ERP-XTTN: Interpretable Prototype-Guided Cross-Attention for Cross-Subject ERP Classification
Pith reviewed 2026-06-28 15:13 UTC · model grok-4.3
The pith
Prototype-guided cross-attention classifies event-related potentials across subjects without calibration while exposing why errors occur through attention patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
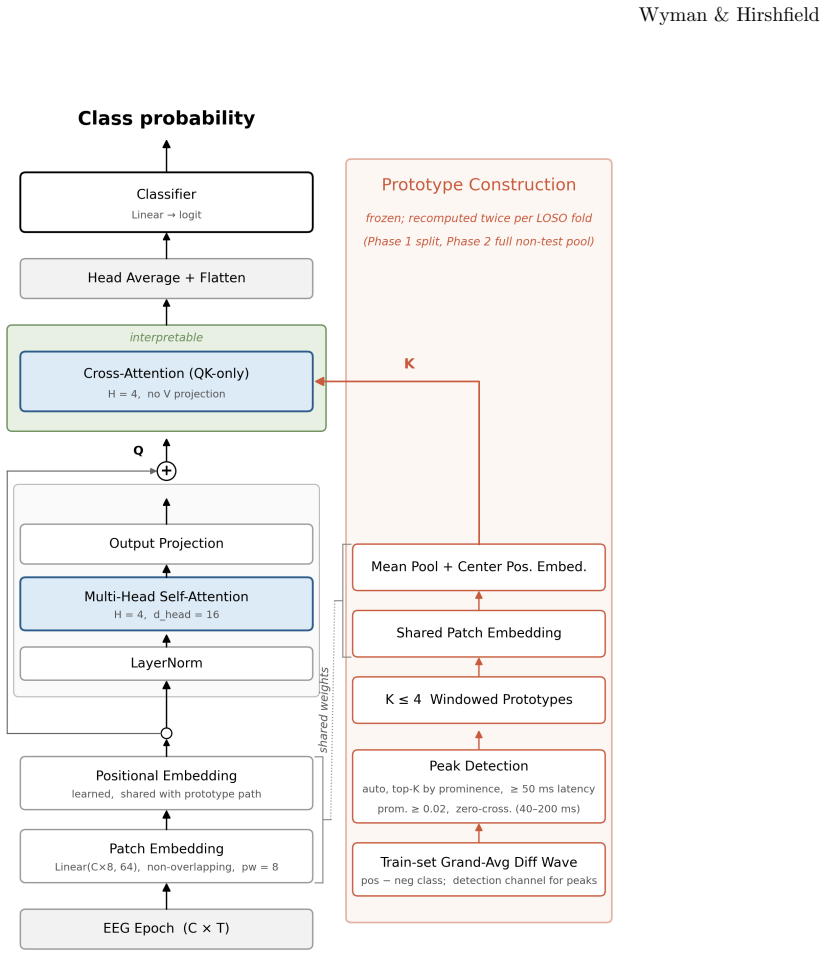
