SEA-NLI: Natural Language Inference as a Lens into Southeast Asian Cultural Understanding
Pith reviewed 2026-06-28 10:17 UTC · model grok-4.3
The pith
All tested language models show low performance on Southeast Asian cultural NLI mainly due to missing cultural knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SEA-NLI shows that frontier language models perform poorly on culturally grounded reasoning from Southeast Asia, with the performance gaps driven primarily by missing regional cultural knowledge that can be partially addressed through model adaptation to the region and culture-aware prompting strategies.
What carries the argument
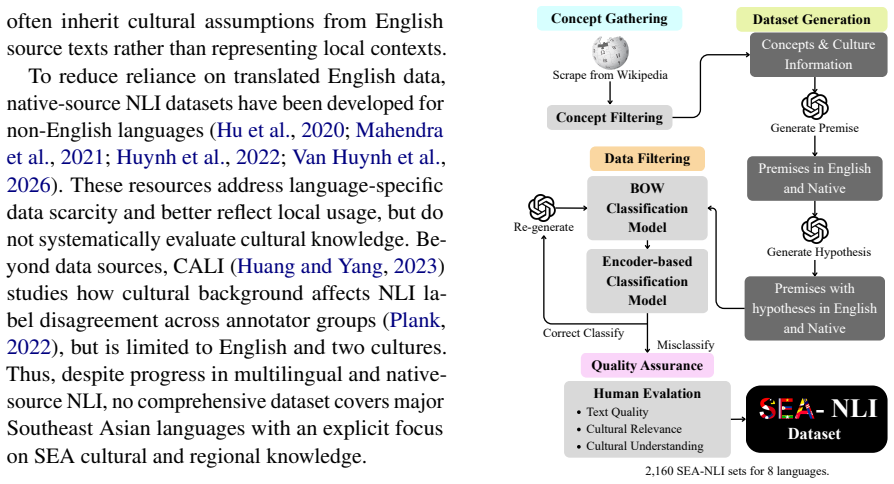
The SEA-NLI benchmark, a set of premise-hypothesis pairs that test culturally specific Southeast Asian facts and norms across eight countries and multiple languages.
If this is right
- SEA-adapted models achieve higher accuracy than general-purpose models on the benchmark.
- Culture-aware prompting produces measurable improvements in model performance.
- Chain-of-thought prompting offers only limited gains compared with culture-aware methods.
- The largest drops occur in knowledge-intensive categories such as Languages and Science and Technology.
Where Pith is reading between the lines
- Similar knowledge gaps are likely present for other underrepresented regions when current models are tested on native cultural reasoning tasks.
- Benchmarks focused on specific cultural contexts can be used to measure progress toward more geographically balanced language models.
- Targeted data collection for underrepresented cultures may be required to close the gaps identified here.
Load-bearing premise
The benchmark items are verifiably culturally grounded and representative of Southeast Asian reasoning, and the observed performance gaps are driven primarily by missing cultural knowledge rather than language modeling difficulty, annotation artifacts, or task formulation.
What would settle it
A model given extensive additional training on Southeast Asian cultural texts and languages that still scores as poorly as the current models on SEA-NLI would challenge the claim that missing cultural knowledge is the main source of errors.
