EvoTrainer: Co-Evolving LLM Policies and Training Harnesses for Autonomous Agentic Reinforcement Learning
Pith reviewed 2026-06-28 10:27 UTC · model grok-4.3
The pith
EvoTrainer co-evolves LLM policies and training harnesses through rollout feedback to match or exceed fixed human RL setups on agentic tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
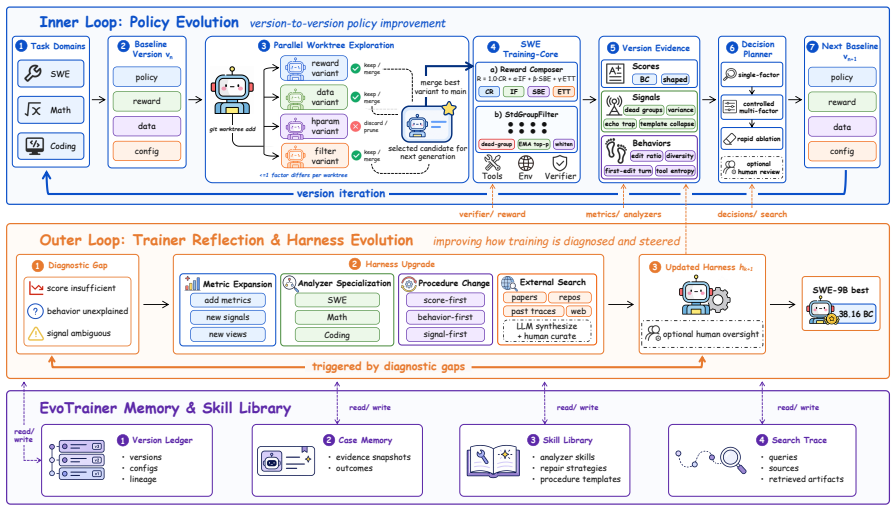
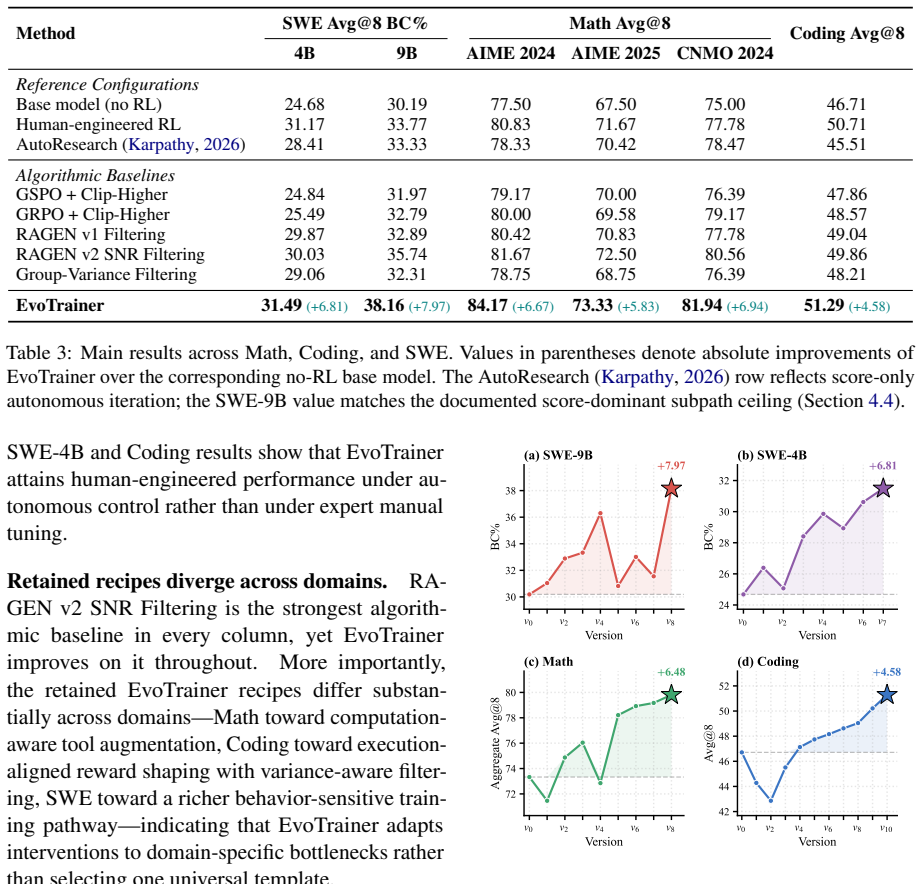
EvoTrainer is an autonomous training framework that co-evolves LLM policies and training-side harnesses through empirical feedback: it diagnoses rollout-level evidence, revises diagnostics, backtests interventions, and accumulates reusable skills. When evaluated on mathematical reasoning, competitive-programming code generation, and repository-level software engineering under the same data, codebase, and evaluation protocol, EvoTrainer matches or exceeds the human-engineered RL references, with the largest gain on long-horizon agentic SWE. Trajectory analyses show that retained strategies diverge across domains, evolving diagnostics prevent invalid high-scoring branches from being promoted,
What carries the argument
The co-evolution loop that diagnoses rollout evidence, revises diagnostics, backtests interventions, and accumulates reusable skills to jointly adapt the policy and the harness that interprets it.