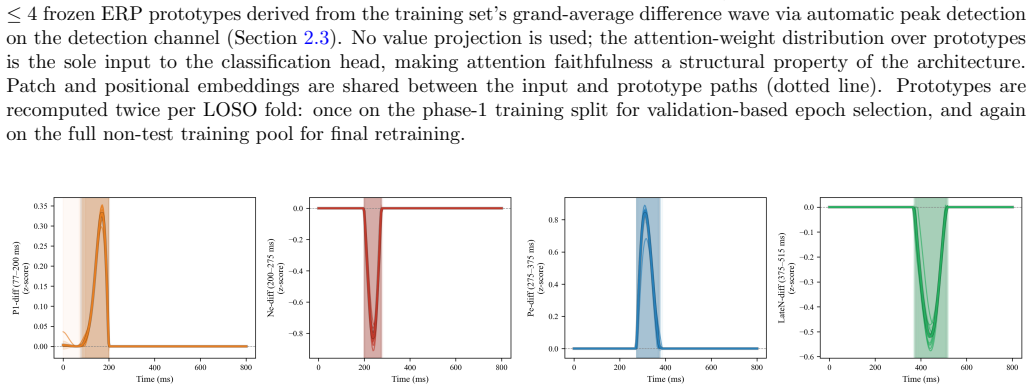
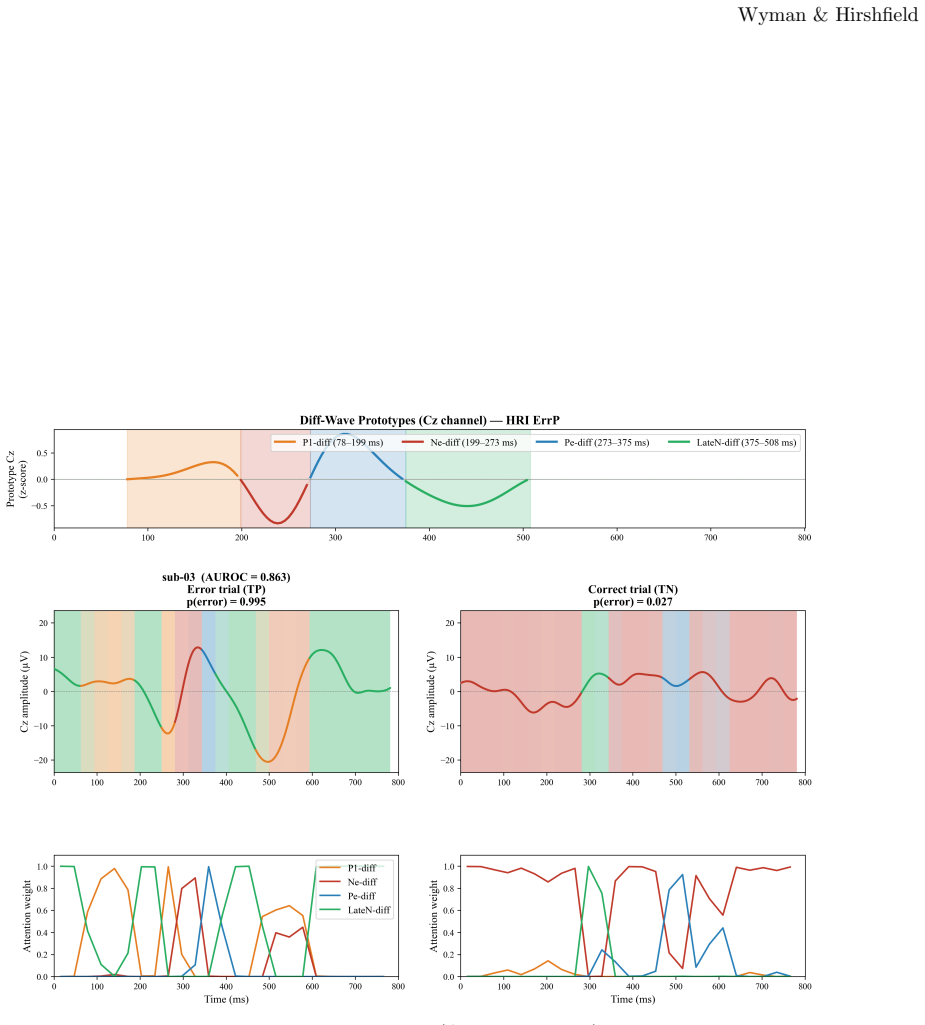
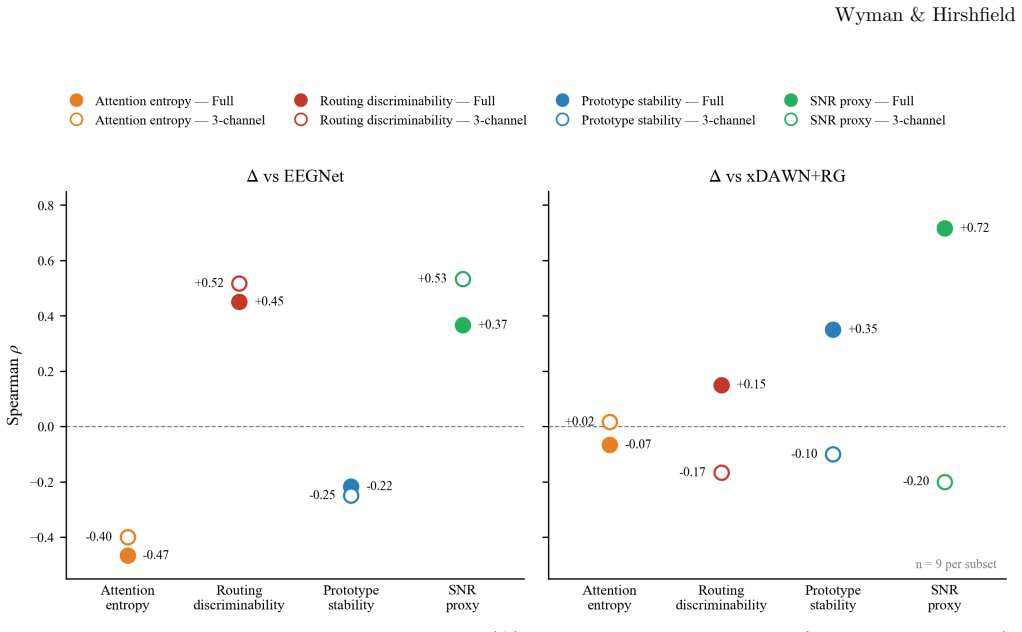
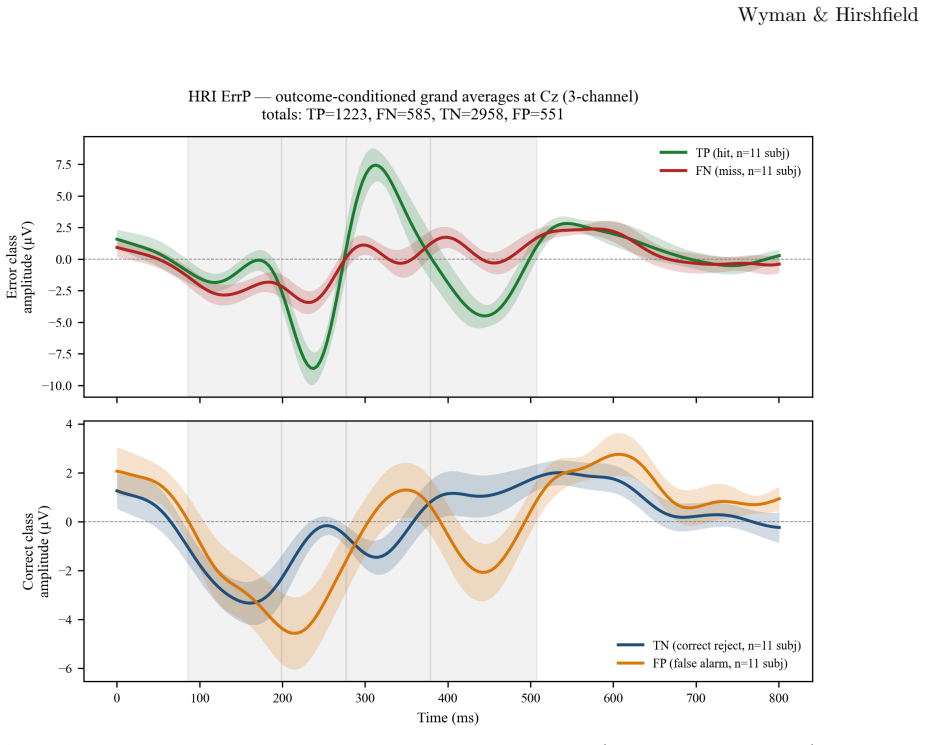
ERP-XTTN derives fixed prototypes from extrema in each training-fold difference wave and routes input EEG patches to those prototypes through query-key-only cross-attention that omits any value projection. Classification therefore depends solely on the resulting attention weights, guaranteeing that explanations are structural. Across eight ERP components and leave-one-subject-out evaluation the mean gap to the best baseline is 0.018 AUROC at three channels and 0.034 at full montage. The transparent routing further shows that misclassified examples resemble correctly classified positive examples more than negative examples, indicating that errors remain neurophysiologically interpretable.
