SpeakerCard-1M: An Evidence-Grounded Corpus for In-the-Wild Speaker Verification
Pith reviewed 2026-06-30 11:21 UTC · model grok-4.3
The pith
SpeakerCard-1M supplies 1.78 million captions to ground speaker verification in acoustic evidence from probes and constrained generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
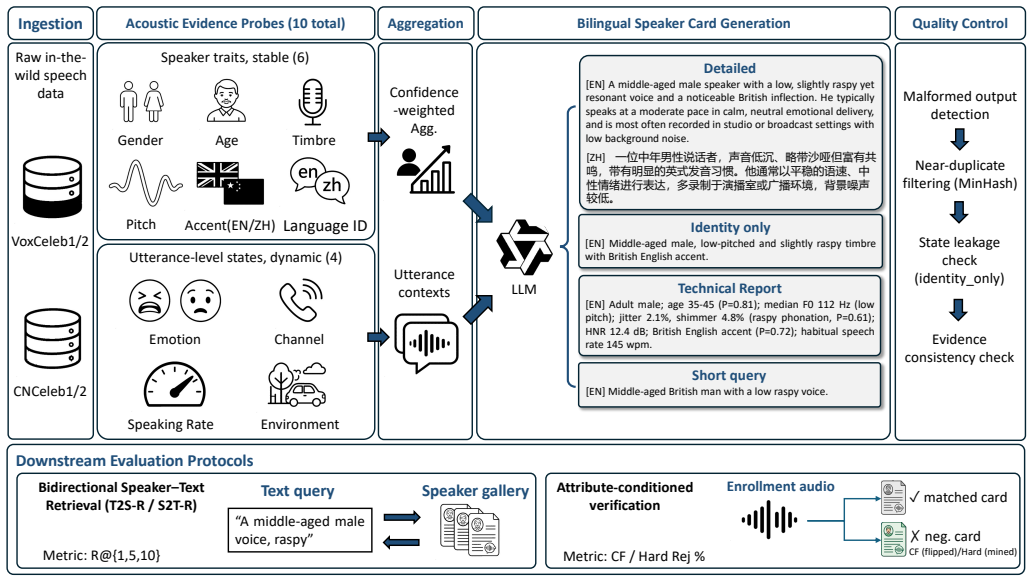
SpeakerCard-1M contains 56.7k speaker card records across 10.2k speakers together with 1.78M utterance captions and hard-negative triplets. The dual-encoder baseline reaches 88.66 percent accuracy on pitch-level AC-Verify in a 2-way forced-choice setting, while eight recent audio language models (7B to 30B+ parameters) reach only 49-77 percent under the same style-symmetric LLM-generated counterfactual protocol. Adding text supervision during training increases EER by just 0.31 percent absolute on VoxCeleb1-O relative to the audio-only baseline.
What carries the argument
The Speaker Card, a structured bilingual profile that aggregates outputs from ten acoustic probes into separate stable-trait and utterance-state fields before constrained LLM rendering.
If this is right
- Joint audio-text training preserves nearly all audio-only verification performance on standard benchmarks such as VoxCeleb1-O.
- Recent audio language models exhibit clear limitations when required to condition verification decisions on specific acoustic attributes such as pitch.
- The speaker-ID-disjoint hard-negative triplets support training of more robust in-the-wild models.
- Bidirectional speaker-text retrieval protocols become directly testable with the released captions and cards.
Where Pith is reading between the lines
- The probe-first aggregation step could be reused to create similar evidence-grounded resources for other biometric modalities.
- The performance gap on AC-Verify points to a missing capability in current audio language models for modeling fine-grained speaker attributes.
- If the trait-state separation holds, the cards could support natural-language queries over speaker archives without retraining the core embedding model.
Load-bearing premise
The acoustic probes and constrained LLM produce accurate, unbiased field-level evidence that separates stable traits from utterance states without systematic errors or hallucinations.
What would settle it
Independent human raters finding that more than a small percentage of the generated speaker cards assign incorrect stable traits to the underlying audio would falsify the evidence-grounded premise of the corpus and the AC-Verify results.
