The Ghost Annotator: a Framework to Explore Human Label Variation in Content Moderation through Conformal Prediction
Pith reviewed 2026-06-28 14:13 UTC · model grok-4.3
The pith
The Ghost Annotator framework shows larger LLMs grow more confident on texts that diverge from every human annotator while revealing demographic misalignments in content moderation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining non-conformity scores from conformal prediction with cosine similarities on collaborative filtering embeddings of annotators, the Ghost Annotator representation quantifies model predictions that diverge from all human labels and demonstrates that larger models exhibit higher confidence on such predictions, that uncertainty scales with annotator disagreement across models, and that demographic misalignment patterns remain consistent across evaluated LLMs and datasets.
What carries the argument
The Ghost Annotator representation, which uses non-conformity scores and cosine similarity on annotator embeddings from collaborative filtering to isolate and compare model outputs that match no human annotation.
If this is right
- Larger models display distinct confidence behavior on fully divergent predictions compared with smaller models.
- Uncertainty in LLM outputs rises in line with measured human annotator disagreement.
- Sociodemographic axes can be used to map systematic differences between model behavior and groups of human annotators.
- The observed demographic misalignment points to patterns that pretraining data may have embedded.
Where Pith is reading between the lines
- The same non-conformity approach could be tested on annotation tasks outside content moderation to check whether similar size-dependent confidence patterns appear.
- If the misalignment traces to pretraining, targeted data curation during pretraining might alter the observed demographic divergence.
- The framework supplies a practical way to flag individual predictions that warrant extra human review in deployed moderation systems.
Load-bearing premise
That non-conformity scores and cosine similarities computed on the chosen collaborative filtering embeddings accurately reflect genuine differences between model and human labeling behavior rather than depending on the specific embedding or normalization choices.
What would settle it
Recomputing the demographic misalignment patterns after swapping the embedding model or the normalization step in the collaborative filtering stage and checking whether the consistent divergence pattern disappears.
Figures
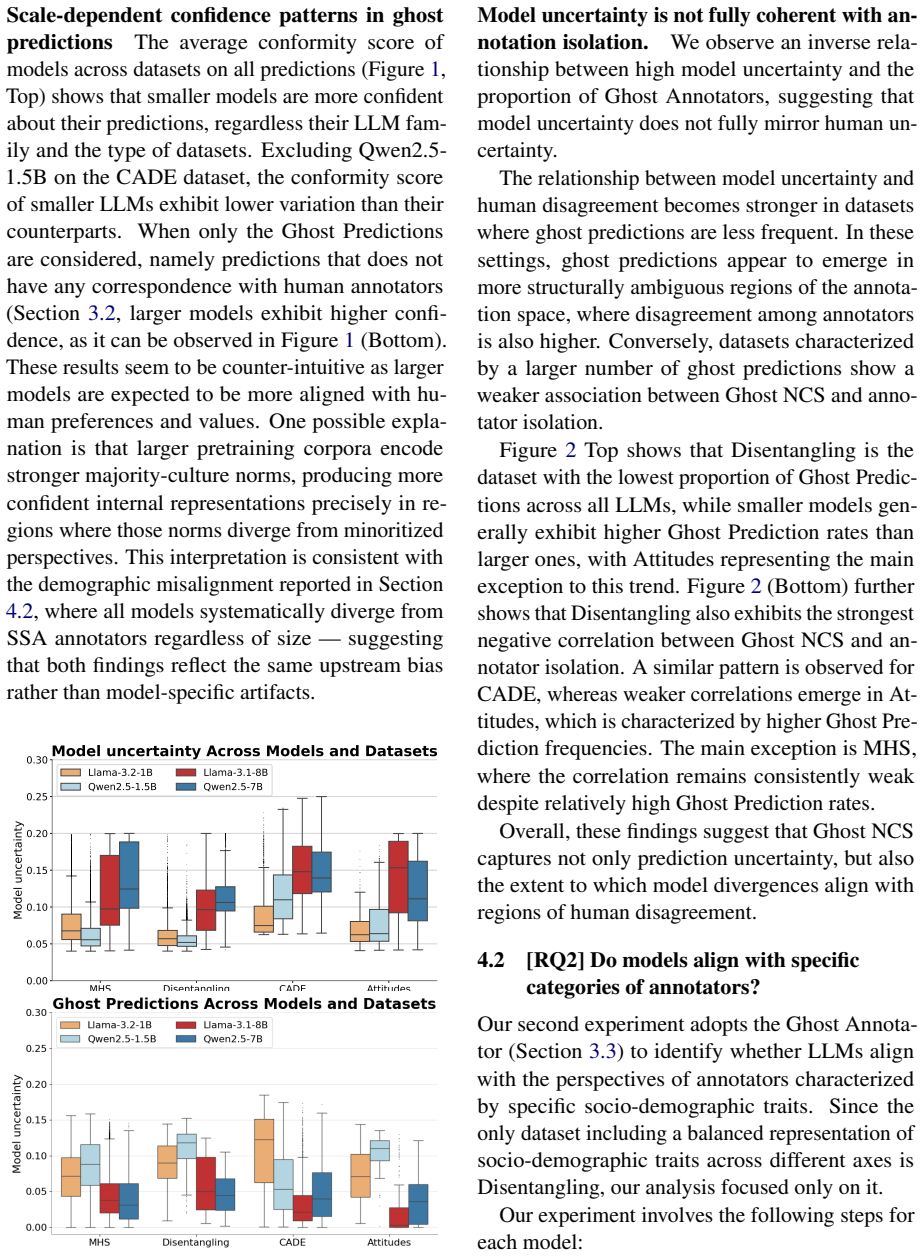

read the original abstract