What carries the argument
Query-key-only cross-attention that routes input EEG patches exclusively to fixed difference-wave prototypes derived from training-fold extrema, with all classification determined by the attention distribution.
If this is right
- Classification decisions can be inspected directly by examining which prototype receives the highest attention weight for any given epoch.
- The same architecture applies without retraining or recalibration to multiple ERP components spanning error, attention, and language processing.
- At minimal channel counts the accuracy cost of built-in interpretability remains small enough for practical deployment.
- False-positive and false-negative patterns can be traced to specific prototype matches that reflect shared neurophysiological features.
Where Pith is reading between the lines
- The query-key-only design could be tested on other single-channel or low-density time-series tasks where class prototypes capture peak timing differences.
- Dynamic updating of prototypes after initial deployment might reduce the observed temporal-flexibility cost while retaining the structural interpretability property.
- Combining the routing step with a lightweight spatial filter at full montage could close the larger gap seen when electrode count increases.
Load-bearing premise
The prototypes taken from extrema in the training difference wave continue to represent the held-out subject's signal structure under leave-one-subject-out conditions.
What would settle it
A new dataset or subject cohort in which the automatically derived prototypes produce attention weights that systematically fail to peak at the known latencies of the target ERP component while accuracy falls more than 0.05 AUROC below the strongest baseline.
Figures
read the original abstract
Interpretable brain-computer interface classifiers that generalize across subjects without calibration remain an open challenge. We test whether prototype-based cross-attention can provide competitive, interpretable event-related potential (ERP) classification under deployment-compatible conditions. We propose ERP-XTTN, a cross-attention architecture that routes input EEG patches to fixed difference-wave prototypes via query-key-only cross-attention with no value projection, so classification depends entirely on attention routing and attention faithfulness is structural rather than post-hoc. Prototypes are derived automatically from extrema in the training-fold difference wave. We evaluate across three public sources (BNCI Horizon 2020, HRI Cursor, and ERP CORE) spanning eight ERP components (ERN, LRP, ErrP, N170, P300, N2pc, MMN, N400), using leave-one-subject-out (LOSO) evaluation with causal filtering at two channel counts (3-channel and full montage), against EEGNet and xDAWN with Riemannian geometry (xDAWN+RG). The mean gap between the best baseline and ERP-XTTN was .018 AUROC at 3 channels and .034 at full montage, arising from two largely distinct sources: a temporal-flexibility cost relative to EEGNet and a spatial-exploitation cost relative to xDAWN+RG, the latter driven by signal-to-noise ratio at full montage. Beyond accuracy, the transparent routing reveals cross-subject signal structure that black-box models cannot: false positives resembled true positives more than true negatives did, indicating that classification errors are neurophysiologically explicable. ERP-XTTN generalizes across diverse ERPs under causal, calibration-free conditions with a small interpretability cost at minimal montages. To our knowledge, this is the first epoch-level LOSO benchmark on ERP CORE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ERP-XTTN, a query-key cross-attention architecture that routes EEG patches to fixed prototypes derived from training-fold difference-wave extrema for cross-subject ERP classification. It reports LOSO results across eight ERP components from three public datasets at 3-channel and full-montage settings, claiming mean AUROC gaps of 0.018 and 0.034 versus EEGNet and xDAWN+RG respectively, with the gaps attributed to temporal flexibility and spatial SNR costs, plus structural interpretability via attention routing that reveals neurophysiologically plausible error patterns.
Significance. If the central generalization claim holds after verification, the work would provide a structurally interpretable, calibration-free alternative for ERP decoding that maintains near-baseline accuracy at minimal montages while exposing cross-subject signal structure inaccessible to black-box models; the multi-dataset LOSO benchmark on ERP CORE is a useful contribution to the field.
major comments (3)
- [Abstract] Abstract: the reported mean AUROC gaps (.018 at 3 channels, .034 at full montage) are presented without error bars, per-fold or per-component standard deviations, or any statistical significance tests, which is required to support the claim that the gaps represent a 'small interpretability cost' rather than noise or dataset-specific effects.
