A Graph Foundation Model with Spectral Parsing and Prototype-Guided Spatial Propagation
Pith reviewed 2026-06-28 11:32 UTC · model grok-4.3
The pith
SPG decomposes graph signals by frequency with learnable Chebyshev filters and distills structural relations into a shared prototype geometry for cross-graph transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
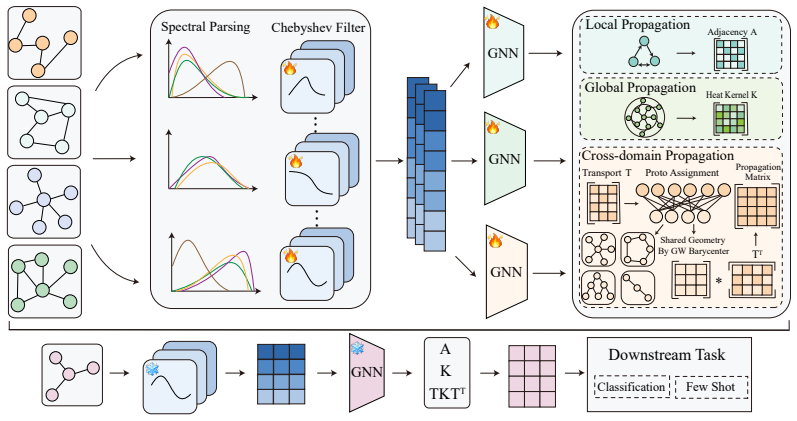
SPG applies learnable Chebyshev filters to decompose node features into multiple spectral responses, reducing the mismatch between frequency-specific graph signals and propagation behaviors. It then constructs a Gromov-Wasserstein prototype geometry to distill transferable pairwise relations beyond predefined substructures into a shared structural space. The learned prototype geometry is further projected back as a prototype-guided propagation operator. Experiments demonstrate consistent improvements in cross-domain generalization.
What carries the argument
Learnable Chebyshev filters for spectral parsing of node features combined with a Gromov-Wasserstein prototype geometry that produces a reusable propagation operator.
If this is right
- Propagation rules can be learned separately for high-frequency and low-frequency signal parts instead of using a single entangled operator.
- Structural knowledge can move between graphs even when those graphs share no common predefined motifs such as cycles or trees.
- A single trained model can serve as a foundation that supplies ready-made propagation behavior to new graphs without retraining the full architecture.
- Cross-domain tasks become feasible because the model stores relations in an abstract prototype space rather than in graph-specific token vocabularies.
Where Pith is reading between the lines
- The same spectral-plus-prototype pattern could be tested on time-varying graphs to see whether the geometry remains stable when edges appear or disappear.
- Replacing the Gromov-Wasserstein step with other optimal-transport distances might reveal whether the particular choice of distance metric is essential for the transfer gains.
- If the prototype geometry truly encodes universal relations, it could be inspected after training to extract human-readable descriptions of common structural motifs that appear across domains.
Load-bearing premise
Learnable Chebyshev filters can separate frequency components in graph signals in a way that aligns with the propagation behaviors actually needed, and the resulting prototype geometry captures relations that transfer across graphs without depending on any fixed list of substructures.
What would settle it
An ablation study on cross-domain benchmark graphs that removes either the spectral decomposition step or the prototype geometry step and finds no gain or a loss in transfer accuracy would falsify the claim that these two components together drive the reported generalization improvement.