Figures
read the original abstract
Modern speaker verification (SV) systems rely on speaker embeddings that are effective but difficult to interpret or query in natural language. Most existing speech-text corpora target controllable synthesis or utterance-level captioning, offering limited speaker-level supervision for in-the-wild speaker recognition. This paper introduces SpeakerCard-1M, a bilingual speaker resource for evidence-grounded SV, derived from VoxCeleb1/2 and CN-Celeb1/2, where the ``-1M'' suffix refers to the 1.78M utterance-level captions contained in the release. We adopt a tool-first, LLM-last approach in which ten acoustic probes produce field-level evidence, the evidence is aggregated into speaker profiles under a schema that separates relatively stable traits from utterance-level states, and bilingual Speaker Cards are rendered by a constrained LLM that sees only the structured fields. The release includes 56.7k Speaker Card records over 10.2k speakers, 1.78M utterance-level captions, and speaker-ID-disjoint hard-negative triplets. We further define two SV-oriented cross-modal protocols, bidirectional Speaker-Text Retrieval (T2S-R / S2T-R) and Attribute-Conditioned Verification (AC-Verify), and compare a dual-encoder baseline against recent audio language models under a zero-shot forced-choice setting. Joint audio-text training costs only 0.31% absolute EER on VoxCeleb1-O relative to the audio-only baseline. Under a style-symmetric LLM-generated counterfactual protocol, eight recent audio language models (7B-30B+ parameters, both open- and closed-source) score 49-77% on pitch-level AC-Verify in a 2-way forced-choice setting, compared with 88.66% for our dual encoder.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpeakerCard-1M, a corpus of 56.7k bilingual speaker cards derived from VoxCeleb1/2 and CN-Celeb1/2 using ten acoustic probes to generate field-level evidence, aggregated into profiles separating stable traits from utterance states, and rendered by a constrained LLM. The release includes 1.78M utterance captions and hard-negative triplets. It defines Speaker-Text Retrieval and Attribute-Conditioned Verification (AC-Verify) protocols, showing that joint audio-text training incurs only 0.31% absolute EER increase on VoxCeleb1-O, and that a dual encoder achieves 88.66% on pitch-level AC-Verify compared to 49-77% for eight recent audio language models.
Significance. If the construction protocol is reliable, the corpus supplies a large-scale, evidence-grounded resource that could support interpretable speaker verification and cross-modal tasks. The empirical findings indicate that joint audio-text training imposes negligible verification cost while exposing performance gaps in current audio LMs on attribute-conditioned tasks. The scale (1.78M captions) and protocol definitions constitute concrete contributions.
major comments (1)
- [Speaker Card construction and AC-Verify protocol (abstract and methods)] The validity of the evidence-grounded claim and the AC-Verify results (dual-encoder 88.66% vs. audio LMs 49-77% on pitch-level 2-way forced choice) rests on the ten acoustic probes and constrained LLM producing accurate, unbiased speaker cards that separate stable traits from states without systematic errors or hallucinations. No human validation of probe accuracy, inter-probe agreement, or LLM fidelity on held-out cards is reported anywhere in the manuscript; this is load-bearing because probe or aggregation errors would directly invalidate both the corpus description and the forced-choice comparisons.
minor comments (2)
- [Abstract] The abstract states the corpus is bilingual but does not name the languages or report language distribution across the 56.7k cards.
- [Dataset release description] Clarify how the 10.2k speakers and speaker-ID-disjoint hard-negative triplets are sampled from the source VoxCeleb/CN-Celeb pools to ensure protocol fairness is transparent.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential utility of SpeakerCard-1M. We address the single major comment below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: The validity of the evidence-grounded claim and the AC-Verify results (dual-encoder 88.66% vs. audio LMs 49-77% on pitch-level 2-way forced choice) rests on the ten acoustic probes and constrained LLM producing accurate, unbiased speaker cards that separate stable traits from states without systematic errors or hallucinations. No human validation of probe accuracy, inter-probe agreement, or LLM fidelity on held-out cards is reported anywhere in the manuscript; this is load-bearing because probe or aggregation errors would directly invalidate both the corpus description and the forced-choice comparisons.
