Decomposing how prompting steers behavior
Pith reviewed 2026-06-28 10:36 UTC · model grok-4.3
The pith
Prompts steer LLMs and VLMs by applying affine transformations that mix dimensions to recover instructed task geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
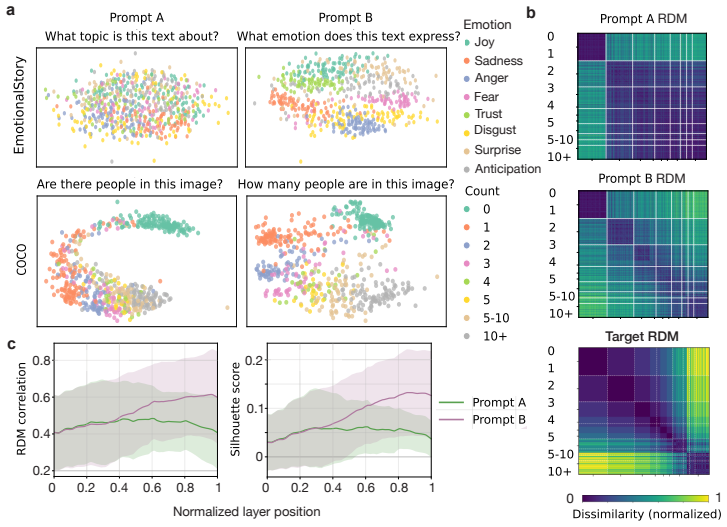
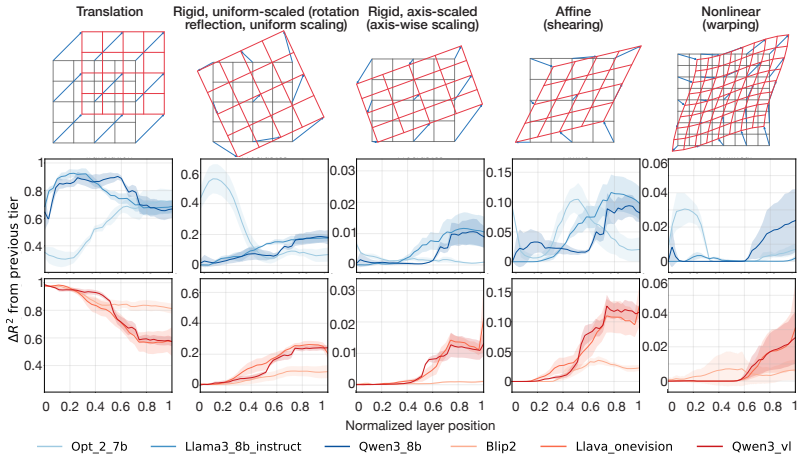
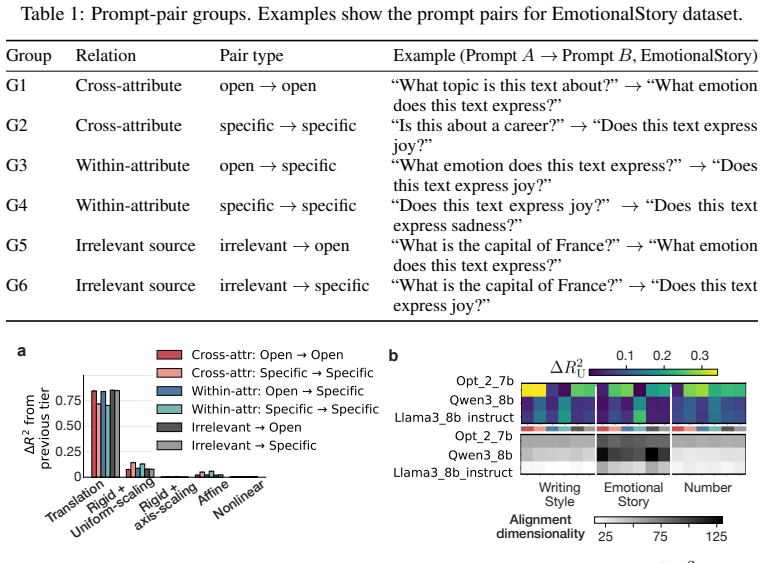
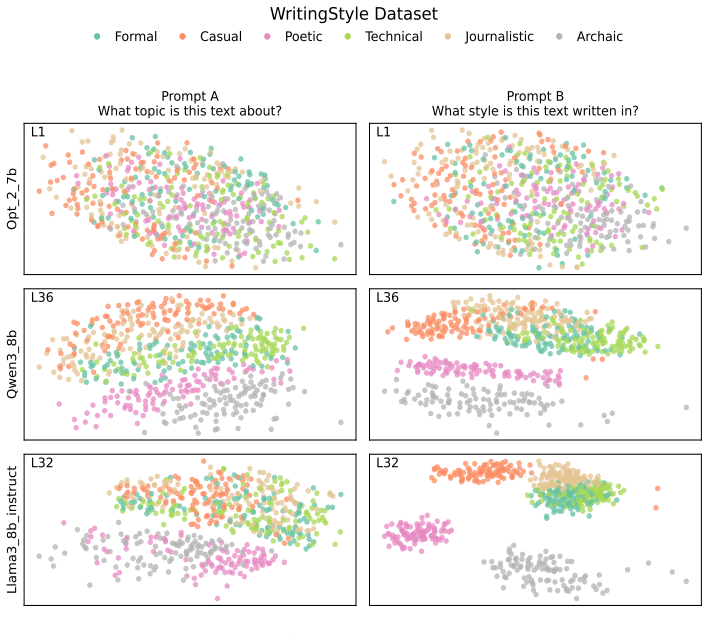
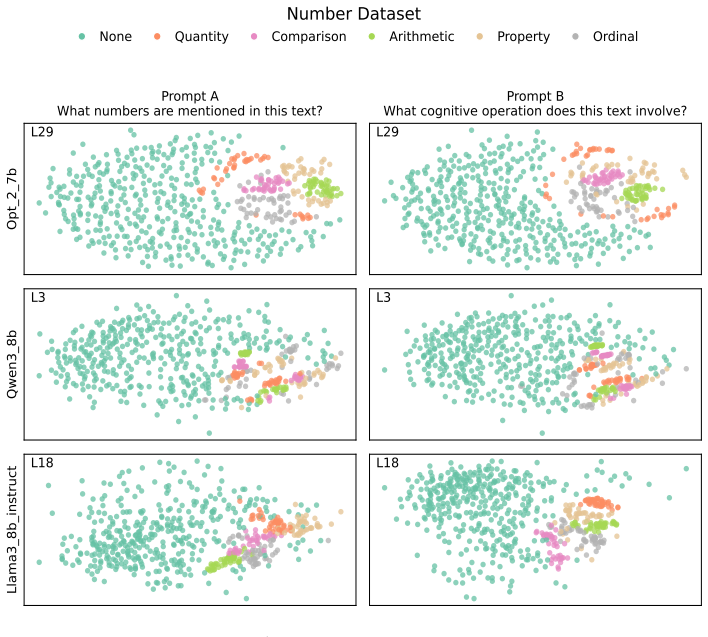
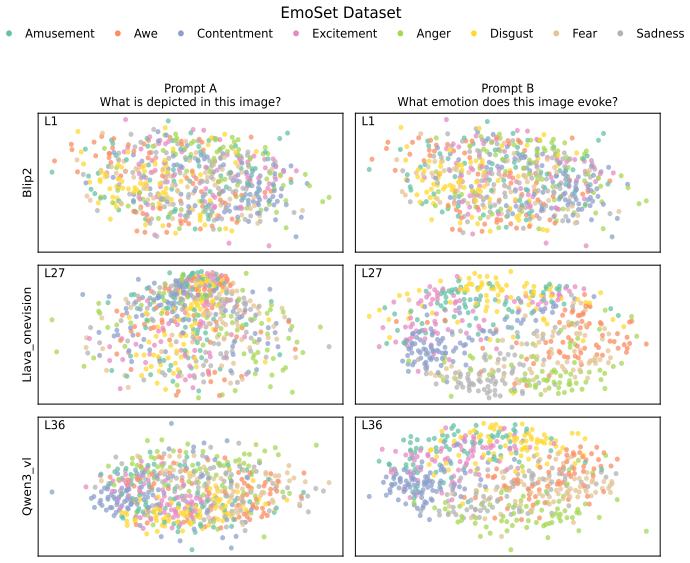
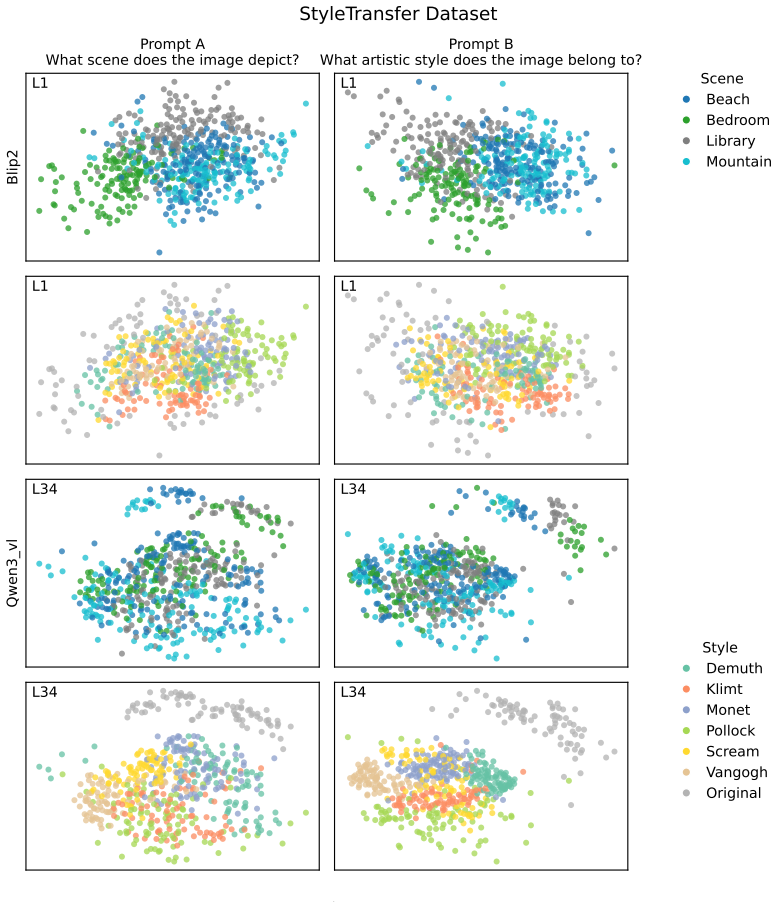
Across three LLMs, three VLMs, and six datasets, prompts reshape hidden-state geometry toward the instructed task structure. Cross-validated variance shows most activation change is captured by shape-preserving maps, with tier profiles varying by model and task. Although earlier tiers improve behavioral agreement, affine transformation is the first to nearly recover target-prompt task geometry and yields corresponding behavioral gains, indicating that cross-dimensional linear mixing is a key mechanism by which prompts reorganize representations.
What carries the argument
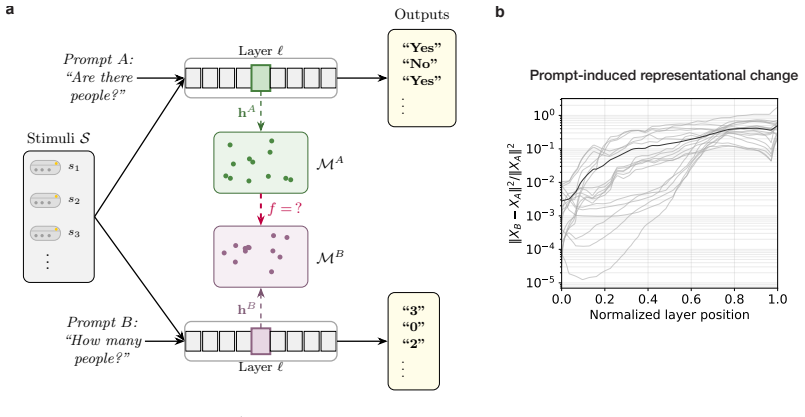
Nested geometric decomposition framework that applies stimulus-invariant maps (translation, rigid with uniform scaling, sequential axis scaling, affine, nonlinear) to align prompt-A and prompt-B representations, then causally replaces single-layer activations to test recovery of geometry and behavior.
If this is right
- Prompts consistently reshape representations toward instructed task structure across text and image domains.
- Much prompt-induced activation change is captured by shape-preserving maps such as translation and rigid transformation.
- Tier profiles reveal model- and task-specific routing strategies across layers.
- Affine transformation produces the largest gains in recovering task geometry and aligning behavior.
Where Pith is reading between the lines
- The same decomposition could be applied to other interventions such as fine-tuning or in-context examples to compare their geometric signatures.
- If affine mixing is the critical step, prompt design might be improved by explicitly encouraging cross-dimensional alignment in the instruction.
- The framework suggests testing whether similar geometric tiers explain steering in non-prompt settings such as activation editing.