Figures


read the original abstract
Graph foundation models aim to learn transferable knowledge from diverse graphs for generalization to unseen graphs and tasks. Unlike text and images, graphs lack a shared vocabulary or regular spatial grid, making cross-graph transfer challenging. This challenge comes from both feature discrepancies and, more critically, diverse graph structures. Existing GFMs mainly improve transferability by unifying feature spaces or incorporating structural tokens and vocabularies. However, existing topology-aware designs still have limitations. Structural tokens are usually discrete, while structural vocabularies often rely on predefined substructures such as trees and cycles, whose limited coverage may miss richer relational patterns across graphs. Moreover, graph signals contain both high-frequency local patterns and smoother low-frequency patterns, which require different propagation behaviors. These components are often entangled in raw graph signals, while this spectral perspective is rarely explored in existing GFMs. To address these challenges, we propose SPG, a graph foundation model with spectral parsing and prototype-guided spatial propagation. SPG applies learnable Chebyshev filters to decompose node features into multiple spectral responses, reducing the mismatch between frequency-specific graph signals and propagation behaviors. It then constructs a Gromov-Wasserstein prototype geometry to distill transferable pairwise relations beyond predefined substructures into a shared structural space. The learned prototype geometry is further projected back as a prototype-guided propagation operator. Experiments demonstrate consistent improvements in cross-domain generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPG, a graph foundation model for cross-graph transfer. It decomposes node features via learnable Chebyshev filters into multiple spectral responses to better match frequency-specific signals with propagation, then builds a Gromov-Wasserstein prototype geometry to extract transferable pairwise relations beyond predefined substructures (e.g., trees or cycles), and projects this geometry back as a prototype-guided propagation operator. Experiments are stated to show consistent gains in cross-domain generalization.
Significance. If the mechanisms prove effective, the work could advance graph foundation models by combining spectral parsing with optimal-transport prototype alignment, addressing both the entanglement of frequency components in graph signals and the limitations of discrete structural tokens or narrow vocabularies. This offers a pathway to more flexible structural transfer without relying on hand-crafted substructures.
minor comments (2)
- The abstract asserts experimental improvements but provides no quantitative details, baselines, or dataset descriptions; the full manuscript should include these in a dedicated experiments section with error bars and ablation studies to substantiate the cross-domain claims.
- Notation for the learnable Chebyshev filter coefficients and the Gromov-Wasserstein distance in the prototype geometry should be introduced with explicit equations early in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive recommendation for minor revision. The assessment correctly identifies the core contributions of spectral decomposition via Chebyshev filters and Gromov-Wasserstein prototype geometry for cross-graph transfer. Since no specific major comments were raised, we address the overall evaluation below.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's pipeline—learnable Chebyshev filters for spectral decomposition of node features, followed by Gromov-Wasserstein prototype geometry to capture pairwise relations, then projection as a propagation operator—is presented as a sequential application of standard techniques without any equations or steps that reduce a claimed prediction or result to its own fitted inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled via prior work, and no renaming of known empirical patterns occurs. The abstract and description supply an independent mechanistic account whose internal consistency does not collapse to tautology; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of learnable Chebyshev filters
axioms (2)
- domain assumption Node features on graphs admit a useful decomposition into multiple spectral responses via Chebyshev filters
- domain assumption Gromov-Wasserstein distance on pairwise relations yields transferable prototypes beyond predefined substructures
invented entities (1)
-
Gromov-Wasserstein prototype geometry
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Position: Graph foundation models are already here
Haitao Mao, Zhikai Chen, Wenzhuo Tang, Jianan Zhao, Yao Ma, Tong Zhao, Neil Shah, Mikhail Galkin, and Jiliang Tang. Position: Graph foundation models are already here. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024
2024
-
[2]
Graph foundation models: A comprehensive survey.arXiv preprint arXiv:2505.15116, 2025
Zehong Wang, Zheyuan Liu, Tianyi Ma, Jiazheng Li, Zheyuan Zhang, Xingbo Fu, Yiyang Li, Zhengqing Yuan, Wei Song, Yijun Ma, et al. Graph foundation models: A comprehensive survey.arXiv preprint arXiv:2505.15116, 2025
- [3]
-
[4]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S. Yu. A comprehensive survey on graph neural networks.IEEE Trans. Neural Networks Learn. Syst., 32 (1):4–24, 2021. doi: 10.1109/TNNLS.2020.2978386
-
[7]
Graph neural networks: A review of methods and applications.AI open, 1:57–81, 2020
Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun. Graph neural networks: A review of methods and applications.AI open, 1:57–81, 2020
2020
-
[8]
Laplacian eigenmaps for dimensionality reduction and data representation.Neural Computation, 15(6):1373–1396, 2003
Mikhail Belkin and Partha Niyogi. Laplacian eigenmaps for dimensionality reduction and data representation.Neural Computation, 15(6):1373–1396, 2003
2003
-
[9]
Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. One for all: Towards training one graph model for all classification tasks.arXiv preprint arXiv:2310.00149, 2023
-
[10]
Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings.Advances in neural information processing systems, 37:5950–5973, 2024
Duo Wang, Yuan Zuo, Fengzhi Li, and Junjie Wu. Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings.Advances in neural information processing systems, 37:5950–5973, 2024. 10
2024
-
[11]
Llaga: Large language and graph assistant
Runjin Chen, Tong Zhao, Ajay Kumar Jaiswal, Neil Shah, and Zhangyang Wang. Llaga: Large language and graph assistant. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024...
