Predicting Inference-Time Scaling Gains from Labeled Validation-Set Output Statistics
Pith reviewed 2026-06-28 11:03 UTC · model grok-4.3
The pith
Three validation-set statistics predict best-of-N gains at Spearman ρ = 0.90 across model families
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across three base-model families, six post-training methods, and math and reasoning task domains, the stability analysis identifies a strict three-feature core spanning prompt-level agreement spread, label-assisted first-correct-sample position, and completion-length variance; a compact ridge predictor built from this core plus an entropy add-on reaches Spearman ρ = 0.90 with actual best-of-N gain under a reward-model verifier.
What carries the argument
Ridge regression predictor on a three-feature core identified via bootstrap-Lasso stability analysis of labeled validation-set output statistics.
If this is right
- Candidate configurations can be screened with one labeled validation sampling pass before full reward-model scoring.
- The three-feature core plus entropy term generalizes across three base-model families and six post-training methods.
- Prediction reaches Spearman ρ = 0.90 on math and reasoning tasks under reward-model verification.
- The method avoids end-to-end best-of-N runs for each configuration tested.
Where Pith is reading between the lines
- The same stability analysis could be applied to predict gains from other inference methods such as majority voting or tree search.
- The predictor may need retraining when shifting to entirely new task distributions or verifiers.
- If the three features capture essential variability, they could inform design of new post-training objectives that increase predictability of scaling.
Load-bearing premise
The features extracted from a single labeled validation-set sampling pass remain stable and predictive when the reward model, task distribution, or model family changes.
What would settle it
Applying the three-feature ridge predictor to a new unseen model family or task domain and measuring whether the Spearman correlation with observed best-of-N gains drops below 0.8.
Figures
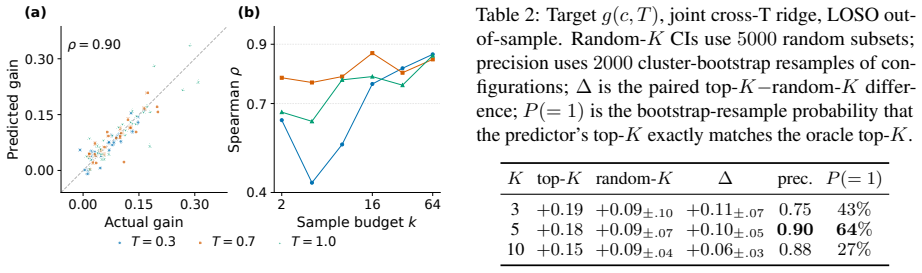
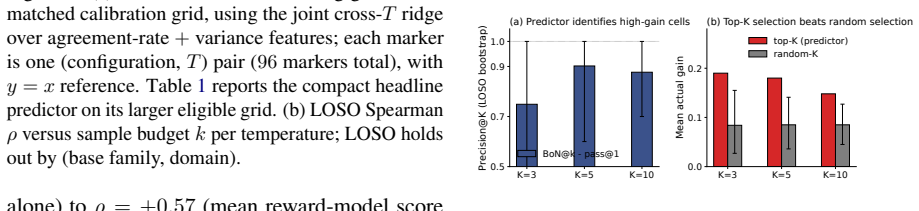
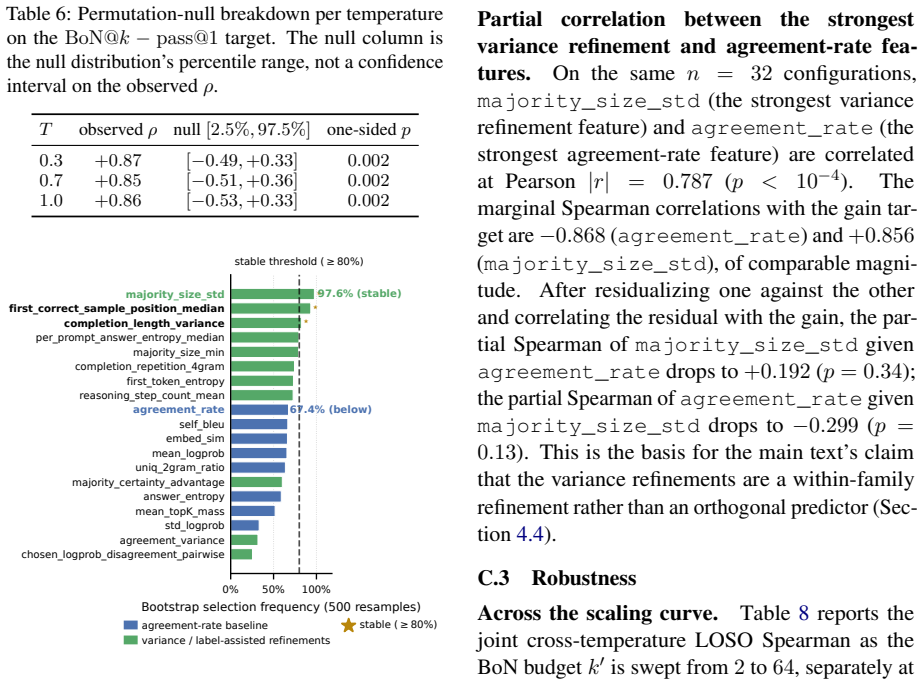
read the original abstract
Best-of-$N$ inference scaling (drawing $N$ candidate answers from a language model and returning the one a reward model ranks highest) improves accuracy by an amount that varies across models, but predicting that amount in advance currently requires running the procedure end-to-end. Prior work links cheap statistics of a model's sampled outputs and validation-set correctness (how often samples agree, how diverse they are, how confident the model is, and where correct samples appear) to model behavior, but does not isolate which of these form a stable, compact predictor of best-of-$N$ gain. We fit ridge predictors on features computed from a single labeled validation-set sampling pass, use bootstrap-Lasso as a stability analysis of the candidate feature set, and give a concentration analysis with an explicit linear-approximation residual. Across three base-model families, six post-training methods, and math