Any2Poster: Any-Source Poster Generation Across Modalities and Domains
Pith reviewed 2026-06-28 14:52 UTC · model grok-4.3
The pith
A single agent generates posters from any input source across modalities and domains using parsing, planning, and visual feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
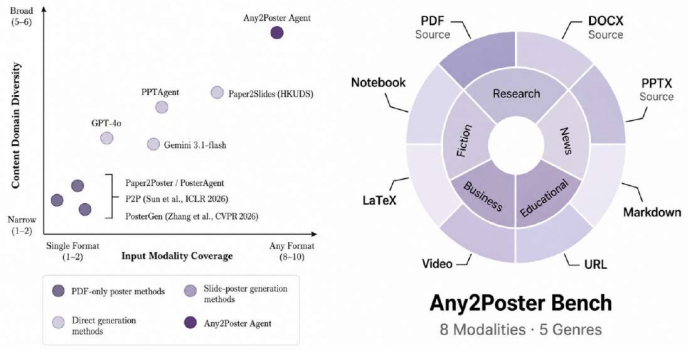
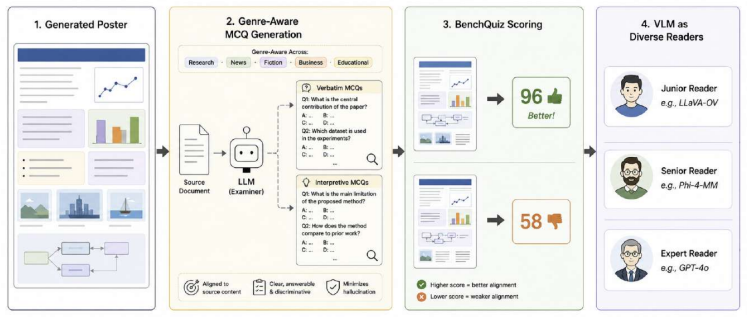
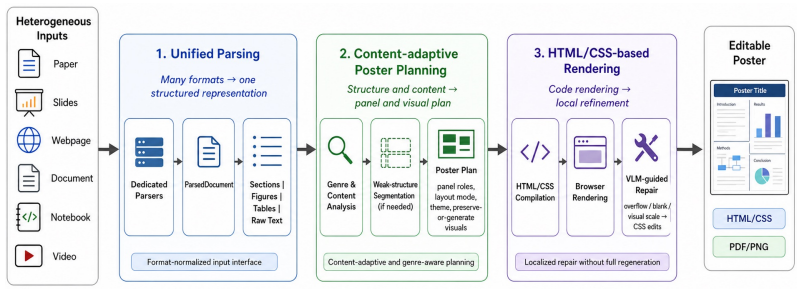
Any2Poster Bench enables reproducible measurement of poster generation from heterogeneous sources by combining quiz probes for information fidelity with VLM assessments of visual communication; Any2Poster Agent demonstrates the feasibility of this approach by automatically handling parsing of diverse inputs, content organization, layout planning, rendering, and refinement, achieving consistent performance across modalities and domains.
What carries the argument
Any2Poster Agent, an end-to-end pipeline that parses heterogeneous sources, organizes salient content, plans layouts, renders posters, and refines them using visual feedback.
If this is right
- Poster generation systems can be evaluated on non-text inputs such as videos and notebooks rather than papers alone.
- Performance can be tracked separately for factual accuracy and for layout or readability quality.
- Iterative visual feedback loops become a standard component in multimodal content creation pipelines.
- Domain-general agents become testable baselines for tasks that require condensing dense information into visual form.
Where Pith is reading between the lines
- The same agent structure could extend to generating other condensed visual formats such as infographics or slide decks from mixed sources.
- Quiz-based evaluation could transfer to measuring retention from other AI-generated summaries or diagrams.
- If the refinement step scales, it suggests a general pattern for agents that improve outputs through self-critique on visual tasks.
Load-bearing premise
VLM judgments of visual quality together with quiz probes provide a valid measure of information fidelity and visual communication quality.
