Fast Unlearning at Scale via Margin Self-Correction
Pith reviewed 2026-06-28 15:19 UTC · model grok-4.3
The pith
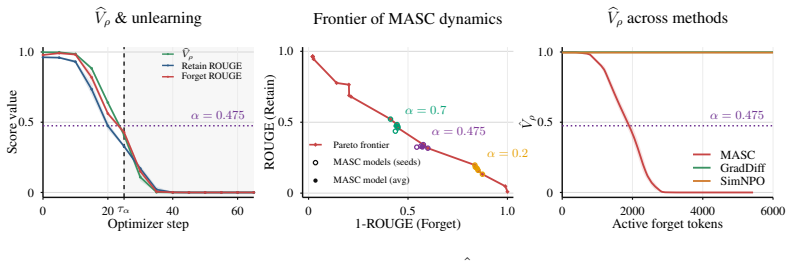
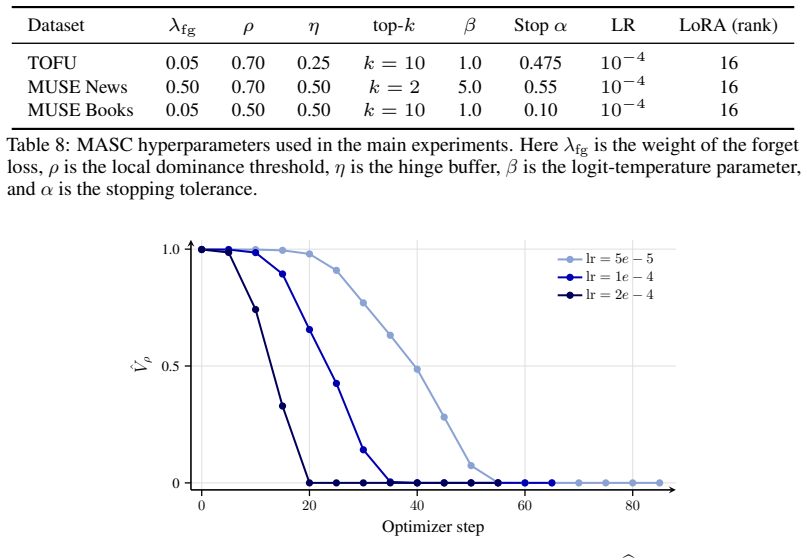
MASC reduces logit gaps on forget sequences until an average threshold is met, providing an online stop for unlearning without downstream checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a text sequence to be forgotten, MASC actively reduces the logit gap between the original next token and the most likely alternatives. It outputs a final model once this gap is small on average over a sufficiently large proportion of token positions across all forget sequences.
