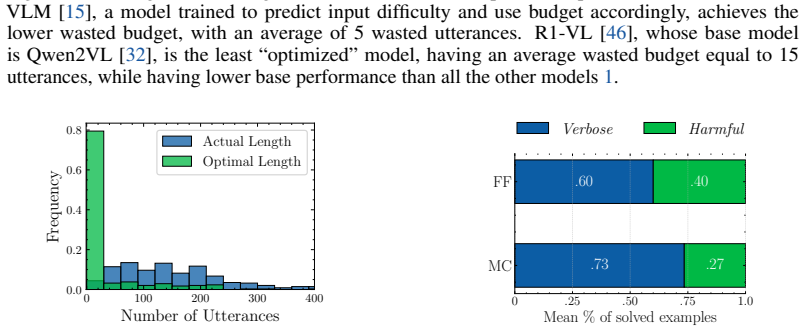
Thinking Past the Answer: Evaluating Harmful Overthinking in Large Reasoning Models
Pith reviewed 2026-06-28 14:12 UTC · model grok-4.3
The pith
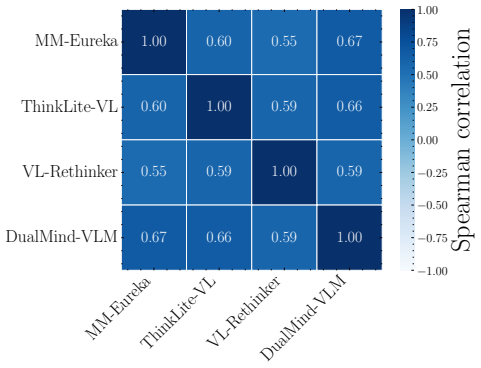
Stopping reasoning at the first correct prefix raises accuracy by up to 21% in large reasoning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
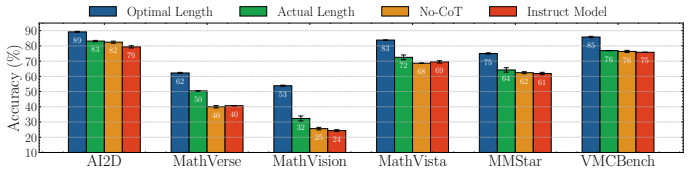
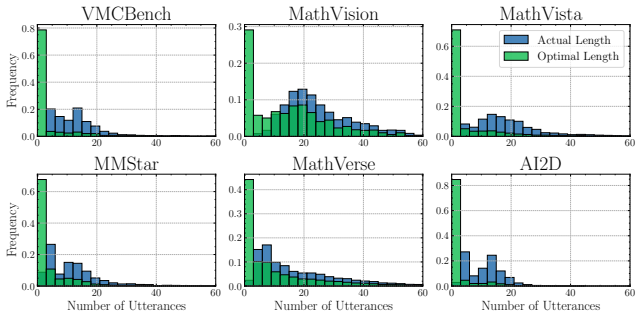
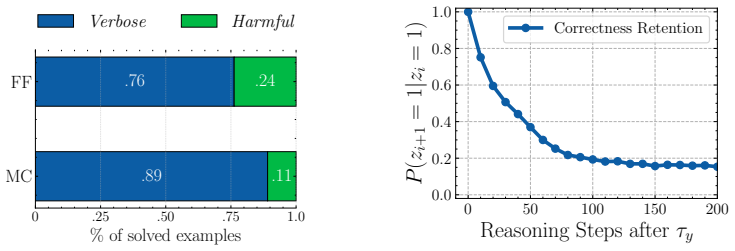
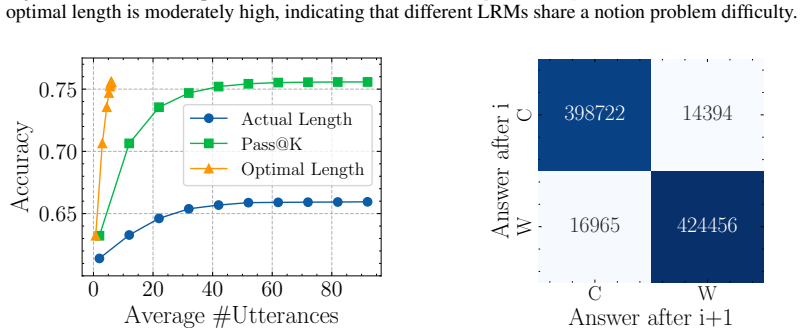
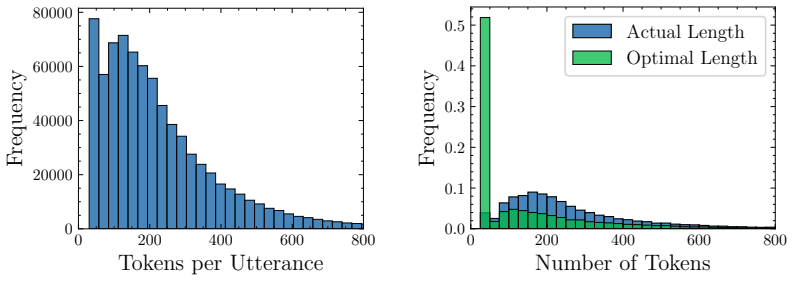
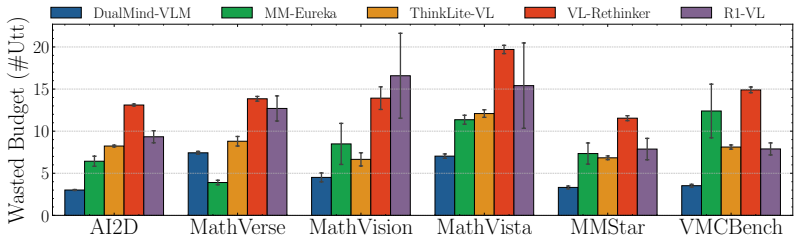
Once a model generates the correct answer inside its reasoning trace, further reasoning frequently destabilizes that solution rather than refining it. The minimum reasoning budget required to reach correctness is often short, and forcing the model to stop at that first correct prefix produces accuracy gains of up to 21 percent over standard full-trace generation. Common early-stopping methods cut redundant steps but leave harmful deviations intact, which are driven mainly by logical drift and visual reinterpretation.
What carries the argument
The prefix-level trajectory evaluation protocol that marks the shortest prefix of a reasoning trace whose final answer is correct and uses that point as the minimum sufficient budget.