Load-bearing premise
Prompt-induced changes can be fully captured by stimulus-invariant geometric maps applied to hidden states, and causally replacing a single layer's activations isolates each transformation tier without confounding effects from other layers or non-geometric factors.
What would settle it
In a new set of models or tasks, replacing activations with the affine-mapped version fails to recover target-prompt representational geometry or behavioral agreement on held-out stimuli.
Figures
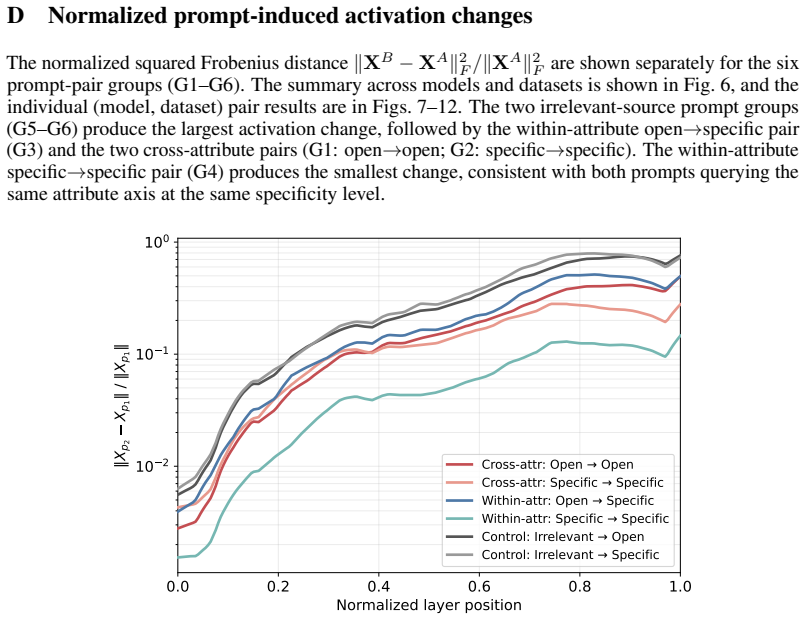
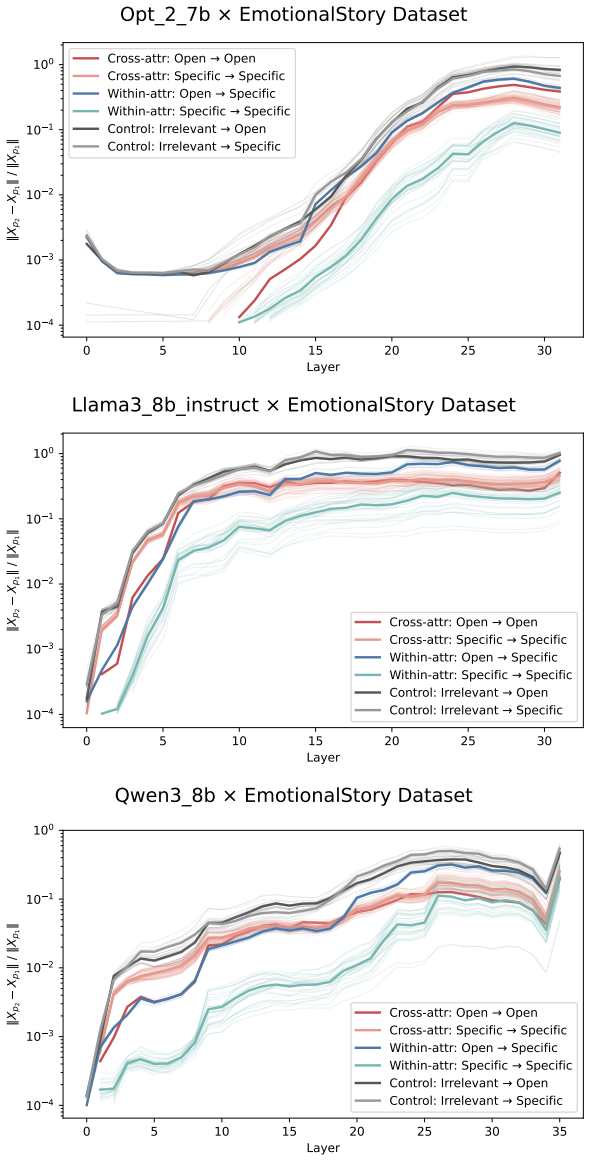
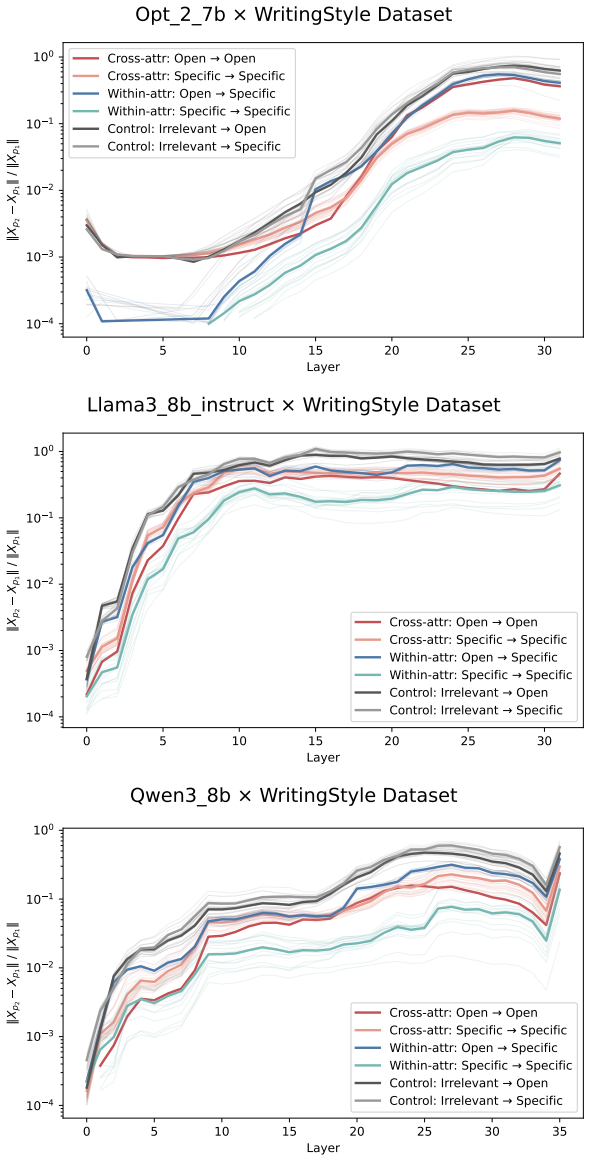
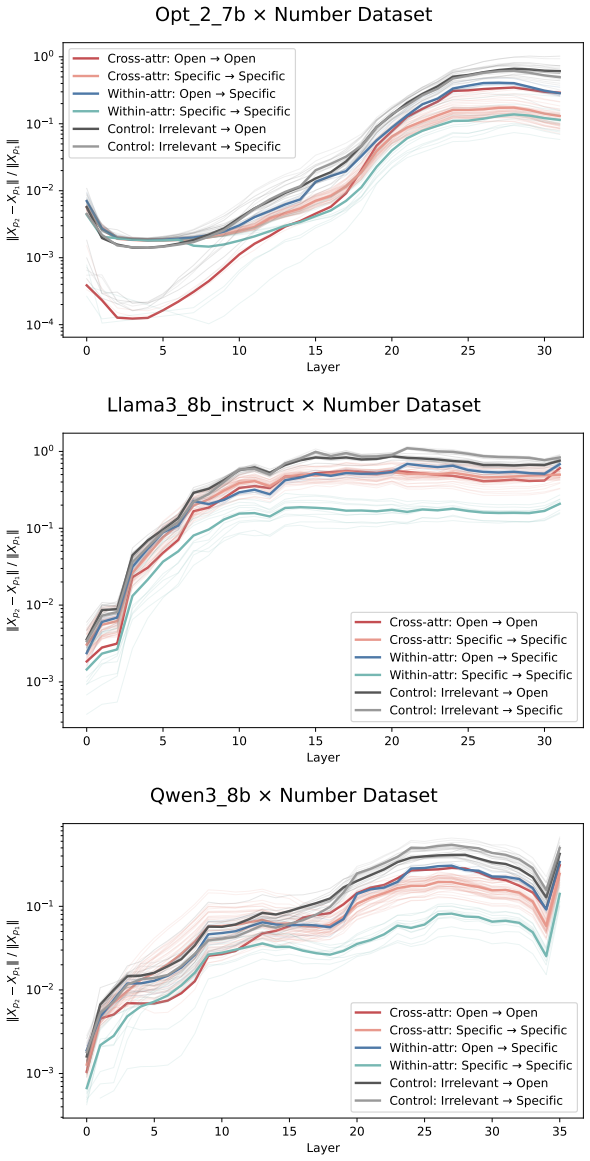
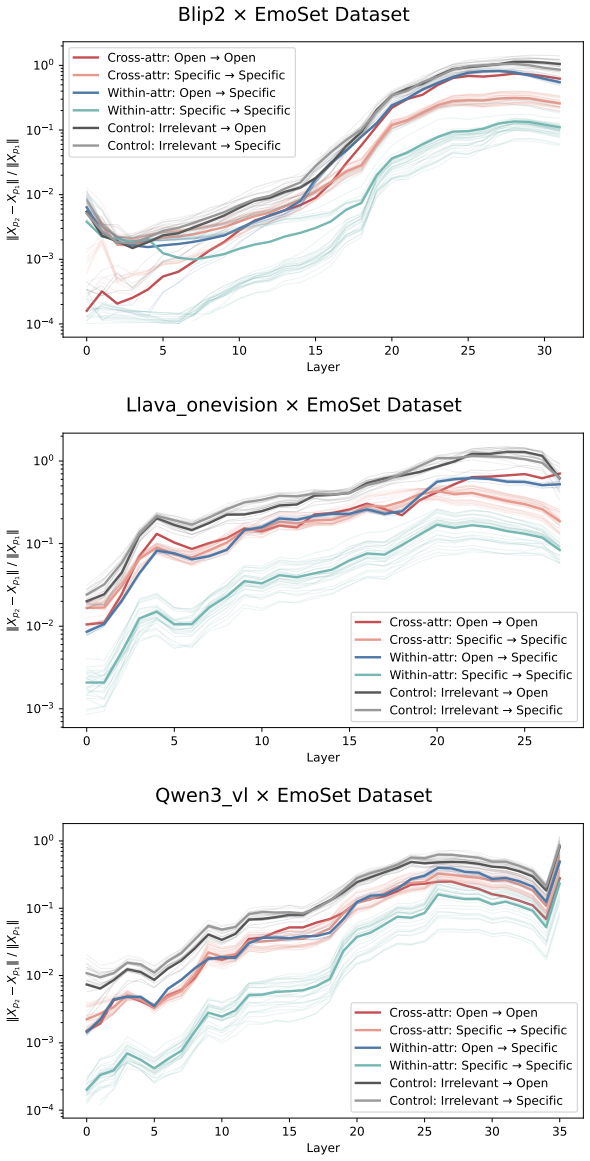
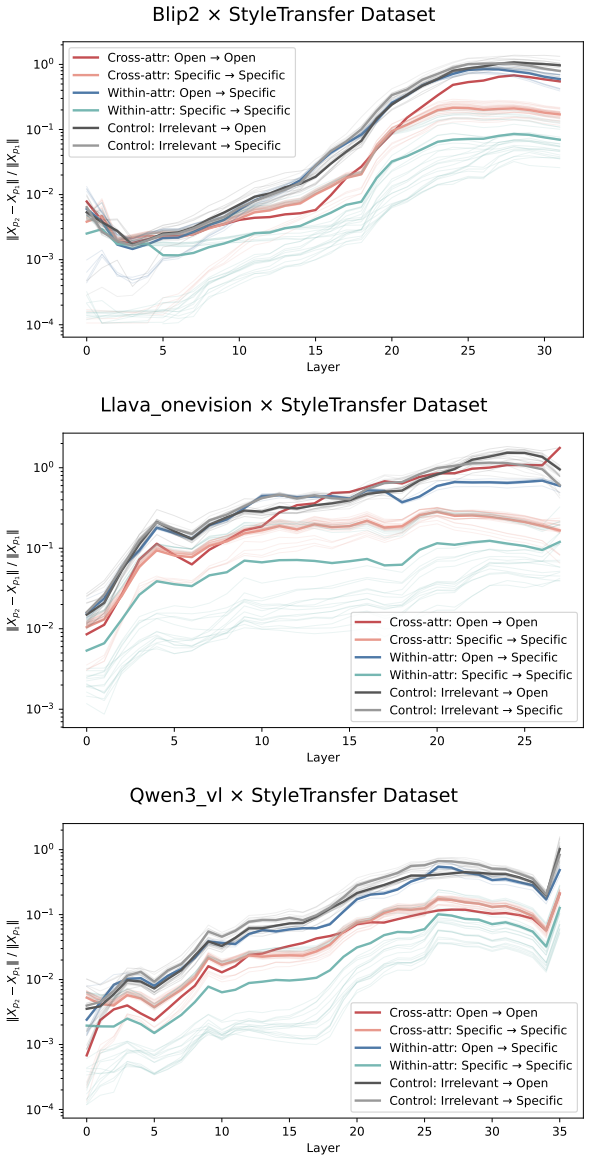
