Don't Gamble, GAMBLe: An Analytical Framework for AI-Driven Research Systems
Pith reviewed 2026-07-01 07:57 UTC · model grok-4.3
The pith
Distinct generator-assessor pairs in AI research systems create different optimization landscapes, so no single set of components works best for all problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
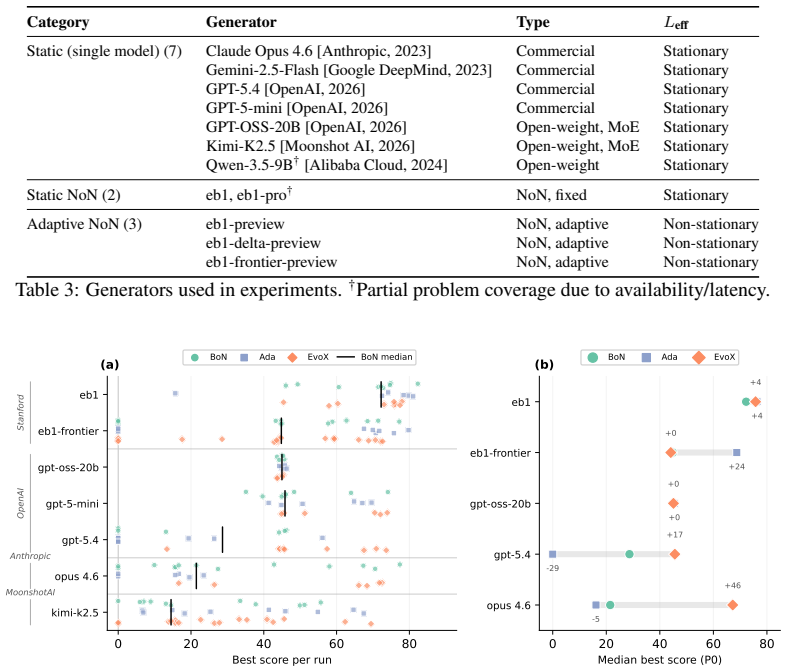
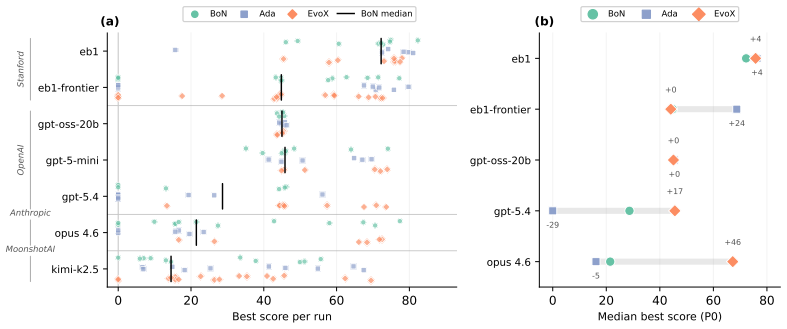
