SketchSong: Hierarchical Song Generation with Sketch Planning and Fine-Grained Multi-Track Modeling
Pith reviewed 2026-06-28 08:50 UTC · model grok-4.3
The pith
SketchSong first plans songs via compact high-level sketch tokens then generates audio with separate modeling of four tracks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
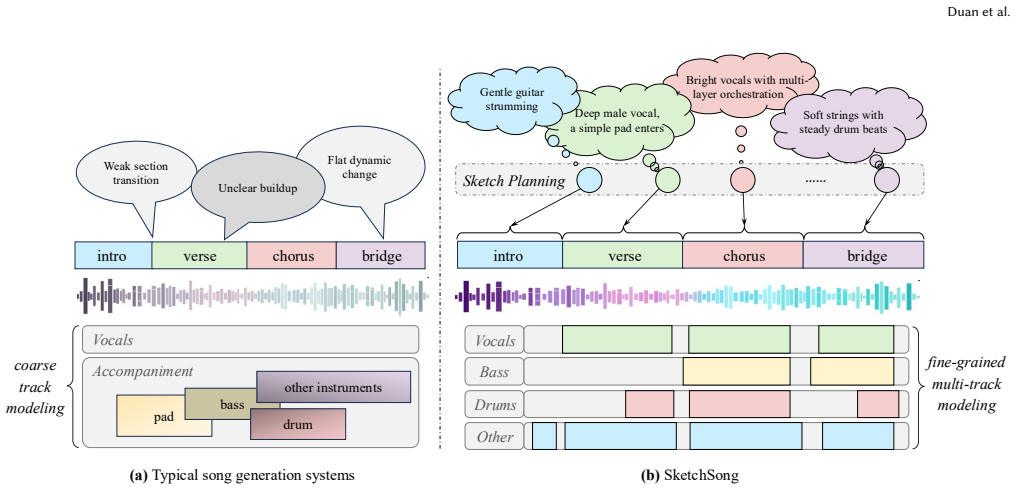
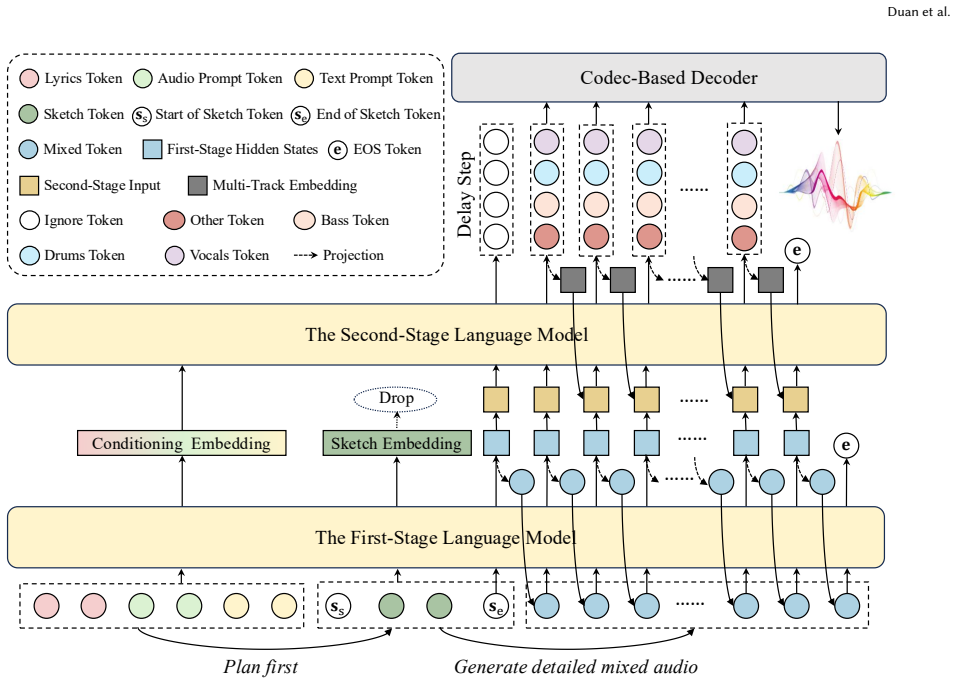
SketchSong generates complete songs by first predicting a compact sequence of high-level sketch tokens derived from compressed audio representations to create an explicit arrangement plan, then generating audio tokens conditioned on those sketches; separately it models four tracks (vocals, bass, drums, other instruments) to capture distinct roles and interactions, producing greater coherence in section transitions and richer arrangement dynamics than prior single-stage or coarsely joint approaches.
What carries the argument
Two-stage coarse-to-fine generation that first outputs high-level sketch tokens from compressed audio to condition later audio token sequences, paired with explicit four-track separation in the generation stage.
If this is right
- Explicit sketch planning before audio generation produces stronger section transitions and dynamic progression without requiring later preference optimization.