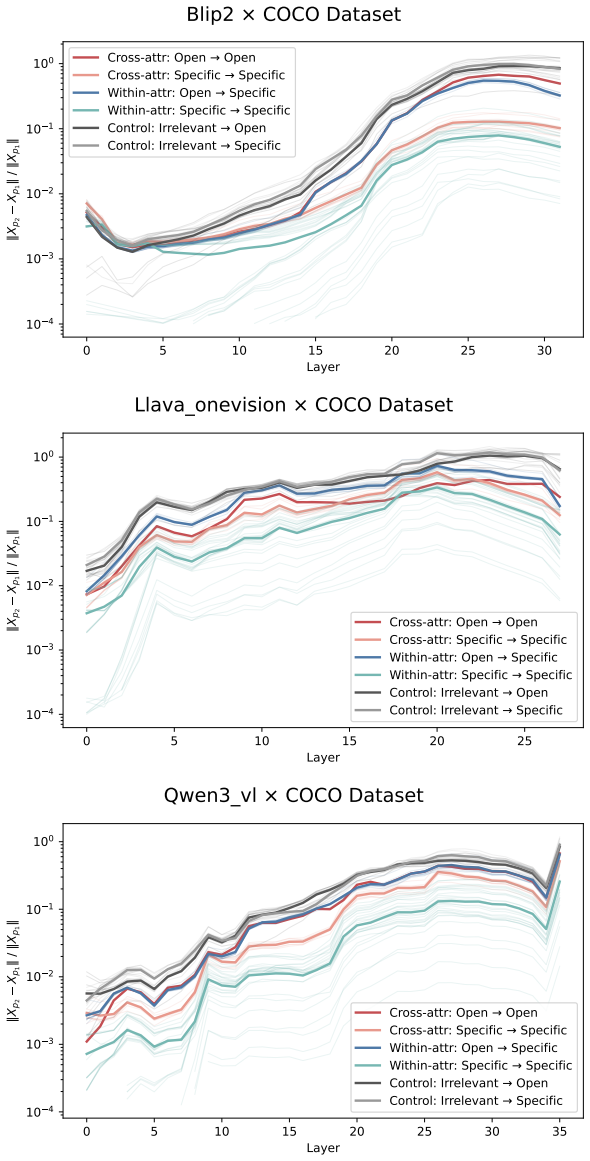
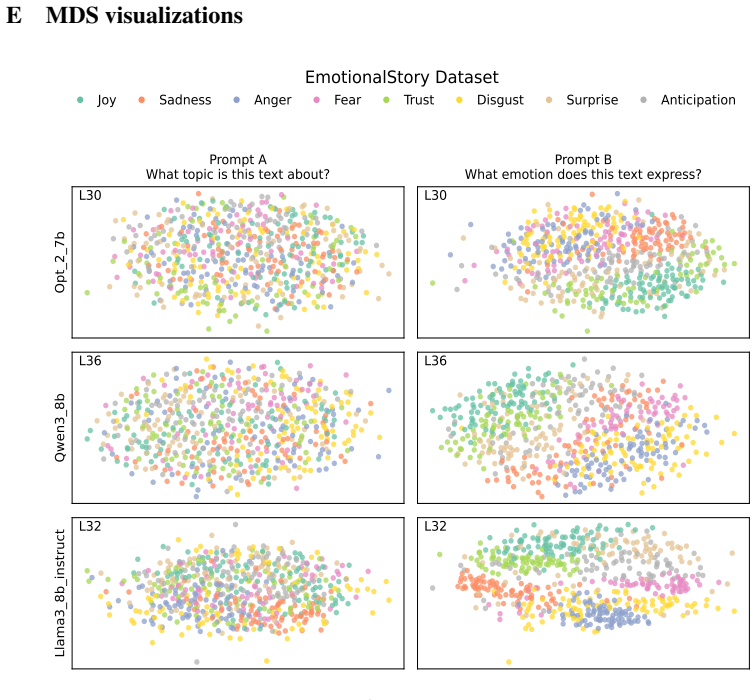
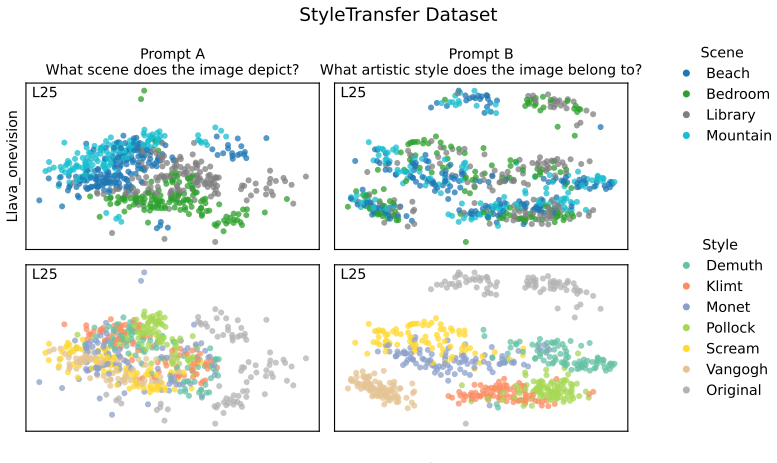
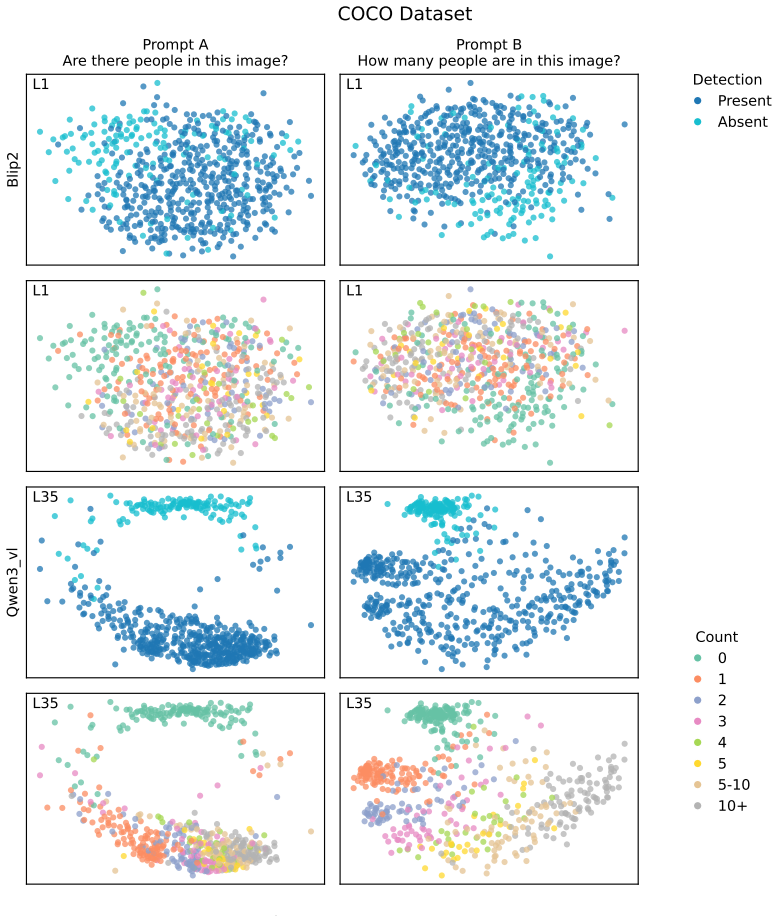
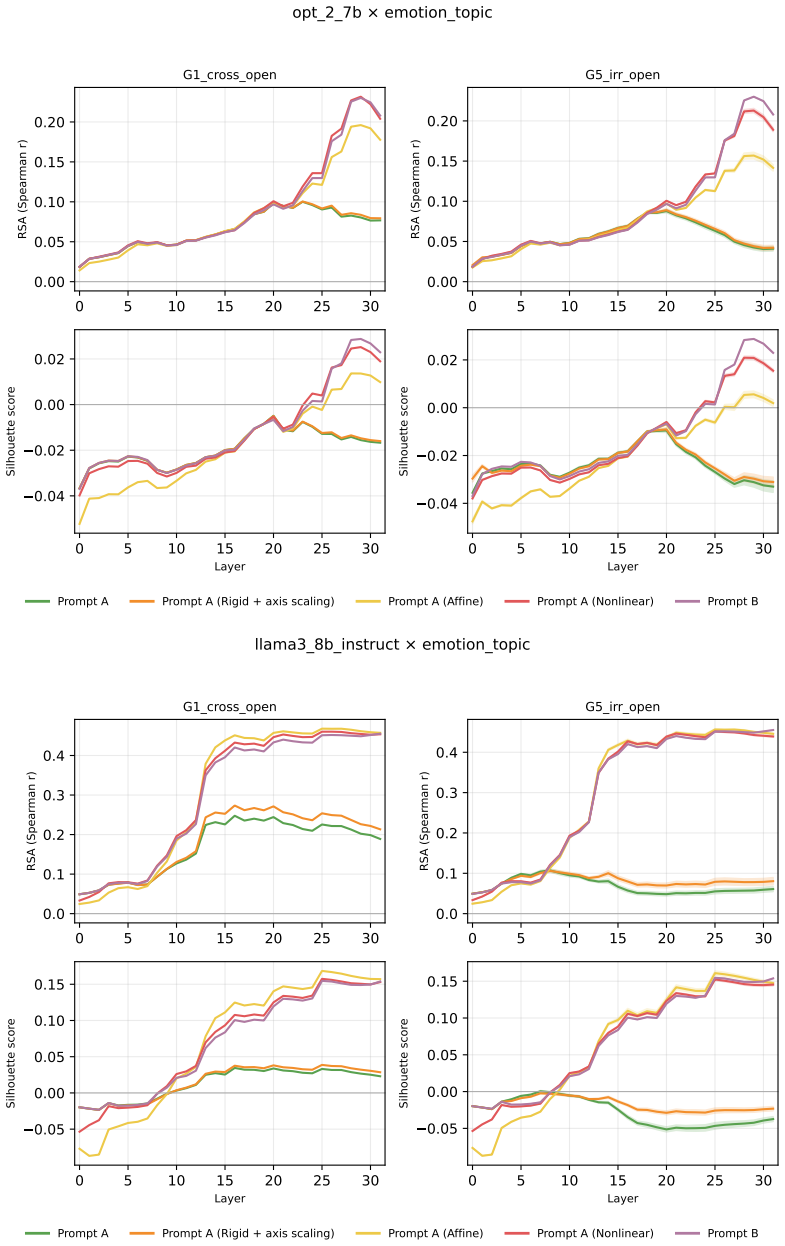
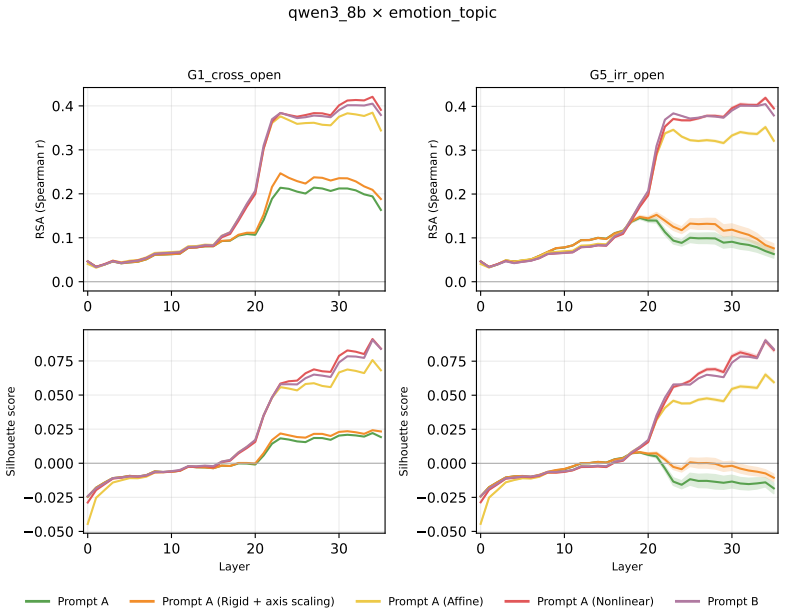
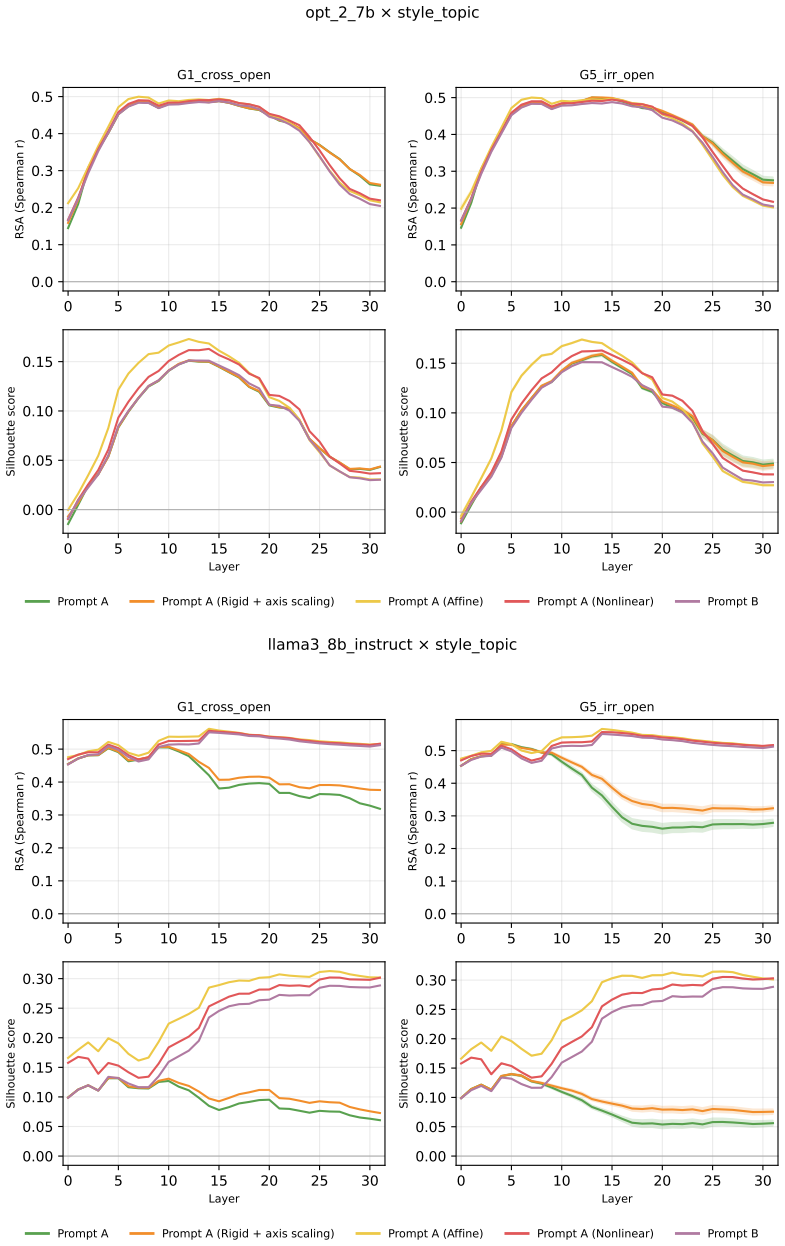
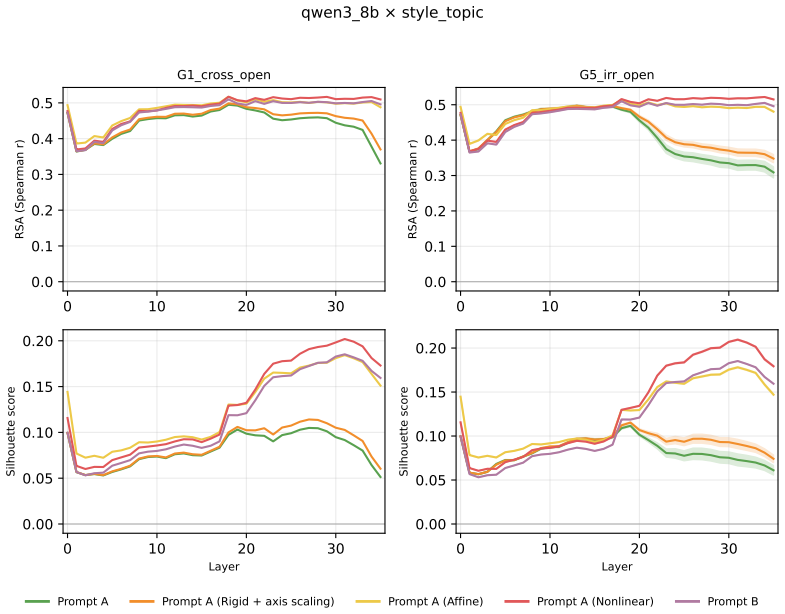
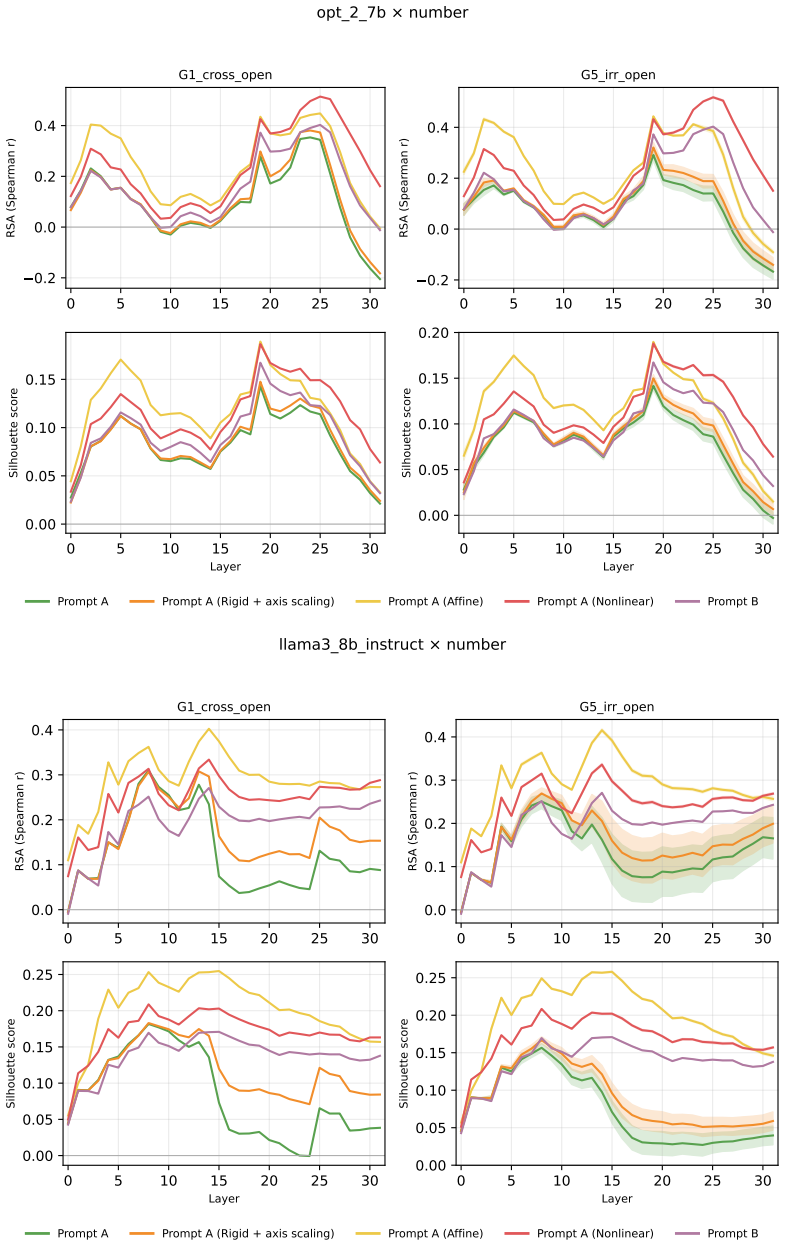
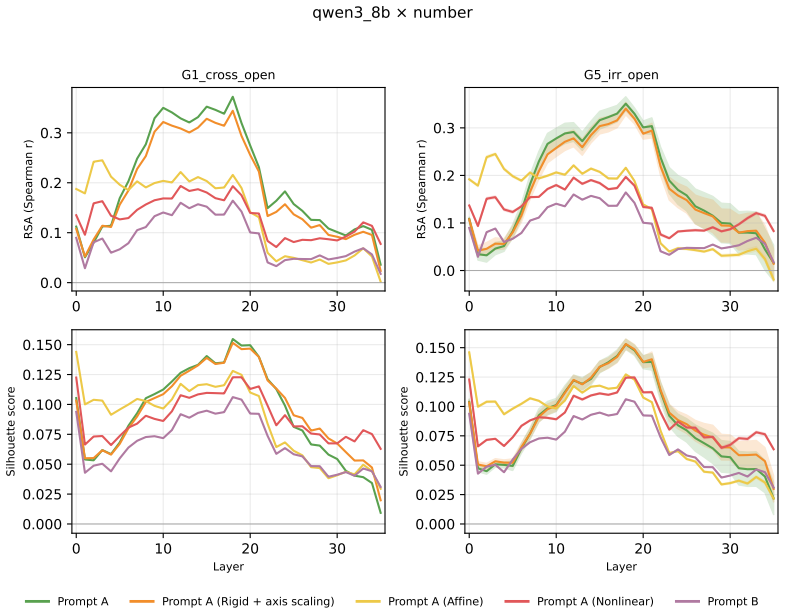
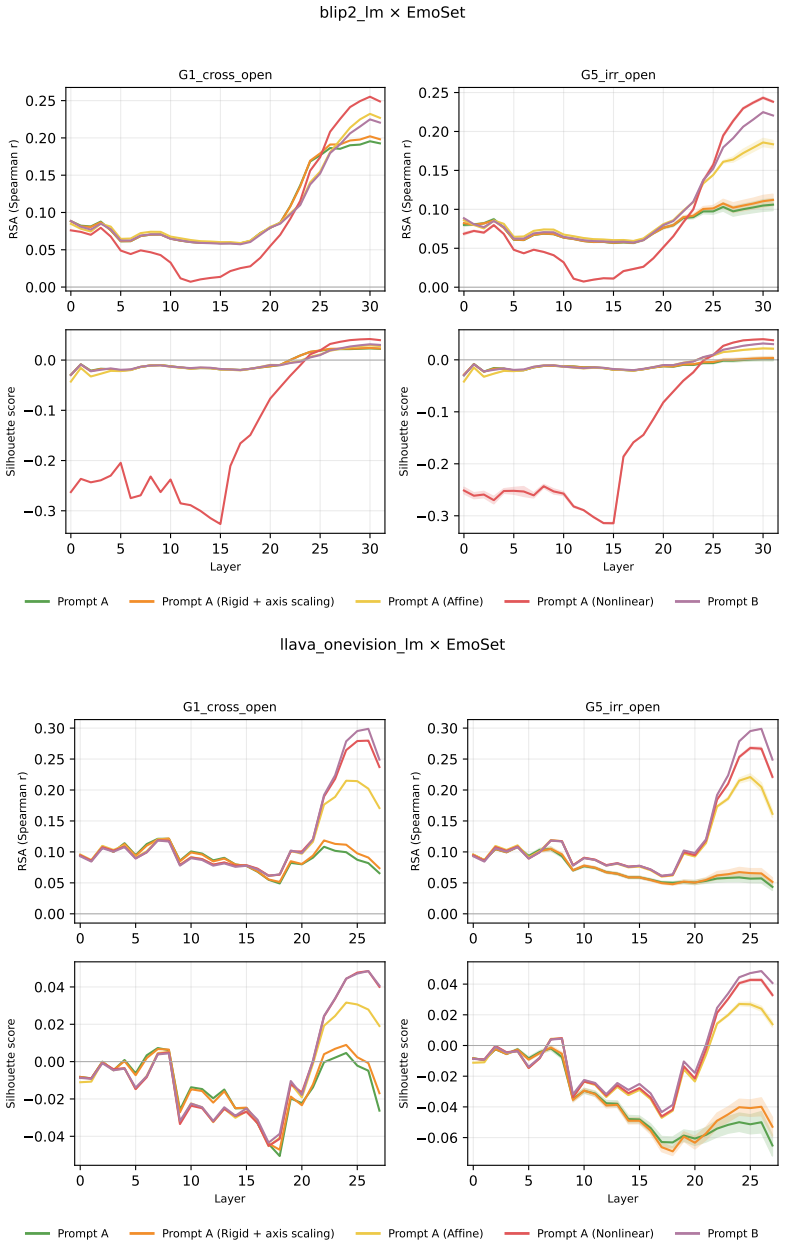
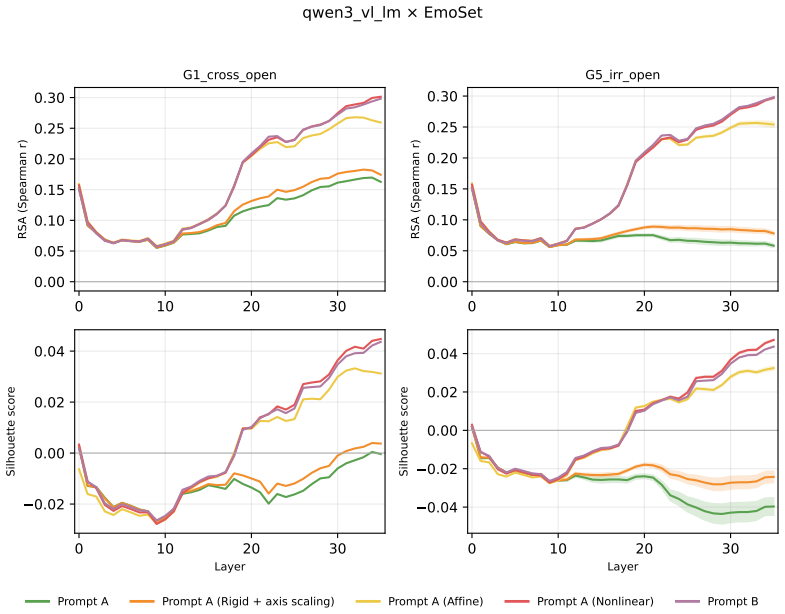
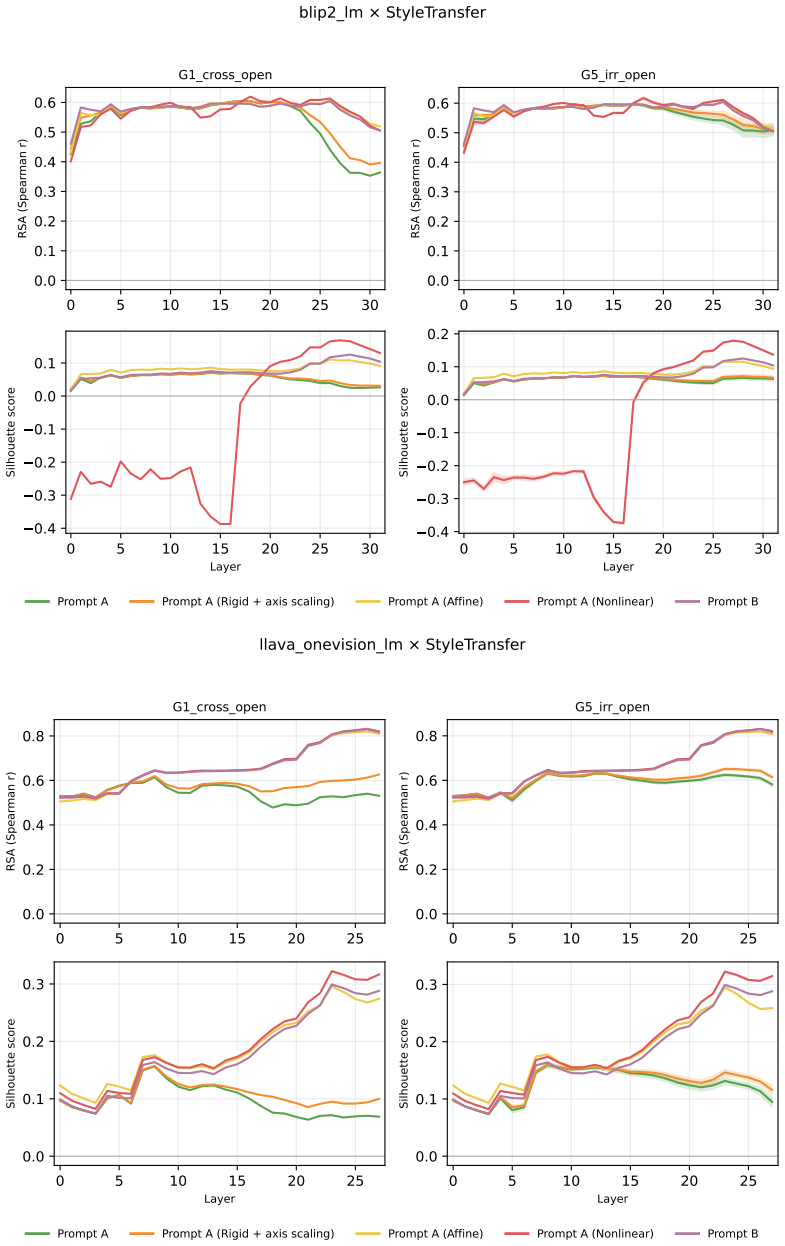
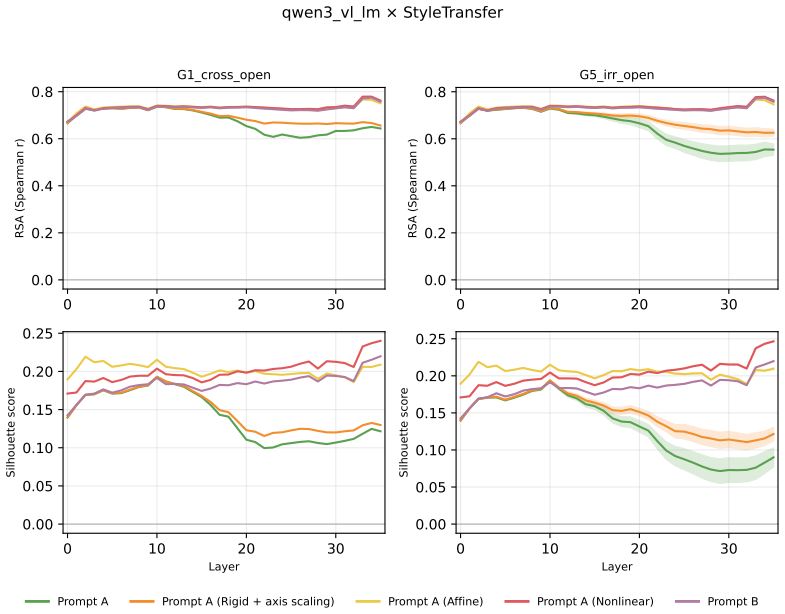
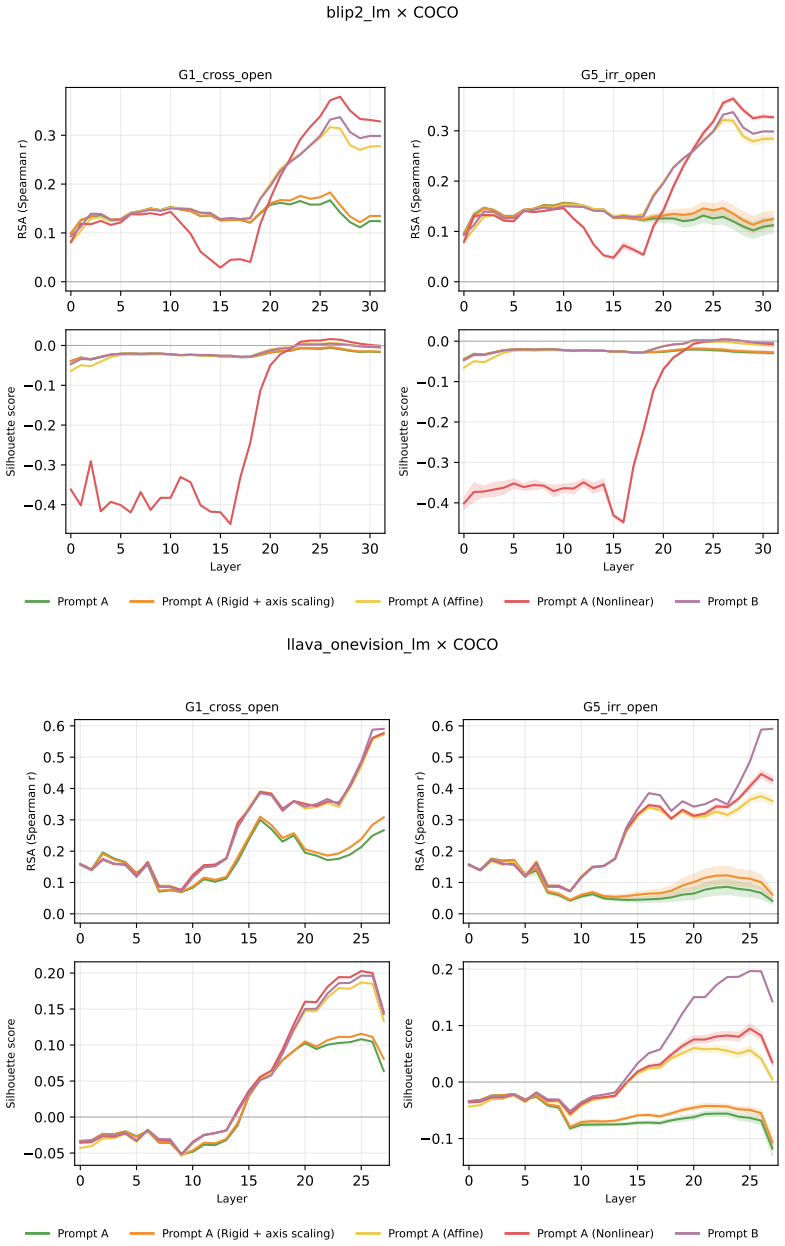
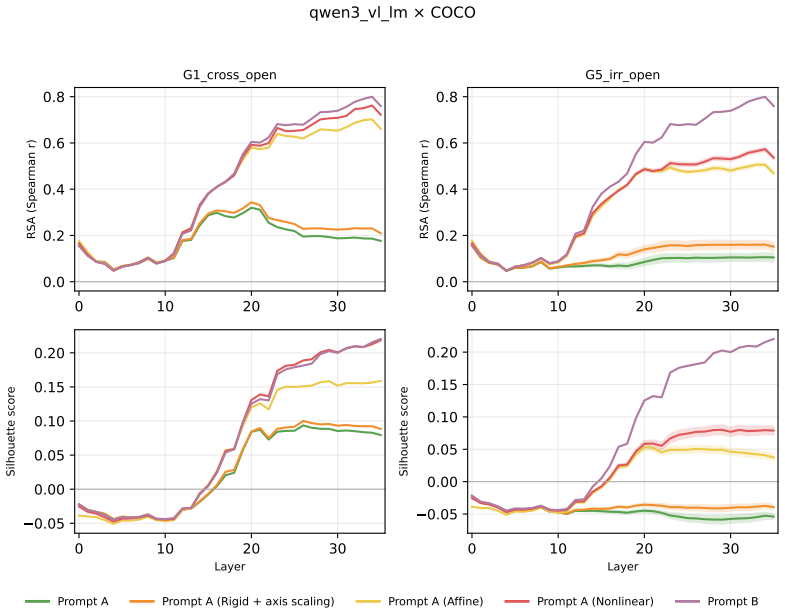
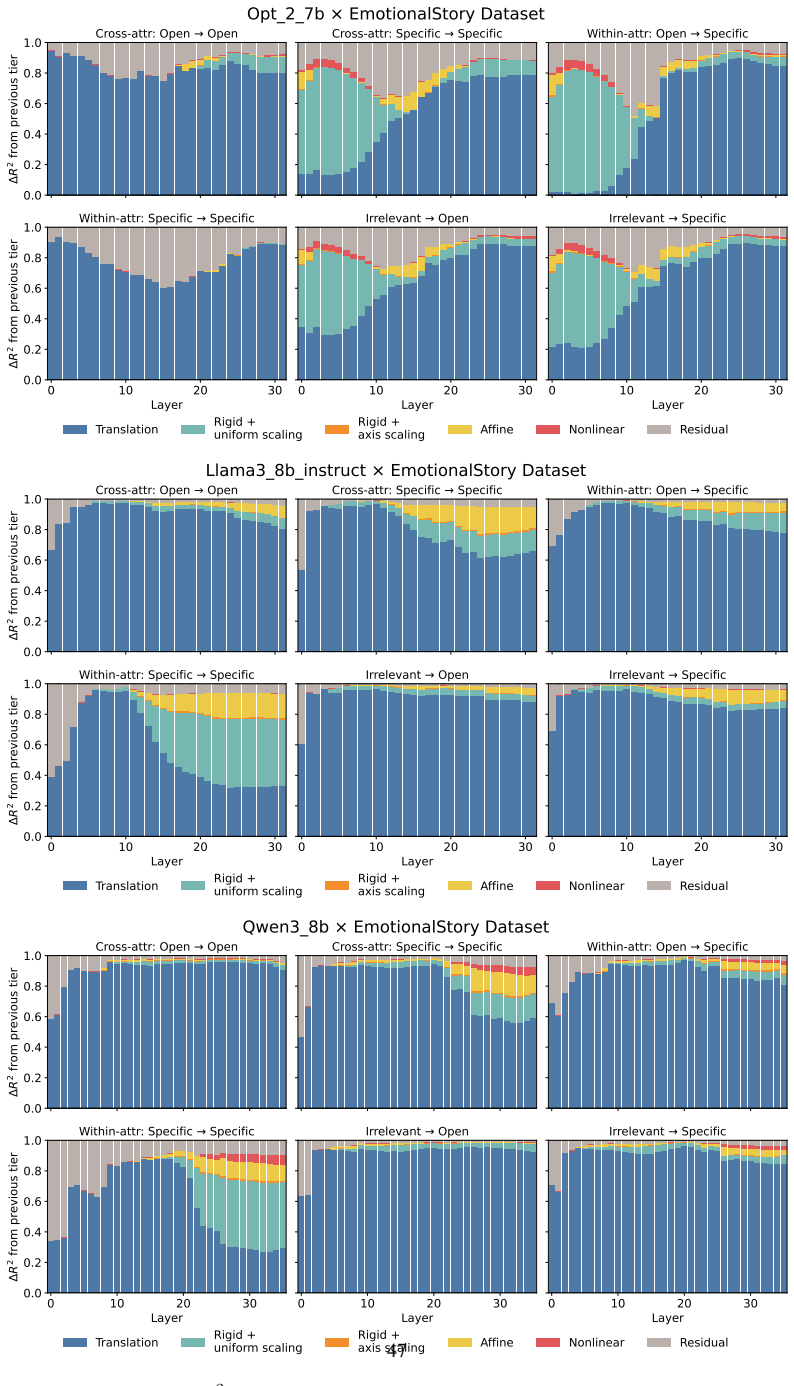
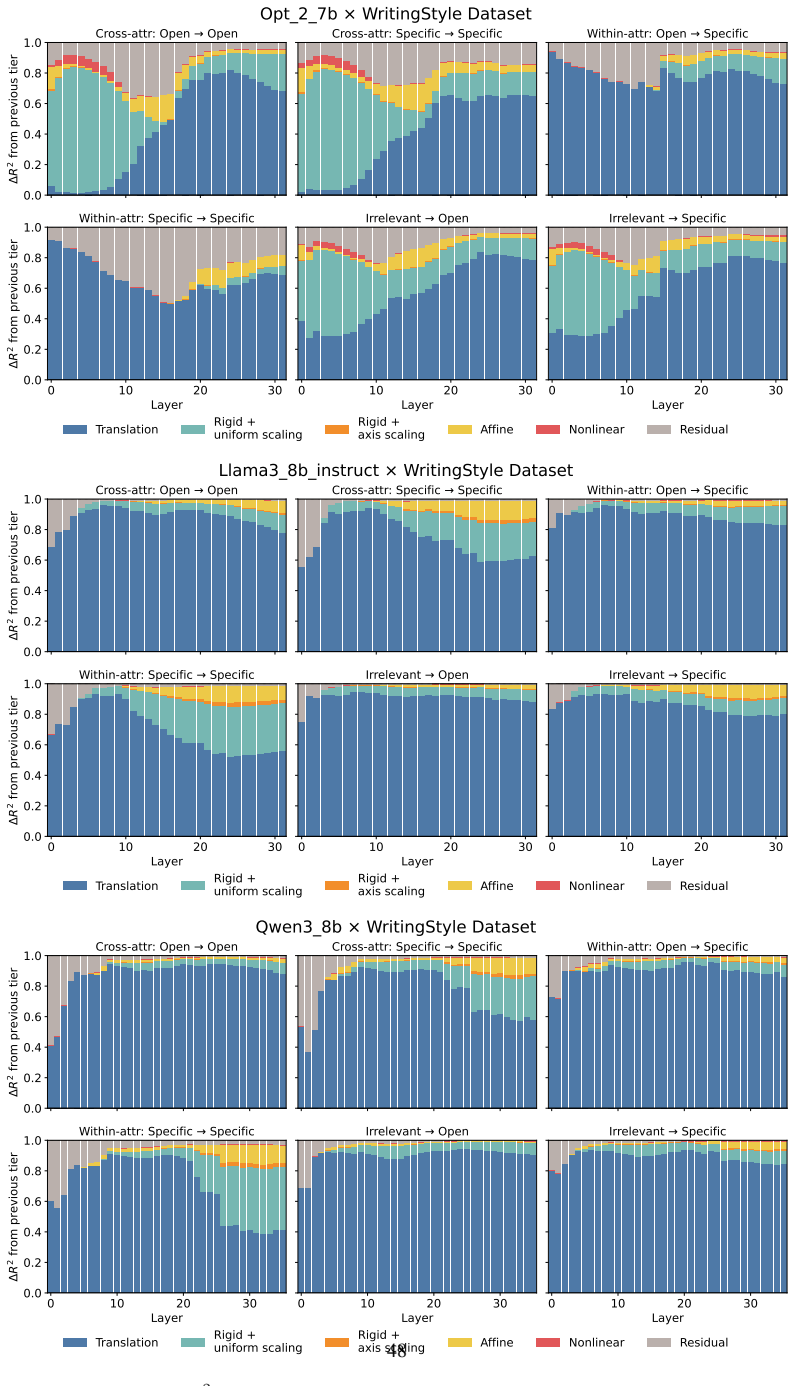
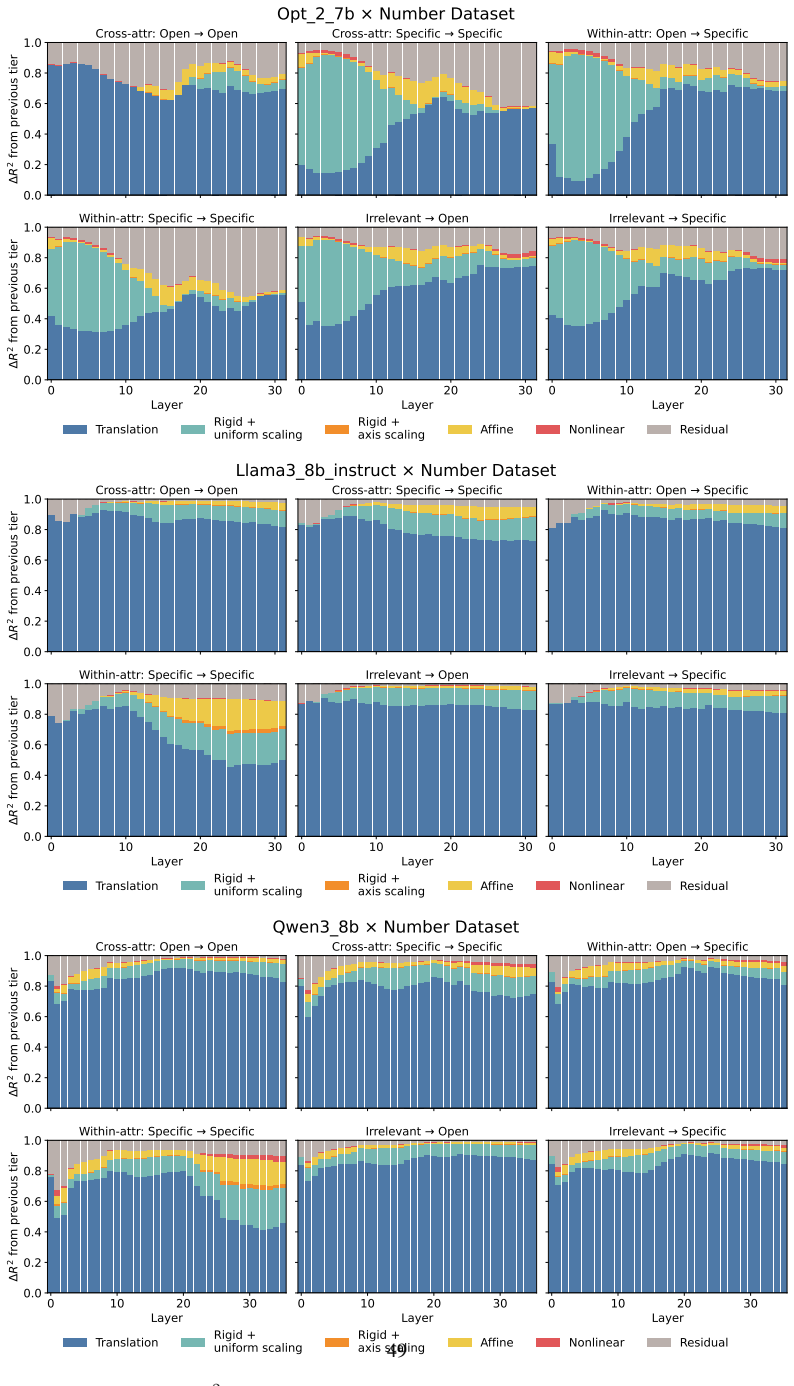