Authors: We agree that explicit human validation of the probe outputs, aggregation rules, and LLM-rendered cards is a valuable addition that would increase confidence in the resource. The ten probes are implemented via deterministic, off-the-shelf acoustic feature extractors (e.g., pitch via YIN, energy via RMS) whose individual accuracies have been established in prior literature; the aggregation schema applies fixed thresholds to distinguish stable traits from utterance states; and the LLM prompt strictly forbids generation of information absent from the structured fields. Nevertheless, these design choices do not substitute for direct empirical checks. In the revised manuscript we will add a dedicated validation subsection reporting: (i) probe-level accuracy on a held-out set of 1,000 utterances against human annotations, (ii) inter-probe agreement on overlapping fields, and (iii) card-level fidelity judged by three independent annotators on 500 randomly sampled speaker cards, including Cohen’s kappa. These results will be used to quantify any residual error rates and to qualify the AC-Verify findings. revision: yes
Circularity Check
No circularity: corpus construction and empirical comparisons are self-contained
full rationale
The paper introduces a corpus via acoustic probes and constrained LLM rendering, then reports empirical results on retrieval and verification protocols. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. The central claims rest on released data and direct model comparisons rather than reducing to self-definitional inputs or prior author work by construction. This is the expected non-finding for a resource paper without mathematical claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X-vectors: Robust DNN embeddings for speaker recognition,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, “X-vectors: Robust DNN embeddings for speaker recognition,” inProc. of ICASSP, 2018, pp. 5329–5333
2018
-
[2]
ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification,” inProc. of Interspeech, 2020, pp. 3830– 3834
2020
-
[3]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[4]
V oxCeleb: A large-scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxCeleb: A large-scale speaker identification dataset,” inProc. of Interspeech, 2017, pp. 2616– 2620
2017
-
[5]
V oxCeleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxCeleb2: Deep speaker recognition,” inProc. of Interspeech, 2018, pp. 1086–1090
2018
-
[6]
SALMONN: Towards generic hearing abilities for large language models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “SALMONN: Towards generic hearing abilities for large language models,” inProc. of ICLR, 2024
2024
-
[7]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-Audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Danget al., “Qwen2.5-Omni technical report,”arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Can audio large language models verify speaker identity?
Y . Ren, X. Xu, B. Li, S. Wang, and C. Zhang, “Can audio large language models verify speaker identity?”arXiv preprint arXiv:2509.19755, 2025
-
[10]
PromptTTS: Controllable text-to-speech with text descriptions,
Z. Guo, Y . Leng, Y . Wu, S. Zhao, and X. Tan, “PromptTTS: Controllable text-to-speech with text descriptions,” inProc. of ICASSP, 2023, pp. 1–5
2023
-
[11]
PromptTTS 2: Describing and generating voices with text prompt,
Y . Leng, Z. Guo, K. Shen, X. Tan, Z. Ju, Y . Liu, Y . Liu, D. Yang, L. Zhang, K. Songet al., “PromptTTS 2: Describing and generating voices with text prompt,” inProc. of ICLR, 2024
2024
-
[12]
PromptTTS++: Controlling speaker identity in prompt-based text-to-speech using natural language descriptions,
R. Shimizu, R. Yamamoto, M. Kawamura, Y . Shirahata, H. Doi, T. Ko- matsu, and K. Tachibana, “PromptTTS++: Controlling speaker identity in prompt-based text-to-speech using natural language descriptions,” in Proc. of ICASSP, 2024, pp. 12 672–12 676
2024
-
[13]
SpeechCraft: A fine-grained expressive speech dataset with natural language description,
Z. Jin, J. Jia, Q. Wang, K. Li, S. Zhou, S. Zhou, X. Qin, and Z. Wu, “SpeechCraft: A fine-grained expressive speech dataset with natural language description,” inProc. of ACM Multimedia (MM), 2024
2024
-
[14]
CN-Celeb: A challenging Chinese speaker recognition dataset,