What would settle it
A controlled human study in which viewers answer the benchmark quiz questions after seeing only the generated poster, compared against answers from the original source.
Figures

read the original abstract
Visual posters are a compact medium for communicating dense information, yet progress on automatic poster generation remains difficult to measure because existing evaluations are often restricted to paper-only inputs, narrow domains, or surface-level visual similarity. We introduce Any2Poster Bench, a benchmark for any-source poster generation that evaluates systems across eight input modalities--PDFs, URLs, PPTX, DOCX, Markdown, LaTeX, notebooks, and videos--and five content domains. Any2Poster Bench pairs each source with quiz-based probes of verbatim factual retention and interpretive understanding, together with VLM-based judgments of visual quality, layout, readability, content completeness, and logical flow, enabling reproducible assessment of both information fidelity and visual communication. To instantiate and validate this benchmark, we further present Any2Poster Agent, an end-to-end reference agent that parses heterogeneous sources, organizes salient content, plans poster layouts, renders posters, and iteratively refines them using visual feedback. On Any2Poster Bench, Any2Poster Agent achieves 87.25% average accuracy across input modalities and 87.28% across content domains. On PaperQuiz-style evaluation, where prior paper-to-poster agents are directly comparable, Any2Poster Agent improves over PosterAgent-4o from 51.06-51.33% to 72.58% overall accuracy and from 116-121 to 145.16 in density-augmented score. Together, Any2Poster Bench and Any2Poster Agent provide a reusable evaluation resource and a competitive baseline for studying multimodal, domain-general poster generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Any2Poster Bench, a benchmark for any-source poster generation across eight input modalities (PDFs, URLs, PPTX, DOCX, Markdown, LaTeX, notebooks, videos) and five content domains. The benchmark uses quiz-based probes for factual retention and interpretive understanding alongside VLM-based judgments of visual quality, layout, readability, content completeness, and logical flow. It also presents Any2Poster Agent, an end-to-end reference agent for parsing sources, organizing content, planning layouts, rendering, and iterative refinement, reporting 87.25% average accuracy across modalities, 87.28% across domains, and improvements over PosterAgent-4o (51.06-51.33% to 72.58% overall accuracy; 116-121 to 145.16 density-augmented score) on PaperQuiz-style evaluation.
Significance. If the VLM judgments prove reliable, the benchmark and agent would supply a standardized, reproducible resource for multimodal poster generation that addresses gaps in prior paper-only or narrow-domain evaluations, with the reported gains providing a competitive baseline.
major comments (1)
- [§3–4] §3–4 (benchmark construction, as referenced in abstract): The central performance claims (87.25% modality accuracy, 72.58% PaperQuiz accuracy) rest on VLM-based judgments of visual quality/layout/readability/completeness/flow and quiz probes, yet no human correlation, inter-annotator agreement, or ablation linking VLM scores to viewer comprehension/preference is reported. This is load-bearing because the skeptic concern directly questions whether these automated signals validly measure poster effectiveness.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on evaluation validity. We address the concern point-by-point below.
read point-by-point responses
-
Referee: [§3–4] §3–4 (benchmark construction, as referenced in abstract): The central performance claims (87.25% modality accuracy, 72.58% PaperQuiz accuracy) rest on VLM-based judgments of visual quality/layout/readability/completeness/flow and quiz probes, yet no human correlation, inter-annotator agreement, or ablation linking VLM scores to viewer comprehension/preference is reported. This is load-bearing because the skeptic concern directly questions whether these automated signals validly measure poster effectiveness.
