TGV-KV: Text-Grounded KV Eviction for Vision-Language Models
Pith reviewed 2026-06-28 11:01 UTC · model grok-4.3
The pith
TGV-KV evicts visual KV cache in vision-language models by grounding decisions in text, preserving 99.2 percent accuracy at 5 percent retention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
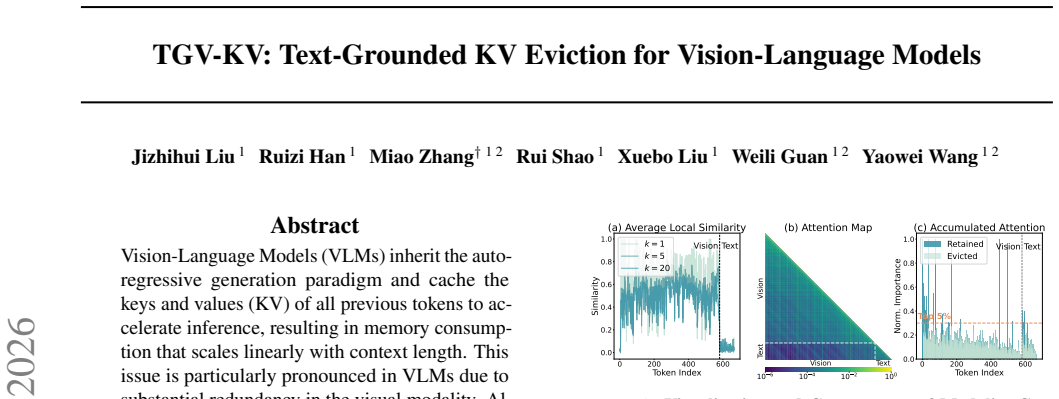
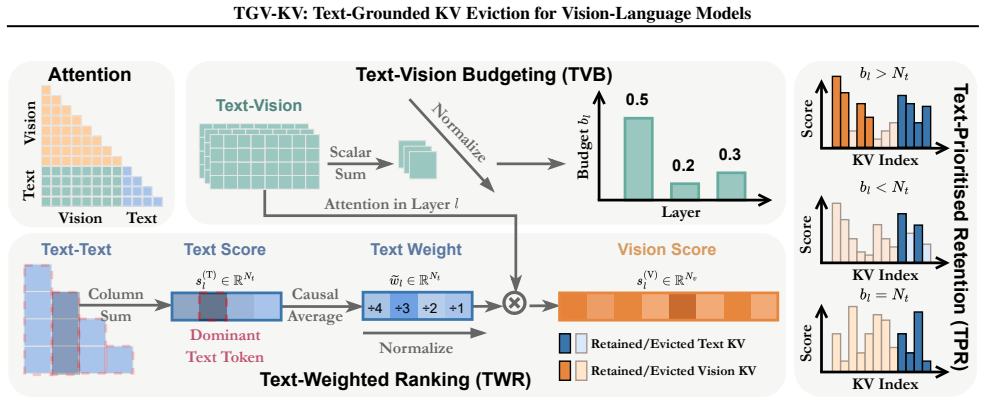
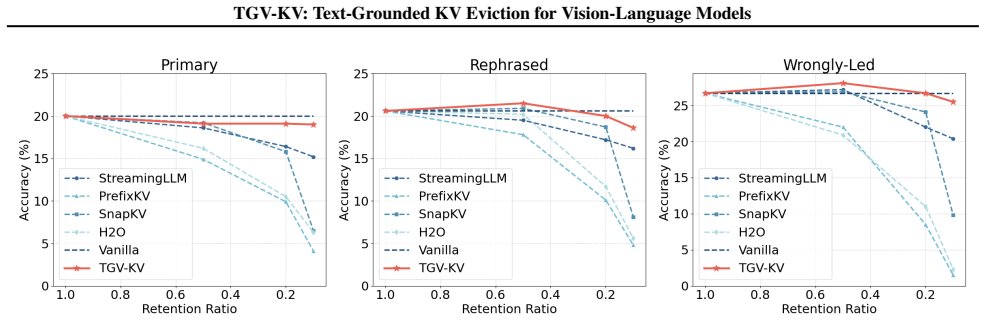
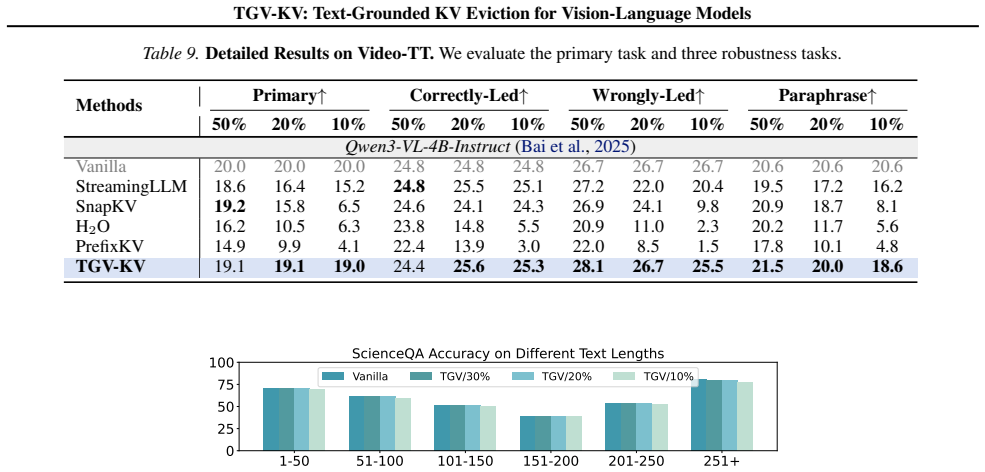
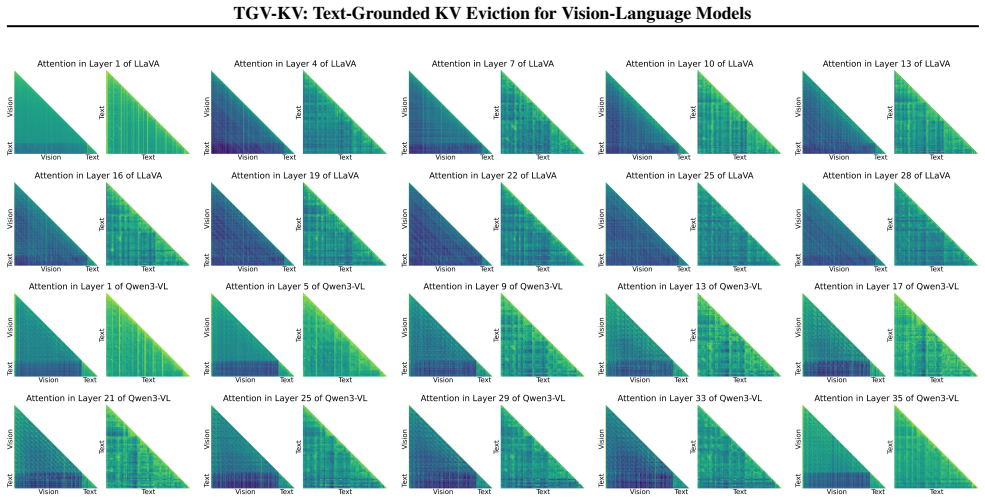
The central claim is that the modality gap in VLMs requires text to guide visual KV eviction. TGV-KV realizes this via Text-Vision Budgeting that sets per-layer retention using mutual information, Text-Weighted Ranking that scores visual importance from text-image attention weights, and Text-Prioritised Retention that keeps every text KV entry. Across five models the method keeps 99.2 percent of full-KV accuracy on VizWiz-VQA with LLaVA-NeXT at a 5 percent retention budget and raises end-to-end throughput by 52.6 percent.
What carries the argument
TGV-KV's three submodules—Text-Vision Budgeting via mutual information, Text-Weighted Ranking via weighted text-image attention, and Text-Prioritised Retention—that use textual guidance to decide which visual KV entries to keep.
If this is right
- KV cache memory for VLMs grows much more slowly with increasing context length.
- End-to-end throughput rises by more than 50 percent at very low retention budgets.
- Visual question answering accuracy remains within 1 percent of the full-cache baseline.