If this is right
- Retained strategies diverge across mathematical reasoning, code generation, and software engineering domains.
- Evolving diagnostics block promotion of invalid high-scoring branches that static harnesses would accept.
- Reusable skills accumulated in early rounds influence the direction of later search.
- Joint evolution of policy and harness yields the largest gains on long-horizon agentic tasks.
Where Pith is reading between the lines
- The approach implies that many apparent limits in current agentic RL stem from static harness design rather than model capacity alone.
- Extending the same loop to non-LLM agents could test whether rollout-driven harness evolution generalizes beyond language models.
- If diagnostics continue to evolve, the framework might surface previously invisible failure modes that scalar rewards have hidden.
- The divergence of retained strategies suggests domain-specific harnesses may become necessary rather than universal training recipes.
Load-bearing premise
Rollout-level evidence can be used to revise diagnostics and backtest interventions without the revisions being shaped by the fixed evaluation protocol in ways that produce inflated scores.
What would settle it
Run EvoTrainer under a held-out evaluation protocol that differs from the one used for backtesting and observe whether final performance falls below the human-engineered RL baselines on the same tasks.
Figures

read the original abstract
Autonomous LLM training is often framed as recipe search, which leaves the training harness largely static. This limitation sharpens in agentic RL, where shifting bottlenecks and scalar rewards mask diverse failure modes. We introduce EvoTrainer, an autonomous training framework that co-evolves LLM policies and training-side harnesses through empirical feedback: it diagnoses rollout-level evidence, revises diagnostics, backtests interventions, and accumulates reusable skills. Evaluated on mathematical reasoning, competitive-programming code generation, and repository-level software engineering, EvoTrainer matches or exceeds the human-engineered RL references under the same data, codebase, and evaluation protocol, with the largest gain on long-horizon agentic SWE. Trajectory analyses show that retained strategies diverge across domains, evolving diagnostics prevent invalid high-scoring branches from being promoted, and reusable skills shape later search. Autonomous LLM RL should move beyond recipe search toward joint evolution of policies and the training harnesses that interpret them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EvoTrainer, an autonomous training framework that co-evolves LLM policies and training harnesses through empirical feedback: diagnosing rollout-level evidence, revising diagnostics, backtesting interventions, and accumulating reusable skills. It claims that on mathematical reasoning, competitive-programming code generation, and repository-level software engineering tasks, EvoTrainer matches or exceeds human-engineered RL references under identical data, codebase, and evaluation protocol, with the largest gains on long-horizon agentic SWE. Trajectory analyses are reported to show domain-divergent retained strategies, prevention of invalid high-scoring branches, and shaping of later search by reusable skills. The work argues that autonomous LLM RL should move beyond static recipe search to joint policy-harness evolution.
Significance. If the empirical results hold under rigorous validation, the work would be significant for agentic RL by addressing the limitation of static training harnesses in the presence of shifting bottlenecks and scalar rewards. The co-evolution approach and emphasis on reusable skills could influence methods for self-improving LLM agents, particularly in long-horizon domains like repository-level SWE. The controlled-protocol comparison is a positive element, though the absence of detailed experimental reporting limits current assessment of broader impact.
major comments (2)
- [Abstract] Abstract: The central empirical claim that EvoTrainer 'matches or exceeds the human-engineered RL references under the same data, codebase, and evaluation protocol' supplies no details whatsoever on experimental design, statistical tests, baseline implementations, number of runs, variance reporting, or controls for protocol leakage. This omission is load-bearing because the soundness of the superiority claim (especially the largest gain on long-horizon agentic SWE) cannot be assessed from the provided description.