Authors: The 87.25% modality and 72.58% PaperQuiz accuracy figures are computed exclusively from the quiz probes, which are manually authored factual and interpretive questions; these provide an objective, human-grounded signal of information retention that does not depend on VLM output. VLM judgments are used only for the separate visual-quality, layout, readability, completeness, and flow dimensions. We acknowledge that the manuscript does not report a new human correlation study or inter-annotator agreement for the VLM component. In revision we will add a dedicated paragraph in §4 discussing VLM reliability, citing prior work on VLM-human alignment for layout and visual tasks, and we will include a small-scale human preference correlation on a held-out subset of posters. revision: yes
Circularity Check
No circularity; benchmark and performance claims are self-contained without reduction to fitted inputs or self-citations.
full rationale
The paper introduces Any2Poster Bench (quiz probes + VLM judgments) and Any2Poster Agent as a reference system, then reports accuracy numbers on that benchmark. No equations, fitted parameters, or derivation steps appear in the provided text. The central claims rest on external evaluation signals (quizzes and VLM rubrics) rather than any quantity that reduces by construction to the agent's own outputs or prior self-citations. Self-citation load-bearing, ansatz smuggling, and renaming patterns are absent. The evaluation methodology is stated explicitly and does not collapse into tautology.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLM-based judgments reliably measure visual quality, layout, readability, content completeness, and logical flow
- domain assumption Quiz-based probes accurately capture verbatim factual retention and interpretive understanding
invented entities (2)
-
Any2Poster Bench
no independent evidence
-
Any2Poster Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Croissant: A metadata format for ml-ready datasets, 2024
Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Luca Foschini, Joan Giner-Miguelez, et al. Croissant: A metadata format for ml-ready datasets, 2024
2024
-
[2]
Lawrence Zitnick, and Devi Parikh
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE International Conference on Computer Vision, 2015
2015
-
[3]
Qwen2.5-VL technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2.5-VL technical report, 2025
2025
-
[4]
Enhancing presentation slide generation by llms with a multi-staged end-to-end approach
Sambaran Bandyopadhyay, Himanshu Maheshwari, Anandhavelu Natarajan, and Apoorv Sax- ena. Enhancing presentation slide generation by llms with a multi-staged end-to-end approach. InProceedings of the 17th International Natural Language Generation Conference, pages 222–229. Association for Computational Linguistics, 2024
2024
-
[5]
Nougat: Neural Optical Understanding for Academic Documents
Lukas Blecher, Guillem Cucurull, Thomas Scialom, and Robert Stojnic. Nougat: Neural optical understanding for academic documents.arXiv preprint arXiv:2308.13418, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
POSTA: A go-to framework for customized artistic poster generation
Haoyu Chen, Xiaojie Xu, Wenbo Li, Jingjing Ren, Tian Ye, Songhua Liu, Ying-Cong Chen, Lei Zhu, and Xinchao Wang. POSTA: A go-to framework for customized artistic poster generation. arXiv preprint arXiv:2503.14908, 2025
-
[7]
Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities, 2025
Gheorghe Comanici et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities, 2025
2025
-
[8]
PAL: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. PAL: Program-aided language models. InProceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[9]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
2021
-
[10]
Paper2Slides: From paper to presentation in one click
HKUDS. Paper2Slides: From paper to presentation in one click. https://github.com/ HKUDS/Paper2Slides, 2025. Software project
2025
-
[11]
Hudson and Christopher D
Drew A. Hudson and Christopher D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6700–6709, 2019
2019
-
[12]
Text2Poster: Laying out stylized texts on retrieved images
Chuhao Jin, Hongteng Xu, Ruihua Song, and Zhiwu Lu. Text2Poster: Laying out stylized texts on retrieved images. InIEEE International Conference on Acoustics, Speech and Signal Processing, pages 4823–4827. IEEE, 2022
2022
-
[13]
WebDraw: A machine learning-driven tool for automatic website prototyping.Science of Computer Programming, 233:103056, 2024
Thisaranie Kaluarachchi and Manjusri Wickramasinghe. WebDraw: A machine learning-driven tool for automatic website prototyping.Science of Computer Programming, 233:103056, 2024
2024
-
[14]
Fengheng Li, An Liu, Wei Feng, Honghe Zhu, Yaoyu Li, Zheng Zhang, Jingjing Lv, Xin Zhu, Junjie Shen, Zhangang Lin, and Jingping Shao. Relation-aware diffusion model for controllable poster layout generation.arXiv preprint arXiv:2306.09086, 2023
-
[15]
Zhaochen Li, Fengheng Li, Wei Feng, Honghe Zhu, Yaoyu Li, Zheng Zhang, Jingjing Lv, Junjie Shen, Zhangang Lin, Jingping Shao, and Zhenglu Yang. Planning and rendering: Towards product poster generation with diffusion models.arXiv preprint arXiv:2312.08822, 2024
-
[16]
Holistic evaluation of language models, 2022
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models, 2022
2022
-
[17]
Jiawei Lin, Jiaqi Guo, Shizhao Sun, Zijiang James Yang, Jian-Guang Lou, and Dongmei Zhang. LayoutPrompter: Awaken the design ability of large language models.arXiv preprint arXiv:2311.06495, 2023. 10
-
[18]
G-Eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: Nlg evaluation using gpt-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, 2023
2023
-
[19]
Nikolaos Livathinos, Christoph Auer, Maksym Lysak, Ahmed Nassar, Michele Dolfi, Panos Vagenas, Cesar Berrospi Ramis, Matteo Omenetti, Kasper Dinkla, Yusik Kim, Shubham Gupta, Rafael Teixeira de Lima, Valery Weber, Lucas Morin, Ingmar Meijer, Viktor Kuropiatnyk, and Peter W. J. Staar. Docling: An efficient open-source toolkit for ai-driven document convers...