- The approach works across VLMs of different sizes and architectures.
- Text KV entries are never evicted, preventing sudden loss of language context.
Where Pith is reading between the lines
- The same text-grounding idea could reduce cache pressure in video or audio-language models.
- Longer multimodal conversations become feasible on edge devices with limited memory.
- Making the per-layer budgets change during generation might yield further speed gains.
- Direct comparison to purely vision-based eviction on identical tasks would quantify the benefit of text guidance.
Load-bearing premise
Mutual information between text and vision plus weighted attention scores can reliably identify which visual KV entries can be evicted without losing task-critical information.
What would settle it
If accuracy on VizWiz-VQA with LLaVA-NeXT falls below 95 percent of the full-KV baseline when TGV-KV is applied at the 5 percent retention budget, the claim that text-grounded selection preserves necessary visual details would not hold.
Figures



read the original abstract
Vision-Language Models (VLMs) inherit the auto-regressive generation paradigm and cache the keys and values (KV) of all previous tokens to accelerate inference, resulting in memory consumption that scales linearly with context length. This issue is particularly pronounced in VLMs due to substantial redundancy in the visual modality. Although KV cache eviction approaches can effectively reduce inference memory, they often incur significant performance degradation in VLMs, as most are designed for language models and overlook the inherent gap between text and vision. By systematically analyzing the modality gap in VLMs in this work, we argue that the importance of visual information should be grounded in textual guidance and accordingly propose a Text-Grounded KV Eviction method for VLMs (TGV-KV). TGV-KV comprises three submodules: (1) Text-Vision Budgeting (TVB) assigns budget to each layer based on the mutual information interaction. (2) Text-Weighted Ranking (TWR) assesses the priority of text and ranks vision importance based on weighted text-image attention. (3) Text-Prioritised Retention (TPR) policy strategically preserves text KV to avoid acute information loss. We evaluate TGV-KV across five models with different sizes and architectures, showing that TGV-KV preserves 99.2% full-KV accuracy on the VizWiz-VQA task with LLaVA-NeXT and boosts end-to-end throughput by 52.6% with an extreme retention budget of 5%. Code is available at https://github.com/Danielement321/TGV-KV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TGV-KV, a KV-cache eviction method for vision-language models that grounds visual token importance in textual guidance. It introduces three components—Text-Vision Budgeting (TVB) via mutual information, Text-Weighted Ranking (TWR) via weighted text-image attention, and Text-Prioritised Retention (TPR)—and reports that the method retains 99.2% of full-KV accuracy on VizWiz-VQA using LLaVA-NeXT while achieving a 52.6% end-to-end throughput gain at a 5% retention budget. The approach is evaluated across five models of varying sizes and architectures, with code released publicly.
Significance. If the empirical claims hold under scrutiny, the work offers a practical, text-aware engineering solution to the memory scaling problem in VLMs that language-model eviction methods overlook. The public code release is a clear strength that enables direct reproducibility and extension.
major comments (3)
- [TWR description] TWR submodule: the ranking of vision KV entries by weighted text-image attention is presented as identifying task-critical tokens, yet no analysis or ablation demonstrates that these scores correlate with downstream VQA answer correctness rather than superficial modality alignment or early-layer features. This assumption is load-bearing for the 99.2% retention result at the 5% budget.
- [TVB description] TVB submodule: mutual-information-based budget allocation across layers is claimed to respect the text-vision gap, but the manuscript supplies no verification that the resulting per-layer budgets preserve answer-relevant visual evidence instead of modality-level statistics.
- [Experiments] Experimental section: the abstract states strong numerical results on VizWiz-VQA and throughput, yet the manuscript contains no ablation studies isolating TVB/TWR/TPR contributions, no error bars, and no comparison against attention-only or random-eviction baselines under identical 5% budgets.
minor comments (1)
- The abstract claims evaluation on five models but does not name the models or additional tasks beyond VizWiz-VQA.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments below and indicate the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [TWR description] TWR submodule: the ranking of vision KV entries by weighted text-image attention is presented as identifying task-critical tokens, yet no analysis or ablation demonstrates that these scores correlate with downstream VQA answer correctness rather than superficial modality alignment or early-layer features. This assumption is load-bearing for the 99.2% retention result at the 5% budget.