Current research primarily focuses on model performance, while comparatively less attention has been devoted to uncertainty estimation, particularly in settings where LLMs are increasingly used to generate annotated data. We introduce a framework combining conformal prediction with Collaborative Filtering-style annotators' representation to model LLM behavior in relation to human annotators and to analyze patterns of agreement and disagreement. Using Non-Conformity Scores, we introduce the Ghost Prediction metric and the Ghost Annotator representation to quantify cases in which model predictions diverge from all available human annotations. We compute cosine similarity measures to explore differences in model behavior across sociodemographic axes. We evaluated four LLMs of different size and families across four content moderation datasets. Our finding shows that while we find that all models uncertainty increases with annotator disagreement, larger models tend to be more confident in the classification of texts that are not aligned with any human annotation. Finally, the Ghost Annotator framework reveals a consistent and robust pattern of demographic misalignment, suggesting a structural bias likely rooted in pretraining corpora.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Ghost Annotator framework combining conformal prediction with collaborative filtering-style annotator representations to model how LLMs relate to human annotators in content moderation. It defines the Ghost Prediction metric and Ghost Annotator representation via non-conformity scores to identify model predictions that diverge from all human annotations, then applies cosine similarity on these representations to examine sociodemographic patterns. Experiments across four LLMs and four datasets report that model uncertainty rises with annotator disagreement, larger models show higher confidence on texts unaligned with any human label, and a consistent demographic misalignment pattern emerges, interpreted as structural bias likely rooted in pretraining corpora.
Significance. If the non-conformity scores and cosine similarities on collaborative-filtering embeddings can be shown to validly capture genuine sociodemographic divergence (rather than modeling artifacts), the framework would offer a new quantitative lens for diagnosing biases in LLM annotation pipelines, particularly relevant for content moderation where label variation is high. The combination of conformal prediction for uncertainty and collaborative filtering for annotator modeling is a methodological strength not commonly seen in this literature.
major comments (2)
- [Abstract] Abstract: the claim of a 'consistent and robust pattern of demographic misalignment' across four LLMs and four datasets is presented without any reported ablations, random-embedding baselines, shuffled-label controls, or sensitivity analyses on the non-conformity score definition, embedding choice, or normalization. This leaves open whether the cosine-similarity patterns reflect true annotator divergence or are artifacts of the chosen representations.