2024
-
[12]
Graphgpt: Graph instruction tuning for large language models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. Graphgpt: Graph instruction tuning for large language models. In Grace Hui Yang, Hongning Wang, Sam Han, Claudia Hauff, Guido Zuccon, and Yi Zhang, editors,Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retriev...
-
[13]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. URL https://openreview.net/forum?id=SJU4ayYgl
2017
-
[14]
Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing
Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. Ininternational conference on machine learning, pages 21–29. PMLR, 2019
2019
-
[15]
Diffusion improves graph learning
Johannes Klicpera, Stefan Weißenberger, and Stephan Günnemann. Diffusion improves graph learning. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors,Advances in Neural Infor- mation Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Dece...
2019
-
[16]
Chawla, Chuxu Zhang, and Yanfang Ye
Zehong Wang, Zheyuan Zhang, Nitesh V . Chawla, Chuxu Zhang, and Yanfang Ye. GFT: graph foundation model with transferable tree vocabulary. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, edi- tors,Advances in Neural Information Processing Systems 38: Annual Conference on Neural Informatio...
2024
-
[17]
Multi-domain graph foundation models: Robust knowledge transfer via topology alignment
Shuo Wang, Bokui Wang, Zhixiang Shen, Boyan Deng, and Zhao Kang. Multi-domain graph foundation models: Robust knowledge transfer via topology alignment. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Forty-second International Conference on Machine Learning, ICML 2025,...
2025
-
[18]
Riemanngfm: Learning a graph foundation model from riemannian geometry
Li Sun, Zhenhao Huang, Suyang Zhou, Qiqi Wan, Hao Peng, and Philip Yu. Riemanngfm: Learning a graph foundation model from riemannian geometry. InProceedings of the ACM on Web Conference 2025, pages 1154–1165, 2025
2025
-
[19]
Opengraph: Towards open graph foundation models
Lianghao Xia, Ben Kao, and Chao Huang. Opengraph: Towards open graph foundation models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 2365–2379, 2024
2024
-
[20]
Samgpt: Text-free graph foundation model for multi-domain pre-training and cross-domain adaptation
Xingtong Yu, Zechuan Gong, Chang Zhou, Yuan Fang, and Hui Zhang. Samgpt: Text-free graph foundation model for multi-domain pre-training and cross-domain adaptation. InProceedings of the ACM on Web Conference 2025, pages 1142–1153, 2025
2025
-
[21]
Autogfm: Automated graph foundation model with adaptive architecture customization
Haibo Chen, Xin Wang, Zeyang Zhang, Haoyang Li, Ling Feng, and Wenwu Zhu. Autogfm: Automated graph foundation model with adaptive architecture customization. InForty-second International Conference on Machine Learning, 2025. 11
2025
-
[22]
Spectral invariant learning for dynamic graphs under distribution shifts.Advances in Neural Information Processing Systems, 36:6619–6633, 2023
Zeyang Zhang, Xin Wang, Ziwei Zhang, Zhou Qin, Weigao Wen, Hui Xue, Haoyang Li, and Wenwu Zhu. Spectral invariant learning for dynamic graphs under distribution shifts.Advances in Neural Information Processing Systems, 36:6619–6633, 2023
2023
-
[23]
Graph neural networks are more than filters: Revisiting and benchmarking from A spectral perspective
Yushun Dong, Patrick Soga, Yinhan He, Song Wang, and Jundong Li. Graph neural networks are more than filters: Revisiting and benchmarking from A spectral perspective. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[24]
URLhttps://openreview.net/forum?id=nWdQX5hOL9
OpenReview.net, 2025. URLhttps://openreview.net/forum?id=nWdQX5hOL9
2025
-
[25]
Restricted global-aware graph filters bridging gnns and transformer for node classification