Y . Fan, J. Kang, L. Li, K. Li, H. Chen, S. Cheng, P. Zhang, Z. Zhou, Y . Cai, and D. Wang, “CN-Celeb: A challenging Chinese speaker recognition dataset,” inProc. of ICASSP, 2020, pp. 7604–7608
2020
-
[15]
CN-Celeb: Multi-genre speaker recognition,
L. Li, R. Liu, J. Kang, Y . Fan, H. Cui, Y . Cai, R. Vipperla, T. F. Zheng, and D. Wang, “CN-Celeb: Multi-genre speaker recognition,”Speech Communication, vol. 137, pp. 77–91, 2022
2022
-
[16]
Speaker- text retrieval via contrastive learning,
X. Liu, X. Wang, E. Cooper, X. Miao, and J. Yamagishi, “Speaker- text retrieval via contrastive learning,”arXiv preprint arXiv:2312.06055, 2024
-
[17]
CoLMbo: Speaker language model for descriptive profiling,
M. Baali, S. Han, S. A. Hannan, P. Samal, K. Singh, S. Deshmukh, R. Singh, and B. Raj, “CoLMbo: Speaker language model for descriptive profiling,” inProc. of IEEE Automatic Speech Recognition and Under- standing Workshop (ASRU), 2025, pp. 1–7
2025
-
[18]
T. Feng, J. Lee, A. Xu, Y . Lee, T. Lertpetchpun, X. Shi, H. Wang, T. Thebaud, L. Moro-Velazquez, D. Byrd, N. Dehak, and S. Narayanan, “V ox-Profile: A speech foundation model benchmark for characterizing diverse speaker and speech traits,”arXiv preprint arXiv:2505.14648, 2025
-
[19]
Scaling rich style- prompted text-to-speech datasets,
A. Diwan, Z. Zheng, D. Harwath, and E. Choi, “Scaling rich style- prompted text-to-speech datasets,” inProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing, 2025, pp. 3639–3659
2025
-
[20]
Speakerlm: End-to-end versatile speaker di- arization and recognition with multimodal large language models,
H. Yin, Y . Chen, C. Deng, L. Cheng, H. Wang, C.-H. Tan, Q. Chen, W. Wang, and X. Li, “Speakerlm: End-to-end versatile speaker di- arization and recognition with multimodal large language models,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 40, 2026, pp. 34 467–34 475
2026
-
[21]
Emilia: A large-scale, extensive, multilingual, and diverse dataset for speech generation,
H. He, Z. Shang, C. Wang, X. Li, Y . Gu, H. Hua, L. Liu, C. Yang, J. Li, P. Shiet al., “Emilia: A large-scale, extensive, multilingual, and diverse dataset for speech generation,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, 2025
2025
-
[22]
Disentangling style factors from speaker representations,
J. Williams and S. King, “Disentangling style factors from speaker representations,” inProc. of Interspeech, 2019, pp. 3945–3949
2019
-
[23]
ExPO: Explainable phonetic trait-oriented network for speaker verification,
Y . Ma, S. Wang, T. Liu, and H. Li, “ExPO: Explainable phonetic trait-oriented network for speaker verification,”IEEE Signal Processing Letters, vol. 32, pp. 731–735, 2025
2025
-
[24]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Y . Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou, “Qwen-Audio: Advancing universal audio understanding via unified large-scale audio-language models,”arXiv preprint arXiv:2311.07919, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio Flamingo 3: Advancing audio intelligence with fully open large audio language models,”arXiv preprint arXiv:2507.08128, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Speech-based age and gender prediction with transformers,
F. Burkhardt, J. Wagner, H. Wierstorf, F. Eyben, and B. Schuller, “Speech-based age and gender prediction with transformers,” inProc. of ITG Conference on Speech Communication, 2023, pp. 46–50
2023
-
[27]
Robust speech recognition via large-scale weak super- vision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak super- vision,” inProc. of ICML, 2023
2023
-
[28]
Brouhaha: Multi- task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation,
M. Lavechin, M. M ´etais, H. Titeux, A. Boissonnet, J. Copet, M. Rivi `ere, E. Bergelson, A. Cristia, E. Dupoux, and H. Bredin, “Brouhaha: Multi- task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation,” inProc. of IEEE ASRU Workshop, 2023
2023
-
[29]
V ocal acoustic analysis – jitter, shimmer and HNR parameters,
J. P. Teixeira, C. Oliveira, and C. Lopes, “V ocal acoustic analysis – jitter, shimmer and HNR parameters,”Procedia Technology, vol. 9, pp. 1112–1122, 2013
2013
-
[30]
Dawn of the transformer era in speech emotion recognition: Closing the valence gap,