If this is right
- Models are limited as much by when they stop as by how well they reason.
- Early-stopping heuristics reduce harmless extra steps but leave harmful overthinking untouched.
- Deviations after correctness arise chiefly from logical drift and visual reinterpretation.
- The inability to stop at the right time appears in both multimodal and language-only settings.
Where Pith is reading between the lines
- Objective functions that explicitly reward termination at first correctness could reduce harmful drift during training.
- Benchmarks that score only the final output may undervalue models that reach the answer early and then wander.
- The same stopping problem could surface in other long-horizon generation tasks such as code synthesis or multi-step planning.
Load-bearing premise
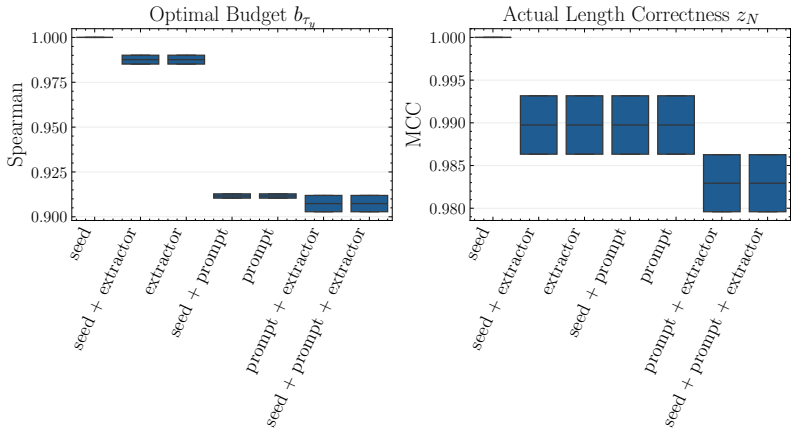
Judging correctness on prefixes does not systematically mislabel the true first point at which the model has solved the problem.
What would settle it
An experiment that forces models to terminate exactly at the identified first-correct prefix and measures whether accuracy still exceeds the accuracy obtained from letting the model generate its full original trace.
