When Does Complexity Conditioning Help a Frozen Sentence Embedding? A Controlled Study of Per-Sentence and Pair-Level Difficulty Adaptation
Pith reviewed 2026-06-28 10:28 UTC · model grok-4.3
The pith
Difficulty in sentence embeddings is a property of pairs rather than individual sentences, so only pair-level adapters improve performance on similarity tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
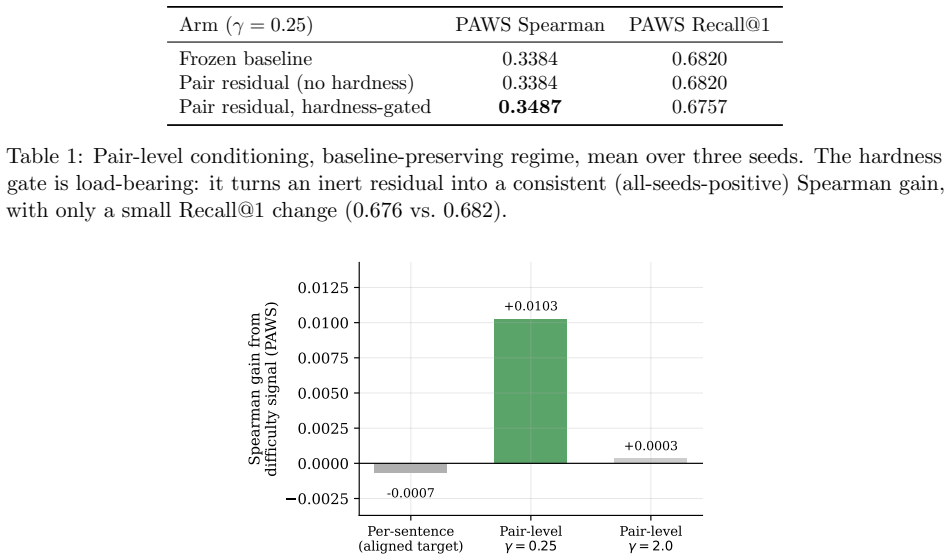
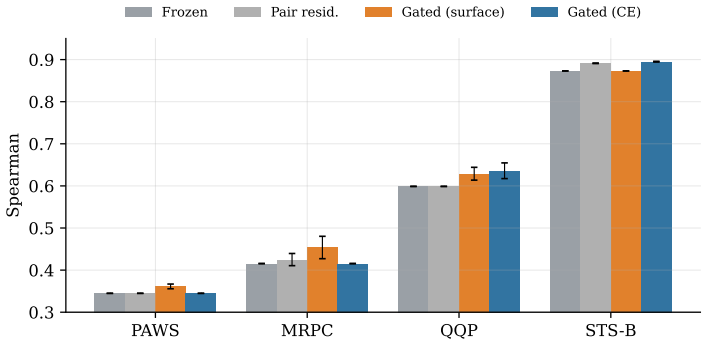
Even when the target is aligned to a non-circular pair-difficulty signal, the per-sentence gate still cannot reliably capture difficulty because difficulty is primarily a property of the pair, not the individual sentence. In contrast, a small pair-level residual gated by a held-out cross-encoder difficulty signal yields consistent gains on the larger and graded tasks, including +0.022 Spearman on STS-B and +0.037 on QQP, while remaining anchored to the frozen baseline across all seeds. Because this useful form operates on sentence pairs rather than individual sentences, the resulting model is best understood as a lightweight re-ranker over cached frozen embeddings.
What carries the argument
Pair-level residual adapter gated by a held-out cross-encoder difficulty signal, which conditions adaptation on the interaction between two sentences rather than on either sentence alone.
If this is right
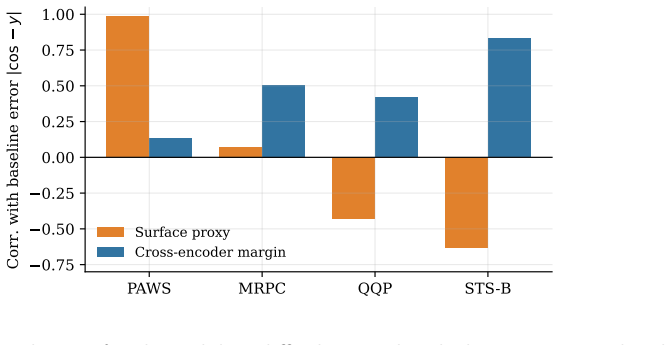
- Surface per-sentence complexity measures remain nearly uncorrelated with frozen-baseline error (Pearson approximately 0.05) and provide no advantage over constant or shuffled controls.
- Pair-level adaptation produces measurable lifts on graded tasks while the model stays anchored to the frozen encoder across multiple seeds.
- The adapted system functions as a re-ranker over cached embeddings rather than a replacement single-vector embedding.
- A pre-training diagnostic can predict the headroom available for difficulty-aware adaptation before any fine-tuning occurs.