What carries the argument
MArgin Self-Correction (MASC), an online stopping rule based on shrinking the average logit gap over forget-sequence token positions.
If this is right
- Unlearning runs can end without storing multiple checkpoints or running repeated validation evaluations.
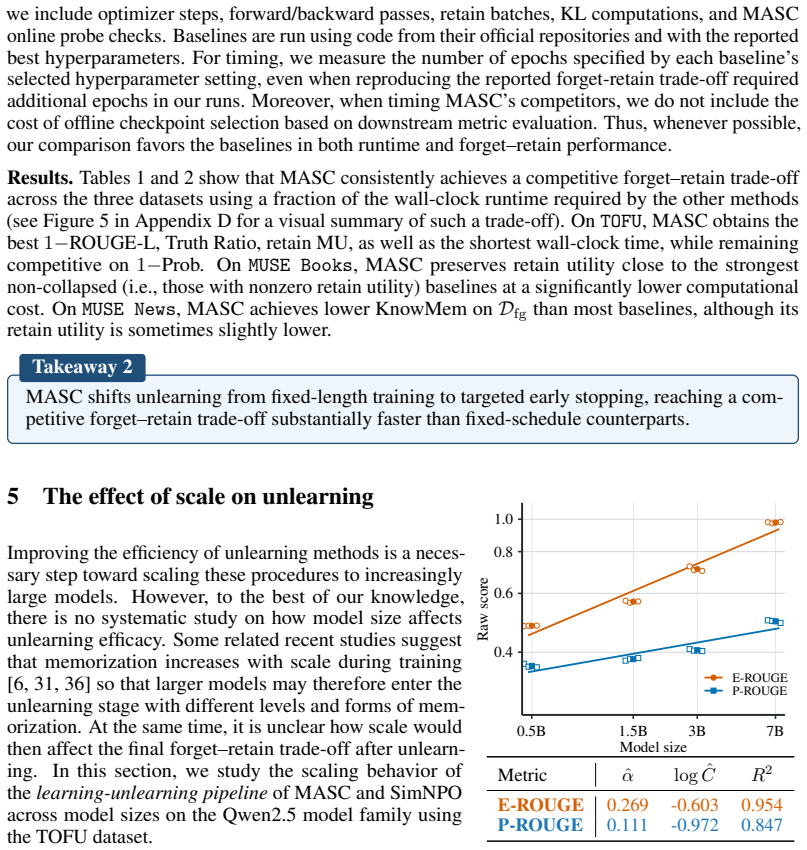
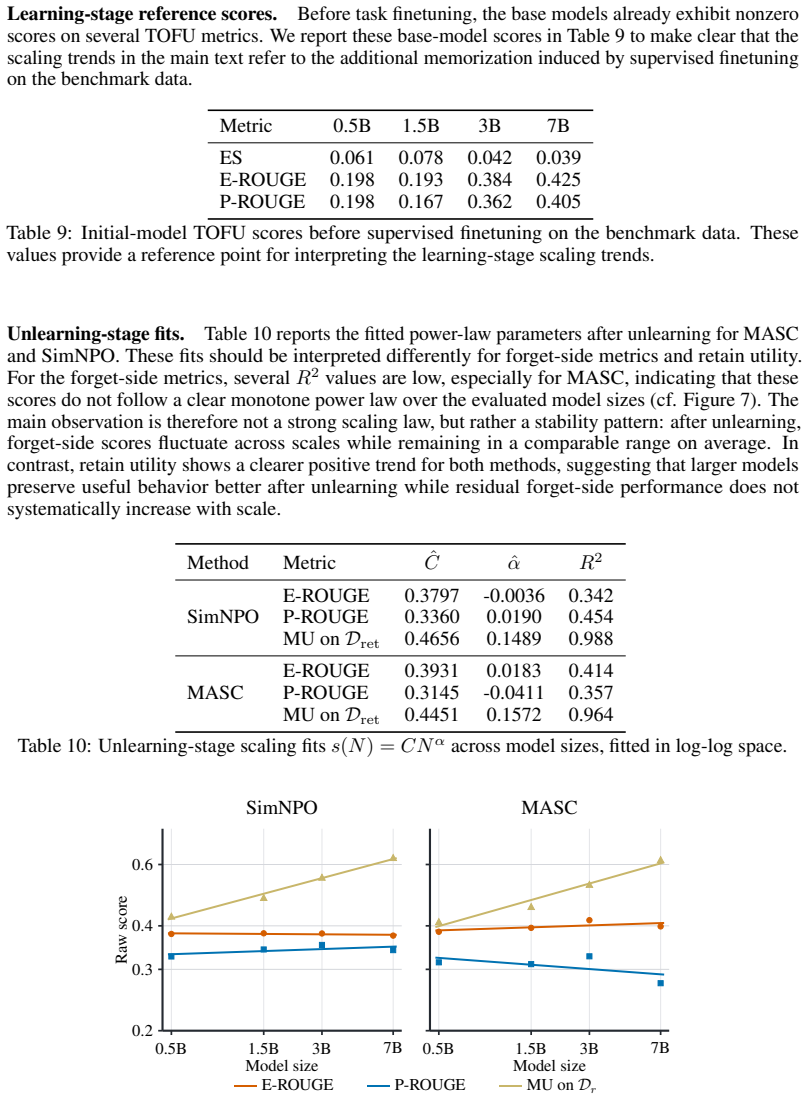
- The forget-retain trade-off improves as the number of model parameters increases, with forget metrics holding steady and retain utility rising.