-
[20]
OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning
Pan Lu, Bowen Chen, Sheng Liu, Rahul Thapa, Joseph Boen, and James Zou. Octo- Tools: An agentic framework with extensible tools for complex reasoning.arXiv preprint arXiv:2502.11271, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Ui layout generation with llms guided by ui grammar.arXiv preprint arXiv:2310.15455, 2023
Yuwen Lu, Ziang Tong, Qinyi Zhao, Chengzhi Zhang, and Toby Jia-Jun Li. Ui layout generation with llms guided by ui grammar.arXiv preprint arXiv:2310.15455, 2023
-
[22]
Jian Ma, Yonglin Deng, Chen Chen, Nanyang Du, Haonan Lu, and Zhenyu Yang. GlyphDraw2: Automatic generation of complex glyph posters with diffusion models and large language models.arXiv preprint arXiv:2407.02252, 2024
-
[23]
Presentations by the humans and for the humans: Harnessing llms for generating persona-aware slides from documents
Ishani Mondal, Shwetha S, Anandhavelu Natarajan, Aparna Garimella, Sambaran Bandyopad- hyay, and Jordan Boyd-Graber. Presentations by the humans and for the humans: Harnessing llms for generating persona-aware slides from documents. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, pages 2664–26...
2024
-
[24]
GPT-4o system card
OpenAI. GPT-4o system card. https://openai.com/index/gpt-4o-system-card/ , 2024
2024
-
[25]
GPT-5 system card.https://openai.com/index/gpt-5-system-card/, 2025
OpenAI. GPT-5 system card.https://openai.com/index/gpt-5-system-card/, 2025
2025
-
[26]
Paper2Poster: Towards multimodal poster automation from scientific papers, 2025
Wei Pang, Kevin Qinghong Lin, Xiangru Jian, Xi He, and Philip Torr. Paper2Poster: Towards multimodal poster automation from scientific papers, 2025
2025
-
[27]
ART: Automatic multi-step reasoning and tool-use for large language models
Bhargavi Paranjape, Scott Lundberg, Sameer Singh, Hannaneh Hajishirzi, Luke Zettlemoyer, and Marco Tulio Ribeiro. ART: Automatic multi-step reasoning and tool-use for large language models.arXiv preprint arXiv:2303.09014, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
marker: Convert pdf to markdown and json quickly with high accuracy
Vik Paruchuri. marker: Convert pdf to markdown and json quickly with high accuracy. https: //github.com/VikParuchuri/marker, 2025. Software project
2025
-
[29]
Nassar, and Peter W
Birgit Pfitzmann, Christoph Auer, Michele Dolfi, Ahmed S. Nassar, and Peter W. J. Staar. DocLayNet: A large human-annotated dataset for document-layout analysis. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3743–3751, 2022
2022
-
[30]
Data cards: Purposeful and trans- parent dataset documentation for responsible ai
Mahima Pushkarna, Andrew Zaldivar, and Oddur Kjartansson. Data cards: Purposeful and trans- parent dataset documentation for responsible ai. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 1776–1826, 2022
2022
-
[31]
Learning to generate posters of scientific papers by probabilistic graphical models, 2017
Yu-ting Qiang, Yanwei Fu, Xiao Yu, Yanwen Guo, Zhi-Hua Zhou, and Leonid Sigal. Learning to generate posters of scientific papers by probabilistic graphical models, 2017
2017
-
[32]
Rodriguez, Xiangru Jian, Siba Smarak Panigrahi, Tianyu Zhang, Aarash Feizi, Abhay Puri, Akshay Kalkunte Suresh, François Savard, Ahmed Masry, Shravan Nayak, et al