Figures









read the original abstract
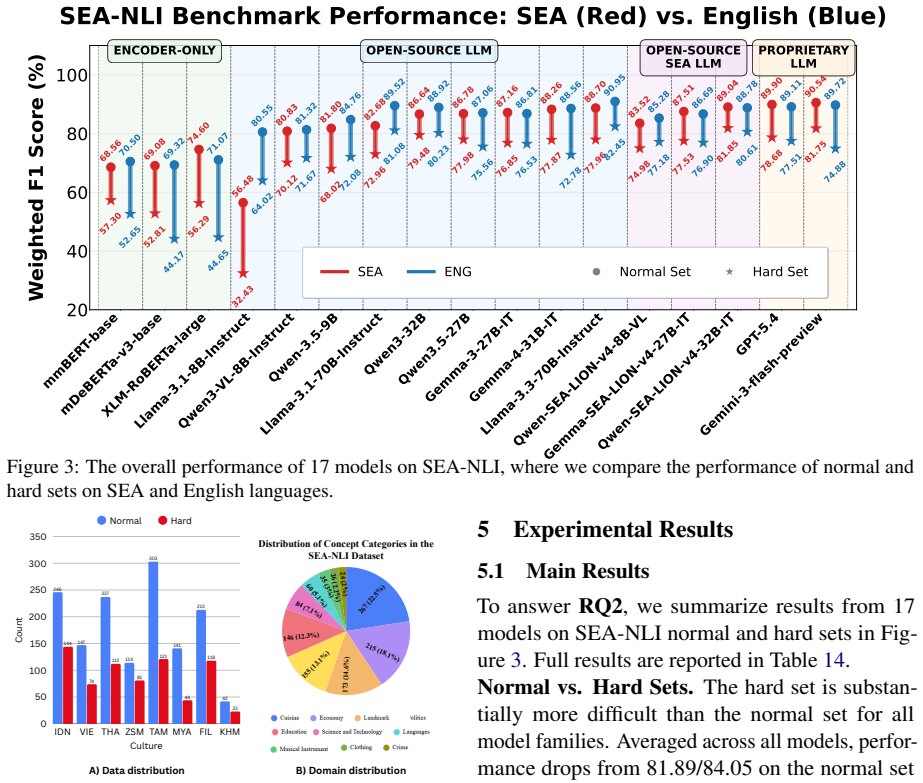
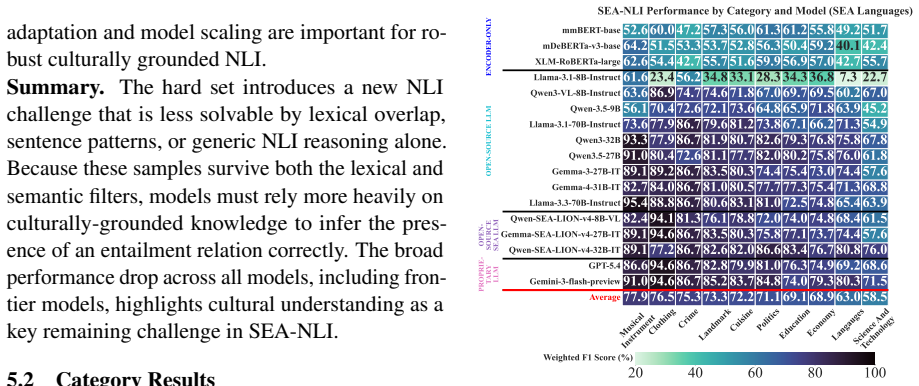
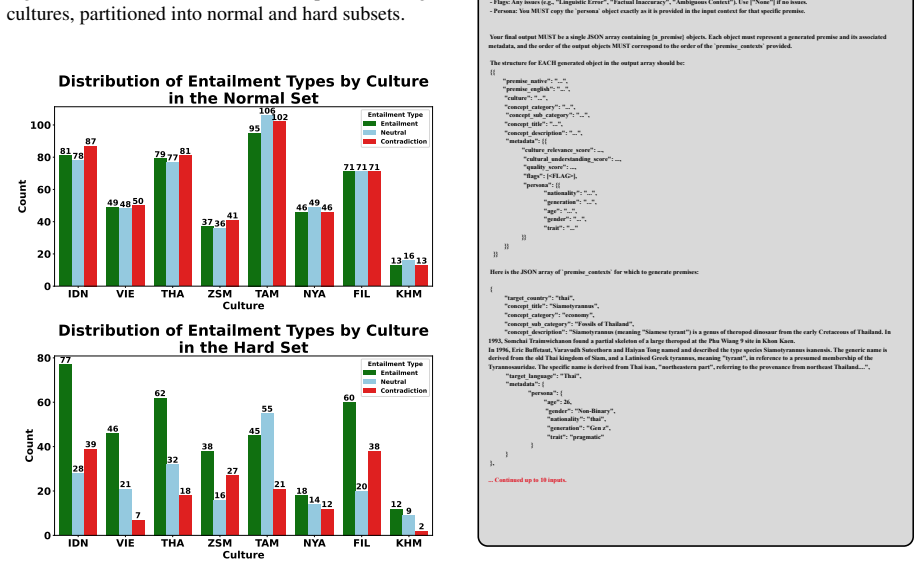
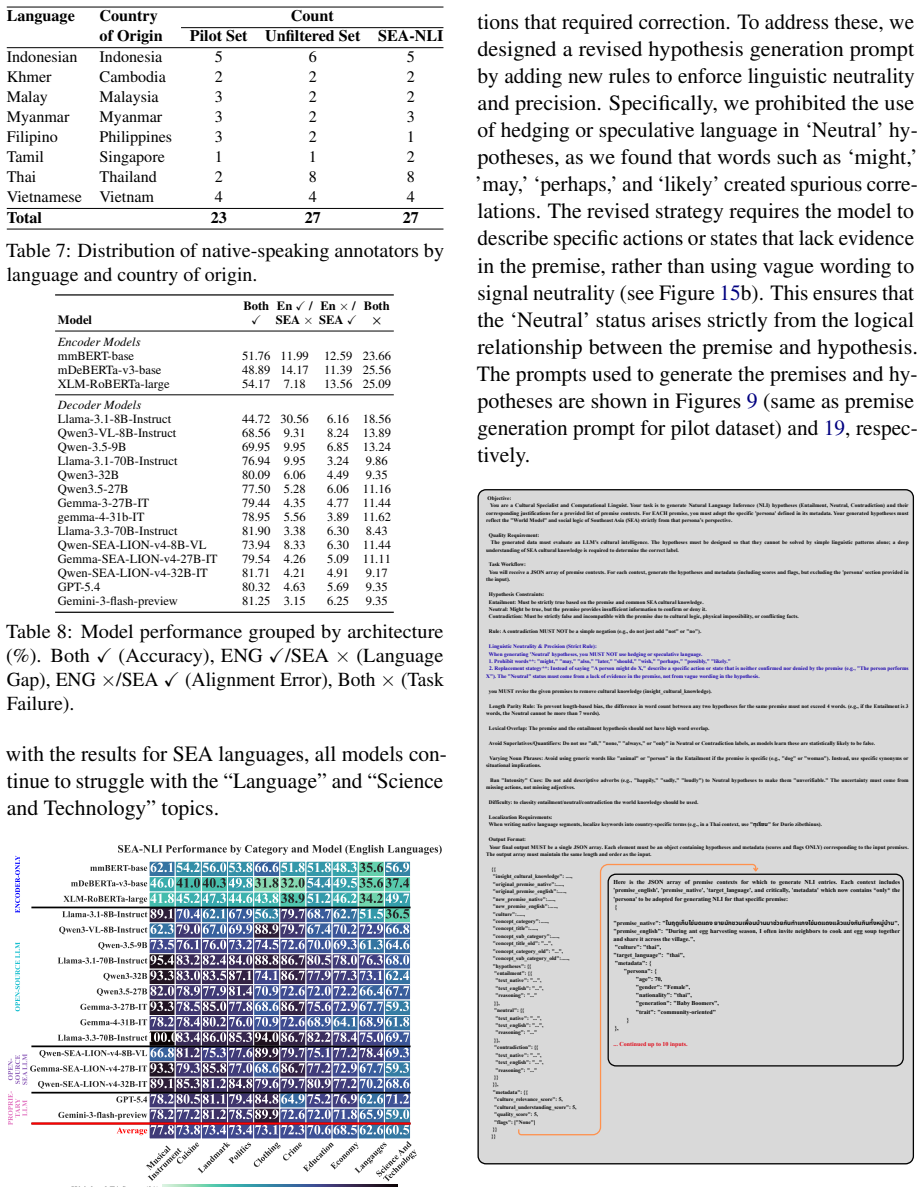
Frontier LLMs perform well in Western contexts, but remain poorly tested on underrepresented cultures such as those in Southeast Asia (SEA). Existing NLI benchmarks are largely Western-centric, translation-derived, or monolingual, limiting their ability to measure culturally grounded reasoning. We introduce SEA-NLI, a native, culturally grounded NLI benchmark covering eight SEA countries in English and native regional languages, verified by native speakers. Across 17 encoder and decoder models, we observe a low performance from all models, especially for knowledge-intensive categories such as Languages and Science and Technology. Our analysis shows that failure cases mainly stem from missing SEA cultural knowledge: SEA-adapted models and culture-aware prompting improve performance, while CoT prompting offers limited gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SEA-NLI, a native, culturally grounded NLI benchmark spanning eight Southeast Asian countries in English and regional languages, verified by native speakers. It evaluates 17 encoder and decoder models, reports low overall performance (especially in knowledge-intensive categories such as Languages and Science and Technology), and attributes failures primarily to missing SEA cultural knowledge, with supporting evidence from gains under SEA-adapted models and culture-aware prompting (while CoT yields limited benefit).