- Separate modeling of vocals, bass, drums and other tracks yields richer arrangement detail by letting the model learn each part's distinct role and interactions.
- The overall design achieves competitive benchmark results against post-trained systems while using only the base training objective.
- Coarse sketch tokens derived from compressed audio can serve as a lightweight conditioning signal that organizes long-form generation.
Where Pith is reading between the lines
- The same sketch-then-detail pattern could be tested on other long sequential domains such as multi-shot video or multi-character dialogue.
- Extending the track dimension beyond four labeled streams might allow finer instrument families or stem-level control.
- Because the method reaches competitive performance without post-training alignment steps, similar hierarchical designs could lower the compute needed for high-quality long-form generation.
- The reliance on compressed audio for sketches raises the question of whether other compact representations, such as symbolic MIDI summaries, would produce comparable plans.
Load-bearing premise
A compact sequence of high-level sketch tokens taken from compressed audio will supply an effective explicit arrangement plan that measurably improves coherence when used to condition the later audio token generation.
What would settle it
A controlled ablation that removes the sketch-planning stage while keeping the four-track modeling and all other architecture fixed, then measures whether coherence metrics and human listening scores on song benchmarks drop to baseline levels.
Figures
read the original abstract
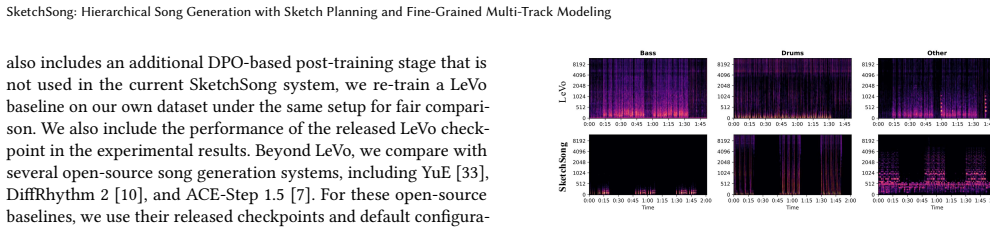
Recent song generation systems can synthesize realistic audio, yet generating complete songs remains challenging for two reasons. First, explicit song-level arrangement planning remains limited in existing methods, so models often need to organize overall arrangement development while generating low-level audio details. This often leads to incoherence in arrangements, such as weak section transitions and limited dynamic progression. Second, coarse modeling of different musical parts obscures their distinct roles and interactions, limiting arrangement richness of generated songs. In this paper, we present SketchSong, a hierarchical song generation framework that addresses these issues through song-level sketch planning and fine-grained multi-track modeling. Along the temporal dimension, SketchSong first predicts a compact sequence of high-level sketch tokens derived from compressed audio representations, and then generates audio tokens conditioned on these sketches. This coarse-to-fine process gives the model an explicit arrangement plan before detailed audio generation. Along the track dimension, SketchSong explicitly models four tracks, i.e., vocals, bass, drums and other instruments. This enables the model to capture the roles and interactions of different musical parts more precisely. Experiments on song generation benchmarks show that SketchSong consistently outperforms our baseline on both objective metrics and human listening tests. Despite not employing additional post-training for preference optimization such as lyrics and text-prompt alignments, SketchSong achieves competitive results against strong, post-trained open-source systems, demonstrating the effectiveness of our overall design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SketchSong, a hierarchical song generation framework that performs song-level sketch planning by predicting a compact sequence of high-level sketch tokens from compressed audio representations, followed by conditioned generation of audio tokens. It also employs fine-grained multi-track modeling by explicitly factoring the generation into four tracks: vocals, bass, drums, and other instruments. The authors claim that this approach improves arrangement coherence and richness, with experiments on song generation benchmarks showing consistent outperformance over their baseline on objective metrics and human listening tests, and competitive results against strong post-trained open-source systems without additional post-training for preference optimization.
Significance. If the experimental results hold, this work would be significant for the field of music generation as it provides an explicit mechanism for arrangement planning and multi-track interaction modeling that achieves strong performance without relying on post-training techniques like preference optimization. This could influence future designs for long-form audio generation tasks.
major comments (1)
- Abstract: The claim that 'Experiments on song generation benchmarks show that SketchSong consistently outperforms our baseline on both objective metrics and human listening tests' and achieves 'competitive results against strong, post-trained open-source systems' is presented without any numerical results, baseline descriptions, dataset details, or statistical significance. This is load-bearing for the central empirical claim in an ML paper whose soundness rests on experimental comparisons.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater specificity in the abstract. We address this point directly below and will revise accordingly.
read point-by-point responses
-
Referee: Abstract: The claim that 'Experiments on song generation benchmarks show that SketchSong consistently outperforms our baseline on both objective metrics and human listening tests' and achieves 'competitive results against strong, post-trained open-source systems' is presented without any numerical results, baseline descriptions, dataset details, or statistical significance. This is load-bearing for the central empirical claim in an ML paper whose soundness rests on experimental comparisons.