- [Methods (prototype derivation and evaluation)] Prototype construction and LOSO evaluation sections: the load-bearing assumption that extrema from the training-fold difference wave remain representative of each left-out subject's latency, amplitude, and topography is not accompanied by any per-subject alignment check, latency jitter quantification, or attention-score distribution analysis; without this, the routing mechanism's ability to generalize under known 50-100 ms inter-subject ERP variability cannot be assessed.
- [Results] Results and discussion: the attribution of the full-montage gap to 'spatial-exploitation cost' versus xDAWN+RG is not supported by an ablation that isolates channel count from prototype alignment, leaving open whether the .034 gap is driven by the fixed-prototype assumption rather than montage size alone.
minor comments (2)
- [Abstract] The abstract states 'causal filtering' but provides no filter type, order, or cutoff frequencies, which are needed for reproducibility of the deployment-compatible claim.
- [Results] No table or figure shows per-ERP-component AUROC values or attention maps, which would strengthen the interpretability claims beyond the qualitative false-positive analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each of the major comments point by point below, indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported mean AUROC gaps (.018 at 3 channels, .034 at full montage) are presented without error bars, per-fold or per-component standard deviations, or any statistical significance tests, which is required to support the claim that the gaps represent a 'small interpretability cost' rather than noise or dataset-specific effects.
Authors: We agree that the presentation of mean AUROC gaps without accompanying variability measures or statistical tests limits the strength of the claims. In the revised manuscript, we will add error bars representing standard deviations across folds and components, and perform statistical significance testing (e.g., Wilcoxon signed-rank tests) to evaluate whether the gaps are significant. revision: yes
-
Referee: [Methods (prototype derivation and evaluation)] Prototype construction and LOSO evaluation sections: the load-bearing assumption that extrema from the training-fold difference wave remain representative of each left-out subject's latency, amplitude, and topography is not accompanied by any per-subject alignment check, latency jitter quantification, or attention-score distribution analysis; without this, the routing mechanism's ability to generalize under known 50-100 ms inter-subject ERP variability cannot be assessed.
Authors: The overall LOSO results provide evidence that the fixed prototypes generalize sufficiently for competitive performance. However, we acknowledge the value of explicit checks for alignment and jitter. We will add per-subject latency jitter quantification and attention-score distribution analysis to the revised methods and supplementary materials. revision: yes
-
Referee: [Results] Results and discussion: the attribution of the full-montage gap to 'spatial-exploitation cost' versus xDAWN+RG is not supported by an ablation that isolates channel count from prototype alignment, leaving open whether the .034 gap is driven by the fixed-prototype assumption rather than montage size alone.
Authors: We agree that an ablation study isolating the contribution of the fixed-prototype approach from channel count effects would better support the attribution. We will include such an ablation in the revised results section, for example by comparing performance with channel-count-matched baselines or adjusted prototype methods. revision: yes
Circularity Check
No circularity: prototypes fitted on training folds, generalization tested on held-out subjects via LOSO
full rationale