and reasoning task domains, the stability analysis identifies a strict three-feature core spanning prompt-level agreement spread, label-assisted first-correct-sample position, and completion-length variance; a compact ridge predictor built from this core plus an entropy add-on reaches Spearman $\rho = 0.90$ with actual best-of-$N$ gain under a reward-model verifier. The intended use is labeled validation-set screening of candidate configurations before paying the full reward-model scoring cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that features derived from a single labeled validation-set sampling pass can predict best-of-N inference scaling gains under a reward-model verifier. Bootstrap-Lasso stability analysis isolates a strict three-feature core (prompt-level agreement spread, label-assisted first-correct-sample position, completion-length variance); a compact ridge model using this core plus an entropy term reaches Spearman ρ=0.90 with observed gains. Results are reported across three base-model families, six post-training methods, and math/reasoning domains, together with a concentration analysis containing an explicit linear-approximation residual. The intended application is cheap labeled-validation screening before full reward-model scoring.
Significance. If the three-feature ridge predictor were shown to transfer, the work would supply a low-cost method for screening inference-scaling configurations, reducing the need for exhaustive reward-model evaluations. The bootstrap-Lasso stability procedure and the explicit residual term in the concentration analysis are positive methodological contributions that would strengthen the result if accompanied by proper generalization evidence.
major comments (3)
- [Abstract] Abstract: the ridge predictor is trained directly on best-of-N gains computed from the identical validation samples used to extract the features, so the reported Spearman ρ=0.90 is an in-sample fit statistic rather than an assessment of predictive performance on unseen data.
- [Abstract] Abstract: the stability analysis and ρ=0.90 claim are supported only by in-distribution results over the three studied model families, six post-training recipes, and math/reasoning domains; no held-out model family, different reward model, or shifted task distribution (e.g., code generation) is used to test transfer of the three-feature core, which is required for the stated use case of labeled validation-set screening.
- [Abstract] Abstract: no sample sizes, confidence intervals around ρ=0.90, ablation tables, or quantitative details of the concentration analysis (including the linear-approximation residual) are supplied, preventing evaluation of the statistical reliability of the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address each major comment below, acknowledging where the manuscript requires clarification or additional reporting, and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the ridge predictor is trained directly on best-of-N gains computed from the identical validation samples used to extract the features, so the reported Spearman ρ=0.90 is an in-sample fit statistic rather than an assessment of predictive performance on unseen data.