Significance. If the items are verifiably representative and the performance gaps are driven by absent cultural knowledge rather than confounds, the benchmark would be a useful diagnostic for culturally inclusive LLM evaluation. The empirical scope across multiple models and prompting conditions is a strength; the native construction and verification process also addresses a clear gap in existing Western-centric or translated NLI resources.
major comments (2)
- [Abstract] Abstract: The central claim that 'failure cases mainly stem from missing SEA cultural knowledge' is load-bearing for the paper's conclusions yet lacks isolating controls; no accuracy comparisons to translated Western NLI items in the same languages, culturally stripped variants, or quantitative measures of pretraining coverage/tokenization difficulty are reported, leaving the causal attribution underdetermined relative to language-modeling artifacts.
- [Abstract] Abstract: Native-speaker verification is asserted but without reported inter-annotator agreement statistics, annotator count, exclusion criteria, or agreement thresholds on cultural grounding, which are required to substantiate that the observed category-level drops reflect genuine cultural knowledge gaps rather than annotation artifacts.
minor comments (1)
- [Abstract] Abstract: The exact number of premise-hypothesis pairs, distribution across the eight countries, and breakdown by language (English vs. native) could be stated explicitly to allow readers to assess scale and balance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and note planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'failure cases mainly stem from missing SEA cultural knowledge' is load-bearing for the paper's conclusions yet lacks isolating controls; no accuracy comparisons to translated Western NLI items in the same languages, culturally stripped variants, or quantitative measures of pretraining coverage/tokenization difficulty are reported, leaving the causal attribution underdetermined relative to language-modeling artifacts.
Authors: We agree that direct isolating controls (e.g., translated Western NLI items or culturally stripped variants) would provide stronger causal evidence. Our current support for the claim rests on the observed performance improvements from SEA-adapted models and culture-aware prompting, contrasted with limited gains from CoT. We will revise the discussion and limitations sections to explicitly acknowledge this gap and clarify that tokenization effects are partially addressed by the English and native-language versions, though quantitative pretraining coverage analysis is not feasible without additional resources. No new experiments will be added. revision: partial
-
Referee: [Abstract] Abstract: Native-speaker verification is asserted but without reported inter-annotator agreement statistics, annotator count, exclusion criteria, or agreement thresholds on cultural grounding, which are required to substantiate that the observed category-level drops reflect genuine cultural knowledge gaps rather than annotation artifacts.
Authors: We will update the manuscript to report the full details of the native-speaker verification process, including inter-annotator agreement statistics, annotator counts, exclusion criteria, and agreement thresholds. These data were collected during benchmark construction and will be added to the methods and appendix sections. revision: yes
Circularity Check
No circularity: purely empirical benchmark construction and model evaluation
full rationale
The paper introduces a new native NLI dataset for SEA cultures, verifies items with native speakers, and reports empirical accuracies across 17 models plus prompt variants. No derivations, equations, fitted parameters, or first-principles predictions exist that could reduce to inputs by construction. Claims about cultural knowledge gaps rest on observed performance differences and prompt improvements rather than any self-referential definition or self-citation chain. The work is self-contained against external benchmarks (model evaluations on the released dataset) and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural language inference can function as a lens into cultural understanding
Reference graph
Works this paper leans on
-
[1]
Flans at semeval-2026 task 7: Rag with open-sourced smaller llms for everyday knowledge across diverse languages and cultures.Preprint, arXiv:2603.01910. Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large anno- tated corpus for learning natural language inference. 9 InProceedings of the 2015 Conference on Empiri- ...