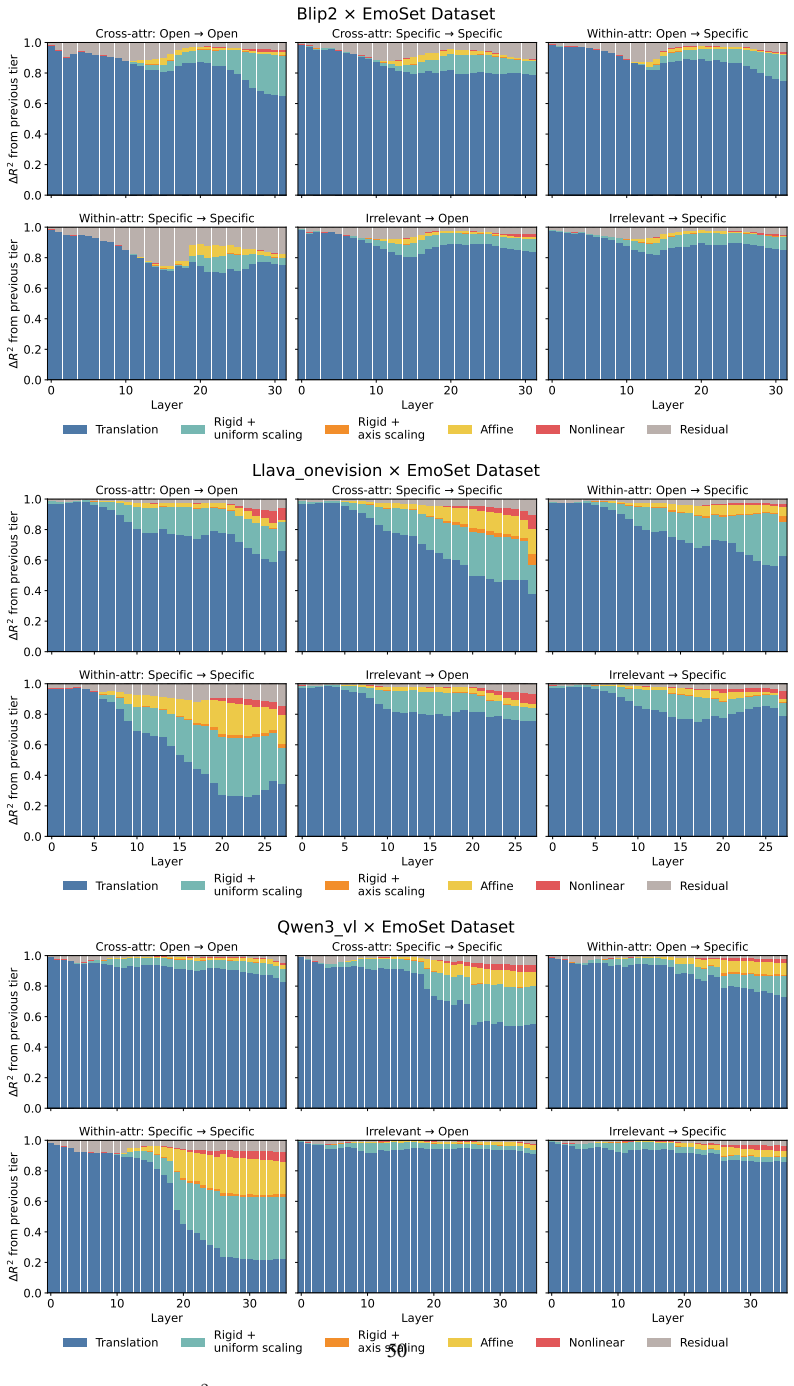
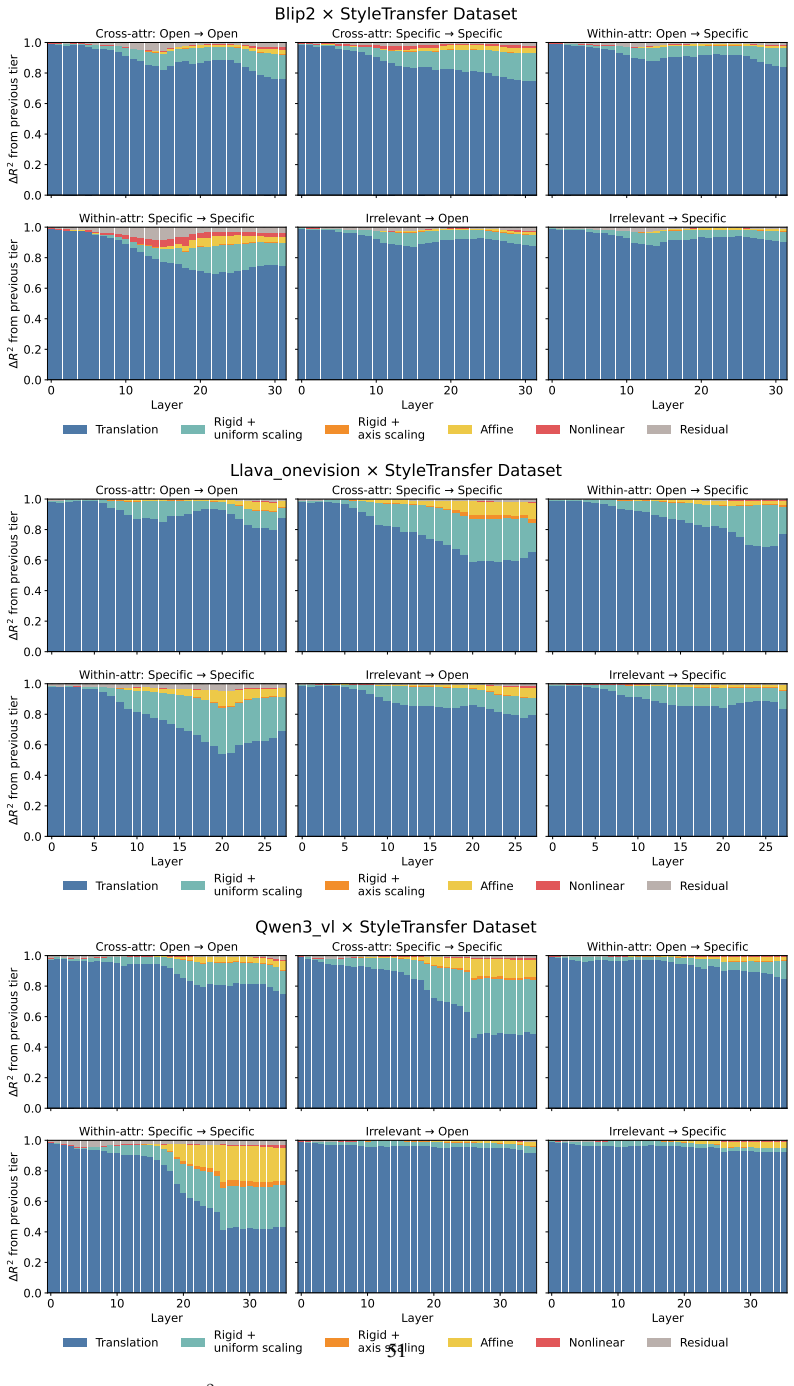
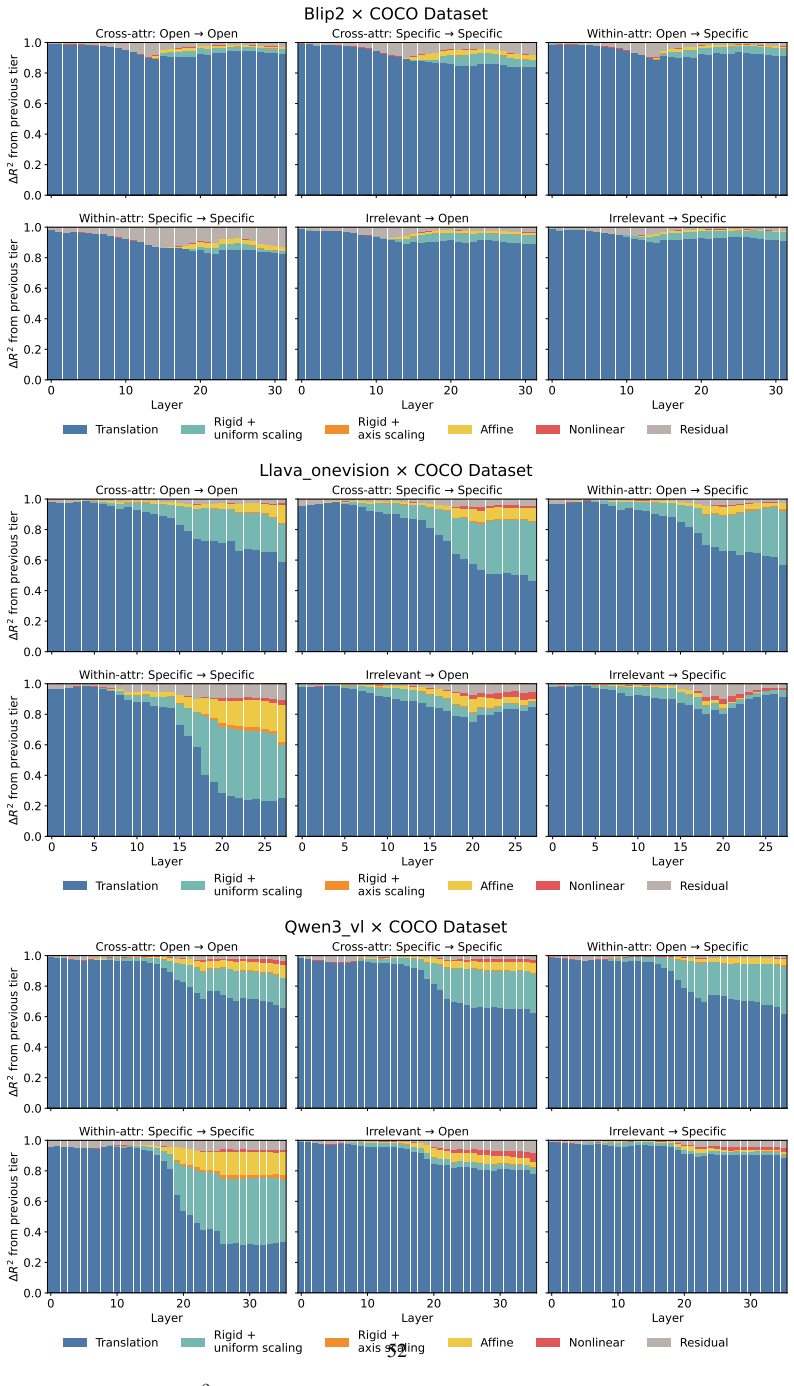

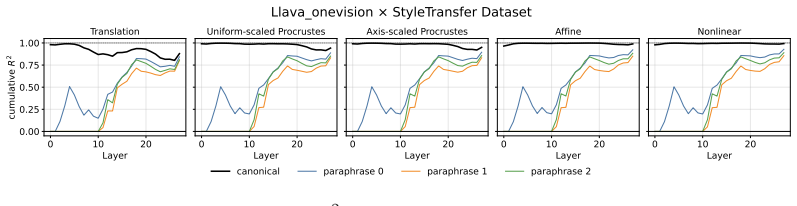
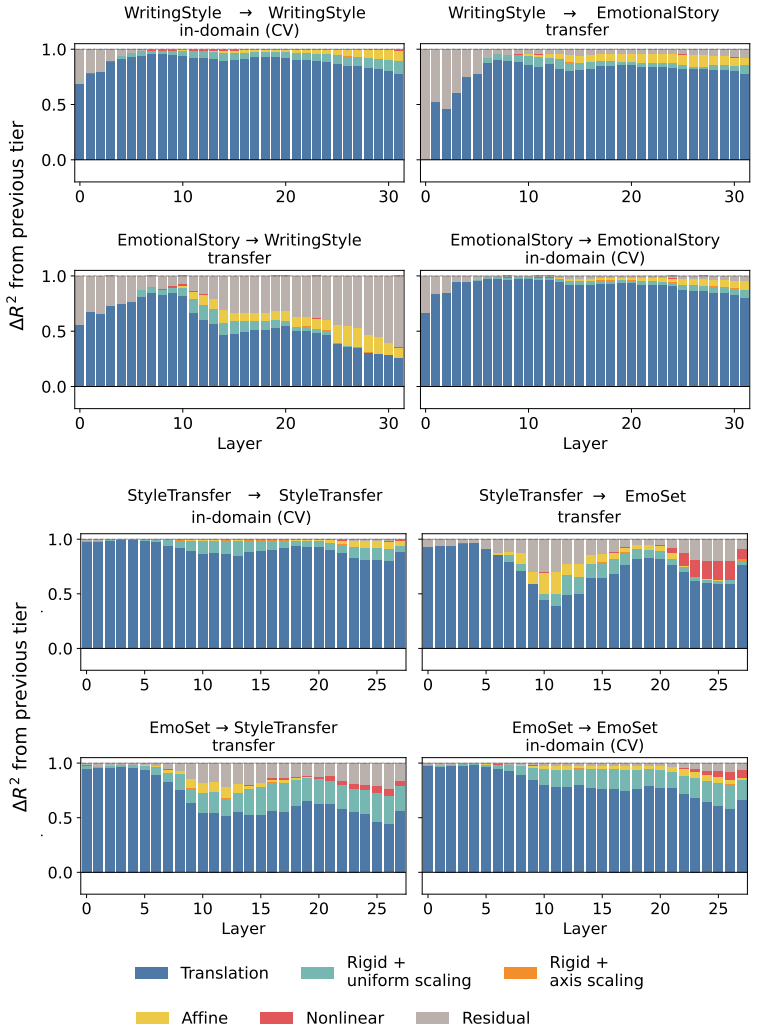
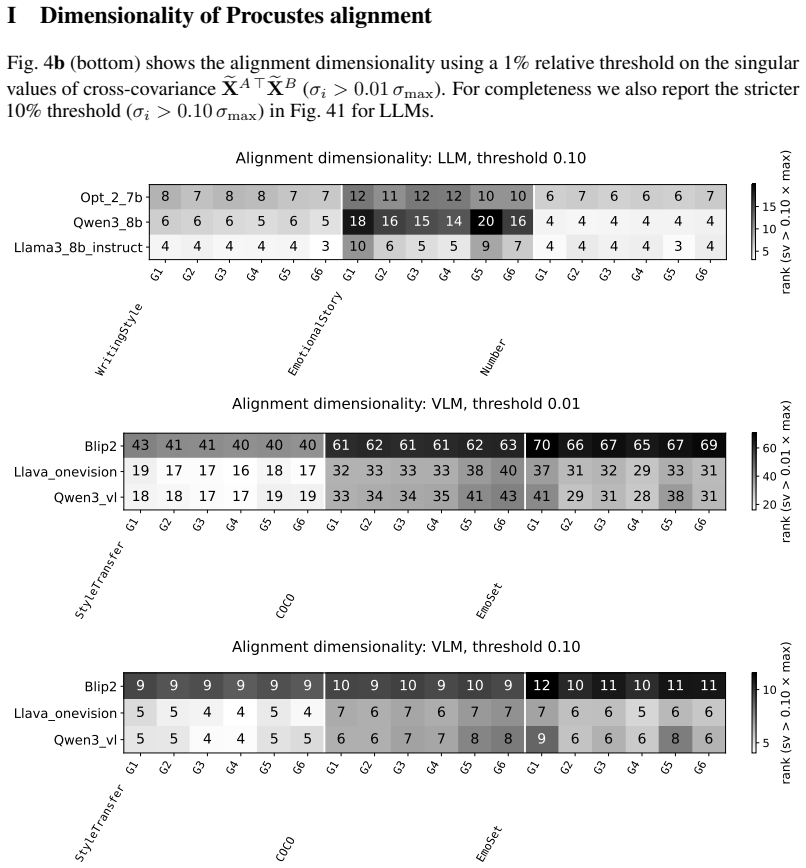
read the original abstract
Prompting steers large language models (LLMs) and vision-language models (VLMs) without weight updates, but it remains unclear how instruction changes reshape internal representations to produce behavior. We introduce a nested geometric decomposition framework that treats prompting as a transformation of the representational geometry of the content following the prompt. For each prompt pair, we align representations of the same stimuli under two prompts