BehaviorBench: Modeling Real-World User Decisions from Behavioral Traces
Pith reviewed 2026-06-28 14:23 UTC · model grok-4.3
The pith
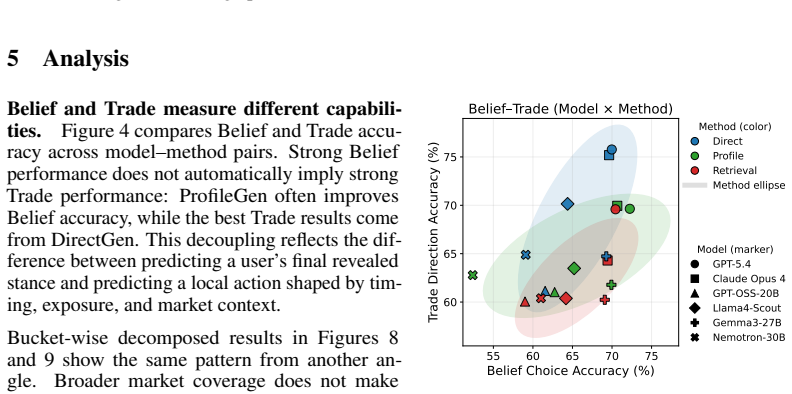
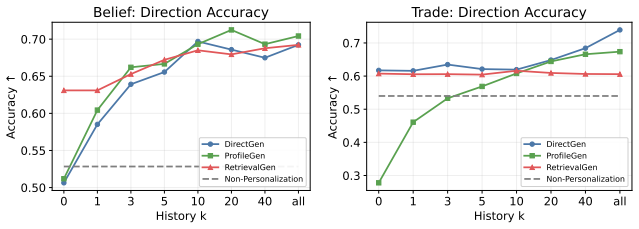
BehaviorBench shows personalization from real trading histories improves belief prediction more consistently than trade prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
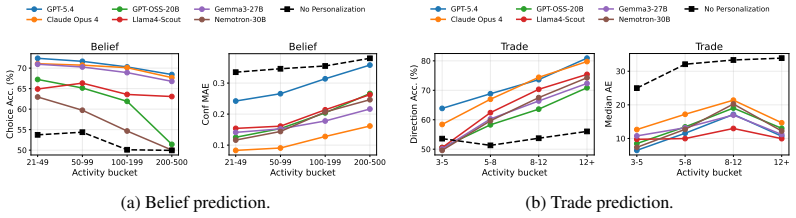
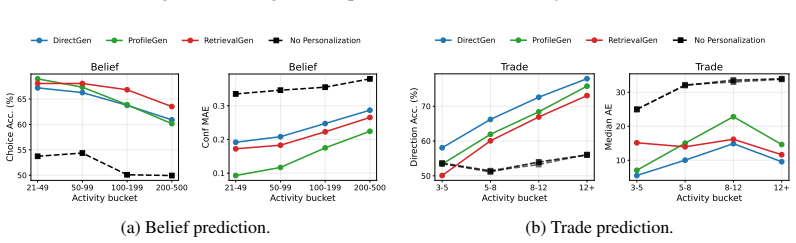
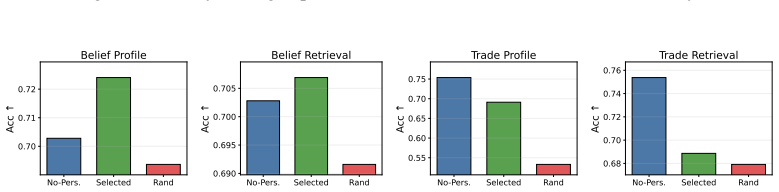
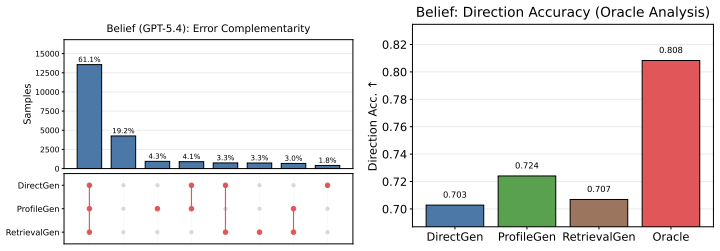
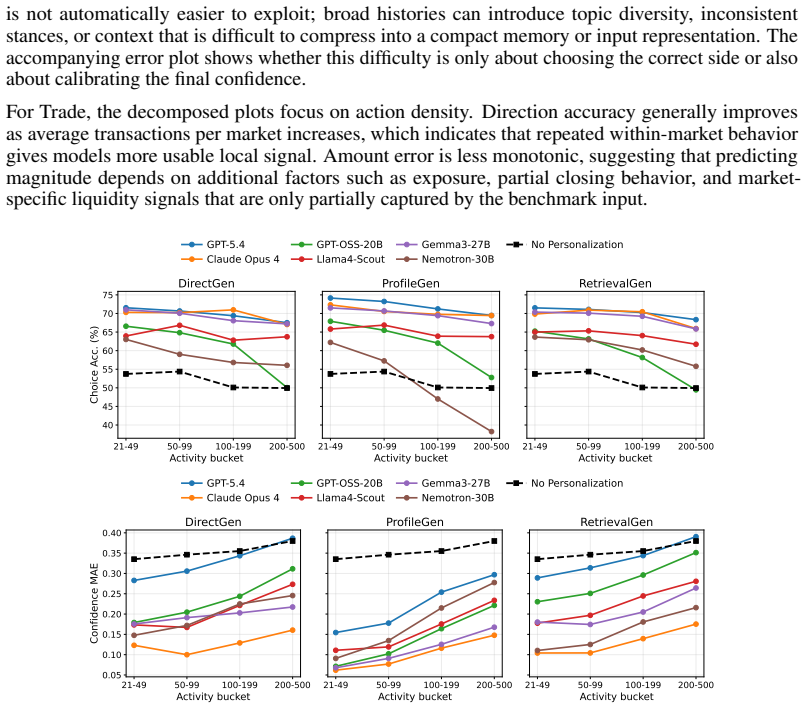
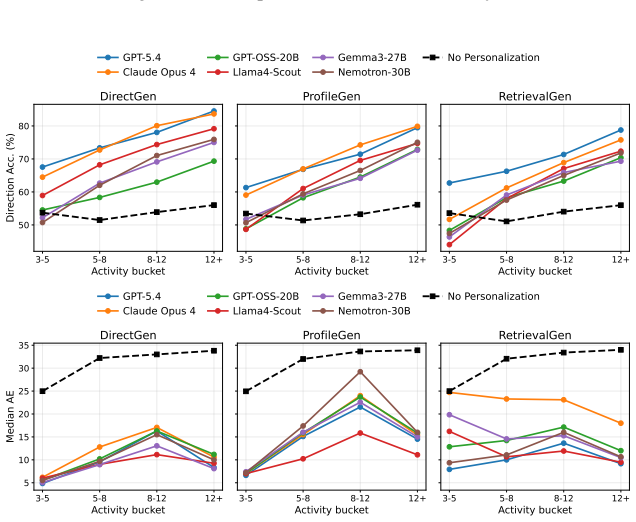
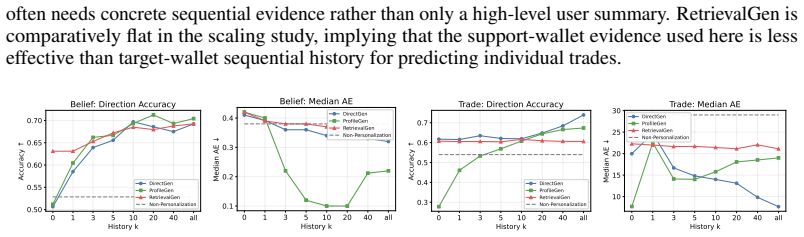
BehaviorBench reconstructs wallet-level decision histories from public prediction-market and on-chain records into 141,445 belief instances and 1,485,972 trade instances across 2,000 wallets. When frontier and open-weight models are evaluated under four history interfaces—no personalization, direct recent history, generated user profiles, and retrieved support-wallet evidence—personalization improves belief prediction more consistently than trade prediction, model rankings change across task layers and metrics, and different history interfaces expose different failure modes.
What carries the argument
BehaviorBench, which turns public market and on-chain records into wallet-level histories organized as belief prediction and trade prediction tasks evaluated under multiple history interfaces.
If this is right
- Model rankings depend on whether the evaluation focuses on belief prediction or trade prediction and on the chosen metric.
- Each history interface—direct history, generated profiles, or retrieved evidence—surfaces distinct limitations in current generative models.
- Real behavioral traces supply a stricter test than model-generated simulations for assessing personalization methods.
- Retrieval from support wallets offers one route to personalization that can be compared against other interfaces.