- [Abstract] Abstract: The framework is described as using rollout evidence to revise diagnostics such that 'evolving diagnostics prevent invalid high-scoring branches from being promoted,' yet no mechanism is supplied to establish that these branches are invalid independent of the fixed evaluation protocol. Because the same protocol supplies the rollout data used for harness revision and backtesting, any selected change could align with protocol-specific features (e.g., test-case distributions or reward shaping) rather than produce generalizable policy improvement; this assumption is load-bearing for the claim of genuine gains over human-engineered baselines.
minor comments (1)
- The abstract is information-dense; separating the high-level method description from the empirical claims and analysis points would improve readability.
Simulated Author's Rebuttal
Thank you for your review. We appreciate the feedback on the need for greater detail in the abstract regarding experimental design and on the potential circularity in validating the evolving diagnostics. We will revise the abstract and add clarifications to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that EvoTrainer 'matches or exceeds the human-engineered RL references under the same data, codebase, and evaluation protocol' supplies no details whatsoever on experimental design, statistical tests, baseline implementations, number of runs, variance reporting, or controls for protocol leakage. This omission is load-bearing because the soundness of the superiority claim (especially the largest gain on long-horizon agentic SWE) cannot be assessed from the provided description.
Authors: The full manuscript reports these details in the Experiments section, including multiple independent runs with reported variance, baseline implementations under the shared codebase and data, statistical comparisons where performed, and explicit controls for the evaluation protocol. We agree the abstract would be strengthened by briefly summarizing these elements. We will revise the abstract to include a concise statement on the number of runs, variance reporting, and controlled protocol comparison. revision: yes
-
Referee: [Abstract] Abstract: The framework is described as using rollout evidence to revise diagnostics such that 'evolving diagnostics prevent invalid high-scoring branches from being promoted,' yet no mechanism is supplied to establish that these branches are invalid independent of the fixed evaluation protocol. Because the same protocol supplies the rollout data used for harness revision and backtesting, any selected change could align with protocol-specific features (e.g., test-case distributions or reward shaping) rather than produce generalizable policy improvement; this assumption is load-bearing for the claim of genuine gains over human-engineered baselines.
Authors: The manuscript uses trajectory analyses to demonstrate that revised diagnostics filter high-scoring but flawed branches, with retained strategies shown to diverge across domains and reusable skills shaping subsequent search. We acknowledge the concern that backtesting occurs under the same protocol. We will revise the relevant sections to expand on the backtesting procedure and any cross-domain or held-out analyses used to support that the gains reflect generalizable improvements rather than protocol artifacts. revision: partial
Circularity Check
No circularity: empirical claims rest on external protocol comparisons
full rationale
The paper describes an empirical co-evolution framework whose central performance claims are benchmarked against independent human-engineered RL baselines under identical fixed data, codebase, and evaluation protocol. No equations, fitted parameters, self-citations, or ansatzes are presented that would reduce the reported gains to internal definitions or inputs by construction. Trajectory analyses and diagnostic revisions are described as operating on rollout evidence, but the success metric remains an external match/exceed comparison rather than a self-referential quantity. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rollout-level evidence can diagnose failure modes and support effective revision of training diagnostics and interventions.
invented entities (1)
-
EvoTrainer framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 , howpublished =
Karpathy, Andrej , title =. 2026 , howpublished =
2026
-
[7]
Darwin G
Zhang, Jenny and Hu, Shengran and Lu, Cong and Lange, Robert and Clune, Jeff , journal =. Darwin G
-
[15]
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and Fan, Tiantian and Liu, Gaohong and Liu, Juncai and Liu, Lingjun and Liu, Xin and Lin, Haibin and Lin, Zhiqi and Ma, Bole and Sheng, Guangming and Tong, Yuxuan and Zhang, Chi and Zhang, Mofan and Zhang, Ru and Zhu, Hang and Zhu, Jinhua and Chen, J...