The paper derives prototypes from extrema in the training-fold difference wave and evaluates classification performance under leave-one-subject-out on independent subjects. This is a standard supervised setup that tests whether the training-derived prototypes generalize, rather than any equation or definition that would force the output metric to equal the input fit by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way that reduces the central claim to prior author work. The architecture (query-key cross-attention with no value projection) is defined independently of the evaluation results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. J. Luck,An Introduction to the Event-Related Potential Technique(A Bradford Book), 2nd ed. Cambridge, Mass: MIT Press, 2014. 12 Wyman & Hirshfield
2014
-
[2]
Brain–computer interfaces for communication and control,
J. R. Wolpaw, N. Birbaumer, D. J. McFarland, G. Pfurtscheller, and T. M. Vaughan, “Brain–computer interfaces for communication and control,”Clinical Neurophysiology, vol. 113, no. 6, pp. 767–791, Jun. 2002
2002
-
[3]
A scoping review on the use of consumer-grade EEG devices for research,
J. Sabio, N. S. Williams, G. M. McArthur, and N. A. Badcock, “A scoping review on the use of consumer-grade EEG devices for research,”PLOS ONE, vol. 19, no. 3, e0291186, Mar. 2024
2024
-
[4]
Signal Processing Approaches to Minimize or Suppress Calibration Time in Oscillatory Activity-Based Brain–Computer Interfaces,
F. Lotte, “Signal Processing Approaches to Minimize or Suppress Calibration Time in Oscillatory Activity-Based Brain–Computer Interfaces,”Proceedings of the IEEE, vol. 103, no. 6, pp. 871–890, Jun. 2015
2015
-
[5]
Towards a Cure for BCI Illiteracy,
C. Vidaurre and B. Blankertz, “Towards a Cure for BCI Illiteracy,”Brain Topography, vol. 23, no. 2, pp. 194–198, Jun. 2010
2010
-
[6]
EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces,
V. J. Lawhern, A. J. Solon, N. R. Waytowich, S. M. Gordon, C. P. Hung, and B. J. Lance, “EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces,”Journal of Neural Engineering, vol. 15, no. 5, p. 056 013, Oct. 2018
2018
-
[7]
Deep Learning Approaches for P300 Classification in Image Triage: Applications to the NAILS Task,
A. J. Solon, S. M. Gordon, V. J. Lawhern, and B. J. Lance, “Deep Learning Approaches for P300 Classification in Image Triage: Applications to the NAILS Task,” inProceedings of the 13th NTCIR Conference on Evaluation of Information Access Technologies (NTCIR-13), Tokyo, Japan, Dec. 2017
2017
-
[8]
A review of classification algorithms for EEG-based brain–computer interfaces: A 10 year update,
F. Lotte et al., “A review of classification algorithms for EEG-based brain–computer interfaces: A 10 year update,”Journal of Neural Engineering, vol. 15, no. 3, p. 031 005, Jun. 2018
2018
-
[9]
A Transformer Encoder and Convolutional Neural Network Combined Method for Classification of Error-related Potentials,
G. Ren, S. S. Mahmoud, A. Kumar, Q. Fang, and B. Yu, “A Transformer Encoder and Convolutional Neural Network Combined Method for Classification of Error-related Potentials,” in2023 IEEE Biomedical Circuits and Systems Conference (BioCAS), Toronto, ON, Canada: IEEE, Oct. 2023, pp. 1–5
2023
-
[10]
A deep neural network and transfer learning combined method for cross-task classification of error-related potentials,
G. Ren, A. Kumar, S. S. Mahmoud, and Q. Fang, “A deep neural network and transfer learning combined method for cross-task classification of error-related potentials,”Frontiers in Human Neuroscience, vol. 18, p. 1 394 107, Jun. 2024
2024
-
[11]
Single-trial analysis and classification of ERP components — A tutorial,
B. Blankertz, S. Lemm, M. Treder, S. Haufe, and K.-R. M¨ uller, “Single-trial analysis and classification of ERP components — A tutorial,”NeuroImage, vol. 56, no. 2, pp. 814–825, May 2011
2011
-
[12]
xDAWN Algorithm to Enhance Evoked Potentials: Application to Brain–Computer Interface,
B. Rivet, A. Souloumiac, V. Attina, and G. Gibert, “xDAWN Algorithm to Enhance Evoked Potentials: Application to Brain–Computer Interface,”IEEE Transactions on Biomedical Engineering, vol. 56, no. 8, pp. 2035–2043, Aug. 2009