-
[2]
Global MMLU: Understanding and addressing cultural and linguistic biases in multilingual evalua- tion. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 18761–18799, Vienna, Austria. 11 Joe Stacey, Lisa Alazraki, Aran Ubhi, Beyza Ermis, Aaron Mueller, and Marek Rei. 2026. Improving t...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Not all countries celebrate thanksgiving: On the cultural dominance in large language models. In Proceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 6349–6384, Bangkok, Thailand. Gijs Wijnholds and Michael Moortgat. 2021. SICK- NL: A dataset for Dutch natural language inference. InProcee...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
- Neutral MUST remain neither entailed nor contradicted
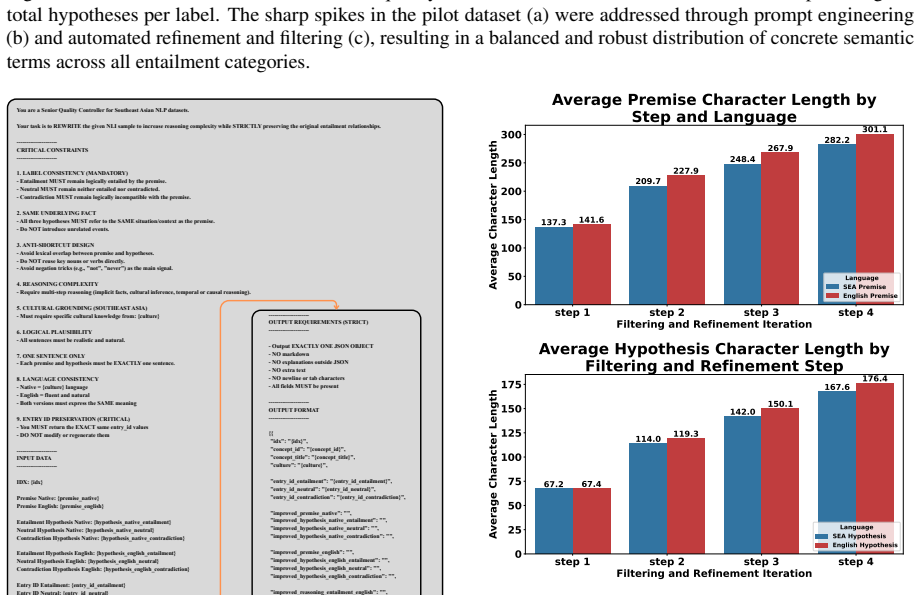
LABEL CONSISTENCY (MANDATORY) - Entailment MUST remain logically entailed by the premise. - Neutral MUST remain neither entailed nor contradicted. - Contradiction MUST remain logically incompatible with the premise
-
[5]
- Do NOT introduce unrelated events
SAME UNDERLYING FACT - All three hypotheses MUST refer to the SAME situation/context as the premise. - Do NOT introduce unrelated events
-
[6]
not", "never
ANTI-SHORTCUT DESIGN - Avoid lexical overlap between premise and hypotheses. - Do NOT reuse key nouns or verbs directly. - Avoid negation tricks (e.g., "not", "never") as the main signal
-
[7]
REASONING COMPLEXITY - Require multi-step reasoning (implicit facts, cultural inference, temporal or causal reasoning)
-
[8]
CULTURAL GROUNDING (SOUTHEAST ASIA) - Must require specific cultural knowledge from: {culture}
-
[9]
LOGICAL PLAUSIBILITY - All sentences must be realistic and natural
-
[10]
ONE SENTENCE ONLY - Each premise and hypothesis must be EXACTLY one sentence
-
[11]
LANGUAGE CONSISTENCY - Native = {culture} language - English = fluent and natural - Both versions must express the SAME meaning
-
[12]
idx": "{idx}
ENTRY ID PRESERVATION (CRITICAL) - You MUST return the EXACT same entry_id values - DO NOT modify or regenerate them --------------------- INPUT DATA --------------------- IDX: {idx} Premise Native: {premise_native} Premise English: {premise_english} Entailment Hypothesis Native: {hypothesis_native_entailment} Neutral Hypothesis Native: {hypothesis_native...
-
[13]