- [Abstract] Abstract (final sentence): the attribution of the observed misalignment to 'structural bias likely rooted in pretraining corpora' is an interpretive leap unsupported by direct evidence such as controlled comparisons across models with differing pretraining data or corpus-level analyses; no such tests are described.
minor comments (1)
- [Abstract] Abstract: the Ghost Prediction metric and Ghost Annotator representation are introduced by name but their precise definitions (how non-conformity scores are aggregated into the representation and how cosine similarity is computed) are not stated, hindering immediate assessment of the method.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments below and will incorporate revisions to strengthen the presentation of results and temper interpretive claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'consistent and robust pattern of demographic misalignment' across four LLMs and four datasets is presented without any reported ablations, random-embedding baselines, shuffled-label controls, or sensitivity analyses on the non-conformity score definition, embedding choice, or normalization. This leaves open whether the cosine-similarity patterns reflect true annotator divergence or are artifacts of the chosen representations.
Authors: We agree that the absence of explicit controls leaves the claim vulnerable to the concern that patterns may be representational artifacts. In the revised manuscript we will add (i) random-embedding baselines, (ii) shuffled-label controls, and (iii) sensitivity analyses varying the non-conformity score definition, embedding choice, and normalization. These results will be reported in a new subsection and the abstract will be updated to reference the controls that support the observed consistency across the four models and four datasets. revision: yes
-
Referee: [Abstract] Abstract (final sentence): the attribution of the observed misalignment to 'structural bias likely rooted in pretraining corpora' is an interpretive leap unsupported by direct evidence such as controlled comparisons across models with differing pretraining data or corpus-level analyses; no such tests are described.
Authors: We accept that the current wording presents an unsupported causal attribution. We will revise the abstract's final sentence to frame the pattern as a hypothesis consistent with the multi-model, multi-dataset results rather than a direct conclusion. The discussion section will be expanded to list alternative explanations (architecture, fine-tuning data, annotation interface effects) and to state explicitly that controlled pretraining-corpus comparisons lie outside the scope of the present study. revision: yes
Circularity Check
No circularity; new metrics applied empirically to data without reduction to inputs
full rationale
The provided abstract introduces the Ghost Prediction metric and Ghost Annotator representation via Non-Conformity Scores and collaborative filtering representations to quantify divergence, then applies cosine similarity to observe patterns across LLMs and datasets. No equations, self-citations, or derivations are quoted that reduce any claimed result (such as demographic misalignment) to a fitted parameter or definition by construction. The findings are presented as empirical outcomes from applying the framework, rendering the chain self-contained with independent content from the data evaluations.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Ghost Annotator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2021 , isbn =. doi:10.1145/3442188.3445922 , abstract =
-
[3]
Publications Manual , year = "1983", publisher =
1983
-
[4]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[5]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[6]
Dan Gusfield , title =. 1997
1997
-
[7]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[8]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[9]
Recommender Systems: Techniques, Applications, and Challenges , booktitle =
Francesco Ricci and Lior Rokach and Bracha Shapira , editor =. Recommender Systems: Techniques, Applications, and Challenges , booktitle =. 2022 , url =. doi:10.1007/978-1-0716-2197-4\_1 , timestamp =
-
[10]
Burke and Alexander Felfernig and Mehmet H