Authors: We acknowledge that a direct analysis linking TWR scores to answer correctness is not present in the current manuscript. The method is grounded in the principle that text provides guidance for visual token importance in VQA tasks. To address this, we will add an ablation study in the revised manuscript that examines the correlation between TWR rankings and token impact on VQA performance, including comparisons to early-layer attention features. revision: yes
-
Referee: [TVB description] TVB submodule: mutual-information-based budget allocation across layers is claimed to respect the text-vision gap, but the manuscript supplies no verification that the resulting per-layer budgets preserve answer-relevant visual evidence instead of modality-level statistics.
Authors: We agree that explicit verification of the per-layer budgets' effectiveness in preserving answer-relevant evidence would be valuable. The TVB uses mutual information to capture the text-vision interaction, but we will include additional analysis in the revision, such as layer-wise performance contributions or visualizations, to demonstrate that the allocation goes beyond modality-level statistics. revision: yes
-
Referee: [Experiments] Experimental section: the abstract states strong numerical results on VizWiz-VQA and throughput, yet the manuscript contains no ablation studies isolating TVB/TWR/TPR contributions, no error bars, and no comparison against attention-only or random-eviction baselines under identical 5% budgets.
Authors: We recognize the importance of these experimental controls. The current results demonstrate the overall effectiveness across multiple models, but we will revise the experimental section to include: (1) ablations isolating the contribution of each submodule (TVB, TWR, TPR), (2) error bars from repeated runs, and (3) direct comparisons to attention-only and random-eviction baselines at the 5% budget on VizWiz-VQA and other tasks. revision: yes
Circularity Check
No circularity: method is an independent engineering proposal with external evaluation
full rationale
The paper introduces TGV-KV via three submodules (TVB using mutual information, TWR using text-weighted attention, TPR for text retention) and reports empirical results on VizWiz-VQA and throughput. No equations, derivations, or self-citations are shown that reduce the claimed accuracy retention or speedup to quantities fitted inside the paper. The central claims rest on benchmark measurements rather than any self-referential definition or prediction-by-construction. This is the normal case of a non-circular applied-methods paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual modality in VLMs contains substantial redundancy that can be identified via text guidance
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[2]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[3]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[4]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[5]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[6]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[7]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[8]
arXiv preprint arXiv:2407.11550 , year=
Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference , author=. arXiv preprint arXiv:2407.11550 , year=
-
[9]
Ao Wang and Hui Chen and Jianchao Tan and Kefeng Zhang and Xunliang Cai and Zijia Lin and Jungong Han and Guiguang Ding , booktitle=. Prefix. 2025 , url=
2025
-
[10]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Proceedings of the IEEE/CVF international conference on computer vision , year=
SparseMM: Head Sparsity Emerges from Visual Concept Responses in MLLMs , author=. Proceedings of the IEEE/CVF international conference on computer vision , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
arXiv preprint arXiv:2509.10798 , year=
Judge Q: Trainable Queries for Optimized Information Retention in KV Cache Eviction , author=. arXiv preprint arXiv:2509.10798 , year=
-
[14]
A Simple and Effective L\_2 Norm-Based Strategy for KV Cache Compression
Devoto, Alessio and Zhao, Yu and Scardapane, Simone and Minervini, Pasquale. A Simple and Effective L\_2 Norm-Based Strategy for KV Cache Compression. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1027
-
[15]
arXiv preprint arXiv:2508.00553 , year=
Hiprune: Training-free visual token pruning via hierarchical attention in vision-language models , author=. arXiv preprint arXiv:2508.00553 , year=
-
[16]
European Conference on Computer Vision , pages=
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[17]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[18]
ICLR , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. ICLR , year=
-
[19]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[20]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[23]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Visionzip: Longer is better but not necessary in vision language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[24]