Authors: We agree that the reported Spearman ρ=0.90 is an in-sample correlation computed on the same validation samples from which both the features and the observed best-of-N gains were derived. This value quantifies the strength of the linear relationship between the selected features and the measured gains across the evaluated configurations rather than out-of-sample predictive accuracy. We will revise the abstract and methods to explicitly distinguish in-sample fit from predictive performance and will add k-fold cross-validation results to provide a more rigorous assessment of the ridge predictor. revision: yes
-
Referee: [Abstract] Abstract: the stability analysis and ρ=0.90 claim are supported only by in-distribution results over the three studied model families, six post-training recipes, and math/reasoning domains; no held-out model family, different reward model, or shifted task distribution (e.g., code generation) is used to test transfer of the three-feature core, which is required for the stated use case of labeled validation-set screening.
Authors: The stability analysis and correlation results are indeed restricted to the three base-model families, six post-training methods, and math/reasoning domains examined; no experiments were conducted on held-out model families, alternative reward models, or out-of-distribution tasks such as code generation. This constitutes a genuine limitation for the screening use case, which would benefit from demonstrated transfer. We will expand the discussion to state this scope limitation explicitly and position the three-feature core as a candidate for future generalization studies rather than a proven transferable predictor. revision: partial
-
Referee: [Abstract] Abstract: no sample sizes, confidence intervals around ρ=0.90, ablation tables, or quantitative details of the concentration analysis (including the linear-approximation residual) are supplied, preventing evaluation of the statistical reliability of the central empirical claim.
Authors: The manuscript does not report the number of configurations evaluated, confidence intervals for the Spearman ρ, feature ablation results, or the numerical magnitude of the linear-approximation residual in the concentration analysis. We will add these elements in the revision: the exact sample size (number of model–post-training–domain combinations), bootstrap confidence intervals for ρ=0.90, an ablation table comparing the three-feature core against larger and smaller feature sets, and the quantitative residual value from the concentration analysis. revision: yes
Circularity Check
Ridge predictor trained and evaluated on best-of-N gains from identical validation samples yields in-sample Spearman ρ=0.90 presented as predictive result
specific steps
-
fitted input called prediction
[Abstract]
"We fit ridge predictors on features computed from a single labeled validation-set sampling pass, use bootstrap-Lasso as a stability analysis of the candidate feature set, and give a concentration analysis with an explicit linear-approximation residual. ... the stability analysis identifies a strict three-feature core spanning prompt-level agreement spread, label-assisted first-correct-sample position, and completion-length variance; a compact ridge predictor built from this core plus an entropy add-on reaches Spearman ρ = 0.90 with actual best-of-N gain under a reward-model verifier."
Features and target (best-of-N gain under reward-model verifier) are both derived from the identical validation sampling pass; the ridge is fit directly to these paired values and the Spearman coefficient is reported on the same data, reducing the 'prediction' to an in-sample fit by construction.
full rationale
The paper's central result is the bootstrap-Lasso isolation of a three-feature core and the claim that a ridge predictor built from it reaches Spearman ρ=0.90 with actual best-of-N gain. Both the input features (agreement spread, first-correct position, length variance, entropy) and the target gains are computed from the exact same labeled validation-set sampling pass. The reported correlation therefore measures in-sample fit quality of the ridge model rather than independent predictive performance on held-out configurations. This matches the fitted-input-called-prediction pattern exactly; the abstract provides no mention of cross-validation, held-out splits, or OOD re-evaluation of the same ridge on new model families or reward models. The stability analysis and concentration result inherit the same data dependence.