Robin D. Burke and Alexander Felfernig and Mehmet H. G. Recommender Systems: An Overview , journal =. 2011 , url =. doi:10.1609/AIMAG.V32I3.2361 , timestamp =
-
[11]
Ben and Frankowski, Dan and Herlocker, Jon and Sen, Shilad
Schafer, J. Ben and Frankowski, Dan and Herlocker, Jon and Sen, Shilad. Collaborative Filtering Recommender Systems. The Adaptive Web: Methods and Strategies of Web Personalization. 2007. doi:10.1007/978-3-540-72079-9_9
-
[12]
Maes, Pattie , title =. 1994 , issue_date =. doi:10.1145/176789.176792 , journal =
-
[13]
Goldberg, David and Nichols, David and Oki, Brian M. and Terry, Douglas , title =. 1992 , issue_date =. doi:10.1145/138859.138867 , journal =
-
[14]
and Ning, Xia and Desrosiers, Christian and Karypis, George
Nikolakopoulos, Athanasios N. and Ning, Xia and Desrosiers, Christian and Karypis, George. Trust Your Neighbors: A Comprehensive Survey of Neighborhood-Based Methods for Recommender Systems. Recommender Systems Handbook. 2022. doi:10.1007/978-1-0716-2197-4_2
-
[15]
Pradipto Chowdhury and Bam Bahadur Sinha , keywords =. Evaluating the Effectiveness of Collaborative Filtering Similarity Measures: A Comprehensive Review , journal =. 2024 , note =. doi:https://doi.org/10.1016/j.procs.2024.04.249 , url =
-
[16]
Sarwar, Badrul and Karypis, George and Konstan, Joseph and Riedl, John , title =. 2001 , isbn =. doi:10.1145/371920.372071 , booktitle =
-
[17]
A Survey of Similarity Measures for Collaborative Filtering-Based Recommender System
Jain, Gourav and Mahara, Tripti and Tripathi, Kuldeep Narayan. A Survey of Similarity Measures for Collaborative Filtering-Based Recommender System. Soft Computing: Theories and Applications. 2020
2020
-
[18]
Fethi Fkih , keywords =. Similarity measures for Collaborative Filtering-based Recommender Systems: Review and experimental comparison , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.jksuci.2021.09.014 , url =
-
[19]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Mind the Uncertainty in Human Disagreement: Evaluating Discrepancies Between Model Predictions and Human Responses in VQA , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2025 , month=. doi:10.1609/aaai.v39i4.32468 , abstractNote=
-
[20]
Frontiers in Artificial Intelligence and Applications , volume=
Llm-generated word association norms , author=. Frontiers in Artificial Intelligence and Applications , volume=. 2024 , publisher=
2024
-
[21]
Language Resources and Evaluation , volume=
Perspectivist approaches to natural language processing: a survey , author=. Language Resources and Evaluation , volume=. 2025 , publisher=
2025
-
[22]
, author=
Capturing human perspectives in NLP: Questionnaires, annotations, and biases. , author=. NLPerspectives@ ECAI , year=
-
[23]
Guillermo Villate-Castillo and Javier. A collaborative content moderation framework for toxicity detection based on multitask neural networks and conformal estimates of annotation disagreement , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.neucom.2025.130542 , url =
-
[24]
Reliably Filter Drug-Induced Liver Injury Literature With Natural Language Processing and Conformal Prediction , year=
Zhan, Xianghao and Wang, Fanjin and Gevaert, Olivier , journal=. Reliably Filter Drug-Induced Liver Injury Literature With Natural Language Processing and Conformal Prediction , year=
-
[25]
arXiv preprint arXiv:2309.07332 , year=
Reliability-based cleaning of noisy training labels with inductive conformal prediction in multi-modal biomedical data mining , author=. arXiv preprint arXiv:2309.07332 , year=
-
[26]
Harvard Data Science Review , volume=
With malice toward none: Assessing uncertainty via equalized coverage , author=. Harvard Data Science Review , volume=. 2020 , publisher=
2020
-
[27]
Transactions of the Association for Computational Linguistics , volume=
Conformal prediction for natural language processing: A survey , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[28]
From Noise to Nuance: Enriching Subjective Data Annotation through Qualitative Analysis
Wan, Ruyuan and Wang, Haonan and Huang, Ting-Hao Kenneth and Gao, Jie. From Noise to Nuance: Enriching Subjective Data Annotation through Qualitative Analysis. Proceedings of the Fourth Workshop on Bridging Human-Computer Interaction and Natural Language Processing (HCI+NLP). 2025. doi:10.18653/v1/2025.hcinlp-1.20