Where Pith is reading between the lines
- The same reconstruction approach could be tested in other traceable domains such as online marketplaces or content platforms to check whether the belief-versus-trade difference holds.
- If the wallet histories prove faithful, the benchmark offers a route to validate personalization techniques in settings where individual decision records are available.
- Scaling the evaluation to additional markets or larger wallet sets would test whether the current patterns in personalization gains persist.
Load-bearing premise
That public prediction-market and on-chain records can be reconstructed into accurate wallet-level decision histories that reflect genuine individual user behavior without significant selection or reporting bias.
What would settle it
A direct comparison showing that the reconstructed histories systematically omit or distort private user decisions would demonstrate that the benchmark does not capture true behavior.
Figures
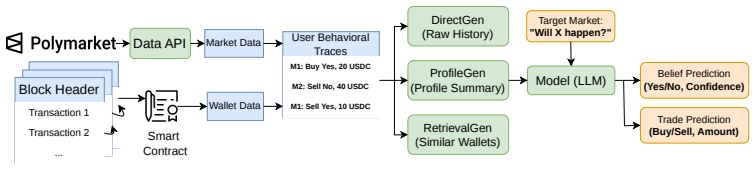


read the original abstract
Many decision-support settings require systems that adapt to individual users, but evaluation data for this problem remain limited. Existing benchmarks for user understanding often rely on simulated users or model-generated behavior, even though recent work cautions that model-based simulations can diverge systematically from human behavior. We introduce \textsc{BehaviorBench}, a benchmark for evaluating personalized decision modeling from real-world behavioral traces. \textsc{BehaviorBench} reconstructs wallet-level decision histories from observed public prediction-market and on-chain records, and organizes them into two complementary task layers: \emph{Belief prediction}, which predicts a user's final revealed stance and confidence in a market, and \emph{Trade prediction}, which predicts the direction and amount of individual transactions. Across 2,000 evaluation wallets, the benchmark contains 141,445 Belief instances and 1,485,972 Trade instances, with disjoint support pools for retrieval-based evaluation. We evaluate frontier and open-weight generative models under four history interfaces: no personalization, direct recent history, generated user profiles, and retrieved support-wallet evidence. Personalization improves Belief prediction more consistently than Trade prediction, model rankings change across task layers and metrics, and different history interfaces expose different failure modes. \textsc{BehaviorBench} provides an evaluation setting for studying whether personalized methods can use real-world behavioral evidence rather than simulated users alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BehaviorBench, a benchmark for personalized decision modeling constructed from real-world behavioral traces. It reconstructs wallet-level histories from public prediction-market and on-chain records across 2,000 wallets, yielding 141,445 Belief prediction instances and 1,485,972 Trade prediction instances. The benchmark evaluates frontier and open-weight generative models under four history interfaces (no personalization, direct recent history, generated user profiles, retrieved support-wallet evidence) on two task layers: predicting final stance/confidence (Belief) and transaction direction/amount (Trade). Reported findings include that personalization improves Belief prediction more consistently than Trade prediction, model rankings vary across tasks and metrics, and history interfaces expose distinct failure modes. The work positions the benchmark as an alternative to simulated-user evaluations.
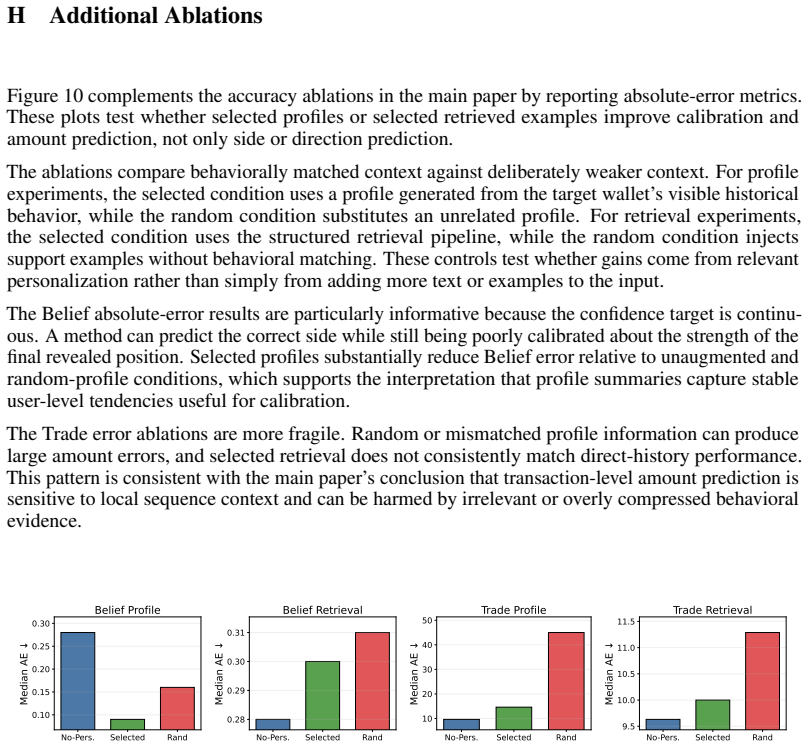
Significance. If the wallet-level reconstructions accurately reflect genuine individual decisions, BehaviorBench would provide a useful real-world evaluation setting for adaptive decision-support systems. This addresses documented concerns about divergence between model-generated simulations and human behavior, enabling direct study of how different forms of personalization (recent history, profiles, retrieval) perform on actual traces from prediction markets and blockchain data.