Figures




read the original abstract
Large Reasoning Models (LRMs) improve performance by generating explicit intermediate reasoning traces through increased test-time compute, yet the assumption that longer reasoning is consistently beneficial remains under-examined. While recent evidence shows that additional reasoning can lead models to overthink, we ask: "Once a model has reached the correct answer, does further reasoning refine the solution, or deviate from it?" To study the dynamics after correctness, we introduce a prefix-level trajectory evaluation protocol grounded in reasoning sufficiency, defining the minimum reasoning budget required for a model to first generate the correct answer. This allows us to disentangle verbose overthinking, where additional reasoning is redundant but harmless, from harmful overthinking, where continued reasoning destabilizes an already-correct trajectory. Starting from multimodal benchmarks, we find that many instances considered reasoning-intensive require surprisingly little reasoning. Moreover, stopping at the first correct prefix improves accuracy over standard reasoning up to 21%, revealing that current models are limited not only by their ability to reason, but also by their inability to stop at the right time. Furthermore, while common efficiency strategies like early stopping substantially reduce verbose overthinking (up to 50%), they fail to mitigate harmful overthinking. Failure analysis reveals that correctness deviations are mainly driven by logical drift and visual reinterpretation. Finally, we show that our findings generalize to language-only reasoning benchmarks, highlighting harmful overthinking as a broader reliability risk. Code available at https://simonecaldarella.github.io/thinking-past-the-answer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a prefix-level trajectory evaluation protocol to study harmful overthinking in Large Reasoning Models (LRMs). It claims that many multimodal reasoning tasks require surprisingly little reasoning to first reach correctness, that stopping at the first correct prefix yields accuracy gains of up to 21% over full trajectories, that common early-stopping methods reduce verbose but not harmful overthinking, and that the phenomenon generalizes to language-only benchmarks. Failure modes are attributed primarily to logical drift and visual reinterpretation.
Significance. If the protocol is robust, the work identifies a previously under-examined reliability failure mode in test-time scaling: models can destabilize correct solutions through continued reasoning. The empirical measurement on public benchmarks, the distinction between verbose and harmful overthinking, the demonstration that standard efficiency interventions do not address the latter, and the public code release are concrete contributions that could inform both evaluation protocols and training objectives for reasoning models.
major comments (3)
- [Methods / prefix-level trajectory evaluation protocol] Methods / prefix-level trajectory evaluation protocol: the paper provides no explicit description of the answer extractor applied to incomplete prefixes (regex for \boxed{}, LLM judge, final-token matching, or other). This detail is load-bearing for the headline 21% accuracy claim, because any systematic misclassification of early prefixes (especially under visual reinterpretation in multimodal traces) directly affects the measured gap between first-correct and full-trajectory accuracy.
- [Results on multimodal benchmarks] Results on multimodal benchmarks: the abstract states that stopping at the first correct prefix improves accuracy “up to 21%,” yet no table or section reports per-benchmark deltas, confidence intervals, or controls for multiple comparisons. Without these, it is impossible to assess whether the reported gain survives statistical scrutiny or benchmark-specific artifacts.
- [Failure analysis] Failure analysis: the claim that “correctness deviations are mainly driven by logical drift and visual reinterpretation” is presented without a quantitative breakdown (e.g., percentage of cases per failure mode) or a table of representative examples. This weakens the causal interpretation of harmful overthinking.
minor comments (2)
- [Abstract] The code link is given only in the abstract; a formal Data Availability or Code Availability statement with a persistent DOI or GitHub release tag would improve reproducibility.
- [Introduction / Methods] Notation for “reasoning sufficiency” and “first correct prefix” should be defined once in a dedicated subsection rather than introduced piecemeal across the abstract and results.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The comments highlight important areas for improving methodological transparency, statistical reporting, and the rigor of our failure analysis. We address each point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods / prefix-level trajectory evaluation protocol] the paper provides no explicit description of the answer extractor applied to incomplete prefixes (regex for \boxed{}, LLM judge, final-token matching, or other). This detail is load-bearing for the headline 21% accuracy claim, because any systematic misclassification of early prefixes (especially under visual reinterpretation in multimodal traces) directly affects the measured gap between first-correct and full-trajectory accuracy.
Authors: We agree that an explicit description of the answer extractor is necessary for reproducibility and to substantiate the accuracy gains. The current manuscript describes the overall prefix-level protocol but does not detail the extractor implementation. In the revised version we will add a dedicated subsection in Methods that specifies: (1) primary use of regex matching on \boxed{} and final-answer formats, (2) fallback to an LLM judge with a fixed prompt and temperature for ambiguous multimodal cases, and (3) human verification on a 200-sample subset to quantify extractor error rates. This addition will directly address concerns about misclassification under visual reinterpretation. revision: yes
-
Referee: [Results on multimodal benchmarks] the abstract states that stopping at the first correct prefix improves accuracy “up to 21%,” yet no table or section reports per-benchmark deltas, confidence intervals, or controls for multiple comparisons. Without these, it is impossible to assess whether the reported gain survives statistical scrutiny or benchmark-specific artifacts.