using increasingly expressive stimulus-invariant maps: translation, rigid transformation with uniform scaling, sequential axis scaling, affine transformation, and nonlinear transformation. We then causally test each map by replacing a single layer's prompt-A hidden state for held-out stimuli with its mapped counterpart and measuring recovery of prompt-B representational geometry and behavior. Across three LLMs, three VLMs, and six text or image datasets spanning style, emotion, scene content, and number, prompts consistently reshape representations toward the instructed task structure. Cross-validated variance decomposition shows that much prompt-induced activation change is captured by shape-preserving maps, especially translation and rigid transformation with uniform scaling, while tier profiles reveal model- and task-specific routing strategies across layers. Crucially, although translation and rigid tiers already improve behavioral agreement, affine transformation is the first tier to nearly recover target-prompt task geometry and yields corresponding behavioral gains. This suggests that cross-dimensional linear mixing is a key mechanism by which prompts reorganize representations toward instructed task structure. Our framework decomposes prompt-induced representational change into interpretable geometric components and reveals how models route task-relevant structure to produce prompt-driven behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a nested geometric decomposition framework that models prompting as stimulus-invariant transformations (translation, rigid+scaling, axis scaling, affine, nonlinear) of hidden-state geometry in LLMs and VLMs. For each prompt pair it fits these maps on training stimuli, then performs causal interventions by replacing a single layer's prompt-A activations for held-out stimuli with the mapped version and measures recovery of prompt-B representational geometry and downstream behavior. Across three LLMs, three VLMs and six datasets it reports that shape-preserving maps capture much of the activation change while affine maps are the first tier to nearly recover target task geometry and produce corresponding behavioral gains, suggesting cross-dimensional linear mixing as a key mechanism.