major comments (1)
- [Abstract] Abstract: The headline claims (personalization improves Belief prediction more consistently than Trade; model rankings and failure modes vary by interface) rest on the assertion that the 141k Belief and 1.48M Trade instances reflect 'genuine individual user behavior.' The reconstruction step from public records is the load-bearing foundation, yet the abstract provides no mention of validation steps such as bot detection, wallet-sharing analysis, or selection-bias quantification. If wallets are shared, automated, or represent a non-random subset, downstream comparisons of history interfaces become difficult to interpret.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for transparency around the wallet reconstruction process. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims (personalization improves Belief prediction more consistently than Trade; model rankings and failure modes vary by interface) rest on the assertion that the 141k Belief and 1.48M Trade instances reflect 'genuine individual user behavior.' The reconstruction step from public records is the load-bearing foundation, yet the abstract provides no mention of validation steps such as bot detection, wallet-sharing analysis, or selection-bias quantification. If wallets are shared, automated, or represent a non-random subset, downstream comparisons of history interfaces become difficult to interpret.
Authors: We agree that the abstract should better contextualize the reconstruction to support the claims. The full manuscript (Section 3) describes wallet selection from public prediction-market and on-chain records using activity thresholds and disjoint support pools, but does not include explicit bot detection, wallet-sharing analysis, or formal selection-bias quantification, as the data is pseudonymous. We will revise the abstract to add a brief clause noting the public-record origin, activity-based filtering, and that results should be interpreted with potential limitations regarding individual vs. shared/automated behavior. This makes the presentation more precise while retaining the benchmark's focus on real traces. revision: yes
Circularity Check
No significant circularity; benchmark constructed from external records
full rationale
The paper introduces BehaviorBench by reconstructing wallet-level histories directly from public prediction-market and on-chain records, with no equations, fitted parameters, or self-referential derivations described. Model evaluations under different history interfaces rely on these external traces rather than reducing to any input by construction. No self-citation load-bearing, ansatz smuggling, or renaming of known results is present in the provided text. The central claims about personalization effects are empirical comparisons on independent data, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
-
[2]
Introduction to the fifth annual lifelog search challenge, lsc’22
Cathal Gurrin, Liting Zhou, Graham Healy, Björn Pór Jónsson, Duc Tien Dang-Nguyen, Jakub Lokoˇc, Minh Triet Tran, Wolfgang Hürst, Luca Rossetto, and Klaus Schöffmann. Introduction to the fifth annual lifelog search challenge, lsc’22. InProceedings of the 2022 International Conference on Multimedia Retrieval, pages 685–687,
2022
-
[3]
Tiancheng Hu, Joachim Baumann, Lorenzo Lupo, Nigel Collier, Dirk Hovy, and Paul Röttger
doi: 10.1145/3512527.3531439. Tiancheng Hu, Joachim Baumann, Lorenzo Lupo, Nigel Collier, Dirk Hovy, and Paul Röttger. SimBench: Benchmarking the ability of large language models to simulate human behaviors.arXiv preprint arXiv:2510.17516, 2025a. Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou...