Where Pith is reading between the lines
- Embedding pipelines that already cache single-sentence vectors could add pair-level re-ranking at inference time without retraining the encoder.
- The same controlled comparison could be repeated on retrieval or clustering tasks to test whether the pair-versus-sentence distinction holds outside paraphrase and similarity.
- If the diagnostic reliably forecasts headroom, it could guide decisions about whether to invest in any form of difficulty conditioning for a given frozen model.
Load-bearing premise
The held-out cross-encoder difficulty signal used to gate the pair-level adapter is itself a valid, non-circular measure of pair difficulty.
What would settle it
Running the pair-level adapter on the same tasks but with the gating signal replaced by a different cross-encoder or by random values and finding that the reported gains disappear.
Figures
read the original abstract
A common intuition is that sentence embeddings should adapt to the difficulty of the input. We test this intuition in a controlled, multi-seed setting: a lightweight post-encoder adapter attaches to a frozen Qwen3-Embedding-0.6B encoder, accessing only its final pooled embedding, and is evaluated on four paraphrase and semantic-similarity tasks (PAWS, MRPC, QQP, STS-B). The naive form of the idea fails: surface-based per-sentence complexity is nearly uncorrelated with frozen-baseline error (Pearson approximately 0.05) and provides no advantage over constant or shuffled controls, while degrading a saturated baseline. Even when the target is aligned to a non-circular pair-difficulty signal, the per-sentence gate still cannot reliably capture difficulty because difficulty is primarily a property of the pair, not the individual sentence. In contrast, a small pair-level residual gated by a held-out cross-encoder difficulty signal yields consistent gains on the larger and graded tasks, including +0.022 Spearman on STS-B and +0.037 on QQP, while remaining anchored to the frozen baseline across all seeds. Because this useful form operates on sentence pairs rather than individual sentences, the resulting model is best understood as a lightweight re-ranker over cached frozen embeddings, not a replacement single-vector embedding; we make no state-of-the-art claim. Our contribution is a controlled account of when difficulty-aware adaptation helps and when it fails, together with a pre-training diagnostic that predicts the available headroom.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a controlled multi-seed study testing whether complexity conditioning improves a frozen sentence embedding (Qwen3-Embedding-0.6B) via a lightweight post-encoder adapter on paraphrase and similarity tasks (PAWS, MRPC, QQP, STS-B). It finds surface per-sentence complexity nearly uncorrelated with baseline error (Pearson ~0.05) and no better than constant/shuffled controls, while even alignment to a pair-difficulty signal fails for per-sentence gating; in contrast, pair-level residual adaptation gated by a held-out cross-encoder difficulty signal yields modest gains (+0.022 Spearman on STS-B, +0.037 on QQP). The work concludes difficulty is primarily a pair property, positions the result as a re-ranker over cached embeddings rather than a single-vector embedder, and offers a pre-training diagnostic for headroom.
Significance. If the results hold, this supplies a useful controlled empirical account of the conditions under which difficulty adaptation helps or fails for frozen embeddings, with explicit credit due to the multi-seed design, constant/shuffled controls, and the diagnostic. The reframing as a lightweight re-ranker (rather than claiming a new embedding) and the absence of SOTA claims strengthen the contribution for the embedding-adaptation literature.
major comments (2)
- [Abstract and §4] Abstract/§4: The central claim that 'difficulty is primarily a property of the pair' (and thus per-sentence gating fails even when aligned) rests on the held-out cross-encoder signal serving as a valid non-circular measure of pair difficulty. No external corroboration (correlation with human difficulty judgments or alternative models) is reported; internal use of the same signal both to define the target and to gate the adapter leaves open the possibility that observed per-sentence failure reflects task-specific artifacts rather than a general pair-level nature of difficulty.
- [Results section (inferred from abstract)] Results (STS-B/QQP rows): The reported gains (+0.022 Spearman on STS-B, +0.037 on QQP) are small relative to a saturated baseline; the manuscript must report per-seed standard deviations, statistical significance (e.g., paired tests across the multi-seed runs), and explicit comparison against the variance of the frozen baseline to establish that the improvements are reliable rather than within seed noise.
minor comments (2)
- [Methods] Provide the exact definition and training details of the held-out cross-encoder (architecture, data, whether disjoint from evaluation splits) to allow replication of the pair-difficulty signal.
- [Results] Add a figure or table summarizing the per-sentence vs. pair-level Pearson/Spearman correlations with baseline error across all tasks and seeds for direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, indicating planned revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract/§4: The central claim that 'difficulty is primarily a property of the pair' (and thus per-sentence gating fails even when aligned) rests on the held-out cross-encoder signal serving as a valid non-circular measure of pair difficulty. No external corroboration (correlation with human difficulty judgments or alternative models) is reported; internal use of the same signal both to define the target and to gate the adapter leaves open the possibility that observed per-sentence failure reflects task-specific artifacts rather than a general pair-level nature of difficulty.