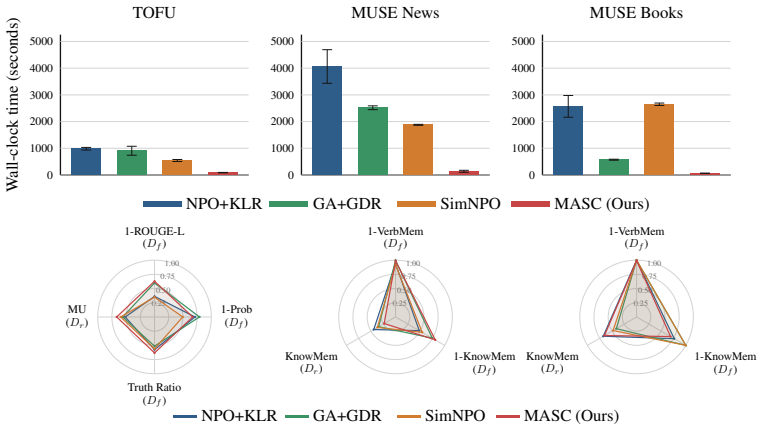
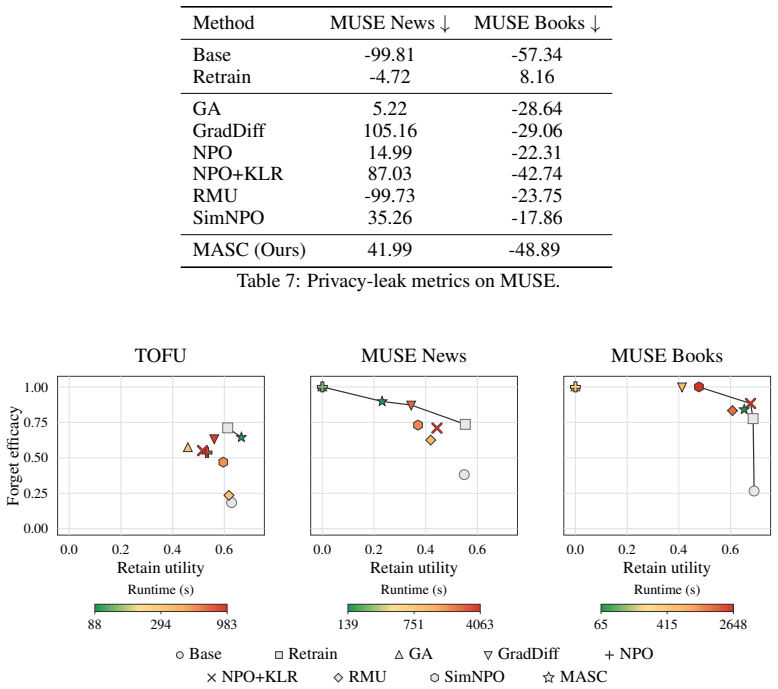
- The method applies across text unlearning benchmarks including TOFU, MUSE News, and MUSE Books while using only a fraction of baseline compute.
- Training stops at the desired trade-off point rather than continuing past it and then selecting afterward.
Where Pith is reading between the lines
- Internal signals such as logit gaps may serve as sufficient proxies for unlearning success in other sequence models if similar margin definitions can be constructed.
- The scaling observation suggests that parameter count itself may help separate forget and retain behavior under margin-based updates.
- The stopping rule could be adapted to streaming or continual unlearning settings where new forget requests arrive over time.
Load-bearing premise
That shrinking the average logit gap on forget sequences by itself produces successful unlearning that keeps retain utility high without any separate downstream checks.
What would settle it
Run MASC to its stopping point on a forget set and then measure whether the model can still generate the original forgotten sequences at high probability or whether retain-task accuracy has fallen below the level of fixed-budget baselines.