-
[29]
URL https: //aclanthology.org/2025.acl-long.336/
Jiang, Liwei and Sorensen, Taylor and Levine, Sydney and Choi, Yejin. Can Language Models Reason about Individualistic Human Values and Preferences?. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.336
-
[30]
From Word to World: Evaluate and Mitigate Culture Bias in LLM s via Word Association Test
Dai, Xunlian and Zhou, Li and Wang, Benyou and Li, Haizhou. From Word to World: Evaluate and Mitigate Culture Bias in LLM s via Word Association Test. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1246
-
[31]
Are you sure? Measuring models bias in content moderation through uncertainty
Urbinati, Alessandra and Lai, Mirko and Frenda, Simona and Stranisci, Marco. Are you sure? Measuring models bias in content moderation through uncertainty. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.980
-
[32]
Proceedings of the 40th International Conference on Machine Learning , pages =
Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[33]
Calderon, Nitay and Reichart, Roi and Dror, Rotem. The Alternative Annotator Test for LLM -as-a-Judge: How to Statistically Justify Replacing Human Annotators with LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.782
-
[34]
arXiv preprint arXiv:2412.05579 , year=
Llms-as-judges: a comprehensive survey on llm-based evaluation methods , author=. arXiv preprint arXiv:2412.05579 , year=
-
[35]
Revisiting Active Learning under (Human) Label Variation
Gruber, Cornelia and Alber, Helen and Bischl, Bernd and Kauermann, G. Revisiting Active Learning under (Human) Label Variation. Proceedings of the The 4th Workshop on Perspectivist Approaches to NLP. 2025. doi:10.18653/v1/2025.nlperspectives-1.7
-
[36]
Can unconfident llm annotations be used for confident conclusions? , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[37]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
Disentangling perceptions of offensiveness: Cultural and moral correlates , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
2024
-
[38]
arXiv preprint arXiv:2106.15896 , year=
Whose opinions matter? perspective-aware models to identify opinions of hate speech victims in abusive language detection , author=. arXiv preprint arXiv:2106.15896 , year=
-
[39]
That is Unacceptable: the Moral Foundations of Canceling
Lo, Soda Marem and Araque, Oscar and Sharma, Rajesh and Stranisci, Marco Antonio. That is Unacceptable: the Moral Foundations of Canceling. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.330
-
[40]
Proceedings of the 2022 conference of the north american chapter of the association for computational linguistics: Human language technologies , pages=
Annotators with attitudes: How annotator beliefs and identities bias toxic language detection , author=. Proceedings of the 2022 conference of the north american chapter of the association for computational linguistics: Human language technologies , pages=
2022
-
[41]
Language and linguistics compass , volume=
Five sources of bias in natural language processing , author=. Language and linguistics compass , volume=. 2021 , publisher=
2021
-
[42]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Agreeing to Disagree: Annotating Offensive Language Datasets with Annotators’ Disagreement , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=. 2021 , organization=
2021
-
[43]
Foundations and trends
Conformal prediction: A gentle introduction , author=. Foundations and trends. 2023 , publisher=
2023
-
[44]
Bernoulli , volume=
Conformal prediction: a unified review of theory and new challenges , author=. Bernoulli , volume=. 2023 , publisher=
2023
-
[45]
Journal of clinical epidemiology , volume=
Use of Brier score to assess binary predictions , author=. Journal of clinical epidemiology , volume=. 2010 , publisher=
2010
-
[46]
Transactions of the Association for Computational Linguistics , year=
Conformal Prediction for Natural Language Processing: A Survey , author=. Transactions of the Association for Computational Linguistics , year=
-
[47]
Journal of Machine Learning Research , author =
A Tutorial on Conformal Prediction , year =. Journal of Machine Learning Research , author =
-
[48]
Tools in Artificial Intelligence , publisher =
Harris Papadopoulos , title =. Tools in Artificial Intelligence , publisher =. 2008 , editor =. doi:10.5772/6078 , url =