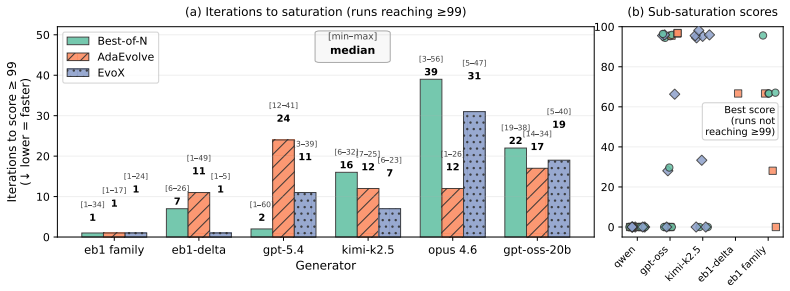
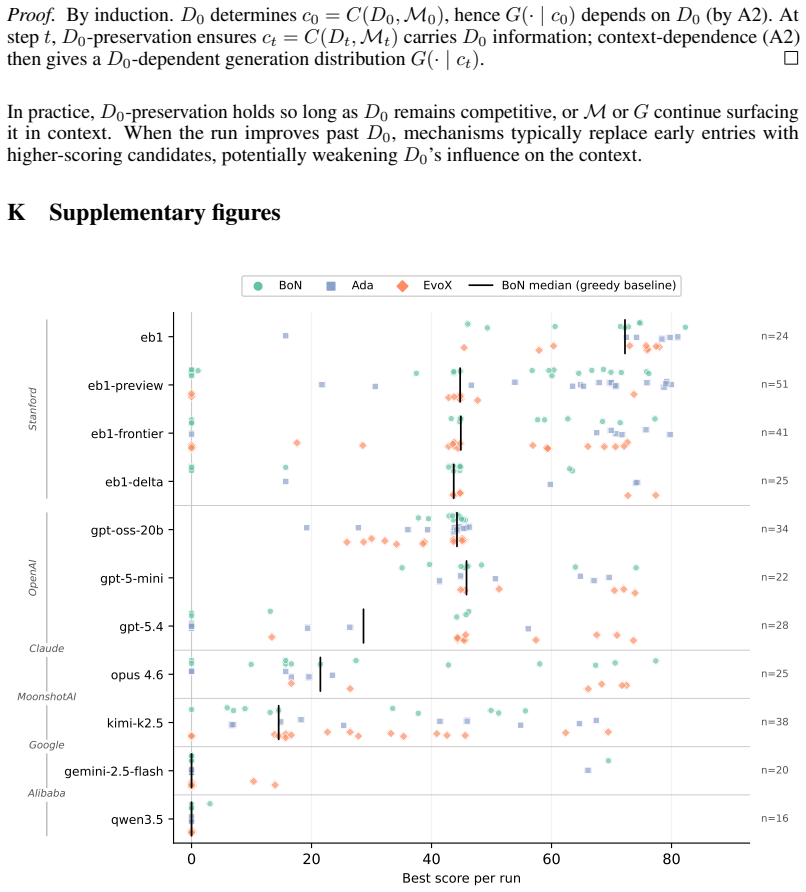
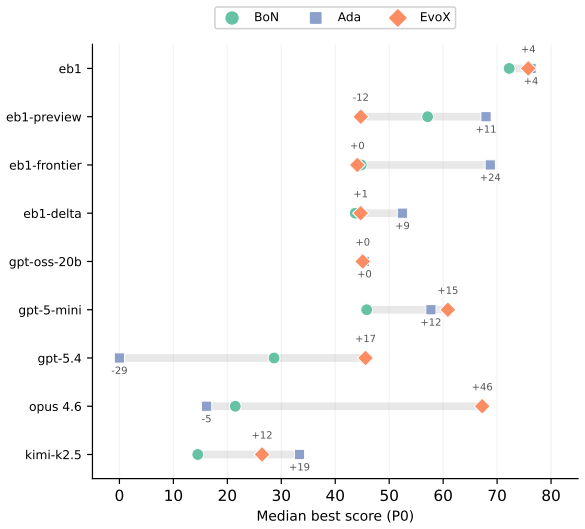
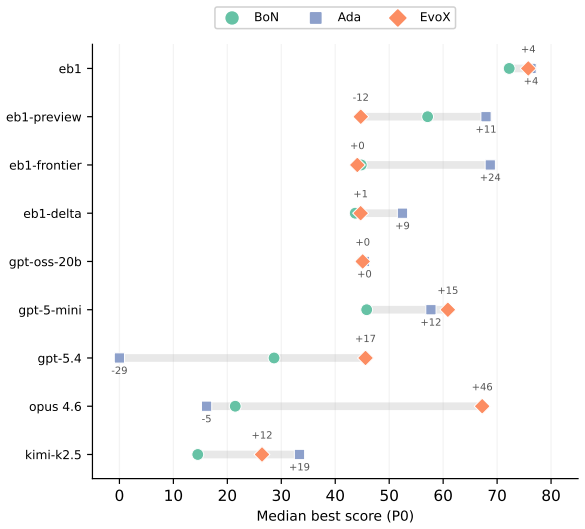
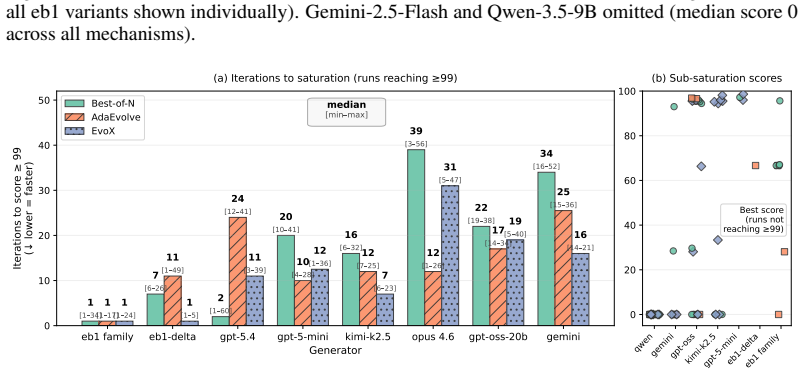
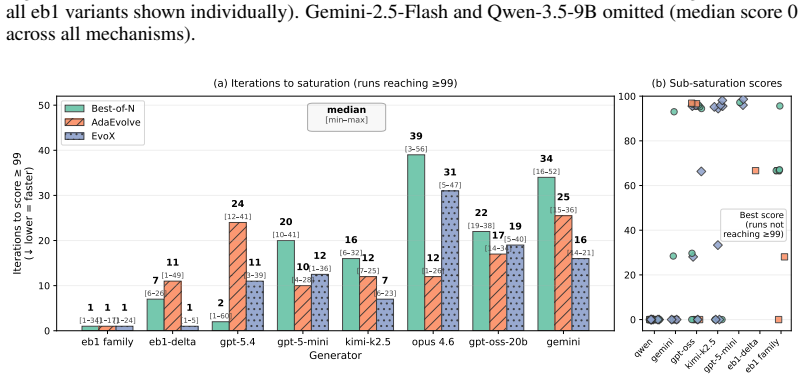
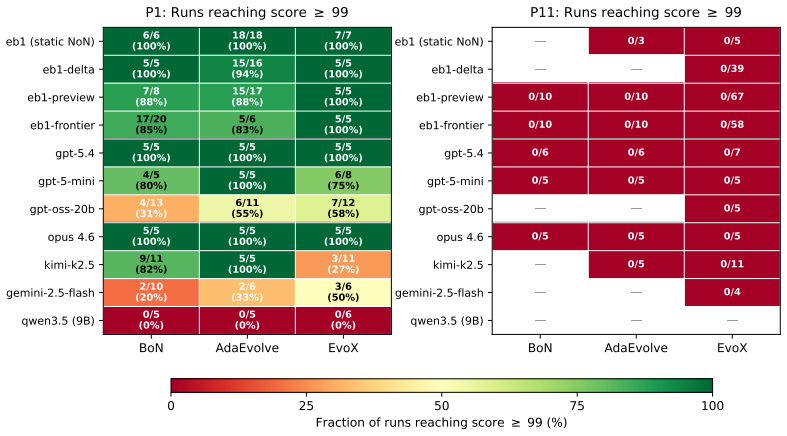
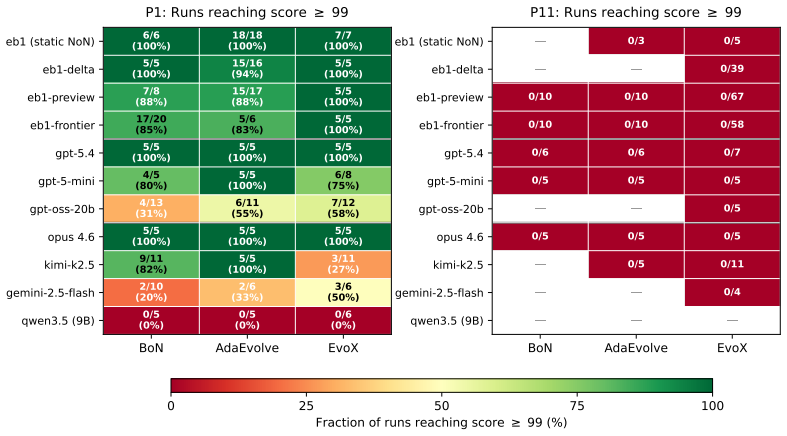
ADRS performance depends on component interactions poorly captured by existing guarantees. The GAMBLe framework decomposes behavior into four parameters and the effective landscape L_eff = A o G, revealing that distinct generator-assessor pairs induce structurally different per-problem optimization landscapes. There is no total ordering of generators or mechanisms across problems. The right choices improve performance by 13-67 percent and search efficiency by 6-39 times even with limited budgets of 60 iterations.