-
[22]
Wang, Zihan and Wang, Kangrui and Wang, Qineng and Zhang, Pingyue and Li, Linjie and Yang, Zhengyuan and Jin, Xing and Yu, Kefan and Nguyen, Minh Nhat and Liu, Licheng and Gottlieb, Eli and Lu, Yiping and Cho, Kyunghyun and Wu, Jiajun and Fei-Fei, Li and Wang, Lijuan and Choi, Yejin and Li, Manling , journal =
-
[30]
Introducing Claude Sonnet 4.6 , year =
-
[31]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and others , journal =. 2025 , doi =
2025
-
[32]
Advances in Neural Information Processing Systems (
Deep Reinforcement Learning at the Edge of the Statistical Precipice , author =. Advances in Neural Information Processing Systems (. 2021 , note =
2021
-
[33]
Proceedings of the Thirty-Second
Deep Reinforcement Learning That Matters , author =. Proceedings of the Thirty-Second
-
[35]
2026 , eprint =
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses , author =. 2026 , eprint =
2026
-
[36]
Bellemare
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville, and Marc G. Bellemare. 2021. Deep reinforcement learning at the edge of the statistical precipice. In Advances in Neural Information Processing Systems ( NeurIPS ) . Outstanding Paper Award
2021
-
[37]
Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, and Nick Haber. 2025. Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models. arXiv preprint arXiv:2502.17387
arXiv 2025
-
[38]
Anthropic . 2026. https://www.anthropic.com/news/claude-sonnet-4-6 Introducing claude sonnet 4.6 . Anthropic announcement. Accessed: 2026-05-21
2026
-
[39]
Ibragim Badertdinov, Alexander Golubev, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Andrei Andriushchenko, Maria Trofimova, Daria Litvintseva, and Boris Yangel. 2025. Swe-rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents. arXiv preprint arXiv:2505.20411
arXiv 2025
-
[40]
Guhong Chen, Chenghao Sun, Cheng Fu, Qiyao Wang, Zhihong Huang, Chaopeng Wei, Guangxu Chen, Feiteng Fang, Ahmadreza Argha, Bing Zhao, Xander Xu, Qi Han, Hamid Alinejad-Rokny, Qiang Qu, Binhua Li, Shiwen Ni, Min Yang, Hu Wei, and Yongbin Li. 2026. Beyond quantity: Trajectory diversity scaling for code agents. arXiv preprint arXiv:2602.03219
arXiv 2026
- [41]
-
[42]
Xiwen Chen, Wenhui Zhu, Peijie Qiu, Xuanzhao Dong, Hao Wang, Haiyu Wu, Huayu Li, Aristeidis Sotiras, Yalin Wang, and Abolfazl Razi. 2025 b . Dra-grpo: Your grpo needs to know diverse reasoning paths for mathematical reasoning. arXiv preprint arXiv:2505.09655
arXiv 2025
-
[43]
C \'e dric Colas, Olivier Sigaud, and Pierre-Yves Oudeyer. 2018. How many random seeds? S tatistical power analysis in deep reinforcement learning experiments. arXiv preprint arXiv:1806.08295
Pith/arXiv arXiv 2018
-
[44]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 1 others. 2025. https://doi.org/10.1038/s41586-025-09422-z DeepSeek-R1 incentivizes reasoning in LLM s through reinforcement learn...
-
[45]
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. 2018. Deep reinforcement learning that matters. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence ( AAAI )
2018
-
[46]
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. 2025. R-zero: Self-evolving reasoning llm from zero data. arXiv preprint arXiv:2508.05004
Pith/arXiv arXiv 2025
-
[47]
Yu Huang, Zixin Wen, Yuejie Chi, Yuting Wei, Aarti Singh, Yingbin Liang, and Yuxin Chen. 2026. The implicit curriculum: Learning dynamics in rl with verifiable rewards. arXiv preprint arXiv:2602.14872
Pith/arXiv arXiv 2026
-
[48]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2024. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974
Pith/arXiv arXiv 2024
-
[49]
Ahmadreza Jeddi, Minh Ngoc Le, Hakki C. Karaimer, Konstantinos G. Derpanis, and Babak Taati. 2026. Gear: Genetic autoresearch for agentic code evolution. arXiv preprint arXiv:2605.13874
Pith/arXiv arXiv 2026
-
[50]
Andrej Karpathy. 2026. https://github.com/karpathy/autoresearch autoresearch : Ai agents running research experiments . GitHub repository. Accessed: 2026-05-24
2026
-
[51]
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. 2026. Meta-harness: End-to-end optimization of model harnesses. arXiv preprint arXiv:2603.28052
Pith/arXiv arXiv 2026
-
[52]
Rongao Li, Jie Fu, Bo-Wen Zhang, Tao Huang, Zhihong Sun, Chen Lyu, Guang Liu, Zhi Jin, and Ge Li. 2023. Taco: Topics in algorithmic code generation dataset. arXiv preprint arXiv:2312.14852
arXiv 2023
-
[53]
Jiahang Lin, Shichun Liu, Chengjun Pan, Lizhi Lin, Shihan Dou, Zhiheng Xi, Xuanjing Huang, Hang Yan, Zhenhua Han, Tao Gui, and Yu-Gang Jiang. 2026. https://arxiv.org/abs/2604.25850 Agentic harness engineering: Observability-driven automatic evolution of coding-agent harnesses . Preprint, arXiv:2604.25850
Pith/arXiv arXiv 2026
-
[54]
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. 2025 a . Understanding r1-zero-like training: A critical perspective. arXiv preprint arXiv:2503.20783
Pith/arXiv arXiv 2025
-
[55]
Ziru Liu, Cheng Gong, Xinyu Fu, Yaofang Liu, Ran Chen, Shoubo Hu, Suiyun Zhang, Rui Liu, Qingfu Zhang, and Dandan Tu. 2025 b . Ghpo: Adaptive guidance for stable and efficient llm reinforcement learning. arXiv preprint arXiv:2507.10628
arXiv 2025
-
[56]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. 2024. The ai scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292
Pith/arXiv arXiv 2024
-
[57]
Jingjie Ning, Xiaochuan Li, Ji Zeng, Hao Kang, and Chenyan Xiong. 2026. Auto research with specialist agents develops effective and non-trivial training recipes. arXiv preprint arXiv:2605.05724
Pith/arXiv arXiv 2026
-
[58]
Alexander Novikov, Ngan Vu, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. 2025. Alphaevolve: A coding agent for scientific and ...