J. Wagner, A. Triantafyllopoulos, H. Wierstorf, M. Schmitt, F. Burkhardt, F. Eyben, and B. W. Schuller, “Dawn of the transformer era in speech emotion recognition: Closing the valence gap,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 9, pp. 10 745– 10 759, 2023
2023
-
[31]
KeSpeech: An open source speech dataset of Mandarin and its eight subdialects,
Z. Tang, D. Wang, Y . Xu, J. Sun, X. Lei, S. Zhao, C. Wen, X. Tan, C. Xie, S. Zhouet al., “KeSpeech: An open source speech dataset of Mandarin and its eight subdialects,” inProc. of NeurIPS Datasets and Benchmarks Track (Round 2), 2021
2021
-
[32]
Praat, a system for doing phonetics by computer,
P. Boersma, “Praat, a system for doing phonetics by computer,”Glot International, vol. 5, no. 9/10, pp. 341–345, 2001
2001
-
[33]
Introducing Parselmouth: A Python interface to Praat,
Y . Jadoul, B. Thompson, and B. de Boer, “Introducing Parselmouth: A Python interface to Praat,”Journal of Phonetics, vol. 71, pp. 1–15, 2018
2018
-
[34]
Crepe: A convolutional representation for pitch estimation,
J. W. Kim, J. Salamon, P. Li, and J. P. Bello, “Crepe: A convolutional representation for pitch estimation,” in2018 IEEE international con- ference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 161–165
2018
-
[35]
RMVPE: A Robust Model for V ocal Pitch Estimation in Polyphonic Music,
H. Wei, X. Cao, T. Dan, and Y . Chen, “RMVPE: A Robust Model for V ocal Pitch Estimation in Polyphonic Music,” inInterspeech 2023, 2023, pp. 5421–5425
2023
-
[36]
Less annotating, more classifying: Addressing the data scarcity issue of supervised machine learning with deep transfer learning and BERT-NLI,
M. Laurer, W. van Atteveldt, A. Casas, and K. Welbers, “Less annotating, more classifying: Addressing the data scarcity issue of supervised machine learning with deep transfer learning and BERT-NLI,”Political Analysis, vol. 32, no. 1, pp. 84–100, 2024
2024
-
[37]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Qwen Team, “Qwen3-Omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
MiMo-Audio: Audio language models are few-shot learners,
LLM-Core Xiaomi, “MiMo-Audio: Audio language models are few-shot learners,”arXiv preprint arXiv:2512.23808, 2025
-
[40]
KimiTeam, “Kimi-Audio technical report,”arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, “Gemini: A family of highly capable multimodal models,” arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
An attention-based backend allowing efficient fine-tuning of transformer models for speaker verification,
J. Peng, O. Plchot, T. Stafylakis, L. Mo ˇsner, L. Burget, and J. ˇCernock´y, “An attention-based backend allowing efficient fine-tuning of transformer models for speaker verification,” inProc. of IEEE Spoken Language Technology Workshop (SLT), 2023, pp. 555–562
2023
-
[43]
CA-MHFA: A context-aware multi-head factorized atten- tive pooling for SSL-based speaker verification,
J. Peng, L. Mo ˇsner, L. Zhang, O. Plchot, T. Stafylakis, L. Burget, and J. ˇCernock´y, “CA-MHFA: A context-aware multi-head factorized atten- tive pooling for SSL-based speaker verification,” inProc. of ICASSP, 2025, pp. 1–5
2025
-
[44]
WeSpeaker: A research and production oriented speaker embedding learning toolkit,
H. Wang, C. Liang, S. Wang, Z. Chen, B. Zhang, X. Xiang, Y . Deng, and Y . Qian, “WeSpeaker: A research and production oriented speaker embedding learning toolkit,” inProc. of ICASSP, 2023, pp. 1–5
2023
-
[45]
BGE M3-Embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation,
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu, “BGE M3-Embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 2318– 2335
2024
-
[46]
ArcFace: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “ArcFace: Additive angular margin loss for deep face recognition,” inProc. of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4690– 4699
2019
-
[47]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[48]
MUSAN: A Music, Speech, and Noise Corpus
D. Snyder, G. Chen, and D. Povey, “MUSAN: A music, speech, and noise corpus,”arXiv preprint arXiv:1510.08484, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[49]
A study on data augmentation of reverberant speech for robust speech recognition,
T. Ko, V . Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A study on data augmentation of reverberant speech for robust speech recognition,” inProc. of ICASSP, 2017, pp. 5220–5224
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.