Authors: We acknowledge that the abstract reports only the maximum observed gain without per-benchmark detail or uncertainty estimates. The full manuscript contains aggregate results but lacks the requested breakdown. In revision we will add a new results table (and corresponding appendix) that reports, for each multimodal benchmark: (i) accuracy of full trajectories, (ii) accuracy when stopping at the first correct prefix, (iii) absolute and relative deltas, and (iv) 95% bootstrap confidence intervals. We will also state that the primary comparisons were pre-specified and therefore no multiple-comparison correction was applied. These changes will allow readers to evaluate statistical robustness directly. revision: yes
-
Referee: [Failure analysis] the claim that “correctness deviations are mainly driven by logical drift and visual reinterpretation” is presented without a quantitative breakdown (e.g., percentage of cases per failure mode) or a table of representative examples. This weakens the causal interpretation of harmful overthinking.
Authors: We agree that the current failure analysis is primarily qualitative. While the manuscript identifies the two dominant modes through manual inspection, it does not provide counts or examples. In the revised manuscript we will add: (1) a quantitative breakdown table based on annotation of 150 randomly sampled failure cases, reporting the percentage attributed to logical drift, visual reinterpretation, and other categories, and (2) a supplementary table with 2–3 representative trace excerpts per mode. These additions will ground the causal claims with concrete evidence. revision: yes
Circularity Check
No circularity: empirical protocol yields measured accuracy deltas on public benchmarks
full rationale
The paper introduces a prefix-level trajectory evaluation protocol as an operational definition for identifying the first correct answer in reasoning traces, then reports empirical accuracy improvements (up to 21%) when stopping at that point versus full trajectories. These are direct measurements on multimodal and language benchmarks, not quantities derived from self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation chain reduces the headline result to its inputs by construction; the protocol is a measurement tool whose validity is separate from circularity concerns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The definition of the first correct prefix can be determined unambiguously from model outputs on the chosen benchmarks.
Reference graph
Works this paper leans on
-
[1]
Intern-s1: A scientific multimodal foundation model.arXiv:2508.15763, 2025
Lei Bai, Zhongrui Cai, Yuhang Cao, Maosong Cao, Weihan Cao, Chiyu Chen, Haojiong Chen, Kai Chen, Pengcheng Chen, Ying Chen, et al. Intern-s1: A scientific multimodal foundation model.arXiv:2508.15763, 2025
arXiv 2025
-
[2]
Are we on the right way for evaluating large vision-language models?NeurIPS, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?NeurIPS, 2024
2024
-
[3]
Evaluating large language models trained on code.arXiv:2107.03374, 2021
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[4]
Do not think that much for 2+ 3=? on the overthinking of o1-like llms.ICML, 2025
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms.ICML, 2025
2025
-
[5]
Training verifiers to solve math word problems.arXiv:2110.14168, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[6]
Alejandro Cuadron, Dacheng Li, Wenjie Ma, Xingyao Wang, Yichuan Wang, Siyuan Zhuang, Shu Liu, Luis Gaspar Schroeder, Tian Xia, Huanzhi Mao, et al. The danger of overthinking: Examining the reasoning-action dilemma in agentic tasks.arXiv:2502.08235, 2025
arXiv 2025
-
[7]
S-grpo: Early exit via reinforcement learning in reasoning models.NeurIPS, 2025
Muzhi Dai, Chenxu Yang, and Qingyi Si. S-grpo: Early exit via reinforcement learning in reasoning models.NeurIPS, 2025
2025
-
[8]
Efficiently scaling llm reasoning with certaindex.NeurIPS, 2025
Yichao Fu, Junda Chen, Siqi Zhu, Zheyu Fu, Zhongdongming Dai, Yonghao Zhuang, Yian Ma, Aurick Qiao, Tajana Rosing, Ion Stoica, et al. Efficiently scaling llm reasoning with certaindex.NeurIPS, 2025
2025
-
[9]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.Nature, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.Nature, 2025
2025
-
[10]
Measuring mathematical problem solving with the math dataset.NeurIPS, 2021
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.NeurIPS, 2021
2021
-
[11]
Openai o1 system card.arXiv:2412.16720, 2024
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv:2412.16720, 2024