What carries the argument
The effective landscape L_eff = A ∘ G, the composition of assessor with generator that determines the structure of the optimization problem for each ADRS instance.
If this is right
- Distinct generator-assessor pairs require tailored optimization approaches rather than a one-size-fits-all strategy.
- No single generator or discovery mechanism outperforms all others across different problems.
- Performance improvements of 13 to 67 percent are achievable by selecting appropriate component combinations.
- Search efficiency can increase by factors of 6 to 39 times through better component matching under limited budgets.
- Frontier large language models can be outperformed by open-source alternatives when paired with suitable assessors and mechanisms.
Where Pith is reading between the lines
- The framework suggests that future ADRS designs could include landscape detection to dynamically select components.
- Similar compositional analysis might help in other automated discovery settings like chemical design or theorem proving.
- Further experiments could identify classes of problems that share similar effective landscapes.
- Hybrid generators that adapt based on the induced landscape may outperform fixed ensembles.
Load-bearing premise
Standard convergence guarantees apply only when the ADRS process satisfies structural assumptions that it does not.
What would settle it
Finding a consistent ranking where one generator outperforms all others across every assessor and all three tested problems would challenge the claim of no total ordering.
Figures

read the original abstract
AI-Driven Research Systems (ADRS) -- systems coupling LLMs with automated evaluation to discover algorithms, proofs, and designs -- are being optimized and adopted across domains, but the tools to analyze them have not kept pace. ADRS performance depends on component interactions that are poorly understood, expensive to explore, and (as we show) not well captured by standard convergence guarantees. These guarantees rely on structural assumptions that do not hold under the ADRS process we formalize. We introduce GAMBLe, a framework that decomposes ADRS behavior into four parameters (generator $G$, assessor $\mathcal{A}$, discovery mechanism $\mathcal{M}$, budget $B$) and one compositional object, the effective landscape $L_{\text{eff}} = \mathcal{A} \circ G$, which reveals that distinct generator-assessor pairs induce structurally different per-problem optimization landscapes. We exercise the framework on 760+ replicated runs (>46,000 iterations) spanning generators from single LLMs to dynamically-adaptive ensembles, mechanisms from greedy selection to co-evolutionary meta-search, and three NP-hard problems whose assessors range from continuous scoring to cliff functions. The experiments reveal no total ordering of generators or mechanisms: frontier models can underperform open-source alternatives and the simplest mechanism sometimes outperforms state-of-the-art meta-search. Results show that even under limited budgets (60 iterations per run), the right component choices can improve performance by 13-67% and search efficiency by 6-39x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the GAMBLe framework decomposing AI-Driven Research Systems (ADRS) into generator G, assessor A, mechanism M, budget B, and the compositional effective landscape L_eff = A ◦ G. It claims that distinct G-A pairs induce structurally different per-problem optimization landscapes (no total ordering of generators or mechanisms), and that appropriate component choices yield 13-67% performance gains and 6-39x efficiency improvements, supported by 760+ replicated runs (>46k iterations) across generators, mechanisms, and three NP-hard problems with varying assessor types.
Significance. If the decomposition and empirical findings hold, GAMBLe provides a useful lens for analyzing component interactions in ADRS beyond standard convergence guarantees, with the large-scale replicated experiments offering concrete evidence of performance variation across LLMs, ensembles, and selection mechanisms. The explicit reporting of run counts and iteration totals is a strength for reproducibility.
major comments (3)
- [Abstract] Abstract: the central claim that 'distinct generator-assessor pairs induce structurally different per-problem optimization landscapes' via L_eff is not directly supported by the reported evidence. The 760+ runs demonstrate performance and efficiency deltas but include no landscape descriptors (modality count, basin sizes, ruggedness, or similar topological measures); performance gaps alone can arise from assessor scaling or sampling bias without structural change in the search space.
- [Abstract] Abstract / experiments description: the 'no total ordering' claim and specific improvement ranges (13-67%, 6-39x) are presented without reference to the statistical tests, data exclusion rules, or variance measures used to establish them. This undermines verification of the claim that frontier models can underperform open-source alternatives or that the simplest mechanism can outperform meta-search.