Axiom & Free-Parameter Ledger
free parameters (1)
- ridge regularization parameter
axioms (1)
- domain assumption Linear relationship between the selected features and best-of-N gain is approximately valid within the tested regime
Reference graph
Works this paper leans on
-
[1]
Amos Azaria and Tom Mitchell. 2023. The internal state of an LLM knows when it's lying. In Findings of the Association for Computational Linguistics: EMNLP 2023
2023
-
[2]
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher R\'e, and Azalia Mirhoseini. 2024. Large language monkeys: Scaling inference compute with repeated sampling. arXiv preprint arXiv:2407.21787
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [3]
-
[4]
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. 2023. Discovering latent knowledge in language models without supervision. In International Conference on Learning Representations (ICLR)
2023
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, and 39 others. 2021. Evaluating large language models trained on code. arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try ARC , the AI2 reasoning challenge. arXiv preprint arXiv:1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. 2024. KTO : Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the MATH dataset. In Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track
2021
-
[10]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, and 3 others. 2022. Training compute-optimal ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text degeneration. In International Conference on Learning Representations (ICLR)
2020
-
[12]
Jiwoo Hong, Noah Lee, and James Thorne. 2024. ORPO : Monolithic preference optimization without reference model. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11170--11189
2024
-
[13]
Zhengbao Jiang, Jun Araki, Haibo Ding, and Graham Neubig. 2021. How can we know when language models know? on the calibration of language models for question answering. Transactions of the Association for Computational Linguistics, 9:962--977
2021
-
[14]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, and 17 others. 2022. Language models (mostly) know what they know. arXiv prep...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[16]
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. 2024. Understanding the effects of RLHF on LLM generalisation and diversity. In International Conference on Learning Representations (ICLR)
2024
-
[17]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with PagedAttention . In Proceedings of the 29th Symposium on Operating Systems Principles
2023
-
[18]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. Let's verify step by step. In International Conference on Learning Representations (ICLR)
2024
-
[19]
Chris Yuhao Liu, Liang Zeng, Jiacai Liu, Rui Yan, Jujie He, Chaojie Wang, Shuicheng Yan, Yang Liu, and Yahui Zhou. 2024. Skywork-reward: Bag of tricks for reward modeling in LLMs . arXiv preprint arXiv:2410.18451
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Ian R. McKenzie, Alexander Lyzhov, Michael Pieler, Alicia Parrish, Aaron Mueller, Ameya Prabhu, Euan McLean, Aaron Kirtland, Alexis Ross, Alisa Liu, Andrew Gritsevskiy, Daniel Wurgaft, Derik Kauffman, Gabriel Recchia, Jiacheng Liu, Joe Cavanagh, Max Weiss, Sicong Huang, The Floating Droid, and 8 others. 2023. Inverse scaling: When bigger isn't better. Tra...
2023
-
[21]
Nicolai Meinshausen and Peter B\"uhlmann. 2010. Stability selection. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 72(4):417--473
2010
-
[22]
Yu Meng, Mengzhou Xia, and Danqi Chen. 2024. SimPO : Simple preference optimization with a reference-free reward. In Advances in Neural Information Processing Systems (NeurIPS)
2024
-
[23]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human fee...
2022
-
[24]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems (NeurIPS)
2023
-
[25]
arXiv preprint arXiv:2405.10938 , year=
Yangjun Ruan, Chris J. Maddison, and Tatsunori Hashimoto. 2024. Observational scaling laws and the predictability of language model performance. arXiv preprint arXiv:2405.10938
-
[26]
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. 2023. Are emergent abilities of large language models a mirage? In Advances in Neural Information Processing Systems (NeurIPS)
2023
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling LLM test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. 2022. Solving math word problems with process- and outcome-based feedback. arXiv preprint arXiv:2211.14275
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, and Tong Zhang. 2024. Interpretable preferences via multi-objective reward modeling and mixture-of-experts. In Findings of the Association for Computational Linguistics: EMNLP 2024
2024
-
[31]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-consistency improves chain of thought reasoning in language models. In International Conference on Learning Representations (ICLR)
2023
-
[32]
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. 2024. Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models. arXiv preprint arXiv:2408.00724
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Lantao Yu, Weinan Zhang, Jun Wang, and Yong Yu. 2017. SeqGAN : Sequence generative adversarial nets with policy gradient. In AAAI Conference on Artificial Intelligence
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.