Pith/arXiv arXiv 2024
-
[12]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. InECCV, 2016
2016
-
[13]
Chain of thought compression: A theoritical analysis.arXiv preprint arXiv:2601.21576, 2026
Juncai Li, Ru Li, Yuxiang Zhou, Boxiang Ma, and Jeff Z Pan. Chain of thought compression: A theoritical analysis.arXiv preprint arXiv:2601.21576, 2026
Pith/arXiv arXiv 2026
-
[14]
To think or not to think: A study of thinking in rule-based visual reinforcement fine-tuning
Ming Li, Jike Zhong, Shitian Zhao, Yuxiang Lai, Haoquan Zhang, Wang Bill Zhu, and Kaipeng Zhang. To think or not to think: A study of thinking in rule-based visual reinforcement fine-tuning. InNeurIPS, 2025
2025
-
[15]
Learning to think fast and slow for visual language models.arXiv:2511.16670, 2025
Chenyu Lin, Cheng Chi, Jinlin Wu, Sharon Li, and Kaiyang Zhou. Learning to think fast and slow for visual language models.arXiv:2511.16670, 2025
arXiv 2025
-
[16]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation.NeurIPS, 2023
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation.NeurIPS, 2023
2023
-
[17]
Qfft, question-free fine-tuning for adaptive reasoning.NeurIPS, 2025
Wanlong Liu, Junxiao Xu, Fei Yu, Yukang Lin, Ke Ji, Wenyu Chen, Yan Xu, Yasheng Wang, Lifeng Shang, and Benyou Wang. Qfft, question-free fine-tuning for adaptive reasoning.NeurIPS, 2025. 10
2025
-
[18]
Efficient inference for large reasoning models: A survey.arXiv:2503.23077, 2025
Yue Liu, Jiaying Wu, Yufei He, Ruihan Gong, Jun Xia, Liang Li, Hongcheng Gao, Hongyu Chen, Baolong Bi, Jiaheng Zhang, et al. Efficient inference for large reasoning models: A survey.arXiv:2503.23077, 2025
arXiv 2025
-
[19]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.ICLR, 2023
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.ICLR, 2023
2023
-
[20]
Reasoning models can be effective without thinking.arXiv:2504.09858, 2025
Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, and Matei Zaharia. Reasoning models can be effective without thinking.arXiv:2504.09858, 2025
arXiv 2025
-
[21]
Comparison of the predicted and observed secondary structure of t4 phage lysozyme
Brian W Matthews. Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochimica et Biophysica Acta (BBA)-Protein Structure, 1975
1975
-
[23]
Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, Ping Luo, Yu Qiao, Qiaosheng Zhang, and Wenqi Shao. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning. arXiv:2503.07365, 2025
Pith/arXiv arXiv 2025
-
[24]
s1: Simple test-time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InEMNLP, 2025
2025
-
[25]
Gpqa: A graduate-level google-proof q&a benchmark.COLM, 2023
David Rein, Betty Hou, Amos Stock, William Liu, Ayan Mandlekar, Arian Ghodsi, Dara Bahri, Fan Zhou, Akshay Mehra, Eunice Yiu, et al. Gpqa: A graduate-level google-proof q&a benchmark.COLM, 2023
2023
-
[26]
Dast: Difficulty-adaptive slow-thinking for large reasoning models
Yi Shen, Jian Zhang, Jieyun Huang, Shuming Shi, Wenjing Zhang, Jiangze Yan, Ning Wang, Kai Wang, Zhaoxiang Liu, and Shiguo Lian. Dast: Difficulty-adaptive slow-thinking for large reasoning models. In EMNLP, pages 2322–2331, 2025
2025
-
[27]
The proof and measurement of association between two things
Charles Spearman. The proof and measurement of association between two things. 1961
1961
-
[28]
Stop overthinking: A survey on efficient reasoning for large language models.arXiv:2503.16419, 2025
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, et al. Stop overthinking: A survey on efficient reasoning for large language models.arXiv:2503.16419, 2025
Pith/arXiv arXiv 2025
-
[29]
Confidence improves self-consistency in llms
Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. Confidence improves self-consistency in llms. InFindings-ACL 2025, 2025
2025
-
[30]
Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning.NeurIPS, 2025
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning.NeurIPS, 2025
2025
-
[31]
Measuring multimodal mathematical reasoning with math-vision dataset.NeurIPS, 2024
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset.NeurIPS, 2024
2024
-
[32]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[33]
Make every penny count: Difficulty-adaptive self-consistency for cost-efficient reasoning
Xinglin Wang, Shaoxiong Feng, Yiwei Li, Peiwen Yuan, Yueqi Zhang, Chuyi Tan, Boyuan Pan, Yao Hu, and Kan Li. Make every penny count: Difficulty-adaptive self-consistency for cost-efficient reasoning. In Findings-NAACL, 2025
2025
-
[35]
Is it thinking or cheating? detecting implicit reward hacking by measuring reasoning effort
