and a mirror-geometry compatibility condition, and obtain an O(1/k^2) rate for convex objectives by homotopy under a bounded-sublevel-set assumption. Experiments on relative-smoothness problems show that combining preconditioning, acceleration, and adaptivity gives substantial gains over methods using only part of this structure.
Significance. If the results hold, this work is significant for providing a new adaptive method for accelerated mirror descent with proofs in both primal and dual spaces. The accumulated Lyapunov perturbation budget is presented as a design choice, which is a strength. The homotopy approach for the O(1/k^2) rate under the bounded-sublevel-set assumption is a useful extension. The empirical results support the practical value of the combined approach.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the work and for recommending acceptance. We are pleased that the combination of preconditioning, acceleration, and adaptivity via the Lyapunov budget, along with the homotopy argument for the O(1/k^2) rate, was viewed as a useful contribution.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and reader's summary describe a proposed algorithm with a Lyapunov perturbation budget and convergence proofs under stated assumptions (dual relative smoothness, mirror-geometry compatibility, bounded sublevel sets). No equations, fitted parameters, or self-citations are exhibited that reduce any claimed rate or result to a definition by construction. The central claims are presented as theorems under explicit conditions rather than tautological renamings or post-hoc fits. Without load-bearing self-citation chains or ansatzes smuggled via prior work in the visible text, the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Dual relative smoothness/convexity holds for the objective
- domain assumption Mirror-geometry compatibility condition
- domain assumption Bounded-sublevel-set assumption
Reference graph
Works this paper leans on
-
[1]
Bertsekas.Convex Optimization Theory
D. Bertsekas.Convex Optimization Theory. Athena Scientific optimization and computation series. Athena Scientific, 2009. ISBN 9781886529311. 3
2009
-
[2]
Adaptive backtracking line search
Joao V Cavalcanti, Laurent Lessard, and Ashia C Wilson. Adaptive backtracking line search. arXiv preprint arXiv:2408.13150, 2024. 5
arXiv 2024
-
[3]
Gong Chen and Marc Teboulle. Convergence analysis of a proximal-like minimization algo- rithm using Bregman functions.SIAM Journal on Optimization, 3(3):538–543, 1993. doi: https://doi.org/10.1137/0803026. 3 9 The results are shown in Fig. 3. Since the prob- lem is not strongly convex, all methods show sublinear convergence. AAMD outperforms the tested ba...
-
[4]
First order optimization methods based on hessian-driven nesterov accelerated gradient flow, 2019
Long Chen and Hao Luo. First order optimization methods based on hessian-driven nesterov accelerated gradient flow, 2019. URLhttps://arxiv.org/abs/1912.09276. 4
arXiv 2019
-
[5]
Accelerated gradient methods through variable and operator splitting, 2025
Long Chen, Luo Hao, and Jingrong Wei. Accelerated gradient methods through variable and operator splitting, 2025. URLhttps://arxiv.org/abs/2505.04065. 2, 18
arXiv 2025
-
[6]
Accelerated mirror descent method through variable and operator splitting, 2026
Long Chen, Hao Luo, Jingrong Wei, Zeyi Xu, and Yuan Yao. Accelerated mirror descent method through variable and operator splitting, 2026. URLhttps://arxiv.org/abs/ 2601.19038. 2
arXiv 2026
-
[7]
Taylor, Alexandre d’Aspremont, and Jérôme Bolte
Radu-Alexandru Dragomir, Adrien B. Taylor, Alexandre d’Aspremont, and Jérôme Bolte. Op- timal complexity and certification of Bregman first-order methods.Mathematical Program- ming, 194(1):41–83, 2022. doi: https://doi.org/10.1007/s10107-021-01618-1. 2
-
[8]
Accelerated bregman proximal gradient meth- ods for relatively smooth convex optimization.Computational Optimization and Applica- tions, 79:405 – 440, 2018
Filip Hanzely, Peter Richtárik, and Lin Xiao. Accelerated bregman proximal gradient meth- ods for relatively smooth convex optimization.Computational Optimization and Applica- tions, 79:405 – 440, 2018. URLhttps://api.semanticscholar.org/CorpusID: 52585212. 9
2018
-
[9]