Figures

read the original abstract
Language-model unlearning updates a trained model to behave as if it had not seen selected training examples, while preserving utility and avoiding costly retraining. Existing approaches typically fine-tune the pretrained model with a fixed training budget and select the final model afterwards by evaluating several saved checkpoints on downstream validation data. Two sources of unnecessary computation limit scalability: training beyond the desired forget-retain trade-off, and checkpoint selection that requires extra storage and repeated evaluations. To address these limitations, we introduce MArgin Self-Correction (MASC), an efficient unlearning method with an online stopping rule that does not require downstream evaluation. Given a text sequence to be forgotten, MASC actively reduces the logit gap between the original next token and the most likely alternatives. It outputs a final model once this gap is small on average over a sufficiently large proportion of token positions across all forget sequences. On TOFU, MUSE News, and MUSE Books, MASC achieves a competitive forget-retain trade-off at a fraction of the computational cost of existing baselines. We further observe that as we increase model size (a.k.a. number of parameters), the trade-offs improve for both MASC and SimNPO -- the forget metrics remain comparable while retain utility increases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Margin Self-Correction (MASC), an unlearning algorithm for language models that iteratively reduces the logit gap between the original next token and the most likely alternatives on forget sequences. It introduces an online stopping rule that halts training once this gap falls below a threshold on a large fraction of token positions across forget data, without requiring downstream retain-set evaluations or checkpoint storage. The central empirical claim is that MASC achieves a competitive forget-retain trade-off on TOFU, MUSE News, and MUSE Books at substantially lower computational cost than existing baselines, with both MASC and SimNPO showing improved trade-offs as model scale increases.
Significance. If the online stopping rule can be shown to reliably preserve retain utility without post-hoc downstream checks, MASC would represent a meaningful advance in scalable unlearning by removing the need for repeated evaluations and extra storage. The reported scaling trend (stable forget metrics with rising retain utility) is also potentially important if substantiated. The absence of quantitative metrics, error bars, ablations, and exact implementation details in the abstract, however, prevents assessment of whether these benefits are realized.
major comments (2)
- [Abstract] Abstract: the claim that MASC 'achieves a competitive forget-retain trade-off' supplies no numerical values, error bars, exact implementation details, or ablation studies, so the data-to-claim link cannot be evaluated.
- [Abstract / §3] Stopping rule (described in Abstract and §3): the criterion is defined solely from the average logit gap on forget sequences and does not incorporate any retain-set signal; because the update direction is derived exclusively from forget data, nothing in the construction prevents incidental degradation of retain logits, yet the manuscript reports only post-hoc retain numbers rather than demonstrating that the chosen threshold lands before retain degradation begins.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that MASC 'achieves a competitive forget-retain trade-off' supplies no numerical values, error bars, exact implementation details, or ablation studies, so the data-to-claim link cannot be evaluated.
Authors: We agree that the abstract would be strengthened by quantitative details. In the revised version we will report specific forget and retain metrics (e.g., exact scores on TOFU, MUSE News, and MUSE Books), computational cost reductions relative to baselines, and the observed scaling trend with model size. Key implementation parameters and a brief note on multiple-run variability will also be added. revision: yes
-
Referee: [Abstract / §3] Stopping rule (described in Abstract and §3): the criterion is defined solely from the average logit gap on forget sequences and does not incorporate any retain-set signal; because the update direction is derived exclusively from forget data, nothing in the construction prevents incidental degradation of retain logits, yet the manuscript reports only post-hoc retain numbers rather than demonstrating that the chosen threshold lands before retain degradation begins.
Authors: The stopping rule is deliberately constructed from forget data alone to remove the need for retain-set evaluations and checkpoint storage. While the construction itself provides no theoretical guarantee against retain degradation, our experiments show that the chosen threshold yields competitive retain utility. We will add an analysis (new figure or table) that plots retain performance as a function of the stopping threshold to explicitly demonstrate that the selected operating point precedes measurable retain degradation. revision: yes
Circularity Check
No significant circularity in claimed method
full rationale
The paper presents MASC as an algorithmic procedure that reduces logit gaps on forget sequences and stops when the average gap falls below threshold on a sufficient fraction of positions; the forget-retain trade-off is then reported via separate post-hoc evaluation on retain benchmarks. No derivation chain reduces a claimed prediction or result to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing self-citation or imported uniqueness theorem appears in the provided text. The stopping rule is a heuristic defined directly on forget data, with retain utility assessed independently afterward, rendering the method self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reducing the logit gap between the original next token and alternatives on forget sequences is sufficient to achieve unlearning while preserving utility.