2035
-
[13]
Transfer Learning Algorithm of P300-EEG Signal Based on XDAWN Spatial Filter and Riemannian Geometry Classifier,
F. Li, Y. Xia, F. Wang, D. Zhang, X. Li, and F. He, “Transfer Learning Algorithm of P300-EEG Signal Based on XDAWN Spatial Filter and Riemannian Geometry Classifier,”Applied Sciences, vol. 10, no. 5, p. 1804, Mar. 2020
2020
-
[14]
Calibration-Free Error-Related Potential Decoding With Adaptive Subject-Independent Models: A Comparative Study,
F. M. Sch¨ onleitner, L. Otter, S. K. Ehrlich, and G. Cheng, “Calibration-Free Error-Related Potential Decoding With Adaptive Subject-Independent Models: A Comparative Study,”IEEE Transactions on Medical Robotics and Bionics, vol. 2, no. 3, pp. 399–409, Aug. 2020
2020
-
[15]
Classification of error-related potentials evoked during stroke rehabilitation training,
A. Kumar, E. Pirogova, S. S. Mahmoud, and Q. Fang, “Classification of error-related potentials evoked during stroke rehabilitation training,”Journal of Neural Engineering, vol. 18, no. 5, p. 056 022, Oct. 2021
2021
-
[16]
A Generic Transferable EEG Decoder for Online Detection of Error Potential in Target Selection,
S. Bhattacharyya, A. Konar, D. N. Tibarewala, and M. Hayashibe, “A Generic Transferable EEG Decoder for Online Detection of Error Potential in Target Selection,”Frontiers in Neuroscience, vol. 11, p. 226, May 2017
2017
-
[17]
Online asynchronous detection of error-related potentials in participants with a spinal cord injury using a generic classifier,
C. Lopes-Dias et al., “Online asynchronous detection of error-related potentials in participants with a spinal cord injury using a generic classifier,”Journal of Neural Engineering, vol. 18, no. 4, p. 046 022, Aug. 2021
2021
-
[18]
Online and Offline Domain Adaptation for Reducing BCI Calibration Effort,
D. Wu, “Online and Offline Domain Adaptation for Reducing BCI Calibration Effort,”IEEE Transactions on Human-Machine Systems, vol. 47, no. 4, pp. 550–563, Aug. 2017
2017
-
[19]
Transfer Learning for EEG-Based Brain–Computer Interfaces: A Review of Progress Made Since 2016,
D. Wu, Y. Xu, and B.-L. Lu, “Transfer Learning for EEG-Based Brain–Computer Interfaces: A Review of Progress Made Since 2016,”IEEE Transactions on Cognitive and Developmental Systems, vol. 14, no. 1, pp. 4–19, Mar. 2022
2016
-
[20]
Domain generalized feature embedded learning for calibration-free event-related potentials recognition,
T.-j. Luo, “Domain generalized feature embedded learning for calibration-free event-related potentials recognition,”Cognitive Neurodynamics, vol. 20, no. 1, p. 77, Apr. 2026
2026
-
[21]
A framework for Interpretable deep learning in cross-subject detection of event-related potentials,
S. Jalilpour and G. M¨ uller-Putz, “A framework for Interpretable deep learning in cross-subject detection of event-related potentials,”Engineering Applications of Artificial Intelligence, vol. 139, p. 109 642, Jan. 2025
2025
-
[22]
Informing EEG-Based Error Decoding With Explainable AI,
H. T. J. Chan, M. Wimmer, I. ˇSimi´ c, G. R. M¨ uller-Putz, and E. Veas, “Informing EEG-Based Error Decoding With Explainable AI,” in2025 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Vienna, Austria: IEEE, Oct. 2025, pp. 4550–4557
2025
-
[23]
ERP prototypical matching net: A meta-learning method for zero-calibration RSVP-based image retrieval,
W. Wei, S. Qiu, Y. Zhang, J. Mao, and H. He, “ERP prototypical matching net: A meta-learning method for zero-calibration RSVP-based image retrieval,”Journal of Neural Engineering, vol. 19, no. 2, p. 026 028, Apr. 2022. 13 Wyman & Hirshfield
2022
-
[24]
Attention-ProNet: A Prototype Network with Hybrid Attention Mechanisms Applied to Zero Calibration in Rapid Serial Visual Presentation-Based Brain–Computer Interface,