-
[49]
Transactions of the Association for Computational Linguistics , volume=
Conformalizing machine translation evaluation , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[50]
Investigating Annotator Bias in Abusive Language Datasets
Wich, Maximilian and Widmer, Christian and Hagerer, Gerhard and Groh, Georg. Investigating Annotator Bias in Abusive Language Datasets. 2021
2021
-
[51]
The ``problem'' of human label variation: On ground truth in data, modeling and evaluation
Plank, Barbara. The Problem of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation. 2022. doi:10.18653/v1/2022.emnlp-main.731
-
[52]
Don`t Blame the Data, Blame the Model: Understanding Noise and Bias When Learning from Subjective Annotations
Anand, Abhishek and Mokhberian, Negar and Kumar, Prathyusha and Saha, Anweasha and He, Zihao and Rao, Ashwin and Morstatter, Fred and Lerman, Kristina. Don`t Blame the Data, Blame the Model: Understanding Noise and Bias When Learning from Subjective Annotations. 2024
2024
-
[53]
The Measuring Hate Speech Corpus: Leveraging Rasch Measurement Theory for Data Perspectivism
Sachdeva, Pratik and Barreto, Renata and Bacon, Geoff and Sahn, Alexander and von Vacano, Claudia and Kennedy, Chris. The Measuring Hate Speech Corpus: Leveraging Rasch Measurement Theory for Data Perspectivism. 2022
2022
-
[54]
Large Language Models for Data Annotation and Synthesis: A Survey
Tan, Zhen and Li, Dawei and Wang, Song and Beigi, Alimohammad and Jiang, Bohan and Bhattacharjee, Amrita and Karami, Mansooreh and Li, Jundong and Cheng, Lu and Liu, Huan. Large Language Models for Data Annotation and Synthesis: A Survey. 2024. doi:10.18653/v1/2024.emnlp-main.54
-
[55]
and Pastells, Pol and Frenda, Simona and Taule, Mariona
Schmeisser-Nieto, Wolfgang S. and Pastells, Pol and Frenda, Simona and Taule, Mariona. Human vs. Machine Perceptions on Immigration Stereotypes. 2024
2024
-
[56]
Wang, Xinpeng and Plank, Barbara. ACTOR : Active Learning with Annotator-specific Classification Heads to Embrace Human Label Variation. 2023. doi:10.18653/v1/2023.emnlp-main.126
-
[57]
Which Examples Should be Multiply Annotated? Active Learning When Annotators May Disagree
Baumler, Connor and Sotnikova, Anna and Daum \'e III, Hal. Which Examples Should be Multiply Annotated? Active Learning When Annotators May Disagree. 2023. doi:10.18653/v1/2023.findings-acl.658
-
[58]
van der Meer, Michiel and Falk, Neele and Murukannaiah, Pradeep K. and Liscio, Enrico. Annotator-Centric Active Learning for Subjective NLP Tasks. 2024. doi:10.18653/v1/2024.emnlp-main.1031
-
[59]
The Effectiveness of LLM s as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
Pavlovic, Maja and Poesio, Massimo. The Effectiveness of LLM s as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation. 2024
2024
-
[60]
Why Don`t You Do It Right? Analysing Annotators' Disagreement in Subjective Tasks
Sandri, Marta and Leonardelli, Elisa and Tonelli, Sara and Jezek, Elisabetta. Why Don`t You Do It Right? Analysing Annotators' Disagreement in Subjective Tasks. 2023. doi:10.18653/v1/2023.eacl-main.178
-
[61]
Annotators with Attitudes: How Annotator Beliefs And Identities Bias Toxic Language Detection
Sap, Maarten and Swayamdipta, Swabha and Vianna, Laura and Zhou, Xuhui and Choi, Yejin and Smith, Noah A. Annotators with Attitudes: How Annotator Beliefs And Identities Bias Toxic Language Detection. 2022. doi:10.18653/v1/2022.naacl-main.431
-
[62]
Mostafazadeh Davani, Aida and Diaz, Mark and Baker, Dylan K and Prabhakaran, Vinodkumar. D 3 CODE : Disentangling Disagreements in Data across Cultures on Offensiveness Detection and Evaluation. 2024. doi:10.18653/v1/2024.emnlp-main.1029
-
[63]
LLM Tropes: Revealing Fine-Grained Values and Opinions in Large Language Models
Wright, Dustin and Arora, Arnav and Borenstein, Nadav and Yadav, Srishti and Belongie, Serge and Augenstein, Isabelle. LLM Tropes: Revealing Fine-Grained Values and Opinions in Large Language Models. 2024. doi:10.18653/v1/2024.findings-emnlp.995
-
[64]
N orm A d: A Framework for Measuring the Cultural Adaptability of Large Language Models
Rao, Abhinav Sukumar and Yerukola, Akhila and Shah, Vishwa and Reinecke, Katharina and Sap, Maarten. N orm A d: A Framework for Measuring the Cultural Adaptability of Large Language Models. 2025