Juan A. Rodriguez, Xiangru Jian, Siba Smarak Panigrahi, Tianyu Zhang, Aarash Feizi, Abhay Puri, Akshay Kalkunte Suresh, François Savard, Ahmed Masry, Shravan Nayak, et al. BigDocs: An open dataset for training multimodal models on document and code tasks. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[33]
Rohit Saxena, Pasquale Minervini, and Frank Keller. PosterSum: A multimodal benchmark for scientific poster summarization.arXiv preprint arXiv:2502.17540, 2025
-
[34]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.arXiv preprint arXiv:2302.04761, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
SlideGen: An abstractive section-based slide generator for scholarly documents
Athar Sefid, Prasenjit Mitra, and Lee Giles. SlideGen: An abstractive section-based slide generator for scholarly documents. InProceedings of the 21st ACM Symposium on Document Engineering. Association for Computing Machinery, 2021
2021
-
[36]
De- sign2Code: Benchmarking multimodal code generation for automated front-end engineering
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. De- sign2Code: Benchmarking multimodal code generation for automated front-end engineering. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3956–3974. Association fo...
2025
-
[37]
Edward Sun, Yufang Hou, Dakuo Wang, Yunfeng Zhang, and Nancy X. R. Wang. D2S: Document-to-slide generation via query-based text summarization. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1405–1418. Association for Computational Linguistics, 2021
2021
-
[38]
P2P: Automated paper-to-poster generation and fine-grained benchmark, 2025
Tao Sun, Enhao Pan, Zhengkai Yang, Kaixin Sui, Jiajun Shi, Xianfu Cheng, Tongliang Li, Wenhao Huang, Ge Zhang, Jian Yang, and Zhoujun Li. P2P: Automated paper-to-poster generation and fine-grained benchmark, 2025
2025
-
[39]
PosterBot: A system for generating posters of scientific papers with neural models
Sheng Xu and Xiaojun Wan. PosterBot: A system for generating posters of scientific papers with neural models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 13233–13235, 2022
2022
-
[40]
Tao Yang, Yingmin Luo, Zhongang Qi, Yang Wu, Ying Shan, and Chang Wen Chen. Poster- LLaV A: Constructing a unified multi-modal layout generator with llm.arXiv preprint arXiv:2406.02884, 2024
-
[41]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[42]
PosterGen: Aesthetic-aware paper-to-poster generation via multi-agent llms, 2025
Zhilin Zhang, Xiang Zhang, Jiaqi Wei, Yiwei Xu, and Chenyu You. PosterGen: Aesthetic-aware paper-to-poster generation via multi-agent llms, 2025
2025
-
[43]
Hao Zheng, Xinyan Guan, Hao Kong, Jia Zheng, Weixiang Zhou, Hongyu Lin, Yaojie Lu, Ben He, Xianpei Han, and Le Sun. PPTAgent: Generating and evaluating presentations beyond text-to-slides.arXiv preprint arXiv:2501.03936, 2025
-
[44]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023
2023
-
[45]
issues": [
Xu Zhong, Jianbin Tang, and Antonio Jimeno Yepes. PubLayNet: Largest dataset ever for document layout analysis. In2019 International Conference on Document Analysis and Recognition, pages 1015–1022, 2019. 12 Appendix Contents ADataset Details .....................................................................................................................
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.