- [Abstract] Abstract: the statement that 'these guarantees rely on structural assumptions that do not hold under the ADRS process we formalize' is asserted but the abstract provides no equation or section reference showing where the formalization of the ADRS process violates those assumptions (e.g., via a counter-example derivation).
minor comments (1)
- [Abstract] The abstract mentions 'three NP-hard problems' but does not name them or their assessor types (continuous vs. cliff); adding this would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will make targeted revisions to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'distinct generator-assessor pairs induce structurally different per-problem optimization landscapes' via L_eff is not directly supported by the reported evidence. The 760+ runs demonstrate performance and efficiency deltas but include no landscape descriptors (modality count, basin sizes, ruggedness, or similar topological measures); performance gaps alone can arise from assessor scaling or sampling bias without structural change in the search space.
Authors: The framework defines L_eff = A ◦ G explicitly as the compositional object that determines the per-problem optimization landscape. The experiments hold M and B fixed while varying G-A pairs, producing statistically distinguishable performance distributions across the same problem instances; we interpret these as evidence of distinct effective landscapes. We agree that explicit topological descriptors (e.g., modality or basin-size statistics) are not reported and would strengthen the claim. We will revise the abstract to reference the controlled experimental design in Section 3 and add a sentence noting that direct topological analysis is left for future work. revision: partial
-
Referee: [Abstract] Abstract / experiments description: the 'no total ordering' claim and specific improvement ranges (13-67%, 6-39x) are presented without reference to the statistical tests, data exclusion rules, or variance measures used to establish them. This undermines verification of the claim that frontier models can underperform open-source alternatives or that the simplest mechanism can outperform meta-search.
Authors: The full manuscript reports these details (including per-run variance, replication counts, and improvement criteria) in Section 4. Space constraints prevented their inclusion in the abstract. We will revise the abstract to add brief parenthetical references to Section 4 and qualify the reported ranges as arising from the replicated experimental protocol described therein. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'these guarantees rely on structural assumptions that do not hold under the ADRS process we formalize' is asserted but the abstract provides no equation or section reference showing where the formalization of the ADRS process violates those assumptions (e.g., via a counter-example derivation).
Authors: The formalization of the ADRS process and the explicit contrast with standard convergence assumptions appears in Section 2. We will add a direct reference to Section 2 in the abstract so readers can locate the relevant definitions and discussion. revision: yes
Circularity Check
No circularity: framework is definitional decomposition with independent empirical tests
full rationale
The paper defines GAMBLe as a decomposition into G, A, M, B and the object L_eff = A ◦ G, then reports direct experimental outcomes (760+ runs on external NP-hard problems) showing performance and efficiency variation across component choices. No step reduces a reported result to a fitted parameter by construction, no self-citation chain bears the central claim, and no prediction is equivalent to its inputs. The derivation chain is self-contained against the stated external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
effective landscape L_eff
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Science , volume=
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
2022
-
[2]
2026 , eprint=
AI-Driven Research for Databases , author=. 2026 , eprint=
2026
-
[3]
2025 , eprint=
Barbarians at the Gate: How AI is Upending Systems Research , author=. 2025 , eprint=
2025
-
[4]
2025 , eprint=
Let the Barbarians In: How AI Can Accelerate Systems Performance Research , author=. 2025 , eprint=
2025
-
[5]
2026 , eprint=
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning , author=. 2026 , eprint=
2026
-
[6]
2026 , url =
SkyDiscover: A Flexible Framework for AI-Driven Scientific and Algorithmic Discovery , author =. 2026 , url =
2026
-
[7]
2026 , eprint=
AdaEvolve: Adaptive LLM Driven Zeroth-Order Optimization , author=. 2026 , eprint=
2026
-
[8]
2026 , eprint=
EvoX: Meta-Evolution for Automated Discovery , author=. 2026 , eprint=
2026
-
[9]
LEVI: LLM-Guided Evolutionary Search Needs Better Harnesses, Not Bigger Models , author =
-
[10]
2024 , eprint =
Networks of Networks: Complexity Class Principles Applied to Compound AI Systems Design , author =. 2024 , eprint =
2024
-
[11]
Pawan Kumar, Emilien Dupont, Francisco J
Romera-Paredes, Bernardino and Barekatain, Mohammadamin and Novikov, Alexander and Balog, Matej and Kumar, M. Pawan and Dupont, Emilien and Ruiz, Francisco J. R. and Ellenberg, Jordan S. and Wang, Pengming and Fawzi, Omar and Kohli, Pushmeet and Fawzi, Alhussein , date =. Mathematical discoveries from program search with large language models , url =. Nat...