Reference graph
Works this paper leans on
-
[1]
Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
2023
-
[2]
Machine unlearning
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. In2021 IEEE symposium on security and privacy (SP), pages 141–159. IEEE, 2021
2021
-
[3]
California consumer privacy act of 2018, AB 375, 2018
California Legislature. California consumer privacy act of 2018, AB 375, 2018. URL https: //ca.gov. Cal. Civ. Code§1798.100 - 1798.199
2018
-
[4]
Rwku: Benchmarking real-world knowledge unlearning for large language models.Advances in Neural Information Processing Systems, 37:98213–98263, 2024
Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, Jun Zhao, et al. Rwku: Benchmarking real-world knowledge unlearning for large language models.Advances in Neural Information Processing Systems, 37:98213–98263, 2024
2024
-
[5]
Towards making systems forget with machine unlearning
Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In 2015 IEEE symposium on security and privacy, pages 463–480. IEEE, 2015
2015
-
[6]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. InThe Eleventh International Conference on Learning Representations, 2022
2022
-
[7]
Unlearn what you want to forget: Efficient unlearning for llms
Jiaao Chen and Diyi Yang. Unlearn what you want to forget: Efficient unlearning for llms. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12041–12052, 2023
2023
-
[8]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
On effects of steering latent representation for large language model unlearning
Huu-Tien Dang, Tin Pham, Hoang Thanh-Tung, and Naoya Inoue. On effects of steering latent representation for large language model unlearning. InProceedings of the AAAI Conference on Artificial Intelligence, pages 23733–23742, 2025
2025
-
[10]
Undial: Self-distillation with adjusted logits for robust unlearning in large language models
Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, and Ivan Vuli´c. Undial: Self-distillation with adjusted logits for robust unlearning in large language models. InPro- ceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), ...
2025
-
[11]
Openunlearning: Accelerating LLM unlearning via unified benchmarking of methods and metrics
Vineeth Dorna, Anmol Reddy Mekala, Wenlong Zhao, Andrew McCallum, J Zico Kolter, Zachary Chase Lipton, and Pratyush Maini. Openunlearning: Accelerating LLM unlearning via unified benchmarking of methods and metrics. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026. URL https://openreview.net...
2026
-
[12]
arXiv preprint arXiv:2310.02238 , year=
Ronen Eldan and Mark Russinovich. Who’s harry potter? approximate unlearning in llms, 2023. URLhttps://arxiv.org/abs/2310.02238
-
[13]
Con- strained entropic unlearning: A primal-dual framework for large language models
Taha Entesari, Arman Hatami, Rinat Khaziev, Anil Ramakrishna, and Mahyar Fazlyab. Con- strained entropic unlearning: A primal-dual framework for large language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=ZtB34bQI54
2026
-
[14]
Towards LLM unlearning resilient to relearning attacks: A sharpness-aware minimization perspective and beyond
Chongyu Fan, Jinghan Jia, Yihua Zhang, Anil Ramakrishna, Mingyi Hong, and Sijia Liu. Towards LLM unlearning resilient to relearning attacks: A sharpness-aware minimization perspective and beyond. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=zZjLv6F0Ks
2025
-
[15]
Simplicity prevails: Rethinking negative preference optimization for LLM unlearning
Chongyu Fan, Jiancheng Liu, Licong Lin, Jinghan Jia, Ruiqi Zhang, Song Mei, and Sijia Liu. Simplicity prevails: Rethinking negative preference optimization for LLM unlearning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=JbvSQm5h1l. 11
2026
-
[16]
Dissecting fine-tuning unlearning in large language models
Yihuai Hong, Yuelin Zou, Lijie Hu, Ziqian Zeng, Di Wang, and Haiqin Yang. Dissecting fine-tuning unlearning in large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 3933–3941, 2024
2024
-
[17]
The euro- pean union general data protection regulation: what it is and what it means.Information & communications technology law, 28(1):65–98, 2019
Chris Jay Hoofnagle, Bart Van Der Sloot, and Frederik Zuiderveen Borgesius. The euro- pean union general data protection regulation: what it is and what it means.Information & communications technology law, 28(1):65–98, 2019
2019
-
[18]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[19]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Reversing the forget-retain objectives: An efficient llm unlearning framework from logit difference.Advances in Neural Information Processing Systems, 37:12581–12611, 2024