Jingyuan Zhang, Xin Wang, Lei Yu, Zhirong Huang, Li Yang, and Fengjun Zhang. Restricted global-aware graph filters bridging gnns and transformer for node classification. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems
-
[26]
Convolutional neural networks on graphs with fast localized spectral filtering.Advances in neural information processing systems, 29, 2016
Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering.Advances in neural information processing systems, 29, 2016
2016
-
[27]
Gromov–Wasserstein Distances and the Metric Approach to Object Matching
Facundo Mémoli. Gromov-wasserstein distances and the metric approach to object matching. Found. Comput. Math., 11(4):417–487, 2011. doi: 10.1007/S10208-011-9093-5. URL https: //doi.org/10.1007/s10208-011-9093-5
-
[28]
Optimal transport for structured data with application on graphs
Vayer Titouan, Nicolas Courty, Romain Tavenard, and Rémi Flamary. Optimal transport for structured data with application on graphs. InInternational Conference on Machine Learning, pages 6275–6284. PMLR, 2019
2019
-
[29]
Fused gromov-wasserstein graph mixup for graph-level classifications
Xinyu Ma, Xu Chu, Yasha Wang, Yang Lin, Junfeng Zhao, Liantao Ma, and Wenwu Zhu. Fused gromov-wasserstein graph mixup for graph-level classifications. In Alice Oh, Tris- tan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processin...
2023
-
[30]
Gromov–wasserstein distances and the metric approach to object matching
Facundo Mémoli. Gromov–wasserstein distances and the metric approach to object matching. Foundations of computational mathematics, 11(4):417–487, 2011
2011
-
[31]
Spectral Networks and Locally Connected Networks on Graphs
Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. Spectral networks and locally connected networks on graphs. In Yoshua Bengio and Yann LeCun, editors,2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014. URLhttp://arxiv.org/abs/1312.6203
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Antonio Ortega, Pascal Frossard, Jelena Kovacevic, José M. F. Moura, and Pierre Vandergheynst. Graph signal processing: Overview, challenges, and applications.Proc. IEEE, 106(5):808–828,
-
[33]
Proceedings of the IEEE , author =
doi: 10.1109/JPROC.2018.2820126. URL https://doi.org/10.1109/JPROC.2018. 2820126
-
[34]
Wavelets on Graphs via Spectral Graph Theory
David K. Hammond, Pierre Vandergheynst, and Rémi Gribonval. Wavelets on graphs via spectral graph theory.CoRR, abs/0912.3848, 2009. URLhttp://arxiv.org/abs/0912.3848
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[35]
Singular value decomposition and least squares solutions
Gene H Golub and Christian Reinsch. Singular value decomposition and least squares solutions. InLinear algebra, pages 134–151. Springer, 1971
1971
-
[36]
Gromov-wasserstein averaging of kernel and distance matrices
Gabriel Peyré, Marco Cuturi, and Justin Solomon. Gromov-wasserstein averaging of kernel and distance matrices. InInternational conference on machine learning, pages 2664–2672. PMLR, 2016
2016
-
[37]
Collective classification in network data.AI magazine, 29(3):93–93, 2008
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi- Rad. Collective classification in network data.AI magazine, 29(3):93–93, 2008
2008
-
[38]
Geom-gcn: Geometric graph convolutional networks
Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. Geom-gcn: Geometric graph convolutional networks. In8th International Conference on Learning Repre- sentations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020. URL https://openreview.net/forum?id=S1e2agrFvS. 12
2020
-
[39]
Pitfalls of Graph Neural Network Evaluation
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of graph neural network evaluation.CoRR, abs/1811.05868, 2018. URL http:// arxiv.org/abs/1811.05868