2025
-
[65]
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations
Mostafazadeh Davani, Aida and D \'i az, Mark and Prabhakaran, Vinodkumar. Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00449
-
[66]
Capturing Perspectives of Crowdsourced Annotators in Subjective Learning Tasks
Mokhberian, Negar and Marmarelis, Myrl and Hopp, Frederic and Basile, Valerio and Morstatter, Fred and Lerman, Kristina. Capturing Perspectives of Crowdsourced Annotators in Subjective Learning Tasks. 2024. doi:10.18653/v1/2024.naacl-long.407
-
[67]
Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus
Dodge, Jesse and Sap, Maarten and Marasovi \'c , Ana and Agnew, William and Ilharco, Gabriel and Groeneveld, Dirk and Mitchell, Margaret and Gardner, Matt. Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus. 2021. doi:10.18653/v1/2021.emnlp-main.98
-
[68]
Voices in a Crowd: Searching for clusters of unique perspectives
Vitsakis, Nikolas and Parekh, Amit and Konstas, Ioannis. Voices in a Crowd: Searching for clusters of unique perspectives. 2024. doi:10.18653/v1/2024.emnlp-main.696
-
[69]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
What are they filtering out? an experimental benchmark of filtering strategies for harm reduction in pretraining datasets , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[70]
What’s in the box? an analysis of undesirable content in the Common Crawl corpus , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) , pages=
-
[71]
arXiv preprint arXiv:2502.12601 , year=
Copu: Conformal prediction for uncertainty quantification in natural language generation , author=. arXiv preprint arXiv:2502.12601 , year=
-
[72]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Annotator-Centric Active Learning for Subjective NLP Tasks , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[73]
Analyzing Uncertainty of LLM -as-a-Judge: Interval Evaluations with Conformal Prediction
Sheng, Huanxin and Liu, Xinyi and He, Hangfeng and Zhao, Jieyu and Kang, Jian. Analyzing Uncertainty of LLM -as-a-Judge: Interval Evaluations with Conformal Prediction. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.569
-
[74]
Leonardelli, Elisa and Casola, Silvia and Peng, Siyao and Rizzi, Giulia and Basile, Valerio and Fersini, Elisabetta and Frassinelli, Diego and Jang, Hyewon and Pavlovic, Maja and Plank, Barbara and Poesio, Massimo. L e W i D i-2025 at NLP erspectives: The Third Edition of the Learning with Disagreements Shared Task. Proceedings of the The 4th Workshop on ...
-
[75]
URL https: //aclanthology.org/2025.acl-long.104/
Orlikowski, Matthias and Pei, Jiaxin and R. Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.104
-
[76]
Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems , pages=
Jury learning: Integrating dissenting voices into machine learning models , author=. Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems , pages=
2022
-
[77]
PERSEVAL : A Framework for Perspectivist Classification Evaluation
Lo, Soda Marem and Casola, Silvia and Sezerer, Erhan and Basile, Valerio and Sansonetti, Franco and Uva, Antonio and Bernardi, Davide. PERSEVAL : A Framework for Perspectivist Classification Evaluation. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1137
-
[78]
and Welch, Charles and Braun, Daniel and Schl
Sarumi, Olufunke O. and Welch, Charles and Braun, Daniel and Schl. The Impact of Annotator Personas on LLM Behavior Across the Perspectivism Spectrum. Proceedings of the 8th International Conference on Natural Language and Speech Processing (ICNLSP-2025). 2025
2025
-
[79]
Proceedings of Algorithmic Fairness through the lens of Metrics and Evaluation Workshop , year=
Understanding The Effect Of Temperature On Alignment With Human Opinions , author=. Proceedings of Algorithmic Fairness through the lens of Metrics and Evaluation Workshop , year=
-
[80]
Learning Personal Human Biases and Representations for Subjective Tasks in Natural Language Processing , year=
Kocoń, Jan and Gruza, Marcin and Bielaniewicz, Julita and Grimling, Damian and Kanclerz, Kamil and Miłkowski, Piotr and Kazienko, Przemysław , booktitle=. Learning Personal Human Biases and Representations for Subjective Tasks in Natural Language Processing , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.