-
[12]
2025 , eprint=
AlphaEvolve: A coding agent for scientific and algorithmic discovery , author=. 2025 , eprint=
2025
-
[13]
, title =
Borkar, Vivek S. , title =. 2009 , isbn =
2009
-
[14]
Dynamics of stochastic approximation algorithms
Bena \"i m, Michel. Dynamics of stochastic approximation algorithms. S \'e minaire de Probabilit \'e s XXXIII. 1999
1999
-
[15]
2025 , eprint=
RouteLLM: Learning to Route LLMs with Preference Data , author=. 2025 , eprint=
2025
-
[16]
Qwen Model Series , year =
-
[17]
Gemini Model Family , year =
-
[18]
Claude Model Family , year =
-
[19]
2026 , url =
OpenAI , title =. 2026 , url =
2026
-
[20]
1993 , publisher =
The Origins of Order: Self-Organization and Selection in Evolution , author =. 1993 , publisher =
1993
-
[21]
and Klein, A
Feurer, M. and Klein, A. and Eggensperger, K. and Springenberg, J. and Blum, M. and Hutter, F. , year =. Proceedings of the 28th International Conference on Advances in Neural Information Processing Systems (NIPS'15) , title =
-
[22]
2026 , eprint=
Bilevel Autoresearch: Meta-Autoresearching Itself , author=. 2026 , eprint=
2026
-
[23]
2022 , eprint=
Evolution through Large Models , author=. 2022 , eprint=
2022
-
[24]
2018 , publisher =
Lectures on Convex Optimization , author =. 2018 , publisher =
2018
-
[25]
Asymptotically efficient adaptive allocation rules , journal =. 1985 , issn =. doi:https://doi.org/10.1016/0196-8858(85)90002-8 , url =
-
[26]
Slivkins, Aleksandrs , title =. Found. Trends Mach. Learn. , month = nov, pages =. 2019 , issue_date =. doi:10.1561/2200000068 , abstract =
-
[27]
2017 , publisher=
Markov chains and mixing times , author=. 2017 , publisher=
2017
-
[28]
2010 , publisher =
Bioinspired Computation in Combinatorial Optimization: Algorithms and Their Computational Complexity , author =. 2010 , publisher =
2010
-
[29]
2025 , eprint=
FrontierCS: Evolving Challenges for Evolving Intelligence , author=. 2025 , eprint=
2025
-
[30]
Proceedings of the ACM Conference on AI and Agentic Systems , pages =
Hamadanian, Pouya and Karimi, Pantea and Nasr-Esfahany, Arash and Noorbakhsh, Kimia and Chandler, Joseph and ParandehGheibi, Ali and Alizadeh, Mohammad and Balakrishnan, Hari , title =. Proceedings of the ACM Conference on AI and Agentic Systems , pages =. 2026 , isbn =. doi:10.1145/3786335.3813125 , abstract =
-
[31]
Open agent specification: Enabling cross-framework comparison of ai agents,
Karimi, Pantea and Noorbakhsh, Kimia and Alizadeh, Mohammad and Balakrishnan, Hari , title =. Proceedings of the ACM Conference on AI and Agentic Systems , pages =. 2026 , isbn =. doi:10.1145/3786335.3813138 , abstract =
-
[32]
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery , author=. arXiv preprint arXiv:2604.01658 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution , author=. arXiv preprint arXiv:2509.19349 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
2026 , eprint=
Meta-Harness: End-to-End Optimization of Model Harnesses , author=. 2026 , eprint=
2026
-
[35]
2024 , eprint=
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling , author=. 2024 , eprint=
2024
-
[36]
2024 , eprint=
Are More LLM Calls All You Need? Towards Scaling Laws of Compound Inference Systems , author=. 2024 , eprint=
2024
-
[37]
2026 , eprint=
Agentic Systems as Boosting Weak Reasoning Models , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.