Significance. If the central claims hold after addressing isolation concerns, the framework supplies a concrete, testable decomposition of prompt effects into interpretable geometric tiers, with the variance-decomposition results and multi-model/multi-task evaluation providing reusable tools for mechanistic interpretability. The explicit causal-intervention design and the finding that affine maps outperform earlier tiers are potentially high-impact contributions.
major comments (2)
- [Causal intervention procedure] Causal intervention procedure (abstract and methods): the headline claim that affine transformation is the first tier to nearly recover target-prompt task geometry rests on single-layer replacement. Because subsequent layers continue to process the replaced activations under the original prompt-A weights and context, recovery may be modulated by non-geometric computations downstream; this undermines the isolation needed to attribute behavioral gains specifically to cross-dimensional linear mixing rather than tier interactions or later layers.
- [Results on tier profiles] Results on tier profiles and behavioral recovery: the assertion that affine is 'the first tier to nearly recover' and 'yields corresponding behavioral gains' requires explicit quantitative support (effect sizes, cross-validated R² or cosine similarities with confidence intervals, and statistical comparisons across tiers) to be load-bearing for the mechanism claim; without these the routing-strategy conclusions remain under-specified.
minor comments (2)
- [Abstract] Abstract: quantitative metrics, dataset sizes, number of stimuli, and exclusion criteria are absent, making it impossible to evaluate the strength of the reported findings from the summary alone.
- [Methods] Notation for maps: the precise parameterization of each tier (e.g., how uniform scaling is enforced in the rigid tier, how the affine matrix is constrained to be stimulus-invariant) should be stated explicitly with equations to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the two major comments below, agreeing where the concerns are valid and outlining targeted revisions.
read point-by-point responses
-
Referee: Causal intervention procedure (abstract and methods): the headline claim that affine transformation is the first tier to nearly recover target-prompt task geometry rests on single-layer replacement. Because subsequent layers continue to process the replaced activations under the original prompt-A weights and context, recovery may be modulated by non-geometric computations downstream; this undermines the isolation needed to attribute behavioral gains specifically to cross-dimensional linear mixing rather than tier interactions or later layers.
Authors: We agree that single-layer replacement does not fully isolate the geometric map from downstream processing under prompt-A weights, and this limits strong causal attribution solely to cross-dimensional mixing. The design measures geometry recovery directly at the intervention layer (via cosine similarity or similar) while behavioral recovery reflects propagation; tier-wise differences still indicate that affine maps provide a better match to target geometry than earlier tiers. We will revise the methods and discussion to explicitly note this limitation and add a sentence clarifying that full isolation would require multi-layer interventions, which we flag as future work. revision: partial
-
Referee: Results on tier profiles and behavioral recovery: the assertion that affine is 'the first tier to nearly recover' and 'yields corresponding behavioral gains' requires explicit quantitative support (effect sizes, cross-validated R² or cosine similarities with confidence intervals, and statistical comparisons across tiers) to be load-bearing for the mechanism claim; without these the routing-strategy conclusions remain under-specified.
Authors: We accept that the current presentation of tier profiles would benefit from more explicit quantitative backing. The manuscript already reports cross-validated variance decomposition, but we will expand the results section to include per-tier effect sizes, confidence intervals on cosine similarities and behavioral metrics, and statistical comparisons (e.g., paired tests) across tiers. These additions will be made in the revision to strengthen the mechanism claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's framework fits stimulus-invariant geometric maps (translation through nonlinear) to align prompt-A and prompt-B representations, then measures recovery of geometry and behavior after single-layer replacement on held-out stimuli, with cross-validated variance decomposition. These steps are empirical measurements of explained variance and causal effects rather than any reduction of a claimed result to its own fitted inputs by construction, self-definitional equivalence, or load-bearing self-citation. No equations or claims in the abstract or described methods rename known patterns, import uniqueness from prior author work, or smuggle ansatzes; the central claim about affine tiers follows directly from the measured recovery metrics without circular collapse to the fitting procedure itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- map parameters per tier
axioms (1)
- domain assumption Prompt effects on representations can be modeled as stimulus-invariant geometric transformations
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2308.10248 , year=
Steering language models with activation engineering , author=. arXiv preprint arXiv:2308.10248 , year=
-
[2]
arXiv preprint arXiv:2310.01405 , year=
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
-
[3]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Singh, Shashwat and Ravfogel, Shauli and Herzig, Jonathan and Aharoni, Roee and Cotterell, Ryan and Kumaraguru, Ponnurangam , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[4]
2nd Workshop on Models of Human Feedback for AI Alignment , year=
Angular Steering: Behavior Control via Rotation in Activation Space , author=. 2nd Workshop on Models of Human Feedback for AI Alignment , year=
-
[5]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Householder pseudo-rotation: A novel approach to activation editing in LLMs with direction-magnitude perspective , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[7]
arXiv preprint arXiv:2410.16314 , year=
Steering large language models using conceptors: Improving addition-based activation engineering , author=. arXiv preprint arXiv:2410.16314 , year=
-
[8]
arXiv preprint arXiv:2603.02237 , year=
Concept Heterogeneity-aware Representation Steering , author=. arXiv preprint arXiv:2603.02237 , year=
-
[9]
arXiv preprint arXiv:2601.19375 , year=
Selective Steering: Norm-Preserving Control Through Discriminative Layer Selection , author=. arXiv preprint arXiv:2601.19375 , year=
-
[10]
arXiv preprint arXiv:2409.05907 , year=
Programming refusal with conditional activation steering , author=. arXiv preprint arXiv:2409.05907 , year=
-
[11]
arXiv preprint arXiv:2510.04309 , year=
Activation Steering with a Feedback Controller , author=. arXiv preprint arXiv:2510.04309 , year=
-
[12]
arXiv preprint arXiv:2602.17560 , year=
ODESteer: A Unified ODE-Based Steering Framework for LLM Alignment , author=. arXiv preprint arXiv:2602.17560 , year=
-
[13]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Sake: Steering activations for knowledge editing , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[14]
arXiv preprint arXiv:2506.07335 , year=
Improving llm reasoning through interpretable role-playing steering , author=. arXiv preprint arXiv:2506.07335 , year=
-
[15]
arXiv preprint arXiv:2511.05408 , year=
Steering Language Models with Weight Arithmetic , author=. arXiv preprint arXiv:2511.05408 , year=
-
[16]
arXiv e-prints , pages=
On the Non-Identifiability of Steering Vectors in Large Lan-guage Models , author=. arXiv e-prints , pages=
-
[17]
The Fourteenth International Conference on Learning Representations , year=
AlphaSteer: Learning Refusal Steering with Principled Null-Space Constraint , author=. The Fourteenth International Conference on Learning Representations , year=
-
[18]
arXiv preprint arXiv:2505.20809 , year=
Improved representation steering for language models , author=. arXiv preprint arXiv:2505.20809 , year=
-
[19]
arXiv preprint arXiv:2603.09313 , year=
Curveball Steering: The Right Direction To Steer Isn't Always Linear , author=. arXiv preprint arXiv:2603.09313 , year=
-
[20]
arXiv preprint arXiv:2502.19649 , year=
Taxonomy, opportunities, and challenges of representation engineering for large language models , author=. arXiv preprint arXiv:2502.19649 , year=
-
[21]
Computational Linguistics , year=
The quest for the right mediator: A history, survey, and theoretical grounding of causal mediation in mechanistic interpretability , author=. Computational Linguistics , year=
-
[22]
ICML , year=
The linear representation hypothesis and the geometry of large language models , author=. ICML , year=
-
[23]
arXiv preprint arXiv:2502.08009 , year=
The geometry of prompting: Unveiling distinct mechanisms of task adaptation in language models , author=. arXiv preprint arXiv:2502.08009 , year=
-
[24]
arXiv preprint arXiv:2601.22364 , year=
Context Structure Reshapes the Representational Geometry of Language Models , author=. arXiv preprint arXiv:2601.22364 , year=
-
[25]
2025 , url=
Core Francisco Park and Andrew Lee and Ekdeep Singh Lubana and Yongyi Yang and Maya Okawa and Kento Nishi and Martin Wattenberg and Hidenori Tanaka , booktitle=. 2025 , url=
2025
-
[26]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Unifying Attention Heads and Task Vectors via Hidden State Geometry in In-Context Learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[27]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Do different prompting methods yield a common task representation in language models? , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[28]
arXiv preprint arXiv:2510.19694 , year=
Do Prompts Reshape Representations? An Empirical Study of Prompting Effects on Embeddings , author=. arXiv preprint arXiv:2510.19694 , year=
-
[29]
arXiv preprint arXiv:2602.20338 , year=
Emergent Manifold Separability during Reasoning in Large Language Models , author=. arXiv preprint arXiv:2602.20338 , year=
-
[30]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
In-context learning creates task vectors , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[31]
International conference on learning representations , year=
Function vectors in large language models , author=. International conference on learning representations , year=
-
[32]
arXiv preprint arXiv:2509.04466 , year=
Just-in-time and distributed task representations in language models , author=. arXiv preprint arXiv:2509.04466 , year=
-
[33]
arXiv preprint arXiv:2509.22518 , year=
REMA: A Unified Reasoning Manifold Framework for Interpreting Large Language Model , author=. arXiv preprint arXiv:2509.22518 , year=
-
[34]
arXiv preprint arXiv:2505.10571 , year=
On the failure of latent state persistence in large language models , author=. arXiv preprint arXiv:2505.10571 , year=
-
[35]
arXiv preprint arXiv:2603.03308 , year=
Old Habits Die Hard: How Conversational History Geometrically Traps LLMs , author=. arXiv preprint arXiv:2603.03308 , year=
-
[36]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Steering llama 2 via contrastive activation addition , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[37]
2024 , publisher=
Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet , author=. 2024 , publisher=
2024
-
[38]
Zhengxuan Wu and Aryaman Arora and Zheng Wang and Atticus Geiger and Dan Jurafsky and Christopher D Manning and Christopher Potts , booktitle=. Re. 2024 , url=
2024
-
[39]
The Thirteenth International Conference on Learning Representations , year=
Controlling Language and Diffusion Models by Transporting Activations , author=. The Thirteenth International Conference on Learning Representations , year=
-
[40]
Advances in Neural Information Processing Systems , volume=
Analysing the generalisation and reliability of steering vectors , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
arXiv preprint arXiv:2502.02716 , year=
A unified understanding and evaluation of steering methods , author=. arXiv preprint arXiv:2502.02716 , year=
-
[42]
arXiv preprint arXiv:2412.09563 , year=
Does representation matter? exploring intermediate layers in large language models , author=. arXiv preprint arXiv:2412.09563 , year=
-
[43]
Forty-second International Conference on Machine Learning , year=
Layer by Layer: Uncovering Hidden Representations in Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[44]
Frontiers in systems neuroscience , volume=
Representational similarity analysis-connecting the branches of systems neuroscience , author=. Frontiers in systems neuroscience , volume=. 2008 , publisher=
2008
-
[45]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[46]
Advances in Neural Information Processing Systems , editor=
Generalized Shape Metrics on Neural Representations , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
2021
-
[47]
UniReps: 2nd Edition of the Workshop on Unifying Representations in Neural Models , year=
Equivalence between representational similarity analysis, centered kernel alignment, and canonical correlations analysis , author=. UniReps: 2nd Edition of the Workshop on Unifying Representations in Neural Models , year=
-
[48]
UniReps: 2nd Edition of the Workshop on Unifying Representations in Neural Models , year=
What Representational Similarity Measures Imply about Decodable Information , author=. UniReps: 2nd Edition of the Workshop on Unifying Representations in Neural Models , year=
-
[49]
Proceedings of the National Academy of Sciences , volume=
The topology and geometry of neural representations , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
2024
-
[50]
NeurIPS 2025 Workshop on CogInterp , year =
Interpreting Style--Content Parsing in Vision--Language Models , author =. NeurIPS 2025 Workshop on CogInterp , year =
2025
-
[51]
bioRxiv , pages=
Quantifying differences in neural population activity with shape metrics , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[52]
Psychometrika , volume=
Generalized procrustes analysis , author=. Psychometrika , volume=. 1975 , publisher=
1975
-
[53]
arXiv preprint arXiv:2505.17322 , year=
From Compression to Expression: A Layerwise Analysis of In-Context Learning , author=. arXiv preprint arXiv:2505.17322 , year=
-
[54]
arXiv preprint arXiv:2408.03326 , year=
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
-
[55]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[56]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[57]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[58]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[59]
arXiv preprint arXiv:2205.01068 , year=
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
-
[60]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Emoset: A large-scale visual emotion dataset with rich attributes , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[61]
Nature Human Behaviour , pages=
The psychophysics of style , author=. Nature Human Behaviour , pages=. 2025 , publisher=
2025
-
[62]
European conference on computer vision , pages=
Microsoft coco: Common objects in context , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[63]
arXiv preprint arXiv:2602.06843 , year=
The Representational Geometry of Number , author=. arXiv preprint arXiv:2602.06843 , year=
-
[64]
arXiv preprint arXiv:1609.07843 , year=
Pointer sentinel mixture models , author=. arXiv preprint arXiv:1609.07843 , year=
-
[65]
arXiv preprint arXiv:2604.07729 , year=
Emotion concepts and their function in a large language model , author=. arXiv preprint arXiv:2604.07729 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.