-
[4]
Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770,
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770,
-
[5]
Realtalk: A 21-day real-world dataset for long-term conversation.arXiv preprint arXiv:2502.13270,
Dong-Ho Lee, Adyasha Maharana, Jay Pujara, Xiang Ren, and Francesco Barbieri. Realtalk: A 21-day real-world dataset for long-term conversation.arXiv preprint arXiv:2502.13270,
-
[6]
Rui Li, Heming Xia, Xinfeng Yuan, Qingxiu Dong, Lei Sha, Wenjie Li, and Zhifang Sui. How far are LLMs from being our digital twins? a benchmark for persona-based behavior chain simulation. arXiv preprint arXiv:2502.14642,
-
[7]
doi: 10.1609/AAAI.V40I1.37040. URL https://doi.org/10. 1609/aaai.v40i1.37040. Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. Memgpt: towards llms as operating systems
-
[8]
doi: 10.1145/3586183.3606763. Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. Lamp: When large lan- guage models meet personalization. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7370–7392,
-
[9]
Personabench: Evaluating ai models on understanding personal information through accessing (synthetic) private user data
Juntao Tan, Liangwei Yang, Zuxin Liu, Zhiwei Liu, Rithesh RN, Tulika Manoj Awalgaonkar, Jianguo Zhang, Weiran Yao, Ming Zhu, Shirley Kokane, et al. Personabench: Evaluating ai models on understanding personal information through accessing (synthetic) private user data. InFindings of the Association for Computational Linguistics: ACL 2025, pages 878–893,
2025
-
[10]
Meiling Tao, Chenghao Zhu, Dongyi Ding, Tiannan Wang, Yuchen Eleanor Jiang, and Wangchunshu Zhou. Personafeedback: A large-scale human-annotated benchmark for personalization.arXiv preprint arXiv:2506.12915,
-
[11]
10 Quang-Linh Tran, Binh Nguyen, Gareth JF Jones, and Cathal Gurrin. Openlifelogqa: An open-ended multi-modal lifelog question-answering dataset.arXiv preprint arXiv:2508.03583,
-
[12]
KnowMe-Bench: Benchmarking Person Understanding for Lifelong Digital Companions
doi: 10.1145/3708985. Tingyu Wu, Zhisheng Chen, Ziyan Weng, Shuhe Wang, Chenglong Li, Shuo Zhang, Sen Hu, Silin Wu, Qizhen Lan, Huacan Wang, et al. Knowme-bench: Benchmarking person understanding for lifelong digital companions.arXiv preprint arXiv:2601.04745,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3708985
-
[13]
On generative agents in recommendation
An Zhang, Yuxin Chen, Leheng Sheng, Xiang Wang, and Tat-Seng Chua. On generative agents in recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2024a. doi: 10.1145/3626772.3657844. Erhan Zhang, Xingzhu Wang, Peiyuan Gong, Yankai Lin, and Jiaxin Mao. USimAgent: Large lang...
-
[14]
Weizhi Zhang, Xiaokai Wei, Wei-Chieh Huang, Zheng Hui, Chen Wang, Michelle Gong, and Philip S Yu. Memorycd: Benchmarking long-context user memory of llm agents for lifelong cross-domain personalization.arXiv preprint arXiv:2603.25973, 2026a. Weizhi Zhang, Wooseong Yang, Yuxin Cui, Zhaohui Guo, Hins Hu, Liangwei Yang, Henry Peng Zou, Qifei Wang, Hanqing Ze...
-
[16]
URL https://arxiv. org/abs/1901.09672. Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724–19731,
arXiv 1901
-
[17]
Mind the Sim2Real gap in user simulation for agentic tasks.arXiv preprint arXiv:2603.11245,
Xuhui Zhou, Weiwei Sun, Qianou Ma, Yiqing Xie, Jiarui Liu, Weihua Du, Sean Welleck, Yiming Yang, Graham Neubig, Sherry Tongshuang Wu, and Maarten Sap. Mind the Sim2Real gap in user simulation for agentic tasks.arXiv preprint arXiv:2603.11245,
-
[19]
URL https://arxiv. org/abs/2605.20204. 12 A Dataset Documentation and Intended Use Intended use.BEHAVIORBENCHis designed for evaluating systems that infer personalized deci- sions from historical behavioral traces. Appropriate uses include benchmarking history representa- tions, retrieval strategies, profile generation methods, memory mechanisms, and cali...
Pith/arXiv arXiv 2025
-
[20]
We do not treat the cutoff as a claim that every later transaction is non-human; rather, it is a benchmark-construction choice that reduces a visible regime shift in the raw data
We use it to avoid blending the pre-2026 user-behavior regime with the sharp transaction-volume increase we observe beginning in January 2026, which is plausibly associated with more automated or agent-mediated activity. We do not treat the cutoff as a claim that every later transaction is non-human; rather, it is a benchmark-construction choice that redu...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.