(2025), this metric assesses how effectively the generated content aligns with the intended Southeast Asian (SEA) cul- tural context
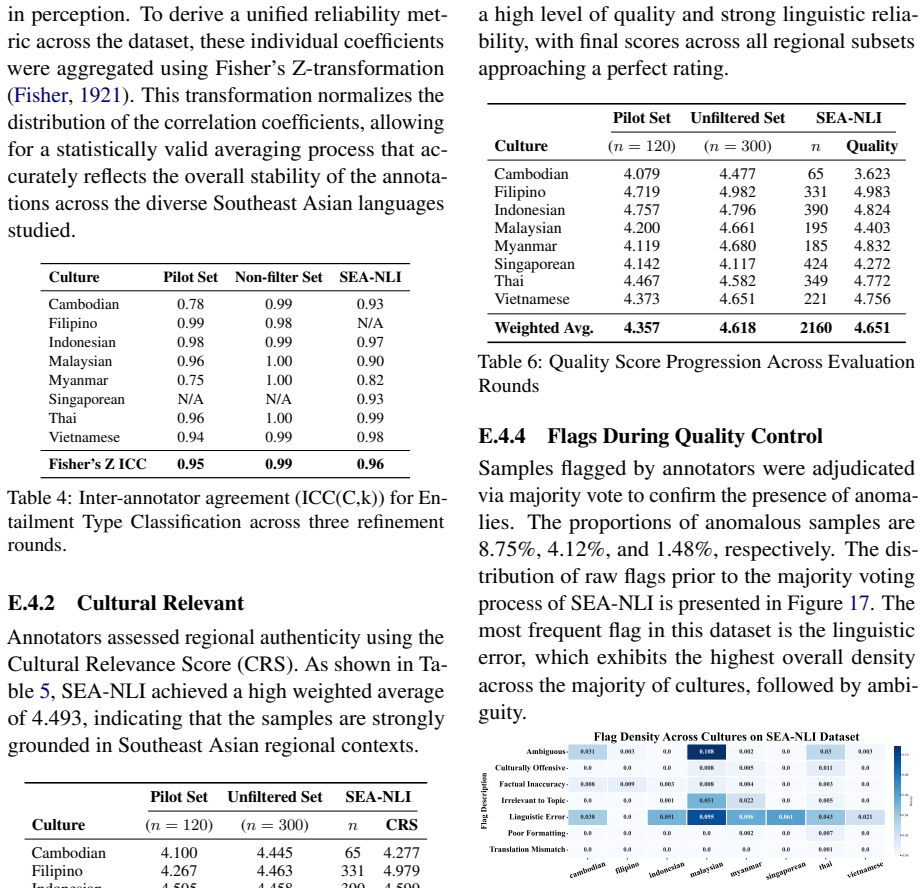
Cultural Relevance Score:Adapted from Cahyawijaya et al. (2025), this metric assesses how effectively the generated content aligns with the intended Southeast Asian (SEA) cul- tural context. • Score 5 (Unique to SEA):The premise describes traditions, objects, or landmarks that originate in SEA and are considered iconic, such as Pad Thai, Batik, Songkran, ...
2025
-
[14]
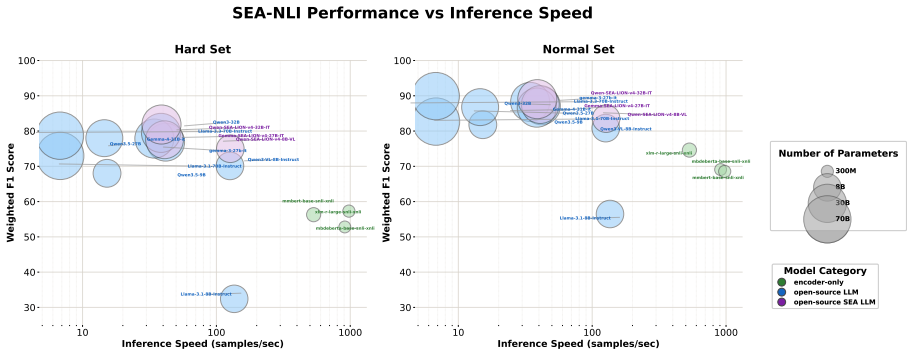
Cultural Understanding Score:This score quantifies the annotator’s personal familiarity with the specific cultural context of the sam- ple. 16 10 100 1000 Inference Speed (samples/sec) 30 40 50 60 70 80 90 100Weighted F1 Score Hard Set mbdeberta-base-snli-xnli xlm-r-large-snli-xnli mmbert-base-snli-xnli Qwen3-VL-8B-Instruct Qwen3.5-9B Qwen-SEA-LION-v4-8B-...
-
[15]
• Score 5 (Excellent):The sentence is natu- ral, grammatically perfect, and provides a clear cultural context
Quality Score:This metric evaluates the lin- guistic clarity and contextual accuracy of the premise and its associated metadata. • Score 5 (Excellent):The sentence is natu- ral, grammatically perfect, and provides a clear cultural context. • Score 4 (Good):The sentence is clear and usable, with only minor stylistic awkward- ness. • Score 3 (Fair):The sent...
-
[16]
Language
Flagging Issues:Annotators identify specific qualitative concerns that may impact the relia- bility of the sample. These include: • Linguistic Error:Significant grammar, spelling, or translation issues. • Factual Inaccuracy:The premise con- tains incorrect information regarding the culture or location. • Ambiguous Context:The statement is too vague to det...
1979
-
[17]
might,"
Prohibit words**: "might," "may," "also," "later," "should," "wish," "perhaps," "possibly," "likely."
-
[18]
A person might do X,
Replacement stategy**: Instead of saying "A person might do X," describe a specific action or state that is neither confirmed nor denied by the premise (e.g., "The person performs X"). The "Neutral" status must come from a lack of evidence in the premise, not from vague wording in the hypothesis. you MUST revise the given premises to remove cultural knowl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.