Pith/arXiv arXiv 2025
-
[59]
Yaonan Qu and Meng Lu. 2026. Bilevel autoresearch: Meta-autoresearching itself. arXiv preprint arXiv:2603.23420
Pith/arXiv arXiv 2026
-
[60]
Qwen Team . 2026. https://huggingface.co/Qwen/Qwen3.5-4B Qwen3.5-4b . Hugging Face model card
2026
-
[61]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
Pith/arXiv arXiv 2024
-
[62]
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, and Jingren Zhou. 2024. A survey on self-evolution of large language models. arXiv preprint arXiv:2404.14387
arXiv 2024
-
[63]
Zihan Wang, Chi Gui, Xing Jin, Qineng Wang, Licheng Liu, Kangrui Wang, Shiqi Chen, Linjie Li, Zhengyuan Yang, Pingyue Zhang, Yiping Lu, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, and Manling Li. 2026. Ragen-2: Reasoning collapse in agentic rl. arXiv preprint arXiv:2604.06268
Pith/arXiv arXiv 2026
-
[64]
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, and Manling Li. 2025. RAGEN : Understanding self-evolution in LLM agents via multi-turn reinforcement learning. arXiv preprint arXiv:2504.20073
Pith/arXiv arXiv 2025
-
[65]
Xixi Wu, Qianguo Sun, Ruiyang Zhang, Chao Song, Junlong Wu, Yiyan Qi, and Hong Cheng. 2026. Demystifying reinforcement learning for long-horizon tool-using agents: A comprehensive recipe. arXiv preprint arXiv:2603.21972
arXiv 2026
-
[66]
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. 2025. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search. arXiv preprint arXiv:2504.08066
Pith/arXiv arXiv 2025
-
[67]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, and 17 others. 2025. DAPO : An open-source LLM reinforcement learning system at scale. arXiv preprint arXiv:2503.14476
Pith/arXiv arXiv 2025
-
[68]
Zhiyin Yu, Bo Zhang, Qibin Hou, Zhonghai Wu, Xiao Luo, and Lei Bai. 2026. Easy samples are all you need: Self-evolving llms via data-efficient reinforcement learning. arXiv preprint arXiv:2604.18639
Pith/arXiv arXiv 2026
-
[69]
Zhiyuan Zeng, Hamish Ivison, Yiping Wang, Lifan Yuan, Shuyue Stella Li, Zhuorui Ye, Siting Li, Jacqueline He, Runlong Zhou, Tong Chen, Chenyang Zhao, Yulia Tsvetkov, Simon Shaolei Du, Natasha Jaques, Hao Peng, Pang Wei Koh, and Hannaneh Hajishirzi. 2025. Rlve: Scaling up reinforcement learning for language models with adaptive verifiable environments. arX...
Pith/arXiv arXiv 2025
-
[70]
Jenny Zhang, Shengran Hu, Cong Lu, Robert Lange, and Jeff Clune. 2025. Darwin g \"o del machine: Open-ended evolution of self-improving agents. arXiv preprint arXiv:2505.22954
Pith/arXiv arXiv 2025
-
[71]
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. 2025. Group sequence policy optimization. arXiv preprint arXiv:2507.18071
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.