B. Zhang, M. Xu, Y. Zhang, S. Ye, and Y. Chen, “Attention-ProNet: A Prototype Network with Hybrid Attention Mechanisms Applied to Zero Calibration in Rapid Serial Visual Presentation-Based Brain–Computer Interface,”Bioengineering, vol. 11, no. 4, p. 347, Apr. 2024
2024
-
[25]
Discriminative Canonical Pattern Matching for Single-Trial Classification of ERP Components,
X. Xiao, M. Xu, J. Jin, Y. Wang, T.-P. Jung, and D. Ming, “Discriminative Canonical Pattern Matching for Single-Trial Classification of ERP Components,”IEEE Transactions on Biomedical Engineering, vol. 67, no. 8, pp. 2266–2275, Aug. 2020
2020
-
[26]
B. Aristimunha, R. Y. de Camargo, W. H. L. Pinaya, S. Chevallier, A. Gramfort, and C. Rommel,Evaluating the structure of cognitive tasks with transfer learning, Jul. 2023. arXiv:2308.02408 [eess.SP]
-
[27]
Evaluating spatial normalization for SVM-based EEG decoding: A within- and between-subjects perspective,
Y. Qin, Q. Xu, T. Kujala, X. Wang, and F. Cong, “Evaluating spatial normalization for SVM-based EEG decoding: A within- and between-subjects perspective,”Biomedical Signal Processing and Control, vol. 116, p. 109 535, May 2026
2026
-
[28]
ERP-XTTN: Interpretable Cross-Subject Error-Related Potential Classification via Cross-Attention to Data-Driven ERP Prototypes,
C. G. Wyman and L. Hirshfield, “ERP-XTTN: Interpretable Cross-Subject Error-Related Potential Classification via Cross-Attention to Data-Driven ERP Prototypes,” inProceedings of the 10th Graz Brain-Computer Interface Conference, accepted, 2026
2026
-
[29]
Learning From EEG Error-Related Potentials in Noninvasive Brain-Computer Interfaces,
R. Chavarriaga and J. D. R. Millan, “Learning From EEG Error-Related Potentials in Noninvasive Brain-Computer Interfaces,”IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 18, no. 4, pp. 381–388, Aug. 2010
2010
-
[30]
A Feasibility Study for Validating Robot Actions Using EEG-Based Error-Related Potentials,
S. K. Ehrlich and G. Cheng, “A Feasibility Study for Validating Robot Actions Using EEG-Based Error-Related Potentials,”International Journal of Social Robotics, vol. 11, no. 2, pp. 271–283, Apr. 2019
2019
-
[31]
ERP CORE: An open resource for human event-related potential research,
E. S. Kappenman, J. L. Farrens, W. Zhang, A. X. Stewart, and S. J. Luck, “ERP CORE: An open resource for human event-related potential research,”NeuroImage, vol. 225, p. 117 465, Jan. 2021
2021
-
[32]
Attention is not Explanation,
S. Jain and B. C. Wallace, “Attention is not Explanation,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota: Association for Computational Linguistics, Jun. 2019, pp. 3543–3556
2019
-
[33]
Attention is not not Explanation,
S. Wiegreffe and Y. Pinter, “Attention is not not Explanation,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China: Association for Computational Linguistics, Nov. 2019, pp. 11–20
2019
-
[34]
Barachant et al.,Pyriemann, version 0.11, 2026
A. Barachant et al.,Pyriemann, version 0.11, 2026. [Online]. Available: https://doi.org/10.5281/zenodo.593816
-
[35]
A Plug&Play P300 BCI Using Information Geometry
A. Barachant and M. Congedo,A Plug&Play P300 BCI Using Information Geometry, Aug. 2014. arXiv: 1409.0107 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
The Necessity of Leave One Subject Out (LOSO) Cross Validation for EEG Disease Diagnosis,
S. Kunjan et al., “The Necessity of Leave One Subject Out (LOSO) Cross Validation for EEG Disease Diagnosis,” inBrain Informatics, M. Mahmud, M. S. Kaiser, S. Vassanelli, Q. Dai, and N. Zhong, Eds., vol. 12960, Cham: Springer International Publishing, 2021, pp. 558–567
2021
-
[37]
C. G. Wyman,ERP-XTTN: Interpretable Cross-Attention ERP Classifier, version 2.0.0, 2026. [Online]. Available:https://doi.org/10.5281/zenodo.20497891 14 Wyman & Hirshfield Supplementary Material T able S1.Balanced accuracy (mean, LOSO) across channel configurations. Layout matches main text Table 2. ∆ = best baseline minus ERP-XTTN (interpretability cost)....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.