Filip Hanzely, Peter Richtárik, and Lin Xiao. Accelerated bregman proximal gradient methods for relatively smooth convex optimization.Computational Optimization and Applications, 79 (2):405–440, 2021. doi: 10.1007/s10589-021-00273-8. URLhttps://doi.org/10. 1007/s10589-021-00273-8. 2
-
[10]
Mirror duality in convex optimization.arXiv preprint arXiv:2311.17296, 2023
Jaeyeon Kim, Chanwoo Park, Asuman Ozdaglar, Jelena Diakonikolas, and Ernest K Ryu. Mirror duality in convex optimization.arXiv preprint arXiv:2311.17296, 2023. 1, 2
arXiv 2023
-
[11]
Accelerated mirror descent in contin- uous and discrete time
Walid Krichene, Alexandre Bayen, and Peter L Bartlett. Accelerated mirror descent in contin- uous and discrete time. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, edi- tors,Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc.,
-
[12]
URLhttps://proceedings.neurips.cc/paper_files/paper/2015/ file/f60bb6bb4c96d4df93c51bd69dcc15a0-Paper.pdf. 1
2015
-
[13]
Anisotropic proximal gradient.Mathematical Pro- gramming, pages 1–45, 2025
Emanuel Laude and Panagiotis Patrinos. Anisotropic proximal gradient.Mathematical Pro- gramming, pages 1–45, 2025. 2, 3, 8, 9, 12
2025
-
[14]
Haihao Lu, Robert M. Freund, and Yurii Nesterov. Relatively smooth convex optimization by first-order methods, and applications.SIAM Journal on Optimization, 28(1):333–354, 2018. doi: https://doi.org/10.1137/16M1099546. 3, 8, 9
-
[15]
Dual space precondi- tioning for gradient descent.SIAM Journal on Optimization, 31(1):991–1016, 2021
Chris J Maddison, Daniel Paulin, Yee Whye Teh, and Arnaud Doucet. Dual space precondi- tioning for gradient descent.SIAM Journal on Optimization, 31(1):991–1016, 2021. 1, 2, 3, 8
2021
-
[16]
Adaptive gradient descent without descent.arXiv preprint arXiv:1910.09529, 2019
Yura Malitsky and Konstantin Mishchenko. Adaptive gradient descent without descent.arXiv preprint arXiv:1910.09529, 2019. 2 10
arXiv 1910
-
[17]
Adaptive proximal gradient method for convex optimization.Advances in Neural Information Processing Systems, 37:100670–100697, 2024
Yura Malitsky and Konstantin Mishchenko. Adaptive proximal gradient method for convex optimization.Advances in Neural Information Processing Systems, 37:100670–100697, 2024. 2
2024
-
[18]
Arkadi Nemirovski. Prox-method with rate of convergence o(1/t) for variational in- equalities with lipschitz continuous monotone operators and smooth convex-concave sad- dle point problems.SIAM Journal on Optimization, 15(1):229–251, 2004. doi: 10.1137/ S1052623403425629. 1
2004
-
[19]
A Wiley-Interscience publication
Arkadij Semenovi ˇc Nemirovskij and David Borisovich Yudin.Problem Complexity and Method Efficiency in Optimization. A Wiley-Interscience publication. Wiley, 1983. ISBN 9780471103455. 1
1983
-
[20]
A method of solving a convex programming problem with convergence rate o 1 k2 .Doklady Akademii Nauk SSSR, 269(3):543–547, 1983
Yurii Nesterov. A method of solving a convex programming problem with convergence rate o 1 k2 .Doklady Akademii Nauk SSSR, 269(3):543–547, 1983. 1, 8, 9
1983
-
[21]
Smooth minimization of non-smooth functions.Mathematical Programming, 103(1):127–152, 2005
Yurii Nesterov. Smooth minimization of non-smooth functions.Mathematical Programming, 103(1):127–152, 2005. doi: https://doi.org/10.1007/s10107-004-0552-5. 1
-
[22]
Konstantinos Oikonomidis, Jan Quan, Emanuel Laude, and Panagiotis Patrinos. Non- linearly preconditioned gradient methods under generalized smoothness.arXiv preprint arXiv:2502.08532, 2025. 1
arXiv 2025
-
[23]
Tyrrell Rockafellar.Convex Analysis
R. Tyrrell Rockafellar.Convex Analysis. Princeton University Press, 1970. ISBN 9780691015866. URLhttp://www.jstor.org/stable/j.ctt14bs1ff. 3
1970
-
[24]
Adaptive accelerated gradient descent methods for convex optimiza- tion, 2026
Zeyi Xu and Long Chen. Adaptive accelerated gradient descent methods for convex optimiza- tion, 2026. URLhttps://arxiv.org/abs/2601.19013. 2, 8
arXiv 2026
-
[25]
curvature
Ya-Xiang Yuan and Yi Zhang. Analyze accelerated mirror descent via high-resolution ODEs. Journal of the Operations Research Society of China, 2024. doi: https://doi.org/10.1007/ s40305-024-00542-3. 1 11 A Discussion: Relation to Anisotropic Smoothness/Convexity Laude et al. (2025) proposed the anisotropic descent (smoothness) and convexity conditions [12]...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.