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020
2020
-
[41]
TUDataset: A collection of benchmark datasets for learning with graphs
Christopher Morris, Nils M. Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. Tudataset: A collection of benchmark datasets for learning with graphs.CoRR, abs/2007.08663, 2020. URLhttps://arxiv.org/abs/2007.08663
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[42]
Deep graph contrastive representation learning.arXiv preprint arXiv:2006.04131, 2020
Yanqiao Zhu, Yichen Xu, Feng Yu, Qiang Liu, Shu Wu, and Liang Wang. Deep graph contrastive representation learning.arXiv preprint arXiv:2006.04131, 2020
-
[43]
Bootstrapped representation learning on graphs
Shantanu Thakoor, Corentin Tallec, Mohammad Gheshlaghi Azar, Rémi Munos, Petar Veliˇckovi´c, and Michal Valko. Bootstrapped representation learning on graphs. InICLR 2021 workshop on geometrical and topological representation learning, pages 1–14. OpenReview. net, 2021
2021
-
[44]
Graphmae2: A decoding-enhanced masked self-supervised graph learner
Zhenyu Hou, Yufei He, Yukuo Cen, Xiao Liu, Yuxiao Dong, Evgeny Kharlamov, and Jie Tang. Graphmae2: A decoding-enhanced masked self-supervised graph learner. InProceedings of the ACM web conference 2023, pages 737–746, 2023
2023
-
[45]
All in one and one for all: A simple yet effective method towards cross-domain graph pretraining
Haihong Zhao, Aochuan Chen, Xiangguo Sun, Hong Cheng, and Jia Li. All in one and one for all: A simple yet effective method towards cross-domain graph pretraining. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4443–4454, 2024
2024
-
[46]
Fully-inductive node classification on arbitrary graphs.arXiv preprint arXiv:2405.20445, 2024
Jianan Zhao, Zhaocheng Zhu, Mikhail Galkin, Hesham Mostafa, Michael Bronstein, and Jian Tang. Fully-inductive node classification on arbitrary graphs.arXiv preprint arXiv:2405.20445, 2024
-
[47]
Towards graph foundation model: Node feature transfer invariant modeling on general graphs
Jitao Zhao, Yi Wang, Yawen Li, Dongxiao He, Di Jin, Zhiyong Feng, and Weixiong Zhang. Towards graph foundation model: Node feature transfer invariant modeling on general graphs. In Hakim Hacid, Yoelle Maarek, Francesco Bonchi, Ido Guy, and Emine Yilmaz, editors, Proceedings of the ACM Web Conference 2026, WWW 2026, Dubai, United Arab Emirates, originally ...
- [48]
-
[49]
doi: 10.48550/ARXIV .2603.00618. URL https://doi.org/10.48550/arXiv.2603. 00618
work page internal anchor Pith review doi:10.48550/arxiv
-
[50]
Petar Veliˇckovi´c, William Fedus, William L Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. Deep graph infomax.arXiv preprint arXiv:1809.10341, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[51]
One for all: Towards training one graph model for all classification tasks
Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. One for all: Towards training one graph model for all classification tasks. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[52]
OpenReview.net, 2024
2024
-
[53]
Unigraph: Learning a unified cross- domain foundation model for text-attributed graphs
Yufei He, Yuan Sui, Xiaoxin He, and Bryan Hooi. Unigraph: Learning a unified cross- domain foundation model for text-attributed graphs. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 448–459, 2025
2025
-
[54]
spectral distribution after parsing
Zehong Wang, Zheyuan Zhang, Nitesh V Chawla, Chuxu Zhang, and Yanfang Ye. Gft: Graph foundation model with transferable tree vocabulary.Advances in neural information processing systems, 37:107403–107443, 2024. 13 A Detailed Theory and Proofs We provide detailed proofs for the three propositions stated in the main text. The three results justify the main ...
2024
-
[55]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.