Authors: The cross-encoder is a distinct held-out model whose difficulty signal is computed on separate data splits, ensuring it is independent of the frozen Qwen3-Embedding-0.6B encoder and its training data. This design avoids direct circularity. We acknowledge that external validation (e.g., human judgments or additional models) is not reported and will add an explicit limitations paragraph in the revised manuscript clarifying the held-out construction while noting this as a boundary on generalizability. The controlled multi-seed results with constant/shuffled baselines still support the pair-level interpretation within the reported experimental scope. revision: partial
-
Referee: [Results section (inferred from abstract)] Results (STS-B/QQP rows): The reported gains (+0.022 Spearman on STS-B, +0.037 on QQP) are small relative to a saturated baseline; the manuscript must report per-seed standard deviations, statistical significance (e.g., paired tests across the multi-seed runs), and explicit comparison against the variance of the frozen baseline to establish that the improvements are reliable rather than within seed noise.
Authors: We agree that per-seed statistics and formal tests are required to substantiate reliability. Although the manuscript already emphasizes consistency across seeds and anchoring to the frozen baseline, it does not currently include standard deviations, paired significance tests, or direct variance comparisons. We will incorporate these analyses (including per-seed means ± std and appropriate paired tests) into the results section of the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical study with held-out external signal
full rationale
The paper presents an empirical controlled study on adapters for frozen embeddings, using multi-seed experiments on paraphrase and similarity tasks. It relies on a held-out cross-encoder difficulty signal for pair-level gating, explicitly labeled non-circular, and reports correlations and gains without any mathematical derivation chain. No equations, self-definitional parameters, fitted-input predictions, or load-bearing self-citations appear in the abstract or described setup. The central claim that difficulty is pair-level follows from experimental comparisons (per-sentence vs. pair-level performance) rather than reducing to the input signal by construction. The study is self-contained against its own benchmarks and controls.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The four tasks (PAWS, MRPC, QQP, STS-B) are valid proxies for paraphrase and semantic similarity performance.
- domain assumption The held-out cross-encoder difficulty signal is non-circular with respect to the adapter being trained.
Reference graph
Works this paper leans on
-
[1]
BAAI/bge-base-en-v1.5 model card
Beijing Academy of Artificial Intelligence. BAAI/bge-base-en-v1.5 model card. https:// huggingface.co/BAAI/bge-base-en-v1.5. Accessed 2026-05-28
2026
-
[2]
Bowman, Gabor Angeli, Christopher Potts, and Christopher D
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. A large annotated corpus for learning natural language inference. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2015
2015
-
[3]
SemEval- 2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation
Daniel Cer, Mona Diab, Eneko Agirre, I˜ nigo Lopez-Gazpio, and Lucia Specia. SemEval- 2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), 2017
2017
-
[4]
Dolan and Chris Brockett
William B. Dolan and Chris Brockett. Automatically constructing a corpus of sentential paraphrases. InProceedings of the Third International Workshop on Paraphrasing (IWP), 2005
2005
-
[5]
SimCSE: Simple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple contrastive learning of sentence embeddings. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021
2021
-
[6]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas O˘ guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[7]
Sheng-Chieh Lin, Jheng-Hong Yang, and Jimmy Lin. Distilling dense representations for ranking using tightly-coupled teachers.arXiv preprint arXiv:2010.11386, 2020
-
[8]
MTEB: Massive Text Embedding Benchmark
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. MTEB: Massive text embedding benchmark.arXiv preprint arXiv:2210.07316, 2022. 12
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Rodrigo Nogueira and Kyunghyun Cho. Passage re-ranking with BERT.arXiv preprint arXiv:1901.04085, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[10]
Quora question pairs
Quora. Quora question pairs. https://quoradata.quora.com/ First-Quora-Dataset-Release-Question-Pairs. Accessed 2026-05-29
2026
-
[11]
Qwen3 embedding models
Qwen Team. Qwen3 embedding models. https://huggingface.co/Qwen/ Qwen3-Embedding-0.6B. Open-weight embedding model (Apache-2.0). Accessed 2026- 05-29
2026
-
[12]
Sentence-BERT: Sentence embeddings using Siamese BERT- networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP-IJCNLP), 2019
2019
-
[13]
cross-encoder/stsb-distilroberta-base
Nils Reimers and Iryna Gurevych. cross-encoder/stsb-distilroberta-base. https:// huggingface.co/cross-encoder/stsb-distilroberta-base. Sentence-Transformers cross- encoder. Accessed 2026-05-29
2026
-
[14]
sentence-transformers/stsb dataset
Sentence-Transformers. sentence-transformers/stsb dataset. https://huggingface.co/ datasets/sentence-transformers/stsb. Accessed 2026-05-29
2026
-
[15]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP, 2018
2018
-
[16]
Bennett, Junaid Ahmed, and Arnold Overwijk
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N. Bennett, Junaid Ahmed, and Arnold Overwijk. Approximate nearest neighbor negative contrastive learning for dense text retrieval. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[17]
PAWS: Paraphrase adversaries from word scrambling
Yuan Zhang, Jason Baldridge, and Luheng He. PAWS: Paraphrase adversaries from word scrambling. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), 2019. 13
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.