arXiv preprint arXiv:2506.10967 , year=
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs , author=. arXiv preprint arXiv:2506.10967 , year=
-
[25]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[26]
arXiv preprint arXiv:2406.02069 , year=
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling , author=. arXiv preprint arXiv:2406.02069 , year=
-
[27]
2025 , url=
Ziran Qin and Yuchen Cao and Mingbao Lin and Wen Hu and Shixuan Fan and Ke Cheng and Weiyao Lin and Jianguo Li , booktitle=. 2025 , url=
2025
-
[28]
Efficient Streaming Language Models with Attention Sinks , volume =
Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike , booktitle =. Efficient Streaming Language Models with Attention Sinks , volume =
-
[29]
International Conference on Machine Learning , year=
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference , author=. International Conference on Machine Learning , year=
-
[30]
arXiv preprint arXiv:2408.03326 , year=
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
-
[31]
2024 , eprint=
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models , author=. 2024 , eprint=
2024
-
[32]
Why 1 + 1
Yangfu Li and Hongjian Zhan and Tianyi Chen and Qi Liu and Yu-Jie Xiong and Yue Lu , booktitle=. Why 1 + 1. 2025 , url=
2025
-
[33]
C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning
Masry, Ahmed and Long, Do Xuan and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul. C hart QA : A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.177
-
[34]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Docvqa: A dataset for vqa on document images , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
doi: 10.1007/ s11432-024-4235-6
Liu, Yuliang and Li, Zhang and Huang, Mingxin and Yang, Biao and Yu, Wenwen and Li, Chunyuan and Yin, Xu-Cheng and Liu, Cheng-Lin and Jin, Lianwen and Bai, Xiang , year=. OCRBench: on the hidden mystery of OCR in large multimodal models , volume=. Science China Information Sciences , publisher=. doi:10.1007/s11432-024-4235-6 , number=
-
[37]
European conference on computer vision , pages=
Mmbench: Is your multi-modal model an all-around player? , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[38]
European conference on computer vision , pages=
Textcaps: a dataset for image captioning with reading comprehension , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[39]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Vizwiz grand challenge: Answering visual questions from blind people , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[40]
2015 , eprint=
Microsoft COCO: Common Objects in Context , author=. 2015 , eprint=
2015
-
[41]
Efficient Inference of Vision Instruction-Following Models with Elastic Cache
Liu, Zuyan and Liu, Benlin and Wang, Jiahui and Dong, Yuhao and Chen, Guangyi and Rao, Yongming and Krishna, Ranjay and Lu, Jiwen. Efficient Inference of Vision Instruction-Following Models with Elastic Cache. Computer Vision -- ECCV 2024. 2025
2024
-
[42]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Towards video thinking test: A holistic benchmark for advanced video reasoning and understanding , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[43]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
Li, Yifan and Du, Yifan and Zhou, Kun and Wang, Jinpeng and Zhao, Xin and Wen, Ji-Rong. Evaluating Object Hallucination in Large Vision-Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.20
-
[44]
Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , month =
Xing, Long and Huang, Qidong and Dong, Xiaoyi and Lu, Jiajie and Zhang, Pan and Zang, Yuhang and Cao, Yuhang and He, Conghui and Wang, Jiaqi and Wu, Feng and Lin, Dahua , title =. Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , month =. 2025 , pages =
2025
-
[45]
ArXiv , year=
Qwen2.5-VL Technical Report , author=. ArXiv , year=
-
[46]
Towards Interpreting Visual Information Processing in Vision-Language Models , volume =
Neo, Clement and Ong, Luke and Torr, Philip and Geva, Mor and Krueger, David and Barez, Fazl , booktitle =. Towards Interpreting Visual Information Processing in Vision-Language Models , volume =
-
[47]
The 36th Conference on Neural Information Processing Systems (NeurIPS) , year=
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , author=. The 36th Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[48]
arXiv preprint arXiv:2503.23956 , year=
AirCache: Activating Inter-modal Relevancy KV Cache Compression for Efficient Large Vision-Language Model Inference , author=. arXiv preprint arXiv:2503.23956 , year=
-
[49]
Dao, Tri , booktitle=. Flash
-
[50]
Video-LLaV A: Learning United Visual Representation by Alignment Before Projection
Lin, Bin and Ye, Yang and Zhu, Bin and Cui, Jiaxi and Ning, Munan and Jin, Peng and Yuan, Li. Video- LL a VA : Learning United Visual Representation by Alignment Before Projection. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.342
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.