Xinpeng Wang, Nitish Joshi, Barbara Plank, Rico Angell, and He He. Is it thinking or cheating? detecting implicit reward hacking by measuring reasoning effort. InICLR, 2026
2026
-
[36]
Sota with less: Mcts-guided sample selection for data-efficient visual reasoning self-improvement
Xiyao Wang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Linjie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, and Lijuan Wang. Sota with less: Mcts-guided sample selection for data-efficient visual reasoning self-improvement. InNeurIPS, 2025
2025
-
[37]
Sota with less: Mcts-guided sample selection for data-efficient visual reasoning self-improvement.NeurIPS, 2025
Xiyao Wang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Linjie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, and Lijuan Wang. Sota with less: Mcts-guided sample selection for data-efficient visual reasoning self-improvement.NeurIPS, 2025. 11
2025
-
[38]
When more is less: Understanding chain-of-thought length in llms.ICLR, 2026
Yuyang Wu, Yifei Wang, Ziyu Ye, Tianqi Du, Stefanie Jegelka, and Yisen Wang. When more is less: Understanding chain-of-thought length in llms.ICLR, 2026
2026
-
[39]
Fast-slow thinking GRPO for large vision-language model reasoning
Wenyi Xiao and Leilei Gan. Fast-slow thinking GRPO for large vision-language model reasoning. In NeurIPS, 2025
2025
-
[40]
Qwen3 technical report.arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[41]
Dynamic early exit in reasoning models.ICLR, 2026
Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Qiaowei Li, Minghui Chen, Zheng Lin, and Weiping Wang. Dynamic early exit in reasoning models.ICLR, 2026
2026
-
[42]
Demystifying long chain-of- thought reasoning
Shiming Yang, Yuxuan Tong, Xinyao Niu, Graham Neubig, and Xiang Yue. Demystifying long chain-of- thought reasoning. InICML, 2025
2025
-
[43]
Reasoning models know when they’re right: Probing hidden states for self-verification.COLM, 2025
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they’re right: Probing hidden states for self-verification.COLM, 2025
2025
-
[44]
Adaptthink: Reasoning models can learn when to think
Jiajie Zhang, Nianyi Lin, Lei Hou, Ling Feng, and Juanzi Li. Adaptthink: Reasoning models can learn when to think. InEMNLP, 2025
2025
-
[45]
R1-vl: Learning to reason with multimodal large language models via step-wise group relative policy optimization
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-vl: Learning to reason with multimodal large language models via step-wise group relative policy optimization. InICCV, 2025
2025
-
[46]
R1-vl: Learning to reason with multimodal large language models via step-wise group relative policy optimization.ICCV, 2025
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-vl: Learning to reason with multimodal large language models via step-wise group relative policy optimization.ICCV, 2025
2025
-
[47]
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, 2024
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, 2024
2024
-
[48]
Instruction tuning for large language models: A survey.ACM, 2026
Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Guoyin Wang, et al. Instruction tuning for large language models: A survey.ACM, 2026
2026
-
[49]
American invitational mathematics examination (aime) 2025
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025. https: //huggingface.co/datasets/math-ai/aime25, 2025
2025
-
[50]
optimized
Yuhui Zhang, Yuchang Su, Yiming Liu, Xiaohan Wang, James Burgess, Elaine Sui, Chenyu Wang, Josiah Aklilu, Alejandro Lozano, Anjiang Wei, et al. Automated generation of challenging multiple-choice questions for vision language model evaluation. InCVPR, 2025. 12 Supplementary Material Overview This appendix is organized in four macro blocks complementing th...
2025
-
[51]
Compare only what changed after the last-correct prefix
-
[52]
Identify the main failure mode introduced by the final/full trace
-
[53]
If an image is provided, decide whether the added suffix hallucinates or misreads visual evidence
-
[54]
Choose the best available category even when the drift is ambiguous
-
[55]
category
Ignore the standard forced final-answer probe suffix. Allowed categories: {categories} Return only valid JSON: { "category": "one_allowed_category", "secondary_categories": ["zero_or_more_allowed_categories"], "severity": 0_to_100_integer, "went_wrong": "short explanation", "evidence": "short quote or paraphrase from the added/final trace", "example": "mi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.