Jiabao Ji, Yujian Liu, Yang Zhang, Gaowen Liu, Ramana R Kompella, Sijia Liu, and Shiyu Chang. Reversing the forget-retain objectives: An efficient llm unlearning framework from logit difference.Advances in Neural Information Processing Systems, 37:12581–12611, 2024
2024
-
[21]
Copyright violations and large language models
Antonia Karamolegkou, Jiaang Li, Li Zhou, and Anders Søgaard. Copyright violations and large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7403–7412, 2023
2023
-
[22]
Preserving privacy through dememorization: An unlearning technique for mitigating memorization risks in language models
Aly Kassem, Omar Mahmoud, and Sherif Saad. Preserving privacy through dememorization: An unlearning technique for mitigating memorization risks in language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4360–4379, 2023
2023
-
[23]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[24]
Lee, Addie Foote, Alex Infanger, Leni Shor, Harish K Kamath, Jacob Goldman- Wetzler, Bryce Woodworth, Alex Cloud, and Alexander Matt Turner
Bruce W. Lee, Addie Foote, Alex Infanger, Leni Shor, Harish K Kamath, Jacob Goldman- Wetzler, Bryce Woodworth, Alex Cloud, and Alexander Matt Turner. Distillation robustifies unlearning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[25]
URLhttps://openreview.net/forum?id=UTGjik64IK
-
[26]
Biobert: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020
2020
-
[27]
Solving quantitative reasoning problems with language models
Aitor Lewkowycz, Anders Johan Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Venkatesh Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun ...
2022
-
[28]
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew Bo Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Ariel Herbert-V oss, Cort B Breuer, Andy Z...
2024
-
[29]
Rethinking machine unlearning for large language models.Nature Machine Intelligence, 7(2):181–194, 2025
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, et al. Rethinking machine unlearning for large language models.Nature Machine Intelligence, 7(2):181–194, 2025
2025
-
[30]
Eraser: Jailbreaking defense in large language models via unlearning harmful knowledge
Weikai Lu, Ziqian Zeng, Jianwei Wang, Zhengdong Lu, Zelin Chen, Huiping Zhuang, and Cen Chen. Eraser: Jailbreaking defense in large language models via unlearning harmful knowledge. arXiv preprint arXiv:2404.05880, 2024
-
[31]
Quark: Controllable text generation with reinforced unlearning
Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, and Yejin Choi. Quark: Controllable text generation with reinforced unlearning. Advances in neural information processing systems, 35:27591–27609, 2022
2022
-
[32]
Scaling laws for fact memorization of large language models
Xingyu Lu, Xiaonan Li, Qinyuan Cheng, Kai Ding, Xuan-Jing Huang, and Xipeng Qiu. Scaling laws for fact memorization of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 11263–11282, 2024
2024
-
[33]
An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[34]
TOFU: A Task of Fictitious Unlearning for LLMs
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C Lipton, and J Zico Kolter. Tofu: A task of fictitious unlearning for llms.arXiv preprint arXiv:2401.06121, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Catastrophic interference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, volume 24, pages 109–165. Elsevier, 1989
1989
-
[36]
Did the neurons read your book? document-level membership inference for large language models
Matthieu Meeus, Shubham Jain, Marek Rei, and Yves-Alexandre de Montjoye. Did the neurons read your book? document-level membership inference for large language models. In33rd USENIX Security Symposium (USENIX Security 24), pages 2369–2385, 2024
2024
-
[37]
How much do language models memorize? arXiv preprint arXiv:2505.24832, 2025
John X Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G Edward Suh, Alexander M Rush, Kamalika Chaudhuri, and Saeed Mahloujifar. How much do language models memorize? arXiv preprint arXiv:2505.24832, 2025
-
[38]
Using an llm to help with code understanding
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. Using an llm to help with code understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13, 2024
2024
-
[39]
In-context unlearning: Language models as few-shot unlearners
Martin Pawelczyk, Seth Neel, and Himabindu Lakkaraju. In-context unlearning: Language models as few-shot unlearners. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceed- ings of the 41st International Conference on Machine Learning, volume 235 ofProceed- ings of Mach...