Authors: We agree the abstract would be strengthened by including concrete numbers and setup details. In the revision we will add key quantitative results (e.g., relative improvements on FAD and other objective metrics, human preference win rates) while briefly naming the primary baselines and the song-generation evaluation datasets. Space constraints preclude full statistical tests or exhaustive baseline lists in the abstract, but the selected figures will directly support the claims; complete tables, significance tests, and dataset descriptions remain in Sections 4 and 5. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
This is an empirical machine-learning paper whose central claims rest on experimental comparisons of a proposed hierarchical architecture (sketch tokens from compressed audio followed by conditioned multi-track audio generation) against baselines. No mathematical derivation, uniqueness theorem, or parameter-fitting step is presented that could reduce to its own inputs by construction. The architecture description uses standard coarse-to-fine conditioning and explicit track factorization without self-definitional loops or load-bearing self-citations. The experimental results are scoped to outperformance metrics and are externally falsifiable, satisfying the criteria for a self-contained, non-circular contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks trained on tokenized audio can learn to generate coherent multi-track music when conditioned on high-level sketch tokens.
Reference graph
Works this paper leans on
-
[1]
Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, An- toine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. 2023. Musiclm: Generating music from text.arXiv preprint arXiv:2301.11325 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems33 (2020), 12449–12460
2020
- [3]
-
[4]
Pengfei Cai, Joanna Wang, Haorui Zheng, Xu Li, Zihao Ji, Teng Ma, Zhongliang Liu, Chen Zhang, and Pengfei Wan. 2025. SegTune: Structured and Fine-Grained Control for Song Generation.arXiv preprint arXiv:2510.18416(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. 2023. Simple and controllable music generation. Advances in neural information processing systems36 (2023), 47704–47720
2023
-
[6]
Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, and Ilya Sutskever. 2020. Jukebox: A generative model for music.arXiv preprint arXiv:2005.00341(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [7]
- [8]
- [9]
- [10]
-
[11]
Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. 2018. Fr\’echet audio distance: A metric for evaluating music enhancement algorithms. arXiv preprint arXiv:1812.08466(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Taejun Kim and Juhan Nam. 2023. All-in-one metrical and functional structure analysis with neighborhood attentions on demixed audio. In2023 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (W ASPAA). IEEE, 1–5
2023
- [13]
- [14]
- [15]
-
[16]
Shun Lei, Yixuan Zhou, Boshi Tang, Max W Lam, Feng Liu, Hangyu Liu, Jingcheng Wu, Shiyin Kang, Zhiyong Wu, and Helen Meng. 2024. Songcreator: Lyrics-based universal song generation.Advances in Neural Information Processing Systems37 (2024), 80107–80140
2024
-
[17]
Jan Melechovsky, Zixun Guo, Deepanway Ghosal, Navonil Majumder, Dorien Her- remans, and Soujanya Poria. 2024. Mustango: Toward controllable text-to-music generation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 8293–8316
2024
- [18]
-
[19]
Julian D Parker, Janne Spijkervet, Katerina Kosta, Furkan Yesiler, Boris Kuznetsov, Ju-Chiang Wang, Matt Avent, Jitong Chen, and Duc Le. 2024. Stemgen: A music generation model that listens. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1116–1120
2024
- [20]
-
[21]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning. PMLR, 28492–28518
2023
-
[22]
Simon Rouard, Francisco Massa, and Alexandre Défossez. 2023. Hybrid trans- formers for music source separation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
- [23]
- [24]
-
[25]
Andros Tjandra, Yi-Chiao Wu, Baishan Guo, John Hoffman, Brian Ellis, Apoorv Vyas, Bowen Shi, Sanyuan Chen, Matt Le, Nick Zacharov, et al . 2025. Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound.arXiv preprint arXiv:2502.05139(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Hugo Touvron, Piotr Bojanowski, Mathilde Caron, Matthieu Cord, Alaaeldin El-Nouby, Edouard Grave, Gautier Izacard, Armand Joulin, Gabriel Synnaeve, Jakob Verbeek, et al. 2022. Resmlp: Feedforward networks for image classification with data-efficient training.IEEE transactions on pattern analysis and machine intelligence45, 4 (2022), 5314–5321
2022
-
[27]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. 2025. Qwen2.5-Omni Technical Report. arXiv:2503.20215 [cs.CL] https://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Yaoxun Xu, Hangting Chen, Jianwei Yu, Wei Tan, Shun Lei, Zhiwei Lin, Rongzhi Gu, and Zhiyong Wu. 2025. MuCodec: Ultra Low-Bitrate Music Codec for Music Generation. InProceedings of the 33rd ACM International Conference on Multime- dia. 689–698
2025
- [29]
- [30]
-
[31]
Yao Yao, Peike Li, Boyu Chen, and Alex Wang. 2025. Jen-1 composer: A unified framework for high-fidelity multi-track music generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 14459–14467
2025
- [32]
- [33]
- [34]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.