2024
-
[40]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[41]
RL’s razor: Why online reinforcement learning forgets less
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. RL’s razor: Why online reinforcement learning forgets less. InThe Fourteenth International Conference on Learning Representations,
-
[42]
URLhttps://openreview.net/forum?id=7HNRYT4V44
-
[43]
Abhay Sheshadri, Aidan Ewart, Phillip Guo, Aengus Lynch, Cindy Wu, Vivek Hebbar, Henry Sleight, Asa Cooper Stickland, Ethan Perez, Dylan Hadfield-Menell, et al. Latent adver- sarial training improves robustness to persistent harmful behaviors in llms.arXiv preprint arXiv:2407.15549, 2024
-
[44]
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A Smith, and Chiyuan Zhang. Muse: Machine unlearning six-way evaluation for language models.arXiv preprint arXiv:2407.06460, 2024. 13
-
[45]
Beyond memorization: Violating privacy via inference with large language models
Robin Staab, Mark Vero, Mislav Balunovic, and Martin Vechev. Beyond memorization: Violating privacy via inference with large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[46]
Tamper-resistant safeguards for open-weight LLMs
Rishub Tamirisa, Bhrugu Bharathi, Long Phan, Andy Zhou, Alice Gatti, Tarun Suresh, Maxwell Lin, Justin Wang, Rowan Wang, Ron Arel, Andy Zou, Dawn Song, Bo Li, Dan Hendrycks, and Mantas Mazeika. Tamper-resistant safeguards for open-weight LLMs. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id...
2025
-
[47]
Guardrail baselines for unlearning in llms.arXiv preprint arXiv:2403.03329, 2024
Pratiksha Thaker, Yash Maurya, Shengyuan Hu, Zhiwei Steven Wu, and Virginia Smith. Guardrail baselines for unlearning in llms.arXiv preprint arXiv:2403.03329, 2024
-
[48]
Unilogit: Robust Machine Unlearning for LLM s Using Uniform-Target Self-Distillation
Stefan Vasilev, Christian Herold, Baohao Liao, Seyyed Hadi Hashemi, Shahram Khadivi, and Christof Monz. Unilogit: Robust machine unlearning for LLMs using uniform-target self- distillation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 2245...
-
[49]
Bichen Wang, Yuzhe Zi, Yixin Sun, Yanyan Zhao, and Bing Qin. Rkld: Reverse kl-divergence- based knowledge distillation for unlearning personal information in large language models. arXiv preprint arXiv:2406.01983, 2024
-
[50]
GRU: Mitigating the trade-off between unlearning and retention for LLMs
Yue Wang, Qizhou Wang, Feng Liu, Wei Huang, Yali Du, Xiaojiang Du, and Bo Han. GRU: Mitigating the trade-off between unlearning and retention for LLMs. InForty-second Inter- national Conference on Machine Learning, 2025. URLhttps://openreview.net/forum? id=EAjhGr1Oeo
2025
-
[51]
BloombergGPT: A Large Language Model for Finance
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance.arXiv preprint arXiv:2303.17564, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Large language model unlearning.Advances in Neural Information Processing Systems, 37:105425–105475, 2024
Yuanshun Yao and Xiaojun Xu. Large language model unlearning.Advances in Neural Information Processing Systems, 37:105425–105475, 2024
2024
-
[53]
Negative preference optimization: From catastrophic collapse to effective unlearning
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning. InFirst Conference on Language Modeling, 2024. URLhttps://openreview.net/forum?id=MXLBXjQkmb
2024
-
[54]
Catastrophic failure of LLM unlearning via quantization
Zhiwei Zhang, Fali Wang, Xiaomin Li, Zongyu Wu, Xianfeng Tang, Hui Liu, Qi He, Wenpeng Yin, and Suhang Wang. Catastrophic failure of LLM unlearning via quantization. InThe Thirteenth International Conference on Learning Representations, 2025. URL https:// openreview.net/forum?id=lHSeDYamnz
2025
-
[55]
target versus nearest rivals
Yisheng Zhong, Zhengbang Yang, and Zhuangdi Zhu. DUET: Distilled LLM unlearning from an efficiently contextualized teacher. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=Xa6QRrXrKX. 14 A Additional related work Beyond the likelihood-reversal and preference-optimization baselines considered ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.